

Cuando los desarrolladores despliegan una carga de trabajo en una plataforma de computación en nube, a menudo no se paran a pensar en el hardware subyacente sobre el que se ejecutan sus servicios. En la imagen idealizada de la "nube", el mantenimiento del hardware y las limitaciones físicas son invisibles. Por desgracia, el hardware necesita mantenimiento de vez en cuando, lo que puede provocar tiempos de inactividad. Para evitar trasladar este tiempo de inactividad a nuestros clientes y cumplir la promesa de la nube, Linode implementa una herramienta llamada Live Migrations.
Live Migrations es una tecnología que permite a las instancias de Linode moverse entre máquinas físicas sin interrumpir el servicio. Cuando se mueve un Linode con Live Migrations, la transición es invisible para los procesos de ese Linode. Si el hardware de un host necesita mantenimiento, las Migraciones en vivo pueden utilizarse para realizar una transición sin problemas de todos los Linodes de ese host a un nuevo host. Una vez finalizada la migración, el hardware físico puede repararse y el tiempo de inactividad no afectará a nuestros clientes.
Para mí, el desarrollo de esta tecnología fue un momento decisivo y un punto de inflexión entre las tecnologías en la nube y las que no lo son. Tengo debilidad por la tecnología de Live Migrations porque pasé más de un año de mi vida trabajando en ella. Ahora, puedo compartir la historia con todos ustedes.
Cómo funcionan las migraciones en vivo
Live Migrations en Linode comenzó como la mayoría de los nuevos proyectos; con mucha investigación, una serie de prototipos y la ayuda de muchos colegas y directivos. El primer movimiento hacia adelante fue investigar cómo QEMU maneja las Live Migrations. QEMU es una tecnología de virtualización utilizada por Linode, y Live Migrations es una característica de QEMU. Por ello, nuestro equipo se centró en llevar esta tecnología a Linode, y no en inventarla.
Entonces, ¿cómo funciona la tecnología de Live Migration de la forma en que QEMU la ha implementado? La respuesta es un proceso de cuatro pasos:
- La instancia qemu de destino se pone en marcha con los mismos parámetros que existen en la instancia qemu de origen.
- Los discos se transfieren en vivo. Cualquier cambio en el disco se comunica también mientras se ejecuta esta transferencia.
- La RAM está migrada en vivo. Cualquier cambio en las páginas de la RAM tiene que ser comunicado también. Si hay algún cambio en los datos del disco durante esta fase también, entonces esos cambios también se copiarán en el disco de la instancia QEMU de destino.
- Se ejecuta el punto de corte. Cuando QEMU determina que hay suficientes páginas de RAM que puede cortar con confianza, las instancias de QEMU de origen y destino se pausan. QEMU copia las últimas páginas de RAM y el estado de la máquina. El estado de la máquina incluye la caché de la CPU y la siguiente instrucción de la CPU. Luego, QEMU le dice al destino que comience, y el destino lo retoma justo donde lo dejó el origen.
Estos pasos explican cómo realizar una migración en vivo con QEMU a alto nivel. Sin embargo, especificar exactamente cómo quieres que se inicie la instancia QEMU de destino es un proceso muy manual. Además, cada acción del proceso debe iniciarse en el momento adecuado.
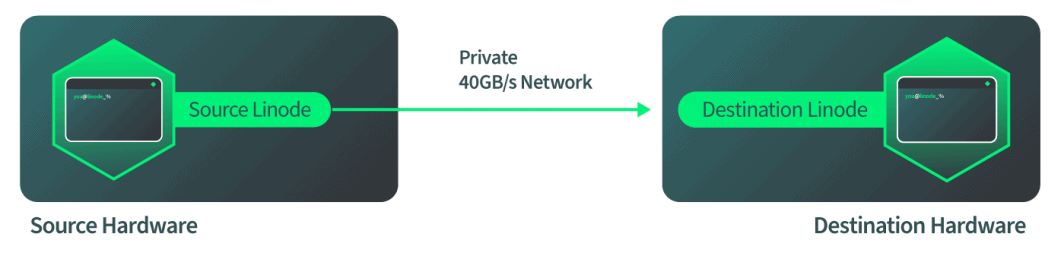
Cómo se implementan las migraciones en vivo en Linode
Después de ver lo que los desarrolladores de QEMU ya han creado, ¿cómo podemos utilizarlo en Linode? La respuesta a esta pregunta es donde estuvo la mayor parte del trabajo para nuestro equipo.
