


TL;DR: In diesem Artikel erfahren Sie, wie Sie Ihre Workloads proaktiv skalieren können, bevor eine Verkehrsspitze auftritt, indem Sie KEDA und den Cron-Skalierer verwenden.
Beim Entwurf eines Kubernetes-Clusters müssen Sie möglicherweise Fragen wie diese beantworten:
- Wie lange dauert es, bis der Cluster skaliert ist?
- Wie lange muss ich warten, bis ein neuer Pod erstellt wird?
Es gibt vier wichtige Faktoren, die die Skalierung beeinflussen:
- Reaktionszeit des horizontalen Pod-Autoscalers;
- Cluster-Autoscaler-Reaktionszeit;
- Zeit für die Bereitstellung von Knoten; und
- Pod-Erstellungszeit.
Lassen Sie uns diese nacheinander untersuchen.
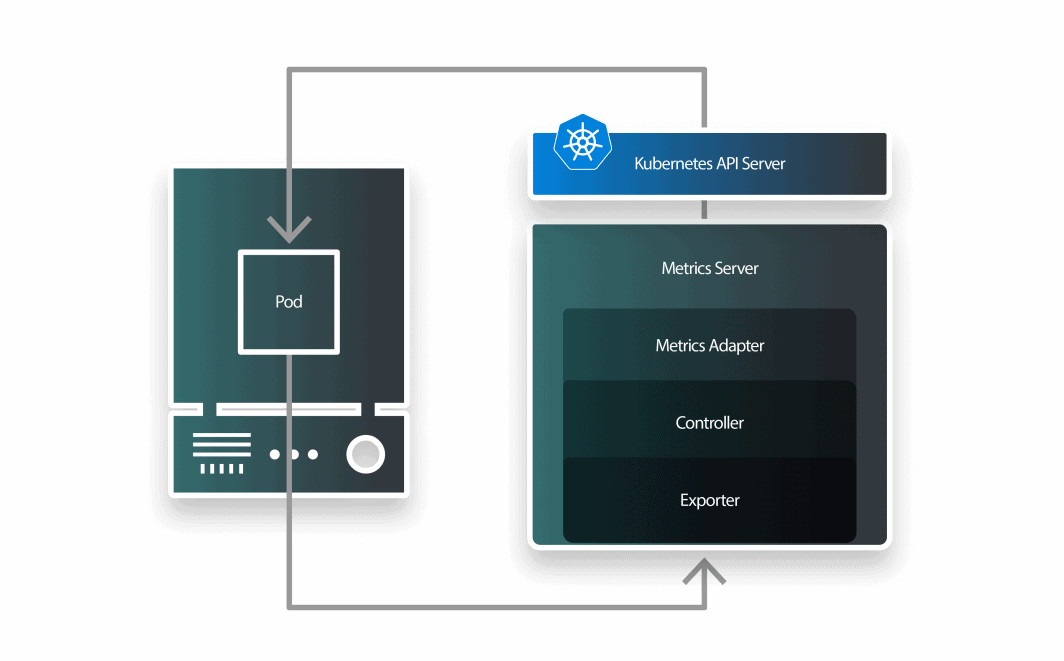
Standardmäßig wird die CPU-Auslastung der Pods von kubelet alle 10 Sekunden abgefragt und von kubelet durch Metrics Server alle 1 Minute abgerufen.
Der horizontale Pod-Autoscaler überprüft alle 30 Sekunden die CPU- und Speichermetriken.
Wenn die Metriken den Schwellenwert überschreiten, erhöht der Autoscaler die Anzahl der Replikate und zieht sich für 3 Minuten zurück, bevor er weitere Maßnahmen ergreift. Im schlimmsten Fall kann es bis zu 3 Minuten dauern, bevor Pods hinzugefügt oder gelöscht werden. Im Durchschnitt sollten Sie jedoch mit einer Minute Wartezeit rechnen, bis der horizontale Pod-Autoscaler die Skalierung auslöst.

