

Cet article fait partie de notre série sur la mise à l'échelle de Kubernetes. Inscrivez-vous sur pour regarder en direct ou accéder à l'enregistrement, et consultez les autres articles de cette série :
- Mise à l'échelle de Kubernetes à zéro (et inversement)
- Mise à l'échelle de Kubernetes entre plusieurs régions
Lorsque votre cluster manque de ressources, le Cluster Autoscaler provisionne un nouveau nœud et l'ajoute au cluster. Si vous êtes déjà un utilisateur de Kubernetes, vous avez peut-être remarqué que la création et l'ajout d'un nœud au cluster prennent plusieurs minutes.
Pendant cette période, votre application peut facilement être submergée par les connexions car elle ne peut plus évoluer.

Comment pouvez-vous remédier à la longue période d'attente ?
Mise à l'échelle proactive, ou :
- comprendre le fonctionnement de l'autoscaler de cluster et maximiser son utilité ;
- utiliser le planificateur Kubernetes pour affecter des pods à un nœud ; et
- le provisionnement proactif des nœuds de travail pour éviter une mauvaise mise à l'échelle.
Si vous préférez lire le code de ce tutoriel, vous pouvez le trouver sur le GitHub de LearnK8s.
Fonctionnement du Cluster Autoscaler dans Kubernetes
L'Autoscaler de cluster ne tient pas compte de la disponibilité de la mémoire ou du CPU lorsqu'il déclenche l'autoscaling. Au lieu de cela, le Cluster Autoscaler réagit aux événements et vérifie s'il existe des pods non planifiables. Un pod n'est pas planifiable lorsque le planificateur ne trouve pas de nœud pouvant l'accueillir.
Testons cela en créant un cluster.
bash
$ linode-cli lke cluster-create \
--label learnk8s \
--region eu-west \
--k8s_version 1.23 \
--node_pools.count 1 \
--node_pools.type g6-standard-2 \
--node_pools.autoscaler.enabled enabled \
--node_pools.autoscaler.max 10 \
--node_pools.autoscaler.min 1 \
$ linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfigVous devez prêter attention aux détails suivants :
- chaque nœud a 4GB de mémoire et 2 vCPU (i.e. `g6-standard-2`) ;
- il n'y a qu'un seul nœud dans la grappe ; et
- le cluster autoscaler est configuré pour passer de 1 à 10 nœuds.
Vous pouvez vérifier que l'installation est réussie avec :
bash
$ kubectl get pods -A --kubeconfig=kubeconfigL'exportation du fichier kubeconfig avec une variable d'environnement est généralement plus pratique.
Vous pouvez le faire avec :
bash
$ export KUBECONFIG=${PWD}/kubeconfig
$ kubectl get podsExcellent !
Déploiement d'une application
Déployons une application qui nécessite 1 Go de mémoire et 250 m* de CPU.Note: m = thousandth of a core, so 250m = 25% of the CPU
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
replicas: 1
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
spec:
containers:
- name: podinfo
image: stefanprodan/podinfo
ports:
- containerPort: 9898
resources:
requests:
memory: 1G
cpu: 250mVous pouvez soumettre la ressource au cluster avec :
bash
$ kubectl apply -f podinfo.yamlDès que vous faites cela, vous pouvez remarquer quelques choses. Tout d'abord, trois pods sont presque immédiatement en cours d'exécution, et un est en attente.

Et puis :
- après quelques minutes, l'autoscaler crée un nœud supplémentaire ; et
- le quatrième pod est déployé dans le nouveau nœud.

