

Lorsque les développeurs déploient une charge de travail sur une plateforme d'informatique en nuage, ils ne s'arrêtent souvent pas pour réfléchir au matériel sous-jacent sur lequel leurs services s'exécutent. Dans l'image idéalisée du "nuage", la maintenance du matériel et les limites physiques sont invisibles. Malheureusement, le matériel a parfois besoin d'être entretenu, ce qui peut entraîner des temps d'arrêt. Pour éviter de répercuter ces temps d'arrêt sur nos clients et pour tenir la promesse du cloud, Linode met en œuvre un outil appelé Live Migrations.
Live Migrations est une technologie qui permet aux instances Linode de passer d'une machine physique à une autre sans interruption de service. Lorsqu'un Linode est déplacé avec Live Migrations, la transition est invisible pour les processus de ce Linode. Si le matériel d'un hôte a besoin de maintenance, les Live Migrations peuvent être utilisées pour transférer de manière transparente tous les Linodes de cet hôte vers un nouvel hôte. Une fois la migration terminée, le matériel physique peut être réparé et le temps d'arrêt n'aura pas d'impact sur nos clients.
Pour moi, le développement de cette technologie a été un moment décisif et un tournant entre les technologies en nuage et les technologies non en nuage. J'ai un faible pour la technologie Live Migrations, car j'y ai consacré plus d'un an de ma vie. Aujourd'hui, je peux partager cette histoire avec vous tous.
Comment fonctionnent les migrations en direct ?
Les Live Migrations chez Linode ont commencé comme la plupart des nouveaux projets : avec beaucoup de recherches, une série de prototypes et l'aide de nombreux collègues et responsables. Le premier pas en avant a été d'étudier comment QEMU gère les Live Migrations. QEMU est une technologie de virtualisation utilisée par Linode, et Live Migrations est une fonctionnalité de QEMU. Par conséquent, l'objectif de notre équipe était d'apporter cette technologie à Linode, et non de l'inventer.
Comment la technologie Live Migration fonctionne-t-elle de la manière dont QEMU l'a mise en œuvre ? La réponse est un processus en quatre étapes :
- L'instance qemu de destination est lancée avec les mêmes paramètres que ceux de l'instance qemu source.
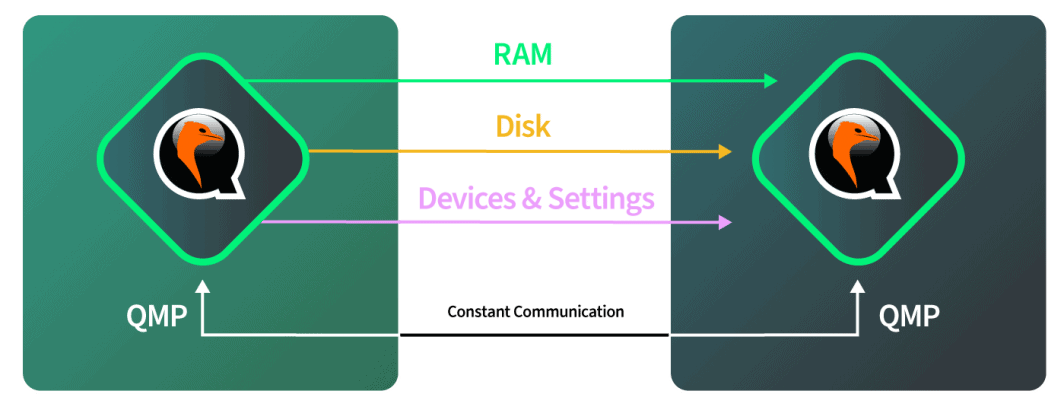
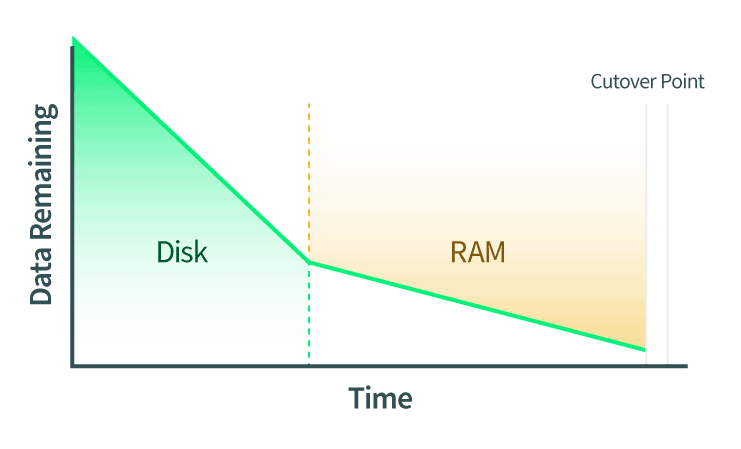
- Les disques sont transférés en direct. Toute modification apportée au disque est également communiquée pendant que ce transfert est en cours.
