

We recently released Flow-IPC – an interprocess communication toolkit in C++ – as open source under the Apache 2.0 and MIT licenses. Flow-IPC will be useful for C++ projects that transmit data between application processes and need to achieve near-zero latency without a trade-off against simple and reusable code.
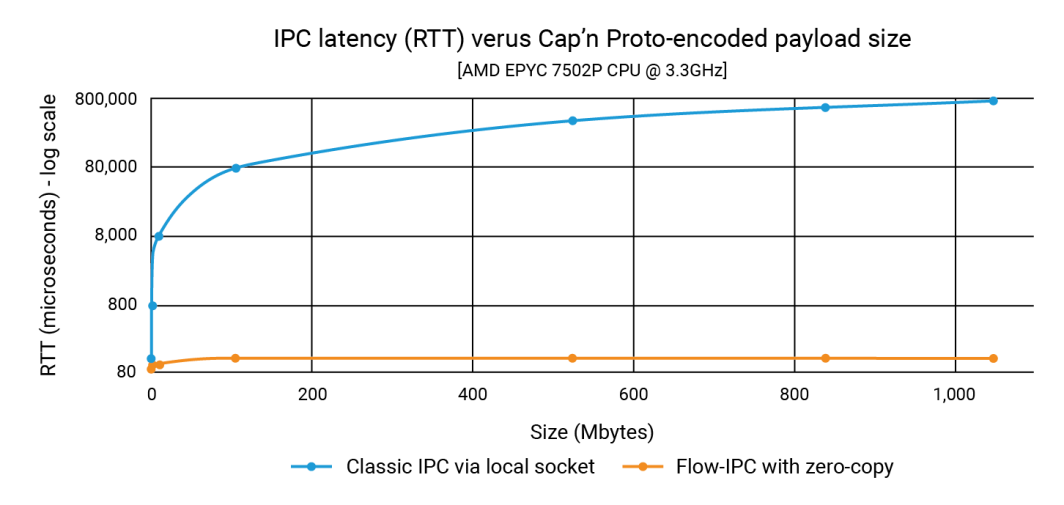
In the announcement, we showed that Flow-IPC can transmit data structure payloads as large as 1GB just as quickly as a 100K payload– and in less than 100 microseconds. With classic IPC, the latency depends on the payload size and can reach into the 1 second range. Thus the improvement can be as much as three or four orders of magnitude.
In this post, we show the source code that produced those numbers. Our example, which centers on the Cap’n Proto integration, shows that Flow-IPC is both fast and easy to use. (Note that the Flow-IPC API is comprehensive in that it supports transmitting various types of payloads, but the Cap’n Proto-based payload transmission is a specific feature.) Cap’n Proto is an open source project not affiliated with Akamai whose use is subject to the license, as of the date of this blog’s publication date, found here.
What’s Included?
Flow-IPC is a library with an extensible C++17 API. It is hosted in GitHub together with full documentation, automated tests and demos, and a CI pipeline. The example we explore below is the perf_demo test application. Flow-IPC currently supports Linux running on x86-64. We have plans to expand this to macOS and ARM64, followed by Windows and other OS variants depending on demand. You’re welcome to contribute and port.
The Flow-IPC API is in the spirit of the C++ standard library and Boost, focusing on integrating various concepts and their implementations in a modular way. It is designed to be extensible. Our CI pipeline tests across a range of GCC and Clang compiler versions and build configurations, including hardening via runtime sanitizers: ASAN (hardens against memory misuse), TSAN (against race conditions), and UBSAN (against miscellaneous undefined behavior).
At this time, Flow-IPC is for local communication: crossing process boundaries but not machine boundaries. However it has an extensible design, so expanding it to networked IPC is a natural next step. We think the use of Remote Direct Memory Access (RDMA) provides an intriguing possibility for ultra-fast LAN performance.
Who Should Use It?
