

Quando gli sviluppatori distribuiscono un carico di lavoro su una piattaforma di cloud computing, spesso non si soffermano a pensare all'hardware sottostante su cui vengono eseguiti i servizi. Nell'immagine idealizzata del "cloud", la manutenzione dell'hardware e i limiti fisici sono invisibili. Purtroppo, ogni tanto l'hardware ha bisogno di manutenzione, il che può causare tempi di inattività. Per evitare di trasferire questi tempi di inattività ai nostri clienti e per essere all'altezza della promessa del cloud, Linode implementa uno strumento chiamato Live Migrations.
Live Migrations è una tecnologia che consente alle istanze Linode di spostarsi tra le macchine fisiche senza interruzione del servizio. Quando un Linode viene spostato con Live Migrations, la transizione è invisibile ai processi di quel Linode. Se l'hardware di un host necessita di manutenzione, è possibile utilizzare Live Migrations per passare senza problemi tutti i Linode di quell'host a un nuovo host. Al termine della migrazione, l'hardware fisico può essere riparato e il tempo di inattività non avrà alcun impatto sui nostri clienti.
Per me lo sviluppo di questa tecnologia ha rappresentato un momento decisivo e un punto di svolta tra le tecnologie cloud e quelle non cloud. Ho un debole per la tecnologia Live Migrations perché ho trascorso più di un anno della mia vita a lavorarci. Ora posso condividere la storia con tutti voi.
Come funzionano le migrazioni live
Le migrazioni live in Linode sono iniziate come la maggior parte dei nuovi progetti: con molte ricerche, una serie di prototipi e l'aiuto di molti colleghi e manager. Il primo passo avanti è stato quello di studiare come QEMU gestisce le migrazioni live. QEMU è una tecnologia di virtualizzazione utilizzata da Linode e Live Migrations è una caratteristica di QEMU. Di conseguenza, l'obiettivo del nostro team era quello di portare questa tecnologia su Linode, e non di inventarla.
Quindi, come funziona la tecnologia Live Migration nel modo in cui QEMU l'ha implementata? La risposta è un processo in quattro fasi:
- L'istanza qemu di destinazione viene avviata con gli stessi parametri presenti nell'istanza qemu di origine.
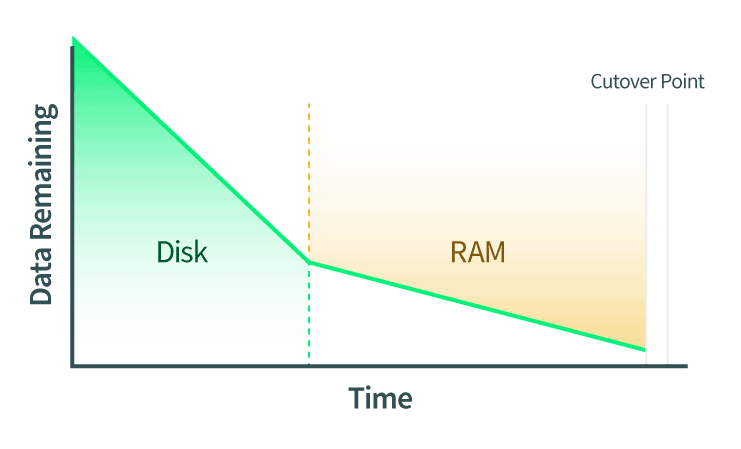
- I dischi vengono migrati in diretta. Durante il trasferimento vengono comunicate anche le eventuali modifiche apportate al disco.
- La RAM è migrata in diretta. Anche le eventuali modifiche alle pagine della RAM devono essere comunicate. Se durante questa fase vengono modificati anche i dati del disco, anche queste modifiche vengono copiate sul disco dell'istanza QEMU di destinazione.