- La RAM est migrée en direct. Toute modification des pages de la RAM doit également être communiquée. S'il y a des changements de données sur le disque pendant cette phase, ces changements seront également copiés sur le disque de l'instance QEMU de destination.
- Le point de basculement est exécuté. Lorsque QEMU détermine qu'il y a suffisamment peu de pages de RAM pour qu'il puisse effectuer le basculement en toute confiance, les instances QEMU source et de destination sont mises en pause. QEMU copie les dernières pages de RAM et l'état de la machine. L'état de la machine comprend le cache du processeur et la prochaine instruction du processeur. Ensuite, QEMU demande à l'instance de destination de démarrer et cette dernière reprend là où la source s'est arrêtée.
Ces étapes expliquent comment effectuer une migration en direct avec QEMU à un niveau élevé. Cependant, spécifier exactement comment vous voulez que l'instance QEMU de destination soit démarrée est un processus très manuel. De plus, chaque action du processus doit être lancée au bon moment.
Comment les migrations en direct sont mises en œuvre chez Linode
Après avoir regardé ce que les développeurs de QEMU ont déjà créé, comment pouvons-nous l'utiliser chez Linode ? La réponse à cette question est celle qui a donné le plus de travail à notre équipe.
Conformément à l'étape 1 du flux de travail de la migration en direct, l'instance QEMU de destination est démarrée pour accepter la migration en direct entrante. Lors de la mise en œuvre de cette étape, la première idée a été de prendre le profil de configuration du Linode actuel et de le démarrer sur une machine de destination. C'est simple en théorie, mais en y réfléchissant un peu plus, on découvre des scénarios plus compliqués. En particulier, le profil de configuration vous indique comment le Linode a démarré, mais il ne décrit pas nécessairement l'état complet du Linode après le démarrage. Par exemple, un utilisateur aurait pu attacher un périphérique Block Storage en le branchant à chaud sur le Linode après le démarrage, ce qui ne serait pas documenté dans le profil de configuration.
Afin de créer l'instance QEMU sur l'hôte de destination, un profil de l'instance QEMU en cours d'exécution a dû être établi. Nous avons établi le profil de cette instance QEMU en cours d'exécution en inspectant l'interface QMP. Cette interface nous donne des informations sur la façon dont l'instance QEMU est organisée. Elle ne fournit pas d'informations sur ce qui se passe à l'intérieur de l'instance du point de vue de l'invité. Elle nous indique où les disques sont branchés et dans quel slot PCI virtualisé les disques virtuels sont branchés, à la fois pour le SSD local et le stockage en bloc. Après avoir interrogé QMP et inspecté et introspecté l'instance QEMU, un profil est construit qui décrit exactement comment reproduire cette machine sur la destination.
Sur la machine de destination, nous recevons la description complète de ce à quoi ressemble l'instance source. Nous pouvons alors recréer fidèlement l'instance ici, à une différence près. La différence est que l'instance QEMU de destination est démarrée avec une option qui indique à QEMU d'accepter une migration entrante.
À ce stade, nous devrions faire une pause dans la documentation sur les migrations en direct et passer à l'explication de la manière dont QEMU réalise ces exploits. L'arborescence du processus QEMU se compose d'un processus de contrôle et de plusieurs processus de travail. L'un de ces processus est chargé de renvoyer les appels QMP ou de gérer une migration en direct. Les autres processus correspondent un à un aux processeurs de l'invité. L'environnement de l'invité est isolé de ce côté de QEMU et se comporte comme son propre système indépendant.