De acuerdo con el paso 1 del flujo de trabajo de la migración en vivo, la instancia QEMU de destino se pone en marcha para aceptar la migración en vivo entrante. Al implementar este paso, el primer pensamiento fue tomar el perfil de configuración del Linode actual y ponerlo en marcha en una máquina de destino. Esto sería sencillo en teoría, pero si lo pensamos un poco más nos encontramos con escenarios más complicados. En concreto, el perfil de configuración indica cómo arrancó Linode , pero no describe necesariamente el estado completo de Linode tras el arranque. Por ejemplo, un usuario podría haber conectado un dispositivo Block Storage dispositivo conectándolo en caliente a Linode tras el arranque, y esto no estaría documentado en el perfil de configuración.
Para crear la instancia de QEMU en el host de destino, había que tomar un perfil de la instancia de QEMU que se está ejecutando actualmente. Hemos perfilado esta instancia de QEMU que se está ejecutando actualmente inspeccionando la interfaz de QMP. Esta interfaz nos da información sobre cómo está dispuesta la instancia QEMU. No proporciona información sobre lo que ocurre dentro de la instancia desde el punto de vista del huésped. Nos dice dónde están conectados los discos y en qué ranura PCI virtualizada están conectados los discos virtuales, tanto para el almacenamiento local SSD como para el almacenamiento en bloque. Después de consultar QMP e inspeccionar e introspeccionar la instancia QEMU, se construye un perfil que describe exactamente cómo reproducir esta máquina en el destino.
En la máquina de destino recibimos la descripción completa del aspecto de la instancia de origen. Entonces podemos recrear fielmente la instancia aquí, con una diferencia. La diferencia es que la instancia QEMU de destino se inicia con una opción que indica a QEMU que acepte una migración entrante.
Llegados a este punto, deberíamos dejar de documentar las migraciones en vivo y pasar a explicar cómo QEMU consigue estas hazañas. El árbol de procesos de QEMU se presenta como un proceso de control y varios procesos de trabajo. Uno de los procesos de trabajo es responsable de cosas como devolver las llamadas a QMP o manejar una migración en vivo. Los otros procesos se asignan uno a uno a las CPUs de los huéspedes. El entorno del huésped está aislado de este lado de QEMU y se comporta como su propio sistema independiente.
En este sentido, hay 3 capas con las que estamos trabajando:
- La capa 1 es nuestra capa de gestión;
- La capa 2 es la parte del proceso de QEMU que maneja todas estas acciones por nosotros; y
- La capa 3 es la capa de invitados con la que interactúan los usuarios de Linode .
