

En 2019, trois départements différents se sont fixé pour objectif de lancer de nouvelles instances Linode GPU pour les clients avant l'anniversaire de Linode. Entre les équipes de matériel, de marketing et de gestion, nous n'étions pas sûrs que cela soit possible, en particulier avec les autres produits sur lesquels nous travaillions pendant cette période.
Nous avons donc choisi la seule équipe qui avait une chance d'y parvenir : une équipe triée sur le volet, composée d'employés enthousiastes issus de plusieurs départements, pour former l'équipe Mission GPU. Aujourd'hui, près de deux ans et de nombreux déploiements d'instances GPU plus tard, nous faisons un voyage dans le passé pour expliquer en détail comment nous avons réussi à transformer une idée en un produit à succès que nous développons activement.
Un bref rappel de l'histoire de la virtualisation chez Linode
Avant de commencer à expliquer comment nous avons lancé les instances GPU , voici quelques détails techniques légers et l'historique des débuts de la virtualisation chez Linode avant que nous ne devenions le fournisseur de cloud que vous connaissez aujourd'hui.
Linode a démarré en 2003 en tant que petite entreprise proposant des machines virtuelles fonctionnant sous UML (User Mode Linux), un paradigme de virtualisation précoce similaire à Qemu (Quick EMUlator). UML fournissait du matériel entièrement virtualisé. Lorsqu'un client se connectait à son Linode, les périphériques qu'il voyait, tels que les disques, le réseau, la carte mère, la mémoire vive, etc., avaient tous l'apparence et le comportement de périphériques matériels réels, mais ces périphériques étaient en fait soutenus par un logiciel au lieu du matériel réel.
Plusieurs années plus tard, Linode est passé à Xen La couche de virtualisation Xen est un hyperviseur de type 1, ce qui signifie que l'hyperviseur s'exécute directement sur le matériel et que les invités s'exécutent au-dessus du noyau Xen . Le noyau Xen fournit une paravirtualisation à ses invités, ou les interfaces matérielles que la Linode voit sont traduites en appels machine réels par le noyau Xen et renvoyées à l'utilisateur. La raison d'être de cette couche de traduction est d'assurer la sécurité et d'autres fonctions de sécurité afin que la bonne instruction aille au bon Linode.
Quelques années plus tard, une nouvelle technologie a été développée sous le nom de KVM (Kernel Virtual Machine). KVM consiste en des parties du noyau Linux qui fournissent des interfaces paravirtuelles aux instructions de l'unité centrale. Qemu est l'une des technologies de virtualisation qui peut tirer parti de KVM. Linode a décidé de changer à nouveau pour le bénéfice de ses clients. Lorsque les clients ont effectué la mise à niveau gratuite vers KVM , la plupart des charges de travail ont vu leurs performances augmenter instantanément. Ce type de paravirtualisation est différent de Xen: les instructions du CPU passent de l'invité (Qemu) au noyau hôte et directement au CPU en utilisant les instructions au niveau du processeur, ce qui permet des vitesses d'exécution quasi natives. Les résultats de ces instructions sont renvoyés au Linode qui les a émises, sans l'overhead que nécessite Xen .
Qu'est-ce que tout cela a à voir avec les instances Linode GPU ?
Linode a mené une étude de marché et a tenté de déterminer ce qui offrirait la meilleure valeur aux clients intéressés par l'exécution de charges de travail sur GPU . Nous avons décidé de fournir les GPU directement aux clients en utilisant une technologie appelée "host passthrough". Nous indiquons à Qemu le périphérique que nous souhaitons transmettre à l'invité, en l'occurrence la carte GPU , et Qemu travaille en collaboration avec Linux pour isoler la carte GPU afin qu'aucun autre processus du système ne puisse l'utiliser. La machine Linux hôte ne peut pas l'utiliser, les autres Linodes sur la machine ne peuvent pas l'utiliser non plus. Seul le client qui en a fait la demande peut utiliser la carte GPU , et il reçoit la carte complète. Le périphérique matériel réel est transmis, sans modification et sans paravirtualisation, ce qui signifie qu'il n'y a pas de couche de traduction.
Semaine 1 : Le matériel arrive chez Linode
Une fois les recherches terminées, toute l'équipe a décidé d'aller de l'avant avec le projet. Pour que le plan fonctionne, le système a nécessité quelques changements dans l'ensemble de la pile de bas niveau. Le matériel a été mis en ligne le lundi et nous avons eu cinq jours pour décider d'aller de l'avant ou non avec une commande importante pour un centre de données afin de respecter le délai.
