

최근 저희는 Apache 2.0 및 MIT 라이선스에 따라 프로세스 간 통신 툴킷인 Flow-IPC를 오픈 소스로 출시했습니다. Flow-IPC는 애플리케이션 프로세스 간에 데이터를 전송하고 단순하고 재사용 가능한 코드를 유지하면서 지연 시간을 거의 제로에 가깝게 달성해야 하는 C++ 프로젝트에 유용합니다.
이번 발표에서는 Flow-IPC가 1GB에 달하는 데이터 구조 페이로드를 100K 페이로드만큼 빠르게, 그것도 100마이크로초 이내에 전송할 수 있음을 보여주었습니다. 기존 IPC의 경우 지연 시간은 페이로드 크기에 따라 달라지며 1초대에 달할 수 있습니다. 따라서 개선 효과는 서너 배에 달할 수 있습니다.
이 글에서는 이러한 수치를 생성한 소스 코드를 보여드리겠습니다. Cap'n Proto 통합을 중심으로 한 이 예시는 Flow-IPC가 빠르고 사용하기 쉽다는 것을 보여줍니다. (Flow-IPC API는 다양한 유형의 페이로드 전송을 지원한다는 점에서 포괄적이지만, Cap'n Proto 기반 페이로드 전송은 특정 기능이라는 점에 유의하세요.) Cap'n Proto는 이 블로그 발행일 기준으로 여기에서 확인할 수 있는 라이선스의 적용을 받는 Akamai와 관련이 없는 오픈 소스 프로젝트입니다.
무엇이 포함되나요?
Flow-IPC는 확장 가능한 C++17 API가 포함된 라이브러리입니다. 이 라이브러리는 GitHub에서 호스팅 전체 문서, 자동화된 테스트 및 데모, CI 파이프라인과 함께 제공됩니다. 아래에서 살펴보는 예는 perf_demo 테스트 애플리케이션. Flow-IPC는 현재 x86-64에서 실행되는 Linux를 지원합니다. 향후 수요에 따라 macOS 및 ARM64로 확장할 계획이며, 이후 Windows 및 기타 OS 변형으로 확장할 예정입니다. 사용자는 기여를 환영합니다. 및 포트.
Flow-IPC API는 다양한 개념과 그 구현을 모듈식으로 통합하는 데 중점을 둔 C++ 표준 라이브러리 및 Boost의 정신을 따르고 있습니다. 확장 가능하도록 설계되었습니다. CI 파이프라인은 다양한 GCC 및 Clang 컴파일러 버전과 빌드 구성에 걸쳐 테스트되며, 런타임 살균제를 통한 강화도 포함됩니다: ASAN (메모리 오용에 대한 강화), TSAN (경쟁 조건에 대한 강화), UBSAN (기타 정의되지 않은 동작에 대한 강화) 등이 있습니다.
현재 Flow-IPC는 프로세스 경계를 넘나드는 로컬 통신용이며, 기계 경계를 넘지 않습니다. 그러나 확장 가능한 설계를 갖추고 있으므로 네트워크 IPC로 확장하는 것은 자연스러운 다음 단계입니다. RDMA(원격 직접 메모리 액세스) 의 사용은 초고속 LAN 성능을 위한 흥미로운 가능성을 제공한다고 생각합니다.
누가 사용해야 하나요?
Flow-IPC는 실용적인 프로세스 간 통신 툴킷입니다. 특히 서버 애플리케이션 개발에서 반복적으로 직면하는 IPC 작업에 맞춰 최신 C++ 시스템 개발자의 관점에서 설계되었습니다. 많은 사람들이 한 프로세스에서 다른 프로세스로 무언가를 전송하기 위해 유닉스 도메인 소켓, 네임드 파이프 또는 로컬 HTTP 기반 프로토콜을 조합해야 했습니다. 때로는 이러한 솔루션에 수반되는 복사를 피하기 위해 까다롭고 재사용하기 어려운 기술로 악명 높은 공유 메모리(SHM)를 사용하기도 합니다. Flow-IPC는 일반적인 작업부터 고급 작업까지 이러한 작업에 직면한 모든 C++ 개발자에게 도움을 줄 수 있습니다.
