
 (1)")
Os modelos de linguagem ampla (LLMs) estão na moda, especialmente com os recentes desenvolvimentos da OpenAI. O fascínio dos LLMs vem de sua capacidade de entender, interpretar e gerar a linguagem humana de uma forma que antes se pensava ser de domínio exclusivo dos seres humanos. Ferramentas como o CoPilot estão se integrando rapidamente à vida cotidiana dos desenvolvedores, enquanto os aplicativos alimentados por ChatGPT estão se tornando cada vez mais comuns.
A popularidade dos LLMs também decorre de sua acessibilidade para o desenvolvedor comum. Com muitos modelos de código aberto disponíveis, novas startups de tecnologia aparecem diariamente com algum tipo de solução baseada em LLM para um problema.
Os dados são chamados de "onovo petróleo". No aprendizado de máquina, os dados são a matéria-prima usada para treinar, testar e validar modelos. Dados de alta qualidade, diversificados e representativos são essenciais para a criação de LLMs precisos, confiáveis e robustos.
Criar seu próprio LLM pode ser um desafio, especialmente quando se trata de coletar e armazenar dados. Lidar com grandes volumes de dados não estruturados, além de armazená-los e gerenciar o acesso, são apenas alguns dos desafios que você pode enfrentar. Nesta postagem, exploraremos esses desafios de gerenciamento de dados. Especificamente, examinaremos:
- Como os LLMs funcionam e como selecionar entre os modelos existentes
- Os tipos de dados usados nos LLMs
- Pipelines de dados e ingestão para LLMs
Nosso objetivo é oferecer a você uma compreensão clara do papel fundamental que os dados desempenham nos LLMs, equipando-o com o conhecimento necessário para gerenciar os dados de forma eficaz em seus próprios projetos de LLM.
Para começar, vamos estabelecer uma base básica de entendimento para os LLMs.
Como funcionam os LLMs e como selecionar entre os modelos existentes
Em um nível mais alto, um LLM funciona convertendo palavras (ou frases) em representações numéricas chamadas de embeddings. Esses embeddings capturam o significado semântico e as relações entre as palavras, permitindo que o modelo compreenda a linguagem. Por exemplo, um LLM aprenderia que as palavras "cachorro" e "filhote" estão relacionadas e as colocaria mais próximas em seu espaço numérico, enquanto a palavra "árvore" estaria mais distante.

A parte mais importante de um LLM é a rede neural, que é um modelo de computação inspirado no funcionamento do cérebro humano. A rede neural pode aprender essas incorporações e suas relações a partir dos dados em que é treinada. Como na maioria dos aplicativos de aprendizado de máquina, os modelos LLM precisam de grandes quantidades de dados. Normalmente, com mais dados e dados de maior qualidade para o treinamento do modelo, mais preciso será o modelo, o que significa que você precisará de um bom método para gerenciar os dados para seus LLMs.
Considerações ao avaliar os modelos existentes
Felizmente para os desenvolvedores, muitas opções de código aberto para LLMs estão disponíveis atualmente, com várias opções populares que permitem o uso comercial, incluindo:
- Dolly (lançado pela Databricks)
- Open LLaMA (Meta reprodução)
- Muitos, muitos mais
Com uma lista tão extensa para escolher, selecionar o modelo de LLM de código aberto correto a ser usado pode ser complicado. É importante entender os recursos de computação e memória necessários para um modelo LLM. O tamanho do modelo - por exemplo, 3 bilhões de parâmetros de entrada versus 7 bilhões - afeta a quantidade de recursos necessários para executar e exercitar o modelo. Considere isso em relação aos seus recursos. Por exemplo, vários modelos DLite foram disponibilizados especificamente para serem executados em laptops, em vez de exigirem recursos de nuvem de alto custo.
Ao pesquisar cada LLM, é importante observar como o modelo foi treinado e para que tipo de tarefa ele é geralmente voltado. Essas distinções também afetarão sua escolha. O planejamento do seu trabalho de LLM envolverá a análise das opções de modelos de código aberto, a compreensão de onde cada modelo se destaca melhor e a previsão dos recursos que você precisará usar para cada modelo.
Dependendo do aplicativo ou do contexto em que você precisará de um LLM, você pode começar com um LLM existente ou pode optar por treinar um LLM do zero. Com um LLM existente, você pode usá-lo como está ou pode ajustar o modelo com dados adicionais que sejam representativos da tarefa que você tem em mente.
Para escolher a melhor abordagem para suas necessidades, é preciso entender bem os dados usados para treinar LLMs.