En ce sens, nous travaillons avec trois couches :
- La couche 1 est notre couche de gestion ;
- La couche 2 est la partie du processus QEMU qui gère toutes ces actions pour nous; et
- La couche 3 est la couche hôte avec laquelle les utilisateurs du Linode interagissent.
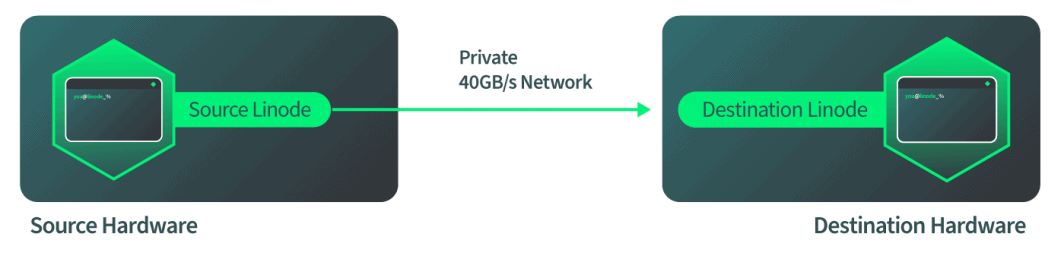
Une fois que la destination est démarrée et prête à accepter la migration entrante, le matériel de destination fait savoir au matériel source que la source doit commencer à envoyer des données. La source démarre dès qu'elle reçoit ce signal et nous demandons à QEMU, dans le logiciel, de commencer la migration du disque. Le logiciel surveille de manière autonome la progression du disque pour vérifier qu'elle est terminée. Le logiciel passe ensuite automatiquement à la migration vers la RAM lorsque le disque est terminé. Le logiciel surveille à nouveau de manière autonome la migration de la RAM et passe automatiquement en mode de basculement lorsque la migration de la RAM est terminée. Tout cela se passe sur le réseau 40Gbps de Linode, donc le côté réseau est assez rapide.
Le passage à l'euro : La section critique
L'étape de basculement est également connue comme la section critique d'une migration en direct, et la compréhension de cette étape est la partie la plus importante de la compréhension des migrations en direct.
Au point de basculement, QEMU a déterminé qu'il était prêt à basculer et à commencer à fonctionner sur la machine de destination. L'instance QEMU source demande aux deux parties de faire une pause. Cela signifie plusieurs choses :
- Le temps s'arrête en fonction de l'invité. Si l'invité utilise un service de synchronisation de l'heure comme le Network Time Protocol(NTP), le NTP resynchronisera automatiquement l'heure une fois la migration en direct terminée. En effet, l'horloge du système aura quelques secondes de retard.
- Les requêtes réseau s'arrêtent. Si ces demandes sont basées sur le protocole TCP, comme SSH ou HTTP, il n'y aura pas de perte de connectivité perçue. Si ces demandes sont basées sur UDP, comme le streaming vidéo en direct, quelques trames peuvent être perdues.
Étant donné que le temps et les requêtes réseau sont arrêtés, nous voulons que le basculement se fasse le plus rapidement possible. Cependant, nous devons d'abord vérifier plusieurs choses pour nous assurer que le transfert se déroule correctement :
- S'assurer que la migration en direct s'est déroulée sans erreur. En cas d'erreur, nous revenons en arrière, nous désactiveons le Linode source et nous n'allons pas plus loin. Ce point spécifique a nécessité beaucoup d'essais et d'erreurs pour être résolu pendant le développement, et il a été la source de beaucoup de douleur, mais notre équipe a finalement réussi à aller au fond des choses.
- Veiller à ce que la mise en réseau s'arrête à la source et redémarre à la destination de manière appropriée.
- Permet au reste de notre infrastructure de savoir exactement sur quelle machine physique cette Linode réside désormais.
Étant donné que le délai imparti pour le passage à l'euro est limité, nous voulons terminer ces étapes rapidement. Une fois ces points réglés, nous terminons le transfert. Le nœud source reçoit automatiquement le signal terminé et indique au nœud de destination de démarrer. Le nœud de destination reprend là où il s'est arrêté. Tous les éléments restants sur la source et la destination sont nettoyés. Si le Linode de destination a besoin d'être migré en direct à nouveau à un moment donné dans le futur, le processus peut être répété.
