

Dieser Beitrag ist Teil unserer Serie zur Skalierung von Kubernetes. Registrieren Sie sich um ihn live zu sehen oder auf die Aufzeichnung zuzugreifen, und sehen Sie sich unsere anderen Beiträge in dieser Serie an:
Wenn die Ressourcen Ihres Clusters zur Neige gehen, stellt der Cluster-Autoscaler einen neuen Knoten bereit und fügt ihn dem Cluster hinzu. Wenn Sie bereits Kubernetes-Benutzer sind, haben Sie vielleicht bemerkt, dass das Erstellen und Hinzufügen eines Knotens zum Cluster mehrere Minuten dauert.
In dieser Zeit kann Ihre App leicht mit Verbindungen überlastet werden, da sie nicht weiter skalieren kann.

Wie können Sie die lange Wartezeit beheben?
Proaktive Skalierung, oder:
- Verständnis der Funktionsweise des Cluster-Autoscalers und Maximierung seines Nutzens;
- Verwendung des Kubernetes-Schedulers zur Zuweisung von Pods an einen Knoten; und
- proaktive Bereitstellung von Arbeitsknoten, um eine schlechte Skalierung zu vermeiden.
Wenn Sie den Code für dieses Tutorial lieber lesen möchten, finden Sie ihn auf LearnK8s GitHub.
Wie der Cluster-Autoscaler in Kubernetes funktioniert
Der Cluster-Autoscaler prüft nicht die Speicher- oder CPU-Verfügbarkeit, wenn er die automatische Skalierung auslöst. Stattdessen reagiert der Cluster-Autoscaler auf Ereignisse und prüft, ob es nicht planbare Pods gibt. Ein Pod ist nicht planbar, wenn der Scheduler keinen Knoten findet, der ihn aufnehmen kann.
Testen wir dies, indem wir einen Cluster erstellen.
bash
$ linode-cli lke cluster-create \
--label learnk8s \
--region eu-west \
--k8s_version 1.23 \
--node_pools.count 1 \
--node_pools.type g6-standard-2 \
--node_pools.autoscaler.enabled enabled \
--node_pools.autoscaler.max 10 \
--node_pools.autoscaler.min 1 \
$ linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfigSie sollten auf die folgenden Details achten:
- jeder Knoten hat 4 GB Speicher und 2 vCPU (d. h. "g6-standard-2");
- ein einzelner Knoten im Cluster vorhanden ist; und
- der Cluster-Autoscaler ist so konfiguriert, dass er von 1 auf 10 Knoten wächst.
Mit können Sie überprüfen, ob die Installation erfolgreich war:
bash
$ kubectl get pods -A --kubeconfig=kubeconfigDas Exportieren der kubeconfig-Datei mit einer Umgebungsvariablen ist in der Regel bequemer.
Sie können dies mit tun:
bash
$ export KUBECONFIG=${PWD}/kubeconfig
$ kubectl get podsAusgezeichnet!
Bereitstellen einer Anwendung
Stellen wir eine Anwendung bereit, die 1 GB Arbeitsspeicher und 250 m* CPU benötigt.Note: m = thousandth of a core, so 250m = 25% of the CPU
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
replicas: 1
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
spec:
containers:
- name: podinfo
image: stefanprodan/podinfo
ports:
- containerPort: 9898
resources:
requests:
memory: 1G
cpu: 250mSie können die Ressource mit an den Cluster übergeben:
bash
$ kubectl apply -f podinfo.yamlSobald Sie dies getan haben, werden Sie einige Dinge bemerken. Erstens werden drei Pods fast sofort ausgeführt, und einer ist in der Schwebe.

Und dann:
- nach ein paar Minuten erstellt der Autoscaler einen zusätzlichen Knoten; und
- der vierte Pod wird auf dem neuen Knoten bereitgestellt.

Warum ist der vierte Pod nicht auf dem ersten Knoten installiert? Schauen wir uns die zuweisbaren Ressourcen an.
Zuweisbare Ressourcen in Kubernetes-Knoten
Pods, die in Ihrem Kubernetes-Cluster bereitgestellt werden, verbrauchen Arbeitsspeicher-, CPU- und Speicherressourcen.
Allerdings benötigen das Betriebssystem und das Kubelet auf demselben Knoten Speicher und CPU.
In einem Kubernetes-Arbeitsknoten werden Speicher und CPU aufgeteilt:
- Ressourcen, die für die Ausführung des Betriebssystems und der Systemdämonen wie SSH, systemd usw. benötigt werden.
- Ressourcen, die für die Ausführung von Kubernetes-Agenten erforderlich sind, z. B. Kubelet, Container-Laufzeitumgebung, Knotenproblemdetektor usw.
- Den Pods zur Verfügung stehende Ressourcen.
- Für die Räumungsschwelle reservierte Ressourcen.
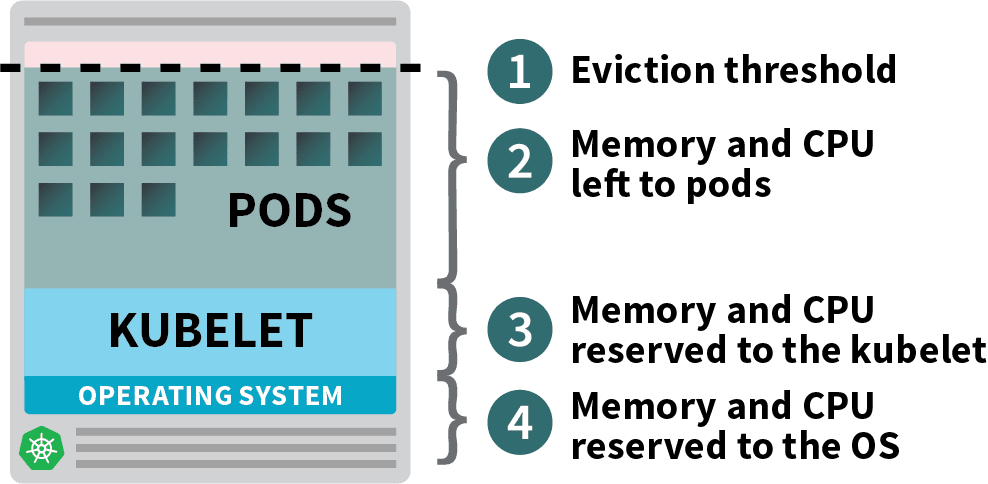
Wenn Ihr Cluster ein DaemonSet wie kube-proxy ausführt, sollten Sie den verfügbaren Speicher und die CPU weiter reduzieren.
