

이 게시물은 쿠버네티스 스케일링 시리즈의 일부입니다. 등록하여 라이브로 시청하거나 녹화에 액세스하고 이 시리즈의 다른 게시물을 확인하십시오.
클러스터의 리소스가 부족하면 클러스터 자동 크기 조정기가 새 노드를 프로비저닝하여 클러스터에 추가합니다. 이미 Kubernetes 사용자인 경우 클러스터에 노드를 만들고 추가하는 데 몇 분 정도 걸린다는 것을 눈치챘을 것입니다.
이 시간 동안 앱은 더 이상 확장할 수 없기 때문에 연결에 쉽게 압도될 수 있습니다.

긴 대기 시간을 어떻게 해결할 수 있습니까?
사전 예방적 크기 조정 또는 :
- 클러스터 자동 크기 조정기의 작동 방식을 이해하고 유용성을 극대화합니다.
- 쿠버네티스 스케줄러를 사용하여 노드에 포드를 할당하는 단계; 그리고
- 작업자 노드를 미리 프로비저닝하여 확장 불량을 방지합니다.
이 자습서의 코드를 읽으려는 경우 LearnK8s GitHub에서 찾을 수 있습니다.
클러스터 오토스케일러가 쿠버네티스에서 작동하는 방식
클러스터 자동 크기 조정기는 자동 크기 조정을 트리거할 때 메모리 또는 CPU 가용성을 확인하지 않습니다. 대신 클러스터 자동 크기 조정기는 이벤트에 반응하고 예약할 수 없는 포드가 있는지 확인합니다. 포드는 스케줄러가 이를 수용할 수 있는 노드를 찾을 수 없는 경우 스케줄링할 수 없습니다.
클러스터를 만들어 테스트해 보겠습니다.
bash
$ linode-cli lke cluster-create \
--label learnk8s \
--region eu-west \
--k8s_version 1.23 \
--node_pools.count 1 \
--node_pools.type g6-standard-2 \
--node_pools.autoscaler.enabled enabled \
--node_pools.autoscaler.max 10 \
--node_pools.autoscaler.min 1 \
$ linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfig다음 세부 정보에주의해야합니다.
- 각 노드에는 4GB 메모리와 2 개의 vCPU (예 : 'g6-standard-2')가 있습니다.
- 클러스터에 단일 노드가 있습니다. 그리고
- 클러스터 자동 크기 조정기는 노드를 1개에서 10개로 늘리도록 구성됩니다.
다음을 사용하여 설치가 성공했는지 확인할 수 있습니다.
bash
$ kubectl get pods -A --kubeconfig=kubeconfigkubeconfig 파일을 환경 변수로 내보내는 것이 일반적으로 더 편리합니다.
다음을 사용하여 그렇게 할 수 있습니다.
bash
$ export KUBECONFIG=${PWD}/kubeconfig
$ kubectl get pods훌륭한!
응용 프로그램 배포
1GB의 메모리와 250m*의 CPU가 필요한 응용 프로그램을 배포해 보겠습니다.Note: m = thousandth of a core, so 250m = 25% of the CPU
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
replicas: 1
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
spec:
containers:
- name: podinfo
image: stefanprodan/podinfo
ports:
- containerPort: 9898
resources:
requests:
memory: 1G
cpu: 250m다음을 사용하여 클러스터에 리소스를 제출할 수 있습니다.
bash
$ kubectl apply -f podinfo.yaml그렇게하자마자 몇 가지 사실을 알 수 있습니다. 첫째, 세 개의 포드가 거의 즉시 실행되고 하나는 보류 중입니다.

그런 다음:
- 몇 분 후 자동 크기 조정기는 추가 노드를 만듭니다. 그리고
- 네 번째 포드는 새 노드에 배포됩니다.

네 번째 포드가 첫 번째 노드에 배포되지 않는 이유는 무엇입니까? 할당 가능한 리소스를 살펴 보겠습니다.
쿠버네티스 노드의 할당 가능한 리소스
Kubernetes 클러스터에 배포된 포드는 메모리, CPU 및 스토리지 리소스를 사용합니다.
그러나 동일한 노드에서 운영 체제와 kubelet에는 메모리와 CPU가 필요합니다.
쿠버네티스 노동자 노드에서 메모리와 CPU는 다음과 같이 나뉩니다.
- 운영 체제 및 SSH, systemd 등과 같은 시스템 데몬을 실행하는 데 필요한 리소스입니다.
- Kubelet, 컨테이너 런타임, 노드 문제 탐지기 등과 같은 Kubernetes 에이전트를 실행하는 데 필요한 리소스입니다.
- Pods에서 사용할 수 있는 리소스입니다.
- 제거 임계값에 대해 예약된 리소스입니다.
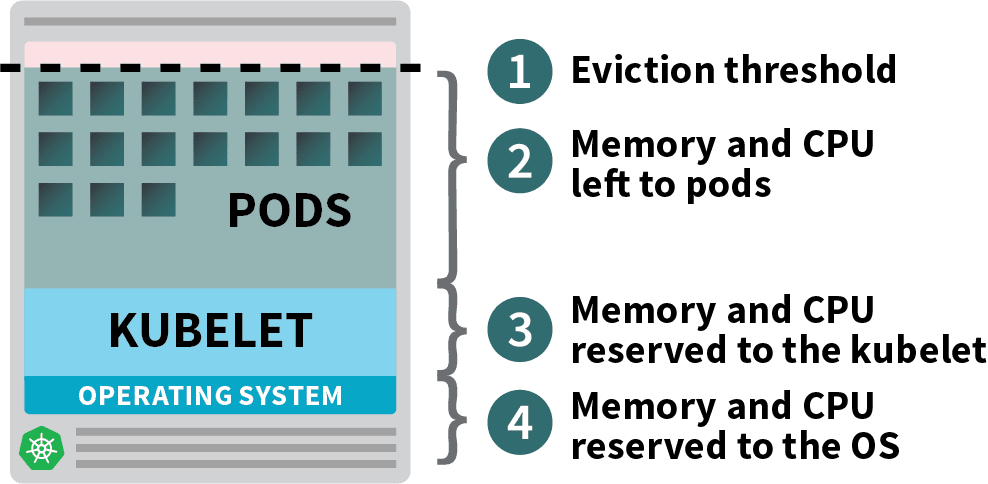
클러스터에서 kube-proxy와 같은 데몬셋을 실행하는 경우 사용 가능한 메모리와 CPU를 더 줄여야 합니다.