Vue d'ensemble des cas limites
La majeure partie de ce processus était simple à mettre en œuvre, mais le développement des migrations en direct a été prolongé par des cas particuliers. Le mérite de la réalisation de ce projet revient en grande partie à l'équipe de direction qui a vu la vision de l'outil achevé et a alloué les ressources nécessaires à la réalisation de la tâche, ainsi qu'aux employés qui ont mené le projet à son terme.
Voici quelques-uns des domaines dans lesquels des cas limites ont été rencontrés :
- L'outil interne permettant d'orchestrer les Live Migrations pour les équipes de support client et d'exploitation matérielle de Linode devait être construit. Cet outil était similaire à d'autres outils existants que nous avions et utilisions à l'époque, mais il était suffisamment différent pour nécessiter un effort de développement important :
- Cet outil doit automatiquement examiner l'ensemble du parc matériel d'un centre de données et déterminer quel hôte doit être la destination de chaque Linode migré en direct. Les spécifications pertinentes lors de cette sélection comprennent l'espace de stockage SSD disponible et les allocations de RAM.
- Le processeur physique de la machine de destination doit être compatible avec le Linode entrant. En particulier, un processeur peut avoir des caractéristiques (également appelées drapeaux de processeur) que le logiciel de l'utilisateur peut exploiter. Par exemple, l'une de ces fonctionnalités est aes, qui fournit un cryptage accéléré par le matériel. L'unité centrale de la destination d'une migration en direct doit prendre en charge les options de l'unité centrale de la machine source. Ce cas de figure s'est avéré très complexe et la section suivante décrit une solution à ce problème.
- Gérer avec élégance les cas d'échec, y compris l'intervention de l'utilisateur final ou la perte de réseau pendant la migration en direct. Ces cas d'échec sont énumérés plus en détail dans une section ultérieure de ce billet.
- Suivre les changements apportés à la plateforme Linode, qui est un processus continu. Pour chaque fonctionnalité que nous supportons sur les Linodes aujourd'hui et dans le futur, nous devons nous assurer que la fonctionnalité est compatible avec les Live Migrations. Ce défi est décrit à la fin de ce billet.
Drapeaux de l'unité centrale
QEMU dispose de différentes options pour présenter un processeur au système d'exploitation invité. L'une de ces options consiste à transmettre directement à l'invité le numéro de modèle et les caractéristiques du processeur hôte (également appelés drapeaux du processeur). En choisissant cette option, l'invité peut utiliser toute la puissance du système de virtualisation KVM . Lorsque KVM a été adopté pour la première fois par Linode (ce qui a précédé les Live Migrations), cette option a été choisie pour maximiser les performances. Cependant, cette décision a ensuite présenté de nombreux défis lors du développement de Live Migrations.

Dans l'environnement de test des migrations en direct, les hôtes source et destination étaient deux machines identiques. Dans le monde réel, notre parc matériel n'est pas 100% identique, et il existe des différences entre les machines qui peuvent entraîner la présence de différents drapeaux CPU. Ceci est important car lorsqu'un programme est chargé dans le système d'exploitation du Linode, le Linode présente des drapeaux CPU à ce programme, et le programme chargera des sections spécifiques du logiciel dans la mémoire pour profiter de ces drapeaux. Si un Linode est migré en direct vers une machine de destination qui ne prend pas en charge ces drapeaux de CPU, le programme se bloque. Cela peut entraîner le plantage du système d'exploitation invité et le redémarrage du Linode.
Nous avons trouvé trois facteurs qui influencent la manière dont les drapeaux du processeur d'une machine sont présentés aux invités :
- Il existe des différences mineures entre les unités centrales, en fonction de la date d'achat de l'unité centrale. Une unité centrale achetée à la fin de l'année peut avoir des indicateurs différents de ceux d'une unité centrale achetée au début de l'année, en fonction de la date à laquelle les fabricants d'unités centrales sortent de nouveaux matériels. Linode achète constamment du nouveau matériel pour augmenter la capacité, et même si le modèle de CPU pour deux commandes de matériel différentes est le même, les drapeaux de CPU peuvent être différents.