Os tipos de dados usados nos LLMs
Quando se trata de treinar um LLM, os dados usados geralmente são textuais. Entretanto, a natureza desses dados textuais pode variar muito, e é essencial compreender os diferentes tipos de dados que podem ser encontrados. Em geral, os dados de LLM podem ser categorizados em dois tipos: dados semiestruturados e não estruturados. Os dados estruturados, que são dados representados em um conjunto de dados tabulares, provavelmente não serão usados em LLMs.
Dados semiestruturados
Os dados semiestruturados são organizados de alguma maneira predefinida e seguem um determinado modelo. Essa organização permite a busca e a consulta diretas dos dados. No contexto dos LLMs, um exemplo de dados semiestruturados pode ser um corpus de texto no qual cada entrada está associada a determinadas tags ou metadados. Exemplos de dados semiestruturados incluem:
- Artigos de notícias, cada um associado a uma categoria (como esportes, política ou tecnologia).
- Avaliações de clientes, com cada avaliação associada a uma classificação e informações sobre o produto.
- Postagens em mídias sociais, com cada postagem associada ao usuário que fez a postagem, o horário da postagem e outros metadados.
Nesses casos, um LLM pode aprender a prever a categoria com base no artigo de notícias, a classificação com base no texto da avaliação ou o sentimento de uma publicação de mídia social com base em seu conteúdo.
Dados não estruturados
Os dados não estruturados, por outro lado, não têm uma organização ou um modelo predefinido. Esses dados costumam ter muito texto e também podem conter datas, números e fatos, o que torna o processamento e a análise mais complicados. No contexto dos LLMs, os dados não estruturados são muito comuns. Exemplos de dados não estruturados incluem:
- Livros, artigos e outros conteúdos longos
- Transcrições de entrevistas ou podcasts
- Páginas ou documentos da Web
Sem rótulos explícitos ou etiquetas organizacionais, os dados não estruturados são mais desafiadores para o treinamento do LLM. No entanto, eles também podem gerar modelos mais gerais. Por exemplo, um modelo treinado em um grande corpus de livros pode aprender a gerar prosa realista, como é o caso do GPT-3.

Vimos que os dados estão no centro dos LLMs, mas como esses dados passam de seu estado bruto para um formato que um LLM pode usar? Vamos mudar nosso foco para considerar os principais processos envolvidos.
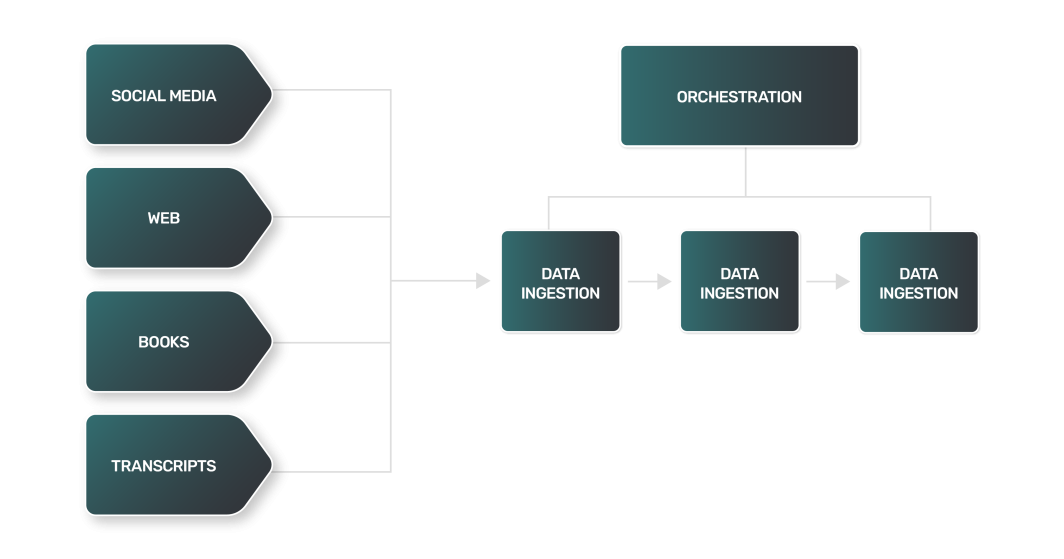
Pipelines de dados e ingestão para LLMs
Os blocos de construção para aquisição e processamento de dados para um LLM estão nos conceitos de pipelines de dados e ingestão de dados.
O que é um pipeline de dados?
