

AI 학습은 리소스 집약적입니다. 모델에 언어, 이미지 또는 오디오를 이해하는 방법을 가르치려면 방대한 데이터 세트, 고급 알고리즘, 특수 하드웨어(예: 고가의 GPU)가 필요합니다. 그러나 학습이 완료된 후에도 추론(결과물을 생성하는 과정)을 실행하는 것도 마찬가지로 부담이 될 수 있습니다.
모든 사용자 요청에 대해 실시간으로 LLM을 쿼리하는 것은 비용도 많이 들 뿐 아니라 비효율적입니다. 특히 답이 이미 존재할 수 있는 경우에는 더욱 그렇습니다. 이 문제를 해결하기 위해 개발팀은 벡터 데이터베이스로 눈을 돌렸습니다.
정확한 키워드 일치에 의존하는 기존 데이터베이스와 달리 벡터 데이터베이스는 텍스트, 이미지 또는 사운드와 같은 데이터의 숫자 표현과 같은 고차원 임베딩으로 정보를 저장합니다. 이를 통해 시맨틱 검색을 수행할 수 있습니다. 따라서 정확한 단어를 찾는 대신 의미를 찾는 것입니다.
이러한 구분은 다음과 같은 사용 사례에서 필수적입니다:
- 검색 증강 생성(RAG)
- 추천 엔진
- 질문 답변 시스템
- 시맨틱 검색
벡터 데이터베이스를 사용하면 인공지능 시스템은 벡터 인덱스에 이미 답이 있을 때 불필요한 추론 호출을 건너뛰고 관련 정보를 더 빠르고 효율적으로 검색할 수 있습니다. 다양한 벡터 데이터베이스 솔루션이 있지만, 오늘은 제가 개인적으로 사용하고 추천하는 오픈 소스 PostgreSQL 확장 프로그램인 pgvector에 대해 이야기해 보겠습니다. 이 도구가 왜 그렇게 훌륭한 도구라고 생각하는지, 그리고 어떻게 시작할 수 있는지 살펴보겠습니다.
pgvector가 개발자를 위한 훌륭한 도구인 이유
우선, pgvector는 벡터 검색 기능을 전 세계에서 가장 널리 채택된 관계형 데이터베이스 중 하나인 PostgreSQL에 직접 통합합니다. 이미 PostgreSQL 기반 환경에서 작업 중인 개발자와 팀에게는 지능형 애플리케이션을 구축하기 위한 원활하고 마찰이 적은 옵션이 제공됩니다.
관리할 별도의 스택을 새로 도입하는 대신 pgvector를 사용하면 팀이 관계형 데이터와 벡터 데이터를 모두 한곳에 저장하고 쿼리할 수 있습니다. 이러한 통합은 서로 다른 데이터베이스를 동기화하는 복잡성을 없애고 개발 수명 주기를 간소화합니다. AI 애플리케이션은 구조화된 필터, 전체 텍스트 검색, 의미론적 유사성 등 다양한 유형의 쿼리를 한 번의 작업으로 결합해야 하는 경우가 많습니다. pgvector는 개발자가 벡터 유사성 점수를 SQL 기반 필터 및 조인과 혼합할 수 있도록 함으로써 이러한 하이브리드 검색 패턴을 기본적으로 지원합니다. 이를 통해 단일 SQL 쿼리 내에서 문서 카테고리 또는 사용자 권한과 같은 필터를 적용하면서 키워드뿐만 아니라 의미론적 의미로도 문서 코퍼스를 검색할 수 있습니다.
pgvector는 실제 확장성과 성능을 위해 구축되었습니다. 수백만 개의 임베딩에 걸쳐 빠른 결과를 제공해야 하는 애플리케이션의 경우, pgvector는 IVFFlat 인덱싱 방법을 통해 근사 근접 이웃(ANN) 검색을 지원합니다. 이를 통해 정확도와 속도 간의 균형을 유지하면서 AI 기반 검색창이나 추천 시스템과 같이 지연 시간에 민감한 애플리케이션에 신속하게 응답할 수 있습니다. Python 개발하는 팀의 경우, pgvector는 psycopg2, asyncpg, SQLAlchemy와 같은 널리 사용되는 PostgreSQL 클라이언트 라이브러리에 원활하게 통합되므로 기존 데이터 파이프라인과 ML 워크플로우에 쉽게 통합할 수 있습니다.