따라서 모든 포드가 단일 노드에 들어갈 수 있는지 확인하기 위해 요구 사항을 낮추겠습니다.
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
replicas: 4
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
spec:
containers:
- name: podinfo
image: stefanprodan/podinfo
ports:
- containerPort: 9898
resources:
requests:
memory: 0.8G # <- lower memory
cpu: 200m # <- lower CPU다음을 사용하여 배포를 수정할 수 있습니다.
bash
$ kubectl apply -f podinfo.yaml인스턴스를 최적화하기 위해 적절한 양의 CPU와 메모리를 선택하는 것은 까다로울 수 있습니다. Learnk8s 도구 계산기를 사용하면 이 작업을 더 빠르게 수행할 수 있습니다.
한 가지 문제를 해결했지만 새 노드를 만드는 데 걸리는 시간은 어떻습니까?
조만간 네 개 이상의 복제본이 생깁니다. 새 포드가 만들어지기 전에 몇 분 정도 기다려야합니까?
짧은 대답은 '예'입니다.
Linode는 처음부터 가상 머신을 생성하고, 프로비저닝하고, 클러스터에 연결해야 합니다. 이 과정은 쉽게 두 분 이상 걸릴 수 있습니다.
그러나 대안이 있습니다.
필요할 때 이미 프로비저닝된 노드를 미리 만들 수 있습니다.
예: 자동 크기 조정기에는 항상 하나의 예비 노드가 있도록 구성할 수 있습니다. 포드가 예비 노드에 배포되면 자동 크기 조정기가 사전에 더 많은 포드를 만들 수 있습니다. 불행히도 자동 크기 조정기에는이 기본 제공 기능이 없지만 쉽게 다시 만들 수 있습니다.
노드의 리소스와 동일한 요청이 있는 포드를 만들 수 있습니다.
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning
spec:
replicas: 1
selector:
matchLabels:
run: overprovisioning
template:
metadata:
labels:
run: overprovisioning
spec:
containers:
- name: pause
image: k8s.gcr.io/pause
resources:
requests:
cpu: 900m
memory: 3.8G다음을 사용하여 클러스터에 리소스를 제출할 수 있습니다.
bash
kubectl apply -f placeholder.yaml이 포드는 절대적으로 아무것도하지 않습니다.
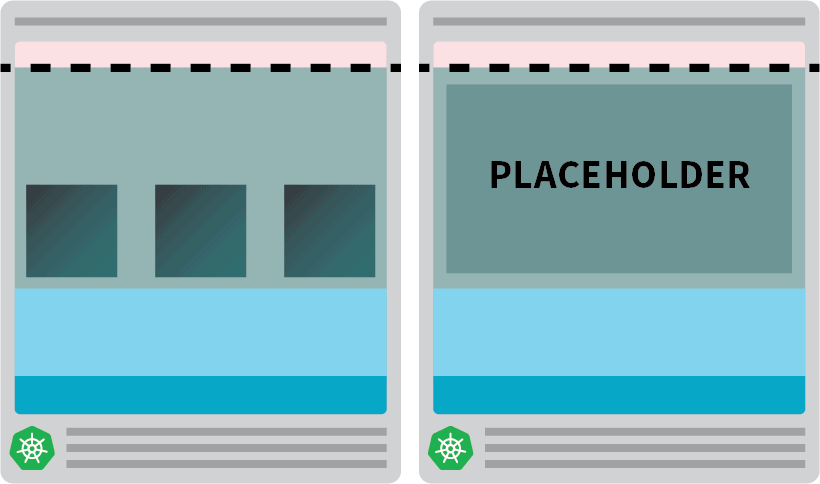
노드를 완전히 점유 상태로 유지합니다.
다음 단계는 크기 조정이 필요한 워크로드가 있는 즉시 자리 표시자 포드가 제거되도록 하는 것입니다.
이를 위해 우선 순위 클래스를 사용할 수 있습니다.
yaml
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: overprovisioning
value: -1
globalDefault: false
description: "Priority class used by overprovisioning."
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning
spec:
replicas: 1
selector:
matchLabels:
run: overprovisioning
template:
metadata:
labels:
run: overprovisioning
spec:
priorityClassName: overprovisioning # <--
containers:
- name: pause
image: k8s.gcr.io/pause
resources:
requests:
cpu: 900m
memory: 3.8G그리고 다음을 사용하여 클러스터에 다시 제출하십시오.
bash
kubectl apply -f placeholder.yaml이제 설정이 완료되었습니다.
자동 크기 조정기가 노드를 만들 때까지 잠시 기다려야 할 수도 있지만 이 시점에서 두 개의 노드가 있어야 합니다.
- 네 개의 포드가 있는 노드입니다.
- 자리 표시자 포드가있는 또 다른 하나.
배포를 복제본 5개로 확장하면 어떻게 되나요? 자동 크기 조정기가 새 노드를 만들 때까지 기다려야합니까?
테스트해 보겠습니다.
bash
kubectl scale deployment/podinfo --replicas=5다음을 관찰해야합니다.
- 다섯 번째 포드는 즉시 생성되며 10초 이내에 실행 중 상태가 됩니다.
- 자리 표시자 포드는 포드를 위한 공간을 만들기 위해 제거되었습니다.

