

Este posto faz parte de nossa série de escalas Kubernetes. Cadastre-se para assistir ao vivo ou acessar a gravação, e verificar nossos outros postos nesta série:
Quando seu agrupamento está com poucos recursos, o Cluster Autoscaler fornece um novo nó e o adiciona ao agrupamento. Se você já é um usuário Kubernetes, talvez tenha notado que criar e adicionar um nó ao aglomerado leva vários minutos.
Durante este tempo, seu aplicativo pode ser facilmente sobrecarregado com conexões, pois não pode ser dimensionado mais.

Como você pode consertar o longo tempo de espera?
Escala pró-ativa, ou:
- compreendendo como funciona o auto-escalador de grupos e maximizando sua utilidade;
- usando o programador Kubernetes para atribuir cápsulas a um nó; e
- nodos de trabalhadores de provisionamento de forma proativa para evitar escalonamento deficiente.
Se você preferir ler o código para este tutorial, você pode encontrar isso no GitHub do LearnK8s.
Como funciona o Cluster Autoscaler em Kubernetes
O Cluster Autoscaler não olha para a disponibilidade de memória ou CPU quando aciona o autoscaling. Em vez disso, o Cluster Autoscaler reage a eventos e verifica se há alguma cápsula não escalonável. Um pod é inescalável quando o programador não consegue encontrar um nó que possa acomodá-lo.
Vamos testar isso criando um cluster.
bash
$ linode-cli lke cluster-create \
--label learnk8s \
--region eu-west \
--k8s_version 1.23 \
--node_pools.count 1 \
--node_pools.type g6-standard-2 \
--node_pools.autoscaler.enabled enabled \
--node_pools.autoscaler.max 10 \
--node_pools.autoscaler.min 1 \
$ linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfigVocê deve prestar atenção aos seguintes detalhes:
- cada nó tem 4GB de memória e 2 vCPU (ou seja, `g6-standard-2`);
- há um único nó no agrupamento; e
- o auto-escalador de cluster está configurado para crescer de 1 a 10 nós.
Você pode verificar se a instalação é bem sucedida:
bash
$ kubectl get pods -A --kubeconfig=kubeconfigExportar o arquivo kubeconfig com uma variável de ambiente é normalmente mais conveniente.
Você pode fazer isso com:
bash
$ export KUBECONFIG=${PWD}/kubeconfig
$ kubectl get podsExcelente!
Implantação de uma aplicação
Vamos implantar uma aplicação que requer 1GB de memória e 250m* de CPU.Note: m = thousandth of a core, so 250m = 25% of the CPU
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
replicas: 1
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
spec:
containers:
- name: podinfo
image: stefanprodan/podinfo
ports:
- containerPort: 9898
resources:
requests:
memory: 1G
cpu: 250mVocê pode enviar o recurso para o agrupamento com:
bash
$ kubectl apply -f podinfo.yamlAssim que você fizer isso, você poderá notar algumas coisas. Primeiro, três cápsulas estão funcionando quase imediatamente, e uma está pendente.

E então:
- após alguns minutos, o autoscaler cria um nó extra; e
- a quarta cápsula é implantada no novo nó.

Por que a quarta cápsula não está implantada no primeiro nó? Vamos cavar os recursos alocáveis.
Recursos alocáveis nos nós de Kubernetes
As cápsulas implantadas em seu cluster Kubernetes consomem memória, CPU e recursos de armazenamento.
Entretanto, no mesmo nó, o sistema operacional e o kubelet requerem memória e CPU.
Em um nó operário Kubernetes, a memória e a CPU são divididas em:
- Recursos necessários para executar o sistema operacional e os daemons do sistema, como SSH, systemd, etc.
- Recursos necessários para operar os agentes Kubernetes, tais como o Kubelet, o tempo de funcionamento do contêiner, detector de problemas de nós, etc.
- Recursos disponíveis para Pods.
- Recursos reservados para o limiar de despejo.
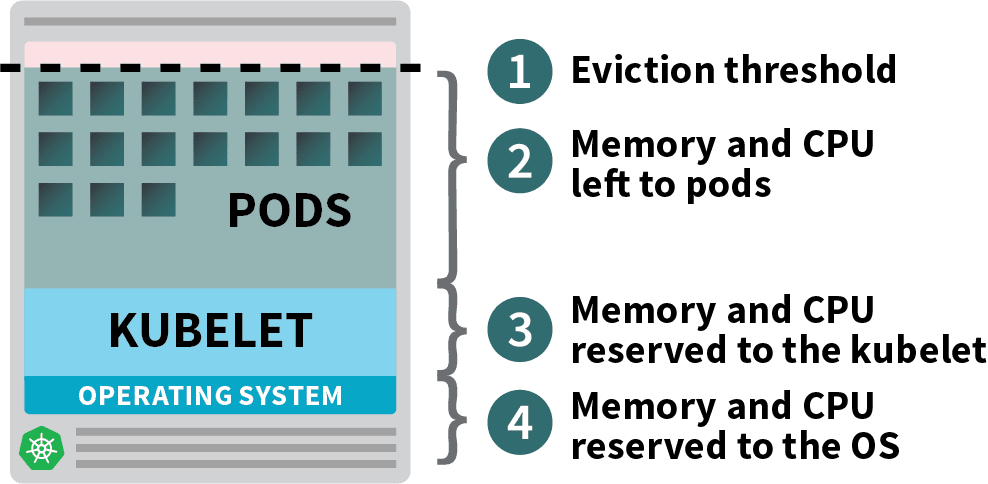
Se seu cluster roda um DaemonSet como o kube-proxy, você deve reduzir ainda mais a memória e a CPU disponíveis.
