
 (1)")
大規模言語モデル(LLM)は、特にOpenAIの最近の開発で大流行している。LLMの魅力は、かつては人間の独占領域と考えられていた方法で人間の言語を理解し、解釈し、生成する能力にある。CoPilotのようなツールは急速に開発者の日常生活に溶け込み、ChatGPTを燃料とするアプリケーションはますます主流になりつつある。
LLMの人気は、平均的な開発者がアクセスしやすいことにも起因している。多くのオープンソースモデルが利用可能なため、LLMをベースにした何らかの問題解決策を持つ新しい技術系スタートアップが日々登場している。
データは "新しい石油"と呼ばれている。機械学習では、データはモデルの訓練、テスト、検証に使用される原材料となる。正確で信頼性が高く、ロバストなLLMを作成するためには、高品質で多様な代表的データが不可欠である。
独自のLLMを構築することは、特にデータの収集と保存に関しては困難な場合があります。大量の非構造化データを扱い、それを保存し、アクセスを管理することは、あなたが直面するかもしれない課題のほんの一部です。この記事では、こうしたデータ管理の課題を探ります。具体的には
私たちの目標は、LLMにおいてデータが果たす重要な役割を明確に理解し、ご自身のLLMプロジェクトにおいてデータを効果的に管理するための知識を身につけていただくことです。
まずは、LLMを理解するための基本的な基礎を固めよう。
LLMの仕組みと既存モデルからの選び方
高レベルでは、LLMは単語(または文)を埋め込みと呼ばれる数値表現に変換することで動作する。これらの埋め込みは、単語間の意味と関係をとらえ、モデルが言語を理解することを可能にする。例えば、LLMは "dog "と "puppy "という単語が関連していることを学習し、数値空間において、"dog "と "puppy "をより近くに配置する一方、"tree "という単語はより遠くに配置する。

LLMの最も重要な部分はニューラルネットワークであり、これは人間の脳の機能にヒントを得た計算モデルである。ニューラルネットワークは、訓練されたデータからこれらの埋め込みとその関係を学習することができる。ほとんどの機械学習アプリケーションと同様、LLMモデルには大量のデータが必要だ。一般的に、モデル学習のためのデータが多く、質の高いデータであればあるほど、モデルの精度は高くなります。つまり、LLMのデータを管理するための優れた方法が必要になります。
既存モデルを比較する際の考慮点
開発者にとっては幸いなことに、現在LLMのための多くのオープンソースオプションが利用可能であり、商業利用が可能ないくつかの人気オプションもある:
- ドリー(データブリックスより発売)
- オープンLLaMA(メタ再生産)
- もっともっとたくさん
このように豊富な選択肢の中から、適切なオープンソースのLLMモデルを選択するのは難しいことです。LLMモデルに必要な計算リソースとメモリリソースを理解することは重要です。例えば、30億の入力パラメータと70億の入力パラメータのように、モデルのサイズは、モデルの実行と演習に必要なリソースの量に影響します。自分の能力と照らし合わせて考えてみてください。例えば、いくつかのDLiteモデルは、高コストのクラウドリソースを必要とせず、ラップトップで実行できるように特別に作られています。
各LLMを調べる際には、そのモデルがどのようにトレーニングされたのか、また一般的にどのようなタスクに向けられているのかに注目することが重要だ。これらの違いも選択に影響します。LLMの作業計画を立てるには、オープンソースのモデルの選択肢を選別し、各モデルがどこで最も輝くかを理解し、各モデルに必要なリソースを予測する必要があります。
LLMを必要とするアプリケーションやコンテキストによって、既存のLLMから始めることもあれば、ゼロからLLMをトレーニングすることもあります。既存のLLMの場合、それをそのまま使うこともできますし、あなたが考えているタスクを代表する追加データでモデルを微調整することもできます。