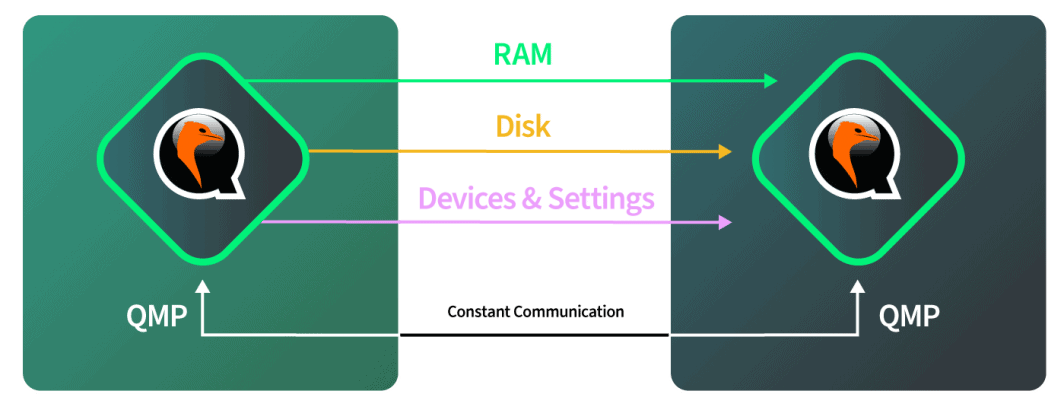
Después de que el destino se inicie y esté listo para aceptar la migración entrante, el hardware de destino hace saber al hardware de origen que éste debe empezar a enviar datos. El origen se inicia una vez que recibe esta señal y le decimos a QEMU, en software, que inicie la migración del disco. El software supervisa de forma autónoma el progreso del disco para comprobar cuándo se ha completado. El software entonces cambia automáticamente a la migración de RAM cuando el disco está completo. El software vuelve a supervisar de forma autónoma la migración de la RAM y luego cambia automáticamente al modo de corte cuando la migración de la RAM se ha completado. Todo esto ocurre a través de la red de 40 Gbps de Linode, por lo que la parte de la red es bastante rápida.
La transición: La sección crítica
El paso de corte también se conoce como la sección crítica de una migración en vivo, y entender este paso es la parte más importante para entender las migraciones en vivo.
En el punto de corte, QEMU ha determinado que está listo para cortar y empezar a funcionar en la máquina de destino. La instancia QEMU de origen ordena a ambas partes que hagan una pausa. Esto significa un par de cosas:
- El tiempo se detiene según el huésped. Si el huésped está ejecutando un servicio de sincronización de tiempo como el Protocolo de Tiempo de Red(NTP), entonces NTP resincronizará automáticamente el tiempo después de que la Migración en Vivo se complete. Esto se debe a que el reloj del sistema se retrasará unos segundos.
- Las peticiones de red se detienen. Si esas peticiones de red están basadas en TCP, como SSH o HTTP, no se percibirá ninguna pérdida de conectividad. Si esas solicitudes de red se basan en UDP, como la transmisión de vídeo en directo, es posible que se pierdan algunas tramas.
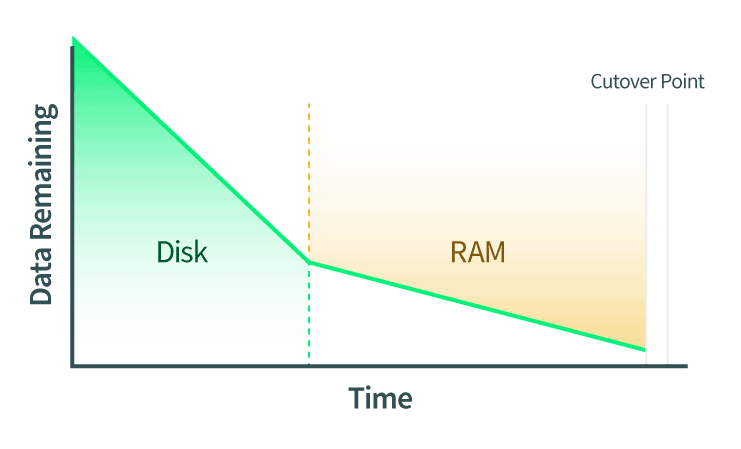
Dado que el tiempo y las peticiones de red se detienen, queremos que el corte se produzca lo más rápidamente posible. Sin embargo, hay varias cosas que tenemos que comprobar primero para asegurarnos de que la transferencia se realiza con éxito:
- Asegúrese de que la migración en vivo se ha completado sin errores. Si se produce un error, retrocedemos, desbloqueamos la fuente Linode y no seguimos adelante. Este punto en concreto requirió mucho ensayo y error para resolverlo durante el desarrollo, y fue la fuente de mucho dolor, pero nuestro equipo finalmente llegó al fondo del asunto.
- Asegúrese de que la red se apague en el origen y se inicie en el destino correctamente.
- Que el resto de nuestra infraestructura sepa exactamente en qué máquina física reside ahora este Linode .
