

TL;DR : dans cet article, vous apprendrez à redimensionner de manière proactive vos charges de travail avant un pic de trafic en utilisant KEDA et le scaler cron.
Lors de la conception d'un cluster Kubernetes, vous devrez peut-être répondre à des questions telles que :
- Combien de temps faut-il à la grappe pour évoluer ?
- Combien de temps dois-je attendre avant qu'un nouveau pod ne soit créé ?
Quatre facteurs importants influencent la mise à l'échelle :
- Temps de réaction du Pod Autoscaler horizontal ;
- Temps de réaction du Cluster Autoscaler ;
- le temps d'approvisionnement des nœuds ; et
- l'heure de création du pod.
Examinons-les un par un.
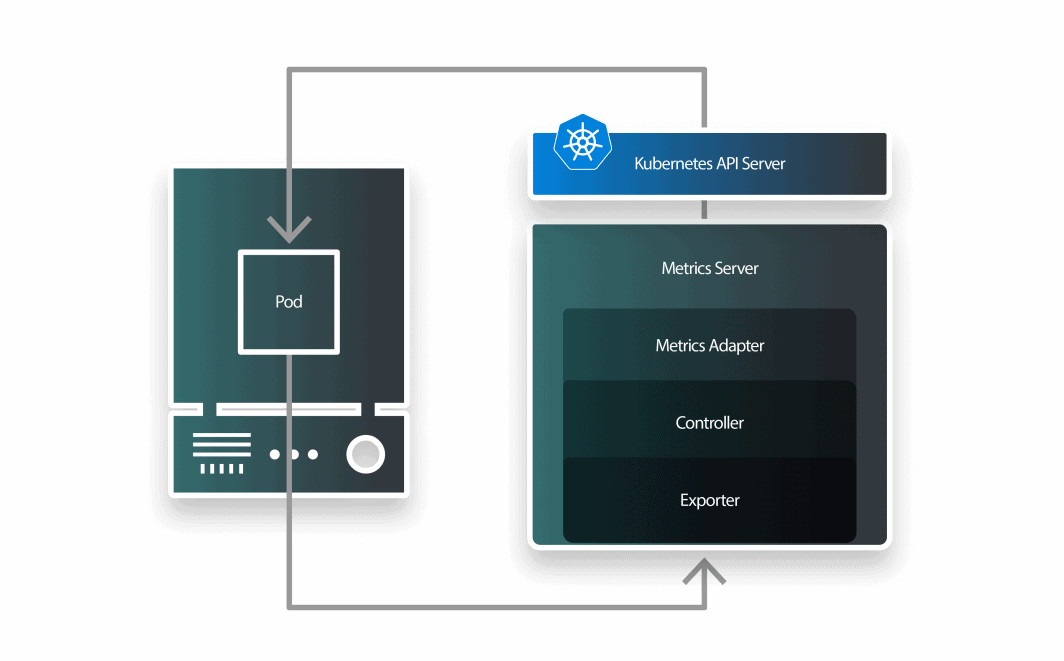
Par défaut, l'utilisation du CPU des pods est récupérée par kubelet toutes les 10 secondes, et obtenue de kubelet par Metrics Server toutes les 1 minutes.
Le Pod Autoscaler Horizontal vérifie les mesures de CPU et de mémoire toutes les 30 secondes.
Si les métriques dépassent le seuil, l'autoscaler augmentera le nombre de réplicas et s'arrêtera pendant 3 minutes avant de prendre d'autres mesures. Dans le pire des cas, il peut s'écouler jusqu'à 3 minutes avant que les pods ne soient ajoutés ou supprimés, mais en moyenne, il faut compter 1 minute pour que l'Horizontal Pod Autoscaler déclenche la mise à l'échelle.

Le Cluster Autoscaler vérifie s'il y a des pods en attente et augmente la taille du cluster. La détection de la nécessité d'augmenter la taille du cluster peut prendre plusieurs heures:
- Jusqu'à 30 secondes sur les clusters de moins de 100 nœuds et 3000 pods, avec une latence moyenne d'environ cinq secondes ; ou
- Jusqu'à 60 secondes de latence sur les clusters de plus de 100 nœuds, avec une latence moyenne d'environ 15 secondes.