- Il punto di cutover viene eseguito. Quando QEMU determina che ci sono poche pagine di RAM sufficienti a garantire il cutover, le istanze QEMU di origine e di destinazione vengono messe in pausa. QEMU copia le ultime pagine di RAM e lo stato della macchina. Lo stato della macchina include la cache della CPU e la prossima istruzione della CPU. Quindi, QEMU dice alla destinazione di avviarsi e quest'ultima riprende da dove si era interrotta l'origine.
Questi passaggi spiegano ad alto livello come eseguire una migrazione live con QEMU. Tuttavia, specificare esattamente come si desidera avviare l'istanza QEMU di destinazione è un processo molto manuale. Inoltre, ogni azione del processo deve essere avviata al momento giusto.
Come vengono implementate le migrazioni live in Linode
Dopo aver visto ciò che gli sviluppatori di QEMU hanno già creato, come possiamo utilizzarlo su Linode? La risposta a questa domanda è il punto in cui si è concentrato il grosso del lavoro del nostro team.
In conformità con la fase 1 del flusso di lavoro della migrazione live, l'istanza QEMU di destinazione viene avviata per accettare la migrazione live in arrivo. Nell'implementare questo passaggio, la prima idea è stata quella di prendere il profilo di configurazione del Linode corrente e avviarlo sulla macchina di destinazione. Questo sarebbe semplice in teoria, ma riflettendoci meglio si scoprono scenari più complicati. In particolare, il profilo di configurazione indica l'avvio del Linode, ma non descrive necessariamente lo stato completo del Linode dopo l'avvio. Ad esempio, un utente potrebbe aver collegato un Block Storage un dispositivo collegandolo a caldo al Linode dopo l'avvio, e questo non sarebbe documentato nel profilo di configurazione.
Per creare l'istanza di QEMU sull'host di destinazione, è stato necessario tracciare un profilo dell'istanza QEMU attualmente in esecuzione. Abbiamo profilato l'istanza QEMU in esecuzione ispezionando l'interfaccia QMP. Questa interfaccia fornisce informazioni su come è disposta l'istanza QEMU. Non fornisce informazioni su ciò che accade all'interno dell'istanza dal punto di vista del guest. Ci dice dove sono collegati i dischi e in quale slot PCI virtualizzato sono inseriti i dischi virtuali, sia per l'SSD locale che per lo storage a blocchi. Dopo aver interrogato QMP e aver ispezionato e introspettato l'istanza QEMU, viene creato un profilo che descrive esattamente come riprodurre questa macchina sulla destinazione.
Sulla macchina di destinazione riceviamo la descrizione completa dell'aspetto dell'istanza di partenza. Possiamo quindi ricreare fedelmente l'istanza qui, con una differenza. La differenza è che l'istanza QEMU di destinazione viene avviata con un'opzione che indica a QEMU di accettare una migrazione in arrivo.
A questo punto, dovremmo fare una pausa dalla documentazione delle migrazioni live e passare a spiegare come QEMU raggiunge questi risultati. L'albero dei processi di QEMU è costituito da un processo di controllo e da diversi processi worker. Uno dei processi worker è responsabile di cose come la restituzione delle chiamate QMP o la gestione di una migrazione live. Gli altri processi corrispondono uno a uno alle CPU del guest. L'ambiente del guest è isolato da questo lato di QEMU e si comporta come un sistema indipendente.
In questo senso, sono tre i livelli con cui lavoriamo:
- Il livello 1 è il nostro livello di gestione;
- Il Layer 2 è la parte del processo QEMU che gestisce tutte queste azioni per noi; e
- Il livello 3 è l'effettivo livello guest con cui interagiscono gli utenti di Linode.
