

Wir haben kürzlich Flow-IPC - ein Interprozess-Kommunikations-Toolkit in C++ - als Open Source unter den Lizenzen Apache 2.0 und MIT veröffentlicht. Flow-IPC wird für C++-Projekte nützlich sein, die Daten zwischen Anwendungsprozessen übertragen und eine Latenzzeit von nahezu Null erreichen müssen, ohne dass dies zu Lasten von einfachem und wiederverwendbarem Code geht.
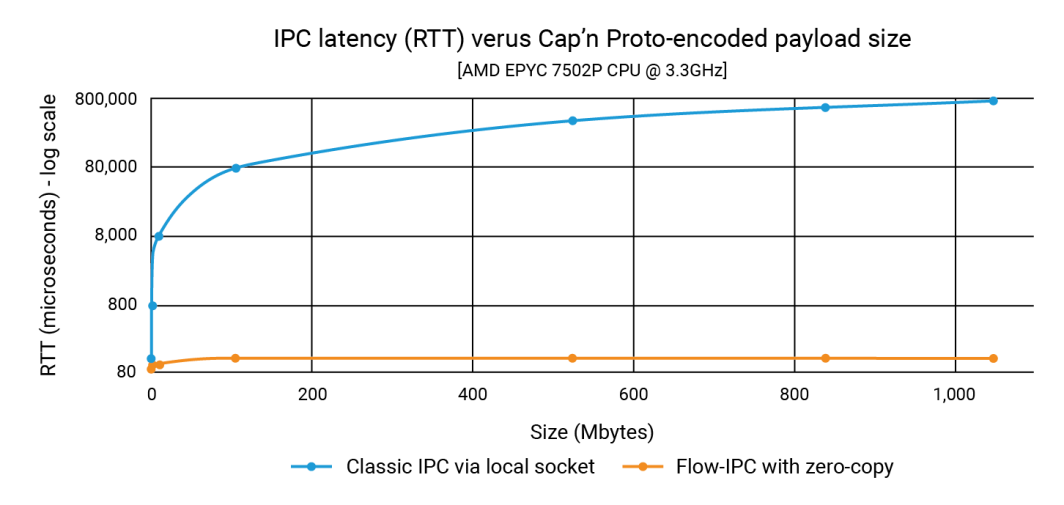
In der Ankündigung haben wir gezeigt, dass Flow-IPC Datenstrukturen mit einer Größe von 1 GB genauso schnell übertragen kann wie eine Nutzlast von 100 K - und das in weniger als 100 Mikrosekunden. Bei der klassischen IPC hängt die Latenzzeit von der Größe der Nutzlast ab und kann bis in den Bereich von 1 Sekunde reichen. Die Verbesserung kann also bis zu drei oder vier Größenordnungen ausmachen.
In diesem Beitrag zeigen wir den Quellcode, der diese Zahlen erzeugt hat. Unser Beispiel, das sich auf die Integration von Cap'n Proto konzentriert, zeigt, dass Flow-IPC sowohl schnell als auch einfach zu verwenden ist. (Beachten Sie, dass die Flow-IPC-API insofern umfassend ist, als sie die Übertragung verschiedener Arten von Nutzdaten unterstützt, aber die Cap'n Proto-basierte Nutzdatenübertragung ist eine spezielle Funktion). Cap'n Proto ist ein Open-Source-Projekt, das nicht mit Akamai verbunden ist und dessen Nutzung der Lizenz unterliegt, die zum Zeitpunkt der Veröffentlichung dieses Blogs hier zu finden ist.
Was ist inbegriffen?
Flow-IPC ist eine Bibliothek mit einer erweiterbaren C++17-API. Sie ist gehostet in GitHub zusammen mit einer vollständigen Dokumentation, automatisierten Tests und Demos sowie einer CI-Pipeline. Das Beispiel, das wir im Folgenden untersuchen, ist die perf_demo Testanwendung. Flow-IPC unterstützt derzeit Linux auf x86-64. Wir planen, diese Unterstützung auf macOS und ARM64 zu erweitern, gefolgt von Windows und anderen Betriebssystemvarianten, je nach Nachfrage. Sie sind Beitrag willkommen und Hafen.