그런 다음:
- 클러스터 자동 크기 조정기는 보류 중인 자리 표시자 포드를 확인하고 새 노드를 프로비전했습니다.
- 자리 표시자 포드는 새로 만든 노드에 배포됩니다.
더 많은 노드를 가질 수있을 때 적극적으로 단일 노드를 만드는 이유는 무엇입니까?
자리 표시자 포드를 여러 복제본으로 확장할 수 있습니다. 각 복제본은 표준 워크로드를 수용할 준비가 된 Kubernetes 노드를 사전 프로비저닝합니다. 그러나 이러한 노드는 여전히 클라우드 청구서에 포함되지만 유휴 상태로 앉아서 아무 것도하지 않습니다. 따라서 조심해야하며 너무 많은 것을 만들지 않아야합니다.
클러스터 자동 크기 조정기와 수평 포드 자동 크기 조정기 결합
이 기술의 의미를 이해하려면 클러스터 자동 크기 조정기를 HPA(Horizontal Pod Autoscaler)와 결합해 보겠습니다. HPA는 배포에서 복제본을 늘리도록 설계되었습니다.
응용 프로그램이 더 많은 트래픽을 수신하면 자동 크기 조정기가 복제본 수를 조정하여 더 많은 요청을 처리하도록 할 수 있습니다.
포드가 사용 가능한 모든 리소스를 소진하면 클러스터 자동 크기 조정기가 HPA가 더 많은 복제본을 계속 만들 수 있도록 새 노드 생성을 트리거합니다.
새 클러스터를 만들어 테스트해 보겠습니다.
bash
$ linode-cli lke cluster-create \
--label learnk8s-hpa \
--region eu-west \
--k8s_version 1.23 \
--node_pools.count 1 \
--node_pools.type g6-standard-2 \
--node_pools.autoscaler.enabled enabled \
--node_pools.autoscaler.max 10 \
--node_pools.autoscaler.min 3 \
$ linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfig-hpa다음을 사용하여 설치가 성공했는지 확인할 수 있습니다.
bash
$ kubectl get pods -A --kubeconfig=kubeconfig-hpakubeconfig 파일을 환경 변수로 내보내는 것이 더 편리합니다.
다음을 사용하여 그렇게 할 수 있습니다.
bash
$ export KUBECONFIG=${PWD}/kubeconfig-hpa
$ kubectl get pods훌륭한!
헬름을 사용하여 설치합시다. Prometheus 배포에서 메트릭을 긁어냅니다.
Helm을 설치하는 방법에 대한 지침은 공식 웹 사이트에서 찾을 수 있습니다.
bash
$ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
$ helm install prometheus prometheus-community/prometheus쿠버네티스는 HPA에 복제본을 동적으로 늘리거나 줄일 수 있는 컨트롤러를 제공합니다.
불행히도 HPA에는 몇 가지 단점이 있습니다.
- 그것은 상자에서 작동하지 않습니다. 메트릭을 집계하고 노출하려면 메트릭 서버를 설치해야 합니다.
- PromQL 쿼리는 즉시 사용할 수 없습니다.
다행히도 HPA 컨트롤러를 확장하는 KEDA를 사용할 수 있습니다 (에서 메트릭 읽기 포함) Prometheus).
KEDA는 세 가지 구성 요소로 구성된 자동 스케일러입니다.
- 스케일러
- 메트릭 어댑터
- 컨트롤러
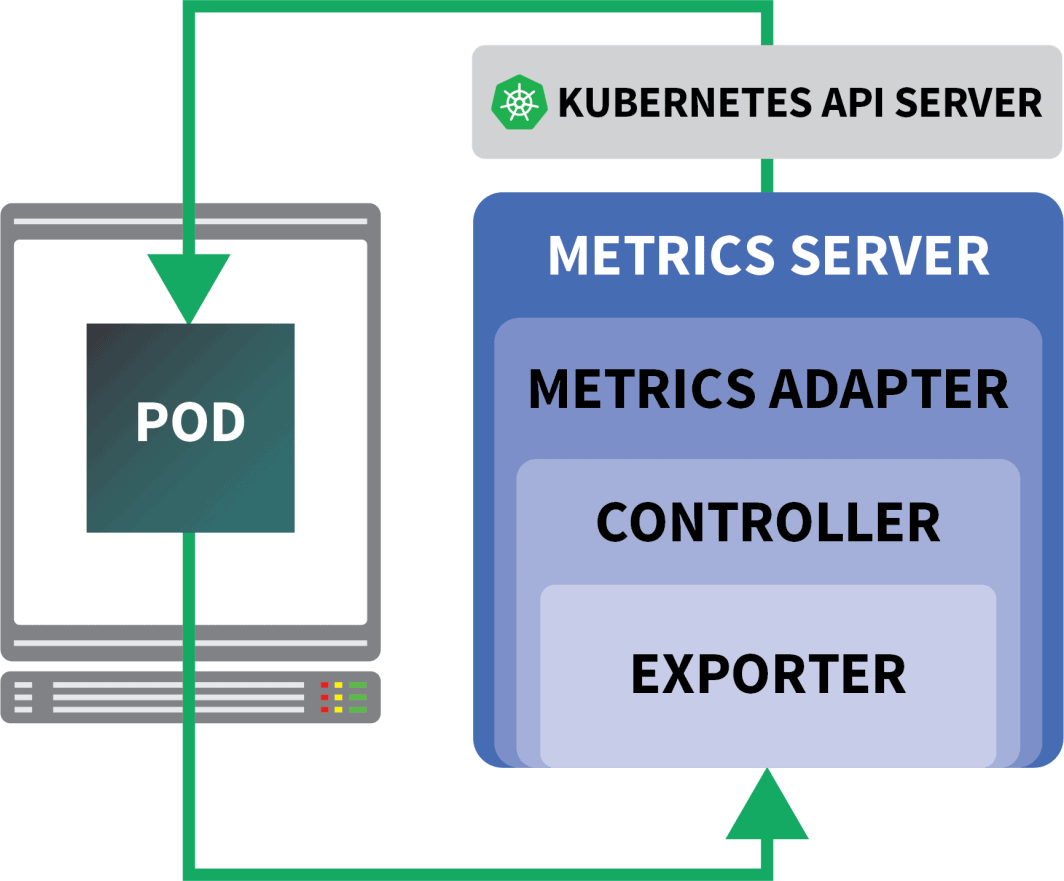
헬름으로 KEDA를 설치할 수 있습니다 :
bash
$ helm repo add kedacore https://kedacore.github.io/charts
$ helm install keda kedacore/keda이제 Prometheus KEDA가 설치되면 배포를 만들어 보겠습니다.