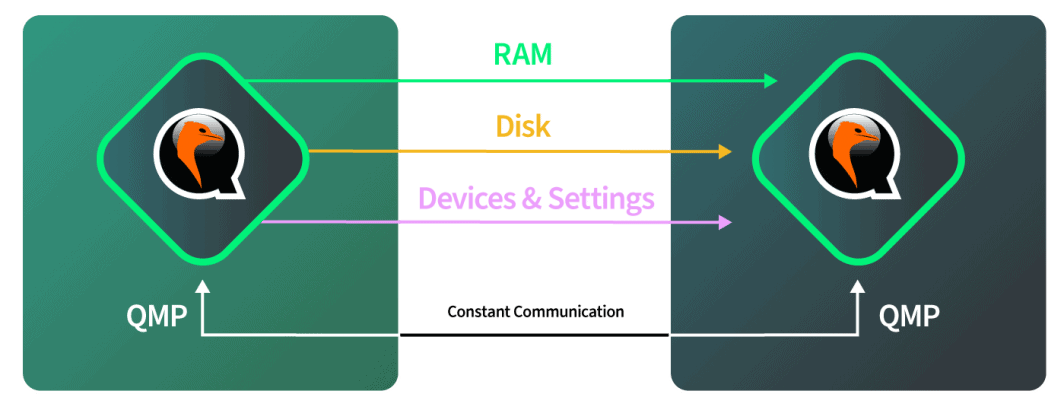
Dopo che la destinazione è stata avviata ed è pronta ad accettare la migrazione in arrivo, l'hardware della destinazione comunica all'hardware della sorgente che quest'ultima deve iniziare a inviare i dati. L'origine si avvia una volta ricevuto questo segnale e si dice a QEMU, nel software, di avviare la migrazione del disco. Il software monitora autonomamente l'avanzamento del disco per verificare quando è stato completato. Quando il disco è completo, il software passa automaticamente alla migrazione della RAM. Il software controlla di nuovo autonomamente la migrazione della RAM e passa automaticamente alla modalità di cutover quando la migrazione della RAM è completata. Tutto questo avviene sulla rete da 40 Gbps di Linode, quindi il lato rete è abbastanza veloce.
Cutover: La sezione critica
La fase di cutover è nota anche come la sezione critica di una migrazione live e la sua comprensione è la parte più importante della comprensione delle migrazioni live.
Al punto di cutover, QEMU ha stabilito che è pronto per il passaggio e l'avvio dell'esecuzione sulla macchina di destinazione. L'istanza QEMU di origine ordina a entrambe le parti di mettersi in pausa. Questo significa un paio di cose:
- Il tempo si ferma in base al guest. Se il guest esegue un servizio di sincronizzazione dell'ora come il Network Time Protocol(NTP), l'NTP risincronizzerà automaticamente l'ora al termine della migrazione live. Questo perché l'orologio di sistema sarà indietro di qualche secondo.
- Le richieste di rete si interrompono. Se le richieste di rete sono basate su TCP, come SSH o HTTP, non si percepisce alcuna perdita di connettività. Se le richieste di rete sono basate su UDP, come lo streaming video in diretta, potrebbero verificarsi alcune cadute di frame.
Poiché il tempo e le richieste di rete sono fermi, vogliamo che il cutover avvenga il più rapidamente possibile. Tuttavia, ci sono diverse cose che dobbiamo controllare prima per assicurarci che il cutover abbia successo:
- Assicurarsi che la migrazione live sia stata completata senza errori. Se si verifica un errore, si torna indietro, si mette in pausa il Linode di origine e non si procede oltre. Questo punto in particolare ha richiesto molti tentativi ed errori durante lo sviluppo ed è stato fonte di molto dolore, ma alla fine il nostro team è riuscito a risolverlo.
- Assicurarsi che la rete si spenga all'origine e si avvii correttamente alla destinazione.
- Il resto dell'infrastruttura sa esattamente su quale macchina fisica risiede ora questo Linode.
Poiché c'è un limite di tempo per il cutover, vogliamo completare queste fasi rapidamente. Dopo aver risolto questi punti, completiamo il cutover. Il Linode di origine riceve automaticamente il segnale di completamento e dice alla destinazione di iniziare. Il Linode di destinazione riprende da dove aveva lasciato. Tutti gli elementi rimasti sull'origine e sulla destinazione vengono ripuliti. Se il Linode di destinazione deve essere nuovamente migrato dal vivo in futuro, il processo può essere ripetuto.