Senken wir also die Anforderungen, um sicherzustellen, dass alle Pods auf einen einzigen Knoten passen:
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
replicas: 4
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
spec:
containers:
- name: podinfo
image: stefanprodan/podinfo
ports:
- containerPort: 9898
resources:
requests:
memory: 0.8G # <- lower memory
cpu: 200m # <- lower CPUSie können die Bereitstellung mit ändern:
bash
$ kubectl apply -f podinfo.yamlDie Auswahl der richtigen Menge an CPU und Speicher zur Optimierung Ihrer Instanzen kann schwierig sein. Der Learnk8s-Tool-Rechner könnte Ihnen dabei helfen, dies schneller zu tun.
Sie haben ein Problem behoben, aber was ist mit der Zeit, die es dauert, einen neuen Knoten zu erstellen?
Früher oder später werden Sie mehr als vier Replikate haben. Müssen Sie wirklich ein paar Minuten warten, bis die neuen Pods erstellt werden?
Die kurze Antwort lautet: Ja.
Linode muss eine virtuelle Maschine von Grund auf erstellen, sie bereitstellen und mit dem Cluster verbinden. Dieser Vorgang kann leicht mehr als zwei Minuten dauern.
Aber es gibt eine Alternative.
Sie könnten proaktiv bereits bereitgestellte Knoten erstellen, wenn Sie sie benötigen.
Sie könnten den Autoscaler beispielsweise so konfigurieren, dass er immer einen Reserveknoten hat. Wenn die Pods auf dem Ersatzknoten bereitgestellt werden, kann der Autoscaler proaktiv weitere erstellen. Leider verfügt der Autoscaler nicht über diese integrierte Funktionalität, aber Sie können sie leicht nachbilden.
Sie können einen Pod erstellen, der Anforderungen hat, die der Ressource des Knotens entsprechen:
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning
spec:
replicas: 1
selector:
matchLabels:
run: overprovisioning
template:
metadata:
labels:
run: overprovisioning
spec:
containers:
- name: pause
image: k8s.gcr.io/pause
resources:
requests:
cpu: 900m
memory: 3.8GSie können die Ressource mit an den Cluster übergeben:
bash
kubectl apply -f placeholder.yamlDiese Kapsel bewirkt überhaupt nichts.
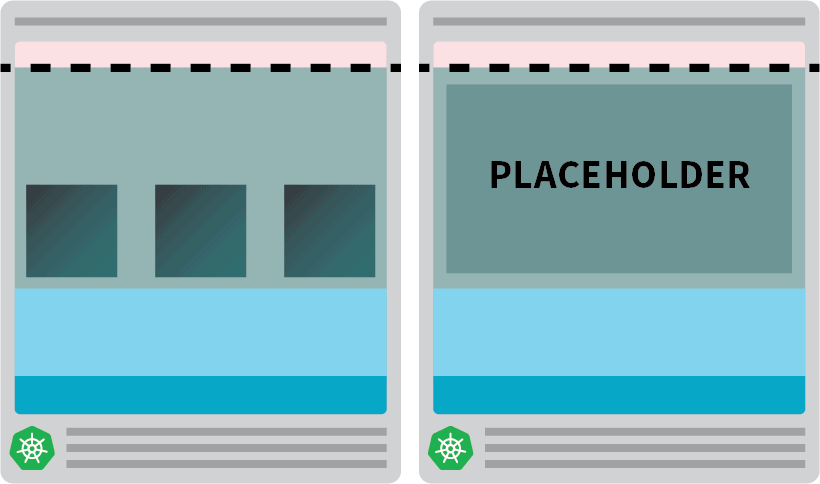
Dadurch bleibt der Knoten voll besetzt.
Der nächste Schritt besteht darin, dafür zu sorgen, dass der Platzhalter-Pod entfernt wird, sobald die Arbeitslast skaliert werden muss.
Hierfür können Sie eine Prioritätsklasse verwenden.
yaml
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: overprovisioning
value: -1
globalDefault: false
description: "Priority class used by overprovisioning."
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning
spec:
replicas: 1
selector:
matchLabels:
run: overprovisioning
template:
metadata:
labels:
run: overprovisioning
spec:
priorityClassName: overprovisioning # <--
containers:
- name: pause
image: k8s.gcr.io/pause
resources:
requests:
cpu: 900m
memory: 3.8GUnd senden Sie es erneut an den Cluster mit:
bash
kubectl apply -f placeholder.yamlNun ist die Einrichtung abgeschlossen.
Es kann sein, dass Sie ein wenig warten müssen, bis der Autoscaler den Knoten erstellt hat, aber zu diesem Zeitpunkt sollten Sie zwei Knoten haben:
- Ein Knoten mit vier Pods.
- Eine weitere mit einem Platzhalterhülse.
Was passiert, wenn Sie die Bereitstellung auf 5 Replikate skalieren? Müssen Sie dann warten, bis der Autoscaler einen neuen Knoten erstellt?
Testen wir mit:
bash
kubectl scale deployment/podinfo --replicas=5Das sollten Sie beachten:
- Der fünfte Pod wird sofort erstellt und befindet sich in weniger als 10 Sekunden im Zustand "Running".
- Der Platzhalter-Pod wurde geräumt, um Platz für den Pod zu schaffen.