- Des noyaux Linux différents peuvent transmettre des drapeaux différents à QEMU. En particulier, le noyau Linux de la machine source d'une migration en direct peut transmettre à QEMU des drapeaux différents de ceux du noyau Linux de la machine de destination. La mise à jour du noyau Linux sur la machine source nécessite un redémarrage, et il n'est donc pas possible de résoudre ce problème en mettant à jour le noyau avant de procéder à la migration en direct, car cela entraînerait un temps d'arrêt pour les Linodes sur cette machine.
- De même, les différentes versions de QEMU peuvent affecter les drapeaux CPU présentés. La mise à jour de QEMU nécessite également un redémarrage de la machine.
Les migrations en direct devaient donc être mises en œuvre de manière à éviter les plantages de programme dus à la non-concordance des drapeaux de l'unité centrale. Deux options sont disponibles :
- Nous pourrions demander à QEMU d'émuler les drapeaux du processeur. Cela conduirait à ce que des logiciels qui fonctionnaient rapidement fonctionnent maintenant lentement, sans qu'il soit possible d'en déterminer la raison.
- Nous pouvons rassembler une liste de drapeaux CPU sur la source et nous assurer que la destination dispose de ces mêmes drapeaux avant de poursuivre. C'est plus compliqué, mais cela permet de préserver la vitesse des programmes de nos utilisateurs. C'est l'option que nous avons mise en œuvre pour les migrations en direct.
Après avoir décidé de faire correspondre les drapeaux des unités centrales de source et de destination, nous avons accompli cette tâche avec une approche de type "ceinture et bretelles" qui consistait en deux méthodes différentes :
- La première méthode est la plus simple des deux. Tous les drapeaux CPU sont envoyés de la source au matériel de destination. Lorsque le matériel de destination configure la nouvelle instance qemu, il vérifie qu'elle possède au moins tous les drapeaux présents sur le Linode source. S'ils ne correspondent pas, la migration en direct n'a pas lieu.
- La deuxième méthode est beaucoup plus compliquée, mais elle permet d'éviter les échecs de migration dus à des erreurs de drapeaux de CPU. Avant de lancer une migration en direct, nous créons une liste de matériel dont les drapeaux de CPU sont compatibles. Ensuite, une machine de destination est choisie dans cette liste.
Cette deuxième méthode doit être exécutée rapidement et elle est très complexe. Dans certains cas, nous devons vérifier jusqu'à 226 drapeaux d'unité centrale sur plus de 900 machines. Il serait très difficile d'écrire toutes ces vérifications de 226 drapeaux de CPU, et il faudrait les maintenir. Ce problème a finalement été résolu par une idée étonnante proposée par le fondateur de Linode, Chris Aker.
L'idée principale était de dresser une liste de tous les drapeaux du processeur et de les représenter sous la forme d'une chaîne binaire. Ensuite, l'opération bitwise et peut être utilisée pour comparer les chaînes. Pour démontrer cet algorithme, je commencerai par un exemple simple. Considérons ce code Python qui compare deux nombres en utilisant l'opération bitwise et :
>>> 1 & 1
1
>>> 2 & 3
2
>>> 1 & 3
1Pour comprendre pourquoi l'opération "bitwise" et donne ces résultats, il est utile de représenter les nombres en binaire. Examinons l'opération "bitwise" et pour les nombres 2 et 3, représentés en binaire :
>>> # 2: 00000010
>>> # &
>>> # 3: 00000011
>>> # =
>>> # 2: 00000010L'opération bitwise et compare les chiffres binaires, ou bits, de deux nombres différents. En commençant par le chiffre le plus à droite dans les nombres ci-dessus et en continuant vers la gauche :
- Les bits les plus à droite/premiers bits de 2 et 3 sont respectivement 0 et 1. Le résultat de l'opération bit à bit et le résultat de l'opération bit à bit pour
0 & 1est de 0. - Le deuxième bit le plus à droite de 2 et 3 est 1 pour les deux nombres. Le résultat de l'opération par bit et pour
1 & 1est de 1. - Tous les autres bits de ces nombres sont à 0, et le résultat bit à bit pour 0 & 0 est 0.
