

Lançámos recentemente o Flow-IPC - um conjunto de ferramentas de comunicação entre processos em C++ - como código aberto ao abrigo das licenças Apache 2.0 e MIT. O Flow-IPC será útil para projectos C++ que transmitam dados entre processos de aplicação e que necessitem de obter uma latência próxima de zero sem comprometer a simplicidade e a reutilização do código.
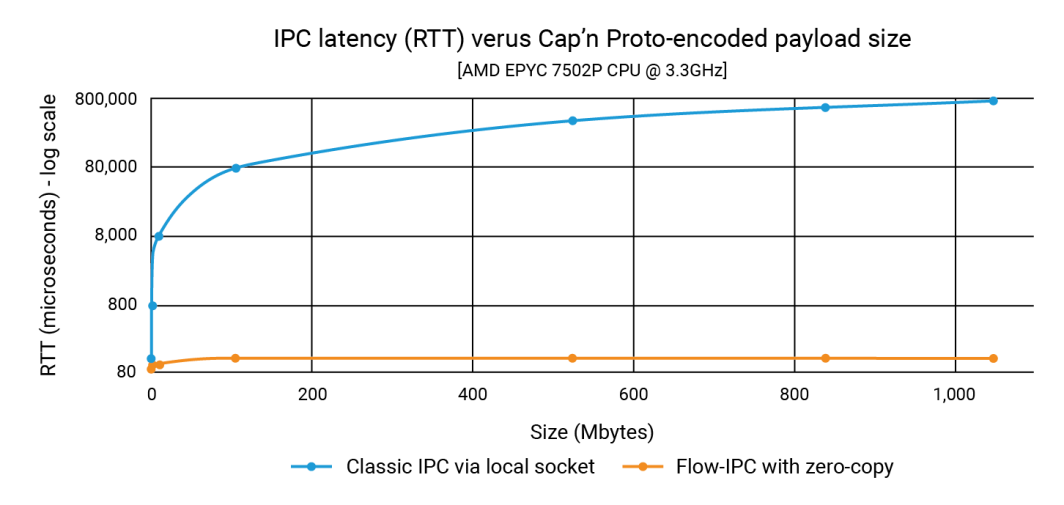
No anúncio, mostrámos que o Flow-IPC pode transmitir cargas úteis de estruturas de dados tão grandes como 1GB tão rapidamente como uma carga útil de 100K - e em menos de 100 microssegundos. Com o IPC clássico, a latência depende do tamanho da carga útil e pode chegar ao intervalo de 1 segundo. Assim, a melhoria pode ser de três ou quatro ordens de grandeza.
Neste post, mostramos o código-fonte que produziu esses números. O nosso exemplo, que se centra na integração do Cap'n Proto, mostra que o Flow-IPC é rápido e fácil de utilizar. (Observe que a API do Flow-IPC é abrangente, pois suporta a transmissão de vários tipos de cargas úteis, mas a transmissão de cargas úteis baseada no Cap'n Proto é um recurso específico). O Cap'n Proto é um projeto de código aberto não afiliado à Akamai, cujo uso está sujeito à licença, a partir da data de publicação deste blog, encontrada aqui.
O que é que está incluído?
Flow-IPC é uma biblioteca com uma API C++17 extensível. Ela é alojado no GitHub juntamente com documentação completa, testes automatizados e demonstrações, e um pipeline de CI. O exemplo que exploramos abaixo é o perf_demo aplicação de teste. Atualmente, o Flow-IPC suporta Linux em x86-64. Temos planos para expandir isto para macOS e ARM64, seguido de Windows e outras variantes de SO, dependendo da procura. Está a bem-vindo a contribuir e porto.
A API Flow-IPC segue o espírito da biblioteca padrão C++ e do Boost, concentrando-se na integração de vários conceitos e suas implementações de forma modular. Foi concebida para ser extensível. O nosso pipeline de CI testa uma série de versões do compilador GCC e Clang e configurações de compilação, incluindo o endurecimento através de higienizadores de tempo de execução: ASAN (endurece contra uso indevido de memória), TSAN (contra condições de corrida) e UBSAN (contra comportamentos indefinidos diversos).