Portanto, vamos baixar os requisitos para garantir que todas as cápsulas possam caber em um único nó:
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
replicas: 4
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
spec:
containers:
- name: podinfo
image: stefanprodan/podinfo
ports:
- containerPort: 9898
resources:
requests:
memory: 0.8G # <- lower memory
cpu: 200m # <- lower CPUVocê pode emendar a implantação com:
bash
$ kubectl apply -f podinfo.yamlSelecionar a quantidade certa de CPU e memória para otimizar suas instâncias pode ser complicado. A calculadora da ferramenta Learnk8s pode ajudá-lo a fazer isso mais rapidamente.
Você resolveu um problema, mas e quanto ao tempo necessário para criar um novo nó?
Mais cedo ou mais tarde, você terá mais de quatro réplicas. Você realmente tem que esperar alguns minutos antes que as novas réplicas sejam criadas?
A resposta curta é sim.
A Linode tem que criar uma máquina virtual a partir do zero, provisioná-la e conectá-la ao cluster. O processo pode facilmente levar mais de dois minutos.
Mas há uma alternativa.
Você poderia criar proativamente nós já provisionados quando precisar deles.
Por exemplo: você poderia configurar o autoscaler para ter sempre um nó de reserva. Quando as cápsulas são implantadas no nó de reposição, o autoscaler pode criar mais proativamente. Infelizmente, o autoescalador não tem esta funcionalidade integrada, mas você pode facilmente recriá-la.
Você pode criar uma cápsula que tenha pedidos iguais ao recurso do nó:
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning
spec:
replicas: 1
selector:
matchLabels:
run: overprovisioning
template:
metadata:
labels:
run: overprovisioning
spec:
containers:
- name: pause
image: k8s.gcr.io/pause
resources:
requests:
cpu: 900m
memory: 3.8GVocê pode enviar o recurso para o agrupamento com:
bash
kubectl apply -f placeholder.yamlEsta cápsula não faz absolutamente nada.
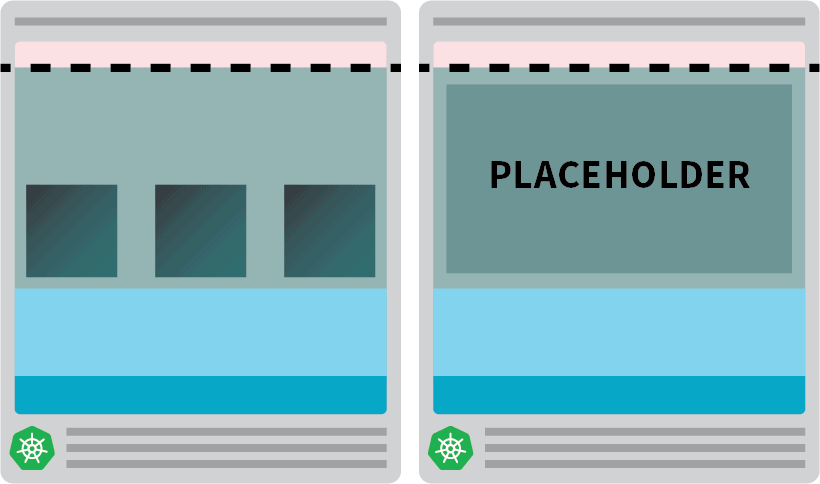
Ele apenas mantém o nó totalmente ocupado.
O próximo passo é certificar-se de que a cápsula de suporte do local seja despejada assim que houver uma carga de trabalho que precise ser escalonada.
Para isso, você pode usar uma Classe Prioritária.
yaml
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: overprovisioning
value: -1
globalDefault: false
description: "Priority class used by overprovisioning."
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning
spec:
replicas: 1
selector:
matchLabels:
run: overprovisioning
template:
metadata:
labels:
run: overprovisioning
spec:
priorityClassName: overprovisioning # <--
containers:
- name: pause
image: k8s.gcr.io/pause
resources:
requests:
cpu: 900m
memory: 3.8GE reapresentá-la ao grupo com:
bash
kubectl apply -f placeholder.yamlAgora a configuração está completa.
Você pode precisar esperar um pouco para que o autoscaler crie o nó, mas neste ponto, você deve ter dois nós:
- Um nódulo com quatro cápsulas.
- Outro com uma cápsula de espaço reservado.
O que acontece quando você dimensiona o desdobramento para 5 réplicas? Você terá que esperar que o autoscaler crie um novo nó?
Vamos testar com:
bash
kubectl scale deployment/podinfo --replicas=5Você deve observar:
- A quinta cápsula é criada imediatamente, e está no estado de funcionamento em menos de 10 segundos.
- A cápsula de suporte foi despejada para abrir espaço para a cápsula.

E então:
- O autoscalador de cluster notou a cápsula de suporte do local pendente e provisionou um novo nó.
- A cápsula de suporte de lugar é implantada no nó recém-criado.
Por que criar proativamente um único nó quando você poderia ter mais?
Você pode escalar a cápsula de suporte de lugar para várias réplicas. Cada réplica fornecerá previamente um nó Kubernetes pronto para aceitar cargas de trabalho padrão. No entanto, esses nós ainda contam contra sua conta de nuvem, mas ficam ociosos e não fazem nada. Portanto, você deve ser cuidadoso e não criar muitos deles.