La représentation binaire du résultat complet est alors la suivante 00000010qui est égal à 2.
Pour les migrations en direct, la liste complète des indicateurs de l'unité centrale est représentée sous la forme d'une chaîne binaire, où chaque bit représente un seul indicateur. Si le bit est à 0, l'indicateur n'est pas présent, et si le bit est à 1, l'indicateur est présent. Par exemple, un bit peut correspondre à l'indicateur aes et un autre à l'indicateur mmx. Les positions spécifiques de ces drapeaux dans la représentation binaire sont maintenues, documentées et partagées par les machines de nos centres de données.
La gestion de cette représentation sous forme de liste est beaucoup plus simple et plus efficace que la gestion d'un ensemble d'instructions if qui vérifieraient hypothétiquement la présence d'un indicateur d'unité centrale. Par exemple, supposons qu'il y ait 7 drapeaux de l'unité centrale qui doivent être suivis et vérifiés au total. Ces indicateurs pourraient être stockés dans un nombre de 8 bits (avec un bit en réserve pour une expansion future). Un exemple de chaîne pourrait ressembler à 00111011où le bit le plus à droite indique que aes est activé, le deuxième bit le plus à droite indique que mmx est activé, le troisième bit indique qu'un autre drapeau est désactivé, et ainsi de suite.
Comme le montre l'extrait de code suivant, nous pouvons alors voir quel matériel supportera cette combinaison de drapeaux et renverra toutes les correspondances en un seul cycle. Si nous avions utilisé une série d'instructions if pour calculer ces correspondances, il aurait fallu un nombre beaucoup plus élevé de cycles pour obtenir ce résultat. Pour un exemple de Live Migration où 4 drapeaux CPU sont présents sur la machine source, il faudrait 203 400 cycles pour trouver le matériel correspondant.
Le code de migration en direct effectue une opération bit à bit et sur les chaînes de drapeaux de l'unité centrale des machines source et de destination. Si le résultat est égal à la chaîne de drapeaux de l'unité centrale de la machine source, la machine de destination est compatible. Prenons l'exemple de l'extrait de code suivant : Python :
>>> # The b'' syntax below represents a binary string
>>>
>>> # The s variable stores the example CPU flag
>>> # string for the source:
>>> s = b'00111011'
>>> # The source CPU flag string is equivalent to the number 59:
>>> int(s.decode(), 2)
59
>>>
>>> # The d variable stores the example CPU flag
>>> # string for the source:
>>> d = b'00111111'
>>> # The destination CPU flag string is equivalent to the number 63:
>>> int(d.decode(), 2)
63
>>>
>>> # The bitwise and operation compares these two numbers:
>>> int(s.decode(), 2) & int(d.decode(), 2) == int(s.decode(), 2)
True
>>> # The previous statement was equivalent to 59 & 63 == 59.
>>>
>>> # Because source & destination == source,
>>> # the machines are compatibleNotez que dans l'extrait de code ci-dessus, la destination supporte plus de drapeaux que la source. Les machines sont considérées comme compatibles parce que tous les drapeaux CPU de la source sont présents sur la destination, ce que l'opération bitwise et garantit.
Les résultats de cet algorithme sont utilisés par notre outil interne pour établir une liste de matériel compatible. Cette liste est affichée à nos équipes d'assistance à la clientèle et d'exploitation du matériel. Ces équipes peuvent utiliser l'outil pour orchestrer différentes opérations :
- L'outil peut être utilisé pour sélectionner le meilleur matériel compatible pour un Linode donné.
- Nous pouvons lancer une migration en direct pour un Linode sans spécifier de destination. Le meilleur matériel compatible dans le même centre de données sera automatiquement sélectionné et la migration commencera.
- Nous pouvons lancer des Live Migrations pour tous les Linodes d'un hôte en une seule tâche. Cette fonctionnalité est utilisée avant d'effectuer une maintenance sur un hôte. L'outil sélectionnera automatiquement les destinations pour tous les Linodes et orchestrera les Live Migrations pour chaque Linode.
- Nous pouvons spécifier une liste de plusieurs machines qui ont besoin de maintenance, et l'outil orchestrera automatiquement les Live Migrations pour tous les Linodes à travers les hôtes.
