

この投稿は「Scaling Kubernetes Series」の一部です。 登録をクリックしてライブ視聴または録画にアクセスし、このシリーズの他の投稿をご覧ください。
Kubernetesの興味深い課題の1つは、複数の地域にまたがるワークロードのデプロイです。技術的には、異なる地域に配置された複数のノードを持つクラスタを持つことができますが、これは一般的に余分なレイテンシーのために避けるべきものと見なされています。
一般的な代替案は、地域ごとにクラスターを展開し、それらをオーケストレーションする方法を見つけることです。
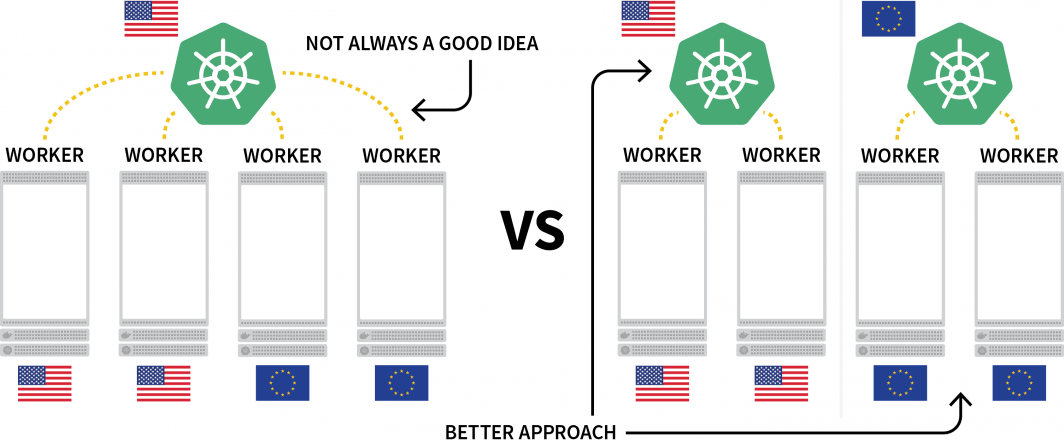
この記事で、あなたは
- 北米、欧州、東南アジアにそれぞれ1つずつ、計3つのクラスターを作る。
- 他のクラスターのオーケストレーターとして機能する4番目のクラスターを作成します。
- 3つのクラスタネットワークのうち、1つのネットワークを設定し、シームレスな通信を実現します。
この投稿は、最小限のインタラクションを必要とするTerraform で動作するようにスクリプト化されています。そのためのコードはLearnK8sのGitHubで見つけることができます。
クラスターマネージャーの作成
まずは、残りを管理するクラスタの作成から始めましょう。以下のコマンドでクラスターを作成し、kubeconfigファイルを保存することができます。
bash
$ linode-cli lke cluster-create \
--label cluster-manager \
--region eu-west \
--k8s_version 1.23
$ linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfig-cluster-managerでインストールが成功したことを確認できます。
bash
$ kubectl get pods -A --kubeconfig=kubeconfig-cluster-managerエクセレント!
クラスタマネージャでは、複数のKubernetesクラスタやクラウドにまたがってクラウドネイティブなアプリケーションを実行できる管理システム「Karmada」をインストールします。Karmadaは、クラスタマネージャにコントロールプレーンがインストールされ、それ以外のクラスタにエージェントがインストールされます。
コントロールプレーンは3つの要素で構成されています。
- アン API サーバー
- コントローラー・マネージャー
- スケジューラ
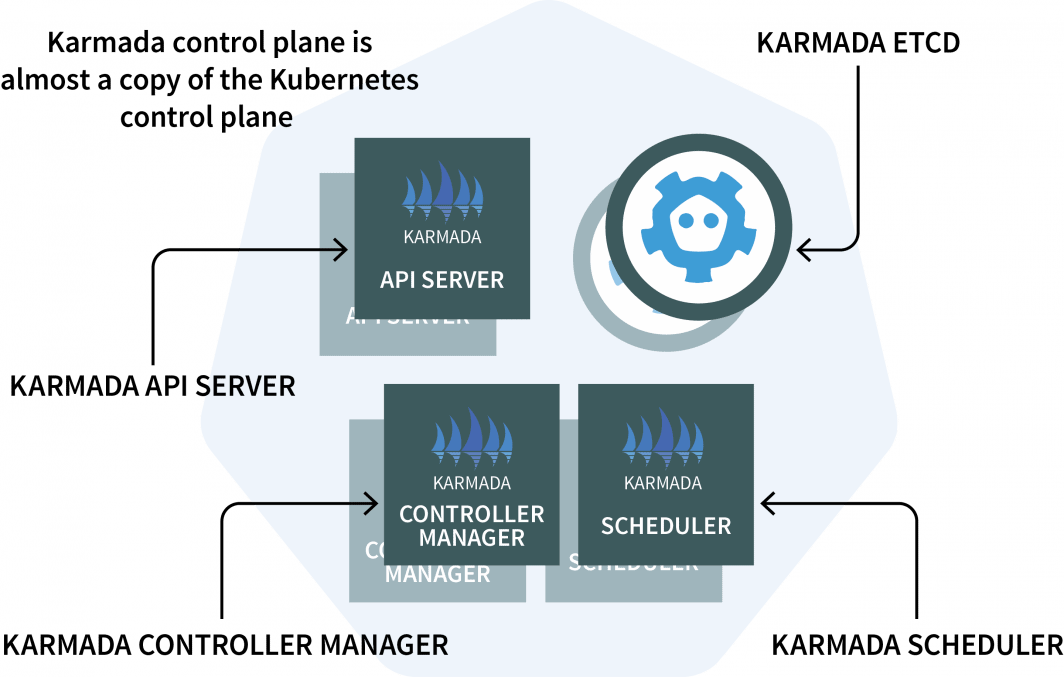
もし見覚えがあるとしたら、それはKubernetesのコントロールプレーンが同じコンポーネントを備えているからです。Karmadaは、複数のクラスタで動作させるために、それらをコピーして補強する必要がありました。
理論はもう十分だ。コードに入りましょう。
Helmを使ってKarmadaサーバーをインストールします。 API サーバーをインストールします。Helmリポジトリを追加しましょう:
bash
$ helm repo add karmada-charts https://raw.githubusercontent.com/karmada-io/karmada/master/charts
$ helm repo list
NAME URL
karmada-charts https://raw.githubusercontent.com/karmada-io/karmada/master/chartsKarmada API サーバーは他のすべてのクラスタからアクセス可能でなければならないので、次のことが必要になります。
- ノードから公開する。
- は、接続が信頼できることを確認します。
で、コントロールプレーンをホストしているノードのIPアドレスを取得してみましょう。
bash
kubectl get nodes -o jsonpath='{.items[0].status.addresses[?(@.type==\"ExternalIP\")].address}' \
--kubeconfig=kubeconfig-cluster-managerでKarmadaコントロールプレーンをインストールすることができるようになりました。
bash
$ helm install karmada karmada-charts/karmada \
--kubeconfig=kubeconfig-cluster-manager \
--create-namespace --namespace karmada-system \
--version=1.2.0 \
--set apiServer.hostNetwork=false \
--set apiServer.serviceType=NodePort \
--set apiServer.nodePort=32443 \