Die Flow-IPC-API orientiert sich an der C++-Standardbibliothek und an Boost, wobei der Schwerpunkt auf der Integration verschiedener Konzepte und ihrer Implementierungen in modularer Weise liegt. Sie ist so konzipiert, dass sie erweiterbar ist. Unsere CI-Pipeline testet eine Reihe von GCC- und Clang-Compiler-Versionen und Build-Konfigurationen, einschließlich Härtung durch Laufzeit-Sanitizer: ASAN (gegen Speichermissbrauch), TSAN (gegen Race Conditions) und UBSAN (gegen sonstiges undefiniertes Verhalten).
Zur Zeit ist Flow-IPC für die lokale Kommunikation gedacht: über Prozessgrenzen hinweg, aber nicht über Maschinengrenzen. Das Design ist jedoch erweiterbar, so dass die Erweiterung auf vernetzte IPC ein natürlicher nächster Schritt ist. Wir glauben, dass die Verwendung von Remote Direct Memory Access (RDMA) eine interessante Möglichkeit für ultraschnelle LAN-Leistung bietet.
Wer sollte es verwenden?
Flow-IPC ist ein pragmatisches Toolkit für die Kommunikation zwischen Prozessen. Wir haben es aus der Perspektive des modernen C++-Systementwicklers entworfen und es speziell auf die IPC-Aufgaben zugeschnitten, mit denen man immer wieder konfrontiert wird, insbesondere bei der Entwicklung von Serveranwendungen. Viele von uns mussten schon einmal ein Unix-Domain-Socket, eine Named-Pipe oder ein lokales HTTP-basiertes Protokoll zusammenstellen, um etwas von einem Prozess zu einem anderen zu übertragen. Um das mit solchen Lösungen verbundene Kopieren zu vermeiden, wendet man sich manchmal an Shared-Memory (SHM), eine notorisch heikle und schwer wiederverwendbare Technik. Flow-IPC kann jedem C++-Entwickler, der mit solchen Aufgaben konfrontiert ist, helfen, von allgemein bis hin zu fortgeschritten.
Zu den Highlights gehören:
- Cap'n Proto-Integration: Tools für die schemabasierte Serialisierung an Ort und Stelle wie Cap'n Proto, das zu den besten seiner Klasse gehört, sind für die prozessübergreifende Arbeit sehr hilfreich. Ohne Flow-IPC müssten Sie die Bits jedoch immer noch in einen Socket oder eine Pipe usw. kopieren und sie dann beim Empfang erneut kopieren. Flow-IPC bietet eine End-to-End-Null-Kopie-Übertragung von Cap'n Proto-kodierten Strukturen mit gemeinsamem Speicher.
- Socket/FD-Unterstützung: Jede über Flow-IPC übertragene Nachricht kann ein natives E/A-Handle (auch bekannt als Dateideskriptor oder FD) enthalten. In einer Webserver-Architektur könnten Sie beispielsweise den Server in zwei Prozesse aufteilen: einen Prozess zur Verwaltung der Endpunkte und einen Prozess zur Verarbeitung der Anfragen. Nachdem der Endpunktprozess die TLS-Aushandlung abgeschlossen hat, kann er das Handle des verbundenen TCP-Sockets direkt an den Prozess zur Verarbeitung der Anfragen weitergeben.
- Unterstützung nativer C++-Strukturen: Viele Algorithmen erfordern direkte Arbeit in C++
structs, meist solche, die mehrere Ebenen von STL-Containern und/oder Zeigern umfassen. Zwei Threads, die an einer solchen Struktur zusammenarbeiten, sind üblich und leicht zu kodieren, während zwei Prozesse dies über Shared-Memory zu tun, ist ziemlich schwierig - selbst mit durchdachten Tools wie Boost.interprocess. Flow-IPC vereinfacht dies, indem es die gemeinsame Nutzung von STL-kompatiblen Strukturen wie Containern, Zeigern und einfachen Daten ermöglicht. - jemalloc plus SHM: Mit einer Zeile Code können Sie alle notwendigen Daten im gemeinsamen Speicher zuweisen, sei es für Operationen hinter den Kulissen wie die Übertragung von Cap'n Proto oder direkt für native C++-Daten. Diese Aufgaben können an jemalloc, die Heap-Engine hinter FreeBSD und Meta, delegiert werden. Diese Funktion ist besonders wertvoll für Projekte, die eine intensive Shared-Memory-Zuweisung erfordern, ähnlich der regulären Heap-Zuweisung.
