
 (1)")
Große Sprachmodelle (Large Language Models, LLMs) sind in aller Munde, insbesondere durch die jüngsten Entwicklungen von OpenAI. Der Reiz von LLMs liegt in ihrer Fähigkeit, menschliche Sprache in einer Weise zu verstehen, zu interpretieren und zu generieren, von der man früher annahm, dass sie ausschließlich dem Menschen vorbehalten sei. Tools wie CoPilot halten schnell Einzug in den Alltag von Entwicklern, während ChatGPT-gestützte Anwendungen zunehmend zum Mainstream werden.
Die Beliebtheit von LLMs rührt auch daher, dass sie für den durchschnittlichen Entwickler zugänglich sind. Da viele Open-Source-Modelle verfügbar sind, erscheinen täglich neue Tech-Startups, die eine Art LLM-basierte Lösung für ein Problem anbieten.
Daten werden als das "neue Öl" bezeichnet. Beim maschinellen Lernen dienen Daten als Rohmaterial für das Trainieren, Testen und Validieren von Modellen. Hochwertige, vielfältige und repräsentative Daten sind für die Erstellung von LLMs, die genau, zuverlässig und robust sind, unerlässlich.
Der Aufbau eines eigenen LLM kann eine Herausforderung sein, insbesondere wenn es um die Erfassung und Speicherung von Daten geht. Der Umgang mit großen Mengen unstrukturierter Daten, ihre Speicherung und die Verwaltung des Zugriffs sind nur einige der Herausforderungen, die sich Ihnen stellen können. In diesem Beitrag werden wir diese Herausforderungen der Datenverwaltung untersuchen. Insbesondere werden wir uns damit befassen:
- Wie LLMs funktionieren und wie man aus bestehenden Modellen auswählt
- Die Arten von Daten, die in LLMs verwendet werden
- Datenpipelines und Dateneingabe für LLMs
Unser Ziel ist es, Ihnen ein klares Verständnis der kritischen Rolle zu vermitteln, die Daten in LLMs spielen, und Sie mit dem Wissen auszustatten, wie Sie Daten in Ihren eigenen LLM-Projekten effektiv verwalten können.
Lassen Sie uns zu Beginn ein grundlegendes Verständnis für LLMs schaffen.
Wie LLMs funktionieren und wie man aus bestehenden Modellen auswählt
Auf einer hohen Ebene funktioniert ein LLM durch die Umwandlung von Wörtern (oder Sätzen) in numerische Darstellungen, die sogenannten Einbettungen. Diese Einbettungen erfassen die semantische Bedeutung und die Beziehungen zwischen den Wörtern und ermöglichen es dem Modell, Sprache zu verstehen. Ein LLM würde zum Beispiel lernen, dass die Wörter "Hund" und "Welpe" miteinander verwandt sind, und würde sie in ihrem numerischen Raum näher beieinander platzieren, während das Wort "Baum" weiter entfernt wäre.

Der wichtigste Teil eines LLM ist das neuronale Netz, ein Computermodell, das von der Funktionsweise des menschlichen Gehirns inspiriert ist. Das neuronale Netz kann diese Einbettungen und ihre Beziehungen aus den Daten lernen, auf denen es trainiert wurde. Wie bei den meisten Anwendungen des maschinellen Lernens sind auch für LLM-Modelle große Mengen an Daten erforderlich. Je mehr Daten und je hochwertiger die Daten für die Modellschulung sind, desto genauer wird das Modell sein.
Überlegungen bei der Abwägung bestehender Modelle
Zum Glück für Entwickler gibt es derzeit viele Open-Source-Optionen für LLMs, darunter auch einige beliebte Optionen, die eine kommerzielle Nutzung erlauben:
- Dolly (veröffentlicht von Databricks)
- LLaMA öffnen (Meta-Reproduktion)
- Viele, viele mehr
Bei einer so umfangreichen Liste kann es schwierig sein, das richtige Open-Source-LLM-Modell zu finden. Es ist wichtig, die für ein LLM-Modell benötigten Rechen- und Speicherressourcen zu verstehen. Die Größe des Modells, z. B. 3 Milliarden Eingabeparameter im Vergleich zu 7 Milliarden, wirkt sich auf die Menge der Ressourcen aus, die Sie für die Ausführung und Anwendung des Modells benötigen. Berücksichtigen Sie dies bei Ihren Möglichkeiten. So wurden beispielsweise mehrere DLite-Modelle speziell für die Ausführung auf Laptops zur Verfügung gestellt, so dass keine teuren Cloud-Ressourcen erforderlich sind.
