

When developers deploy a workload to a cloud computing platform, they often don’t pause to think about the underlying hardware that their services run on. In the idealized image of the “cloud,” hardware maintenance and physical limitations are invisible. Unfortunately, hardware does need maintenance occasionally, which can cause downtime. To avoid passing this downtime on to our customers, and to live up to the promise of the cloud, Linode implements a tool called Live Migrations.
Live Migrations is a technology that allows Linode instances to move between physical machines without interruption of service. When a Linode is moved with Live Migrations, the transition is invisible to that Linode’s processes. If a host’s hardware needs maintenance, Live Migrations can be used to seamlessly transition all of that host’s Linodes to a new host. After this migration is finished, the physical hardware can be repaired, and the downtime will not impact our customers.
For me, developing this technology was a defining moment and a turning point between cloud technologies and non-cloud technologies. I have a soft spot for the Live Migrations technology because I spent over a year of my life working on it. Now, I get to share the story with all of you.
How Live Migrations Work
Live Migrations at Linode started like most new projects; with a lot of research, a series of prototypes, and help from many colleagues and managers. The first movement forward was to investigate how QEMU handles Live Migrations. QEMU is a virtualization technology used by Linode, and Live Migrations is a feature of QEMU. As a result, our team’s focus was to bring this technology to Linode, and not to invent it.
So, how does Live Migration technology work the way QEMU has implemented it? The answer is a four step process:
- The destination qemu instance is spun up with the exact same parameters that exist on the source qemu instance.
- The disks are Live Migrated over. Any changes to the disk are communicated as well while this transfer is running.
- The RAM is Live Migrated over. Any changes to the RAM pages have to be communicated as well. If there are any disk data changes during this phase too, then those changes will also be copied over to the disk of the destination QEMU instance.
- The cutover point is executed. When QEMU determines that there are few enough pages of RAM that it can confidently cut over, the source and destination QEMU instances are paused. QEMU copies over the last few pages of RAM and the machine state. The machine state includes the CPU cache and the next CPU instruction. Then, QEMU tells the destination to start, and the destination picks up right where the source left off.
These steps explain how to perform a Live Migration with QEMU at a high level. However, specifying exactly how you want the destination QEMU instance to be started is a very manual process. As well, each action in the process needs to be started at the right time.
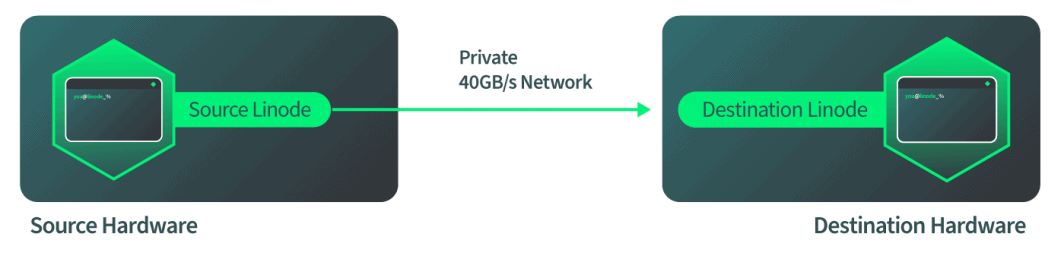
How Live Migrations are Implemented at Linode
After looking at what the QEMU developers have already created, how do we utilize this at Linode? The answer to this question is where the bulk of the work was for our team.
In accordance with step 1 of the Live Migration workflow, the destination QEMU instance is spun up to accept the incoming Live Migration. When implementing this step, the first thought was to take the config profile of the current Linode and spin it up on a destination machine. This would be simple in theory, but thinking about it further reveals more complicated scenarios. In particular, the config profile tells you how the Linode booted, but it doesn’t necessarily describe the complete state of the Linode after booting. For example, a user could have attached a Block Storage device by hot plugging it into the Linode after it was booted, and this would not be documented in the config profile.
In order to create the QEMU instance on the destination host, a profile of the currently running QEMU instance had to be taken. We profiled this currently running QEMU instance by inspecting the QMP interface. This interface gives us information about how the QEMU instance is laid out. It does not provide information about what is going on inside the instance from the guest’s point of view. It tells us where the disks are plugged in and which virtualized PCI slot the virtual disks are plugged into, for both local SSD and block storage. After querying QMP and inspecting and introspecting the QEMU instance, a profile is built that describes exactly how to reproduce this machine on the destination.