- Keine Kopfschmerzen bei der Namensgebung oder Bereinigung: Mit Flow-IPC brauchen Sie keine Server-Sockets, SHM-Segmente oder Pipes zu benennen oder sich um ausgelaufenen persistenten RAM zu kümmern. Stattdessen richten Sie eine Flow-IPC-Sitzung zwischen Prozessen ein: Das ist Ihr IPC-Kontext. Von diesem einzigen Sitzungsobjekt aus können Kommunikationskanäle nach Belieben und ohne zusätzliche Benennung geöffnet werden. Für Aufgaben, die direkten gemeinsamen Speicherzugriff (SHM) erfordern, steht eine dedizierte SHM-Arena zur Verfügung. Flow-IPC führt eine automatische Bereinigung durch, selbst im Falle eines anormalen Exits, und vermeidet Konflikte zwischen Ressourcennamen.
- Verwendung für RPC: Flow-IPC wurde entwickelt, um Kommunikationsframeworks auf höherer Ebene wie gRPC und Cap'n Proto RPC zu ergänzen und nicht mit ihnen zu konkurrieren. Es gibt keinen Grund, sich zwischen ihnen und Flow-IPC zu entscheiden. Tatsächlich kann die Verwendung der Zero-Copy-Funktionen von Flow-IPC im Allgemeinen die Leistung dieser Protokolle verbessern.
Beispiel: Versenden einer mehrteiligen Datei
Flow-IPC kann zwar Daten verschiedener Art übertragen, wir haben uns jedoch auf eine Datenstruktur konzentriert, die durch ein Cap'n Proto (capnp)-Schema beschrieben wird. Dieses Beispiel wird besonders für diejenigen verständlich sein, die mit capnp und Protokollpuffern vertraut sind, aber wir geben auch denjenigen, die mit diesen Werkzeugen weniger vertraut sind, genügend Kontext.
In diesem Beispiel gibt es zwei Anwendungen, die an einem Anfrage-Antwort-Szenario beteiligt sind.
- Anwendung 1 (Server): Dies ist ein Cache-Server, der Dateien zwischen 100kb und 1GB in den Arbeitsspeicher geladen hat. Er steht bereit, um Anfragen nach im Cache gespeicherten Dateien zu bearbeiten und Antworten zu geben.
- Anwendung 2 (Client): Dieser Client fordert eine Datei mit einer bestimmten Größe an. Anwendung 1 (Server) sendet die Dateidaten in einer einzigen Nachricht, die in eine Reihe von Chunks unterteilt ist. Jeder Chunk enthält die Daten zusammen mit ihrem Hash.
# Cap'n Proto schema (.capnp file, generates .h and .c++ source code
# using capnp compiler tool):
$Cxx.namespace("cache_demo::schema");
struct Body
{
union
{
getCacheReq @0 :GetCacheReq;
getCacheRsp @1 :GetCacheRsp;
}
}
struct GetCacheReq
{
fileName @0 :Text;
}
struct GetCacheRsp
{
# We simulate the server returning file multiple parts,
# each (~equally) sized at its discretion.
struct FilePart
{
data @0 :Data;
dataSizeToVerify @1 :UInt64;
# Recipient can verify that `data` blob's size is indeed this.
dataHashToVerify @2 :Hash;
# Recipient can hash `data` and verify it is indeed this.
}
fileParts @0 :List(FilePart);
}Unser Ziel in diesem Experiment ist es, eine Anfrage für eine Datei der Größe N zu stellen, die Antwort zu erhalten, die Bearbeitungszeit zu messen und die Integrität eines Teils der Datei zu überprüfen. Diese Interaktion findet über einen Kommunikationskanal statt.