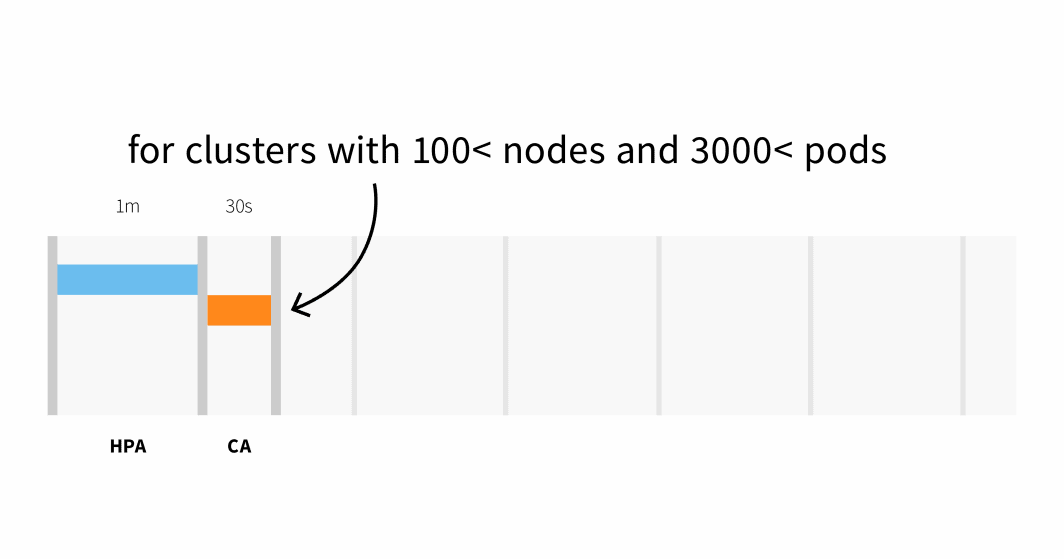
Le provisionnement des nœuds sur Linode prend généralement 3 à 4 minutes entre le moment où le Cluster Autoscaler déclenche l'API et le moment où les pods peuvent être planifiés sur les nœuds nouvellement créés.
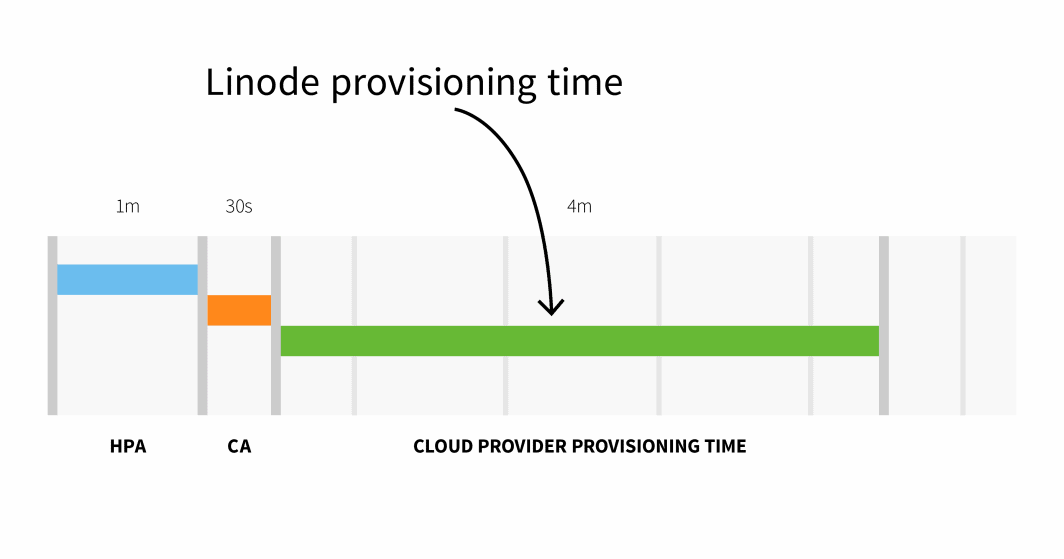
En résumé, avec une petite grappe, vous avez :
```
HPA delay: 1m +
CA delay: 0m30s +
Cloud provider: 4m +
Container runtime: 0m30s +
=========================
Total 6m
```
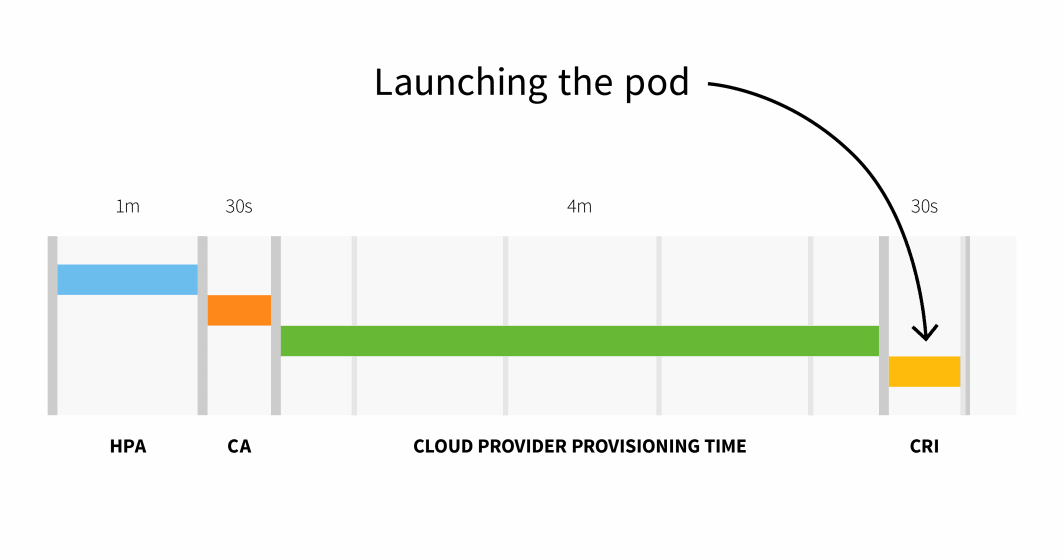
Avec un cluster de plus de 100 nœuds, le délai total peut atteindre 6 minutes et 30 secondes... c'est beaucoup, alors comment remédier à ce problème ?
Vous pouvez faire évoluer vos charges de travail de manière proactive ou, si vous connaissez bien vos modèles de trafic, vous pouvez faire évoluer vos charges de travail à l'avance.
Mise à l'échelle préemptive avec KEDA
Si votre trafic est prévisible, il est logique d'augmenter vos charges de travail (et vos nœuds) avant les pics de trafic et de les réduire lorsque le trafic diminue.
Kubernetes ne fournit aucun mécanisme permettant de dimensionner les charges de travail en fonction de dates ou d'heures. Dans cette partie, vous utiliserez donc KEDA,le Kubernetes Event Driven Autoscaler.
KEDA est un autoscaler composé de trois éléments :
- un mesureur ;
- un adaptateur de métriques ; et
- un contrôleur.
Vous pouvez installer KEDA avec Helm :
```bash
$ helm repo add kedacore https://kedacore.github.io/charts
$ helm install keda kedacore/keda
```Maintenant que Prometheus et KEDA sont installés, créons un déploiement.
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
replicas: 1
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
spec:
containers:
- name: podinfo
image: stefanprodan/podinfoVous pouvez soumettre la ressource au cluster avec :
```bash
$ kubectl apply -f deployment.yaml
```KEDA s'appuie sur l'autoscaler de pods horizontaux existant et l'enveloppe d'une définition de ressource personnalisée appelée ScaleObject.