Combinando o Cluster Autoscaler com o Pod Autoscaler Horizontal
Para entender a implicação desta técnica, vamos combinar o Autoscaler de cluster com o Autoscaler Horizontal Pod (HPA). O HPA é projetado para aumentar as réplicas em suas implantações.
Como sua aplicação recebe mais tráfego, você pode fazer com que o autoscaler ajuste o número de réplicas para lidar com mais pedidos.
Quando as cápsulas esgotarem todos os recursos disponíveis, o autoescalador de cluster desencadeará a criação de um novo nó para que o HPA possa continuar criando mais réplicas.
Vamos testar isso, criando um novo grupo:
bash
$ linode-cli lke cluster-create \
--label learnk8s-hpa \
--region eu-west \
--k8s_version 1.23 \
--node_pools.count 1 \
--node_pools.type g6-standard-2 \
--node_pools.autoscaler.enabled enabled \
--node_pools.autoscaler.max 10 \
--node_pools.autoscaler.min 3 \
$ linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfig-hpaVocê pode verificar se a instalação é bem sucedida:
bash
$ kubectl get pods -A --kubeconfig=kubeconfig-hpaExportar o arquivo kubeconfig com uma variável de ambiente é mais conveniente.
Você pode fazer isso com:
bash
$ export KUBECONFIG=${PWD}/kubeconfig-hpa
$ kubectl get podsExcelente!
Vamos usar o Helm para instalar Prometheus e raspar métricas das implantações.
Você pode encontrar as instruções sobre como instalar o Helm em seu site oficial.
bash
$ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
$ helm install prometheus prometheus-community/prometheusA Kubernetes oferece ao HPA um controlador para aumentar e diminuir as réplicas de forma dinâmica.
Infelizmente, a HPA tem alguns inconvenientes:
- Não funciona fora da caixa. Você precisa instalar um Servidor de métricas para agregar e expor as métricas.
- Você não pode usar as consultas da PromQL fora da caixa.
Felizmente, você pode usar a KEDA, que estende o controlador HPA com algumas características extras (incluindo a leitura de métricas de Prometheus).
A KEDA é um autoscaler feito de três componentes:
- Um Escalador
- Um Adaptador de Métricas
- Um Controlador
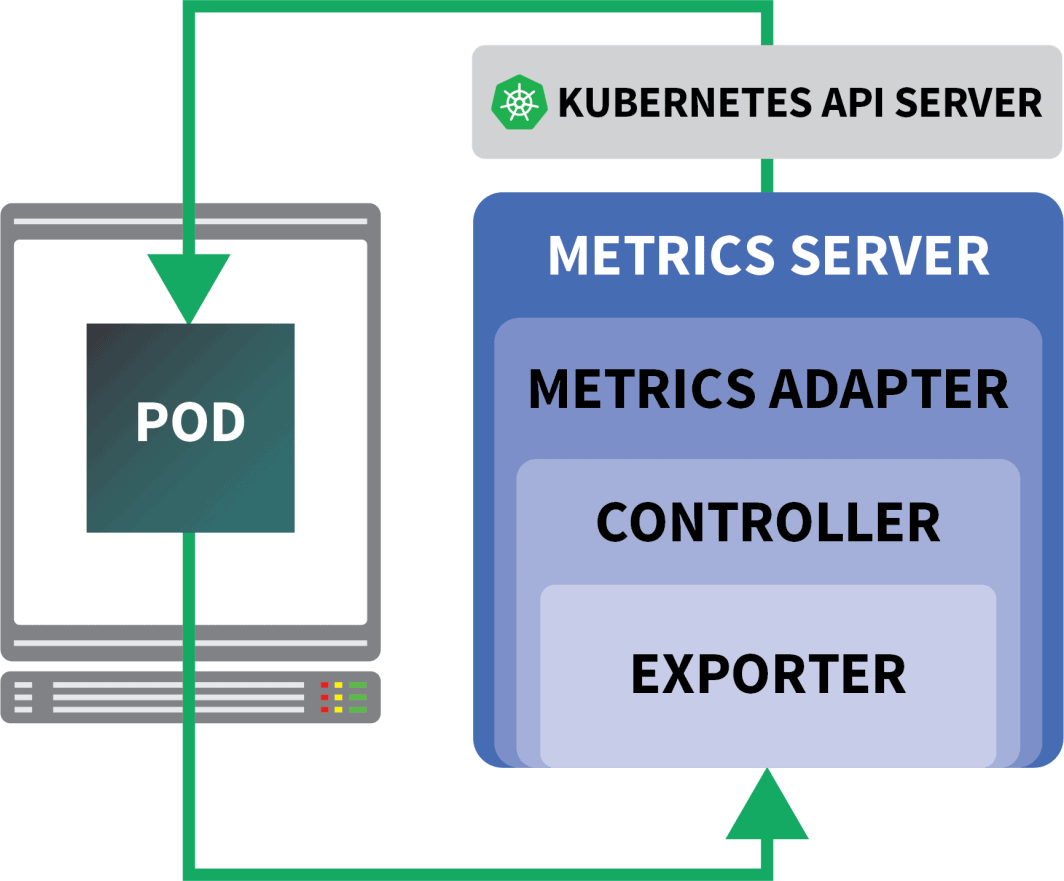
Você pode instalar a KEDA com o Helm:
bash
$ helm repo add kedacore https://kedacore.github.io/charts
$ helm install keda kedacore/kedaAgora que Prometheus e KEDA estão instalados, vamos criar uma implantação.
Para esta experiência, você usará um aplicativo projetado para lidar com um número fixo de solicitações por segundo.