On the destination machine we receive the complete description of what the source instance looks like. We can then faithfully recreate the instance here, with one difference. The difference is that the destination QEMU instance is booted with an option that tells QEMU to accept an incoming migration.
At this point, we should take a break from documenting Live Migrations and switch to explaining how QEMU achieves these feats. The QEMU process tree is laid out as a controlling process and several worker processes. One of the worker processes is responsible for things like returning QMP calls or handling a Live Migration. The other processes map one-to-one to guest CPUs. The guest’s environment is isolated from this side of QEMU and behaves as its own independent system.
In this sense, there are 3 layers we are working with:
- Layer 1 is our management layer;
- Layer 2 is the part of the QEMU process that is handling all of these actions for us; and
- Layer 3 is the actual guest layer that Linode users interact with.
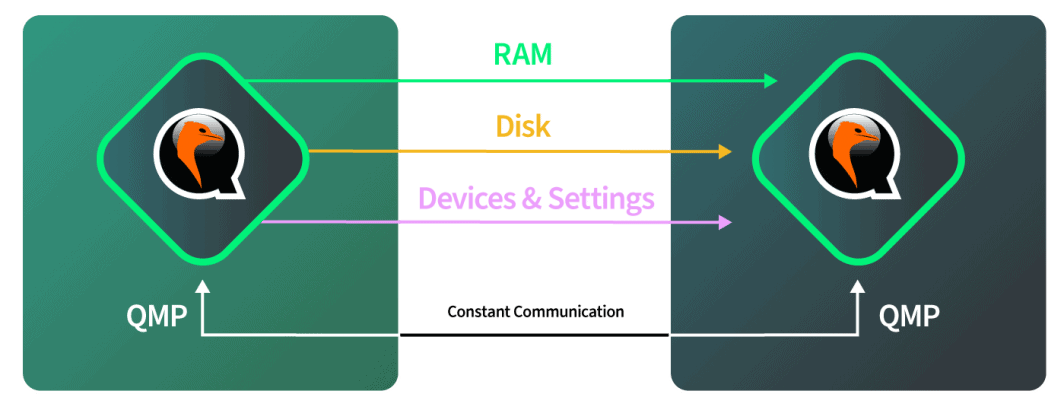
After the destination is booted and is ready to accept the incoming migration, the destination hardware lets the source hardware know that the source should start sending data over. The source starts once it receives this signal and we tell QEMU, in software, to start the disk migration. The software autonomously monitors the disk progress to check when it is completed. The software then automatically switches to RAM migration when the disk is complete. The software then again autonomously monitors the RAM migration and then automatically switches to the cutover mode when the RAM migration is complete. All of this happens over Linode’s 40Gbps network, so the network side of things is fairly quick.
Cutover: The Critical Section
The cutover step is also known as the critical section of a Live Migration, and understanding this step is the most important part of understanding Live Migrations.
At the cutover point QEMU has determined that it is ready to cut over and start running on the destination machine. The source QEMU instance instructs both sides to pause. This means a couple of things:
- Time stops according to the guest. If the guest is running a time synchronization service like the Network Time Protocol (NTP), then NTP will automatically resync the time after the Live Migration completes. This is because the system clock will be a few seconds behind.
- Network requests stop. If those network requests are TCP based like SSH or HTTP, there will be no perceived loss in connectivity. If those network requests are UDP based like live streaming video, it may result in a few dropped frames.