Flow-IPC is a pragmatic inter-process communication toolkit. In designing it, we came from the perspective of the modern C++ systems developer, specifically tailoring it to the IPC tasks one faces repeatedly, particularly in server application development. Many of us have had to throw together a Unix-domain-socket, named-pipe, or local HTTP-based protocol to transmit something from one process to another. Sometimes, to avoid the copying involved in such solutions, one might turn to shared-memory (SHM), a notoriously touchy and hard-to-reuse technique. Flow-IPC can help any C++ developer faced with such tasks, from common to advanced.
Highlights include:
- Cap’n Proto integration: Tools for in-place schema-based serialization like Cap’n Proto, which is best-in-class, are very helpful for inter-process work. However, without Flow-IPC, you’d still have to copy the bits into a socket or pipe, etc., and then copy them again on receipt. Flow-IPC provides end-to-end zero-copy transmission of Cap’n Proto-encoded structures using shared memory.
- Socket/FD support: Any message transmitted via Flow-IPC can include a native I/O handle (also known as a file descriptor or FD). For example, in a web server architecture, you could split the server into two processes: a process for managing endpoints and a process for processing requests. After the endpoint process completes the TLS negotiation, it can pass the connected TCP socket handle directly to the request processing process.
- Native C++ structure support: Many algorithms require work directly on C++
structs, most often ones involving multiple levels of STL containers and/or pointers. Two threads collaborating on such a structure is common and easy to code whereas two processes doing so via shared-memory is quite hard – even with thoughtful tools like Boost.interprocess. Flow-IPC simplifies this by enabling sharing of STL-compliant structures like containers, pointers, and plain-old-data. - jemalloc plus SHM: One line of code allows you to allocate any necessary data in shared memory, whether it’s for behind the scenes operations like Cap’n Proto transmission or directly for native C++ data. These tasks can be delegated to jemalloc, the heap engine behind FreeBSD and Meta. This feature can be particularly valuable for projects that require intensive shared memory allocation, similar to regular heap allocation.
- No naming or cleanup headaches: With Flow-IPC, you need not name server-sockets, SHM segments, or pipes, or worry about leaked persistent RAM. Instead, establish a Flow-IPC session between processes: this is your IPC context. From this single session object, communication channels can be opened at will, without additional naming. For tasks that require direct shared memory (SHM) access, a dedicated SHM arena is available. Flow-IPC performs automatic cleanup, even in the case of an abnormal exit, and it avoids conflicts among resource names.
- Use for RPC: Flow-IPC is designed to complement, not compete with higher-level communication frameworks like gRPC and Cap’n Proto RPC. There’s no need to choose between them and Flow-IPC. In fact, using Flow-IPC’s zero-copy features can generally enhance the performance of these protocols.
Example: Sending a Multi-Part File
While Flow-IPC can transmit data of various kinds, we decided to focus on a data structure described by a Cap’n Proto (capnp) schema. This example will be particularly clear to those familiar with capnp and Protocol Buffers, but we’ll give plenty of context for those who are less familiar with these tools.
In this example, there are two apps that engage in a request-response scenario.
- App 1 (server): This is a memory-caching server that has pre-loaded files ranging from 100kb to 1GB into RAM. It stands by to handle get-cached file requests and issue responses.
- App 2 (client): This client requests a file of a certain size. App 1 (server) sends the file data in a single message broken down into a series of chunks. Each chunk includes the data along with its hash.
# Cap'n Proto schema (.capnp file, generates .h and .c++ source code
# using capnp compiler tool):
$Cxx.namespace("cache_demo::schema");
struct Body
{
union
{
getCacheReq @0 :GetCacheReq;
getCacheRsp @1 :GetCacheRsp;
}
}
struct GetCacheReq
{
fileName @0 :Text;
}
struct GetCacheRsp
{
# We simulate the server returning file multiple parts,
# each (~equally) sized at its discretion.
struct FilePart
{
data @0 :Data;
dataSizeToVerify @1 :UInt64;
# Recipient can verify that `data` blob's size is indeed this.
dataHashToVerify @2 :Hash;
# Recipient can hash `data` and verify it is indeed this.
}
fileParts @0 :List(FilePart);
}Our goal in this experiment is to issue a request for an N-sized file, receive the response, measure the time it took to process, and check the integrity of a part of the file. This interaction takes place through a communication channel.