Le ScaledObject suivant utilise le Cron Scaler pour définir une fenêtre temporelle dans laquelle le nombre de répliques doit être modifié :
```yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 1
scaleTargetRef:
name: podinfo
triggers:
- type: cron
metadata:
timezone: Europe/London
start: 23 * * * *
end: 28 * * * *
desiredReplicas: "5"
```Vous pouvez soumettre l'objet avec :
```bash
$ kubectl apply -f scaled-object.yaml
```Que se passera-t-il ensuite ? Rien. L'échelle automatique ne se déclenchera qu'entre 23 * * * * et 28 * * * *. Avec l'aide de Cron Guruvous pouvez traduire les deux expressions cron en :
- Commencez à la minute 23 (par exemple 2:23, 3:23, etc.).
- Arrêtez-vous à la minute 28 (par exemple 2:28, 3:28, etc.).
Si vous attendez la date de démarrage, vous remarquerez que le nombre de répliques passe à 5.
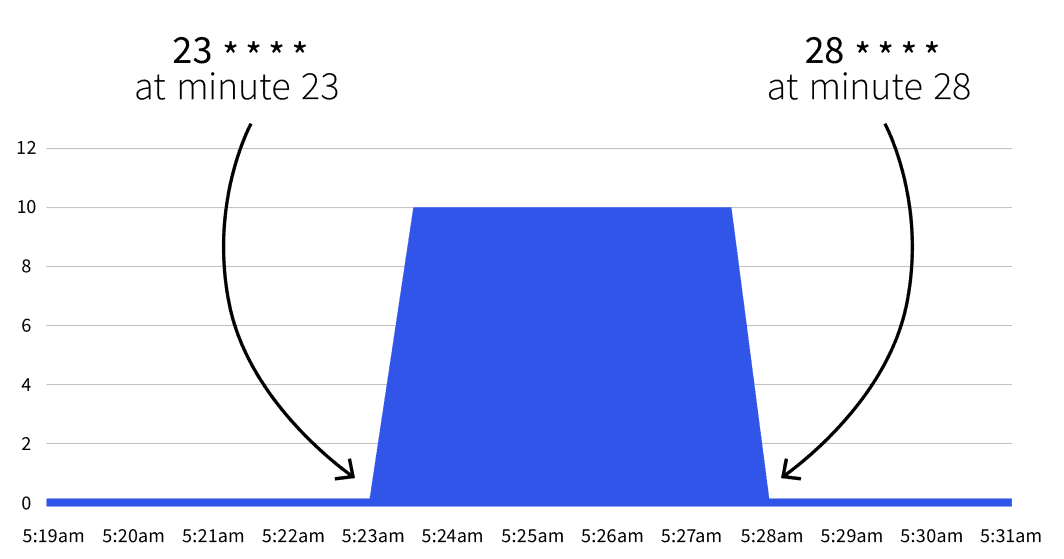
Le nombre revient-il à 1 après la 28e minute ? Oui, l'autoscaler revient au nombre de répliques spécifié dans la section minReplicaCount.
Que se passe-t-il si vous augmentez le nombre de réplicas entre deux intervalles ? Si, entre les minutes 23 et 28, vous augmentez votre déploiement à 10 réplicas, KEDA écrasera votre changement et fixera le nombre de réplicas. Si vous répétez la même expérience après la 28e minute, le nombre de répliques sera fixé à 10. Maintenant que vous connaissez la théorie, examinons quelques cas d'utilisation pratiques.
Réduire la consommation pendant les heures de travail
Vous avez un déploiement dans un environnement de développement qui doit être actif pendant les heures de travail et doit être désactivé pendant la nuit.
Vous pouvez utiliser le ScaledObject suivant :
```yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 0
scaleTargetRef:
name: podinfo
triggers:
- type: cron
metadata:
timezone: Europe/London
start: 0 9 * * *
end: 0 17 * * *
desiredReplicas: "10"
```Le nombre de réplicas par défaut est de zéro, mais pendant les heures de travail (de 9 heures à 17 heures), le nombre de réplicas est porté à 10.