이 실험에서는 고정된 초당 요청 수를 처리하도록 설계된 앱을 사용합니다.
각 포드는 초당 최대 열 개의 요청을 처리할 수 있습니다. 포드가 11번째 요청을 수신하면 요청을 보류 상태로 두고 나중에 처리합니다.
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
replicas: 4
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
annotations:
prometheus.io/scrape: "true"
spec:
containers:
- name: podinfo
image: learnk8s/rate-limiter:1.0.0
imagePullPolicy: Always
args: ["/app/index.js", "10"]
ports:
- containerPort: 8080
resources:
requests:
memory: 0.9G
---
apiVersion: v1
kind: Service
metadata:
name: podinfo
spec:
ports:
- port: 80
targetPort: 8080
selector:
app: podinfo다음을 사용하여 클러스터에 리소스를 제출할 수 있습니다.
bash
$ kubectl apply -f rate-limiter.yaml일부 트래픽을 생성하려면 Locust를 사용합니다.
다음 YAML 정의는 분산 부하 테스트 클러스터를 만듭니다.
yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: locust-script
data:
locustfile.py: |-
from locust import HttpUser, task, between
class QuickstartUser(HttpUser):
@task
def hello_world(self):
self.client.get("/", headers={"Host": "example.com"})
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: locust
spec:
selector:
matchLabels:
app: locust-primary
template:
metadata:
labels:
app: locust-primary
spec:
containers:
- name: locust
image: locustio/locust
args: ["--master"]
ports:
- containerPort: 5557
name: comm
- containerPort: 5558
name: comm-plus-1
- containerPort: 8089
name: web-ui
volumeMounts:
- mountPath: /home/locust
name: locust-script
volumes:
- name: locust-script
configMap:
name: locust-script
---
apiVersion: v1
kind: Service
metadata:
name: locust
spec:
ports:
- port: 5557
name: communication
- port: 5558
name: communication-plus-1
- port: 80
targetPort: 8089
name: web-ui
selector:
app: locust-primary
type: LoadBalancer
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: locust
spec:
selector:
matchLabels:
app: locust-worker
template:
metadata:
labels:
app: locust-worker
spec:
containers:
- name: locust
image: locustio/locust
args: ["--worker", "--master-host=locust"]
volumeMounts:
- mountPath: /home/locust
name: locust-script
volumes:
- name: locust-script
configMap:
name: locust-script다음을 사용하여 클러스터에 제출할 수 있습니다.
bash
$ kubectl locust.yaml메뚜기는 다음을 읽습니다. locustfile.py- ConfigMap에 저장됩니다.
py
from locust import HttpUser, task, between
class QuickstartUser(HttpUser):
@task
def hello_world(self):
self.client.get("/")이 파일은 URL에 대한 요청과 별개로 특별한 작업을 수행하지 않습니다. Locust 대시보드에 연결하려면 로드 밸런서의 IP 주소가 필요합니다.
다음 명령을 사용하여 검색할 수 있습니다.
bash
$ kubectl get service locust -o jsonpath='{.status.loadBalancer.ingress[0].ip}'브라우저를 열고 해당 IP 주소를 입력합니다.
훌륭한!
누락 된 부분이 하나 있습니다 : 수평 포드 자동 스케일러.
KEDA 자동 크기 조정기는 수평 자동 크기 조정기를 ScaledObject라는 특정 개체로 래핑합니다.
yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: podinfo
spec:
scaleTargetRef:
kind: Deployment
name: podinfo
minReplicaCount: 1
maxReplicaCount: 30
cooldownPeriod: 30
pollingInterval: 1
triggers:
- type: prometheus
metadata:
serverAddress: http://prometheus-server
metricName: connections_active_keda
query: |
sum(increase(http_requests_total{app="podinfo"}[60s]))
threshold: "480" # 8rps * 60sKEDA는 수집한 메트릭을 연결합니다. Prometheus 그리고 그들을 쿠버네티스에 먹이준다.
마지막으로 이러한 메트릭을 사용하여 HPA(Horizontal Pod Autoscaler) 를 만듭니다.
다음을 사용하여 HPA를 수동으로 검사할 수 있습니다.
bash
$ kubectl get hpa
$ kubectl describe hpa keda-hpa-podinfo다음을 사용하여 객체를 제출할 수 있습니다.
bash
$ kubectl apply -f scaled-object.yaml스케일링이 작동하는지 테스트 할 때입니다.
Locust 대시보드에서 다음 설정으로 실험을 시작합니다.