To do this, we need to first establish this channel. While Flow-IPC allows you to manually establish a channel from its low-level constituent parts (local socket, POSIX message queue, and more), it is much easier to use Flow-IPC sessions instead. A session is simply the communication context between two live processes. Once established, channels are readily available.
From a bird’s eye view, here’s how the process works.
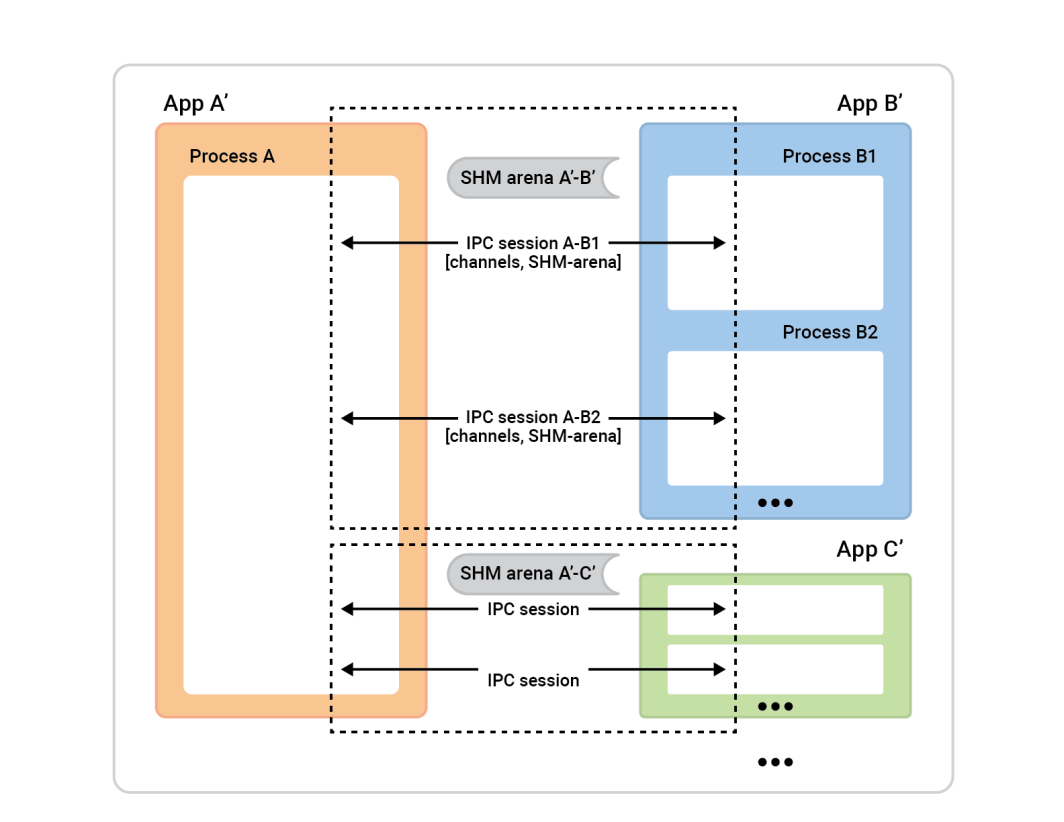
Process A on the left is called the session-server. The process boxes on the right – session-clients – connect to Process A in order to establish sessions. Generally, any given session is completely symmetrical, so it doesn’t matter who initiated the connection. Both sides are equally capable and can be assigned any algorithmic role. Before the session is ready, though, we’ll need to assign roles. One side will be the session-client and will perform an instant connect of a single session, and the other side, the session-server, will accept as many sessions as it wants.
In this example, the setup is straightforward. There are two apps with one session between them and one channel in that session. The cache-client (App 2) plays the role of session-client, and the session-server role is taken by App 1. However, the reverse would work fine as well.
To set this up, each application (the cache-client and cache-server) must understand the same IPC universe, which just means that they need to know basic facts about the applications involved.