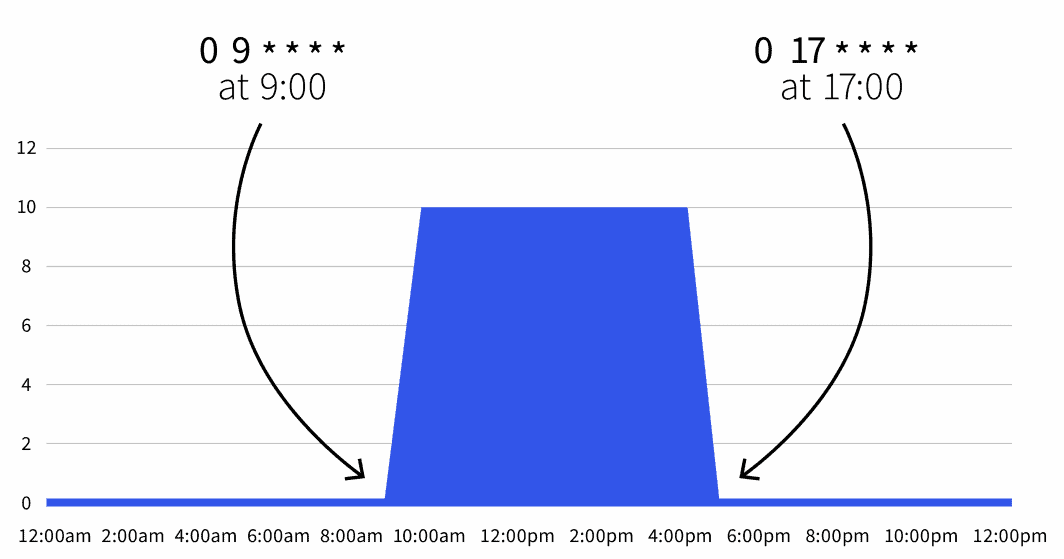
Vous pouvez également développer l'objet mis à l'échelle pour exclure le week-end :
```yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 0
scaleTargetRef:
name: podinfo
triggers:
- type: cron
metadata:
timezone: Europe/London
start: 0 9 * * 1-5
end: 0 17 * * 1-5
desiredReplicas: "10"
```Aujourd'hui, votre charge de travail n'est active que de 9 à 5, du lundi au vendredi. Comme vous pouvez combiner plusieurs déclencheurs, vous pouvez également inclure des exceptions.
Réduction d'échelle pendant les week-ends
Par exemple, si vous prévoyez de maintenir vos charges de travail actives plus longtemps le mercredi, vous pouvez utiliser la définition suivante :
```yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 0
scaleTargetRef:
name: podinfo
triggers:
- type: cron
metadata:
timezone: Europe/London
start: 0 9 * * 1-5
end: 0 17 * * 1-5
desiredReplicas: "10"
- type: cron
metadata:
timezone: Europe/London
start: 0 17 * * 3
end: 0 21 * * 3
desiredReplicas: "10"
```Dans cette définition, la charge de travail est active de 9 à 17 heures du lundi au vendredi, sauf le mercredi, qui se déroule de 9 à 21 heures.
Résumé
L'autoscaler KEDA cron vous permet de définir une plage de temps dans laquelle vous souhaitez mettre à l'échelle vos charges de travail.
Cela vous permet de dimensionner les pods avant les pics de trafic, ce qui déclenchera le Cluster Autoscaler à l'avance.
Dans cet article, vous avez appris :
- Fonctionnement du Cluster Autoscaler.
- Le temps nécessaire pour évoluer horizontalement et ajouter des nœuds à votre cluster.
- Comment mettre à l'échelle des applications basées sur des expressions cron avec KEDA.
Vous voulez en savoir plus ? Inscrivez-vous pour voir cette solution en action lors de notre webinaire en partenariat avec les services de cloud computing d'Akamai.




Commentaires