Panoramica dei casi limite
La maggior parte di questo processo è stato semplice da implementare, ma lo sviluppo di Live Migrations è stato ampliato da casi limite. Gran parte del merito per il completamento di questo progetto va al team di gestione che ha visto la visione di uno strumento completo e ha stanziato le risorse per portare a termine il compito, nonché ai dipendenti che hanno portato a termine il progetto.
Ecco alcune delle aree in cui sono stati riscontrati casi limite:
- È stato necessario creare uno strumento interno per orchestrare le migrazioni live per i team di assistenza clienti e di gestione dell'hardware di Linode. Si trattava di uno strumento simile ad altri esistenti e utilizzati all'epoca, ma abbastanza diverso da richiedere un grande sforzo di sviluppo per la sua realizzazione:
- Questo strumento deve esaminare automaticamente l'intero parco hardware di un datacenter e capire quale host deve essere la destinazione di ogni Linode migrato in diretta. Le specifiche rilevanti per effettuare questa selezione includono lo spazio di archiviazione SSD disponibile e le allocazioni di RAM.
- Il processore fisico della macchina di destinazione deve essere compatibile con il Linode in arrivo. In particolare, una CPU può avere caratteristiche (chiamate anche flag della CPU) che il software degli utenti può sfruttare. Ad esempio, una di queste caratteristiche è aes, che fornisce una crittografia accelerata dall'hardware. La CPU della destinazione di una Live Migration deve supportare i flag della CPU della macchina di origine. Questo si è rivelato un caso limite molto complesso e la prossima sezione descrive una soluzione a questo problema.
- Gestire con grazia i casi di errore, tra cui l'intervento dell'utente finale o la perdita della rete durante la migrazione live. Questi casi di errore sono elencati in modo più dettagliato in una sezione successiva di questo post.
- Tenere il passo con i cambiamenti della piattaforma Linode, che è un processo continuo. Per ogni funzionalità che supportiamo su Linode ora e in futuro, dobbiamo assicurarci che sia compatibile con Live Migrations. Questa sfida è descritta alla fine di questo post.
Flag della CPU
QEMU ha diverse opzioni per presentare una CPU al sistema operativo guest. Una di queste opzioni consiste nel passare il numero di modello e le caratteristiche della CPU host (chiamate anche flag della CPU) direttamente al guest. Scegliendo questa opzione, il guest può utilizzare tutta la potenza libera consentita dal sistema di virtualizzazione KVM . Quando KVM è stato adottato per la prima volta da Linode (che ha preceduto le Live Migrations), questa opzione è stata scelta per massimizzare le prestazioni. Tuttavia, questa decisione ha presentato in seguito molte sfide durante lo sviluppo di Live Migrations.

Nell'ambiente di test per le migrazioni live, gli host di origine e di destinazione erano due macchine identiche. Nel mondo reale il nostro parco hardware non è uguale al 100% e ci sono differenze tra le macchine che possono portare alla presenza di flag CPU diversi. Questo è importante perché quando un programma viene caricato all'interno del sistema operativo di Linode, quest'ultimo presenta i flag della CPU a tale programma, che caricherà sezioni specifiche del software in memoria per sfruttare tali flag. Se un Linode viene migrato in diretta a una macchina di destinazione che non supporta tali flag della CPU, il programma si blocca. Questo può portare all'arresto del sistema operativo guest e al riavvio di Linode.
Abbiamo individuato tre fattori che influenzano il modo in cui i flag della CPU di una macchina vengono presentati agli ospiti:
- Esistono piccole differenze tra le CPU, a seconda della data di acquisto. Una CPU acquistata alla fine dell'anno può avere flag diversi rispetto a una acquistata all'inizio dell'anno, a seconda di quando i produttori di CPU rilasciano nuovo hardware. Linode acquista costantemente nuovo hardware per aggiungere capacità, e anche se il modello di CPU per due ordini di hardware diversi è lo stesso, i flag della CPU possono differire.