Here’s why:
- The client needs to know how to locate the server to initiate a session. If you’re the connecting-app (the client), you need to know the name of the accepting-app. Flow-IPC uses the server’s name to figure out details like the socket addresses and shared-memory segment names based on this name.
- The server app must know who’s allowed to connect to it, for security reasons. Flow-IPC checks the client’s details, like user/group and executable path, against the operating system to ensure everything matches up.
- Standard OS safety mechanisms (owners, permissions) apply to various IPC transports (sockets, MQs, SHM). A single selector
enumwill set the high-level policy to use and Flow-IPC will then set permissions as restrictively as possible while respecting that choice.
For us, we will just need to execute the following in each of the two applications. This can be in a single .cpp file linked into both the cache-server and cache-client apps.
// IPC app universe: simple structs naming the 2 apps.
// The applications should share this code.
const ipc::session::Client_app
CLI_APP{ "cacheCli", // Name the app uniquely.
// From where it will run (for safety).
"/usr/bin/cache_client.exec",
CLI_UID, GID }; // The user and group ID (for safety).
const ipc::session::Server_app
SRV_APP{ { "cacheSrv", "/usr/bin/cache_server.exec", SRV_UID, GID },
// For the server, provide similar details --^.
// Plus a few server-specific settings:
// Safety: List client-app names that can connect to server-app.
// So in our case this will just be { "cacheCli" }.
{ CLI_APP.m_name },
"", // An optional path override; don't worry about it here.
// Safety/permissions selector:
// We've decided to run the two apps as different users
// in the same group - so we indicate that here.
ipc::util::Permissions_level::S_GROUP_ACCESS }; Note that more complex setups can have more of these definitions.
Having executed that code in each of our applications, we’ll simply pass these objects into the session object constructor so that the server will know what to expect when accepting sessions and the client will know which server to connect to.
So let’s open the session. In App 2 (the cache-client), we just want to open a session and a channel within it. While Flow-IPC allows instantly opening channels anytime (given a session object), it is typical to need a certain number of ready-to-go channels at the start of the session. Since we want to open one channel, we can let Flow-IPC create the channel when creating the session. This avoids any unnecessary asynchronicity. So, at the beginning of our cache-client’s main() function, we can connect and open a channel with a single .sync_connect() call:
// Specify that we *do* want zero-copy behavior, by merely choosing our
// backing-session type.
// In other words, setting this alias says, “be fast about Cap’n Proto things.”
//
// Different (subsequent) capnp-serialization-backing and SHM-related behaviors
// are available; just change this alias. E.g., omit `::shm::classic` to disable
// SHM entirely; or specify `::shm::arena_lend::jemalloc` to employ
// jemalloc-based SHM. Subsequent code remains the same!
// This demonstrates a key design tenet of Flow-IPC.
using Session = ipc::session::shm::classic::Client_session<...>;
// Tell Session object about the applications involved.
Session session{ CLI_APP, SRV_APP, /* detail omitted */ };
// Ask for 1 *channel* to be available on both sides
// from the very start of the session.
Session::Channels ipc_raw_channels(1);
// Instantly open session - and the 1 channel.
// (Fail if server is not running at this time.)
session.sync_connect(session.mdt_builder(), &ipc_raw_channels);
auto& ipc_raw_channel = ipc_raw_channels[0];
// (Can also instantly open more channel(s) anytime:
// `session.open_channel(&channel)`.)
We should have a ipc_raw_channel now, which is a basic channel object. Depending on specific settings, this could represent a Unix-domain stream socket, a POSIX MQ, or other types of channels. If we wanted to, we could use it in unstructured fashion immediately, meaning we could use it to transmit binary blobs (with boundaries preserved) and/or native handles (FDs). We could also directly access an SHM arena via session.session_shm()->construct<T>(...). This is outside our discussion scope here, but it’s a powerful capability worth mentioning.
For now, we just want to speak the Cap’n Proto cache_demo::schema::Body protocol (from our .capnp file). So we upgrade the raw channel object to a structured channel object like so:
// Template arg indicates capnp schema. (Take a look at the .capnp file above.)