pgvector의 다재다능함은 산업 전반에 걸쳐 그 가치가 입증되고 있습니다. 이커머스 기업들은 전환율을 높이기 위해 개인화된 추천을 제공하는 데 이를 활용하고 있습니다. 대형 미디어 플랫폼에서는 관련성 높은 콘텐츠를 노출하여 사용자의 참여를 유도하는 데 사용합니다. 의료 및 생명 과학 팀은 더 빠른 연구, 화합물 발견, 진단 인사이트를 위해 이를 활용하고 있습니다. 많은 기술 기업에서 LLM을 통해 고객 지원과 더 스마트한 내부 도구를 구현하고 있습니다.
pgvector를 더욱 강력하게 만드는 것은 Akamai Cloud와 같은 플랫폼에 배포하는 것입니다. Akamai의 클라우드 솔루션은 프로덕션급 워크로드에 필요한 관리형 인프라, 확장성, 글로벌 성능 우위를 제공합니다. 개발자는 관리형 PostgreSQL을 통해 운영 오버헤드에 대한 걱정 없이 pg벡터 기반 애플리케이션을 배포할 수 있습니다. 자동화된 백업, 기본 제공 보안, 자동 확장 옵션을 통해 스택의 복원력을 유지하면서 팀은 구축에 집중할 수 있습니다. 또한 Akamai의 컴퓨팅 및 네트워크 인프라는 글로벌 전송에 최적화되어 있으므로 빠른 추론 또는 실시간 추천 엔진에 의존하는 애플리케이션은 지연 시간을 단축하고 규모에 맞게 안정성을 높일 수 있습니다.
이미 PostgreSQL을 사용하고 있거나 완전한 스택 개편이 필요 없는 AI 지원 벡터 검색 엔진을 찾고 계신다면, 다음 섹션에서 pgvector를 시작하는 방법을 안내해드리겠습니다.
Akamai에서 pgvector 시작하기
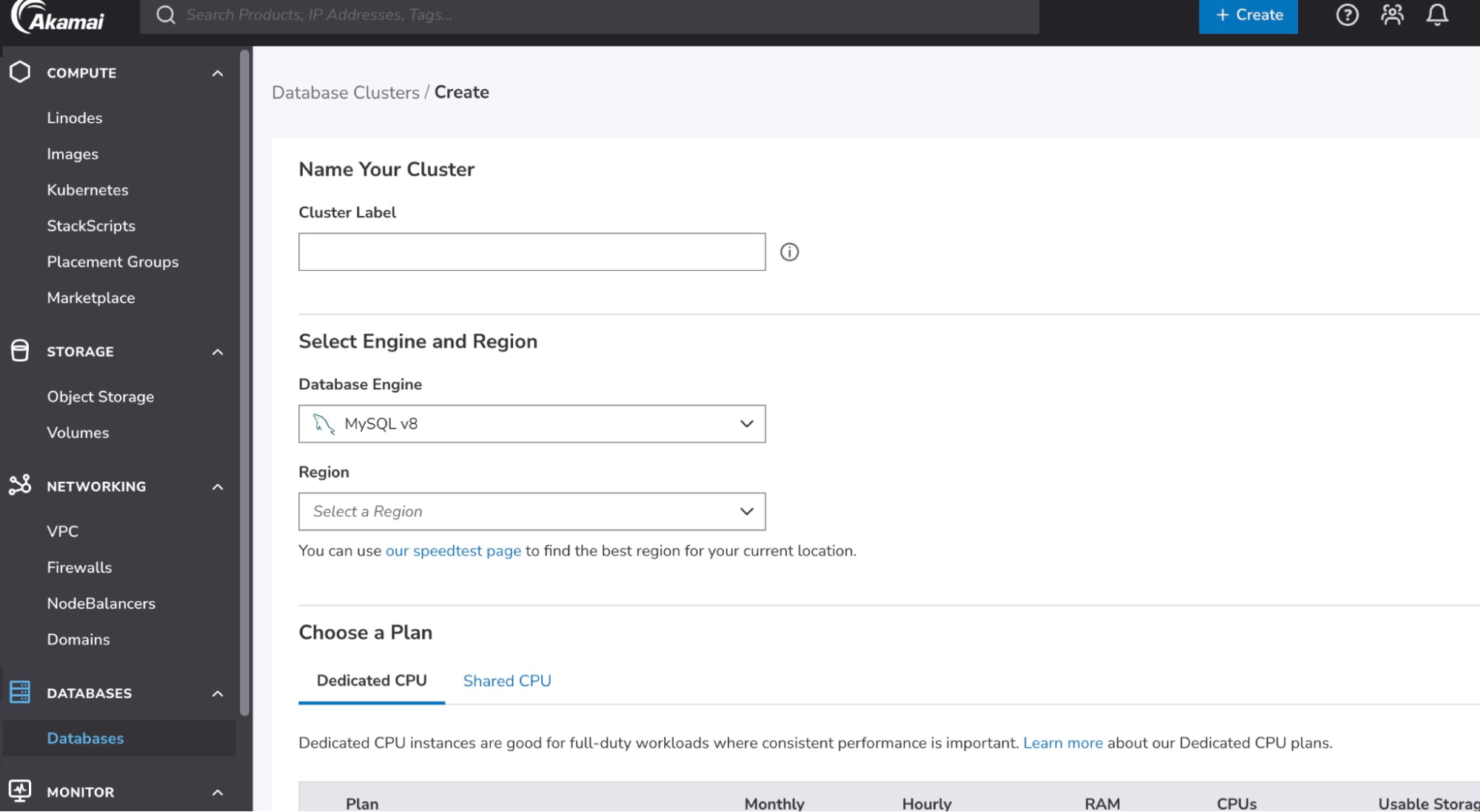
- Akamai의 매니지드 데이터베이스 대시보드를 사용하여 PostgreSQL 클러스터를 프로비저닝합니다.
- 클라우드 관리자에 로그인합니다.
- 주 메뉴에서 데이터베이스를 선택합니다.
- 데이터베이스 클러스터 생성을 클릭합니다.
- 클러스터 레이블 필드에 계정의 클러스터를 쉽게 식별할 수 있도록 레이블을 입력합니다. 레이블은 영숫자로 3~32자 사이여야 합니다.
- 새 데이터베이스에 사용할 데이터베이스 엔진을 선택합니다.