Atualmente, o Flow-IPC destina-se à comunicação local: atravessando as fronteiras dos processos, mas não as fronteiras das máquinas. No entanto, ele tem um design extensível, portanto, expandi-lo para IPC em rede é um próximo passo natural. Pensamos que a utilização do Acesso Remoto Direto à Memória (RDMA) oferece uma possibilidade intrigante para um desempenho ultrarrápido da LAN.
Quem deve utilizá-lo?
O Flow-IPC é um kit de ferramentas pragmático para comunicação entre processos. Ao projetá-lo, partimos da perspetiva do desenvolvedor de sistemas C++ moderno, adaptando-o especificamente às tarefas de IPC que enfrentamos repetidamente, particularmente no desenvolvimento de aplicativos de servidor. Muitos de nós já tivemos que montar um protocolo baseado em Unix-domain-socket, named-pipe ou HTTP local para transmitir algo de um processo para outro. Por vezes, para evitar a cópia envolvida em tais soluções, pode recorrer-se à memória partilhada (SHM), uma técnica notoriamente sensível e difícil de reutilizar. O Flow-IPC pode ajudar qualquer programador de C++ confrontado com este tipo de tarefas, desde as mais comuns às mais avançadas.
Os destaques incluem:
- Integração do Cap'n Proto: As ferramentas de serialização no local baseadas em esquemas, como o Cap'n Proto, que é o melhor da sua classe, são muito úteis para o trabalho entre processos. No entanto, sem o Flow-IPC, continuaria a ter de copiar os bits para uma tomada ou um tubo, etc., e depois copiá-los novamente na receção. O Flow-IPC fornece uma transmissão de ponta a ponta sem cópia de estruturas codificadas pelo Cap'n Proto usando memória compartilhada.
- Suporte a Socket/FD: Qualquer mensagem transmitida através do Flow-IPC pode incluir um identificador de E/S nativo (também conhecido como descritor de ficheiro ou FD). Por exemplo, numa arquitetura de servidor Web, pode dividir o servidor em dois processos: um processo para gerir pontos finais e um processo para processar pedidos. Depois que o processo de ponto de extremidade conclui a negociação TLS, ele pode passar o identificador de soquete TCP conectado diretamente para o processo de processamento de solicitação.
- Suporte nativo de estruturas C++: Muitos algoritmos requerem trabalho direto em C++
structs, na maioria das vezes envolvendo vários níveis de contentores STL e/ou ponteiros. Duas threads colaborando em tal estrutura é comum e fácil de codificar, enquanto duas processos fazê-lo através de uma memória partilhada é bastante difícil - mesmo com ferramentas inteligentes como Boost.interprocess. O Flow-IPC simplifica isto, permitindo a partilha de estruturas compatíveis com STL, como contentores, ponteiros e dados simples. - jemalloc mais SHM: Uma linha de código permite-lhe alocar quaisquer dados necessários na memória partilhada, quer seja para operações de bastidores como a transmissão Cap'n Proto ou diretamente para dados C++ nativos. Essas tarefas podem ser delegadas ao jemalloc, o mecanismo de heap por trás do FreeBSD e do Meta. Este recurso pode ser particularmente valioso para projetos que requerem alocação intensiva de memória compartilhada, semelhante à alocação regular de heap.
- Sem dores de cabeça de nomeação ou limpeza: Com o Flow-IPC, não é necessário nomear sockets de servidor, segmentos SHM ou pipes, nem se preocupar com a fuga de RAM persistente. Em vez disso, estabeleça uma sessão Flow-IPC entre processos: este é o seu contexto IPC. A partir deste objeto de sessão única, os canais de comunicação podem ser abertos à vontade, sem nomeação adicional. Para tarefas que requerem acesso direto à memória partilhada (SHM), está disponível uma arena SHM dedicada. O Flow-IPC efectua uma limpeza automática, mesmo no caso de uma saída anormal, e evita conflitos entre nomes de recursos.
- Uso para RPC: O Flow-IPC foi projetado para complementar, não competir com estruturas de comunicação de alto nível como gRPC e Cap'n Proto RPC. Não há necessidade de escolher entre eles e o Flow-IPC. Na verdade, usar os recursos de cópia zero do Flow-IPC pode geralmente melhorar o desempenho desses protocolos.