Toutes les personnes impliquées étaient d'accord pour dire que si nous n'étions pas en mesure de faire fonctionner le produit dans le cadre d'une semaine de travail de 40 heures, nous n'irions pas de l'avant. Cela signifie qu'il n'y avait pas de pression pour faire des heures supplémentaires, mais nous n'avions que cinq jours pour déterminer l'avenir d'un nouveau produit Linode.
Que s'est-il passé en fin de compte ? Il s'avère que toutes nos recherches ont porté leurs fruits. Nous avons essayé de suivre la documentation existante et cela a fonctionné exactement comme prévu. En quelques jours, nous avons été en mesure d'attacher des GPU à des Linodes dans un environnement de test. Vendredi, nous étions sûrs de pouvoir réussir. Le test a été couronné de succès ! Il était maintenant temps de passer une grosse commande pour les clients et d'aller de l'avant.
Semaine 2 : Faire fonctionner la couche d'interface matérielle avec les GPU
Après un premier test réussi, nous sommes rentrés au bureau lundi, regonflés à bloc et prêts à intégrer le processus d'attachement à GPU à nos flux de création de Linodes existants. Nous essayons de rendre notre interface aussi simple que possible : il suffit de quelques clics pour déployer un Linode, et beaucoup de choses se passent dans ces quelques actions que nous avons dû prendre en compte.
Afin de rendre les GPU possibles, plusieurs parties de bas niveau ont dû être écrites et mises en œuvre, telles que l'isolation de la RAM pour GPU et la Linode, ainsi que l'attribution à la Linode de cœurs de CPU dédiés qui ont été associés à la RAM isolée et à GPU. Nous avons fait des recherches sur l'architecture NUMA (Non Uniform Memory Access) de la carte mère et nous avons pu isoler le groupe NUMA de la RAM au CPU auquel il était le plus étroitement associé, ainsi que le groupe NUMA qui était attaché à la voie PCIe (PCI [Peripheral Computer Interface] express) dans laquelle le site GPU était branché. Cela nous a permis de démarrer un Linode avec 1, 2, 3 ou 4 GPU connectés, et d'utiliser la partie de la RAM et les cœurs du CPU qui étaient étroitement associés à la carte GPU en fonction de la structure de la carte mère.
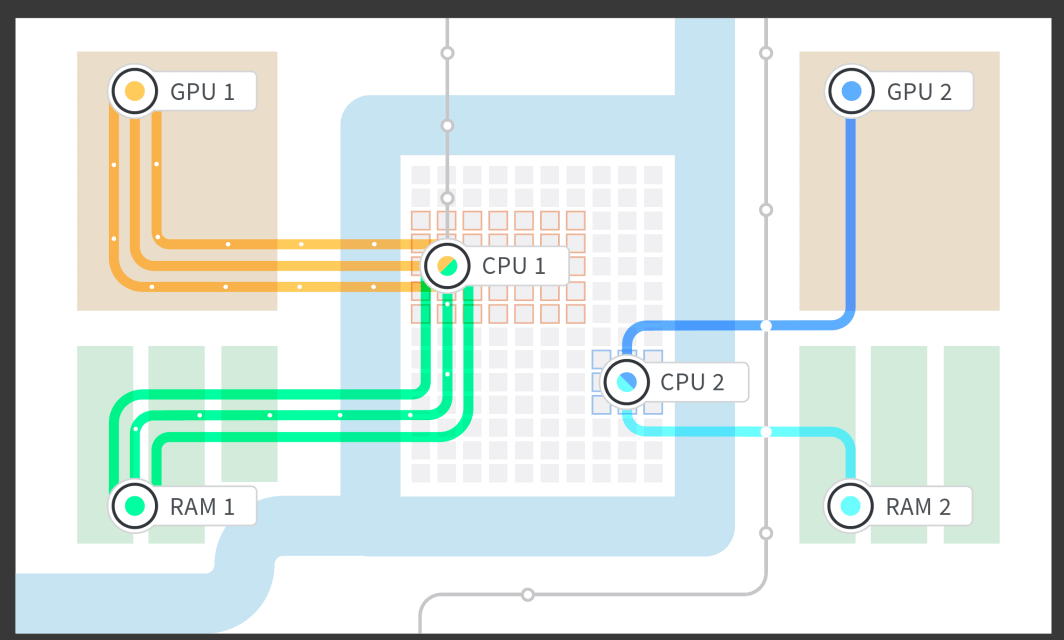
Une fois la couche matérielle terminée, nous avons travaillé sur l'interface avec les mécanismes de mise en file d'attente des Linodes afin de pouvoir démarrer les Linodes par le biais de notre gestionnaire de cloud et de notre API. À ce stade, nous avons pu commencer à tester la fiabilité. La dernière chose que nous voulions, c'était qu'un ingénieur de garde soit appelé au milieu de la nuit à cause d'un système défaillant, ou qu'un système tombe en panne au milieu de la journée de travail pour un client situé dans un autre fuseau horaire. En gardant à l'esprit les horaires de sommeil des clients et des ingénieurs, nous avons commencé les tests très tôt et nous avons continué à nous assurer que les clients disposaient d'un produit solide et fiable.