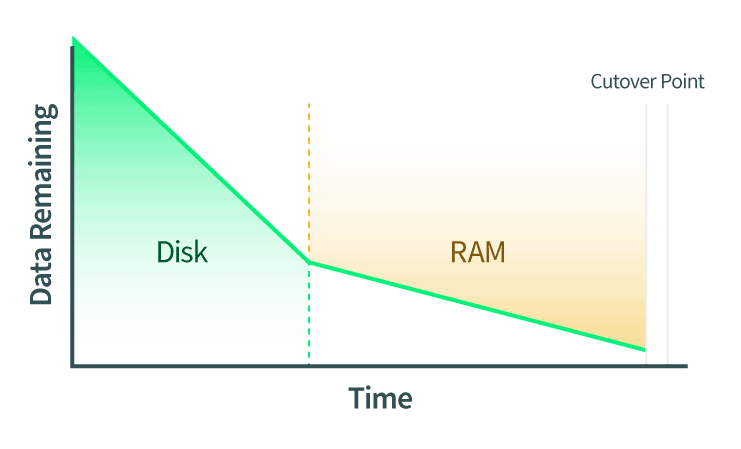
Because time and network requests are stopped, we want the cutover to happen as quickly as possible. However, there are several things we need to check first to ensure the cutover succeeds:
- Make sure the Live Migration completed without errors. If there was an error, we roll back, unpause the source Linode, and don’t proceed any further. This point specifically took a lot of trial and error to resolve during development, and it was the source of much pain, but our team finally got to the bottom of it.
- Ensure networking is going to turn off at the source and start up at the destination properly.
- Let the rest of our infrastructure know exactly what physical machine this Linode now resides on.
As there is a time limit for the cutover, we want to finish these steps quickly. After these points are addressed, we complete the cutover. The source Linode automatically gets the completed signal and tells the destination to start. The destination Linode picks up right where it left off. Any remaining items on the source and the destination are cleaned up. If the destination Linode needs to be Live Migrated again at some point in the future, the process can be repeated.
Overview of Edge Cases
Most of this process was straightforward to implement, but the development of Live Migrations was extended by edge cases. A lot of credit for completing this project goes to the management team who saw the vision of the completed tool and allocated the resources to complete the task, as well as the employees who saw the project through to completion.
Here are some of the areas where edge cases were encountered:
- The internal tooling to orchestrate Live Migrations for the Linode customer support and hardware operations teams had to be built. This was similar to other existing tools we had and used at the time, but different enough that a large development effort was required to build it:
- This tool has to automatically look at the entire hardware fleet in a datacenter and figure out which host should be the destination for each Live Migrated Linode. The relevant specifications when making this selection include SSD storage space available and RAM allocations.
- The physical processor of the destination machine has to be compatible with the incoming Linode. In particular, a CPU can have features (also referred to as CPU flags) that users’ software can leverage. For example, one such feature is aes, which provides hardware-accelerated encryption. The CPU of the destination for a Live Migration needs to support the CPU flags of the source machine. This turned out to be a very complex edge case, and the next section describes a solution to this problem.
- Gracefully handling failure cases, including end user intervention or loss of networking during the Live Migration. These failure cases are enumerated in more detail in a later section of this post.
- Keeping up with changes to the Linode platform, which is an ongoing process. For every feature we support on Linodes now and in the future, we have to make sure the feature is compatible with Live Migrations. This challenge is described at the end of this post.
CPU flags
QEMU has different options for how to present a CPU to the guest operating system. One of those options is to pass the host CPU’s model number and features (also referred to as CPU flags) directly to the guest. By choosing this option, the guest can use the full unencumbered power that the KVM virtualization system allows. When KVM was first adopted by Linode (which preceded Live Migrations), this option was selected to maximize performance. However, this decision later presented many challenges during the development of Live Migrations.

In the testing environment for Live Migrations, the source and destination hosts were two identical machines. In the real world our hardware fleet is not 100% the same, and there are differences between machines that can result in different CPU flags being present. This matters because when a program is loaded inside the Linode’s operating system, the Linode presents CPU flags to that program, and the program will load specific sections of the software into memory to take advantage of those flags. If a Linode is Live Migrated to a destination machine that does not support those CPU flags, the program will crash. This can lead to the guest operating system crashing and may result in the Linode rebooting.
We found three factors that influence how a machine’s CPU flags are presented to guests:
- There are minor differences between CPUs, depending on when the CPU was purchased. A CPU purchased at the end of the year may have different flags than one purchased at the beginning of the year, depending on when CPU manufacturers release new hardware. Linode is constantly buying new hardware to add capacity, and even if the CPU model for two different hardware orders is the same, the CPU flags may differ.