Exemplo: Envio de um ficheiro com várias partes
Embora o Flow-IPC possa transmitir dados de vários tipos, decidimos concentrar-nos numa estrutura de dados descrita por um esquema Cap'n Proto (capnp). Este exemplo será particularmente claro para aqueles que estão familiarizados com capnp e Protocol Buffers, mas daremos bastante contexto para aqueles que estão menos familiarizados com estas ferramentas.
Neste exemplo, existem duas aplicações que se envolvem num cenário de pedido-resposta.
- Aplicação 1 (servidor): Este é um servidor de memória cache que tem ficheiros pré-carregados que variam de 100kb a 1GB na RAM. Está pronto para lidar com pedidos de ficheiros em cache e emitir respostas.
- Aplicação 2 (cliente): Este cliente pede um ficheiro de um determinado tamanho. A aplicação 1 (servidor) envia os dados do ficheiro numa única mensagem dividida numa série de pedaços. Cada pedaço inclui os dados juntamente com o seu hash.
# Cap'n Proto schema (.capnp file, generates .h and .c++ source code
# using capnp compiler tool):
$Cxx.namespace("cache_demo::schema");
struct Body
{
union
{
getCacheReq @0 :GetCacheReq;
getCacheRsp @1 :GetCacheRsp;
}
}
struct GetCacheReq
{
fileName @0 :Text;
}
struct GetCacheRsp
{
# We simulate the server returning file multiple parts,
# each (~equally) sized at its discretion.
struct FilePart
{
data @0 :Data;
dataSizeToVerify @1 :UInt64;
# Recipient can verify that `data` blob's size is indeed this.
dataHashToVerify @2 :Hash;
# Recipient can hash `data` and verify it is indeed this.
}
fileParts @0 :List(FilePart);
}O nosso objetivo nesta experiência é fazer um pedido para um ficheiro de tamanho N, receber a resposta, medir o tempo que demorou a ser processado e verificar a integridade de uma parte do ficheiro. Esta interação tem lugar através de um canal de comunicação.
Para fazer isso, precisamos primeiro estabelecer esse canal. Embora o Flow-IPC permita que você estabeleça manualmente um canal a partir de suas partes constituintes de baixo nível (soquete local, fila de mensagens POSIX e mais), é muito mais fácil usar as sessões do Flow-IPC. Uma sessão é simplesmente o contexto de comunicação entre dois processos ativos. Uma vez estabelecidos, os canais estão prontamente disponíveis.
De uma perspetiva geral, eis como funciona o processo.
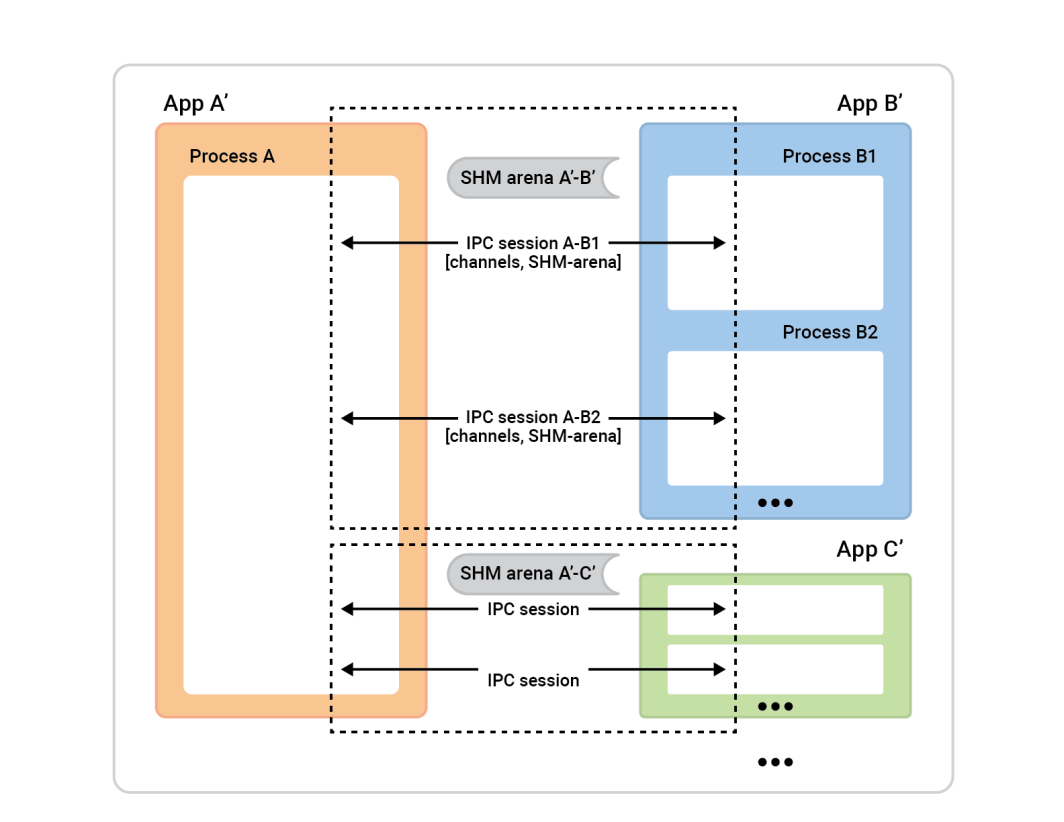
