
 (1)")
Les grands modèles de langage (LLM) font fureur, surtout depuis les récents développements de l'OpenAI. L'attrait des LLM vient de leur capacité à comprendre, interpréter et générer du langage humain d'une manière que l'on pensait autrefois être le domaine exclusif de l'homme. Des outils comme CoPilot s'intègrent rapidement dans la vie quotidienne des développeurs, tandis que les applications alimentées par le ChatGPT deviennent de plus en plus courantes.
La popularité des LLM tient également à leur accessibilité pour le développeur moyen. Avec de nombreux modèles open-source disponibles, de nouvelles startups technologiques apparaissent chaque jour avec une sorte de solution basée sur le LLM pour résoudre un problème.
Les données ont été qualifiées de "nouveau pétrole". Dans l'apprentissage automatique, les données constituent la matière première utilisée pour former, tester et valider les modèles. Des données de haute qualité, diversifiées et représentatives sont essentielles pour créer des LLM précis, fiables et robustes.
Construire son propre LLM peut être un défi, en particulier lorsqu'il s'agit de collecter et de stocker des données. La gestion de grands volumes de données non structurées, leur stockage et la gestion de l'accès ne sont que quelques-uns des défis auxquels vous pourriez être confronté. Dans ce billet, nous allons explorer ces défis liés à la gestion des données. Plus précisément, nous nous pencherons sur les points suivants
- Comment fonctionnent les mécanismes d'apprentissage tout au long de la vie et comment choisir parmi les modèles existants ?
- Les types de données utilisées dans les LLM
- Pipelines de données et ingestion pour les LLM
Notre objectif est de vous donner une compréhension claire du rôle critique que les données jouent dans les LLM, en vous dotant des connaissances nécessaires pour gérer efficacement les données dans vos propres projets LLM.
Pour commencer, posons les bases de la compréhension du LLM.
Comment fonctionnent les LLM et comment choisir parmi les modèles existants ?
À un niveau élevé, un LLM fonctionne en convertissant les mots (ou les phrases) en représentations numériques appelées "embeddings". Ces représentations capturent le sens sémantique et les relations entre les mots, ce qui permet au modèle de comprendre le langage. Par exemple, un LLM apprendrait que les mots "chien" et "chiot" sont liés et les placerait plus près l'un de l'autre dans leur espace numérique, tandis que le mot "arbre" serait plus éloigné.

La partie la plus critique d'un LLM est le réseau neuronal, qui est un modèle informatique inspiré du fonctionnement du cerveau humain. Le réseau neuronal peut apprendre ces enchâssements et leurs relations à partir des données sur lesquelles il est formé. Comme pour la plupart des applications d'apprentissage automatique, les modèles LLM ont besoin de grandes quantités de données. Généralement, plus il y a de données et de données de qualité pour l'entraînement du modèle, plus le modèle sera précis, ce qui signifie que vous aurez besoin d'une bonne méthode de gestion des données pour vos LLM.
Éléments à prendre en compte lors de l'évaluation des modèles existants
Heureusement pour les développeurs, de nombreuses options open-source pour les LLM sont actuellement disponibles, avec plusieurs options populaires qui permettent une utilisation commerciale, notamment :
- Dolly (publié par Databricks)
- Open LLaMA (Méta reproduction)
- Beaucoup, beaucoup plus
Avec une telle liste de choix, sélectionner le bon modèle LLM open-source à utiliser peut s'avérer délicat. Il est important de comprendre les ressources de calcul et de mémoire nécessaires pour un modèle LLM. La taille du modèle - par exemple, 3 milliards de paramètres d'entrée contre 7 milliards - a un impact sur la quantité de ressources dont vous aurez besoin pour exécuter et exercer le modèle. Considérez ceci par rapport à vos capacités. Par exemple, plusieurs modèles DLite ont été mis à disposition spécifiquement pour être exécutés sur des ordinateurs portables plutôt que de nécessiter des ressources cloud coûteuses.
Lors de la recherche de chaque LLM, il est important de noter comment le modèle a été formé et à quel type de tâche il est généralement destiné. Ces distinctions influenceront également votre choix. Pour planifier votre travail sur le LLM, vous devrez passer au crible les options de modèles open-source, comprendre où chaque modèle est le plus performant et anticiper les ressources que vous devrez utiliser pour chaque modèle.
Selon l'application ou le contexte dans lequel vous aurez besoin d'un LLM, vous pouvez commencer par un LLM existant ou choisir de former un LLM à partir de zéro. Avec un LLM existant, vous pouvez l'utiliser tel quel ou affiner le modèle avec des données supplémentaires représentatives de la tâche que vous avez à l'esprit.