Der Cluster-Autoscaler prüft, ob es ausstehende Pods gibt und erhöht die Größe des Clusters. Die Erkennung, dass der Cluster vergrößert werden muss , kann dauern:
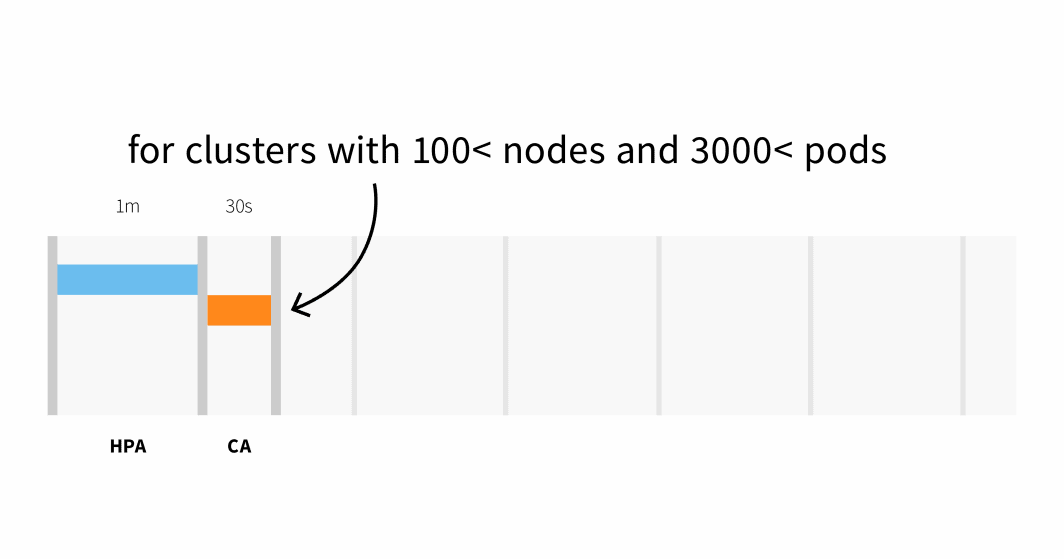
- Bis zu 30 Sekunden auf Clustern mit weniger als 100 Knoten und 3000 Pods, mit einer durchschnittlichen Latenzzeit von etwa fünf Sekunden; oder
- Bis zu 60 Sekunden Latenzzeit auf Clustern mit mehr als 100 Knoten, mit einer durchschnittlichen Latenz von etwa 15 Sekunden.
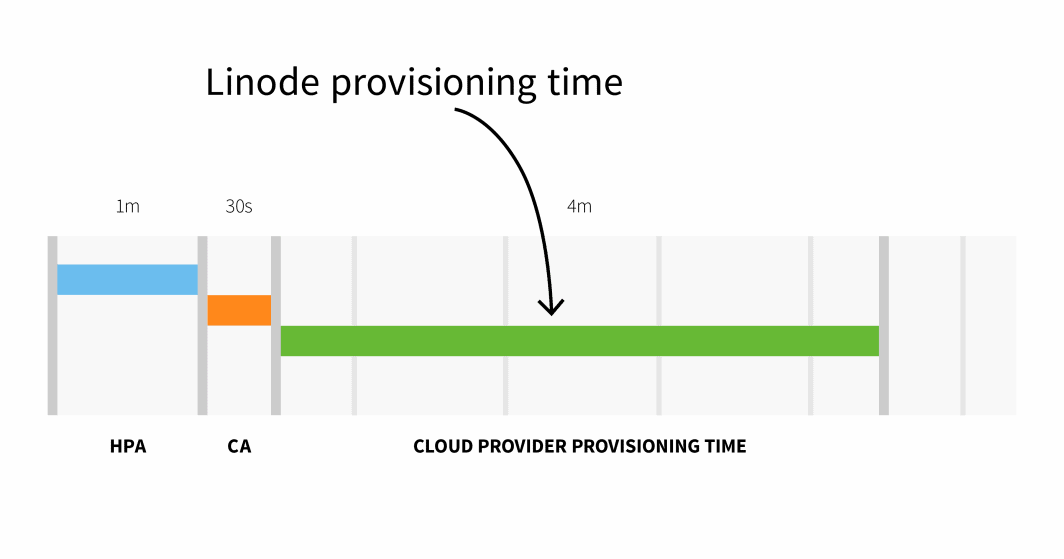
Die Bereitstellung von Knoten auf Linode dauert in der Regel 3 bis 4 Minuten, von der Auslösung der API durch den Cluster-Autoscaler bis zum Zeitpunkt, an dem Pods auf neu erstellten Knoten geplant werden können.
