

Nous avons récemment publié Flow-IPC - une boîte à outils de communication interprocessus en C++ - en tant que source ouverte sous les licences Apache 2.0 et MIT. Flow-IPC sera utile pour les projets C++ qui transmettent des données entre les processus d'application et qui doivent atteindre une latence proche de zéro sans compromettre la simplicité et la réutilisation du code.
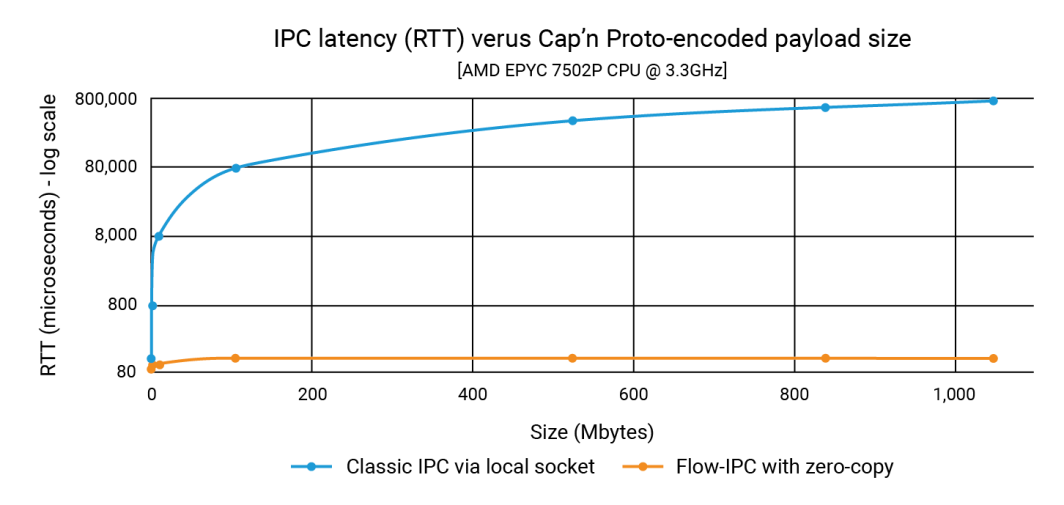
Dans cette annonce, nous avons montré que Flow-IPC peut transmettre des charges utiles de structures de données d'une taille de 1 Go aussi rapidement qu'une charge utile de 100 Ko, et ce en moins de 100 microsecondes. Avec l'IPC classique, la latence dépend de la taille de la charge utile et peut atteindre une seconde. L'amélioration peut donc atteindre trois ou quatre ordres de grandeur.
Dans ce billet, nous montrons le code source qui a produit ces chiffres. Notre exemple, centré sur l'intégration de Cap'n Proto, montre que Flow-IPC est à la fois rapide et facile à utiliser. (Notez que le Flow-IPC API est complet en ce sens qu'il prend en charge la transmission de divers types de charges utiles, mais la transmission de charges utiles basée sur Cap'n Proto est une fonctionnalité spécifique). Cap'n Proto est un projet open source non affilié à Akamai dont l'utilisation est soumise à la licence, à la date de publication de ce blog, qui se trouve ici.
Qu'est-ce qui est inclus ?
Flow-IPC est une bibliothèque dotée d'une interface extensible C++17 API. Elle est hébergé sur GitHub avec une documentation complète, des tests automatisés et des démonstrations, ainsi qu'un pipeline CI. L'exemple que nous explorons ci-dessous est le perf_demo l'application de test. Flow-IPC prend actuellement en charge Linux fonctionnant sur x86-64. Nous prévoyons d'étendre cette prise en charge à macOS et ARM64, puis à Windows et à d'autres variantes de systèmes d'exploitation en fonction de la demande. Vous êtes Bienvenue à la contribution et le port.
Le Flow-IPC API s'inscrit dans l'esprit de la bibliothèque standard C++ et de Boost, en se concentrant sur l'intégration de divers concepts et de leurs implémentations de manière modulaire. Il est conçu pour être extensible. Notre pipeline CI teste une gamme de versions de compilateurs GCC et Clang et de configurations de construction, y compris le durcissement via des assainisseurs de temps d'exécution : ASAN (contre l'utilisation abusive de la mémoire), TSAN (contre les conditions de course) et UBSAN (contre divers comportements indéfinis).