주요 내용은 다음과 같습니다:
- Cap'n Proto 통합: 동급 최강의 Cap'n Proto와 같은 인플레이스 스키마 기반 직렬화를 위한 도구는 프로세스 간 작업에 매우 유용합니다. 하지만 Flow-IPC가 없으면 비트를 소켓이나 파이프 등에 복사한 다음 수신 시 다시 복사해야 합니다. Flow-IPC는 공유 메모리를 사용하여 Cap'n Proto 인코딩 구조의 엔드투엔드 제로 카피 전송을 제공합니다.
- 소켓/FD 지원: Flow-IPC를 통해 전송되는 모든 메시지에는 기본 I/O 핸들(파일 설명자 또는 FD라고도 함)이 포함될 수 있습니다. 예를 들어 웹 서버 아키텍처에서 서버를 엔드포인트 관리 프로세스와 요청 처리 프로세스의 두 가지 프로세스로 나눌 수 있습니다. 엔드포인트 프로세스가 TLS 협상을 완료한 후 연결된 TCP 소켓 핸들을 요청 처리 프로세스에 직접 전달할 수 있습니다.
- 네이티브 C++ 구조 지원: 많은 알고리즘은 C++에서 직접 작업해야 합니다.
struct를 사용하는 경우가 많으며, 대부분 여러 레벨의 STL 컨테이너 및/또는 포인터를 사용하는 경우가 많습니다. 이러한 구조에서 두 개의 스레드가 협업하는 것은 일반적이며 코딩하기 쉬운 반면, 두 개의 프로세스 공유 메모리를 통해 그렇게 하는 것은 매우 어렵습니다. Boost.interprocess. Flow-IPC는 컨테이너, 포인터 및 일반 데이터와 같은 STL 호환 구조를 공유할 수 있도록 하여 이를 간소화합니다. - jemalloc과 SHM: 코드 한 줄로 Cap'n Proto 전송과 같은 백그라운드 작업이나 네이티브 C++ 데이터에 직접 할당하는 등 필요한 모든 데이터를 공유 메모리에 할당할 수 있습니다. 이러한 작업은 FreeBSD와 Meta의 힙 엔진인 jemalloc에 위임할 수 있습니다. 이 기능은 일반 힙 할당과 유사하게 집중적인 공유 메모리 할당이 필요한 프로젝트에 특히 유용할 수 있습니다.
- 이름 지정이나 정리의 번거로움이 없습니다: Flow-IPC를 사용하면 서버 소켓, SHM 세그먼트 또는 파이프의 이름을 지정하거나 영구 RAM 누출을 걱정할 필요가 없습니다. 대신 프로세스 간에 Flow-IPC 세션을 설정하기만 하면 됩니다. 이 단일 세션 개체에서 추가적인 이름 지정 없이도 통신 채널을 마음대로 열 수 있습니다. 직접 공유 메모리(SHM) 액세스가 필요한 작업의 경우 전용 SHM 아레나를 사용할 수 있습니다. Flow-IPC는 비정상 종료 시에도 자동 정리를 수행하며 리소스 이름 간의 충돌을 방지합니다.
- RPC에 사용: Flow-IPC는 gRPC 및 Cap'n Proto RPC와 같은 상위 수준의 통신 프레임워크와 경쟁하는 것이 아니라 보완하도록 설계되었습니다. 이 프레임워크와 Flow-IPC 중 하나를 선택할 필요가 없습니다. 실제로 Flow-IPC의 제로 카피 기능을 사용하면 일반적으로 이러한 프로토콜의 성능을 향상시킬 수 있습니다.