Bei der Untersuchung der einzelnen LLMs ist es wichtig, darauf zu achten, wie das Modell trainiert wurde und auf welche Art von Aufgabe es im Allgemeinen ausgerichtet ist. Diese Unterscheidungen werden auch Ihre Wahl beeinflussen. Bei der Planung Ihrer LLM-Arbeit müssen Sie die Open-Source-Modelloptionen durchsehen, verstehen, wo jedes Modell am besten glänzt, und die Ressourcen vorhersehen, die Sie für jedes Modell verwenden müssen.
Je nach Anwendung oder Kontext, in dem Sie ein LLM benötigen, können Sie mit einem bestehenden LLM beginnen oder ein LLM von Grund auf trainieren. Bei einem vorhandenen LLM können Sie es so verwenden, wie es ist, oder Sie können das Modell mit zusätzlichen Daten, die repräsentativ für die von Ihnen geplante Aufgabe sind, feinabstimmen.
Die Wahl des besten Ansatzes für Ihre Bedürfnisse erfordert ein umfassendes Verständnis der für die Ausbildung von LLMs verwendeten Daten.
Die Arten von Daten, die in LLMs verwendet werden
Wenn es um die Ausbildung eines LLM geht, werden in der Regel Textdaten verwendet. Die Art dieser Textdaten kann jedoch sehr unterschiedlich sein, und es ist wichtig, die verschiedenen Arten von Daten zu verstehen, auf die man treffen kann. Im Allgemeinen können LLM-Daten in zwei Typen unterteilt werden: halbstrukturierte und unstrukturierte Daten. Strukturierte Daten, d. h. Daten, die in einem tabellarischen Datensatz dargestellt sind, werden wahrscheinlich nicht in LLMs verwendet.
Semi-Strukturierte Daten
Halbstrukturierte Daten sind in einer vordefinierten Weise organisiert und folgen einem bestimmten Modell. Diese Organisation ermöglicht eine unkomplizierte Suche und Abfrage der Daten. Im Zusammenhang mit LLMs könnte ein Beispiel für halbstrukturierte Daten ein Textkorpus sein, in dem jeder Eintrag mit bestimmten Tags oder Metadaten verknüpft ist. Beispiele für halbstrukturierte Daten sind:
- Nachrichtenartikel, die jeweils einer Kategorie zugeordnet sind (z. B. Sport, Politik oder Technik).
- Kundenrezensionen, wobei jede Rezension mit einer Bewertung und Produktinformationen verbunden ist.
- Beiträge in sozialen Medien, wobei jeder Beitrag mit dem Benutzer, der ihn gepostet hat, dem Zeitpunkt des Postings und anderen Metadaten verknüpft ist.
In diesen Fällen könnte ein LLM lernen, die Kategorie auf der Grundlage des Nachrichtenartikels, die Bewertung auf der Grundlage des Rezensionstextes oder die Stimmung eines Beitrags in sozialen Medien auf der Grundlage seines Inhalts vorherzusagen.
Unstrukturierte Daten
Bei unstrukturierten Daten hingegen fehlt eine vordefinierte Organisation oder ein Modell. Diese Daten sind oft textlastig und können auch Daten, Zahlen und Fakten enthalten, was ihre Verarbeitung und Analyse erschwert. Im Zusammenhang mit LLMs sind unstrukturierte Daten sehr verbreitet. Beispiele für unstrukturierte Daten sind:
- Bücher, Artikel und andere Langform-Inhalte
- Abschriften von Interviews oder Podcasts
- Web-Seiten oder Dokumente
Ohne explizite Kennzeichnungen oder organisatorische Tags sind unstrukturierte Daten eine größere Herausforderung für das LLM-Training. Sie können jedoch auch allgemeinere Modelle hervorbringen. Ein Modell, das auf einem großen Buchkorpus trainiert wurde, könnte beispielsweise lernen, realistische Prosa zu erzeugen, wie es bei GPT-3 der Fall ist.

Wir haben gesehen, dass Daten das Herzstück von LLMs sind, aber wie kommen diese Daten von ihrem Rohzustand in ein Format, das ein LLM nutzen kann? Lassen Sie uns den Fokus auf die wichtigsten beteiligten Prozesse richten.