ニーズに最適なアプローチを選択するには、LLMのトレーニングに使用されるデータをしっかりと理解する必要があります。
LLMで使用されるデータの種類
LLMをトレーニングする場合、使用されるデータは通常テキストである。しかし、このテキストデータの性質は様々であり、遭遇する可能性のある様々なタイプのデータを理解することは不可欠である。一般的に、LLMデータは半構造化データと非構造化データの2種類に分類できる。構造化データとは、表形式のデータセットで表現されたデータのことで、LLMで使用される可能性は低い。
半構造化データ
半構造化データは、あらかじめ定義された方法で整理され、一定のモデルに従っている。このような構成により、データの検索や問い合わせが容易になる。LLMの文脈では、半構造化データの例として、各エントリーに特定のタグやメタデータが関連付けられたテキスト・コーパスを挙げることができる。半構造化データの例としては、以下のようなものがある:
- ニュース記事は、それぞれカテゴリー(スポーツ、政治、テクノロジーなど)に関連している。
- 各レビューには、評価と製品情報が関連付けられています。
- ソーシャルメディアへの投稿。各投稿には、投稿したユーザー、投稿時刻、その他のメタデータが関連付けられている。
このような場合、LLMはニュース記事に基づいてカテゴリーを予測したり、レビューテキストに基づいて評価を予測したり、ソーシャルメディアへの投稿内容に基づいてその感情を予測したりする。
非構造化データ
一方、非構造化データは、事前に定義された組織やモデルがない。このデータはテキストが多く、日付、数字、事実が含まれることもあり、処理や分析がより複雑になります。LLMの文脈では、非構造化データは非常に一般的です。非構造化データの例としては、以下のようなものがある:
- 書籍、記事、その他の長編コンテンツ
- インタビューやポッドキャストからの書き起こし
- ウェブページまたは文書
明示的なラベルや組織タグがない非構造化データは、LLMの学習にとってより困難である。しかし、より一般的なモデルを得ることもできる。例えば、書籍の大規模なコーパスで学習したモデルは、GPT-3のように現実的な散文を生成することを学習するかもしれない。

データがLLMの核心であることはこれまで見てきたとおりだが、このデータはどのようにして生の状態からLLMが使用できる形式になるのだろうか?ここで焦点を移し、主要なプロセスを考えてみよう。
LLMのためのデータパイプラインと取り込み
LLMのためにデータを取得し処理するための構成要素は、データパイプラインとデータ取り込みの概念にある。
データパイプラインとは何か?
データパイプラインは、生の非構造化データと完全に訓練されたLLMの間のパイプラインを形成します。データパイプラインは、データが適切に収集、処理、準備され、LLM構築プロセスのトレーニングおよび検証段階に対応できるようにします。
データ・パイプラインとは、データをソースから保存・分析可能なデスティネーションに移動させる一連のプロセスのことである。通常、次のような処理が含まれる:
- データ抽出: データは、データベース、データウェアハウス、あるいは外部APIなどのソースから抽出される。
- データの変換:生データを洗浄し、分析に適した形式に変換する必要がある。変換には、欠損値の処理、一貫性のないデータの修正、データタイプの変換、カテゴリー変数のワンホットエンコーディングなどが含まれる。
- データのロード:変換されたデータは、データベースやデータウェアハウスなどのストレージシステムにロードされる。このデータは、機械学習モデルですぐに利用できる。
データの取り込みといえば、データの取得と利用の準備を扱うパイプライン・プロセスのフロントエンドを指す。
LLMにおけるデータ・パイプラインとは?