예시: 여러 부분으로 구성된 파일 보내기
Flow-IPC는 다양한 종류의 데이터를 전송할 수 있지만, 여기서는 캡앤프로토(capnp) 스키마로 설명되는 데이터 구조에 초점을 맞추기로 했습니다. 이 예제는 capnp와 프로토콜 버퍼에 익숙한 분들에게는 특히 명확할 것이지만, 이러한 도구에 익숙하지 않은 분들을 위해 충분한 맥락을 제공하겠습니다.
이 예제에는 요청-응답 시나리오에 참여하는 두 개의 앱이 있습니다.
- 앱 1(서버): 메모리 캐싱 서버로, 100kb에서 1GB 범위의 파일이 RAM에 미리 로드되어 있습니다. 캐시된 파일 요청을 처리하고 응답을 발행하기 위해 대기합니다.
- 앱 2(클라이언트): 이 클라이언트는 특정 크기의 파일을 요청합니다. 앱 1(서버)은 파일 데이터를 여러 개의 청크로 나눈 단일 메시지로 전송합니다. 각 청크에는 해시와 함께 데이터가 포함됩니다.
# Cap'n Proto schema (.capnp file, generates .h and .c++ source code
# using capnp compiler tool):
$Cxx.namespace("cache_demo::schema");
struct Body
{
union
{
getCacheReq @0 :GetCacheReq;
getCacheRsp @1 :GetCacheRsp;
}
}
struct GetCacheReq
{
fileName @0 :Text;
}
struct GetCacheRsp
{
# We simulate the server returning file multiple parts,
# each (~equally) sized at its discretion.
struct FilePart
{
data @0 :Data;
dataSizeToVerify @1 :UInt64;
# Recipient can verify that `data` blob's size is indeed this.
dataHashToVerify @2 :Hash;
# Recipient can hash `data` and verify it is indeed this.
}
fileParts @0 :List(FilePart);
}이 실험의 목표는 N 크기의 파일을 요청하고, 응답을 받고, 처리하는 데 걸린 시간을 측정하고, 파일 일부의 무결성을 확인하는 것입니다. 이러한 상호 작용은 통신 채널을 통해 이루어집니다.