Session::Structured_channel<cache_demo::schema::Body>
ipc_channel
{ nullptr, std::move(ipc_raw_channel), “Eat” the raw channel: take over it.
ipc::transport::struc::Channel_base::S_SERIALIZE_VIA_SESSION_SHM,
&session }; That’s it for our setup. We are now ready to exchange capnp messages over the channel. Notice that we’ve bypassed dealing with OS specific details like object names, Unix permissions values, and so on. Our approach was merely to name our two applications. We also opted for end-to-end zero-copy transmission to maximize performance by leveraging shared-memory without a single ::shm_open() or ::mmap() in sight.
We are now ready for the fun part: issuing the GetCacheReq request, receiving the GetCacheRsp response, and accessing various parts of that response, namely the file parts and their hashes.
Here’s the code:
// Issue request and process response. TIMING FOR LATENCY GRAPH STARTS HERE -->
auto req_msg = ipc_channel.create_msg();
req_msg.body_root() // Vanilla capnp code: call Cap'n Proto-generated mutator API.
->initGetCacheReq().setFileName("huge-file.bin");
// Send message; get ~instant reply.
const auto rsp_msg = ipc_channel.sync_request(req_msg);
// More vanilla capnp work: accessors.
const auto rsp_root = rsp_msg->body_root().getGetCacheRsp();
// <-- TIMING FOR LATENCY GRAPH STOPS HERE.
// ...
verify_hash(rsp_root, some_file_chunk_idx);
// ...
// More vanilla Cap'n Proto accessor code.
void verify_hash(const cache_demo::schema::GetCacheRsp::Reader& rsp_root,
size_t idx)
{
const auto file_part = rsp_root.getFileParts()[idx];
if (file_part.getHashToVerify() != compute_hash(file_part.getData()))
{
throw Bad_hash_exception(...);
}
} In the code above we used the simple .sync_request() which both sends a message and awaits a specific response. The ipc::transport::struc::Channel API provides a number of niceties to make protocols natural to code, including async receiving, demultiplexing to handler functions by message type, notification versus request, and unsolicited-message versus response. There are no restrictions placed on your schema (cache_demo::schema::Body in our case). If it is expressible in capnp, you can use it with Flow-IPC structured channels.
That’s it! The server side is similar in spirit and level of difficulty. The perf_demo source code is available.
Without Flow-IPC, replicating this setup for end-to-end zero-copy performance would involve a significant amount of difficult code, including management of SHM segments whose names and cleanup would have to be coordinated between the two applications. Even without zero-copy – i.e., simply ::write()ing a copy of the capnp serialization of req_msg to and ::read()ing rsp_msg from a Unix domain socket FD – sufficiently robust code would be non-trivial to write in comparison.
The graph below shows the latencies, where each point on the x-axis represents the sum of all filePart.data sizes for each given test run. The blue line shows the latencies from the basic method where App 1 writes capnp serializations to a Unix domain socket using ::write(), and App 2 reads them with ::read(). The orange line represents the latencies for the code using Flow-IPC, as discussed above.
How to Contribute
For feature requests and defect reports, please look at the Issue database on the Flow-IPC GitHub site. File Issues as needed.
To contribute changes and new features, please consult the contribution guide. We can be reached at the Flow-IPC discussions board on GitHub.
What’s Next?
We tried to provide a realistic experiment in the above example, skipping nothing significant in the code shown. We did deliberately choose a scenario that lacks asynchronicity and callbacks. Accordingly, questions will arise, such as, “how do I integrate Flow-IPC with my event loop?” or, “how do I handle session and channel closing? Can I just open a simple stream socket without all this session stuff?”, etc.
Such questions are addressed in the full documentation. The docs include a reference generated from API comments in the code, a guided Manual with a gentler learning curve, and installation instructions. The main repository’s README will point you to all of these resources. The Manual intro and API synopsis cover the breadth of available features.
Resources
- Announcement Blog Post
- Flow-IPC Project at GitHub
To install, read documentation, file feature/change requests, or contribute. - Flow-IPC Discussions
Great way to reach us – and the rest of the community.



Comments