Dazu müssen wir diesen Kanal zunächst einrichten. Flow-IPC ermöglicht es Ihnen zwar, einen Kanal manuell aus seinen Low-Level-Bestandteilen (lokaler Socket, POSIX-Nachrichtenwarteschlange usw.) aufzubauen, aber es ist viel einfacher, stattdessen Flow-IPC-Sitzungen zu verwenden. Eine Sitzung ist einfach der Kommunikationskontext zwischen zwei laufenden Prozessen. Einmal eingerichtet, sind Kanäle sofort verfügbar.
Aus der Vogelperspektive betrachtet, funktioniert der Prozess folgendermaßen.
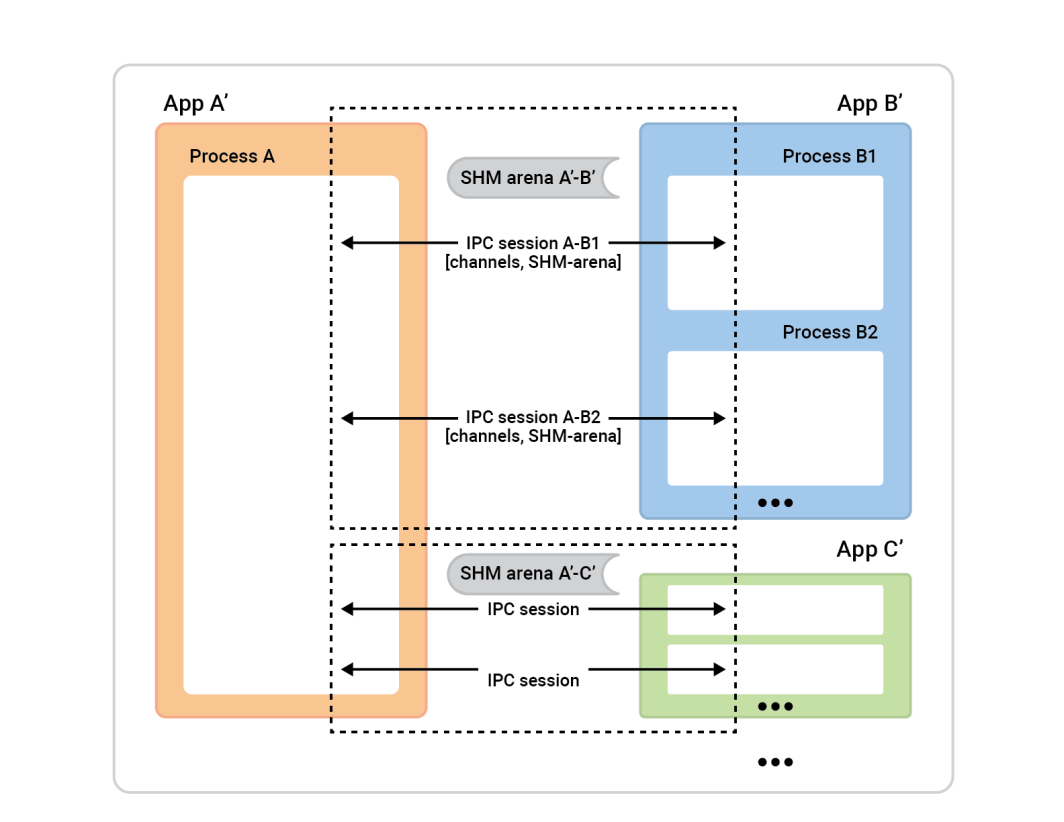
Der Prozess A auf der linken Seite ist der Sitzungsserver. Die Prozessboxen auf der rechten Seite - Sitzungsclients - stellen eine Verbindung zu Prozess A her, um Sitzungen aufzubauen. Im Allgemeinen ist jede Sitzung völlig symmetrisch, so dass es keine Rolle spielt, wer die Verbindung initiiert hat. Beide Seiten sind gleichermaßen fähig und können jede beliebige algorithmische Rolle zugewiesen bekommen. Bevor die Sitzung jedoch fertig ist, müssen wir die Rollen zuweisen. Eine Seite wird der Sitzungs-Client sein und eine sofortige Verbindung für eine einzige Sitzung herstellen, die andere Seite, der Sitzungs-Server, wird so viele Sitzungen akzeptieren , wie er möchte.