Und dann:
- Der Cluster-Autoscaler bemerkte den ausstehenden Platzhalter-Pod und stellte einen neuen Knoten bereit.
- Der Platzhalter-Pod wird auf dem neu erstellten Knoten bereitgestellt.
Warum sollten Sie proaktiv einen einzigen Knoten erstellen, wenn Sie mehrere haben könnten?
Sie können den Platzhalter-Pod auf mehrere Replikate skalieren. Jedes Replikat stellt einen Kubernetes-Knoten bereit, der Standardarbeitslasten aufnehmen kann. Diese Knoten werden jedoch weiterhin auf Ihre Cloud-Rechnung angerechnet, sind aber untätig und tun nichts. Daher sollten Sie vorsichtig sein und nicht zu viele davon erstellen.
Kombination des Cluster-Autoscalers mit dem horizontalen Pod-Autoscaler
Um die Auswirkungen dieser Technik zu verstehen, kombinieren wir den Cluster-Autoscaler mit dem Horizontal Pod Autoscaler (HPA). Der HPA wurde entwickelt, um die Anzahl der Replikate in Ihren Bereitstellungen zu erhöhen.
Wenn Ihre Anwendung mehr Datenverkehr erhält, können Sie den Autoscaler die Anzahl der Replikate anpassen lassen, um mehr Anfragen zu verarbeiten.
Wenn die Pods alle verfügbaren Ressourcen ausgeschöpft haben, löst der Cluster-Autoscaler die Erstellung eines neuen Knotens aus, damit die HPA weitere Replikate erstellen kann.
Testen wir dies, indem wir einen neuen Cluster erstellen:
bash
$ linode-cli lke cluster-create \
--label learnk8s-hpa \
--region eu-west \
--k8s_version 1.23 \
--node_pools.count 1 \
--node_pools.type g6-standard-2 \
--node_pools.autoscaler.enabled enabled \
--node_pools.autoscaler.max 10 \
--node_pools.autoscaler.min 3 \
$ linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfig-hpaMit können Sie überprüfen, ob die Installation erfolgreich war:
bash
$ kubectl get pods -A --kubeconfig=kubeconfig-hpaDer Export der kubeconfig-Datei mit einer Umgebungsvariablen ist bequemer.
Sie können dies mit tun:
bash
$ export KUBECONFIG=${PWD}/kubeconfig-hpa
$ kubectl get podsAusgezeichnet!
Verwenden wir Helm, um Prometheus zu installieren und Metriken aus den Bereitstellungen abzurufen.
Eine Anleitung zur Installation von Helm finden Sie auf der offiziellen Website des Unternehmens.
bash
$ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
$ helm install prometheus prometheus-community/prometheusKubernetes bietet der HPA einen Controller, um Replikate dynamisch zu erhöhen und zu verringern.
Leider hat die HPA auch einige Nachteile:
- Es funktioniert nicht ohne Weiteres. Sie müssen einen Metrics Server installieren, um die Metriken zu aggregieren und zu veröffentlichen.
- Sie können PromQL-Abfragen nicht standardmäßig verwenden.
Glücklicherweise können Sie KEDA verwenden, das den HPA-Controller um einige zusätzliche Funktionen erweitert (einschließlich des Lesens von Metriken von Prometheus).
KEDA ist ein Auto-Scaler, der aus drei Komponenten besteht:
- Ein Zahnsteinentferner
- Ein Metrik-Adapter
- Ein Controller
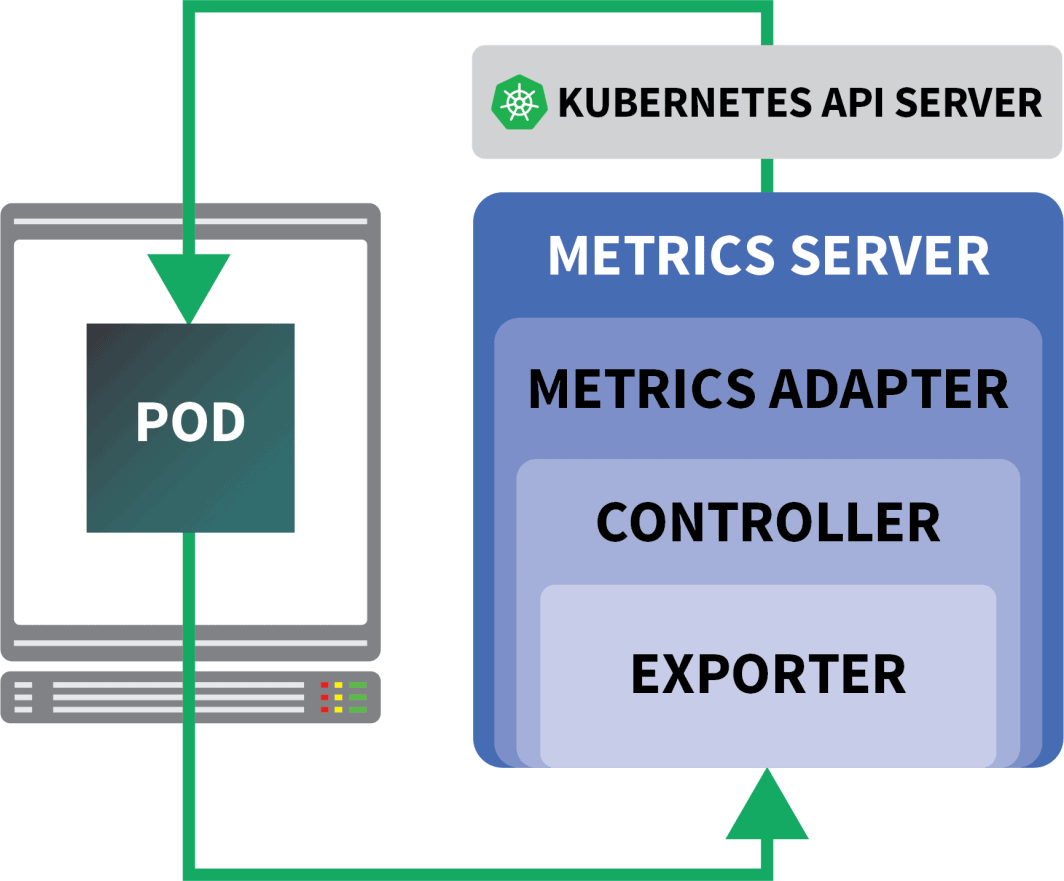
Sie können KEDA mit Helm installieren:
bash
$ helm repo add kedacore https://kedacore.github.io/charts
$ helm install keda kedacore/kedaNun, da Prometheus und KEDA installiert sind, können wir ein Deployment erstellen.