--set certs.auto.hosts[0]="kubernetes.default.svc" \
--set certs.auto.hosts[1]="*.etcd.karmada-system.svc.cluster.local" \
--set certs.auto.hosts[2]="*.karmada-system.svc.cluster.local" \
--set certs.auto.hosts[3]="*.karmada-system.svc" \
--set certs.auto.hosts[4]="localhost" \
--set certs.auto.hosts[5]="127.0.0.1" \
--set certs.auto.hosts[6]="<insert the IP address of the node>"インストールが完了したら、kubeconfig を取得して Karmada に接続します。 API に接続します:
bash
kubectl get secret karmada-kubeconfig \
--kubeconfig=kubeconfig-cluster-manager \
-n karmada-system \
-o jsonpath={.data.kubeconfig} | base64 -d > karmada-configしかし、ちょっと待ってください、なぜ別のkubeconfigファイルを?
Karmada API は、標準的なKubernetesを置き換えるように設計されている。 API を置き換えるように設計されているが、あなたが慣れ親しんでいる機能はすべて残している。つまり、kubectlを使って複数のクラスタにまたがるデプロイメントを作成できる。
をテストする前に、Karmada API とkubectlをテストする前に、kubeconfigファイルにパッチを当てる必要があります。デフォルトでは、生成されたkubeconfigはクラスタネットワーク内からしか使用できません。
ただし、以下の行を置き換えることで、動作するようになります。
yaml
apiVersion: v1
kind: Config
clusters:
- cluster:
certificate-authority-data: LS0tLS1CRUdJTi…
insecure-skip-tls-verify: false
server: https://karmada-apiserver.karmada-system.svc.cluster.local:5443 # <- this works only in the cluster
name: karmada-apiserver
# truncatedこれを先ほど取得したノードのIPアドレスに置き換えてください。
yaml
apiVersion: v1
kind: Config
clusters:
- cluster:
certificate-authority-data: LS0tLS1CRUdJTi…
insecure-skip-tls-verify: false
server: https://<node's IP address>:32443 # <- this works from the public internet
name: karmada-apiserver
# truncated素晴らしい、カルマダを試すときが来たのだ。
Karmadaエージェントのインストール
次のコマンドを実行し、すべてのデプロイメントとすべてのクラスタを取得します。
bash
$ kubectl get clusters,deployments --kubeconfig=karmada-config
No resources found当然のことながら、デプロイはされておらず、クラスタも追加されていません。さらにいくつかのクラスタを追加して、Karmadaコントロールプレーンに接続してみましょう。
以下のコマンドを3回繰り返してください。
bash
linode-cli lke cluster-create \
--label <insert-cluster-name> \
--region <insert-region> \
--k8s_version 1.23
linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfig-<insert-cluster-name>値は以下の通りであることが望ましい。
- クラスター名
eu地域eu-wesトとkubeconfigファイルkubeconfig-eu - クラスター名
ap地域ap-southとkubeconfigファイルkubeconfig-ap - クラスター名
us地域us-westとkubeconfigファイルkubeconfig-us
でクラスタが正常に作成されたことを確認できます。
bash
$ kubectl get pods -A --kubeconfig=kubeconfig-eu