이를 위해서는 먼저 이 채널을 설정해야 합니다. Flow-IPC를 사용하면 하위 수준 구성 요소(로컬 소켓, POSIX 메시지 큐 등)에서 채널을 수동으로 설정할 수 있지만, 그 대신 Flow-IPC 세션을 사용하는 것이 훨씬 쉽습니다. 세션은 단순히 두 개의 실시간 프로세스 간의 통신 컨텍스트입니다. 일단 설정되면 채널을 바로 사용할 수 있습니다.
조감도를 통해 프로세스가 어떻게 진행되는지 살펴보세요.
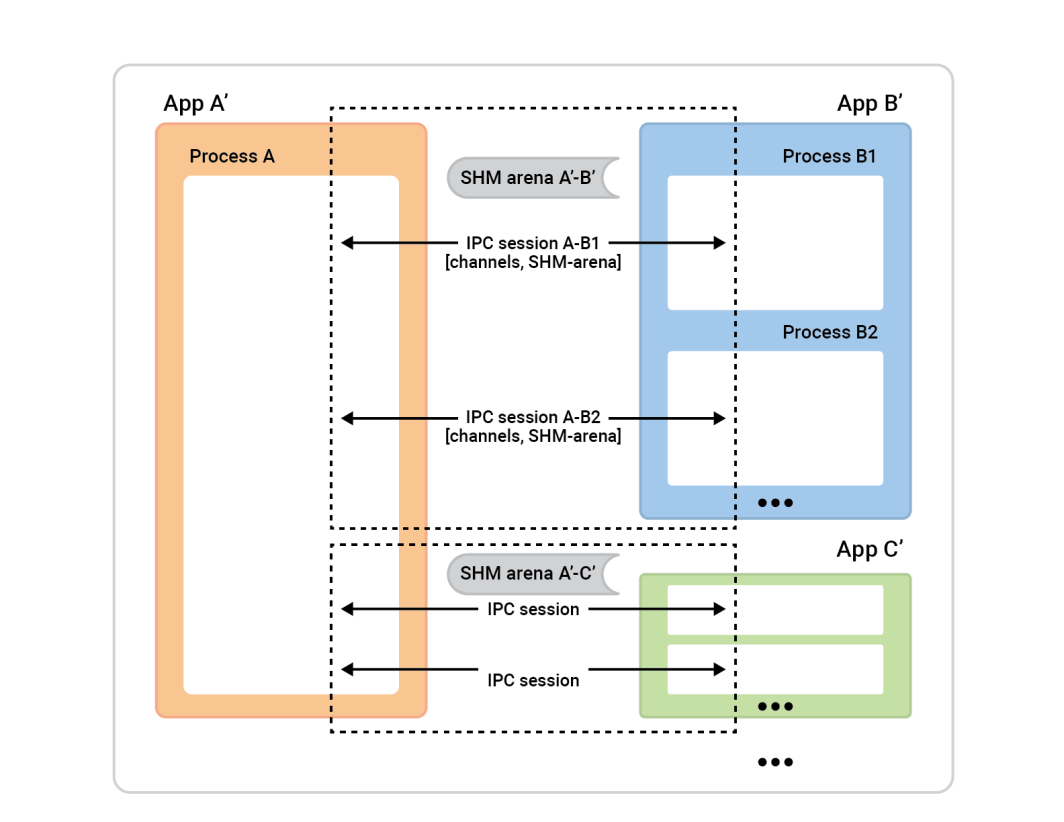
왼쪽의 프로세스 A를 세션 서버라고 합니다. 오른쪽의 프로세스 상자( 세션 클라이언트 )는 세션을 설정하기 위해 프로세스 A에 연결합니다. 일반적으로 주어진 세션은 완전히 대칭이므로 누가 연결을 시작했는지는 중요하지 않습니다. 양쪽 모두 동등한 능력을 갖추고 있으며 어떤 알고리즘 역할도 할당될 수 있습니다. 하지만 세션이 준비되기 전에 역할을 할당해야 합니다. 한 쪽은 세션 클라이언트가 되어 단일 세션의 인스턴트 연결을 수행하고 다른 쪽은 세션 서버가 되어 원하는 만큼 세션을 수락합니다 .
이 예에서는 설정이 간단합니다. 두 앱 사이에 하나의 세션과 해당 세션에 하나의 채널이 있는 두 개의 앱이 있습니다. 캐시 클라이언트(앱 2)는 세션 클라이언트 역할을 하고 세션 서버 역할은 앱 1이 수행합니다. 하지만 그 반대도 정상적으로 작동합니다.
이를 설정하려면 각 애플리케이션(캐시 클라이언트 및 캐시 서버)이 동일한 IPC 세계를 이해해야 하는데, 이는 관련된 애플리케이션에 대한 기본적인 사실을 알아야 한다는 의미입니다.
그 이유는 다음과 같습니다:
- 클라이언트는 세션을 시작하기 위해 서버를 찾는 방법을 알아야 합니다. 연결하는 앱(클라이언트)인 경우 수락하는 앱의 이름을 알아야 합니다. Flow-IPC는 서버의 이름을 사용하여 이 이름을 기반으로 소켓 주소 및 공유 메모리 세그먼트 이름과 같은 세부 정보를 파악합니다.
- 서버 앱은 보안상의 이유로 누가 연결할 수 있는지 알아야 합니다. Flow-IPC는 사용자/그룹 및 실행 경로와 같은 클라이언트의 세부 정보를 운영 체제와 대조하여 모든 것이 일치하는지 확인합니다.
- 표준 OS 안전 메커니즘(소유자, 권한)은 다양한 IPC 전송(소켓, MQ, SHM)에 적용됩니다. 단일 선택기
enum는 사용할 상위 수준의 정책을 설정하고 Flow-IPC는 그 선택을 존중하면서 가능한 한 제한적으로 권한을 설정합니다.