In diesem Beispiel ist die Einrichtung ganz einfach. Es gibt zwei Anwendungen mit einer Sitzung zwischen ihnen und einem Kanal in dieser Sitzung. Der Cache-Client (App 2) spielt die Rolle des Sitzungs-Clients, und die Rolle des Sitzungs-Servers wird von App 1 übernommen. Der umgekehrte Fall würde jedoch auch gut funktionieren.
Um dies einzurichten, muss jede Anwendung (der Cache-Client und der Cache-Server) dasselbe IPC-Universum verstehen, was lediglich bedeutet, dass sie grundlegende Fakten über die beteiligten Anwendungen kennen müssen.
Hier ist der Grund dafür:
- Der Client muss wissen, wie er den Server finden kann, um eine Sitzung zu initiieren. Wenn Sie die verbindende Anwendung (der Client) sind, müssen Sie den Namen der akzeptierenden Anwendung kennen. Flow-IPC verwendet den Namen des Servers, um Details wie die Socket-Adressen und die Namen der Shared-Memory-Segmente auf der Grundlage dieses Namens zu ermitteln.
- Die Serveranwendung muss aus Sicherheitsgründen wissen, wer eine Verbindung zu ihr herstellen darf. Flow-IPC prüft die Angaben des Clients, wie Benutzer/Gruppe und Pfad der ausführbaren Datei, mit dem Betriebssystem, um sicherzustellen, dass alles übereinstimmt.
- Standardmäßige OS-Sicherheitsmechanismen (Eigentümer, Berechtigungen) gelten für verschiedene IPC-Transporte (Sockets, MQs, SHM). Ein einziger Selektor
enumlegt die zu verwendende übergeordnete Richtlinie fest, und Flow-IPC legt dann die Berechtigungen so restriktiv wie möglich fest und respektiert dabei diese Wahl.
Für uns reicht es aus, wenn wir in jeder der beiden Anwendungen Folgendes ausführen. Dies kann in einer einzigen .cpp Datei, die sowohl mit der Cache-Server- als auch mit der Cache-Client-Anwendung verknüpft ist.
// IPC app universe: simple structs naming the 2 apps.
// The applications should share this code.
const ipc::session::Client_app
CLI_APP{ "cacheCli", // Name the app uniquely.
// From where it will run (for safety).
"/usr/bin/cache_client.exec",
CLI_UID, GID }; // The user and group ID (for safety).
const ipc::session::Server_app
SRV_APP{ { "cacheSrv", "/usr/bin/cache_server.exec", SRV_UID, GID },
// For the server, provide similar details --^.
// Plus a few server-specific settings:
// Safety: List client-app names that can connect to server-app.
// So in our case this will just be { "cacheCli" }.
{ CLI_APP.m_name },
"", // An optional path override; don't worry about it here.
// Safety/permissions selector:
// We've decided to run the two apps as different users
// in the same group - so we indicate that here.
ipc::util::Permissions_level::S_GROUP_ACCESS }; Beachten Sie, dass komplexere Konfigurationen mehr dieser Definitionen haben können.
Nachdem wir diesen Code in jeder unserer Anwendungen ausgeführt haben, übergeben wir diese Objekte einfach an den Konstruktor des Sitzungsobjekts, so dass der Server weiß, was er zu erwarten hat, wenn er Sitzungen annimmt, und der Client weiß, mit welchem Server er sich verbinden muss.
Eröffnen wir also die Sitzung. In App 2 (dem Cache-Client) wollen wir einfach eine Sitzung und einen Kanal darin öffnen. Flow-IPC erlaubt zwar das sofortige Öffnen von Kanälen zu jeder Zeit (bei Vorhandensein eines Sitzungsobjekts), aber es ist typisch, dass man zu Beginn der Sitzung eine bestimmte Anzahl von einsatzbereiten Kanälen benötigt. Da wir nur einen Kanal öffnen wollen, können wir Flow-IPC den Kanal beim Erstellen der Sitzung erstellen lassen. Dadurch wird jede unnötige Asynchronität vermieden. Zu Beginn der Sitzung unseres Cache-Clients wird also main() können wir einen Kanal mit einer einzigen Funktion verbinden und öffnen .sync_connect() anrufen:
// Specify that we *do* want zero-copy behavior, by merely choosing our
// backing-session type.