$ kubectl get pods -A --kubeconfig=kubeconfig-ap
$ kubectl get pods -A --kubeconfig=kubeconfig-us今度は、彼らをカルマダクラスターに参加させる番です。
Karmadaは、他のクラスタごとにエージェントを使用して、コントロールプレーンとのデプロイメントを調整します。
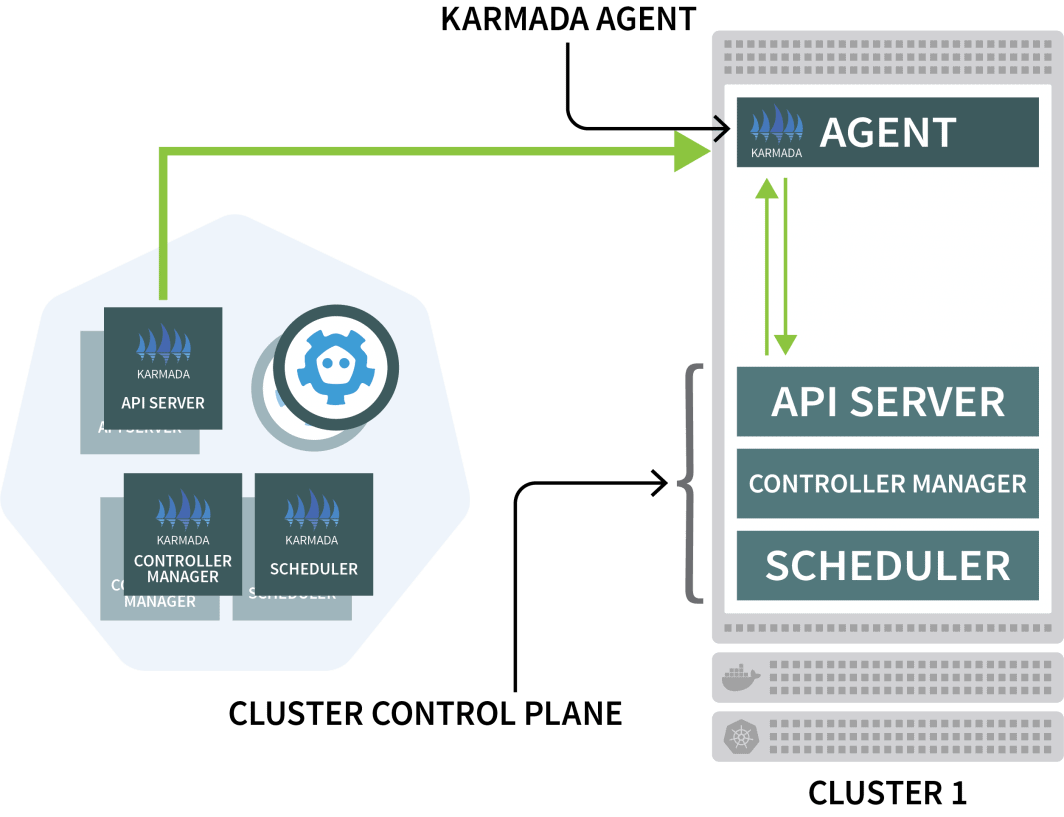
Helmを使用してKarmadaエージェントをインストールし、クラスタマネージャにリンクします。
bash
$ helm install karmada karmada-charts/karmada \
--kubeconfig=kubeconfig-<insert-cluster-name> \
--create-namespace --namespace karmada-system \
--version=1.2.0 \
--set installMode=agent \
--set agent.clusterName=<insert-cluster-name> \
--set agent.kubeconfig.caCrt=<karmada kubeconfig certificate authority> \
--set agent.kubeconfig.crt=<karmada kubeconfig client certificate data> \
--set agent.kubeconfig.key=<karmada kubeconfig client key data> \
--set agent.kubeconfig.server=https://<insert node's IP address>:32443 \上記のコマンドを3回繰り返し、以下の変数を挿入する必要があります。
- クラスター名。これは以下のいずれかです。
eu,apまたはus - クラスタ・マネージャの認証局。この値は
karmada-configファイルunder clusters[0].cluster['certificate-authority-data'].
から値をデコードすることができます。 ベース64. - ユーザーのクライアント証明書データです。この値は
karmada-configファイルアンダーusers[0].user['client-certificate-data'].
base64から値をデコードすることができます。 - ユーザーのクライアント証明書データです。この値は
karmada-configファイルアンダーusers[0].user['client-key-data'].
base64から値をデコードすることができます。 - KarmadaコントロールプレーンをホストしているノードのIPアドレス。
インストールが完了したことを確認するために、次のコマンドを実行します。
bash
$ kubectl get clusters --kubeconfig=karmada-config
NAME VERSION MODE READY
eu v1.23.8 Pull True
ap v1.23.8 Pull True
us v1.23.8 Pull Trueエクセレント!
Karmada ポリシーによるマルチクラスターデプロイメントのオーケストレーション
現在の構成では、Karmadaにワークロードを投入すると、Karmadaがそれを他のクラスタに分散させます。
デプロイメントを作成してテストしてみましょう。
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello
spec:
replicas: 3
selector:
matchLabels:
app: hello
template:
metadata:
labels:
app: hello
spec:
containers:
- image: stefanprodan/podinfo
name: hello
---
apiVersion: v1
kind: Service
metadata:
name: hello
spec:
ports:
- port: 5000
targetPort: 9898
selector:
app: helloデプロイメントを Karmada サーバに送信するには、次のようにします。 API サーバーに送信できます:
bash
$ kubectl apply -f deployment.yaml --kubeconfig=karmada-configこのデプロイメントには3つのレプリカがありますが、これらは3つのクラスタに均等に分散されるのでしょうか?
確認しよう。
bash
$ kubectl get deployments --kubeconfig=karmada-config
NAME READY UP-TO-DATE AVAILABLE
hello 0/3 0 0なぜ、カルマダはポッドを作らないのですか?