Datenpipelines und Dateneingabe für LLMs
Die Bausteine für die Beschaffung und Verarbeitung von Daten für ein LLM liegen in den Konzepten der Datenpipelines und der Dateneingabe.
Was ist eine Datenpipeline?
Datenpipelines bilden die Verbindung zwischen rohen, unstrukturierten Daten und einem vollständig trainierten LLM. Sie stellen sicher, dass die Daten ordnungsgemäß erfasst, verarbeitet und aufbereitet werden, sodass sie für die Trainings- und Validierungsphasen Ihres LLM-Erstellungsprozesses bereit sind.
Eine Datenpipeline ist eine Reihe von Prozessen, die Daten von ihrer Quelle zu einem Zielort transportieren, wo sie gespeichert und analysiert werden können. Typischerweise beinhaltet dies:
- Datenextraktion: Die Daten werden aus ihrer Quelle extrahiert, bei der es sich um eine Datenbank, ein Data Warehouse oder sogar eine externe API handeln kann.
- Datenumwandlung: Die Rohdaten müssen bereinigt und in ein Format umgewandelt werden, das für die Analyse geeignet ist. Die Transformation umfasst den Umgang mit fehlenden Werten, die Korrektur inkonsistenter Daten, die Konvertierung von Datentypen oder die One-Hot-Codierung kategorialer Variablen.
- Laden von Daten: Die umgewandelten Daten werden in ein Speichersystem, z. B. eine Datenbank oder ein Data Warehouse, geladen. Diese Daten stehen dann für die Verwendung in einem maschinellen Lernmodell bereit.
Wenn wir von Datenaufnahme sprechen, beziehen wir uns auf das vordere Ende dieser Pipeline-Prozesse, das sich mit der Erfassung von Daten und ihrer Aufbereitung für die Verwendung befasst.
Wie sieht eine Datenpipeline im Rahmen eines LLM aus?
Während sich eine Datenpipeline für ein LLM im Allgemeinen mit den meisten Pipelines überschneiden kann, die von Datenteams verwendet werden, stellen LLMs bestimmte einzigartige Herausforderungen an die Datenverwaltung für LLMs. Zum Beispiel:
- Datenextraktion: Die Datenextraktion für einen LLM ist oft komplexer, vielfältiger und rechenintensiver. Da es sich bei den Datenquellen um Websites, Bücher, Transkripte oder soziale Medien handeln kann, hat jede Quelle ihre eigenen Nuancen und erfordert einen eigenen Ansatz.
- Datenumwandlung: Bei einem so breiten Spektrum an LLM-Datenquellen ist jeder Transformationsschritt für jeden Datentyp anders und erfordert eine eigene Logik, um die Daten in ein Standardformat zu bringen, das ein LLM für das Training nutzen kann.
- Laden von Daten: In vielen Fällen kann der abschließende Schritt des Datenladens Technologien zur Datenspeicherung erfordern, die nicht der Norm entsprechen. Unstrukturierte Textdaten können die Verwendung von NoSQL-Datenbanken erfordern, im Gegensatz zu den relationalen Datenspeichern, die von vielen Datenpipelines verwendet werden.
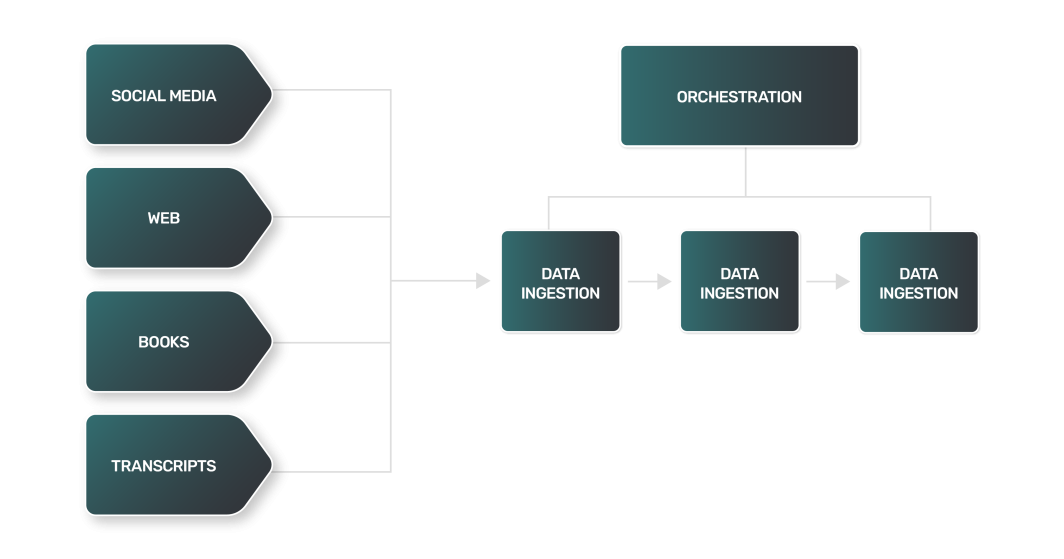
Der Datenumwandlungsprozess für LLMs umfasst Techniken, die denen der natürlichen Sprachverarbeitung (NLP) ähneln:
- Tokenisierung: Zerlegen von Text in einzelne Wörter oder "Token".