O processo A , à esquerda, é chamado de servidor de sessão. As caixas de processo à direita - clientes de sessão - conectam-se ao processo A para estabelecer sessões. Geralmente, uma dada sessão é completamente simétrica, pelo que não importa quem iniciou a ligação. Ambos os lados são igualmente capazes e pode ser-lhes atribuído qualquer papel algorítmico. No entanto, antes de a sessão estar pronta, precisamos de atribuir papéis. Um lado será o cliente da sessão e executará uma conexão instantânea de uma única sessão, e o outro lado, o servidor da sessão, aceitará quantas sessões quiser.
Neste exemplo, a configuração é simples. Existem duas aplicações com uma sessão entre elas e um canal nessa sessão. O cliente de cache (App 2) desempenha o papel de cliente de sessão, e o papel de servidor de sessão é assumido pela App 1. No entanto, o inverso também funcionaria bem.
Para o configurar, cada aplicação (o cliente e o servidor de cache) deve compreender o mesmo universo IPC, o que significa apenas que precisam de conhecer factos básicos sobre as aplicações envolvidas.
Eis porquê:
- O cliente precisa de saber como localizar o servidor para iniciar uma sessão. Se você é a aplicação de ligação (o cliente), precisa de saber o nome da aplicação de aceitação. O Flow-IPC utiliza o nome do servidor para descobrir detalhes como os endereços de socket e os nomes dos segmentos de memória partilhada com base neste nome.
- A aplicação do servidor tem de saber quem tem permissão para se ligar a ele, por razões de segurança. O Flow-IPC verifica os detalhes do cliente, como o utilizador/grupo e o caminho do executável, em relação ao sistema operativo para garantir que tudo corresponde.
- Os mecanismos de segurança padrão do SO (proprietários, permissões) aplicam-se a vários transportes IPC (sockets, MQs, SHM). Um único seletor
enumdefinirá a política de alto nível a utilizar e o Flow-IPC definirá as permissões de forma tão restritiva quanto possível, respeitando essa escolha.
Para nós, só precisamos de executar o seguinte em cada uma das duas aplicações. Isto pode ser feito numa única .cpp ligado às aplicações cache-server e cache-client.
// IPC app universe: simple structs naming the 2 apps.
// The applications should share this code.
const ipc::session::Client_app
CLI_APP{ "cacheCli", // Name the app uniquely.
// From where it will run (for safety).
"/usr/bin/cache_client.exec",
CLI_UID, GID }; // The user and group ID (for safety).
const ipc::session::Server_app
SRV_APP{ { "cacheSrv", "/usr/bin/cache_server.exec", SRV_UID, GID },
// For the server, provide similar details --^.
// Plus a few server-specific settings:
// Safety: List client-app names that can connect to server-app.
// So in our case this will just be { "cacheCli" }.