Como hay un límite de tiempo para el corte, queremos terminar estos pasos rápidamente. Una vez solucionados estos puntos, completamos el corte. La fuente Linode recibe automáticamente la señal completada y le dice al destino que comience. El destino Linode retoma justo donde lo dejó. Cualquier elemento restante en el origen y el destino se limpia. Si el destino Linode necesita ser migrado en vivo de nuevo en algún momento en el futuro, el proceso se puede repetir.
Visión general de los casos límite
La mayor parte de este proceso fue sencillo de implementar, pero el desarrollo de las migraciones en vivo se vio ampliado por casos extremos. Gran parte del mérito de la realización de este proyecto corresponde al equipo directivo, que vio la visión de la herramienta terminada y asignó los recursos para completar la tarea, así como a los empleados que vieron el proyecto hasta su finalización.
Estos son algunos de los ámbitos en los que se encontraron casos límite:
- Había que construir la herramienta interna para orquestar las migraciones en vivo para los equipos de soporte al cliente y de operaciones de hardware de Linode . Era similar a otras herramientas existentes que teníamos y utilizábamos en ese momento, pero lo suficientemente diferente como para que fuera necesario un gran esfuerzo de desarrollo para construirla:
- Esta herramienta tiene que mirar automáticamente toda la flota de hardware de un centro de datos y averiguar qué host debe ser el destino de cada Live Migrated Linode. Las especificaciones relevantes al hacer esta selección incluyen el espacio de almacenamiento SSD disponible y las asignaciones de RAM.
- El procesador físico de la máquina de destino tiene que ser compatible con el entrante Linode. En particular, una CPU puede tener características (también denominadas banderas de la CPU) que el software de los usuarios puede aprovechar. Por ejemplo, una de estas características es aes, que proporciona un cifrado acelerado por hardware. La CPU del destino de una migración en vivo necesita soportar los indicadores de CPU de la máquina de origen. Esto resultó ser un caso límite muy complejo, y la siguiente sección describe una solución a este problema.
- Manejar con elegancia los casos de fallo, incluyendo la intervención del usuario final o la pérdida de la red durante la migración en vivo. Estos casos de fallo se enumeran con más detalle en una sección posterior de este post.
- Mantenerse al día con los cambios en la plataforma Linode , que es un proceso continuo. Para cada característica que apoyamos en Linodes ahora y en el futuro, tenemos que asegurarnos de que la característica es compatible con Live Migrations. Este reto se describe al final de este post.
Banderas de la CPU
QEMU tiene diferentes opciones para presentar una CPU al sistema operativo invitado. Una de esas opciones es pasar el número de modelo y las características de la CPU anfitriona (también denominadas banderas de la CPU) directamente al invitado. Al elegir esta opción, el invitado puede utilizar toda la potencia libre que permite el sistema de virtualización KVM . Cuando KVM fue adoptado por primera vez por Linode (que precedió a las migraciones en vivo), se seleccionó esta opción para maximizar el rendimiento. Sin embargo, esta decisión presentó posteriormente muchos desafíos durante el desarrollo de Live Migrations.

En el entorno de pruebas de las migraciones en vivo, los hosts de origen y destino eran dos máquinas idénticas. En el mundo real, nuestro parque de hardware no es 100% igual, y hay diferencias entre las máquinas que pueden resultar en la presencia de diferentes banderas de CPU. Esto es importante porque cuando se carga un programa dentro del sistema operativo de Linode, el Linode presenta banderas de CPU a ese programa, y el programa cargará secciones específicas del software en la memoria para aprovechar esas banderas. Si un Linode se migra en vivo a una máquina de destino que no soporta esos indicadores de CPU, el programa se bloqueará. Esto puede llevar a que el sistema operativo huésped se bloquee y puede provocar el reinicio de Linode .