Pour l'instant, Flow-IPC est destiné à la communication locale, c'est-à-dire qu'il franchit les limites du processus mais pas celles de la machine. Cependant, sa conception étant extensible, l'étendre à l'IPC en réseau est une prochaine étape naturelle. Nous pensons que l'utilisation de l'accès direct à la mémoire à distance (RDMA) offre une possibilité intrigante pour des performances LAN ultra-rapides.
Qui doit l'utiliser ?
Flow-IPC est une boîte à outils pragmatique de communication interprocessus. Lors de sa conception, nous avons adopté le point de vue du développeur de systèmes C++ moderne, en l'adaptant spécifiquement aux tâches de communication interprocessus auxquelles il est régulièrement confronté, en particulier dans le cadre du développement d'applications serveur. Beaucoup d'entre nous ont dû mettre au point un socket de domaine Unix, un named-pipe ou un protocole local basé sur HTTP pour transmettre quelque chose d'un processus à un autre. Parfois, pour éviter la copie qu'impliquent de telles solutions, on peut se tourner vers la mémoire partagée (SHM), une technique notoirement délicate et difficile à réutiliser. Flow-IPC peut aider tout développeur C++ confronté à de telles tâches, qu'elles soient courantes ou avancées.
Les points forts sont les suivants :
- Intégration de Cap'n Proto : Les outils de sérialisation sur place basés sur des schémas, comme Cap'n Proto, qui est le meilleur de sa catégorie, sont très utiles pour le travail interprocessus. Toutefois, sans Flow-IPC, il faudrait toujours copier les bits dans une prise ou un tuyau, etc., puis les copier de nouveau à la réception. Flow-IPC permet la transmission sans copie de bout en bout des structures codées par Cap'n Proto- à l'aide de la mémoire partagée.
- Prise en charge des sockets/FD : Tout message transmis via Flow-IPC peut inclure une poignée d'E/S native (également connue sous le nom de descripteur de fichier ou FD). Par exemple, dans une architecture de serveur web, vous pouvez diviser le serveur en deux processus : un processus de gestion des points d'extrémité et un processus de traitement des demandes. Une fois que le processus de gestion des points d'accès a terminé la négociation TLS, il peut transmettre le handle du socket TCP connecté directement au processus de traitement des requêtes.
- Prise en charge native des structures C++ : De nombreux algorithmes nécessitent de travailler directement en C++
structLe plus souvent, il s'agit de structures impliquant plusieurs niveaux de conteneurs STL et/ou de pointeurs. Deux threads collaborant sur une telle structure sont courants et faciles à coder, alors que deux threads collaborant sur une même structure sont plus faciles à coder que deux threads collaborant sur une même structure. processus le faire via la mémoire partagée est assez difficile - même avec des outils bien pensés comme le Boost.interprocessus. Flow-IPC simplifie cette tâche en permettant le partage de structures conformes à la STL, telles que les conteneurs, les pointeurs et les données ordinaires. - jemalloc plus SHM : Une ligne de code vous permet d'allouer toutes les données nécessaires dans la mémoire partagée, que ce soit pour des opérations en coulisse comme la transmission de Cap'n Proto ou directement pour des données C++ natives. Ces tâches peuvent être déléguées à jemalloc, le moteur de tas derrière FreeBSD et Meta. Cette fonctionnalité peut s'avérer particulièrement précieuse pour les projets qui nécessitent une allocation intensive de la mémoire partagée, similaire à l'allocation régulière du tas.
- Pas de problèmes de dénomination ou de nettoyage : Avec Flow-IPC, vous n'avez pas besoin de nommer les sockets serveur, les segments SHM ou les tuyaux, ni de vous préoccuper des fuites de RAM persistante. Vous devez plutôt établir une session Flow-IPC entre les processus : c'est votre contexte IPC. À partir de cet objet de session unique, des canaux de communication peuvent être ouverts à volonté, sans qu'il soit nécessaire de les nommer. Pour les tâches qui nécessitent un accès direct à la mémoire partagée (SHM), une arène SHM dédiée est disponible. Flow-IPC effectue un nettoyage automatique, même en cas de sortie anormale, et évite les conflits entre les noms de ressources.