Le choix de la meilleure approche pour vos besoins nécessite une bonne compréhension des données utilisées pour la formation des MLD.
Les types de données utilisées dans les LLM
Lorsqu'il s'agit de former un LLM, les données utilisées sont généralement textuelles. Cependant, la nature de ces données textuelles peut varier considérablement et il est essentiel de comprendre les différents types de données que l'on peut rencontrer. En général, les données LLM peuvent être classées en deux catégories : les données semi-structurées et les données non structurées. Les données structurées, qui sont des données représentées dans un ensemble de données tabulaires, ont peu de chances d'être utilisées dans les LLM.
Données semi-structurées
Les données semi-structurées sont organisées d'une manière prédéfinie et suivent un certain modèle. Cette organisation permet une recherche et une interrogation directes des données. Dans le contexte des LLM, un exemple de données semi-structurées pourrait être un corpus de texte dans lequel chaque entrée est associée à certaines étiquettes ou métadonnées. Voici quelques exemples de données semi-structurées :
- Articles d'actualité, chacun étant associé à une catégorie (sports, politique ou technologie, par exemple).
- les avis des clients, chaque avis étant associé à une note et à des informations sur le produit.
- Les messages des médias sociaux, chaque message étant associé à l'utilisateur qui l'a publié, à l'heure de publication et à d'autres métadonnées.
Dans ces cas, un LLM peut apprendre à prédire la catégorie sur la base de l'article de presse, l'évaluation sur la base du texte de l'avis, ou le sentiment d'un message sur les médias sociaux sur la base de son contenu.
Données non structurées
Les données non structurées, quant à elles, n'ont pas d'organisation ou de modèle prédéfini. Ces données sont souvent riches en texte et peuvent également contenir des dates, des chiffres et des faits, ce qui rend leur traitement et leur analyse plus compliqués. Dans le contexte des LLM, les données non structurées sont très courantes. Voici quelques exemples de données non structurées
- Livres, articles et autres contenus de longue durée
- Transcriptions d'interviews ou de podcasts
- Pages web ou documents
Sans étiquettes explicites ou étiquettes organisationnelles, les données non structurées sont plus difficiles pour la formation LLM. Cependant, elles peuvent également produire des modèles plus généraux. Par exemple, un modèle formé sur un large corpus de livres peut apprendre à générer une prose réaliste, comme c'est le cas avec GPT-3.

Nous avons vu que les données sont au cœur des LLM, mais comment ces données passent-elles de l'état brut à un format utilisable par un LLM ? Concentrons-nous sur les principaux processus impliqués.
Pipelines de données et ingestion pour les LLM
Les éléments constitutifs de l'acquisition et du traitement des données pour un LLM reposent sur les concepts de pipelines de données et d'ingestion de données.
Qu'est-ce qu'un pipeline de données ?
Les pipelines de données constituent le conduit entre les données brutes et non structurées et un LLM entièrement formé. Ils garantissent que les données sont correctement collectées, traitées et préparées, afin qu'elles soient prêtes pour les étapes de formation et de validation de votre processus de construction de LLM.
Un pipeline de données est un ensemble de processus qui déplace les données de leur source vers une destination où elles peuvent être stockées et analysées. En règle générale, il s'agit de
- Extraction de données : Les données sont extraites de leur source, qui peut être une base de données, un entrepôt de données ou même une API externe.
- Transformation des données: Les données brutes doivent être nettoyées et transformées dans un format adapté à l'analyse. La transformation comprend le traitement des valeurs manquantes, la correction des données incohérentes, la conversion des types de données ou le codage univoque des variables catégorielles.
- Chargement des données : Les données transformées sont chargées dans un système de stockage, tel qu'une base de données ou un entrepôt de données. Ces données sont alors facilement disponibles pour être utilisées dans un modèle d'apprentissage automatique.
Lorsque nous parlons d'ingestion de données, nous nous référons à l'amont de ces processus de pipeline, c'est-à-dire à l'acquisition des données et à leur préparation en vue de leur utilisation.
À quoi ressemble un pipeline de données dans le contexte d'un LLM ?
Bien qu'un pipeline de données pour un LLM puisse se superposer à la plupart des pipelines utilisés par les équipes chargées des données, les LLM posent certains défis particuliers en matière de gestion des données pour les LLM. Par exemple :
- Extraction de données : L'extraction de données pour un LLM est souvent plus complexe, plus variée et plus lourde en termes de calcul. Les sources de données pouvant être des sites web, des livres, des transcriptions ou des médias sociaux, chaque source a ses propres nuances et nécessite une approche unique.