Für dieses Experiment werden Sie eine Anwendung verwenden, die für eine bestimmte Anzahl von Anfragen pro Sekunde ausgelegt ist.
Jeder Pod kann maximal zehn Anfragen pro Sekunde bearbeiten. Wenn der Pod die elfte Anfrage erhält, lässt er die Anfrage in der Schwebe und bearbeitet sie später.
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
replicas: 4
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
annotations:
prometheus.io/scrape: "true"
spec:
containers:
- name: podinfo
image: learnk8s/rate-limiter:1.0.0
imagePullPolicy: Always
args: ["/app/index.js", "10"]
ports:
- containerPort: 8080
resources:
requests:
memory: 0.9G
---
apiVersion: v1
kind: Service
metadata:
name: podinfo
spec:
ports:
- port: 80
targetPort: 8080
selector:
app: podinfoSie können die Ressource mit an den Cluster übergeben:
bash
$ kubectl apply -f rate-limiter.yamlUm etwas Traffic zu generieren, werden Sie Locust verwenden.
Die folgende YAML-Definition erstellt einen verteilten Lasttest-Cluster:
yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: locust-script
data:
locustfile.py: |-
from locust import HttpUser, task, between
class QuickstartUser(HttpUser):
@task
def hello_world(self):
self.client.get("/", headers={"Host": "example.com"})
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: locust
spec:
selector:
matchLabels:
app: locust-primary
template:
metadata:
labels:
app: locust-primary
spec:
containers:
- name: locust
image: locustio/locust
args: ["--master"]
ports:
- containerPort: 5557
name: comm
- containerPort: 5558
name: comm-plus-1
- containerPort: 8089
name: web-ui
volumeMounts:
- mountPath: /home/locust
name: locust-script
volumes:
- name: locust-script
configMap:
name: locust-script
---
apiVersion: v1
kind: Service
metadata:
name: locust
spec:
ports:
- port: 5557
name: communication
- port: 5558
name: communication-plus-1
- port: 80
targetPort: 8089
name: web-ui
selector:
app: locust-primary
type: LoadBalancer
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: locust
spec:
selector:
matchLabels:
app: locust-worker
template:
metadata:
labels:
app: locust-worker
spec:
containers:
- name: locust
image: locustio/locust
args: ["--worker", "--master-host=locust"]
volumeMounts:
- mountPath: /home/locust
name: locust-script
volumes:
- name: locust-script
configMap:
name: locust-scriptSie können es dem Cluster mit übergeben:
bash
$ kubectl locust.yamlHeuschrecke liest sich wie folgt locustfile.pydie in einer ConfigMap gespeichert ist:
py
from locust import HttpUser, task, between
class QuickstartUser(HttpUser):
@task
def hello_world(self):
self.client.get("/")Die Datei tut nichts Besonderes, außer eine Anfrage an eine URL zu stellen. Um sich mit dem Locust-Dashboard zu verbinden, benötigen Sie die IP-Adresse seines Load Balancers.
Sie können sie mit dem folgenden Befehl abrufen:
bash
$ kubectl get service locust -o jsonpath='{.status.loadBalancer.ingress[0].ip}'Öffnen Sie Ihren Browser und geben Sie die IP-Adresse ein.
Ausgezeichnet!
Es fehlt noch ein Teil: der horizontale Pod-Autoscaler.
Der KEDA-Autoscaler umhüllt den horizontalen Autoscaler mit einem speziellen Objekt namens ScaledObject.
yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: podinfo
spec:
scaleTargetRef:
kind: Deployment
name: podinfo
minReplicaCount: 1
maxReplicaCount: 30
cooldownPeriod: 30
pollingInterval: 1
triggers:
- type: prometheus
metadata:
serverAddress: http://prometheus-server
metricName: connections_active_keda
query: |
sum(increase(http_requests_total{app="podinfo"}[60s]))
threshold: "480" # 8rps * 60sKEDA überbrückt die von Prometheus gesammelten Metriken und speist sie in Kubernetes ein.
Schließlich wird ein horizontaler Pod-Autoscaler (HPA) mit diesen Metriken erstellt.
Sie können die HPA mit manuell überprüfen:
bash
$ kubectl get hpa
$ kubectl describe hpa keda-hpa-podinfoSie können das Objekt mit einreichen:
bash
$ kubectl apply -f scaled-object.yamlEs ist an der Zeit zu testen, ob die Skalierung funktioniert.