Encontramos tres factores que influyen en la forma en que los indicadores de la CPU de una máquina se presentan a los invitados:
- Hay pequeñas diferencias entre las CPUs, dependiendo de cuándo se compró la CPU. Una CPU comprada a finales de año puede tener banderas diferentes que una comprada a principios de año, dependiendo de cuándo los fabricantes de CPUs lanzan nuevo hardware. Linode está constantemente comprando nuevo hardware para añadir capacidad, e incluso si el modelo de CPU para dos pedidos de hardware diferentes es el mismo, las banderas de la CPU pueden diferir.
- Diferentes kernels de Linux pueden pasar diferentes banderas a QEMU. En particular, el kernel Linux de la máquina de origen de una migración en vivo puede pasar diferentes banderas a QEMU que el kernel Linux de la máquina de destino. La actualización del kernel Linux en la máquina de origen requiere un reinicio, por lo que este desajuste no puede resolverse actualizando el kernel antes de proceder a la Migración en vivo, ya que esto provocaría un tiempo de inactividad para los Linodes de esa máquina.
- Del mismo modo, las diferentes versiones de QEMU pueden afectar a los indicadores de la CPU que se presentan. La actualización de QEMU también requiere un reinicio de la máquina.
Por lo tanto, las migraciones en vivo debían implementarse de manera que se evitara el bloqueo del programa por desajustes en los indicadores de la CPU. Hay dos opciones disponibles:
- Podríamos decirle a QEMU que emule las banderas de la CPU. Esto llevaría a que el software que solía ejecutarse rápido ahora se ejecute lento, sin poder investigar por qué.
- Podemos reunir una lista de banderas de la CPU en el origen y asegurarnos de que el destino tiene esas mismas banderas antes de proceder. Esto es más complicado, pero preservará la velocidad de los programas de nuestros usuarios. Esta es la opción que implementamos para las migraciones en vivo.
Una vez que decidimos hacer coincidir las banderas de la CPU de origen y destino, realizamos esta tarea con un enfoque de cinturón y tirantes que consistía en dos métodos diferentes:
- El primer método es el más sencillo de los dos. Todas las banderas de la CPU se envían desde el hardware de origen al de destino. Cuando el hardware de destino configura la nueva instancia de qemu, comprueba que tiene al menos todas las banderas que estaban presentes en el origen Linode. Si no coinciden, la migración en vivo no procede.
- El segundo método es mucho más complicado, pero puede evitar las migraciones fallidas que resultan de los desajustes de los indicadores de la CPU. Antes de iniciar una migración en vivo, creamos una lista de hardware con banderas de CPU compatibles. A continuación, se elige una máquina de destino de esta lista.
Este segundo método debe realizarse rápidamente, y conlleva una gran complejidad. Tenemos que comprobar hasta 226 banderas de la CPU en más de 900 máquinas en algunos casos. Escribir todas estas 226 comprobaciones de banderas de la CPU sería muy difícil, y habría que mantenerlas. Este problema se resolvió finalmente con una idea sorprendente propuesta por el fundador de Linode, Chris Aker.
La idea clave era hacer una lista de todas las banderas de la CPU y representarla como una cadena binaria. Luego, se puede utilizar la operación bitwise y para comparar las cadenas. Para demostrar este algoritmo, empezaré con un ejemplo sencillo como el siguiente. Considere este código Python que compara dos números usando bitwise and:
>>> 1 & 1
1
>>> 2 & 3
2
>>> 1 & 3
1Para entender por qué la operación "bitwise" y tiene estos resultados, es útil representar los números en binario. Examinemos la operación bit a bit y para los números 2 y 3, representados en binario:
>>> # 2: 00000010
>>> # &
>>> # 3: 00000011
>>> # =
>>> # 2: 00000010La operación bitwise and compara los dígitos binarios, o bits, de los dos números diferentes. Empezando por el dígito de más a la derecha en los números anteriores y luego procediendo hacia la izquierda:
- Los primeros bits de la derecha de 2 y 3 son 0 y 1, respectivamente. El resultado de los bits y el resultado de
0 & 1es 0. - El segundo bit más a la derecha de 2 y 3 es 1 para ambos números. El bit y el resultado para
1 & 1es 1. - Todos los demás bits de estos números son 0, y el resultado de 0 y 0 es 0.