- 사용자 수:
300 - 스폰 속도:
0.4 - 호스트:
http://podinfo
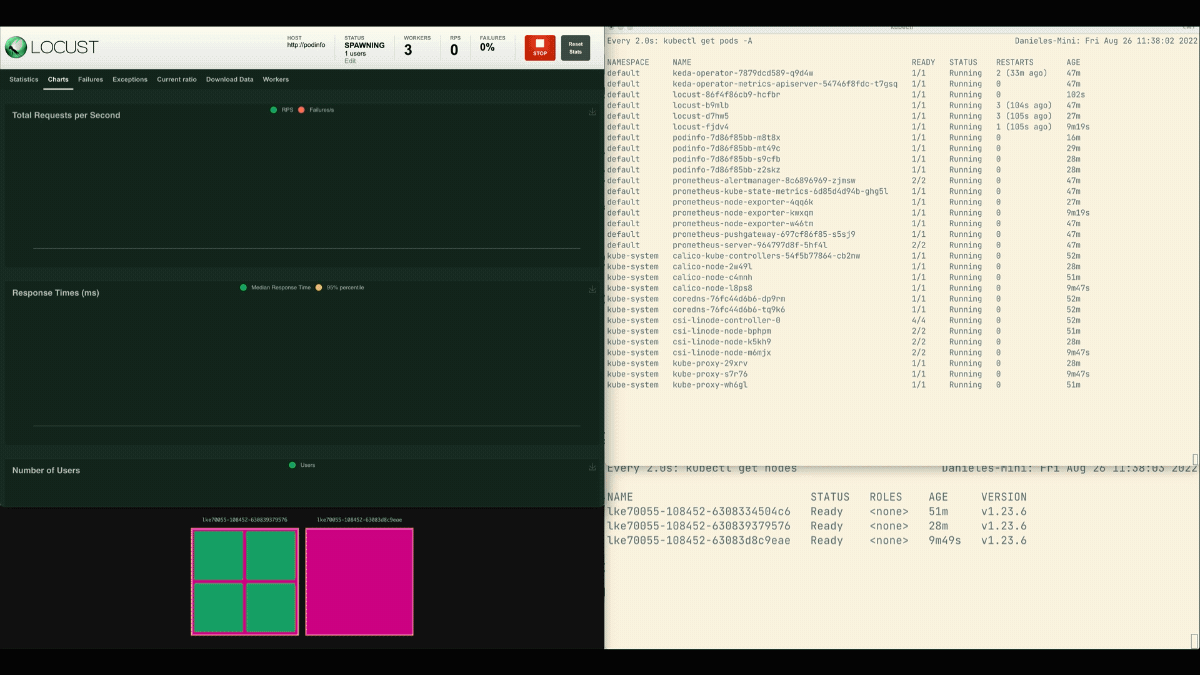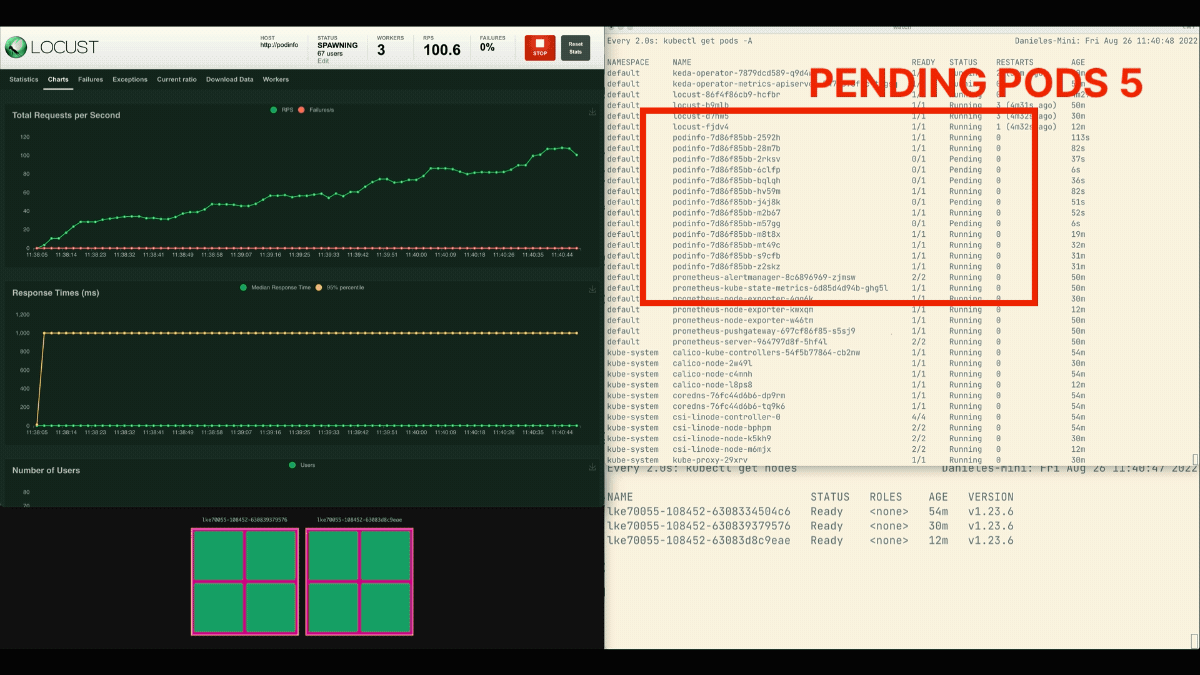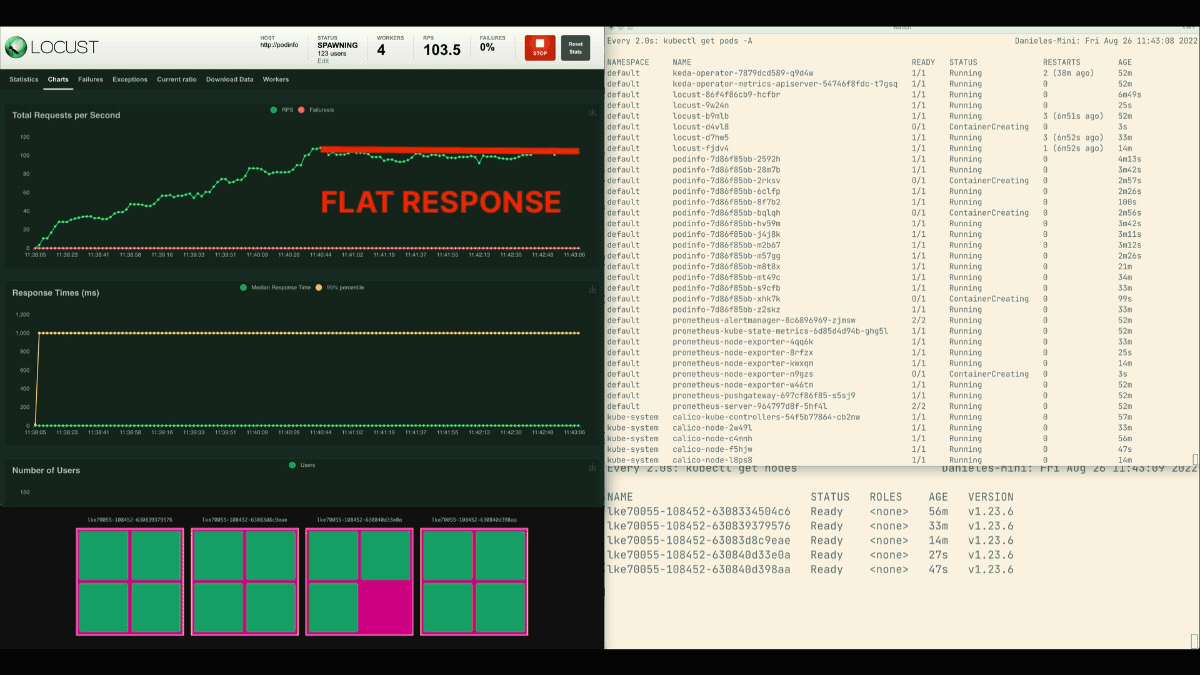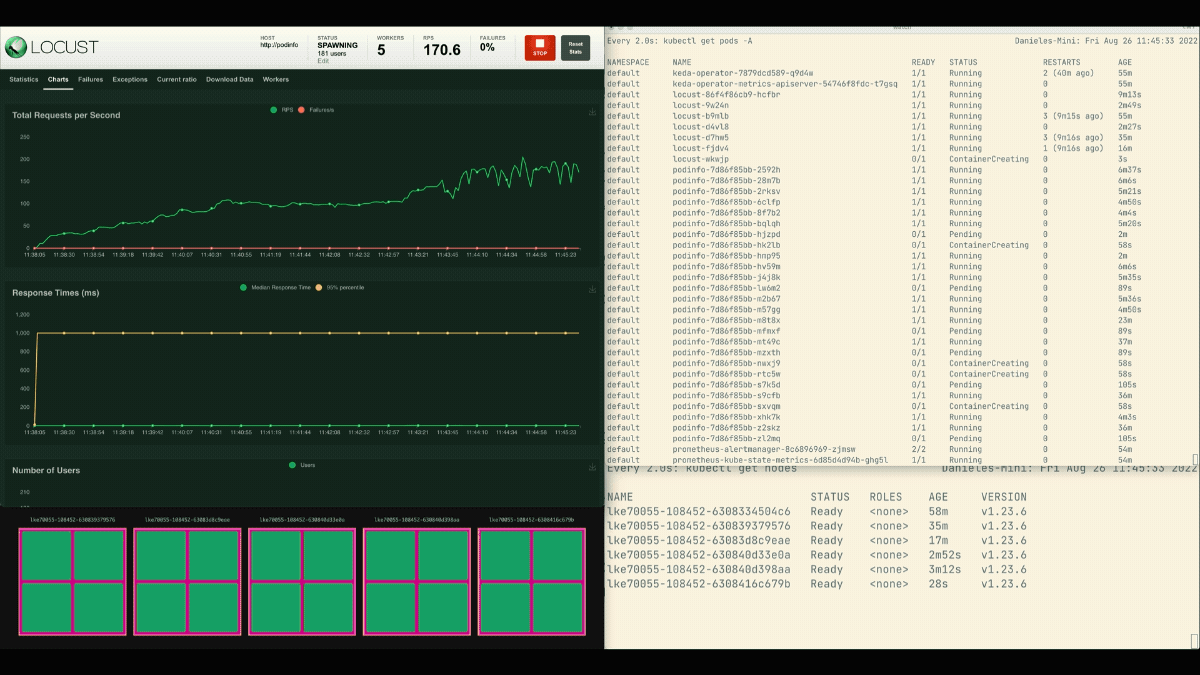
복제본의 수가 증가하고 있습니다!
훌륭한! 그러나 눈치 챘습니까?
배포가 8개의 포드로 확장되면 새 노드에 더 많은 포드가 만들어지기 전에 몇 분 정도 기다려야 합니다.
이 기간에는 현재 여덟 개의 복제본이 각각 열 개의 요청만 처리할 수 있기 때문에 초당 요청이 정체됩니다.
규모를 축소하고 실험을 반복해 보겠습니다.
bash
kubectl scale deployment/podinfo --replicas=4 # or wait for the autoscaler to remove pods이번에는 자리 표시자 포드로 노드를 과도하게 프로비저닝해 보겠습니다.
yaml
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: overprovisioning
value: -1
globalDefault: false
description: "Priority class used by overprovisioning."
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning
spec:
replicas: 1
selector:
matchLabels:
run: overprovisioning
template:
metadata:
labels:
run: overprovisioning
spec:
priorityClassName: overprovisioning
containers:
- name: pause
image: k8s.gcr.io/pause
resources:
requests:
cpu: 900m
memory: 3.9G다음을 사용하여 클러스터에 제출할 수 있습니다.
bash
kubectl apply -f placeholder.yamlLocust 대시보드를 열고 다음 설정으로 실험을 반복합니다.