Starten Sie im Locust-Dashboard ein Experiment mit den folgenden Einstellungen:
- Anzahl der Benutzer:
300 - Laichrate:
0.4 - Gastgeber:
http://podinfo
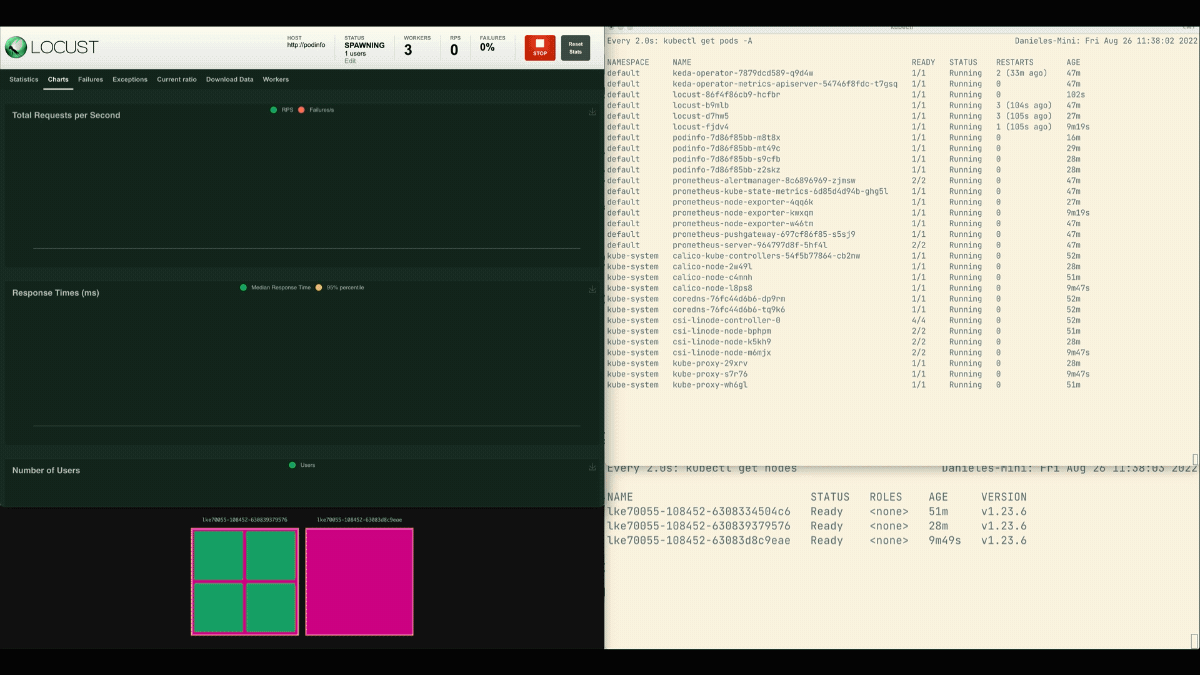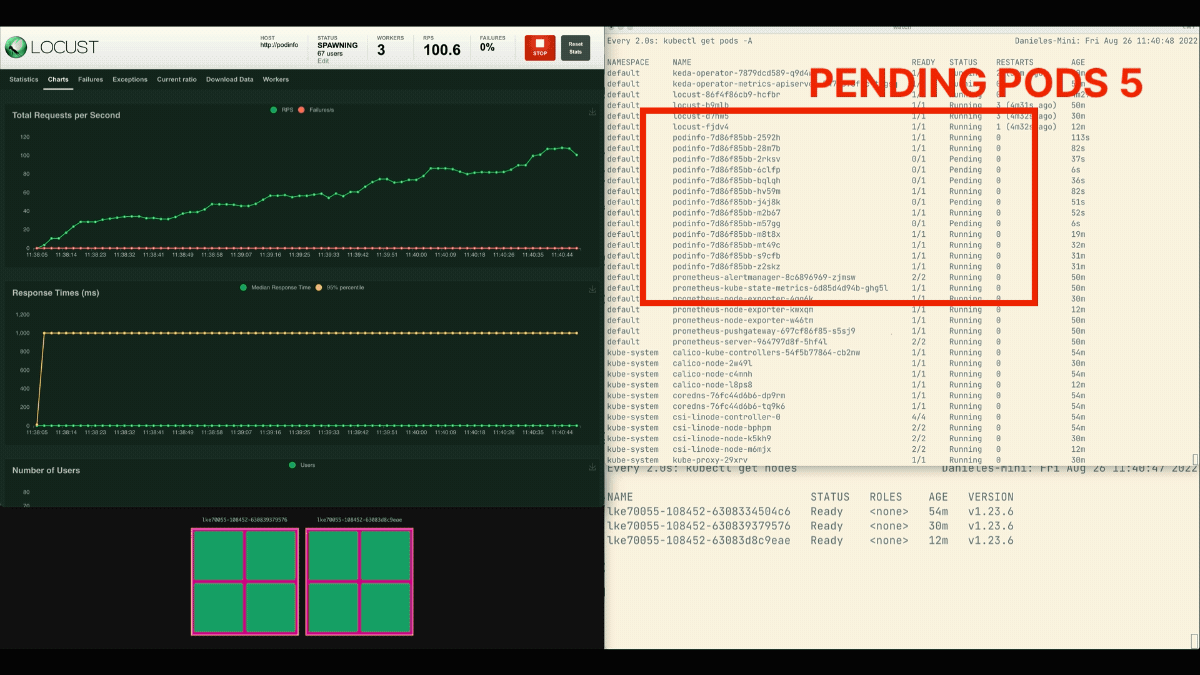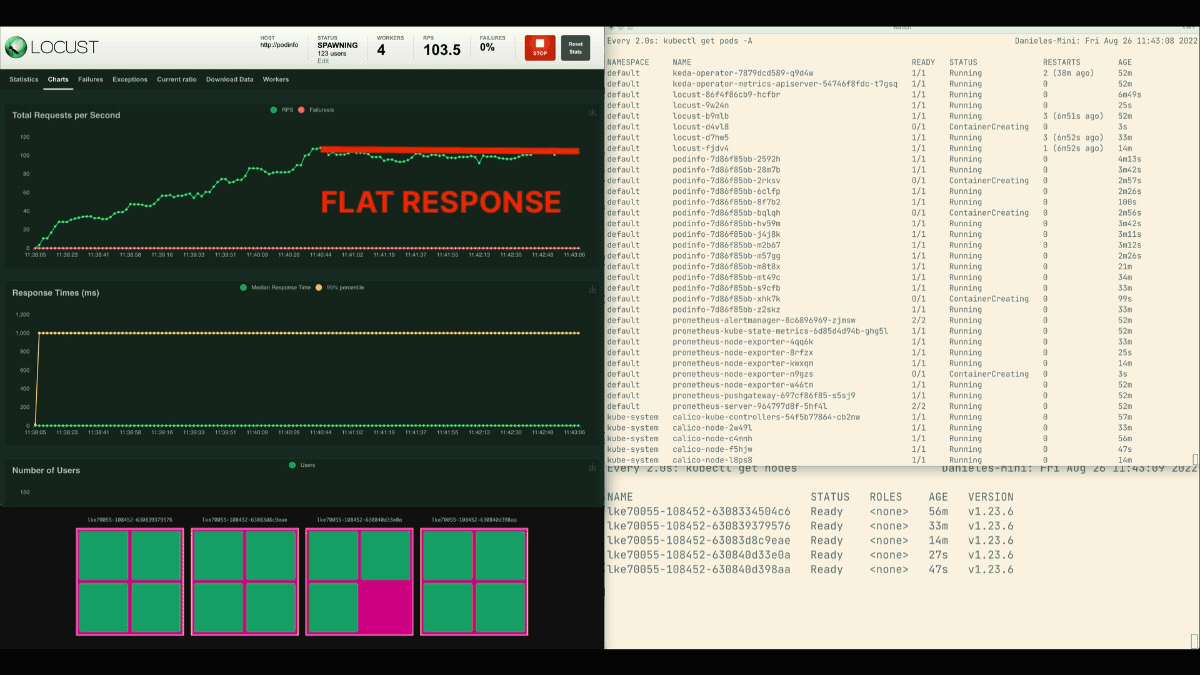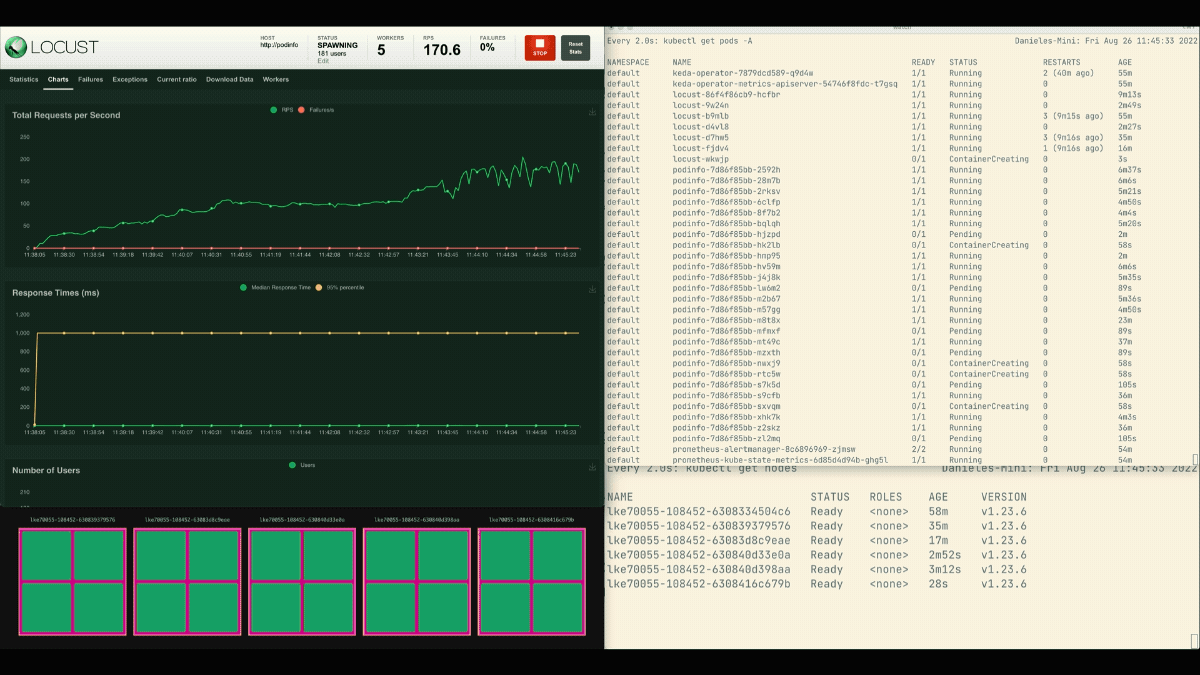
Die Zahl der Replikate nimmt zu!
Ausgezeichnet! Aber haben Sie es bemerkt?
Nachdem die Bereitstellung auf 8 Pods skaliert wurde, muss sie ein paar Minuten warten, bevor weitere Pods auf dem neuen Knoten erstellt werden.
In dieser Zeit stagnieren die Anfragen pro Sekunde, da die derzeit acht Replikate jeweils nur zehn Anfragen bearbeiten können.
Verkleinern wir und wiederholen wir das Experiment:
bash
kubectl scale deployment/podinfo --replicas=4 # or wait for the autoscaler to remove podsDiesmal wollen wir den Knoten mit dem Platzhalter-Pod überversorgen:
yaml
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: overprovisioning
value: -1
globalDefault: false
description: "Priority class used by overprovisioning."