- Utilisation pour RPC : Flow-IPC est conçu pour compléter les cadres de communication de niveau supérieur comme gRPC et Cap'n Proto RPC, et non pour leur faire concurrence. Il n'est pas nécessaire de choisir entre eux et Flow-IPC. En fait, l'utilisation des fonctions de zéro copie de Flow-IPC peut généralement améliorer la performance de ces protocoles.
Exemple : Envoi d'un fichier en plusieurs parties
Bien que Flow-IPC puisse transmettre des données de différents types, nous avons décidé de nous concentrer sur une structure de données décrite par un schéma Cap'n Proto (capnp). Cet exemple sera particulièrement clair pour ceux qui connaissent capnp et les Protocol Buffers, mais nous donnerons beaucoup de contexte pour ceux qui sont moins familiers avec ces outils.
Dans cet exemple, deux applications s'engagent dans un scénario de demande-réponse.
- App 1 (serveur): Il s'agit d'un serveur de mise en cache de la mémoire qui a préchargé des fichiers allant de 100 kb à 1 GB dans la RAM. Il se tient prêt à traiter les demandes de fichiers mis en cache et à fournir des réponses.
- App 2 (client) : Ce client demande un fichier d'une certaine taille. L'application 1 (serveur) envoie les données du fichier dans un message unique divisé en une série de morceaux. Chaque morceau comprend les données ainsi que leur hachage.
# Cap'n Proto schema (.capnp file, generates .h and .c++ source code
# using capnp compiler tool):
$Cxx.namespace("cache_demo::schema");
struct Body
{
union
{
getCacheReq @0 :GetCacheReq;
getCacheRsp @1 :GetCacheRsp;
}
}
struct GetCacheReq
{
fileName @0 :Text;
}
struct GetCacheRsp
{
# We simulate the server returning file multiple parts,
# each (~equally) sized at its discretion.
struct FilePart
{
data @0 :Data;
dataSizeToVerify @1 :UInt64;
# Recipient can verify that `data` blob's size is indeed this.
dataHashToVerify @2 :Hash;
# Recipient can hash `data` and verify it is indeed this.
}
fileParts @0 :List(FilePart);
}Notre objectif dans cette expérience est d'émettre une requête pour un fichier de taille N, de recevoir la réponse, de mesurer le temps de traitement et de vérifier l'intégrité d'une partie du fichier. Cette interaction se fait par l'intermédiaire d'un canal de communication.
Pour ce faire, nous devons d'abord établir ce canal. Bien que Flow-IPC vous permette d'établir manuellement un canal à partir de ses éléments constitutifs de bas niveau (socket local, file d'attente de messages POSIX, etc.), il est beaucoup plus facile d'utiliser les sessions Flow-IPC. Une session est simplement le contexte de communication entre deux processus actifs. Une fois établis, les canaux sont facilement accessibles.
Voici une vue d'ensemble du processus.
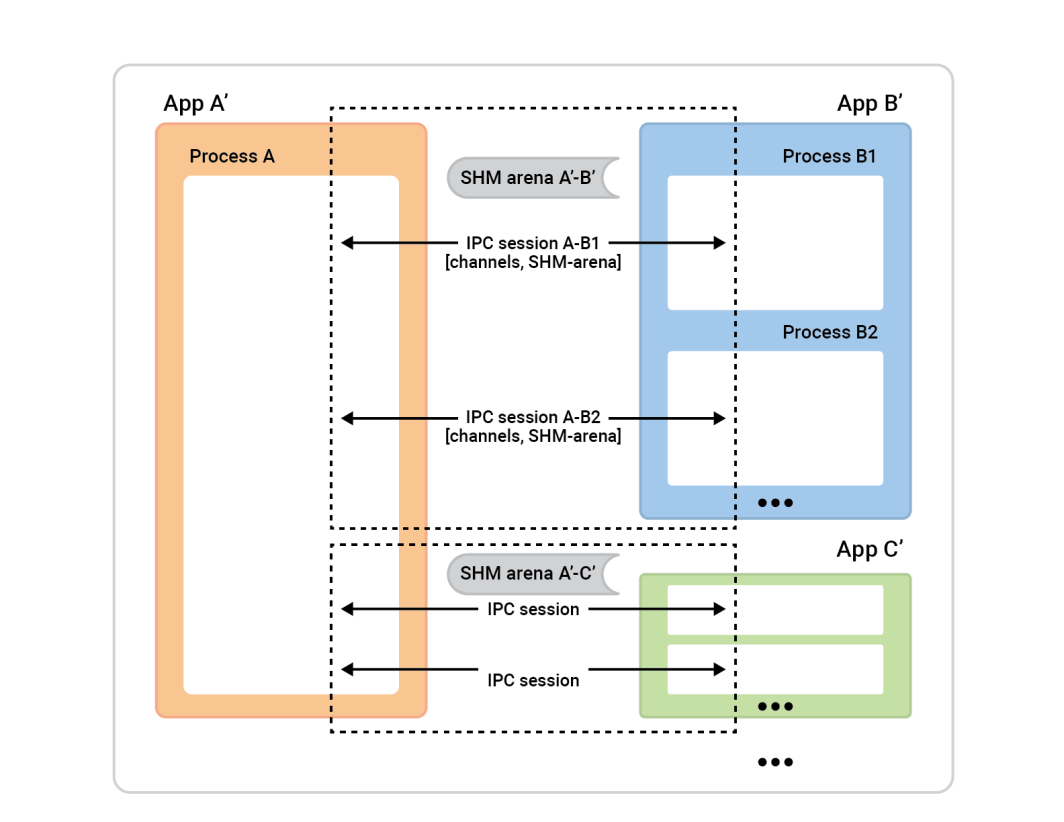