- 데이터베이스 클러스터가 상주할 지역을 선택합니다.
- 데이터베이스 클러스터의 모든 노드는 자체 리노드에 구축됩니다. 요금제 선택 섹션에서 노드에서 사용할 리노드 유형과 요금제를 선택합니다.
- 클릭 데이터베이스 클러스터 생성. 클러스터를 완전히 프로비저닝하는 데는 약 10~15분이 소요됩니다. 상태를 추적하려면 상태 열에 있는 데이터베이스 클러스터 목록입니다.
참고: API를 사용하여 프로비저닝할 수도 있습니다.
- 클러스터에 로그인
명령줄에서 데이터베이스에 직접 연결하려면 psql 도구를 사용하면 됩니다. 이 도구는 대부분의 운영 체제에서 별도로 설치할 수도 있지만 대부분의 PostgreSQL 서버 설치의 일부로 포함되어 있습니다.
아래 psql 명령을 사용하여 데이터베이스에 연결하려면 다음을 대체합니다.[host]그리고[username]를 연결 세부 정보 섹션의 해당 값으로 대체합니다.psql --host=[host] --username=[username] --password --dbname=postgres - 확장 프로그램 설치
데이터베이스에 사용 가능한 확장 기능 중 하나를 설치하려면 [extension_name]을 설치하려는 확장 기능의 이름으로 바꾸어 CREATE EXTENSION 명령을 사용합니다. 이 경우 확장자는 다음과 같습니다.vector.CREATE EXTENSION vector; - 벡터 열 정의
벡터 확장 프로그램을 설치하면 벡터라는 새로운 데이터 유형에 액세스할 수 있습니다. 벡터의 크기(괄호 안에 표시됨)는 해당 벡터에 저장된 차원 수를 나타냅니다. 이 예에서는 13을 사용하지만 실제 사용 사례에서는 수천 개가 될 수 있습니다.CREATE TABLE items ( id serial PRIMARY KEY, description text, embedding vector(13) ); - ML 모델에서 임베딩을 삽입합니다(예 OpenAI의 또는 포옹하는 얼굴). 샘플 임베딩을 수집하기 위해 아래 Python 스크립트를 사용할 수 있으며, 이는 Hugging Face 데모에서 변형된 것입니다. 이 예제를 사용하려면 허깅 페이스 토큰을 가져와야 합니다.