デプロイメントを説明しよう。
bash
$ kubectl describe deployment hello --kubeconfig=karmada-config
Name: hello
Namespace: default
Selector: app=hello
Replicas: 3 desired | 0 updated | 0 total | 0 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Events:
Type Reason From Message
---- ------ ---- -------
Warning ApplyPolicyFailed resource-detector No policy match for resourceKarmadaは、あなたがポリシーを指定していないため、デプロイメントをどうすればいいかわからないのです。
Karmadaスケジューラは、クラスタにワークロードを割り当てるために、ポリシーを使用します。
各クラスタにレプリカを割り当てる簡単なポリシーを定義してみましょう。
yaml
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: hello-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: hello
- apiVersion: v1
kind: Service
name: hello
placement:
clusterAffinity:
clusterNames:
- eu
- ap
- us
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- us
weight: 1
- targetCluster:
clusterNames:
- ap
weight: 1
- targetCluster:
clusterNames:
- eu
weight: 1でクラスタにポリシーを提出することができます。
bash
$ kubectl apply -f policy.yaml --kubeconfig=karmada-configデプロイメントとポッドを点検してみましょう。
bash
$ kubectl get deployments --kubeconfig=karmada-config
NAME READY UP-TO-DATE AVAILABLE
hello 3/3 3 3
$ kubectl get pods --kubeconfig=kubeconfig-eu
NAME READY STATUS RESTARTS
hello-5d857996f-hjfqq 1/1 Running 0
$ kubectl get pods --kubeconfig=kubeconfig-ap
NAME READY STATUS RESTARTS
hello-5d857996f-xr6hr 1/1 Running 0
$ kubectl get pods --kubeconfig=kubeconfig-us
NAME READY STATUS RESTARTS
hello-5d857996f-nbz48 1/1 Running 0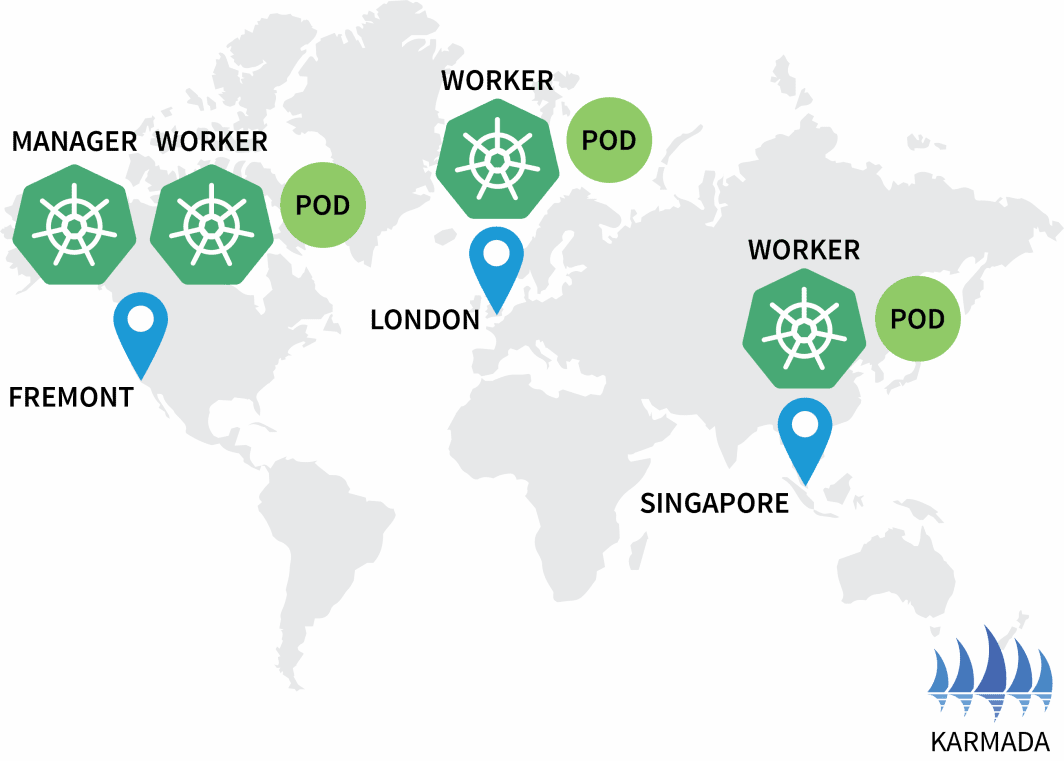
Karmadaは、ポリシーで各クラスタに等しい重みが定義されているため、各クラスタにポッドを割り当てました。
で10個のレプリカにデプロイメントをスケールしてみましょう。
bash
$ kubectl scale deployment/hello --replicas=10 --kubeconfig=karmada-configポッドを検査すると、次のようなものが見つかるかもしれません。
bash
$ kubectl get deployments --kubeconfig=karmada-config
NAME READY UP-TO-DATE AVAILABLE
hello 10/10 10 10
$ kubectl get pods --kubeconfig=kubeconfig-eu
NAME READY STATUS RESTARTS
hello-5d857996f-dzfzm 1/1 Running 0
hello-5d857996f-hjfqq 1/1 Running 0
hello-5d857996f-kw2rt 1/1 Running 0
hello-5d857996f-nz7qz 1/1 Running 0
$ kubectl get pods --kubeconfig=kubeconfig-ap
NAME READY STATUS RESTARTS
hello-5d857996f-pd9t6 1/1 Running 0
hello-5d857996f-r7bmp 1/1 Running 0
hello-5d857996f-xr6hr 1/1 Running 0
$ kubectl get pods --kubeconfig=kubeconfig-us
NAME READY STATUS RESTARTS
hello-5d857996f-nbz48 1/1 Running 0
hello-5d857996f-nzgpn 1/1 Running 0
hello-5d857996f-rsp7k 1/1 Running 0EUとUSのクラスタが40%のポッドを持ち、APクラスタには20%しか残らないように、方針を修正しよう。
yaml
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: hello-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: hello
- apiVersion: v1
kind: Service
name: hello
placement:
clusterAffinity:
clusterNames:
- eu
- ap
- us
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- us
weight: 2
- targetCluster:
clusterNames:
- ap
weight: 1
- targetCluster:
clusterNames:
- eu
weight: 2で保険証券を提出することができます。
bash
$ kubectl apply -f policy.yaml --kubeconfig=karmada-configそれに伴い、ポッドの分布が変化しているのが観察できます。
bash
$ kubectl get pods --kubeconfig=kubeconfig-eu
NAME READY STATUS RESTARTS AGE
hello-5d857996f-hjfqq 1/1 Running 0 6m5s
hello-5d857996f-kw2rt 1/1 Running 0 2m27s
$ kubectl get pods --kubeconfig=kubeconfig-ap
hello-5d857996f-k9hsm 1/1 Running 0 51s
hello-5d857996f-pd9t6 1/1 Running 0 2m41s
hello-5d857996f-r7bmp 1/1 Running 0 2m41s
hello-5d857996f-xr6hr 1/1 Running 0 6m19s
$ kubectl get pods --kubeconfig=kubeconfig-us
hello-5d857996f-nbz48 1/1 Running 0 6m29s
hello-5d857996f-nzgpn 1/1 Running 0 2m51s
hello-5d857996f-rgj9t 1/1 Running 0 61s
hello-5d857996f-rsp7k 1/1 Running 0 2m51s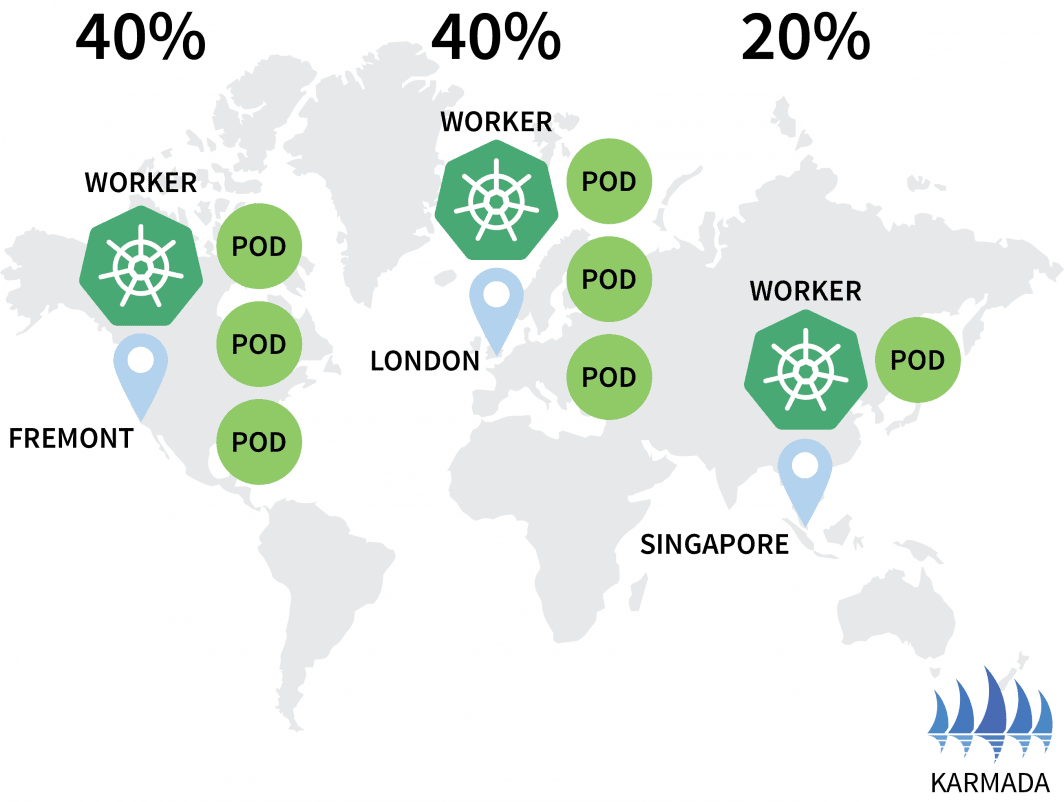
最高ですね。
Karmadaはワークロードを分散させるためのいくつかのポリシーをサポートしています。より高度なユースケースについては、ドキュメントをご覧ください。
3つのクラスターでポッドが動いていますが、どのようにアクセスすればよいのでしょうか。
Karmadaのサービスを点検してみよう。
bash
$ kubectl describe service hello --kubeconfig=karmada-config
Name: hello
Namespace: default
Labels: propagationpolicy.karmada.io/name=hello-propagation
propagationpolicy.karmada.io/namespace=default
Selector: app=hello
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.105.24.193
IPs: 10.105.24.193
Port: <unset> 5000/TCP
TargetPort: 9898/TCP
Events:
Type Reason Message
---- ------ -------
Normal SyncSucceed Successfully applied resource(default/hello) to cluster ap
Normal SyncSucceed Successfully applied resource(default/hello) to cluster us
Normal SyncSucceed Successfully applied resource(default/hello) to cluster eu
Normal AggregateStatusSucceed Update resourceBinding(default/hello-service) with AggregatedStatus successfully.
Normal ScheduleBindingSucceed Binding has been scheduled
Normal SyncWorkSucceed Sync work of resourceBinding(default/hello-service) successful.サービスは3つのクラスタすべてに展開されているが、それらは接続されていない。
Karmadaが複数のクラスタを管理できるとしても、3つのクラスタがリンクしていることを確認するためのネットワーキングメカニズムは提供 されません。言い換えれば、Karmadaはクラスタ間のデプロイメントをオーケストレーションするための優れたツールですが、それらのクラスタが互いに通信できることを確認するために何か他のものが必要なのです。
Istioで複数のクラスターを接続する
Istioは通常、同じクラスタ内のアプリケーション間のネットワークトラフィックを制御するために使用されます。これは、すべての送信および受信要求を傍受し、Envoyを介してそれらをプロキシングすることによって動作します。
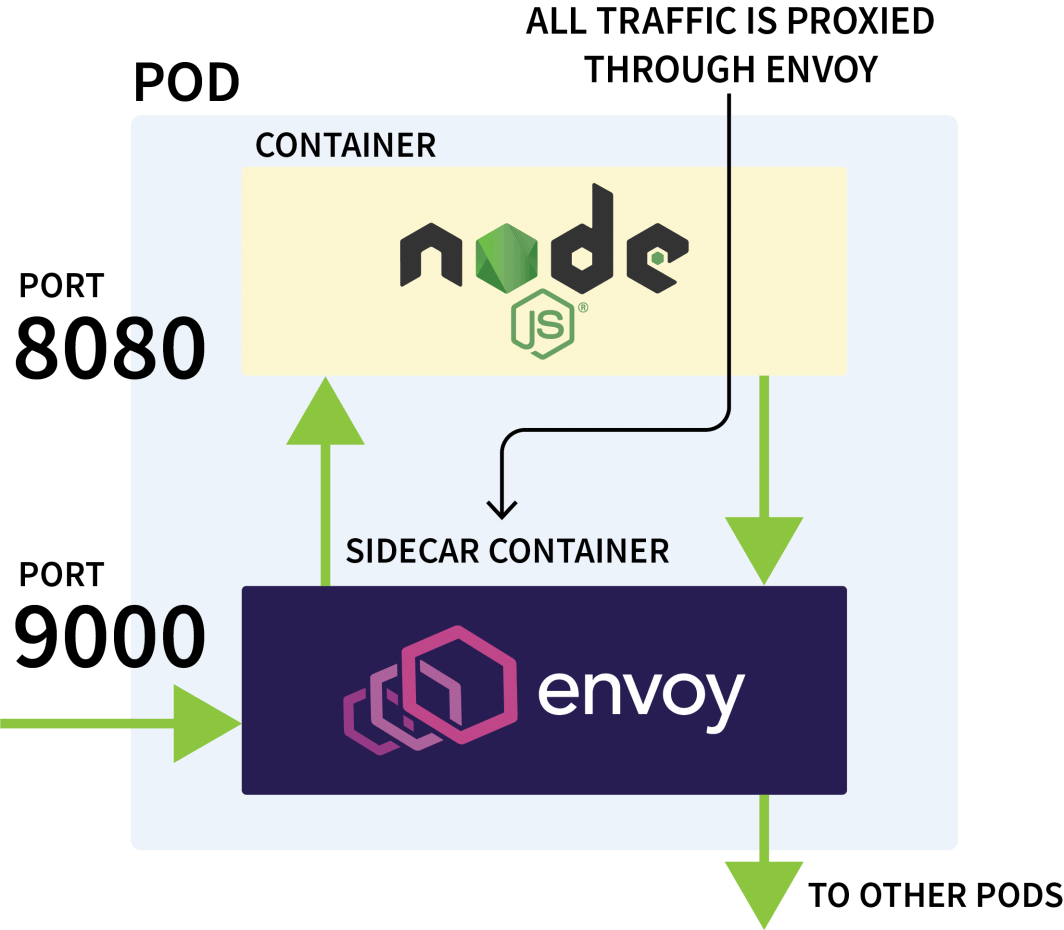
Istioのコントロールプレーンは、それらのプロキシからメトリックの更新と収集を担当し、トラフィックを迂回させる指示を出すこともできる。
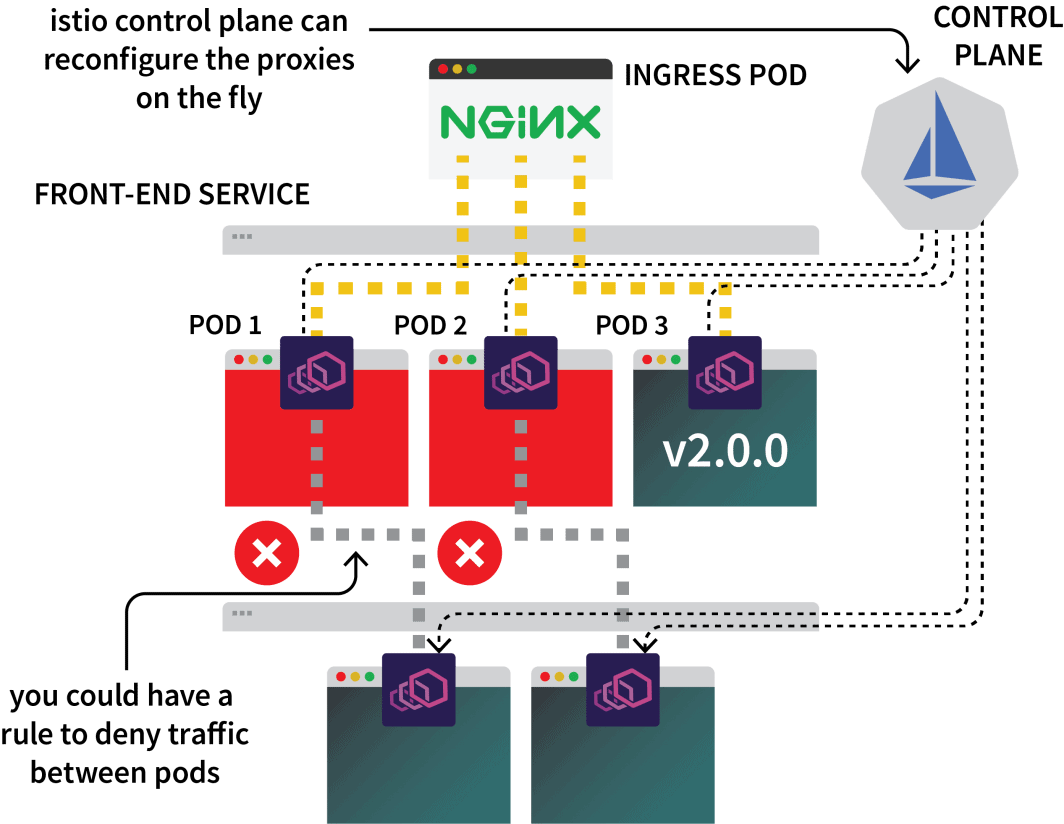
つまり、Istioを使って特定のサービスに対するすべてのトラフィックをインターセプトし、3つのクラスタのうちの1つに誘導することができます。それがIstioのマルチクラスターセットアップのアイデアです。