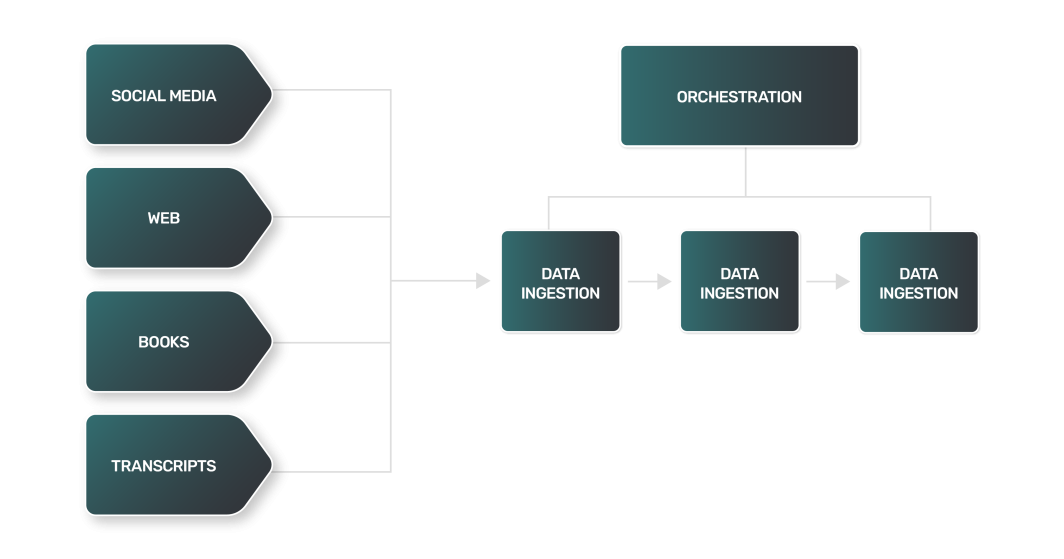
LLMのデータパイプラインは、データチームが使用するほとんどのパイプラインと一般的には重複するかもしれないが、LLMのデータ管理にはLLM特有の課題がある。例えば
- データ抽出: LLMのデータ抽出は、より複雑で多岐にわたり、計算量も多くなることが多い。データソースはウェブサイト、書籍、トランスクリプト、ソーシャルメディアであるため、それぞれのソースには独自のニュアンスがあり、独自のアプローチが必要となります。
- データ変換:LLMのデータソースは多岐にわたるため、データの種類ごとに変換ステップが異なり、LLMがトレーニングに利用できる標準的な形式にデータを処理するための独自のロジックが必要になる。
- データのロード:多くの場合、データロードの最終ステップでは、通常とは異なるデータストレージ技術が必要になる。非構造化テキストデータでは、多くのデータパイプラインで使用されているリレーショナルデータストアとは対照的に、NoSQLデータベースの使用が必要になる場合がある。
LLMのデータ変換プロセスには、自然言語処理(NLP)で見られるようなテクニックが含まれている:
- トークン化:テキストを個々の単語または「トークン」に分割すること。
- ストップワードの除去:"and"、"the"、"is "のような一般的に使用される単語の除去。ただし、LLMが訓練されたタスクによっては、重要な構文情報や意味情報を保持するために、ストップワードが保持されることもある。
- レンマタイゼーション:単語を原形または語根に還元すること。
ご想像の通り、これらのステップをすべて組み合わせて、さまざまなソースから大量のデータを取り込むと、信じられないほど複雑で大規模なデータパイプラインになります。この作業を支援するには、優れたツールとリソースが必要だ。
データ取り込みによく使われるツール
データエンジニアリング分野で非常に人気のあるいくつかのツールは、データパイプラインの一部を形成する複雑なデータ取り込みプロセスを支援することができます。独自のLLMを構築する場合、開発時間の大半はトレーニングに使用するデータの収集、クリーニング、保存に費やされるでしょう。 LLMのデータ管理を支援するツールは、以下のように分類できます:
- パイプライン・オーケストレーション:データパイプラインのプロセスを監視・管理するためのプラットフォーム。
- コンピュート:データを大規模に処理するためのリソース。
- ストレージ:効果的なLLMトレーニングに必要な大量のデータを保存するためのデータベース。
それぞれの詳細を見てみよう。
パイプライン・オーケストレーション
Apache Airflowは、データワークフローをプログラムでオーサリング、スケジューリング、モニタリングするための人気の高いオープンソースプラットフォームです。Python をベースとしたコーディングインターフェイスにより、複雑なデータパイプラインを作成することができます。Airflow のタスクは、各ノードがタスクを表し、エッジがタスク間の依存関係を表す有向 非循環グラフ(DAG)で構成されます。
Airflowは、データ抽出、変換、ロード操作に広く使用されており、データ取り込みプロセスにおける貴重なツールとなっています。LinodeのMarketplace 、Apache Airflowを提供し、セットアップと使用を容易にします。
コンピュート
Airflowのようなツールでパイプラインを管理することに加えて、大規模でも確実に実行できる適切なコンピューティングリソースが必要です。大量のテキストデータをインジェストし、多くのソースからダウンストリーム処理を実行するため、タスクには必要に応じてスケーリング可能な、理想的には水平方向にスケーリング可能なコンピューティングリソースが必要になります。