{ CLI_APP.m_name },
"", // An optional path override; don't worry about it here.
// Safety/permissions selector:
// We've decided to run the two apps as different users
// in the same group - so we indicate that here.
ipc::util::Permissions_level::S_GROUP_ACCESS }; Note-se que as configurações mais complexas podem ter mais destas definições.
Depois de executar esse código em cada uma das nossas aplicações, passamos simplesmente estes objectos para o construtor do objeto de sessão, para que o servidor saiba o que esperar ao aceitar sessões e o cliente saiba a que servidor se deve ligar.
Vamos então abrir a sessão. No aplicativo 2 (o cliente de cache), queremos apenas abrir uma sessão e um canal dentro dela. Embora o Flow-IPC permita abrir canais instantaneamente a qualquer momento (dado um objeto de sessão), é típico precisar de um determinado número de canais prontos a utilizar no início da sessão. Como queremos abrir um canal, podemos deixar o Flow-IPC criar o canal ao criar a sessão. Isto evita qualquer assincronia desnecessária. Portanto, no início da sessão do nosso cliente de cache main() podemos ligar e abrir um canal com uma única função .sync_connect() chamada:
// Specify that we *do* want zero-copy behavior, by merely choosing our
// backing-session type.
// In other words, setting this alias says, “be fast about Cap’n Proto things.”
//
// Different (subsequent) capnp-serialization-backing and SHM-related behaviors
// are available; just change this alias. E.g., omit `::shm::classic` to disable
// SHM entirely; or specify `::shm::arena_lend::jemalloc` to employ
// jemalloc-based SHM. Subsequent code remains the same!
// This demonstrates a key design tenet of Flow-IPC.
using Session = ipc::session::shm::classic::Client_session<...>;
// Tell Session object about the applications involved.
Session session{ CLI_APP, SRV_APP, /* detail omitted */ };
// Ask for 1 *channel* to be available on both sides
// from the very start of the session.
Session::Channels ipc_raw_channels(1);
// Instantly open session - and the 1 channel.
// (Fail if server is not running at this time.)
session.sync_connect(session.mdt_builder(), &ipc_raw_channels);
auto& ipc_raw_channel = ipc_raw_channels[0];
// (Can also instantly open more channel(s) anytime:
// `session.open_channel(&channel)`.)
Deveríamos ter um ipc_raw_channel now, que é um objeto de canal básico. Dependendo das configurações específicas, ele pode representar um soquete de fluxo do domínio Unix, um MQ POSIX ou outros tipos de canais. Se quiséssemos, poderíamos usá-lo em não estruturado ou seja, podemos utilizá-lo para transmitir blobs binários (com limites preservados) e/ou identificadores nativos (FDs). Também podemos aceder diretamente a uma arena SHM através de session.session_shm()->construct<T>(...). Isto está fora do âmbito da nossa discussão aqui, mas é uma capacidade poderosa que vale a pena mencionar.
Por agora, só queremos falar do Capitão Proto cache_demo::schema::Body (do nosso ficheiro .capnp). Assim, nós atualização o objeto de canal em bruto para um canal estruturado objeto desta forma:
// Template arg indicates capnp schema. (Take a look at the .capnp file above.)
Session::Structured_channel<cache_demo::schema::Body>
ipc_channel
{ nullptr, std::move(ipc_raw_channel), “Eat” the raw channel: take over it.
ipc::transport::struc::Channel_base::S_SERIALIZE_VIA_SESSION_SHM,
&session }; É tudo para a nossa configuração. Agora estamos prontos para trocar mensagens capnp pelo canal. Repare que evitamos lidar com detalhes específicos do sistema operacional, como nomes de objetos, valores de permissões Unix e assim por diante. A nossa abordagem consistiu apenas em dar nomes às nossas duas aplicações. Também optamos pela transmissão de ponta a ponta sem cópia para maximizar o desempenho, aproveitando a memória compartilhada sem um único ::shm_open() ou ::mmap() à vista.
Agora estamos prontos para a parte divertida: emitir o GetCacheReq pedido, recebendo o GetCacheRsp e aceder a várias partes dessa resposta, nomeadamente as partes do ficheiro e os seus hashes.