- Different Linux kernels may pass different flags to QEMU. In particular, the Linux kernel for the source machine of a Live Migration may pass different flags to QEMU than the destination machine’s Linux kernel. Updating the Linux kernel on the source machine requires a reboot, and so this mismatch can’t be resolved by upgrading the kernel before proceeding with the Live Migration, because that would result in downtime for the Linodes on that machine.
- Similarly, different QEMU versions can affect which CPU flags are presented. Updating QEMU also requires a reboot of the machine.
So, Live Migrations needed to be implemented in a way that prevents program crashes from CPU flag mismatches. There are two options available:
- We could tell QEMU to emulate the CPU flags. This would lead to software that used to run fast now running slow, with no way to investigate why.
- We can gather a list of CPU flags on the source and make sure the destination has those same flags before proceeding. This is more complicated, but it will preserve the speed of our users’ programs. This is the option that we implemented for Live Migrations.
After we decided on matching the source and destination CPU flags, we accomplished this task with a belt and suspenders approach that consisted of two different methods:
- The first method is the simpler of the two. All of the CPU flags are sent from the source to the destination hardware. When the destination hardware sets up the new qemu instance, it checks to make sure that it has at least all of the flags that were present on the source Linode. If they don’t match, the Live Migration does not proceed.
- The second method is much more complicated, but it can prevent failed migrations that result from CPU flag mismatches. Before a Live Migration is initiated, we create a list of hardware with compatible CPU flags. Then, a destination machine from this list is chosen.
This second method needs to be performed quickly, and it carries a lot of complexity. We need to check up to 226 CPU flags across more than 900 machines in some cases. Writing all of these 226 CPU flag checks would be very difficult, and they would have to be maintained. This problem was ultimately solved by an amazing idea proposed by Linode’s founder, Chris Aker.
The key idea was to make a list of all the CPU flags and represent it as a binary string. Then, the bitwise and operation can be used to compare the strings. To demonstrate this algorithm, I’ll start with a simple example as follows. Consider this Python code that compares two numbers using bitwise and:
>>> 1 & 1
1
>>> 2 & 3
2
>>> 1 & 3
1To understand why the bitwise and operation has these results, it’s helpful to represent the numbers in binary. Let’s examine the bitwise and operation for the numbers 2 and 3, represented in binary:
>>> # 2: 00000010
>>> # &
>>> # 3: 00000011
>>> # =
>>> # 2: 00000010The bitwise and operation compares the binary digits, or bits, of the two different numbers. Starting from the rightmost digit in the above numbers and then proceeding to the left:
- The rightmost/first bits of 2 and 3 are 0 and 1, respectively. The bitwise and result for
0 & 1is 0. - The second rightmost bit of 2 and 3 is 1 for both numbers. The bitwise and result for
1 & 1is 1. - All other bits for these numbers are 0, and the bitwise and result for 0 & 0 is 0.
The binary representation for the full result is then 00000010, which is equal to 2.
For Live Migrations, the full list of CPU flags is represented as a binary string, where each bit represents a single flag. If the bit is 0, then the flag is not present, and if the bit is 1, then the flag is present. For example, one bit may correspond to the aes flag, and another bit may correspond to the mmx flag. The specific positions of these flags in the binary representation is maintained, documented, and shared by the machines in our datacenters.
Maintaining this list representation is much simpler and more efficient than maintaining a set of if statements that would hypothetically check for the presence of a CPU flag. For example, suppose that there were 7 CPU flags that needed to be tracked and checked in total. These flags could be stored in an 8 bit number (with one bit left over for future expansion). An example string could look like 00111011, where the rightmost bit shows that aes is enabled, the second rightmost bit shows that mmx is enabled, the third bit indicates that another flag is disabled, and so on.
As shown in the next code snippet, we can then see which hardware will support this combination of flags and return all of the matches in one cycle. If we had used a set of if statements to compute these matches, it would take a much higher number of cycles to achieve this result. For an example Live Migration where 4 CPU flags were present on the source machine, it would take 203,400 cycles to find matching hardware.