여기서는 두 애플리케이션 각각에서 다음을 실행하기만 하면 됩니다. 이것은 하나의 .cpp 파일을 캐시 서버와 캐시 클라이언트 앱에 모두 연결합니다.
// IPC app universe: simple structs naming the 2 apps.
// The applications should share this code.
const ipc::session::Client_app
CLI_APP{ "cacheCli", // Name the app uniquely.
// From where it will run (for safety).
"/usr/bin/cache_client.exec",
CLI_UID, GID }; // The user and group ID (for safety).
const ipc::session::Server_app
SRV_APP{ { "cacheSrv", "/usr/bin/cache_server.exec", SRV_UID, GID },
// For the server, provide similar details --^.
// Plus a few server-specific settings:
// Safety: List client-app names that can connect to server-app.
// So in our case this will just be { "cacheCli" }.
{ CLI_APP.m_name },
"", // An optional path override; don't worry about it here.
// Safety/permissions selector:
// We've decided to run the two apps as different users
// in the same group - so we indicate that here.
ipc::util::Permissions_level::S_GROUP_ACCESS }; 복잡한 설정일수록 이러한 정의가 더 많이 포함될 수 있습니다.
각 애플리케이션에서 해당 코드를 실행한 후 이러한 객체를 세션 객체 생성자에 전달하면 서버는 세션을 수락할 때 예상되는 사항을 알 수 있고 클라이언트는 연결할 서버를 알 수 있습니다.
이제 세션을 열어 보겠습니다. 앱 2(캐시 클라이언트)에서는 세션과 그 안에 있는 채널만 열려고 합니다. Flow-IPC를 사용하면 세션 객체가 주어지면 언제든지 채널을 즉시 열 수 있지만, 일반적으로 세션 시작 시 일정 수의 즉시 사용 가능한 채널이 필요합니다. 하나의 채널을 열려고 하므로 세션을 만들 때 Flow-IPC가 채널을 만들도록 할 수 있습니다. 이렇게 하면 불필요한 비동시성을 방지할 수 있습니다. 따라서 캐시 클라이언트의 시작 부분에서 main() 기능으로 채널을 연결하고 열 수 있습니다. .sync_connect() 호출합니다:
// Specify that we *do* want zero-copy behavior, by merely choosing our
// backing-session type.
// In other words, setting this alias says, “be fast about Cap’n Proto things.”
//
// Different (subsequent) capnp-serialization-backing and SHM-related behaviors
// are available; just change this alias. E.g., omit `::shm::classic` to disable
// SHM entirely; or specify `::shm::arena_lend::jemalloc` to employ
// jemalloc-based SHM. Subsequent code remains the same!
// This demonstrates a key design tenet of Flow-IPC.
using Session = ipc::session::shm::classic::Client_session<...>;
// Tell Session object about the applications involved.
Session session{ CLI_APP, SRV_APP, /* detail omitted */ };
// Ask for 1 *channel* to be available on both sides
// from the very start of the session.
Session::Channels ipc_raw_channels(1);
// Instantly open session - and the 1 channel.
// (Fail if server is not running at this time.)
session.sync_connect(session.mdt_builder(), &ipc_raw_channels);
auto& ipc_raw_channel = ipc_raw_channels[0];
// (Can also instantly open more channel(s) anytime:
// `session.open_channel(&channel)`.)
우리는 ipc_raw_channel 를 기본 채널 객체로 설정합니다. 특정 설정에 따라 유닉스 도메인 스트림 소켓, POSIX MQ 또는 기타 유형의 채널을 나타낼 수 있습니다. 원한다면 다음에서 사용할 수 있습니다. 구조화되지 않은 패션을 즉시 사용하여 바이너리 블롭(경계가 보존된 상태) 및/또는 기본 핸들(FD)을 전송할 수 있습니다. 또한 다음을 통해 SHM 아레나에 직접 액세스할 수도 있습니다. session.session_shm()->construct<T>(...). 여기서는 논의 범위를 벗어나지만 언급할 만한 가치가 있는 강력한 기능입니다.