Cada cápsula pode processar no máximo dez pedidos por segundo. Se a cápsula receber a 11ª solicitação, ela deixará a solicitação pendente e a processará mais tarde.
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
replicas: 4
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
annotations:
prometheus.io/scrape: "true"
spec:
containers:
- name: podinfo
image: learnk8s/rate-limiter:1.0.0
imagePullPolicy: Always
args: ["/app/index.js", "10"]
ports:
- containerPort: 8080
resources:
requests:
memory: 0.9G
---
apiVersion: v1
kind: Service
metadata:
name: podinfo
spec:
ports:
- port: 80
targetPort: 8080
selector:
app: podinfoVocê pode enviar o recurso para o agrupamento com:
bash
$ kubectl apply -f rate-limiter.yamlPara gerar algum tráfego, você usará Locust.
A seguinte definição de YAML cria um cluster de teste de carga distribuído:
yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: locust-script
data:
locustfile.py: |-
from locust import HttpUser, task, between
class QuickstartUser(HttpUser):
@task
def hello_world(self):
self.client.get("/", headers={"Host": "example.com"})
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: locust
spec:
selector:
matchLabels:
app: locust-primary
template:
metadata:
labels:
app: locust-primary
spec:
containers:
- name: locust
image: locustio/locust
args: ["--master"]
ports:
- containerPort: 5557
name: comm
- containerPort: 5558
name: comm-plus-1
- containerPort: 8089
name: web-ui
volumeMounts:
- mountPath: /home/locust
name: locust-script
volumes:
- name: locust-script
configMap:
name: locust-script
---
apiVersion: v1
kind: Service
metadata:
name: locust
spec:
ports:
- port: 5557
name: communication
- port: 5558
name: communication-plus-1
- port: 80
targetPort: 8089
name: web-ui
selector:
app: locust-primary
type: LoadBalancer
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: locust
spec:
selector:
matchLabels:
app: locust-worker
template:
metadata:
labels:
app: locust-worker
spec:
containers:
- name: locust
image: locustio/locust
args: ["--worker", "--master-host=locust"]
volumeMounts:
- mountPath: /home/locust
name: locust-script
volumes:
- name: locust-script
configMap:
name: locust-scriptVocê pode submetê-lo ao agrupamento com:
bash
$ kubectl locust.yamlGafanhoto lê o seguinte locustfile.pyque é armazenado em um ConfigMap:
py
from locust import HttpUser, task, between
class QuickstartUser(HttpUser):
@task
def hello_world(self):
self.client.get("/")O arquivo não faz nada de especial além de fazer um pedido para uma URL. Para conectar-se ao painel de controle da Locust, é necessário o endereço IP de seu equilibrador de carga.
Você pode recuperá-la com o seguinte comando:
bash
$ kubectl get service locust -o jsonpath='{.status.loadBalancer.ingress[0].ip}'Abra seu navegador e digite esse endereço IP.
Excelente!
Falta uma peça: o Autoscaler Horizontal Pod.
O autoscaler KEDA envolve o Autoscaler Horizontal com um objeto específico chamado ScaledObject.
yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: podinfo
spec:
scaleTargetRef:
kind: Deployment
name: podinfo
minReplicaCount: 1
maxReplicaCount: 30
cooldownPeriod: 30
pollingInterval: 1
triggers:
- type: prometheus
metadata:
serverAddress: http://prometheus-server
metricName: connections_active_keda
query: |
sum(increase(http_requests_total{app="podinfo"}[60s]))
threshold: "480" # 8rps * 60sA KEDA faz a ponte entre as métricas coletadas por Prometheus e as alimenta com Kubernetes.
Finalmente, ele cria um Pod Autoscaler Horizontal (HPA) com essas métricas.
Você pode inspecionar manualmente o HPA com:
bash
$ kubectl get hpa
$ kubectl describe hpa keda-hpa-podinfoVocê pode apresentar o objeto com:
bash
$ kubectl apply -f scaled-object.yamlÉ hora de testar se a escalada funciona.