Semaine 3 : Modifications de l'interface administrateur et de la comptabilité
Au cours de la troisième semaine, nous devions répondre à quelques questions d'ordre administratif : comment savoir quels clients sont assignés à quels Linodes ? Comment envoyer les clients vers une instance de Linode avec un GPU, et non vers une instance de Linode sans GPU?
Tout le suivi et le contrôle ont dû être mis en œuvre. Nous l'avons fait pour pouvoir comptabiliser le nombre de cartes GPU dont nous disposions, le nombre de cartes prises, le nombre de cartes vides et le nombre de cartes que nous pouvions encore vendre à de nouveaux clients. Nous avons également dû intégrer ce suivi GPU dans nos interfaces d'administration internes. Cela peut sembler être un travail comptable ennuyeux, mais il a fallu beaucoup d'ingéniosité de la part de toute l'équipe et des membres de l'équipe externe pour interfacer ce nouveau produit avec tous nos produits existants, sans nécessiter d'étapes manuelles.
Heureusement, nous avons réuni tout le monde et nous avons pu écrire le code et le tester pour nous assurer qu'il fonctionnait bien, qu'il était fiable et qu'il ne nécessitait pas d'intervention manuelle pour mettre en place une instance Linode GPU et la faire fonctionner. Un autre avantage de ce travail à ce stade est que les tests ont été plus faciles. Il nous a suffi de cliquer sur un seul bouton de notre interface d'administrateur pour lancer une instance Linode GPU .
Semaine 4 : Modifications de l'API publique pour que les clients puissent créer des Linodes
Après avoir créé le bouton de l'interface administrateur permettant d'ouvrir une instance Linode GPU , nous nous sentions plutôt bien. Nous devions maintenant travailler sur l'exposition de cette même fonctionnalité aux clients. L'API publique est soutenue par Python, ce qui a rendu le code extrêmement intuitif. Nous avons pu déployer les changements et les tester très rapidement. La partie la plus délicate consistait à rendre cette fonctionnalité disponible au sein de l'entreprise à des fins de test, mais pas à l'extérieur de l'entreprise tant que nous n'avions pas effectué les tests nécessaires à des fins de fiabilité.
Semaine 5 : Déployer ! Ou comment déployer une fonctionnalité publique derrière un drapeau de fonctionnalité (Feature Flag)
Nous avons donc posé la question suivante : comment nous sentons-nous à l'idée de lancer ce service auprès du public et de le faire utiliser par les clients ?
La réponse a été de gérer toutes les inconnues dès le début et d'en tenir compte en déployant tôt et souvent. Alors que nous étions encore en train de tester certains cas d'utilisation au sein de l'équipe, nous avons déployé des instances Linode GPU pour le public, mais cachées derrière un drapeau de fonctionnalité. Nous avons pu tester les GPU sur les comptes de nos employés, ce qui nous a permis de nous assurer que les choses se comporteraient exactement comme prévu si un client devait les utiliser. Chaque fois que nous avons trouvé quelque chose que nous n'attendions pas, nous avons apporté une correction et effectué un déploiement public.
Lentement mais sûrement, et en déployant du code presque tous les jours, nous avons résolu tous les points de notre liste. Nous n'avions plus de changements à faire et nous nous sommes sentis en confiance pour ouvrir véritablement le projet aux clients.
Semaine 6 : Test ! Ouvrir les GPU aux employés de Linode
L'un des avantages de travailler chez Linode est que nous avons l'occasion de jouer avec des technologies de pointe avant tout le monde (P.S. nous embauchons !). (P.S. nous embauchons !) Chaque employé a la possibilité de tester un nouveau produit, de sorte que chaque élément technologique que nous lançons a fait l'objet d'un test approfondi. Tout employé peut s'inscrire pour tester une instance Linode GPU pendant les heures de travail, et même après le travail s'il le souhaite vraiment, afin d'utiliser l'instance Linode GPU comme le ferait un client. Tout ce qu'ils avaient à faire était de marquer leur compte d'employé et de démarrer une instance GPU.