지금은 캡틴 프로토의 cache_demo::schema::Body 프로토콜을 사용합니다(.capnp 파일에서). 그래서 우리는 업그레이드 원시 채널 객체를 구조화된 채널 객체처럼:
// Template arg indicates capnp schema. (Take a look at the .capnp file above.)
Session::Structured_channel<cache_demo::schema::Body>
ipc_channel
{ nullptr, std::move(ipc_raw_channel), “Eat” the raw channel: take over it.
ipc::transport::struc::Channel_base::S_SERIALIZE_VIA_SESSION_SHM,
&session }; 설정은 여기까지입니다. 이제 채널을 통해 capnp 메시지를 교환할 준비가 되었습니다. 개체 이름, Unix 권한 값 등과 같은 OS별 세부 정보를 처리하지 않은 것을 주목하세요. 우리의 접근 방식은 단지 두 애플리케이션의 이름만 지정하는 것이었습니다. 또한 엔드투엔드 제로 카피 전송을 선택해 단 하나의 ::shm_open() 또는 ::mmap() 가 보입니다.
이제 재미있는 부분을 준비했습니다. GetCacheReq 요청을 수신하고 GetCacheRsp 응답에 액세스하고 해당 응답의 다양한 부분, 즉 파일 부분과 해당 해시에 액세스합니다.
코드는 다음과 같습니다:
// Issue request and process response. TIMING FOR LATENCY GRAPH STARTS HERE -->
auto req_msg = ipc_channel.create_msg();
req_msg.body_root() // Vanilla capnp code: call Cap'n Proto-generated mutator API.
->initGetCacheReq().setFileName("huge-file.bin");
// Send message; get ~instant reply.
const auto rsp_msg = ipc_channel.sync_request(req_msg);
// More vanilla capnp work: accessors.
const auto rsp_root = rsp_msg->body_root().getGetCacheRsp();
// <-- TIMING FOR LATENCY GRAPH STOPS HERE.
// ...
verify_hash(rsp_root, some_file_chunk_idx);
// ...
// More vanilla Cap'n Proto accessor code.
void verify_hash(const cache_demo::schema::GetCacheRsp::Reader& rsp_root,
size_t idx)
{
const auto file_part = rsp_root.getFileParts()[idx];
if (file_part.getHashToVerify() != compute_hash(file_part.getData()))
{
throw Bad_hash_exception(...);
}
} 위의 코드에서는 간단한 .sync_request() 메시지를 보내고 특정 응답을 기다립니다. 그리고 ipc::transport::struc::Channel API는 비동기 수신, 메시지 유형별 핸들러 함수에 대한 다중화 해제, 알림 대 요청, 요청하지 않은 메시지 대 응답 등 프로토콜을 자연스럽게 코딩할 수 있는 여러 가지 기능을 제공합니다. 스키마에는 제한이 없습니다(cache_demo::schema::Body 로 표현할 수 있습니다.) capnp로 표현할 수 있는 경우 Flow-IPC 구조화 채널과 함께 사용할 수 있습니다.
여기까지입니다! 서버 쪽은 정신과 난이도가 비슷합니다. 서버 측의 perf_demo 소스 코드를 사용할 수 있습니다.
Flow-IPC가 없으면 엔드투엔드 제로 카피 성능을 위해 이 설정을 복제하려면 두 애플리케이션 간에 이름과 정리를 조정해야 하는 SHM 세그먼트 관리를 포함해 상당한 양의 어려운 코드가 필요합니다. 제로 카피 없이도, 즉 단순히 ::write()의 CAPNP 직렬화 사본을 생성합니다. req_msg 및 ::read()ing rsp_msg 유닉스 도메인 소켓 FD에서 충분히 강력한 코드를 작성할 수 있습니다.