No painel de controle de Gafanhoto, lançar uma experiência com as seguintes configurações:
- Número de usuários:
300 - Taxa de reprodução:
0.4 - Anfitrião:
http://podinfo
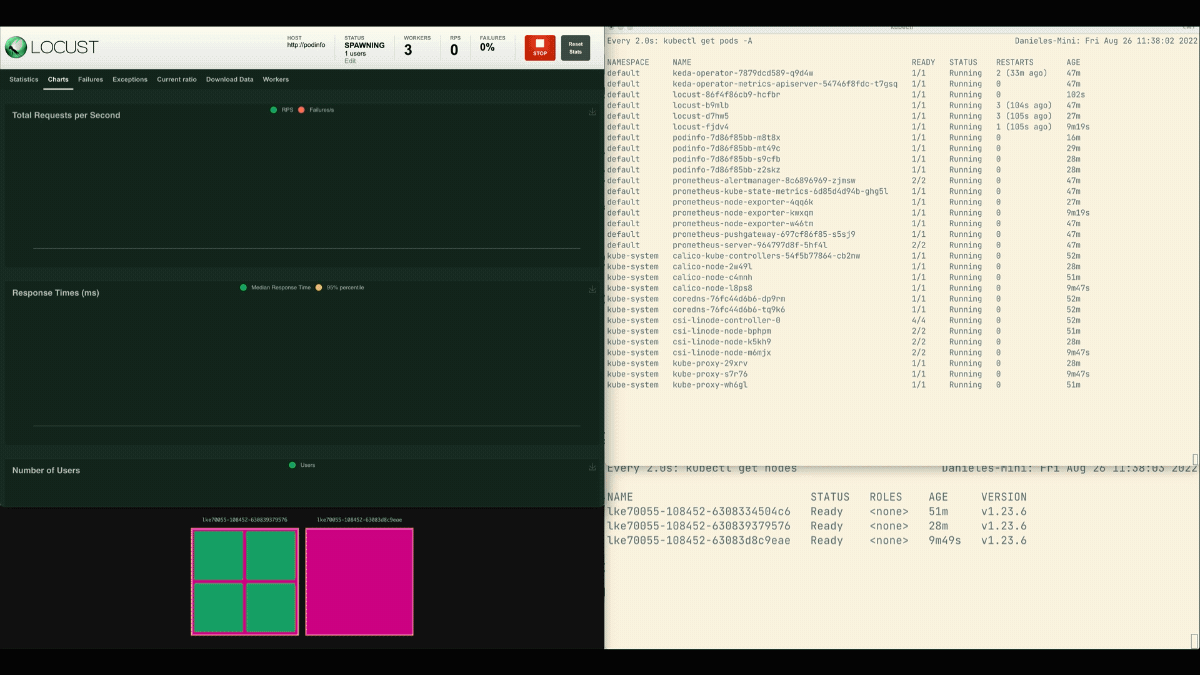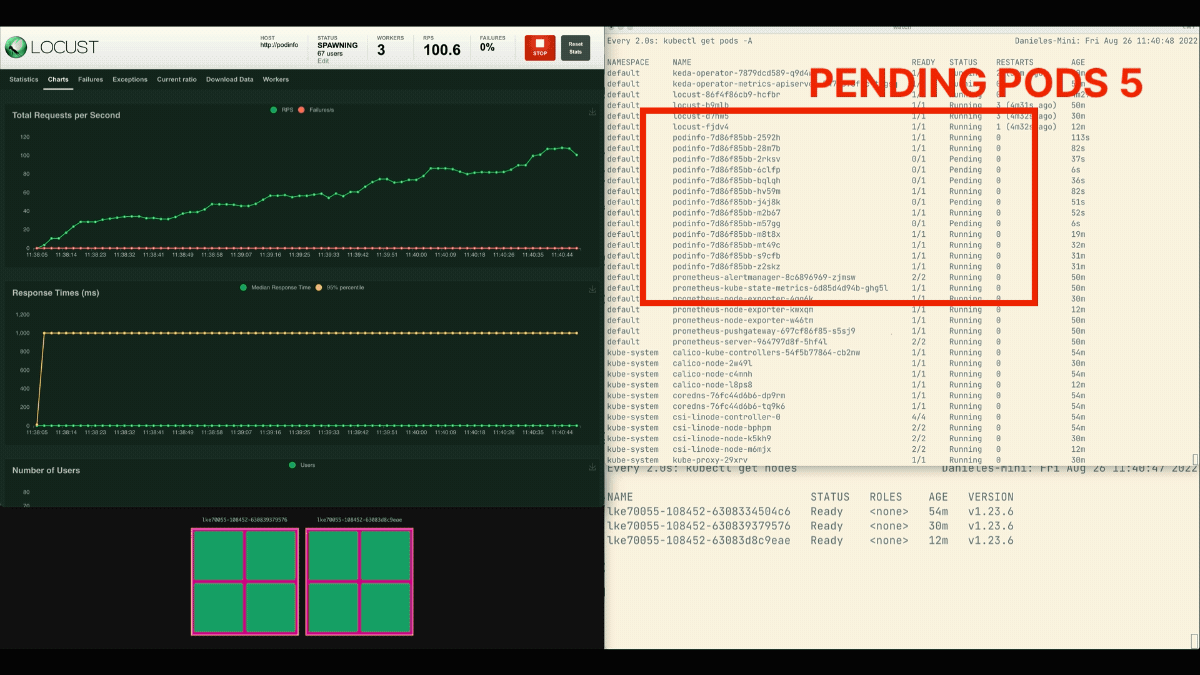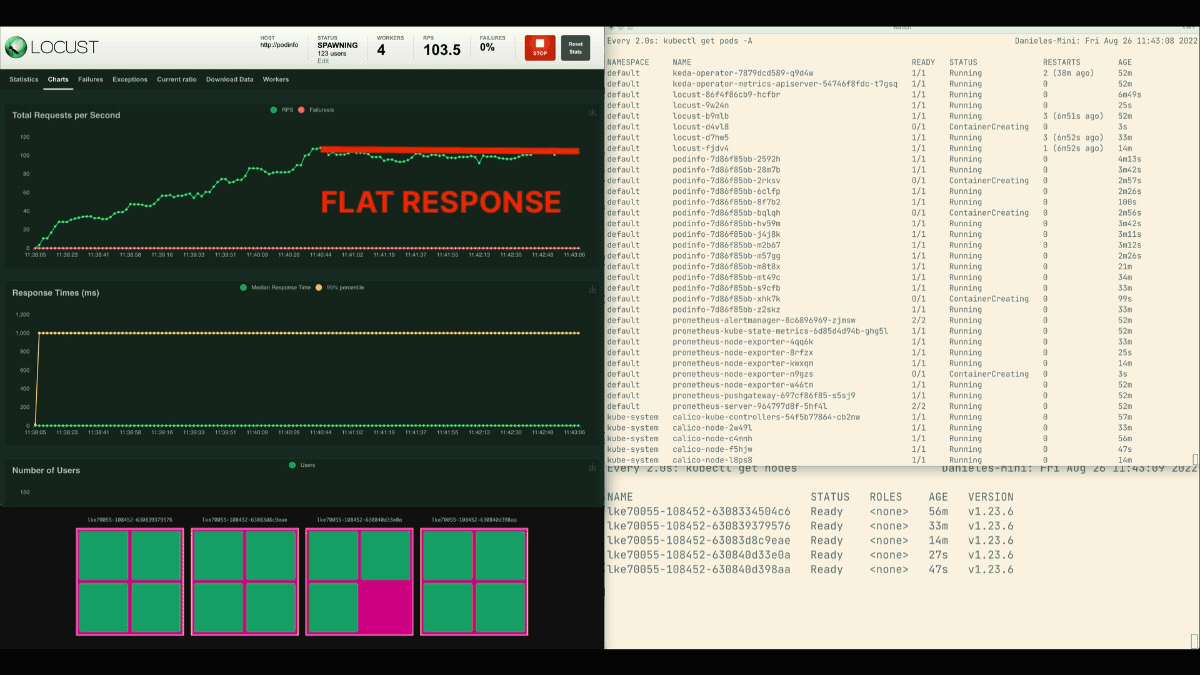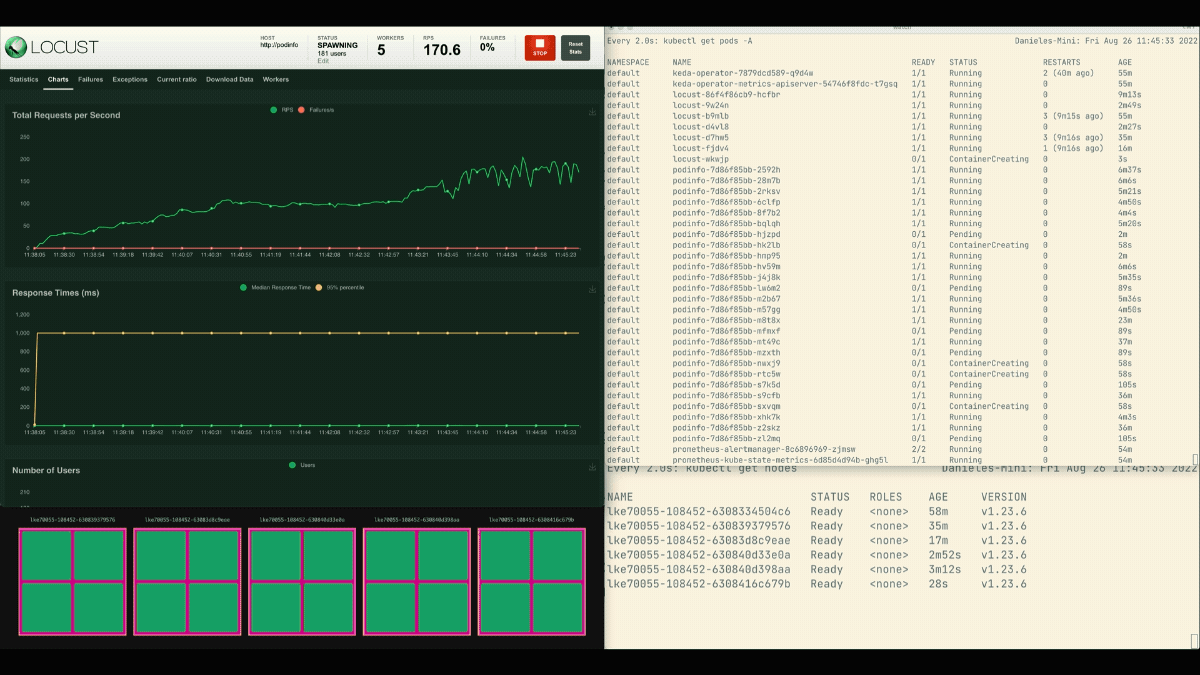
O número de réplicas está aumentando!
Excelente! Mas você notou?
Após as escalas de implantação para 8 pods, é preciso esperar alguns minutos antes que mais pods sejam criados no novo nó.
Neste período, os pedidos por segundo estagnam porque as oito réplicas atuais só podem atender dez pedidos cada uma.
Vamos reduzir a escala e repetir a experiência:
bash
kubectl scale deployment/podinfo --replicas=4 # or wait for the autoscaler to remove podsDesta vez, vamos suprir o nódulo com a cápsula de suporte do lugar:
yaml
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: overprovisioning
value: -1
globalDefault: false
description: "Priority class used by overprovisioning."