Os pipelines de dados formam o canal entre os dados brutos e não estruturados e um LLM totalmente treinado. Eles garantem que os dados sejam coletados, processados e preparados adequadamente, tornando-os prontos para os estágios de treinamento e validação do processo de criação do LLM.
Um pipeline de dados é um conjunto de processos que move os dados de sua origem para um destino onde podem ser armazenados e analisados. Normalmente, isso envolve:
- Extração de dados: Os dados são extraídos de sua fonte, que pode ser um banco de dados, um data warehouse ou até mesmo uma API externa.
- Transformação de dados: Os dados brutos precisam ser limpos e transformados em um formato adequado para análise. A transformação inclui o tratamento de valores ausentes, a correção de dados inconsistentes, a conversão de tipos de dados ou a codificação de variáveis categóricas em um único ponto.
- Carregamento de dados: Os dados transformados são carregados em um sistema de armazenamento, como um banco de dados ou um data warehouse. Esses dados ficam então prontamente disponíveis para uso em um modelo de aprendizado de máquina.
Quando falamos de ingestão de dados, estamos nos referindo ao front-end desses processos de pipeline, lidando com a aquisição de dados e sua preparação para uso.
Como é um pipeline de dados no contexto de um LLM?
Embora um pipeline de dados para um LLM possa se sobrepor, em geral, à maioria dos pipelines usados pelas equipes de dados, os LLMs apresentam alguns desafios exclusivos para o gerenciamento de dados para LLMs. Por exemplo:
- Extração de dados: A extração de dados para um LLM costuma ser mais complexa, variada e pesada em termos de computação. Como as fontes de dados podem ser sites, livros, transcrições ou mídias sociais, cada fonte tem suas próprias nuances e exige uma abordagem exclusiva.
- Transformação de dados: Com uma variedade tão grande de fontes de dados de LLM, cada etapa de transformação para cada tipo de dados será diferente, exigindo uma lógica exclusiva para processar os dados em um formato mais padrão que um LLM possa consumir para treinamento.
- Carregamento de dados: Em muitos casos, a etapa final do carregamento de dados pode exigir tecnologias de armazenamento de dados fora do padrão. Dados de texto não estruturados podem exigir o uso de bancos de dados NoSQL, em contraste com os armazenamentos de dados relacionais usados por muitos pipelines de dados.
O processo de transformação de dados para LLMs inclui técnicas semelhantes às encontradas no processamento de linguagem natural (NLP):
- Tokenização: Dividir o texto em palavras individuais ou "tokens".
- Remoção de palavras de parada: Eliminação de palavras comumente usadas, como "e", "o" e "é". No entanto, dependendo da tarefa para a qual o LLM foi treinado, as palavras de parada podem ser mantidas para preservar informações sintáticas e semânticas importantes.
- Lemmatização: Redução das palavras à sua forma básica ou raiz.
Como você pode imaginar, a combinação de todas essas etapas para ingerir grandes quantidades de dados de uma ampla variedade de fontes pode resultar em um pipeline de dados incrivelmente complicado e grande. Para ajudá-lo em sua tarefa, você precisará de boas ferramentas e recursos.
Ferramentas comuns usadas para ingestão de dados
Várias ferramentas extremamente populares no espaço da engenharia de dados podem ajudá-lo com os complexos processos de ingestão de dados que fazem parte do seu pipeline de dados. Se você estiver criando seu próprio LLM, a maior parte do tempo de desenvolvimento será gasta na coleta, limpeza e armazenamento dos dados usados para treinamento. As ferramentas que o ajudam a gerenciar dados para LLMs podem ser categorizadas da seguinte forma:
- Orquestração de pipeline: Plataformas para monitorar e gerenciar os processos em seu pipeline de dados.
- Computação: Recursos para processar seus dados em escala.
- Armazenamento: Bancos de dados para armazenar a grande quantidade de dados necessários para um treinamento eficaz em LLM.
Vamos dar uma olhada em cada um deles com mais detalhes.
Orquestração de pipeline
Apache O Airflow é uma plataforma popular e de código aberto para criar, agendar e monitorar fluxos de trabalho de dados de forma programática. Ele permite que você crie pipelines de dados complexos com sua interface de codificação baseada em Python, que é versátil e fácil de trabalhar. As tarefas no Airflow são organizadas em gráficos acíclicos direcionados (DAGs), em que cada nó representa uma tarefa e as bordas representam as dependências entre as tarefas.