La representación binaria del resultado completo es entonces 00000010que es igual a 2.
Para las migraciones en vivo, la lista completa de indicadores de la CPU se representa como una cadena binaria, donde cada bit representa un único indicador. Si el bit es 0, entonces la bandera no está presente, y si el bit es 1, entonces la bandera está presente. Por ejemplo, un bit puede corresponder a la bandera aes, y otro a la bandera mmx. Las posiciones específicas de estas banderas en la representación binaria se mantienen, se documentan y son compartidas por las máquinas de nuestros centros de datos.
Mantener esta representación en forma de lista es mucho más simple y eficiente que mantener un conjunto de sentencias if que hipotéticamente comprobarían la presencia de una bandera de la CPU. Por ejemplo, supongamos que hay 7 banderas de CPU que necesitan ser rastreadas y verificadas en total. Estas banderas podrían ser almacenadas en un número de 8 bits (con un bit de sobra para una futura expansión). Un ejemplo de cadena podría ser como 00111011donde el bit más a la derecha muestra que aes está activado, el segundo bit más a la derecha muestra que mmx está activado, el tercer bit indica que otra bandera está desactivada, y así sucesivamente.
Como se muestra en el siguiente fragmento de código, podemos ver qué hardware admite esta combinación de banderas y devolver todas las coincidencias en un ciclo. Si hubiéramos utilizado un conjunto de sentencias if para calcular estas coincidencias, se necesitaría un número mucho mayor de ciclos para lograr este resultado. Para un ejemplo de Migración en vivo en el que 4 banderas de CPU estuvieran presentes en la máquina de origen, se necesitarían 203.400 ciclos para encontrar el hardware coincidente.
El código de Migración en vivo realiza una operación a nivel de bits y en las cadenas de banderas de la CPU en las máquinas de origen y de destino. Si el resultado es igual a la cadena de banderas de CPU de la máquina de origen, entonces la máquina de destino es compatible. Considere este fragmento de código de Python :
>>> # The b'' syntax below represents a binary string
>>>
>>> # The s variable stores the example CPU flag
>>> # string for the source:
>>> s = b'00111011'
>>> # The source CPU flag string is equivalent to the number 59:
>>> int(s.decode(), 2)
59
>>>
>>> # The d variable stores the example CPU flag
>>> # string for the source:
>>> d = b'00111111'
>>> # The destination CPU flag string is equivalent to the number 63:
>>> int(d.decode(), 2)
63
>>>
>>> # The bitwise and operation compares these two numbers:
>>> int(s.decode(), 2) & int(d.decode(), 2) == int(s.decode(), 2)
True
>>> # The previous statement was equivalent to 59 & 63 == 59.
>>>
>>> # Because source & destination == source,
>>> # the machines are compatibleObserve que en el fragmento de código anterior, el destino admitía más banderas que el origen. Las máquinas se consideran compatibles porque todas las banderas de la CPU del origen están presentes en el destino, que es lo que asegura la operación bitwise and.
Los resultados de este algoritmo son utilizados por nuestra herramienta interna para construir una lista de hardware compatible. Esta lista se muestra a nuestros equipos de asistencia al cliente y de operaciones de hardware. Estos equipos pueden utilizar las herramientas para orquestar diferentes operaciones:
- La herramienta puede utilizarse para seleccionar el mejor hardware compatible para un determinado Linode.
- Podemos iniciar una migración en vivo para un Linode sin especificar un destino. Se seleccionará automáticamente el mejor hardware compatible en el mismo centro de datos y se iniciará la migración.
- Podemos iniciar migraciones en vivo para todos los Linodes de un host como una única tarea. Esta funcionalidad se utiliza antes de realizar el mantenimiento de un host. La herramienta seleccionará automáticamente los destinos para todos los Linodes y orquestará Migraciones en vivo para cada Linode.
- Podemos especificar una lista de varias máquinas que necesitan mantenimiento, y la herramienta orquestará automáticamente las migraciones en vivo para todos los Linodes a través de los hosts.