- Entfernung von Stoppwörtern: Eliminierung von häufig verwendeten Wörtern wie "und", "der" und "ist". Je nach der Aufgabe, für die das LLM trainiert wurde, können Stoppwörter jedoch beibehalten werden, um wichtige syntaktische und semantische Informationen zu erhalten.
- Lemmatisierung: Reduktion von Wörtern auf ihre Grund- oder Stammform.
Wie Sie sich vorstellen können, kann die Kombination all dieser Schritte zur Aufnahme großer Datenmengen aus einer Vielzahl von Quellen zu einer unglaublich komplizierten und umfangreichen Datenpipeline führen. Um Sie bei Ihrer Aufgabe zu unterstützen, benötigen Sie gute Tools und Ressourcen.
Gängige Tools für die Datenübernahme
Mehrere äußerst beliebte Tools aus dem Bereich der Datentechnik können Sie bei den komplexen Dateneingabeprozessen unterstützen, die Teil Ihrer Datenpipeline sind. Wenn Sie Ihr eigenes LLM erstellen, werden Sie den Großteil Ihrer Entwicklungszeit damit verbringen, die für das Training verwendeten Daten zu sammeln, zu bereinigen und zu speichern. Tools, die Sie bei der Datenverwaltung für LLMs unterstützen, können wie folgt kategorisiert werden:
- Pipeline-Orchestrierung: Plattformen zur Überwachung und Verwaltung der Prozesse in Ihrer Datenpipeline.
- Berechnen: Ressourcen zur Verarbeitung Ihrer Daten in großem Umfang.
- Speicherung: Datenbanken zur Speicherung der großen Datenmengen, die für eine effektive LLM-Ausbildung erforderlich sind.
Schauen wir uns jedes dieser Elemente genauer an.
Pipeline-Orchestrierung
Apache Airflow ist eine beliebte Open-Source-Plattform für die programmatische Erstellung, Planung und Überwachung von Daten-Workflows. Sie ermöglicht die Erstellung komplexer Datenpipelines mit ihrer Python-basierten Codierungsschnittstelle, die sowohl vielseitig als auch einfach zu handhaben ist. Die Aufgaben in Airflow sind in gerichteten azyklischen Graphen (Directed Acyclic Graphs, DAGs) organisiert, wobei jeder Knoten eine Aufgabe darstellt und die Kanten Abhängigkeiten zwischen den Aufgaben repräsentieren.
Airflow wird häufig für Datenextraktion, -umwandlung und -ladevorgänge verwendet und ist damit ein wertvolles Werkzeug für den Dateneingabeprozess. Linode's Marketplace bietet Apache Airflow für eine einfache Einrichtung und Nutzung.
Computing
Zusätzlich zur Pipeline-Verwaltung mit Tools wie Airflow benötigen Sie angemessene Rechenressourcen, die zuverlässig und skalierbar arbeiten können. Da Sie große Mengen an Textdaten einlesen und eine nachgelagerte Verarbeitung aus vielen Quellen durchführen, benötigen Sie Rechenressourcen, die je nach Bedarf skaliert werden können - idealerweise horizontal.
Eine beliebte Wahl für skalierbares Computing ist Kubernetes. Kubernetes bietet Flexibilität und lässt sich gut mit vielen Tools, einschließlich Airflow, integrieren. Durch die Nutzung von verwaltetem Kubernetes können Sie schnell und einfach flexible Rechenressourcen einrichten.