Le processus A à gauche est appelé le serveur de session. Les boîtes de processus à droite - les clients de session - se connectent au processus A afin d'établir des sessions. En règle générale, une session donnée est totalement symétrique, de sorte que l'initiateur de la connexion n'a pas d'importance. Les deux parties ont les mêmes capacités et peuvent se voir attribuer n'importe quel rôle algorithmique. Cependant, avant que la session ne soit prête, nous devons attribuer des rôles. L'une des parties sera le client de session et effectuera une connexion instantanée d'une seule session, tandis que l'autre partie, le serveur de session, acceptera autant de sessions qu'elle le souhaite.
Dans cet exemple, la configuration est simple. Il y a deux applications avec une session entre elles et un canal dans cette session. Le client-cache (App 2) joue le rôle de client-session, et le rôle de serveur-session est joué par App 1. Cependant, l'inverse fonctionnerait également très bien.
Pour mettre en place ce système, chaque application (le client et le serveur de cache) doit comprendre le même univers IPC, ce qui signifie simplement qu'elle doit connaître des données de base sur les applications concernées.
Voici pourquoi :
- Le client doit savoir comment localiser le serveur pour initier une session. Si vous êtes l'application de connexion (le client), vous devez connaître le nom de l'application d'acceptation. Flow-IPC utilise le nom du serveur pour déterminer des détails tels que les adresses des sockets et les noms des segments de mémoire partagée en fonction de ce nom.
- L'application serveur doit savoir qui est autorisé à s'y connecter, pour des raisons de sécurité. Flow-IPC vérifie les données du client, comme l'utilisateur/le groupe et le chemin d'accès à l'exécutable, par rapport au système d'exploitation, afin de s'assurer que tout concorde.
- Les mécanismes de sécurité standard du système d'exploitation (propriétaires, permissions) s'appliquent aux différents transports IPC (sockets, MQ, SHM). Un seul sélecteur
enumdéfinira la politique de haut niveau à utiliser et Flow-IPC définira alors les autorisations de la manière la plus restrictive possible tout en respectant ce choix.
En ce qui nous concerne, il nous suffira d'exécuter ce qui suit dans chacune des deux applications. Cela peut se faire dans un seul .cpp lié aux applications cache-server et cache-client.
// IPC app universe: simple structs naming the 2 apps.
// The applications should share this code.
const ipc::session::Client_app
CLI_APP{ "cacheCli", // Name the app uniquely.
// From where it will run (for safety).
"/usr/bin/cache_client.exec",
CLI_UID, GID }; // The user and group ID (for safety).
const ipc::session::Server_app
SRV_APP{ { "cacheSrv", "/usr/bin/cache_server.exec", SRV_UID, GID },
// For the server, provide similar details --^.
// Plus a few server-specific settings:
// Safety: List client-app names that can connect to server-app.
// So in our case this will just be { "cacheCli" }.
{ CLI_APP.m_name },
"", // An optional path override; don't worry about it here.