理論はこれくらいにして、さっそく手を動かしてみましょう。最初のステップは、3つのクラスタにIstioをインストールすることです。
Istioをインストールする方法はいくつかありますが、私は通常、Helmを使用します。
bash
$ helm repo add istio https://istio-release.storage.googleapis.com/charts
$ helm repo list
NAME URL
istio https://istio-release.storage.googleapis.com/chartsで3つのクラスタにIstioをインストールすることができます。
bash
$ helm install istio-base istio/base \
--kubeconfig=kubeconfig-<insert-cluster-name> \
--create-namespace --namespace istio-system \
--version=1.14.1を交換する必要があります。 cluster-name をもって ap, eu と us を実行し、それぞれについてコマンドを実行します。
ベースチャートは、RolesやRoleBindingsなど、主に共通のリソースをインストールします。
実際のインストールは、パッケージの istiod チャートで確認することができます。しかし、それを進める前に Istio認証局(CA)を設定する の3つのクラスタが互いに接続し、信頼できることを確認するためです。
新しいディレクトリで、Istioのリポジトリをcloneする。
bash
$ git clone https://github.com/istio/istioを作成します。 certs フォルダに移動し、そのディレクトリに移動してください。
bash
$ mkdir certs
$ cd certsでルート証明書を作成します。
bash
$ make -f ../istio/tools/certs/Makefile.selfsigned.mk root-caこのコマンドにより、以下のファイルが生成されました。
root-cert.pem: 生成されたルート証明書root-key.pem: 生成されたルートキーroot-ca.conf: OpenSSL がルート証明書を生成するための設定root-cert.csr: ルート証明書の CSR を生成します。
各クラスターについて、Istio認証局用の中間証明書と鍵を生成します。
bash
$ make -f ../istio/tools/certs/Makefile.selfsigned.mk cluster1-cacerts
$ make -f ../istio/tools/certs/Makefile.selfsigned.mk cluster2-cacerts
$ make -f ../istio/tools/certs/Makefile.selfsigned.mk cluster3-cacertsコマンドを実行すると、以下のファイルが cluster1, cluster2と cluster3:
bash
$ kubectl create secret generic cacerts -n istio-system \
--kubeconfig=kubeconfig-<cluster-name>
--from-file=<cluster-folder>/ca-cert.pem \
--from-file=<cluster-folder>/ca-key.pem \
--from-file=<cluster-folder>/root-cert.pem \
--from-file=<cluster-folder>/cert-chain.pem以下の変数でコマンドを実行する必要があります。
| cluster name | folder name |
| :----------: | :---------: |
| ap | cluster1 |
| us | cluster2 |
| eu | cluster3 |これらが終わって、ようやくistiodをインストールする準備が整いました。
bash
$ helm install istiod istio/istiod \
--kubeconfig=kubeconfig-<insert-cluster-name> \
--namespace istio-system \
--version=1.14.1 \
--set global.meshID=mesh1 \
--set global.multiCluster.clusterName=<insert-cluster-name> \
--set global.network=<insert-network-name>以下の変数でコマンドを3回繰り返す必要があります。
| cluster name | network name |
| :----------: | :----------: |
| ap | network1 |
| us | network2 |
| eu | network3 |また、Istioの名前空間にはトポロジーアノテーションのタグを付ける必要があります。
bash
$ kubectl label namespace istio-system topology.istio.io/network=network1 --kubeconfig=kubeconfig-ap
$ kubectl label namespace istio-system topology.istio.io/network=network2 --kubeconfig=kubeconfig-us
$ kubectl label namespace istio-system topology.istio.io/network=network3 --kubeconfig=kubeconfig-euそれだけですか?
ほとんど。
東西ゲートウェイによるトラフィックのトンネリング
まだ必要なんですね。