O Airflow é amplamente utilizado para operações de extração, transformação e carregamento de dados, o que o torna uma ferramenta valiosa no processo de ingestão de dados. O site Marketplace da Linode oferece o Apache Airflow para facilitar a configuração e o uso.
Computação
Além do gerenciamento de pipeline com ferramentas como o Airflow, você precisará de recursos de computação adequados que possam ser executados de forma confiável em escala. À medida que você ingere grandes quantidades de dados textuais e realiza o processamento downstream de muitas fontes, sua tarefa exigirá recursos de computação que possam ser dimensionados - idealmente, de forma horizontal - conforme necessário.
Uma opção popular para computação dimensionável é o Kubernetes. O Kubernetes traz flexibilidade e se integra bem a muitas ferramentas, incluindo o Airflow. Ao aproveitar o Kubernetes gerenciado, você pode ativar recursos de computação flexíveis de forma rápida e simples.
Armazenamento
Um banco de dados é parte integrante do processo de ingestão de dados, servindo como o principal destino dos dados ingeridos depois de limpos e transformados. Vários tipos de bancos de dados podem ser empregados. O tipo a ser usado depende da natureza dos dados e dos requisitos específicos de seu caso de uso:
- Os bancos de dados relacionais usam uma estrutura tabular para armazenar e representar dados. Eles são uma boa opção para dados que têm relações claras e onde a integridade dos dados é fundamental. Embora seu LLM dependa de dados não estruturados, um banco de dados relacional como o PostgreSQL também pode trabalhar com tipos de dados não estruturados.
- Bancos de dados NoSQL: Os bancos de dados NoSQL incluem bancos de dados orientados a documentos, que não usam uma estrutura tabular para armazenar dados. Eles são uma boa opção para lidar com grandes volumes de dados não estruturados, proporcionando alto desempenho, alta disponibilidade e fácil escalabilidade.
Como alternativa aos bancos de dados para armazenamento de dados do LLM, alguns engenheiros preferem usar sistemas de arquivos distribuídos. Os exemplos incluem AWS S3 ou Hadoop. Embora um sistema de arquivos distribuídos possa ser uma boa opção para armazenar grandes quantidades de dados não estruturados, ele exige um esforço adicional para organizar e gerenciar seus grandes conjuntos de dados.
Para opções de armazenamento do site Marketplace, você encontrará o PostgreSQL gerenciado e o MySQL gerenciado. Ambas as opções são fáceis de configurar e conectar ao pipeline de dados do LLM.
Embora seja possível que LLMs menores treinem com menos dados e consigam trabalhar com bancos de dados menores (como um único nó do PostgreSQL), os casos de uso mais pesados trabalharão com quantidades muito grandes de dados. Nesses casos, você provavelmente precisará de algo como um cluster PostgreSQL para suportar o volume de dados com o qual trabalhará, gerenciar dados para LLMs e fornecer esses dados de forma confiável.
Ao escolher um banco de dados para gerenciar dados para LLMs, considere a natureza dos dados e os requisitos do seu caso. O tipo de dados que você ingere determinará qual tipo de banco de dados é mais adequado às suas necessidades. Os requisitos do seu caso de uso - como desempenho, disponibilidade e escalabilidade - também serão considerações importantes.
A ingestão de dados de forma eficaz e precisa é fundamental para o sucesso de um LLM. Com o uso adequado das ferramentas, você pode criar processos de ingestão de dados confiáveis e eficientes para o seu pipeline, lidando com grandes quantidades de dados e garantindo que o LLM tenha o que precisa para aprender e fornecer resultados precisos.
Para encerrar
O aumento meteórico da popularidade dos LLMs abriu novas portas no espaço tecnológico. A tecnologia está prontamente acessível aos desenvolvedores, mas sua capacidade de gerenciar dados para LLMs e aproveitar os dados para treinar novos LLMs ou ajustar os existentes ditará seu sucesso a longo prazo.
Se você está começando a trabalhar em um projeto de LLM, precisa entender os conceitos básicos antes de se aprofundar no assunto. Para ser mais eficaz, um LLM requer a ingestão de um grande volume de dados não estruturados, um processo que inclui extração de fontes, pré-processamento, transformação e importação. A execução dessas tarefas requer ferramentas como Airflow e Kubernetes para orquestração de pipeline e recursos de computação dimensionáveis. Além disso, a natureza não estruturada dos dados comumente usados para o treinamento do LLM exige uma opção de armazenamento de dados como o PostgreSQL, que pode ser usado de forma confiável em escala por meio de clusters.




Comentários