// Safety/permissions selector:
// We've decided to run the two apps as different users
// in the same group - so we indicate that here.
ipc::util::Permissions_level::S_GROUP_ACCESS }; Notez que les configurations plus complexes peuvent avoir plus de ces définitions.
Après avoir exécuté ce code dans chacune de nos applications, nous passerons simplement ces objets dans le constructeur de l'objet session afin que le serveur sache à quoi s'attendre lorsqu'il accepte des sessions et que le client sache à quel serveur se connecter.
Ouvrons donc la session. Dans l'application 2 (le client-cache), nous voulons simplement ouvrir une session et un canal à l'intérieur de celle-ci. Bien que Flow-IPC permette d'ouvrir instantanément des canaux à tout moment (à partir d'un objet session), il est courant d'avoir besoin d'un certain nombre de canaux prêts à l'emploi au début de la session. Puisque nous voulons ouvrir un canal, nous pouvons laisser Flow-IPC créer le canal lors de la création de la session. Cela permet d'éviter toute asynchronie inutile. Ainsi, au début de la session de notre client-cache main() nous pouvons connecter et ouvrir un canal avec une seule fonction .sync_connect() appel :
// Specify that we *do* want zero-copy behavior, by merely choosing our
// backing-session type.
// In other words, setting this alias says, “be fast about Cap’n Proto things.”
//
// Different (subsequent) capnp-serialization-backing and SHM-related behaviors
// are available; just change this alias. E.g., omit `::shm::classic` to disable
// SHM entirely; or specify `::shm::arena_lend::jemalloc` to employ
// jemalloc-based SHM. Subsequent code remains the same!
// This demonstrates a key design tenet of Flow-IPC.
using Session = ipc::session::shm::classic::Client_session<...>;
// Tell Session object about the applications involved.
Session session{ CLI_APP, SRV_APP, /* detail omitted */ };
// Ask for 1 *channel* to be available on both sides
// from the very start of the session.
Session::Channels ipc_raw_channels(1);
// Instantly open session - and the 1 channel.
// (Fail if server is not running at this time.)
session.sync_connect(session.mdt_builder(), &ipc_raw_channels);
auto& ipc_raw_channel = ipc_raw_channels[0];
// (Can also instantly open more channel(s) anytime:
// `session.open_channel(&channel)`.)
Nous devrions avoir un ipc_raw_channel qui est un objet canal de base. En fonction de paramètres spécifiques, cet objet peut représenter une socket de flux du domaine Unix, un MQ POSIX ou d'autres types de canaux. Si nous le souhaitions, nous pourrions l'utiliser en non structuré Cela signifie que nous pourrions l'utiliser pour transmettre des blobs binaires (avec des frontières préservées) et/ou des poignées natives (FD). Nous pouvons également accéder directement à une arène SHM par l'intermédiaire de session.session_shm()->construct<T>(...). Cela sort du cadre de notre discussion ici, mais c'est une capacité puissante qui mérite d'être mentionnée.
Pour l'instant, nous voulons juste parler du Cap'n Proto cache_demo::schema::Body (à partir de notre fichier .capnp). Ainsi, nous mise à niveau l'objet canal brut vers un objet canal structuré comme suit :
// Template arg indicates capnp schema. (Take a look at the .capnp file above.)
Session::Structured_channel<cache_demo::schema::Body>
ipc_channel
{ nullptr, std::move(ipc_raw_channel), “Eat” the raw channel: take over it.
ipc::transport::struc::Channel_base::S_SERIALIZE_VIA_SESSION_SHM,
&session }; C'est tout pour notre configuration. Nous sommes maintenant prêts à échanger des messages capnp sur le canal. Remarquez que nous n'avons pas eu à nous occuper des détails spécifiques au système d'exploitation, tels que les noms d'objets, les valeurs de permissions Unix, etc. Notre approche consistait simplement à nommer nos deux applications. Nous avons également opté pour une transmission de bout en bout sans copie afin de maximiser les performances en exploitant la mémoire partagée sans une seule copie. ::shm_open() ou ::mmap() en vue.
Nous sommes maintenant prêts pour la partie la plus amusante : l'émission du GetCacheReq en recevant la demande de GetCacheRsp et d'accéder aux différentes parties de cette réponse, à savoir les parties du fichier et leurs hachages.
Voici le code :
// Issue request and process response. TIMING FOR LATENCY GRAPH STARTS HERE -->
auto req_msg = ipc_channel.create_msg();
req_msg.body_root() // Vanilla capnp code: call Cap'n Proto-generated mutator API.