スケーラブルなコンピューティングのための人気のある選択肢のひとつがKubernetesだ。Kubernetesは柔軟性をもたらし、Airflowを含む多くのツールとうまく統合できる。マネージドKubernetesを活用することで、柔軟なコンピュートリソースを迅速かつシンプルに立ち上げることができます。
ストレージ
データベースはデータ取り込みプロセスに不可欠であり、取り込まれたデータがクリーニングされ、変換された後の主な保存先として機能する。データベースには様々な種類があります。どのタイプを使用するかは、データの性質とユースケースの特定の要件に依存します:
- リレーショナル・データベースは、表形式の構造を使ってデータを保存し、表現する。関係性が明確で、データの完全性が重要なデータに向いています。LLMは非構造化データに依存しますが、PostgreSQLのようなリレーショナル・データベースは非構造化データも扱うことができます。
- NoSQLデータベース:NoSQLデータベースには文書指向データベースがあり、データの保存に表構造を使用しない。大量の非構造化データを扱うのに適しており、高いパフォーマンス、高い可用性、容易なスケーラビリティを提供する。
LLMデータを保存するためのデータベースの代替として、分散ファイルシステムの使用を好むエンジニアもいる。例えば、AWS S3 、Hadoopなどがある。分散ファイルシステムは、大量の非構造化データを保存するのに適したオプションではあるが、大規模なデータセットを整理・管理するためには、さらなる労力が必要となる。
Marketplace のストレージ・オプションには、マネージドPostgreSQLと マネージドMySQLがある。どちらのオプションもセットアップが簡単で、LLMデータパイプラインにプラグインできます。
小規模なLLMであれば、少ないデータで学習し、小規模なデータベース(単一のPostgreSQLノードなど)で済ませることも可能ですが、より大規模なユースケースでは非常に大量のデータを扱うことになります。このようなケースでは、扱うデータ量をサポートし、LLMのデータを管理し、データを確実に提供するために、PostgreSQL Clusterのようなものが必要になるでしょう。
LLMのデータを管理するデータベースを選ぶ際には、データの性質と案件の要件を考慮してください。取り込むデータの種類によって、どの種類のデータベースがニーズに最も適しているかが決まります。また、パフォーマンス、可用性、スケーラビリティといったユースケースの要件も重要な検討事項となります。
データを効果的かつ正確に取り込むことは、LLMの成功にとって極めて重要です。ツールを適切に使用することで、パイプライン用の信頼性の高い効率的なデータ取り込みプロセスを構築し、大量のデータを処理して、LLMが学習して正確な結果を出すために必要なものを確保することができます。
まとめ
LLMの人気は急上昇しており、技術分野に新たな扉を開いている。しかし、LLMのデータを管理し、データを活用して新しいLLMを訓練したり、既存のLLMを微調整したりする能力が、長期的な成功を左右するだろう。
LLMプロジェクトに着手するなら、深みにはまる前に基本を理解しておく必要がある。LLMを最も効果的に行うには、大量の非構造化データを取り込む必要がある。このプロセスには、ソースからの抽出、前処理、変換、インポートが含まれる。これらのタスクを実行するには、パイプラインオーケストレーション用のAirflowやKubernetesのようなツールと、スケーラブルなコンピューティングリソースが必要です。さらに、LLMのトレーニングに一般的に使用されるデータの非構造化という性質から、PostgreSQLのようなデータストレージオプションが必要です。




コメント