- Transformation des données: Avec un tel éventail de sources de données LLM, chaque étape de transformation pour chaque type de données sera différente, nécessitant une logique unique pour traiter les données dans un format plus standard qu'un LLM peut utiliser pour la formation.
- Chargement des données : Dans de nombreux cas, l'étape finale du chargement des données peut nécessiter des technologies de stockage des données hors normes. Les données textuelles non structurées peuvent nécessiter l'utilisation de bases de données NoSQL, contrairement aux magasins de données relationnels utilisés par de nombreux pipelines de données.
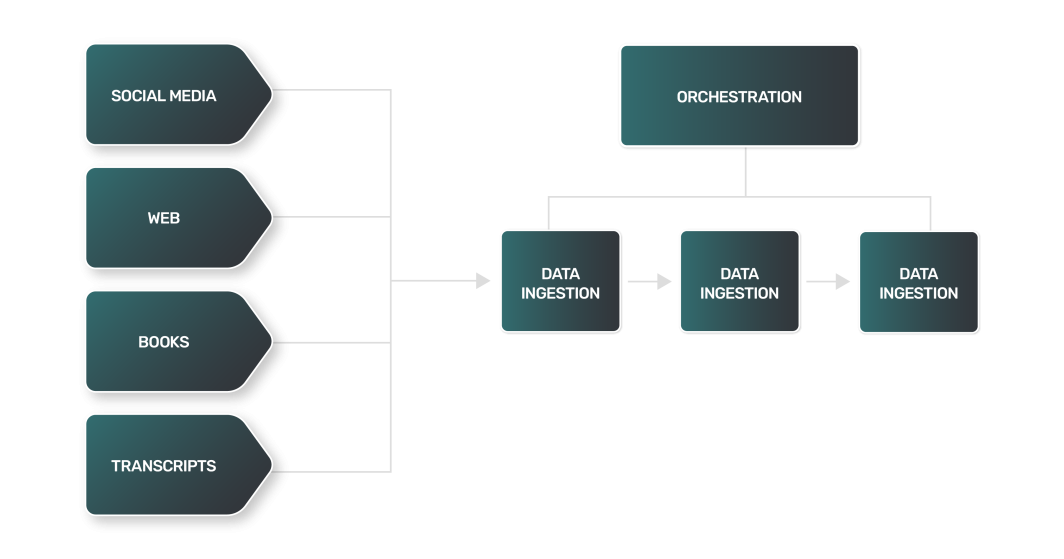
Le processus de transformation des données pour les LLM comprend des techniques similaires à celles que l'on trouve dans le traitement du langage naturel (NLP) :
- Tokenisation: Décomposition d'un texte en mots individuels ou "jetons".
- Suppression des mots vides: Élimination des mots couramment utilisés tels que "et", "le" et "est". Cependant, en fonction de la tâche pour laquelle le LLM a été formé, les mots vides peuvent être conservés afin de préserver des informations syntaxiques et sémantiques importantes.
- Lemmatisation: Réduire les mots à leur forme de base ou racine.
Comme vous pouvez l'imaginer, la combinaison de toutes ces étapes pour ingérer des quantités massives de données provenant d'un large éventail de sources peut donner lieu à un pipeline de données incroyablement compliqué et volumineux. Pour vous aider dans votre tâche, vous aurez besoin d'outils et de ressources de qualité.
Outils couramment utilisés pour l'ingestion de données
Plusieurs outils extrêmement populaires dans le domaine de l'ingénierie des données peuvent vous aider dans les processus complexes d'ingestion de données qui font partie de votre pipeline de données. Si vous construisez votre propre LLM, la majeure partie de votre temps de développement sera consacrée à la collecte, au nettoyage et au stockage des données utilisées pour la formation. Les outils qui vous aident à gérer les données pour les LLM peuvent être classés comme suit :
- Orchestration du pipeline: Plateformes permettant de surveiller et de gérer les processus de votre pipeline de données.
- Calcul: Ressources pour traiter vos données à grande échelle.
- Stockage: Bases de données pour stocker la grande quantité de données nécessaires à une formation LLM efficace.
Examinons chacun d'entre eux plus en détail.
Orchestration du pipeline
Apache Airflow est une plateforme open-source populaire pour la création programmatique, la planification et la surveillance des flux de données. Elle vous permet de créer des pipelines de données complexes grâce à son interface de codage basée sur Python, qui est à la fois polyvalente et facile à utiliser. Les tâches dans Airflow sont organisées en graphes acycliques dirigés (DAG), où chaque nœud représente une tâche et les arêtes représentent les dépendances entre les tâches.