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning
spec:
replicas: 1
selector:
matchLabels:
run: overprovisioning
template:
metadata:
labels:
run: overprovisioning
spec:
priorityClassName: overprovisioning
containers:
- name: pause
image: k8s.gcr.io/pause
resources:
requests:
cpu: 900m
memory: 3.9GSie können es dem Cluster mit übergeben:
bash
kubectl apply -f placeholder.yamlÖffnen Sie das Locust-Dashboard und wiederholen Sie das Experiment mit den folgenden Einstellungen:
- Anzahl der Benutzer:
300 - Laichrate:
0.4 - Gastgeber:
http://podinfo
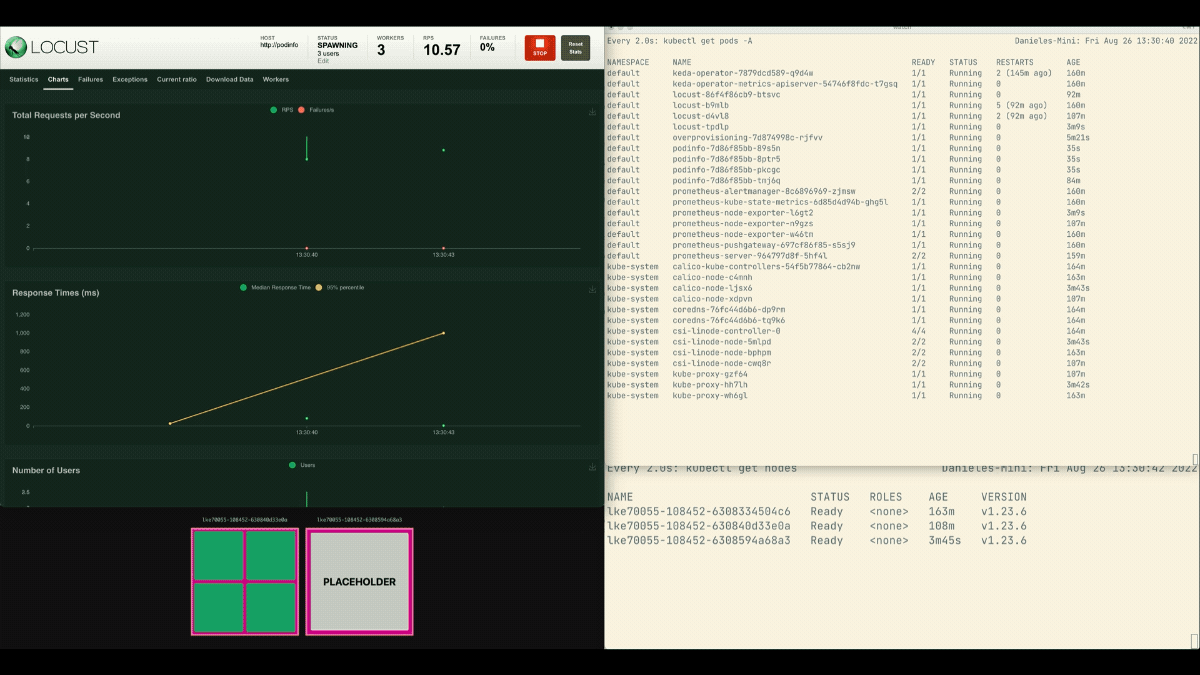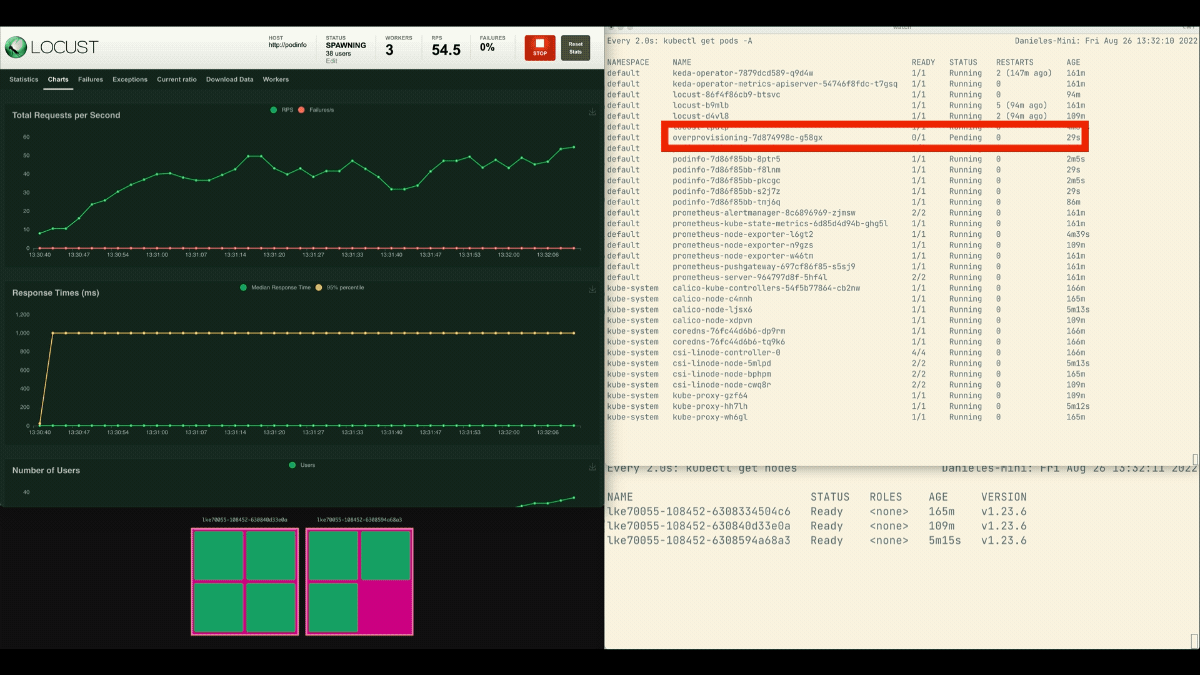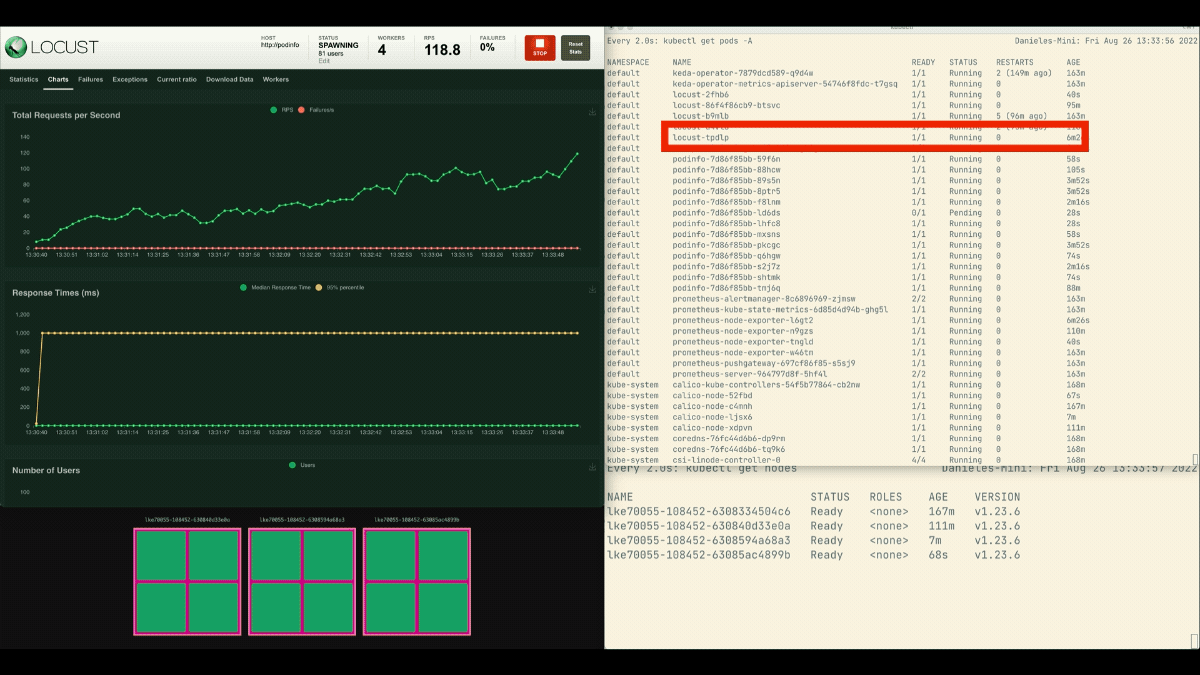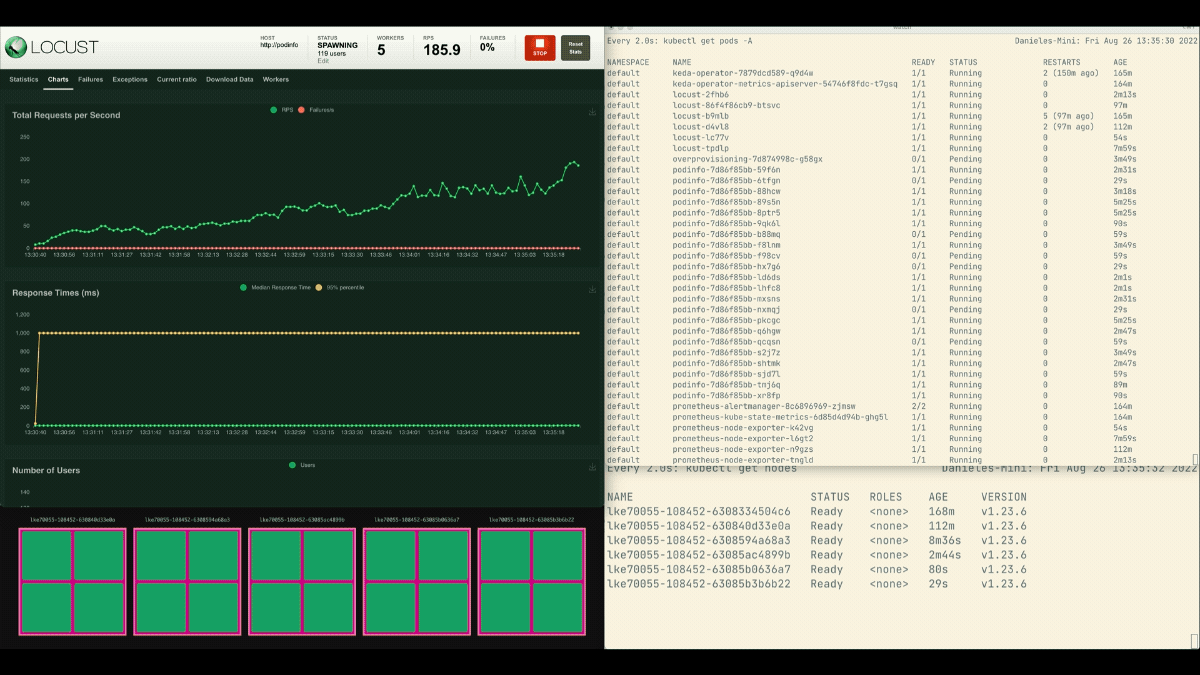
Diesmal werden neue Knoten im Hintergrund erstellt, und die Anfragen pro Sekunde steigen, ohne abzuflachen. Toll gemacht!
Lassen Sie uns noch einmal zusammenfassen, was Sie in diesem Beitrag gelernt haben:
- Der Cluster-Autoscaler überwacht nicht den CPU- oder Speicherverbrauch. Stattdessen überwacht er ausstehende Pods;
- können Sie einen Pod erstellen, der den gesamten verfügbaren Speicher und die CPU verwendet, um einen Kubernetes-Knoten proaktiv bereitzustellen;
- Kubernetes-Knoten verfügen über reservierte Ressourcen für Kubelet, Betriebssystem und Eviction Threshold; und
- können Sie Prometheus mit KEDA kombinieren, um Ihren Pod mit einer PromQL-Abfrage zu skalieren.
Möchten Sie an unserer Webinarreihe zur Skalierung von Kubernetes teilnehmen? Registrieren Sie sich und erfahren Sie mehr über die Verwendung von KEDA zur Skalierung von Kubernetes-Clustern auf Null.




Kommentare