->initGetCacheReq().setFileName("huge-file.bin");
// Send message; get ~instant reply.
const auto rsp_msg = ipc_channel.sync_request(req_msg);
// More vanilla capnp work: accessors.
const auto rsp_root = rsp_msg->body_root().getGetCacheRsp();
// <-- TIMING FOR LATENCY GRAPH STOPS HERE.
// ...
verify_hash(rsp_root, some_file_chunk_idx);
// ...
// More vanilla Cap'n Proto accessor code.
void verify_hash(const cache_demo::schema::GetCacheRsp::Reader& rsp_root,
size_t idx)
{
const auto file_part = rsp_root.getFileParts()[idx];
if (file_part.getHashToVerify() != compute_hash(file_part.getData()))
{
throw Bad_hash_exception(...);
}
} Dans le code ci-dessus, nous avons utilisé le simple .sync_request() qui envoie un message et attend une réponse spécifique. Les ipc::transport::struc::Channel API fournit un certain nombre d'astuces pour rendre les protocoles naturels à coder, notamment la réception asynchrone, le démultiplexage vers les fonctions de traitement par type de message, la notification par rapport à la demande, et le message non sollicité par rapport à la réponse. Aucune restriction n'est imposée à votre schéma (cache_demo::schema::Body dans notre cas). S'il est exprimable en capnp, vous pouvez l'utiliser avec les canaux structurés Flow-IPC.
Voilà, c'est fait ! La partie serveur est similaire dans l'esprit et le niveau de difficulté. La partie perf_demo Le code source est disponible.
Sans Flow-IPC, la reproduction de cette configuration pour une performance de bout en bout sans copie impliquerait une quantité importante de code difficile, y compris la gestion des segments SHM dont les noms et le nettoyage devraient être coordonnés entre les deux applications. Même sans copie zéro - c'est-à-dire simplement ::write()une copie de la sérialisation de capnp de req_msg à et ::read()ingurgiter rsp_msg à partir d'un socket FD du domaine Unix - un code suffisamment robuste serait non trivial à écrire en comparaison.
Le graphique ci-dessous montre les temps de latence, où chaque point sur l'axe des x représente la somme de tous les temps de latence. filePart.data pour chaque test donné. La ligne bleue montre les latences de la méthode de base où l'application 1 écrit des sérialisations capnp sur un socket de domaine Unix à l'aide de ::write()et l'application 2 les lit avec ::read(). La ligne orange représente les temps de latence pour le code utilisant Flow-IPC, comme indiqué ci-dessus.
Comment contribuer
Pour les demandes de fonctionnalités et les rapports de défauts, veuillez consulter la base de données Issue sur le site GitHub de Flow-IPC. Déposez des questions si nécessaire.
Pour contribuer aux changements et aux nouvelles fonctionnalités, veuillez consulter le guide de contribution. Nous sommes joignables sur le forum de discussion Flow-IPC sur GitHub.
Quelle est la prochaine étape ?
Nous avons essayé de fournir une expérience réaliste dans l'exemple ci-dessus, en n'omettant rien d'important dans le code présenté. Nous avons délibérément choisi un scénario dépourvu d'asynchronisme et de rappels. En conséquence, des questions se poseront, telles que "comment intégrer Flow-IPC à ma boucle d'événements ?" ou "comment gérer la fermeture d'une session et d'un canal ? Puis-je me contenter d'ouvrir une simple prise de flux sans tous ces trucs de session ?", etc.
Ces questions sont traitées dans la documentation complète. La documentation comprend une référence générée à partir des commentaires du code, un manuel guidé avec une courbe d'apprentissage plus douce et des instructions d'installation. API dans le code, un manuel guidé avec une courbe d'apprentissage plus douce, et des instructions d'installation. Le README du dépôt principal vous dirigera vers toutes ces ressources. L'introduction du manuel et le synopsis deAPI couvrent l'ensemble des fonctionnalités disponibles.
Ressources
- Annonce d'un article de blog
- Projet Flow-IPC sur GitHub
Pour installer, lire la documentation, déposer des demandes de fonctionnalités/changements, ou contribuer. - Discussions sur le CIP-Flow
Un excellent moyen de nous joindre - ainsi que le reste de la communauté.



Commentaires