The Live Migration code performs a bitwise and operation on the CPU flag strings on the source and destination machines. If the result is equal to the CPU flag string of the source machine, then the destination machine is compatible. Consider this Python code snippet:
>>> # The b'' syntax below represents a binary string
>>>
>>> # The s variable stores the example CPU flag
>>> # string for the source:
>>> s = b'00111011'
>>> # The source CPU flag string is equivalent to the number 59:
>>> int(s.decode(), 2)
59
>>>
>>> # The d variable stores the example CPU flag
>>> # string for the source:
>>> d = b'00111111'
>>> # The destination CPU flag string is equivalent to the number 63:
>>> int(d.decode(), 2)
63
>>>
>>> # The bitwise and operation compares these two numbers:
>>> int(s.decode(), 2) & int(d.decode(), 2) == int(s.decode(), 2)
True
>>> # The previous statement was equivalent to 59 & 63 == 59.
>>>
>>> # Because source & destination == source,
>>> # the machines are compatibleNote that in the above code snippet, the destination supported more flags than the source. The machines are considered compatible because all the source’s CPU flags are present on the destination, which is what the bitwise and operation ensures.
The results of this algorithm are used by our internal tooling to build a list of compatible hardware. This list is displayed to our Customer Support and Hardware Operations teams. These teams can use the tooling to orchestrate different operations:
- The tooling can be used to select the best compatible hardware for a given Linode.
- We can initiate a Live Migration for a Linode without specifying a destination. The best compatible hardware in the same datacenter will automatically be selected and the migration will begin.
- We can initiate Live Migrations for all the Linodes on a host as a single task. This functionality is used before performing maintenance on a host. The tooling will automatically select destinations for all of the Linodes and orchestrate Live Migrations for each Linode.
- We can specify a list of several machines that need maintenance, and the tooling will automatically orchestrate Live Migrations for all of the Linodes across the hosts.
A lot of development time goes into making software “just work…”
Failure Cases
One feature that is not talked about very often in software is handling failure cases gracefully. Software is supposed to “just work.” A lot of development time goes into making software “just work,” and that was very much the case for Live Migrations. A lot of time was spent thinking about all the ways in which this tool could not work and gracefully handling those cases. Here are some of those scenarios and how they are addressed:
- What happens if a customer wants to access a feature of their Linode from the Cloud Manager? For example, a user may reboot the Linode or attach a Block Storage Volume to it.
- Answer: The customer has the power to do this. The Live Migration gets interrupted and does not proceed. This solution is appropriate because the Live Migration can be attempted later.
- What happens if the destination Linode fails to boot?
- Answer: Let the source hardware know, and engineer the internal tooling to automatically pick a different piece of hardware in the datacenter. Also, notify the operations team so they can investigate the original destination’s hardware. This has happened in production and was handled by our Live Migrations implementation.
- What happens if you lose networking mid-migration?
- Answer: Autonomously monitor the progress of the Live Migration, and if it hasn’t made any progress over the last minute, cancel the Live Migration and let the operations team know. This has not happened outside of a test environment, but our implementation is prepared for this scenario.
- What happens if the rest of the Internet shuts down, but the source and destination hardware is still running and communicating, and the source or destination Linode is running normally?
- Answer: If the Live Migration is not in the critical section, stop the Live Migration. Then attempt it again later.
- If you are in the critical section, continue the Live Migration. This is important because the source Linode is paused, and the destination Linode needs to start for operation to resume.
- These scenarios were modeled in the test environment, and the prescribed behavior was found to be the best course of action.
Keeping Up with Changes
After hundreds of thousands of successful Live Migrations, a question that is sometimes asked is “When is Live Migrations done?” Live Migrations is a technology whose use expands over time and which is continually refined, so marking the end of the project is not necessarily straightforward. One way to answer this question is to consider when the bulk of the work for this project is complete. The answer is: for reliable, dependable software, the work is not done for a long time.
As new features are developed for Linodes over time, work must be done to ensure compatibility with Live Migrations for those features. When introducing some features, there is no new development work on Live Migrations to be done, and we only need to test that Live Migrations still works as expected. For others, the Live Migrations compatibility work is marked as a task early in the new features’ development.
As with everything in software, there are always better implementation methods that are discovered through research. For example, it may be that a more modular approach to Live Migrations’ integration will offer less maintenance in the long run. Or, it’s possible that blending Live Migrations functionality into lower level code will help enable it out of the box for future Linode features. Our teams consider all of these options, and the tools that power the Linode platform are living entities that will continue to evolve.






Comments