// In other words, setting this alias says, “be fast about Cap’n Proto things.”
//
// Different (subsequent) capnp-serialization-backing and SHM-related behaviors
// are available; just change this alias. E.g., omit `::shm::classic` to disable
// SHM entirely; or specify `::shm::arena_lend::jemalloc` to employ
// jemalloc-based SHM. Subsequent code remains the same!
// This demonstrates a key design tenet of Flow-IPC.
using Session = ipc::session::shm::classic::Client_session<...>;
// Tell Session object about the applications involved.
Session session{ CLI_APP, SRV_APP, /* detail omitted */ };
// Ask for 1 *channel* to be available on both sides
// from the very start of the session.
Session::Channels ipc_raw_channels(1);
// Instantly open session - and the 1 channel.
// (Fail if server is not running at this time.)
session.sync_connect(session.mdt_builder(), &ipc_raw_channels);
auto& ipc_raw_channel = ipc_raw_channels[0];
// (Can also instantly open more channel(s) anytime:
// `session.open_channel(&channel)`.)
Wir sollten eine ipc_raw_channel ist ein einfaches Kanalobjekt. Je nach den spezifischen Einstellungen kann dies ein Unix-Domänen-Stream-Socket, ein POSIX MQ oder andere Arten von Kanälen darstellen. Wenn wir wollten, könnten wir es in unstrukturiert Das heißt, wir könnten damit binäre Blobs (mit erhaltenen Grenzen) und/oder native Handles (FDs) übertragen. Wir könnten auch direkt auf eine SHM-Arena über session.session_shm()->construct<T>(...). Dies liegt außerhalb des Rahmens, den wir hier abstecken, aber es handelt sich um eine leistungsstarke Funktion, die es wert ist, erwähnt zu werden.
Im Moment wollen wir nur mit Cap'n Proto sprechen. cache_demo::schema::Body Protokoll (aus unserer .capnp-Datei). Also wir aktualisieren das rohe Kanalobjekt in ein strukturierter Kanal Objekt wie folgt:
// Template arg indicates capnp schema. (Take a look at the .capnp file above.)
Session::Structured_channel<cache_demo::schema::Body>
ipc_channel
{ nullptr, std::move(ipc_raw_channel), “Eat” the raw channel: take over it.
ipc::transport::struc::Channel_base::S_SERIALIZE_VIA_SESSION_SHM,
&session }; Das war's mit unserer Einrichtung. Wir sind nun bereit, capnp-Nachrichten über den Kanal auszutauschen. Beachten Sie, dass wir uns nicht um betriebssystemspezifische Details wie Objektnamen, Unix-Berechtigungswerte usw. kümmern müssen. Unser Ansatz bestand lediglich darin, unsere beiden Anwendungen zu benennen. Außerdem haben wir uns für eine End-to-End-Null-Kopie-Übertragung entschieden, um die Leistung zu maximieren, indem wir Shared-Memory ohne einen einzigen ::shm_open() oder ::mmap() in Sicht.
Jetzt geht es ans Eingemachte: das Ausstellen der GetCacheReq Anfrage, den Erhalt der GetCacheRsp Antwort und den Zugriff auf verschiedene Teile dieser Antwort, nämlich die Dateiteile und ihre Hashes.
Hier ist der Code:
// Issue request and process response. TIMING FOR LATENCY GRAPH STARTS HERE -->
auto req_msg = ipc_channel.create_msg();
req_msg.body_root() // Vanilla capnp code: call Cap'n Proto-generated mutator API.
->initGetCacheReq().setFileName("huge-file.bin");
// Send message; get ~instant reply.
const auto rsp_msg = ipc_channel.sync_request(req_msg);
// More vanilla capnp work: accessors.
const auto rsp_root = rsp_msg->body_root().getGetCacheRsp();
// <-- TIMING FOR LATENCY GRAPH STOPS HERE.
// ...
verify_hash(rsp_root, some_file_chunk_idx);
// ...