Voici quelques-unes des façons dont les Linodiens ont essayé nos nouveaux GPU :
- Cloud gaming - où le jeu tourne sur l'instance Linode GPU et où la vidéo et les commandes sont envoyées via Steam Link™.
- Rendu 3D
- Transcodage vidéo
- Test de force des mots de passe
- Exécution de TensorFlow
À l'issue de cette étape, nous avons recueilli des données sur les performances et décidé que nous étions prêts à passer à la production et à lancer le produit auprès des clients.
Lancement !
Nous avons lancé ! Nous avons fait la fête ! Il y avait de la glace et des cadeaux! Les clients ont commencé à essayer le produit qui était en cours de développement il y a seulement quelques semaines. Le plus beau, c'est que tout a fonctionné le jour du lancement. Nous n'avons pas eu à faire de changements de dernière minute, il n'y a pas eu d'incendie à éteindre, les clients étaient contents et tout a fonctionné de manière fiable.
Le lancement du code n'a pas été difficile. Du point de vue du code et de la configuration du système, tout ce qu'il fallait pour lancer les GPU en production était la suppression d'un drapeau de fonctionnalité. Mais il y a aussi des tonnes d'autres choses qui entrent dans le lancement d'un produit chez Linode : la documentation technique, les changements d'interface utilisateur dans le Linode Cloud Manager, et tout le matériel marketing amusant pour aider à célébrer notre nouveau produit.
Lancement de poste : Pas de changement de code pendant six mois
Certaines questions nous viennent toujours à l'esprit : avons-nous effectué suffisamment de tests ? Six semaines, c'est trop rapide ?
Dans notre cas, c'était juste la bonne vitesse : je n'ai pas eu à toucher au code depuis le lancement. De plus, les GPU Linode ont été utilisés par les clients tous les jours. C'est formidable de pouvoir créer un produit et de le faire fonctionner, puis de continuer à créer d'autres produits géniaux, et que cette chose que vous avez créée il y a deux ans fonctionne toujours, toute seule, avec un minimum d'interaction nécessaire
Rétrospectivement, voici quelques éléments qui nous ont permis de réussir :
- Faire des recherches à l'avance - Cela nous a beaucoup aidés à faire face à toutes les inconnues que nous pouvions avoir sans avoir le matériel en main.
- Établir un plan - Nous avions un plan très détaillé et chaque étape devait être exécutée dans les délais, faute de quoi nous n'aurions pas pu lancer le projet.
- S'en tenir au plan - Se concentrer sur la tâche à accomplir et garder à l'esprit les tâches restantes.
- Avoir une bonne équipe de gestion - S'assurer que tous les niveaux de gestion comprennent que si un projet avec un délai serré manque une étape, le délai de lancement ne sera pas respecté. C'est peut-être l'élément le plus important qui nous a permis de réussir. Une certaine pression est une bonne chose, comme ce fut le cas pour nous, mais trop de pression mène à l'épuisement et à l'échec. Après avoir discuté du calendrier avec la direction, celle-ci était tout à fait d'accord.
- Se soutenir mutuellement - L'équipe qui a eu une chance n'en aurait pas eu sans la structure de soutien du reste de l'organisation. Lorsque tous vos collègues veulent que vous réussissiez, ils se joignent à vous et vous aident si vous en avez besoin.
- Test - Test test test test test, si je pouvais l'écrire une fois de plus, je dirais encore test. Les tests automatisés et manuels. C'est, de loin, la principale raison pour laquelle personne dans mon équipe n'a eu à toucher au code pendant plus de 6 mois.
Pour en savoir plus sur les instances Linode GPU , consultez notre documentationGPU . Nous venons d'étendre la disponibilité de GPU dans nos centres de données de Newark, Mumbai et Singapour.
Vous souhaitez essayer les GPU Linode pour vos charges de travail actuelles ? Vous pouvez obtenir un essai gratuit d'une semaine pour voir comment nos GPU fonctionnent pour vous. Pour en savoir plus, cliquez ici.
(Et encore une fois, si vous voulez nous aider à construire et à tester des produits tels que les GPU Linode, nous recrutons !)


Commentaires (1)
how to make windows os in linode