- Kernel Linux diversi possono passare flag diversi a QEMU. In particolare, il kernel Linux della macchina di origine di una migrazione live può passare flag diversi a QEMU rispetto al kernel Linux della macchina di destinazione. L'aggiornamento del kernel Linux sulla macchina di origine richiede un riavvio, quindi questa discrepanza non può essere risolta aggiornando il kernel prima di procedere con la migrazione live, perché ciò comporterebbe un tempo di inattività per i Linode su quella macchina.
- Allo stesso modo, versioni diverse di QEMU possono influenzare i flag della CPU presentati. L'aggiornamento di QEMU richiede anche un riavvio della macchina.
Per questo motivo, è stato necessario implementare le migrazioni live in modo da evitare gli arresti anomali del programma a causa di una mancata corrispondenza dei flag della CPU. Sono disponibili due opzioni:
- Potremmo dire a QEMU di emulare i flag della CPU. In questo modo, il software che prima andava veloce ora va lento, senza che si possa indagare sul perché.
- Possiamo raccogliere un elenco di flag della CPU sull'origine e assicurarci che la destinazione abbia gli stessi flag prima di procedere. Si tratta di un'operazione più complicata, ma che consente di preservare la velocità dei programmi dei nostri utenti. Questa è l'opzione che abbiamo implementato per le migrazioni live.
Dopo aver deciso di abbinare i flag della CPU di origine e di destinazione, abbiamo svolto questo compito con un approccio a cinghia e bretelle che consisteva in due metodi diversi:
- Il primo metodo è il più semplice dei due. Tutti i flag della CPU vengono inviati dall'origine all'hardware di destinazione. Quando l'hardware di destinazione configura la nuova istanza qemu, controlla che abbia almeno tutti i flag presenti sul Linode di origine. Se non corrispondono, la migrazione live non procede.
- Il secondo metodo è molto più complicato, ma può evitare migrazioni fallite a causa di una mancata corrispondenza dei flag della CPU. Prima di avviare una migrazione live, si crea un elenco di hardware con flag CPU compatibili. Quindi si sceglie una macchina di destinazione da questo elenco.
Questo secondo metodo deve essere eseguito rapidamente e comporta una notevole complessità. In alcuni casi, dobbiamo controllare fino a 226 flag della CPU su più di 900 macchine. Scrivere tutti questi 226 controlli dei flag della CPU sarebbe molto difficile e sarebbe necessario mantenerli. Questo problema è stato risolto da un'idea straordinaria proposta dal fondatore di Linode, Chris Aker.
L'idea chiave è stata quella di creare un elenco di tutti i flag della CPU e di rappresentarlo come una stringa binaria. Quindi, è possibile utilizzare l'operazione bitwise e per confrontare le stringhe. Per dimostrare questo algoritmo, inizierò con un semplice esempio. Consideriamo questo codice Python che confronta due numeri utilizzando l'operazione bitwise and:
>>> 1 & 1
1
>>> 2 & 3
2
>>> 1 & 3
1Per capire perché l'operazione bitwise and dà questi risultati, è utile rappresentare i numeri in binario. Esaminiamo l'operazione bitwise and per i numeri 2 e 3, rappresentati in binario:
>>> # 2: 00000010
>>> # &
>>> # 3: 00000011
>>> # =
>>> # 2: 00000010L'operazione bitwise and confronta le cifre binarie, o bit, di due numeri diversi. Partendo dalla cifra più a destra nei numeri precedenti e procedendo verso sinistra:
- I bit più a destra/primi di 2 e 3 sono rispettivamente 0 e 1. Il bitwise e il risultato per
0 & 1è 0. - Il secondo bit più a destra di 2 e 3 è 1 per entrambi i numeri. Il risultato bitwise e per
1 & 1è 1. - Tutti gli altri bit di questi numeri sono 0, e il risultato bitwise and 0 è 0.
La rappresentazione binaria del risultato completo è quindi 00000010che è uguale a 2.