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning
spec:
replicas: 1
selector:
matchLabels:
run: overprovisioning
template:
metadata:
labels:
run: overprovisioning
spec:
priorityClassName: overprovisioning
containers:
- name: pause
image: k8s.gcr.io/pause
resources:
requests:
cpu: 900m
memory: 3.9GVocê pode submetê-lo ao agrupamento com:
bash
kubectl apply -f placeholder.yamlAbra o painel de controle de Gafanhoto e repita a experiência com as seguintes configurações:
- Número de usuários:
300 - Taxa de reprodução:
0.4 - Anfitrião:
http://podinfo
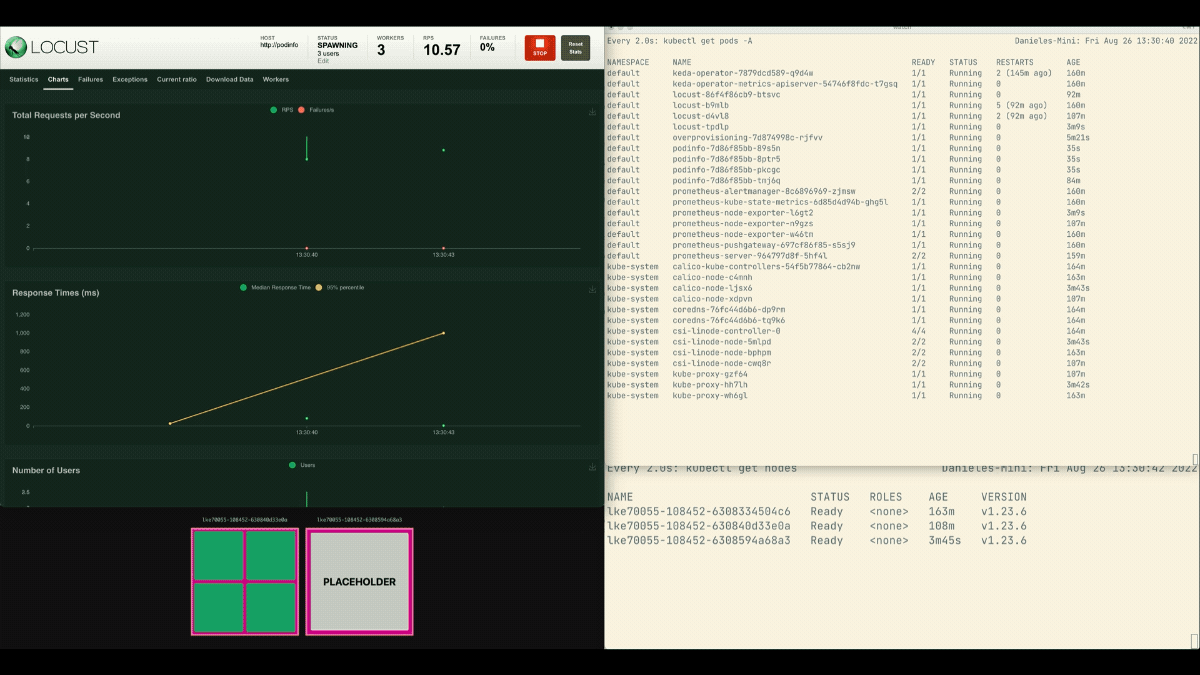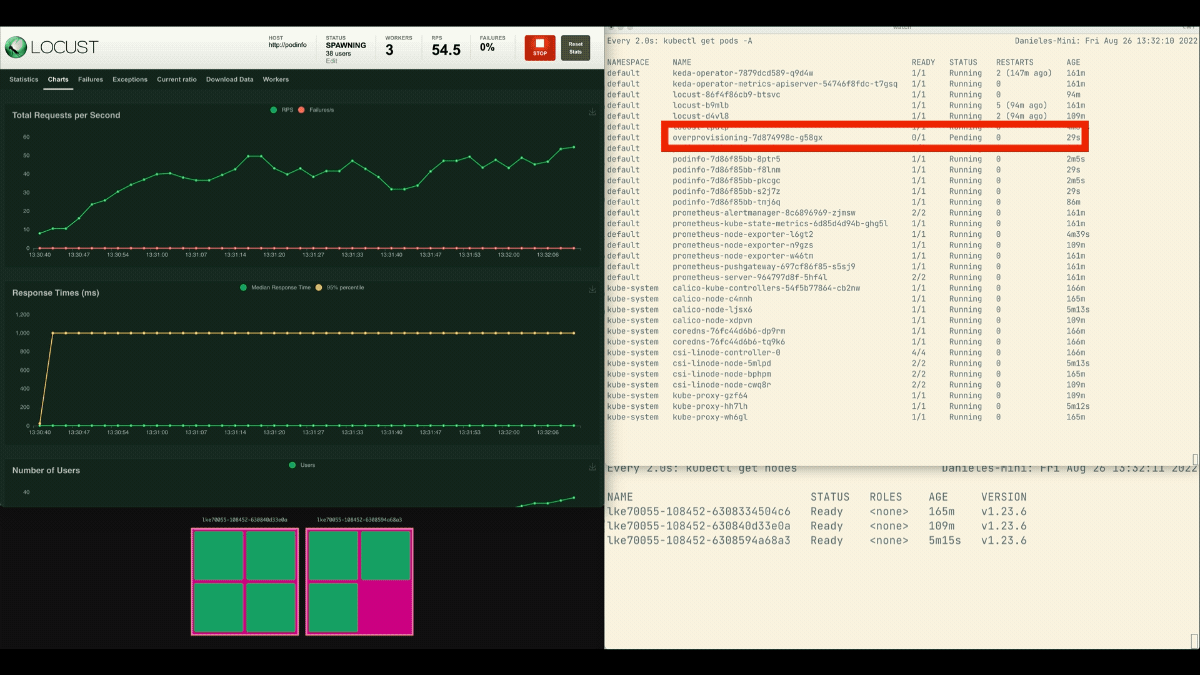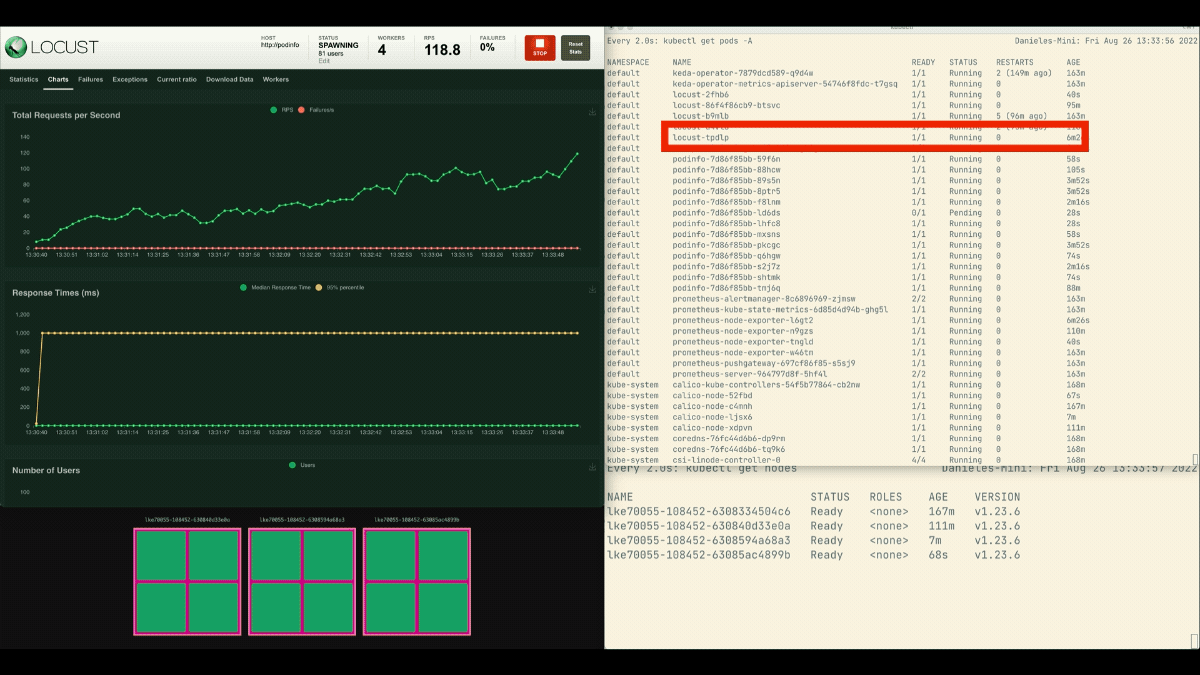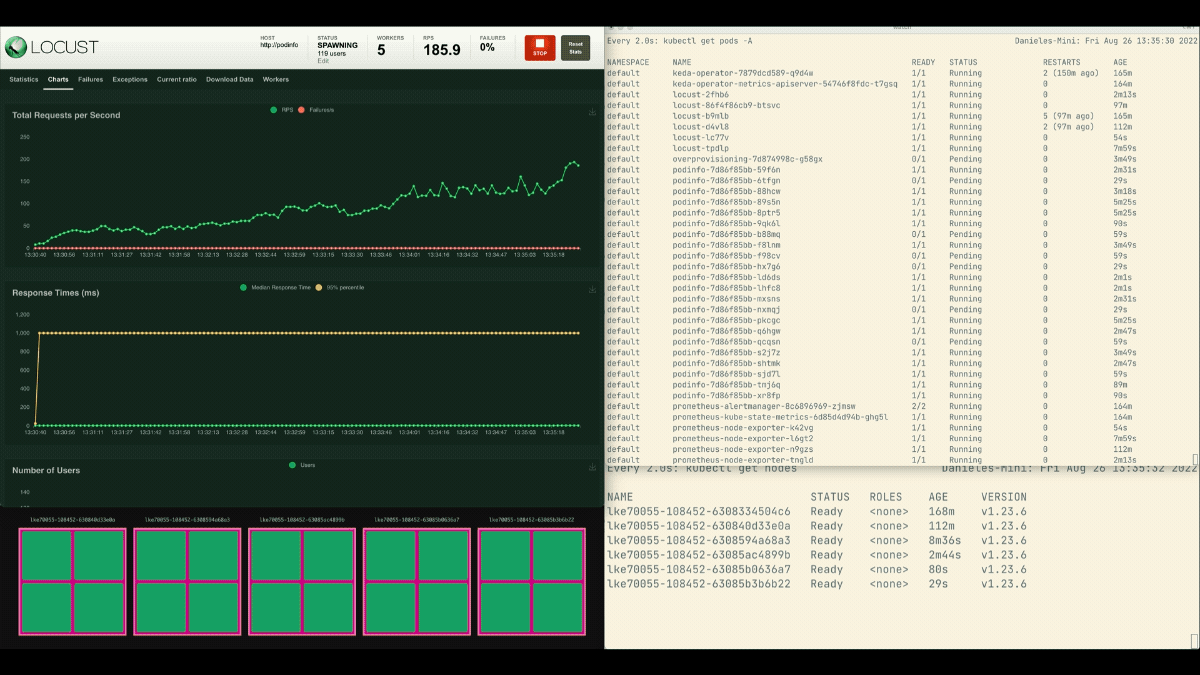
Desta vez, novos nós são criados em segundo plano e as solicitações por segundo aumentam sem aplanar. Ótimo trabalho!
Vamos recapitular o que você aprendeu neste post:
- o autoscalador de cluster não rastreia o consumo de CPU ou memória. Ao invés disso, ele monitora as cápsulas pendentes;
- você pode criar um módulo que utiliza a memória total e a CPU disponível para fornecer um nó Kubernetes de forma pró-ativa;
- Os nós Kubernetes têm recursos reservados para kubelet, sistema operacional e limiar de despejo; e
- você pode combinar Prometheus com a KEDA para dimensionar sua cápsula com uma consulta PromQL.
Quer seguir junto com nossa série de webinars Kubernetes em escala? Registre-se para começar, e aprenda mais sobre o uso da KEDA para escalar os clusters Kubernetes a zero.



Comentários