import requests
import psycopg2
import os
# Hugging Face Configuration
model_id = "sentence-transformers/all-MiniLM-L6-v2"
hf_token = os.environ.get("HF_TOKEN") # Set an environmental variable called HF_TOKEN with your Hugging Face token
api_url = f"https://router.huggingface.co/hf-inference/models/{model_id}"
headers = {"Authorization": f"Bearer {hf_token}"}
# Database Configuration
db_conn_string = os.environ.get("DB_CONN_STRING") # Replace with your connection string or set an env var
# Source for Embeddings
source_sentence = "How do I get Medicare?"
sentences = [
"How do I get a replacement Medicare card?",
"What is the monthly premium for Medicare Part B?",
"How do I terminate my Medicare Part B (medical insurance)?",
"How do I sign up for Medicare?",
"Can I sign up for Medicare Part B if I am working and have health insurance through an employer?",
"How do I sign up for Medicare Part B if I already have Part A?",
"What are Medicare late enrollment penalties?",
"What is Medicare and who can get it?",
"How can I get help with my Medicare Part A and Part B premiums?",
"What are the different parts of Medicare?",
"Will my Medicare premiums be higher because of my higher income?",
"What is TRICARE ?",
"Should I sign up for Medicare Part B if I have Veterans' Benefits?"
]
# Hugging Face API Query Function
def get_embeddings(source_sentence, sentences):
"""Queries the Hugging Face API to get sentence embeddings."""
try:
response = requests.post(
Api_url,
headers=headers,
json={"inputs": { "source_sentence": source_sentence, "sentences": sentences }, "options": {"wait_for_model": True}}
)
response.raise_for_status() # Raise an exception for bad status codes (4xx or 5xx)
return response.json()
except requests.exceptions.RequestException as e:
print(f"Error querying Hugging Face API: {e}")
return None
# Main Execution
print("Fetching embeddings from Hugging Face...")
embeddings = get_embeddings(source_sentence, sentences)
if embeddings:
print(f"Successfully fetched {len(embeddings)} embeddings.")
conn = None
Try:
# Establish connection to the database
print("Connecting to the PostgreSQL database...")
conn = psycopg2.connect(db_conn_string)
cur = conn.cursor()
print("Connection successful.")
# Insert descriptions and embeddings into the database
print("Inserting data into the 'items' table...")
for description, embedding in zip(sentences, embeddings):
# The pgvector extension expects the vector as a string representation of a list
cur.execute(
"INSERT INTO items (description, embedding) VALUES (%s, %s)",
(description, embeddings)
)
# Commit the transaction to make the changes permanent
conn.commit()
print(f"Successfully inserted {cur.rowcount} records into the database.")
except psycopg2.Error as e:
print(f"Database error: {e}")
if conn:
conn.rollback() # Rollback the transaction on error
Finally:
# Ensure the connection is closed
if conn:
cur.close()
conn.close()
print("Database connection closed.") - pgvector의 인덱싱 및 검색 사용
Create the index after the table has some data
CREATE INDEX ON items USING ivfflat (embedding vector_cosine_ops);
SELECT *, embedding <-> query_embedding AS similarity FROM items ORDER BY similarity LIMIT 5;
벡터 데이터베이스는 팀이 성능을 최적화하고, 추론 비용을 절감하며, 더 스마트하고 빠른 사용자 경험을 제공할 수 있도록 지원하며, pgvector와 같은 확장 기능을 사용하면 아키텍처를 개편하지 않고도 시맨틱 검색 및 하이브리드 쿼리를 PostgreSQL과 같은 익숙한 환경에 쉽게 도입할 수 있습니다.
문서에서 pgVector 및 기타 사용 가능한 확장 기능을 배포하고 사용하는 방법에 대해 자세히 알아보세요.






내용