- 사용자 수:
300 - 스폰 속도:
0.4 - 호스트:
http://podinfo
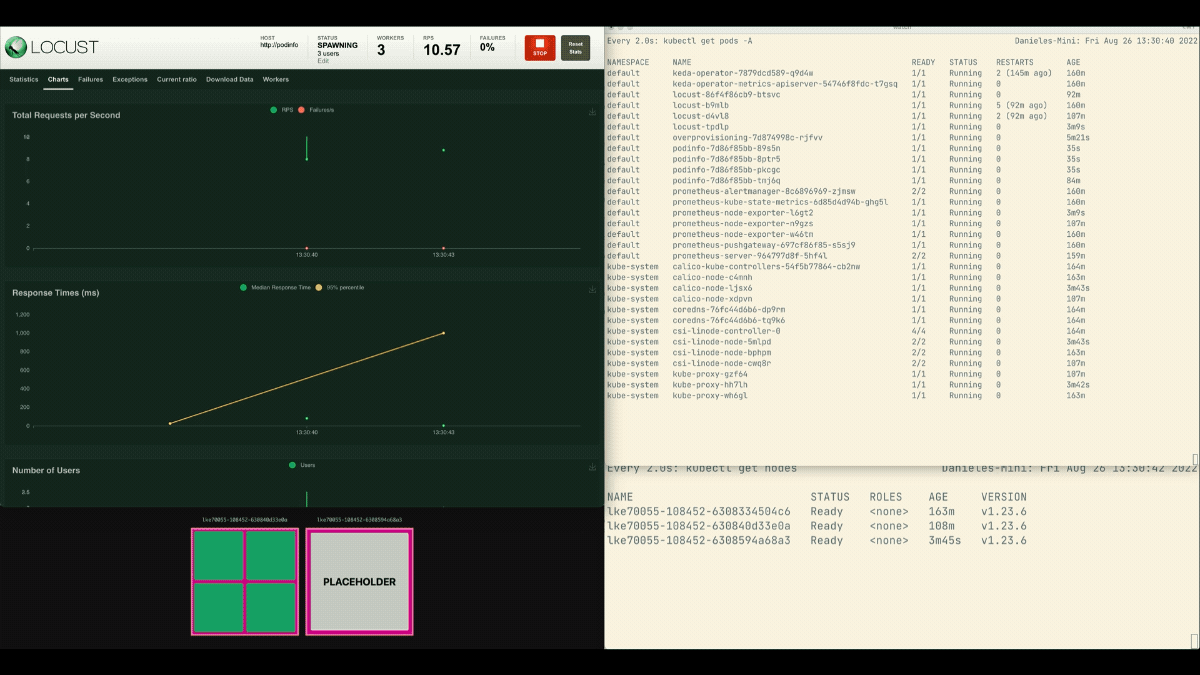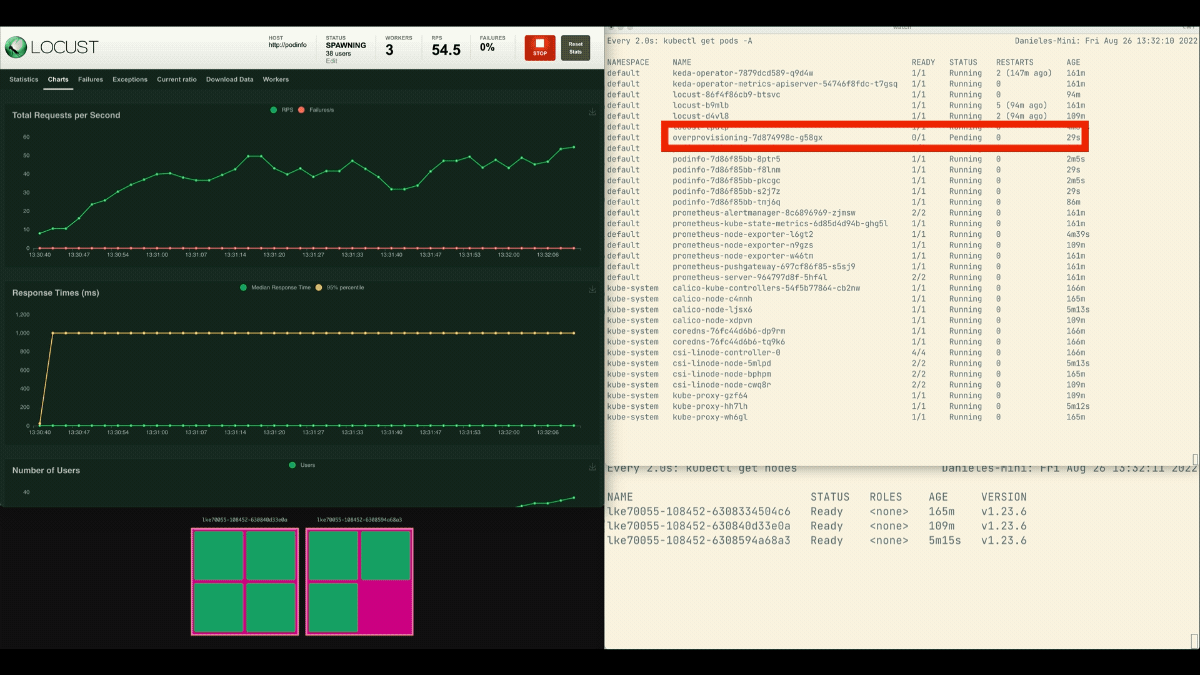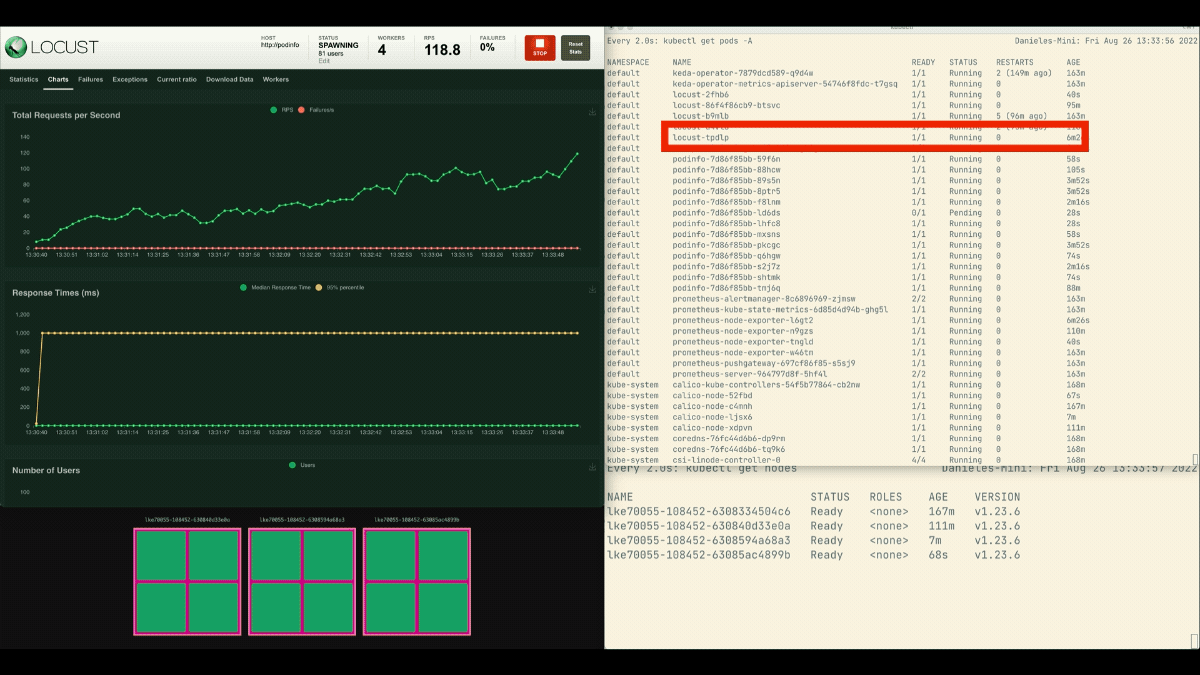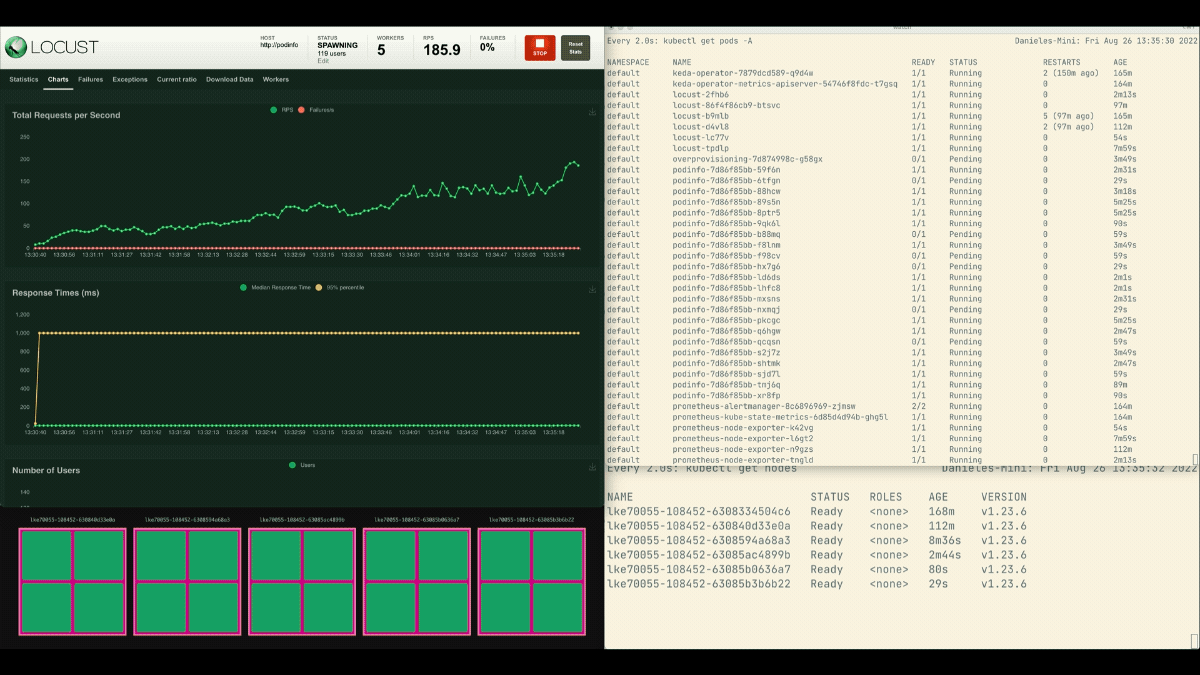
이번에는 백그라운드에서 새 노드가 생성되고 병합 없이 초당 요청이 증가합니다. 잘했어!
이 게시물에서 배운 내용을 요약 해 보겠습니다.
- 클러스터 자동 크기 조정기는 CPU 또는 메모리 사용량을 추적하지 않습니다. 대신 보류 중인 포드를 모니터링합니다.
- 사용 가능한 총 메모리와 CPU를 사용하여 Kubernetes 노드를 사전에 프로비저닝하는 포드를 만들 수 있습니다.
- 쿠버네티스 노드는 kubelet, 운영 체제 및 퇴거 임계값을 위한 자원을 예약했습니다. 그리고
- 당신은 결합 할 수 있습니다 Prometheus KEDA를 사용하여 PromQL 쿼리로 포드를 확장합니다.
Scaling Kubernetes 웨비나 시리즈를 팔로우하고 싶으신가요? 등록하여 시작하고 KEDA를 사용하여 쿠버네티스 클러스터를 0으로 확장하는 방법에 대해 자세히 알아보세요.




내용