Per le migrazioni live, l'elenco completo dei flag della CPU è rappresentato come una stringa binaria, dove ogni bit rappresenta un singolo flag. Se il bit è 0, il flag non è presente, mentre se il bit è 1, il flag è presente. Ad esempio, un bit può corrispondere al flag aes e un altro bit al flag mmx. Le posizioni specifiche di questi flag nella rappresentazione binaria sono mantenute, documentate e condivise dalle macchine dei nostri data center.
Mantenere questa rappresentazione a elenco è molto più semplice ed efficiente che mantenere un insieme di istruzioni if che ipoteticamente controllerebbero la presenza di un flag della CPU. Ad esempio, supponiamo che ci siano 7 flag della CPU che devono essere monitorati e controllati in totale. Questi flag potrebbero essere memorizzati in un numero a 8 bit (con un bit in più per un'espansione futura). Un esempio di stringa potrebbe essere il seguente 00111011dove il bit più a destra indica che aes è abilitato, il secondo bit più a destra indica che mmx è abilitato, il terzo bit indica che un altro flag è disabilitato e così via.
Come mostrato nel prossimo frammento di codice, possiamo vedere quale hardware supporterà questa combinazione di flag e restituire tutte le corrispondenze in un solo ciclo. Se avessimo usato una serie di if per calcolare queste corrispondenze, avremmo impiegato un numero molto più elevato di cicli per ottenere questo risultato. Per un esempio di Live Migration in cui erano presenti 4 flag della CPU sulla macchina di origine, sarebbero stati necessari 203.400 cicli per trovare l'hardware corrispondente.
Il codice Live Migration esegue un'operazione bitwise and sulle stringhe di flag della CPU della macchina di origine e di quella di destinazione. Se il risultato è uguale alla stringa dei flag della CPU della macchina di origine, la macchina di destinazione è compatibile. Si consideri questo frammento di codice Python :
>>> # The b'' syntax below represents a binary string
>>>
>>> # The s variable stores the example CPU flag
>>> # string for the source:
>>> s = b'00111011'
>>> # The source CPU flag string is equivalent to the number 59:
>>> int(s.decode(), 2)
59
>>>
>>> # The d variable stores the example CPU flag
>>> # string for the source:
>>> d = b'00111111'
>>> # The destination CPU flag string is equivalent to the number 63:
>>> int(d.decode(), 2)
63
>>>
>>> # The bitwise and operation compares these two numbers:
>>> int(s.decode(), 2) & int(d.decode(), 2) == int(s.decode(), 2)
True
>>> # The previous statement was equivalent to 59 & 63 == 59.
>>>
>>> # Because source & destination == source,
>>> # the machines are compatibleSi noti che nel frammento di codice sopra riportato, la destinazione supportava un numero maggiore di flag rispetto all'origine. Le macchine sono considerate compatibili perché tutti i flag della CPU dell'origine sono presenti nella destinazione, come garantisce l'operazione bitwise and.
I risultati di questo algoritmo vengono utilizzati dal nostro tooling interno per creare un elenco di hardware compatibili. Questo elenco viene visualizzato dai team dell'assistenza clienti e delle operazioni hardware. Questi team possono utilizzare il tooling per orchestrare diverse operazioni:
- Il tooling può essere usato per selezionare il miglior hardware compatibile per un determinato Linode.
- È possibile avviare una migrazione live per un Linode senza specificare una destinazione. Verrà selezionato automaticamente il miglior hardware compatibile nello stesso datacenter e la migrazione avrà inizio.
- È possibile avviare le migrazioni live per tutti i Linode di un host come un'unica attività. Questa funzionalità viene utilizzata prima di eseguire la manutenzione di un host. Il tooling seleziona automaticamente le destinazioni per tutti i Linode e orchestra le migrazioni live per ciascun Linode.
- Possiamo specificare un elenco di macchine che necessitano di manutenzione e il tooling orchestrerà automaticamente le migrazioni live per tutti i Linode sugli host.