- 1つのクラスタから他のクラスタにトラフィックを流すゲートウェイと
- 他のクラスタにあるIPアドレスを発見するメカニズム。
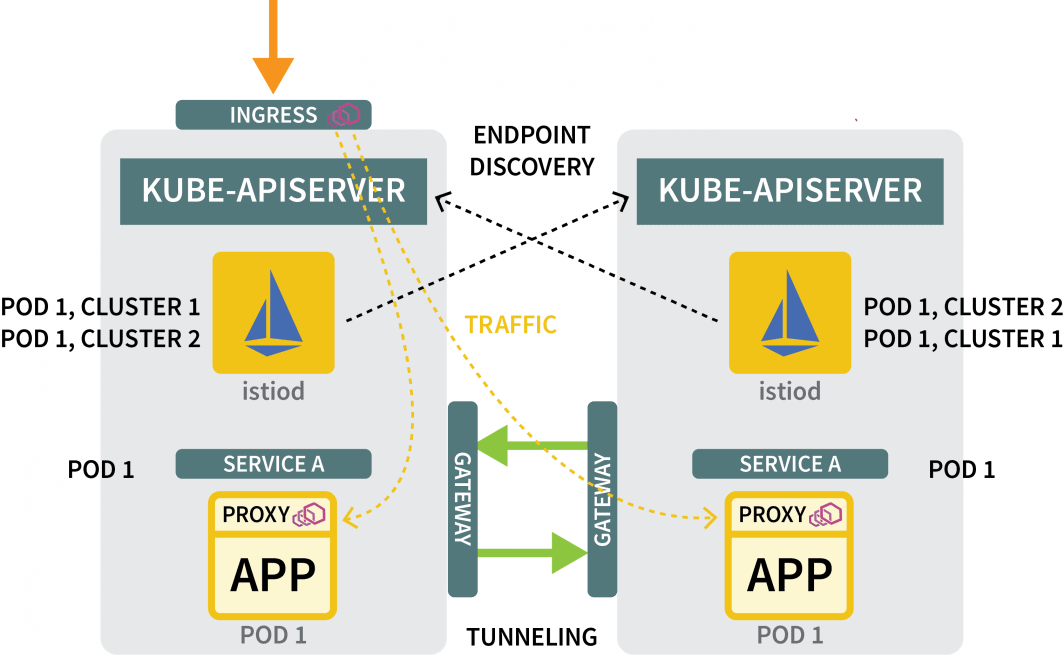
ゲートウェイについては、Helmを使用してインストールすることができます。
bash
$ helm install eastwest-gateway istio/gateway \
--kubeconfig=kubeconfig-<insert-cluster-name> \
--namespace istio-system \
--version=1.14.1 \
--set labels.istio=eastwestgateway \
--set labels.app=istio-eastwestgateway \
--set labels.topology.istio.io/network=istio-eastwestgateway \
--set labels.topology.istio.io/network=istio-eastwestgateway \
--set networkGateway=<insert-network-name> \
--set service.ports[0].name=status-port \
--set service.ports[0].port=15021 \
--set service.ports[0].targetPort=15021 \
--set service.ports[1].name=tls \
--set service.ports[1].port=15443 \
--set service.ports[1].targetPort=15443 \
--set service.ports[2].name=tls-istiod \
--set service.ports[2].port=15012 \
--set service.ports[2].targetPort=15012 \
--set service.ports[3].name=tls-webhook \
--set service.ports[3].port=15017 \
--set service.ports[3].targetPort=15017 \以下の変数でコマンドを3回繰り返す必要があります。
| cluster name | network name |
| :----------: | :----------: |
| ap | network1 |
| us | network2 |
| eu | network3 |そして、各クラスタに対して、以下のリソースを持つGatewayを公開します。
yaml
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: cross-network-gateway
spec:
selector:
istio: eastwestgateway
servers:
- port:
number: 15443
name: tls
protocol: TLS
tls:
mode: AUTO_PASSTHROUGH
hosts:
- "*.local"でクラスタに提出することができます。
bash
$ kubectl apply -f expose.yaml --kubeconfig=kubeconfig-eu
$ kubectl apply -f expose.yaml --kubeconfig=kubeconfig-ap
$ kubectl apply -f expose.yaml --kubeconfig=kubeconfig-us発見メカニズムについては、各クラスタのクレデンシャルを共有する必要があります。これは、クラスタが互いを認識していないために必要です。
他のIPアドレスを発見するためには、他のクラスタにアクセスし、それらをトラフィックの可能な宛先として登録する必要があります。これを行うには、他のクラスタ用のkubeconfigファイルでKubernetesシークレットを作成する必要があります。
Istioはそれらを使って他のクラスタに接続し、エンドポイントを発見し、Envoyプロキシにトラフィックを転送するように指示します。
3つの秘密が必要です。
yaml
apiVersion: v1
kind: Secret
metadata:
labels:
istio/multiCluster: true
annotations:
networking.istio.io/cluster: <insert cluster name>
name: "istio-remote-secret-<insert cluster name>"
type: Opaque
data:
<insert cluster name>: <insert cluster kubeconfig as base64>以下の変数で3つのsecretを作成する必要があります。
| cluster name | secret filename | kubeconfig |
| :----------: | :-------------: | :-----------: |
| ap | secret1.yaml | kubeconfig-ap |
| us | secret2.yaml | kubeconfig-us |
| eu | secret3.yaml | kubeconfig-eu |ここで、APクラスタにAPの秘密を提出しないように注意しながら、クラスタに秘密を提出する必要があります。
コマンドは以下のようにします。
bash
$ kubectl apply -f secret2.yaml -n istio-system --kubeconfig=kubeconfig-ap
$ kubectl apply -f secret3.yaml -n istio-system --kubeconfig=kubeconfig-ap