Airflow est largement utilisé pour les opérations d'extraction, de transformation et de chargement des données, ce qui en fait un outil précieux dans le processus d'ingestion des données. Le site Marketplace de Linode propose Apache Airflow pour une installation et une utilisation faciles.
Calcul
Outre la gestion du pipeline avec des outils tels qu'Airflow, vous aurez besoin de ressources informatiques adéquates pouvant fonctionner de manière fiable à l'échelle. L'ingestion de grandes quantités de données textuelles et le traitement en aval à partir de nombreuses sources nécessitent des ressources informatiques capables d'évoluer, idéalement de manière horizontale, en fonction des besoins.
Kubernetes est un choix populaire pour l'informatique évolutive. Kubernetes apporte de la flexibilité et s'intègre bien avec de nombreux outils, notamment Airflow. En tirant parti de Kubernetes géré, vous pouvez faire tourner des ressources de calcul flexibles rapidement et simplement.
Stockage
Une base de données fait partie intégrante du processus d'ingestion des données, car elle sert de destination principale aux données ingérées après leur nettoyage et leur transformation. Différents types de bases de données peuvent être utilisés. Le choix dépend de la nature des données et des exigences spécifiques de votre cas d'utilisation :
- Les bases de données relationnelles utilisent une structure tabulaire pour stocker et représenter les données. Elles constituent un bon choix pour les données qui ont des relations claires et pour lesquelles l'intégrité des données est essentielle. Bien que votre LLM dépende de données non structurées, une base de données relationnelle comme PostgreSQL peut également fonctionner avec des types de données non structurées.
- Les bases de données NoSQL: Les bases de données NoSQL comprennent les bases de données orientées documents, qui n'utilisent pas de structure tabulaire pour stocker les données. Elles constituent un bon choix pour traiter d'importants volumes de données non structurées et offrent de hautes performances, une grande disponibilité et une grande évolutivité.
Comme alternative aux bases de données pour le stockage des données LLM, certains ingénieurs préfèrent utiliser des systèmes de fichiers distribués. Les exemples incluent AWS S3 ou Hadoop. Bien qu'un système de fichiers distribués puisse être une bonne option pour stocker de grandes quantités de données non structurées, il nécessite un effort supplémentaire pour organiser et gérer vos grands ensembles de données.
Pour les options de stockage du site Marketplace, vous trouverez PostgreSQL et MySQL gérés. Ces deux options sont faciles à mettre en place et à intégrer dans votre pipeline de données LLM.
Bien qu'il soit possible pour les petits LLM de s'entraîner avec moins de données et de s'en sortir avec des bases de données plus petites (telles qu'un seul nœud PostgreSQL), les cas d'utilisation plus lourds travailleront avec de très grandes quantités de données. Dans ces cas, vous aurez probablement besoin de quelque chose comme un cluster PostgreSQL pour supporter le volume de données avec lequel vous travaillerez, gérer les données pour les LLMs, et servir ces données de manière fiable.
Lorsque vous choisissez une base de données pour gérer les données des MLD, tenez compte de la nature des données et des exigences de votre dossier. Le type de données ingérées déterminera le type de base de données le mieux adapté à vos besoins. Les exigences de votre cas d'utilisation, telles que les performances, la disponibilité et l'évolutivité, seront également des éléments importants à prendre en compte.
L'ingestion efficace et précise des données est cruciale pour la réussite d'un LLM. Grâce à une utilisation appropriée des outils, vous pouvez mettre en place des processus d'ingestion de données fiables et efficaces pour votre pipeline, en traitant de grandes quantités de données et en veillant à ce que votre LLM dispose de ce dont il a besoin pour apprendre et fournir des résultats précis.
Pour conclure
L'essor fulgurant de la popularité des LLM a ouvert de nouvelles portes dans l'espace technologique. La technologie est facilement accessible aux développeurs, mais leur capacité à gérer les données pour les LLM et à exploiter les données pour former de nouveaux LLM ou affiner les LLM existants dictera leur succès à long terme.
Si vous commencez à travailler sur un projet LLM, vous devez comprendre les bases avant de vous lancer. Pour être le plus efficace possible, un LLM nécessite l'ingestion d'un grand volume de données non structurées, un processus qui comprend l'extraction des sources, le prétraitement, la transformation et l'importation. L'exécution de ces tâches nécessite des outils comme Airflow et Kubernetes pour l'orchestration des pipelines et des ressources informatiques évolutives. En outre, la nature non structurée des données couramment utilisées pour la formation LLM nécessite une option de stockage de données telle que PostgreSQL, qui peut être utilisée de manière fiable à l'échelle par le biais de clusters.




Commentaires (1)
Artigo muito bom para quem quer se aprofundar em LLM! Parabéns!