Zusammenfassend lässt sich sagen, dass Sie mit einem kleinen Cluster Folgendes haben:
```
HPA delay: 1m +
CA delay: 0m30s +
Cloud provider: 4m +
Container runtime: 0m30s +
=========================
Total 6m
```
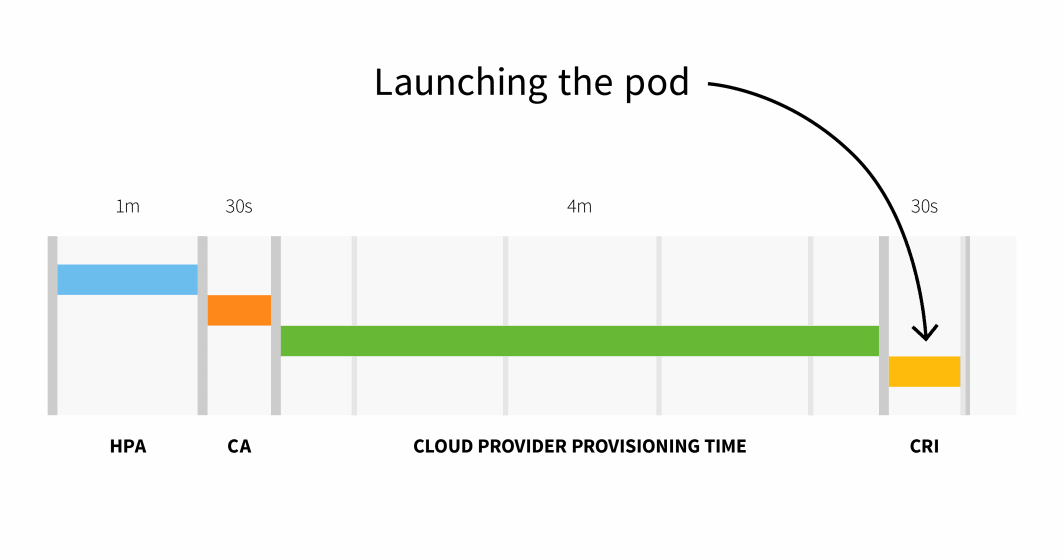
Bei einem Cluster mit mehr als 100 Knoten kann die Gesamtverzögerung 6 Minuten und 30 Sekunden betragen... das ist eine lange Zeit, wie kann man das also beheben?
Sie können Ihre Arbeitslasten proaktiv skalieren, oder wenn Sie Ihre Verkehrsmuster gut kennen, können Sie im Voraus skalieren.
Präemptive Skalierung mit KEDA
Wenn Sie Datenverkehr mit vorhersehbaren Mustern abwickeln, ist es sinnvoll, Ihre Arbeitslasten (und Knoten) vor einem Spitzenwert zu vergrößern und zu verkleinern, sobald der Datenverkehr nachlässt.
Kubernetes bietet keinen Mechanismus zur Skalierung von Arbeitslasten auf der Grundlage von Daten oder Uhrzeiten, daher werden Sie in diesem Teil KEDAverwenden -den Kubernetes Event Driven Autoscaler.
KEDA ist ein Auto-Scaler, der aus drei Komponenten besteht:
- einen Scaler;
- einen Metrik-Adapter; und
- einen Controller.
Sie können KEDA mit Helm installieren:
```bash
$ helm repo add kedacore https://kedacore.github.io/charts
$ helm install keda kedacore/keda
```Nun, da Prometheus und KEDA installiert sind, können wir ein Deployment erstellen.
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
replicas: 1
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
spec:
containers:
- name: podinfo
image: stefanprodan/podinfoSie können die Ressource mit an den Cluster übergeben:
```bash
$ kubectl apply -f deployment.yaml
```KEDA setzt auf dem bestehenden horizontalen Pod-Autoscaler auf und umhüllt ihn mit einer benutzerdefinierten Ressourcendefinition namens ScaleObject.