Molto tempo di sviluppo viene impiegato per far sì che il software "funzioni e basta"...
Casi di fallimento
Una caratteristica di cui non si parla molto spesso nel software è la gestione dei casi di guasto con garbo. Il software dovrebbe "funzionare e basta". Molto tempo di sviluppo viene dedicato a far sì che il software "funzioni e basta", e questo è stato il caso di Live Migrations. È stato dedicato molto tempo a pensare a tutti i modi in cui questo strumento non poteva funzionare e a gestire con garbo questi casi. Ecco alcuni di questi scenari e come sono stati affrontati:
- Cosa succede se un cliente vuole accedere a una funzione del proprio Linode dal sito web di Linode? Cloud Manager? Per esempio, un utente può riavviare il Linode o collegarvi un volume Block Storage .
- Risposta: Il cliente ha la facoltà di farlo. La migrazione live viene interrotta e non procede. Questa soluzione è appropriata perché la migrazione live può essere tentata in un secondo momento.
- Cosa succede se il Linode di destinazione non si avvia?
- Risposta: Informare l'hardware di origine e progettare il tooling interno per scegliere automaticamente un altro pezzo di hardware nel data center. Inoltre, informare il team operativo in modo che possa indagare sull'hardware della destinazione originale. Questo è accaduto in produzione ed è stato gestito dalla nostra implementazione di Live Migrations.
- Cosa succede se si perde la rete a metà della migrazione?
- Risposta: Monitorare autonomamente l'avanzamento della migrazione live e, se non ha fatto progressi nell'ultimo minuto, annullare la migrazione live e informare il team operativo. Questo non è accaduto al di fuori di un ambiente di test, ma la nostra implementazione è preparata per questo scenario.
- Cosa succede se il resto di Internet si spegne, ma l'hardware di origine e di destinazione è ancora in funzione e comunica e il Linode di origine o di destinazione funziona normalmente?
- Risposta: Se la migrazione in tempo reale non è nella sezione critica, interrompere la migrazione in tempo reale. Ripetere l'operazione in un secondo momento.
- Se ci si trova nella sezione critica, continuare la migrazione live. Questo è importante perché il Linode di origine è in pausa e il Linode di destinazione deve essere avviato per riprendere il funzionamento.
- Questi scenari sono stati modellati nell'ambiente di test e il comportamento prescritto è risultato essere il migliore.
Tenere il passo con i cambiamenti
Dopo centinaia di migliaia di migrazioni live di successo, una domanda che a volte ci si pone è: "Quando sono finite le migrazioni live?". Le migrazioni dal vivo sono una tecnologia il cui uso si espande nel tempo e che viene continuamente perfezionata, quindi non è necessariamente semplice stabilire la fine del progetto. Un modo per rispondere a questa domanda è considerare quando la maggior parte del lavoro per questo progetto è completato. La risposta è: per un software affidabile, il lavoro non è finito per molto tempo.
Quando nel tempo vengono sviluppate nuove funzionalità per Linodes, è necessario lavorare per garantire la compatibilità con Live Migrations per tali funzionalità. Quando si introducono alcune funzionalità, non è necessario svolgere un nuovo lavoro di sviluppo su Live Migrations, ma è sufficiente verificare che Live Migrations continui a funzionare come previsto. Per altre, il lavoro di compatibilità con Live Migrations è contrassegnato come compito all'inizio dello sviluppo delle nuove funzionalità.
Come per ogni cosa nel software, ci sono sempre metodi di implementazione migliori che vengono scoperti attraverso la ricerca. Ad esempio, è possibile che un approccio più modulare all'integrazione di Live Migrations offra meno manutenzione a lungo termine. Oppure, è possibile che l'integrazione delle funzionalità di Live Migrations nel codice di livello più basso possa aiutare a renderle disponibili per le future funzionalità di Linode. I nostri team considerano tutte queste opzioni e gli strumenti che alimentano la piattaforma Linode sono entità vive che continueranno a evolversi.






Commenti