Aqui está o código:
// Issue request and process response. TIMING FOR LATENCY GRAPH STARTS HERE -->
auto req_msg = ipc_channel.create_msg();
req_msg.body_root() // Vanilla capnp code: call Cap'n Proto-generated mutator API.
->initGetCacheReq().setFileName("huge-file.bin");
// Send message; get ~instant reply.
const auto rsp_msg = ipc_channel.sync_request(req_msg);
// More vanilla capnp work: accessors.
const auto rsp_root = rsp_msg->body_root().getGetCacheRsp();
// <-- TIMING FOR LATENCY GRAPH STOPS HERE.
// ...
verify_hash(rsp_root, some_file_chunk_idx);
// ...
// More vanilla Cap'n Proto accessor code.
void verify_hash(const cache_demo::schema::GetCacheRsp::Reader& rsp_root,
size_t idx)
{
const auto file_part = rsp_root.getFileParts()[idx];
if (file_part.getHashToVerify() != compute_hash(file_part.getData()))
{
throw Bad_hash_exception(...);
}
} No código acima, usámos o simples .sync_request() que envia uma mensagem e aguarda uma resposta específica. O ipc::transport::struc::Channel A API fornece um certo número de funcionalidades para tornar os protocolos naturais para o código, incluindo a receção assíncrona, a desmultiplexação para funções de tratamento por tipo de mensagem, a notificação versus pedido e a mensagem não solicitada versus resposta. Não há restrições impostas ao seu esquema (cache_demo::schema::Body no nosso caso). Se for expressável em capnp, pode utilizá-lo com canais estruturados Flow-IPC.
É isso mesmo! O lado do servidor é semelhante em espírito e nível de dificuldade. Os perf_demo o código-fonte está disponível.
Sem o Flow-IPC, replicar esta configuração para obter um desempenho de cópia zero de ponta a ponta implicaria uma quantidade significativa de código difícil, incluindo a gestão de segmentos SHM cujos nomes e limpeza teriam de ser coordenados entre as duas aplicações. Mesmo sem cópia zero - ou seja, simplesmente ::write()uma cópia da serialização capnp de req_msg para e ::read()ing rsp_msg de um FD de socket de domínio Unix - um código suficientemente robusto não seria trivial de escrever em comparação.
O gráfico abaixo mostra as latências, onde cada ponto no eixo x representa a soma de todos os filePart.data para cada execução de teste. A linha azul mostra as latências do método básico em que o aplicativo 1 grava serializações capnp em um soquete de domínio Unix usando ::write()e a App 2 lê-os com ::read(). A linha laranja representa as latências para o código que usa o Flow-IPC, conforme discutido acima.
Como contribuir
Para pedidos de funcionalidades e relatórios de defeitos, consulte a base de dados de problemas no site Flow-IPC GitHub. Arquive os problemas conforme necessário.
Para contribuir com alterações e novas funcionalidades, consulte o guia de contribuições. Podemos ser contactados no fórum de discussão do Flow-IPC no GitHub.
O que é que se segue?
Tentámos fornecer uma experiência realista no exemplo acima, não ignorando nada de significativo no código apresentado. Escolhemos deliberadamente um cenário que carece de assincronia e de chamadas de retorno. Por conseguinte, surgirão questões como "como integro o Flow-IPC no meu ciclo de eventos?" ou "como lido com o fecho da sessão e do canal? Posso simplesmente abrir um simples socket de stream sem toda esta coisa da sessão?", etc.
Essas questões são abordadas na documentação completa. A documentação inclui uma referência gerada a partir dos comentários da API no código, um manual guiado com uma curva de aprendizagem mais suave e instruções de instalação. O README do repositório principal indica-lhe todos estes recursos. A introdução do Manual e a sinopse da API cobrem a amplitude das funcionalidades disponíveis.
Recursos
- Anúncio de publicação no blogue
- Projeto Flow-IPC no GitHub
Para instalar, ler a documentação, apresentar pedidos de funcionalidades/alterações ou contribuir. - Discussões Flow-IPC
Óptima maneira de nos contactar - e ao resto da comunidade.



Comentários