Das folgende ScaledObject verwendet den Cron Scaler, um ein Zeitfenster zu definieren, in dem die Anzahl der Replikate geändert werden soll:
```yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 1
scaleTargetRef:
name: podinfo
triggers:
- type: cron
metadata:
timezone: Europe/London
start: 23 * * * *
end: 28 * * * *
desiredReplicas: "5"
```Sie können das Objekt mit einreichen:
```bash
$ kubectl apply -f scaled-object.yaml
```Was wird als nächstes passieren? Nichts. Die automatische Skalierung wird nur ausgelöst zwischen 23 * * * * und 28 * * * *. Mit Hilfe von Cron-Gurukönnen Sie die beiden Cron-Ausdrücke übersetzen in:
- Einstieg bei Minute 23 (z.B. 2:23, 3:23, usw.).
- Halten Sie bei Minute 28 an (z.B. 2:28, 3:28, usw.).
Wenn Sie bis zum Startdatum warten, werden Sie feststellen, dass sich die Anzahl der Replikate auf 5 erhöht.
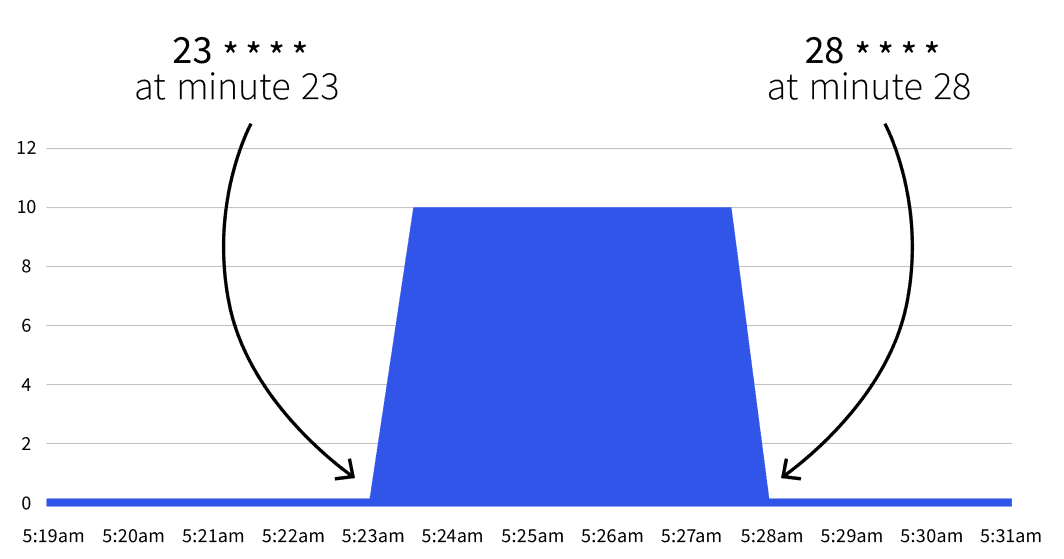
Wird die Zahl nach der 28. Minute auf 1 zurückgesetzt? Ja, der Autoscaler kehrt zu der Anzahl der Replikate zurück, die in minReplicaCount.
Was passiert, wenn Sie die Anzahl der Replikate zwischen den Intervallen erhöhen? Wenn Sie zwischen Minute 23 und 28 Ihre Bereitstellung auf 10 Replikate skalieren, überschreibt KEDA Ihre Änderung und setzt die Anzahl. Wenn Sie das gleiche Experiment nach der 28. Minute wiederholen, wird die Anzahl der Replikate auf 10 gesetzt. Nun, da Sie die Theorie kennen, lassen Sie uns einige praktische Anwendungsfälle betrachten.
Verkleinerung während der Arbeitszeiten
Sie haben eine Bereitstellung in einer Entwicklungsumgebung, die während der Arbeitszeit aktiv sein und nachts ausgeschaltet werden sollte.