// More vanilla Cap'n Proto accessor code.
void verify_hash(const cache_demo::schema::GetCacheRsp::Reader& rsp_root,
size_t idx)
{
const auto file_part = rsp_root.getFileParts()[idx];
if (file_part.getHashToVerify() != compute_hash(file_part.getData()))
{
throw Bad_hash_exception(...);
}
} Im obigen Code haben wir die einfache .sync_request() die sowohl eine Nachricht sendet als auch eine bestimmte Antwort erwartet. Die Website ipc::transport::struc::Channel API bietet eine Reihe von Annehmlichkeiten, um Protokolle natürlich zu kodieren, einschließlich asynchronem Empfang, Demultiplexing zu Handler-Funktionen nach Nachrichtentyp, Benachrichtigung versus Anfrage und unaufgeforderte Nachricht versus Antwort. Es gibt keine Einschränkungen für Ihr Schema (cache_demo::schema::Body in unserem Fall). Wenn es in capnp ausgedrückt werden kann, können Sie es mit Flow-IPC strukturierten Kanälen verwenden.
Das war's! Die Serverseite ist in Geist und Schwierigkeitsgrad ähnlich. Die perf_demo Der Quellcode ist verfügbar.
Ohne Flow-IPC würde die Replikation dieses Aufbaus für eine durchgängige Zero-Copy-Leistung eine erhebliche Menge an schwierigem Code erfordern, einschließlich der Verwaltung von SHM-Segmenten, deren Namen und Bereinigung zwischen den beiden Anwendungen koordiniert werden müssten. Auch ohne Zero-Copy - d. h. einfach ::write()eine Kopie der capnp-Serialisierung von req_msg zu und ::read()ing rsp_msg von einem Unix-Domain-Socket FD - ausreichend robuster Code wäre im Vergleich dazu nicht trivial zu schreiben.
Das nachstehende Diagramm zeigt die Latenzzeiten, wobei jeder Punkt auf der x-Achse die Summe aller filePart.data Größen für jeden gegebenen Testlauf. Die blaue Linie zeigt die Latenzen der Basismethode, bei der App 1 capnp-Serialisierungen an einen Unix-Domain-Socket schreibt und dabei ::write(), und App 2 liest sie mit ::read(). Die orangefarbene Linie zeigt die Latenzen für den Code, der Flow-IPC verwendet, wie oben beschrieben.
Wie Sie beitragen können
Für Funktionsanfragen und Fehlerberichte schauen Sie bitte in die Issue-Datenbank auf der Flow-IPC GitHub-Seite. Legen Sie bei Bedarf Issues an.
Um Änderungen und neue Funktionen beizutragen, konsultieren Sie bitte den Contribution Guide. Sie können uns im Flow-IPC-Diskussionsforum auf GitHub erreichen.
Was kommt als Nächstes?
Wir haben versucht, im obigen Beispiel ein realistisches Experiment durchzuführen und nichts Wesentliches im gezeigten Code auszulassen. Wir haben bewusst ein Szenario gewählt, in dem Asynchronität und Rückrufe fehlen. Dementsprechend werden Fragen auftauchen, wie z. B. "Wie integriere ich Flow-IPC in meine Ereignisschleife?" oder "Wie behandle ich das Schließen von Sitzungen und Kanälen? Kann ich einfach einen einfachen Stream-Socket ohne diesen ganzen Sitzungskram öffnen?" usw.
Solche Fragen werden in der vollständigen Dokumentation behandelt. Die Dokumentation enthält eine Referenz, die aus den API-Kommentaren im Code generiert wurde, eine Anleitung mit einer sanfteren Lernkurve und Installationsanweisungen. Die README des Hauptrepositorys verweist Sie auf all diese Ressourcen. Die Einführung in das Handbuch und die API-Synopse decken den Umfang der verfügbaren Funktionen ab.
Ressourcen
- Ankündigung Blog Post
- Flow-IPC-Projekt auf GitHub
Zum Installieren, Lesen der Dokumentation, Einreichen von Funktions- und Änderungsanfragen oder zum Mitwirken. - Flow-IPC-Diskussionen
Eine gute Möglichkeit, uns - und den Rest der Gemeinschaft - zu erreichen.



Kommentare