Se invierte mucho tiempo de desarrollo en hacer que el software "simplemente funcione"...
Casos de fracaso
Una característica de la que no se habla muy a menudo en el software es el manejo de los casos de fallo con gracia. Se supone que el software "simplemente funciona". Se dedica mucho tiempo de desarrollo a hacer que el software "simplemente funcione", y ese fue en gran medida el caso de Live Migrations. Se dedicó mucho tiempo a pensar en todas las formas en las que esta herramienta podría no funcionar y a manejar esos casos con elegancia. He aquí algunos de esos escenarios y cómo se abordan:
- ¿Qué ocurre si un cliente quiere acceder a una función de su Linode desde el Cloud Manager? Por ejemplo, un usuario puede reiniciar el Linode o adjuntarle un Volumen Block Storage .
- Respuesta: El cliente tiene la facultad de hacerlo. La Migración en vivo se interrumpe y no procede. Esta solución es adecuada porque la Migración en vivo puede intentarse más tarde.
- ¿Qué ocurre si el destino Linode no arranca?
- Respuesta: Avise al hardware de origen y diseñe las herramientas internas para que elijan automáticamente otro hardware en el centro de datos. Además, notifique al equipo de operaciones para que puedan investigar el hardware de destino original. Esto ha sucedido en producción y fue manejado por nuestra implementación de Migraciones en Vivo.
- ¿Qué ocurre si se pierde la red a mitad de la migración?
- Respuesta: Supervisar de forma autónoma el progreso de la migración en vivo, y si no ha avanzado en el último minuto, cancelar la migración en vivo y avisar al equipo de operaciones. Esto no ha ocurrido fuera de un entorno de pruebas, pero nuestra implementación está preparada para este escenario.
- ¿Qué sucede si el resto de Internet se apaga, pero el hardware de origen y destino sigue funcionando y comunicándose, y el Linode de origen o destino funciona normalmente?
- Respuesta: Si la migración en vivo no está en la sección crítica, detenga la migración en vivo. Vuelva a intentarlo más tarde.
- Si se encuentra en la sección crítica, continúe con la migración en vivo. Esto es importante porque el Linode de origen está en pausa, y el Linode de destino necesita iniciarse para que se reanude la operación.
- Estos escenarios fueron modelados en el entorno de prueba, y se encontró que el comportamiento prescrito era el mejor curso de acción.
Al día con los cambios
Después de cientos de miles de Migraciones en Vivo exitosas, una pregunta que a veces se hace es "¿Cuándo se acaba con las Migraciones en Vivo?" Live Migrations es una tecnología cuyo uso se expande con el tiempo y que se perfecciona continuamente, por lo que marcar el final del proyecto no es necesariamente sencillo. Una forma de responder a esta pregunta es considerar cuándo se ha completado la mayor parte del trabajo de este proyecto. La respuesta es: para un software fiable y de confianza, el trabajo no está hecho durante mucho tiempo.
A medida que se desarrollan nuevas características para Linodes a lo largo del tiempo, se debe trabajar para asegurar la compatibilidad con Migraciones en vivo para esas características. Cuando se introducen algunas características, no hay que hacer un nuevo trabajo de desarrollo en Migraciones en vivo, y sólo tenemos que probar que Migraciones en vivo sigue funcionando como se espera. Para otras, el trabajo de compatibilidad con Live Migrations se marca como una tarea al principio del desarrollo de las nuevas características.
Como todo en el ámbito del software, siempre hay mejores métodos de implementación que se descubren a través de la investigación. Por ejemplo, es posible que un enfoque más modular de la integración de Migraciones en vivo ofrezca menos mantenimiento a largo plazo. O bien, es posible que la integración de la funcionalidad de Live Migrations en el código de nivel inferior ayude a habilitarla de forma inmediata para futuras funciones de Linode . Nuestros equipos tienen en cuenta todas estas opciones, y las herramientas que impulsan la plataforma Linode son entidades vivas que seguirán evolucionando.





Comentarios (1)
Grande e maravilhoso trabalho!
Obrigado!