Sie könnten das folgende ScaledObject verwenden:
```yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 0
scaleTargetRef:
name: podinfo
triggers:
- type: cron
metadata:
timezone: Europe/London
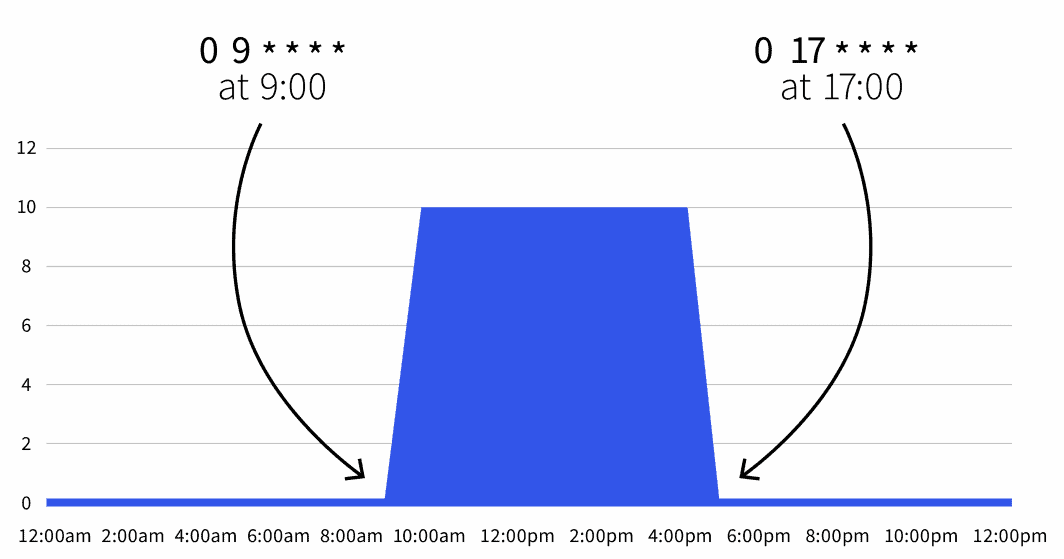
start: 0 9 * * *
end: 0 17 * * *
desiredReplicas: "10"
```Die Standardanzahl der Replikate ist Null, aber während der Arbeitszeiten (9 bis 17 Uhr) werden die Replikate auf 10 skaliert.
Sie können das skalierte Objekt auch erweitern, um das Wochenende auszuschließen:
```yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 0
scaleTargetRef:
name: podinfo
triggers:
- type: cron
metadata:
timezone: Europe/London
start: 0 9 * * 1-5
end: 0 17 * * 1-5
desiredReplicas: "10"
```Jetzt ist Ihre Arbeitsbelastung nur von Montag bis Freitag von 9 bis 17 Uhr aktiv. Da Sie mehrere Auslöser kombinieren können, können Sie auch Ausnahmen einbeziehen.
Verkleinerung an Wochenenden
Wenn Sie beispielsweise planen, Ihre Arbeitslasten am Mittwoch länger aktiv zu halten, könnten Sie die folgende Definition verwenden:
```yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 0
scaleTargetRef:
name: podinfo
triggers:
- type: cron
metadata:
timezone: Europe/London
start: 0 9 * * 1-5
end: 0 17 * * 1-5
desiredReplicas: "10"
- type: cron
metadata:
timezone: Europe/London
start: 0 17 * * 3
end: 0 21 * * 3
desiredReplicas: "10"
```Nach dieser Definition ist das Arbeitspensum von Montag bis Freitag zwischen 9 und 17 Uhr aktiv, außer am Mittwoch, der von 9 bis 21 Uhr dauert.
Zusammenfassung
Mit dem KEDA cron autoscaler können Sie eine Zeitspanne definieren, in der Sie Ihre Workloads aus-/einskalieren möchten.
Auf diese Weise können Sie Pods vor Spitzenbelastungen skalieren, wodurch der Cluster-Autoscaler im Voraus ausgelöst wird.
In diesem Artikel erfahren Sie mehr:
- Wie der Cluster-Autoscaler funktioniert.
- Wie lange die horizontale Skalierung und das Hinzufügen von Knoten zu Ihrem Cluster dauert.
- Skalierung von Anwendungen auf Basis von Cron-Ausdrücken mit KEDA.
Möchten Sie mehr erfahren? Melden Sie sich an, um dies in unserem Webinar in Zusammenarbeit mit Akamai Cloud Computing Services in Aktion zu sehen.





Kommentare