Beaucoup de temps de développement est consacré à faire en sorte que le logiciel "fonctionne"...
Cas de défaillance
Une caractéristique dont on ne parle pas souvent dans les logiciels est le traitement gracieux des cas d'échec. Les logiciels sont censés "fonctionner". Beaucoup de temps de développement est consacré à faire en sorte qu'un logiciel "fonctionne", et c'était tout à fait le cas pour Live Migrations. Nous avons passé beaucoup de temps à réfléchir à toutes les façons dont cet outil pourrait ne pas fonctionner et à traiter ces cas de manière élégante. Voici quelques-uns de ces scénarios et la manière dont ils sont traités :
- Que se passe-t-il si un client souhaite accéder à une fonctionnalité de son Linode à partir de la page d'accueil ? Cloud Manager? Par exemple, un utilisateur peut redémarrer le Linode ou y attacher un volume Block Storage .
- Réponse : Le client a le pouvoir de le faire. La migration en direct est interrompue et n'a pas lieu. Cette solution est appropriée car la migration en direct peut être tentée ultérieurement.
- Que se passe-t-il si le Linode de destination ne démarre pas ?
- Réponse : Informez le matériel source et développez l'outil interne pour choisir automatiquement un autre matériel dans le centre de données. Informez également l'équipe d'exploitation afin qu'elle puisse examiner le matériel de la destination d'origine. Cette situation s'est produite en production et a été gérée par notre implémentation de Live Migrations.
- Que se passe-t-il si vous perdez votre réseau au milieu de la migration ?
- Réponse : Surveiller de manière autonome la progression de la migration en direct et, si elle n'a pas progressé au cours de la dernière minute, annuler la migration en direct et en informer l'équipe des opérations. Cela ne s'est pas produit en dehors d'un environnement de test, mais notre mise en œuvre est préparée à ce scénario.
- Que se passe-t-il si le reste de l'internet s'arrête, mais que le matériel de la source et de la destination fonctionne et communique toujours, et que le Linode de la source ou de la destination fonctionne normalement ?
- Réponse : Si la migration en direct n'est pas dans la section critique, arrêtez la migration en direct. Réessayez plus tard.
- Si vous êtes dans la section critique, continuez la migration en direct. Ceci est important car le Linode source est en pause et le Linode de destination doit être démarré pour que l'opération reprenne.
- Ces scénarios ont été modélisés dans l'environnement de test, et le comportement prescrit s'est avéré être la meilleure ligne de conduite.
Suivre les changements
Après des centaines de milliers de migrations en direct réussies, une question est parfois posée : "Quand les migrations en direct sont-elles terminées ?" Les migrations en direct sont une technologie dont l'utilisation s'étend au fil du temps et qui est continuellement perfectionnée, de sorte qu'il n'est pas nécessairement facile de marquer la fin du projet. Une façon de répondre à cette question est de considérer le moment où l'essentiel du travail pour ce projet est terminé. La réponse est la suivante : pour un logiciel fiable, le travail n'est pas terminé avant longtemps.
Au fur et à mesure que de nouvelles fonctionnalités sont développées pour les Linodes, un travail doit être effectué pour assurer la compatibilité avec Live Migrations pour ces fonctionnalités. Lors de l'introduction de certaines fonctionnalités, il n'y a pas de nouveau travail de développement sur Live Migrations à faire, et nous avons seulement besoin de tester que Live Migrations fonctionne toujours comme prévu. Pour d'autres, le travail de compatibilité avec Live Migrations est marqué comme une tâche au début du développement des nouvelles fonctionnalités.
Comme pour tout ce qui concerne les logiciels, la recherche permet toujours de découvrir de meilleures méthodes de mise en œuvre. Par exemple, il se peut qu'une approche plus modulaire de l'intégration de Live Migrations permette de réduire la maintenance à long terme. Il est également possible que l'intégration de la fonctionnalité Live Migrations dans un code de niveau inférieur permette de l'activer dès le départ pour les futures fonctionnalités de Linode. Nos équipes considèrent toutes ces options, et les outils qui alimentent la plateforme Linode sont des entités vivantes qui continueront d'évoluer.





Commentaires