Speicher
Eine Datenbank ist ein wesentlicher Bestandteil des Datenerfassungsprozesses und dient als primäres Ziel für die erfassten Daten, nachdem sie bereinigt und umgewandelt wurden. Es können verschiedene Arten von Datenbanken verwendet werden. Welcher Typ zu verwenden ist, hängt von der Art der Daten und den spezifischen Anforderungen Ihres Anwendungsfalls ab:
- Relationale Datenbanken verwenden eine tabellarische Struktur zur Speicherung und Darstellung von Daten. Sie sind eine gute Wahl für Daten, die klare Beziehungen aufweisen und bei denen die Datenintegrität entscheidend ist. Obwohl Ihr LLM von unstrukturierten Daten abhängen wird, kann eine relationale Datenbank wie PostgreSQL auch mit unstrukturierten Datentypen arbeiten.
- NoSQL-Datenbanken: Zu den NoSQL-Datenbanken gehören dokumentenorientierte Datenbanken, die keine tabellarische Struktur zur Speicherung von Daten verwenden. Sie sind eine gute Wahl für die Verarbeitung großer Mengen unstrukturierter Daten und bieten hohe Leistung, hohe Verfügbarkeit und einfache Skalierbarkeit.
Als Alternative zu Datenbanken für die Speicherung von LLM-Daten bevorzugen einige Ingenieure die Verwendung von verteilten Dateisystemen. Beispiele hierfür sind AWS S3 oder Hadoop. Obwohl ein verteiltes Dateisystem eine gute Option für die Speicherung großer Mengen unstrukturierter Daten sein kann, erfordert es zusätzlichen Aufwand für die Organisation und Verwaltung Ihrer großen Datensätze.
Als Speicheroptionen finden Sie unter Marketplaceverwaltete PostgreSQL- und MySQL-Speicher. Beide Optionen sind einfach einzurichten und in Ihre LLM-Datenpipeline zu integrieren.
Während es für kleinere LLMs möglich ist, mit weniger Daten zu trainieren und mit kleineren Datenbanken auszukommen (z. B. einem einzelnen PostgreSQL-Knoten), werden schwerere Anwendungsfälle mit sehr großen Datenmengen arbeiten. In diesen Fällen benötigen Sie wahrscheinlich so etwas wie einen PostgreSQL-Cluster, um das Datenvolumen, mit dem Sie arbeiten werden, zu unterstützen, die Daten für LLMs zu verwalten und diese Daten zuverlässig bereitzustellen.
Bei der Auswahl einer Datenbank zur Verwaltung von Daten für LLMs sollten Sie die Art der Daten und die Anforderungen Ihres Falles berücksichtigen. Die Art der Daten, die Sie einlesen, bestimmt, welche Art von Datenbank für Ihre Bedürfnisse am besten geeignet ist. Die Anforderungen Ihres Anwendungsfalls - wie Leistung, Verfügbarkeit und Skalierbarkeit - sind ebenfalls wichtige Überlegungen.
Eine effektive und genaue Dateneingabe ist für den Erfolg eines LLM entscheidend. Mit dem richtigen Einsatz der Tools können Sie zuverlässige und effiziente Dateningestionsprozesse für Ihre Pipeline aufbauen, große Datenmengen verarbeiten und sicherstellen, dass Ihr LLM über das verfügt, was es braucht, um zu lernen und genaue Ergebnisse zu liefern.
Einpacken
Der kometenhafte Anstieg der Popularität von LLMs hat neue Türen in der Technologiebranche geöffnet. Die Technologie ist für Entwickler leicht zugänglich, aber ihre Fähigkeit, Daten für LLMs zu verwalten und Daten zu nutzen, um neue LLMs zu trainieren oder bestehende zu optimieren, wird ihren langfristigen Erfolg bestimmen.
Wenn Sie mit der Arbeit an einem LLM-Projekt beginnen, müssen Sie die Grundlagen verstehen, bevor Sie sich ins kalte Wasser stürzen. Um möglichst effektiv zu sein, erfordert ein LLM die Aufnahme einer großen Menge unstrukturierter Daten, ein Prozess, der die Extraktion aus Quellen, die Vorverarbeitung, die Transformation und den Import umfasst. Für die Durchführung dieser Aufgaben sind Tools wie Airflow und Kubernetes für die Pipeline-Orchestrierung und skalierbare Rechenressourcen erforderlich. Darüber hinaus erfordert die unstrukturierte Natur der Daten, die üblicherweise für LLM-Schulungen verwendet werden, eine Datenspeicheroption wie PostgreSQL, die durch Cluster zuverlässig in großem Umfang genutzt werden kann.




Kommentare