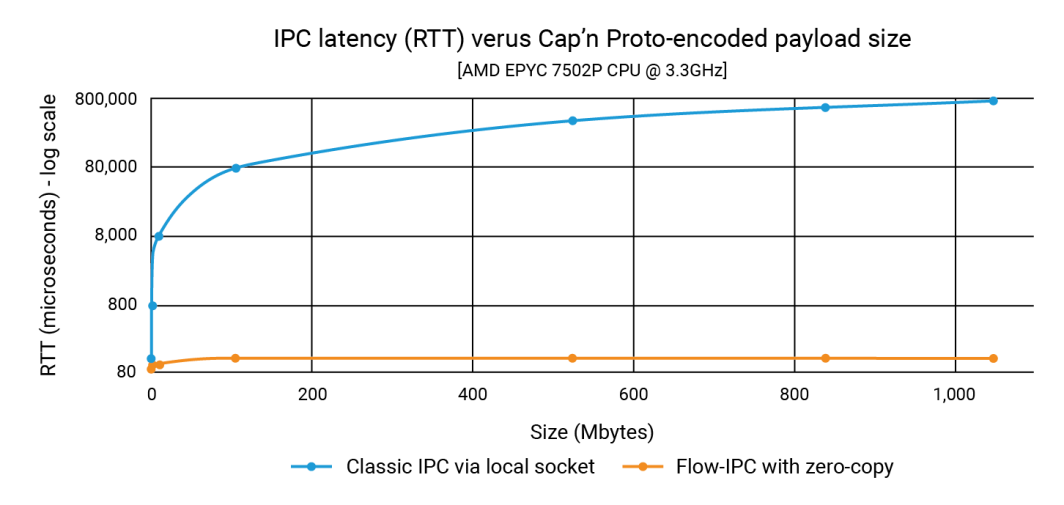
아래 그래프는 지연 시간을 나타내며, X축의 각 점은 모든 지연 시간의 합을 나타냅니다. filePart.data 크기를 비교합니다. 파란색 선은 앱 1이 다음을 사용하여 Unix 도메인 소켓에 capnp 직렬화를 쓰는 기본 방법의 지연 시간을 보여줍니다. ::write()로 읽고, 앱 2는 ::read(). 주황색 선은 위에서 설명한 대로 Flow-IPC를 사용하는 코드의 지연 시간을 나타냅니다.
기여하는 방법
기능 요청 및 결함 보고는 Flow-IPC GitHub 사이트의 이슈 데이터베이스를 참조하세요. 필요에 따라 이슈를 제출하세요.
변경 사항과 새로운 기능을 기여하려면 기여 가이드를 참조하세요. GitHub의 Flow-IPC 토론 게시판에서 문의하실 수 있습니다.
다음 단계는 무엇인가요?
위 예시에서는 현실적인 실험을 제공하기 위해 표시된 코드에서 중요한 부분을 생략했습니다. 일부러 비동기성과 콜백이 없는 시나리오를 선택했습니다. 따라서 "Flow-IPC를 이벤트 루프와 어떻게 통합할 것인가?" 또는 "세션 및 채널 종료를 어떻게 처리할 것인가?"와 같은 질문이 발생할 수 있습니다. 이 모든 세션 없이 간단한 스트림 소켓만 열 수 있나요?" 등과 같은 질문이 발생할 수 있습니다.
이러한 질문은 전체 문서에서 다루고 있습니다. 이 문서에는 코드의 API 주석에서 생성된 참조, 학습 곡선이 완만한 가이드 매뉴얼, 설치 지침이 포함되어 있습니다. 메인 리포지토리의 README에서 이러한 모든 리소스를 찾아볼 수 있습니다. 매뉴얼 소개 와 API 개요에서는 사용 가능한 다양한 기능을 다룹니다.
리소스
- 공지 사항 블로그 게시물
- GitHub의 Flow-IPC 프로젝트
설치, 문서 읽기, 기능/변경 요청 파일 제출 또는 기여하기. - 플로우-IPC 토론
저희는 물론 다른 커뮤니티와 소통할 수 있는 좋은 방법입니다.



내용