$ kubectl apply -f secret1.yaml -n istio-system --kubeconfig=kubeconfig-us
$ kubectl apply -f secret3.yaml -n istio-system --kubeconfig=kubeconfig-us
$ kubectl apply -f secret1.yaml -n istio-system --kubeconfig=kubeconfig-eu
$ kubectl apply -f secret2.yaml -n istio-system --kubeconfig=kubeconfig-euそして、それだけです!
セットアップをテストする準備ができました。
マルチクラスターネットワークのテスト
スリープポッド用のデプロイメントを作成してみましょう。
このポッドを使用して、先ほど作成したHelloデプロイメントにリクエストを行います。
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: sleep
spec:
selector:
matchLabels:
app: sleep
template:
metadata:
labels:
app: sleep
spec:
terminationGracePeriodSeconds: 0
containers:
- name: sleep
image: curlimages/curl
command: ["/bin/sleep", "3650d"]
imagePullPolicy: IfNotPresent
volumeMounts:
- mountPath: /etc/sleep/tls
name: secret-volume
volumes:
- name: secret-volume
secret:
secretName: sleep-secret
optional: trueでデプロイメントを作成することができます。
bash
$ kubectl apply -f sleep.yaml --kubeconfig=karmada-configこの配置に対応するポリシーがないため、Karmada はこの配置を処理せず、保留のままにします。この配置を含めるようにポリシーを修正することができます。
yaml
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: hello-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: hello
- apiVersion: v1
kind: Service
name: hello
- apiVersion: apps/v1
kind: Deployment
name: sleep
placement:
clusterAffinity:
clusterNames:
- eu
- ap
- us
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- us
weight: 2
- targetCluster:
clusterNames:
- ap
weight: 2
- targetCluster:
clusterNames:
- eu
weight: 1でポリシーを適用することができます。
bash
$ kubectl apply -f policy.yaml --kubeconfig=karmada-configでポッドがデプロイされた場所を把握することができます。
bash
$ kubectl get pods --kubeconfig=kubeconfig-eu
$ kubectl get pods --kubeconfig=kubeconfig-ap
$ kubectl get pods --kubeconfig=kubeconfig-usここで、PodがUSクラスタに着地したと仮定して、以下のコマンドを実行します。
Now, assuming the pod landed on the US cluster, execute the following command:
bash
for i in {1..10}
do
kubectl exec --kubeconfig=kubeconfig-us -c sleep \
"$(kubectl get pod --kubeconfig=kubeconfig-us -l \
app=sleep -o jsonpath='{.items[0].metadata.name}')" \
-- curl -sS hello:5000 | grep REGION
done産地によって異なるポッドから反応があることに気づくかもしれませんね
仕事完了
これからどうすればいいのか?
この設定はかなり基本的なもので、おそらく取り入れたいと思ういくつかの機能が欠けています。
- 各クラスタからIstioのイングレスを公開し、トラフィックを取り込むことができます。
- Istioを使用して、ローカルトラフィックを優先するようにトラフィックを形成することができます。
- は、クラスタ間のトラフィックの流れを定義するために、Istioのポリシー強制ルールを使用したいと思うかもしれません。
この記事で取り上げた内容をおさらいします。
- Karmadaを使って複数のクラスターを制御しています。
- 複数のクラスタにワークロードをスケジューリングするためのポリシーを定義します。
- Istioを使用して、複数のクラスタのネットワークの橋渡しをすること、および
- Istioがどのようにトラフィックをインターセプトし、他のクラスタに転送しているか。
他のスケーリング手法に加え、Kubernetesを地域間でスケーリングするための完全なウォークスルーは、当社のウェビナーシリーズに登録してオンデマンドで視聴できます。



コメント