Pourquoi le quatrième pod n'est-il pas déployé dans le premier nœud ? Creusons dans les ressources allouables.
Ressources allouables dans les nœuds de Kubernetes
Les pods déployés dans votre cluster Kubernetes consomment des ressources de mémoire, de CPU et de stockage.
Cependant, sur un même nœud, le système d'exploitation et le kubelet ont besoin de mémoire et de CPU.
Dans un nœud de travail Kubernetes, la mémoire et le processeur sont divisés en deux parties :
- Ressources nécessaires à l'exécution du système d'exploitation et des démons du système tels que SSH, systemd, etc.
- Ressources nécessaires à l'exécution des agents Kubernetes, telles que le Kubelet, le runtime de conteneurs, le détecteur de problèmes de nœuds, etc.
- Ressources disponibles pour les pods.
- Ressources réservées pour le seuil d'éviction.
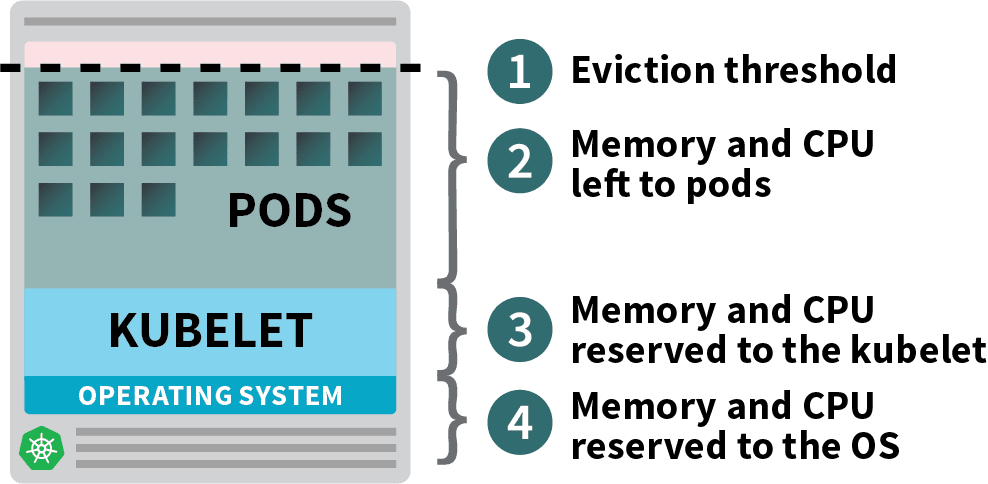
Si votre cluster exécute un DaemonSet tel que kube-proxy, vous devez réduire davantage la mémoire et le CPU disponibles.
Réduisons donc les exigences pour nous assurer que tous les pods peuvent tenir sur un seul nœud :
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
replicas: 4
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
spec:
containers:
- name: podinfo
image: stefanprodan/podinfo
ports:
- containerPort: 9898
resources:
requests:
memory: 0.8G # <- lower memory
cpu: 200m # <- lower CPUVous pouvez modifier le déploiement avec :
bash
$ kubectl apply -f podinfo.yamlChoisir la bonne quantité de CPU et de mémoire pour optimiser vos instances peut s'avérer délicat. La calculatrice de l'outil Learnk8s pourrait vous aider à le faire plus rapidement.
Vous avez résolu un problème, mais qu'en est-il du temps nécessaire à la création d'un nouveau nœud ?
Tôt ou tard, vous aurez plus de quatre répliques. Devez-vous vraiment attendre quelques minutes avant que les nouveaux pods soient créés ?
La réponse courte est oui.
Linode doit créer une machine virtuelle à partir de zéro, la provisionner et la connecter au cluster. Ce processus peut facilement prendre plus de deux minutes.
Mais il y a une alternative.
Vous pourriez créer de manière proactive des nœuds déjà provisionnés lorsque vous en avez besoin.
Par exemple, vous pouvez configurer l'autoscaler pour qu'il ait toujours un nœud de rechange. Lorsque les pods sont déployés sur le nœud de réserve, l'autoscaler peut en créer d'autres de manière proactive. Malheureusement, l'autoscaler ne dispose pas de cette fonctionnalité intégrée, mais vous pouvez facilement la recréer.
Vous pouvez créer un pod qui a des demandes égales à la ressource du nœud :
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning
spec:
replicas: 1
selector:
matchLabels:
run: overprovisioning
template:
metadata:
labels:
run: overprovisioning
spec:
containers:
- name: pause
image: k8s.gcr.io/pause
resources:
requests:
cpu: 900m
memory: 3.8GVous pouvez soumettre la ressource au cluster avec :
bash
kubectl apply -f placeholder.yamlCette capsule ne fait absolument rien.
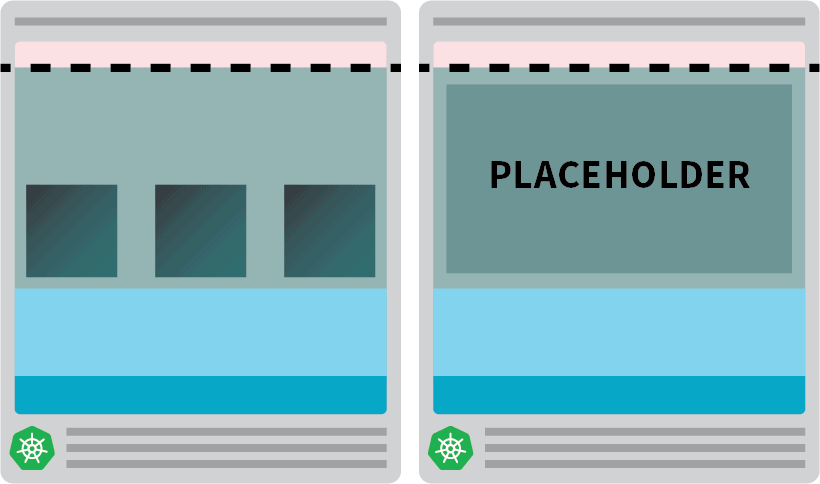
Ça permet juste de garder le nœud pleinement occupé.
L'étape suivante consiste à s'assurer que le pod de remplacement est expulsé dès qu'il y a une charge de travail qui nécessite une mise à l'échelle.
Pour cela, vous pouvez utiliser une classe prioritaire.
yaml
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: overprovisioning
value: -1
globalDefault: false
description: "Priority class used by overprovisioning."
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning
spec:
replicas: 1
selector:
matchLabels:
run: overprovisioning
template:
metadata:
labels:
run: overprovisioning
spec:
priorityClassName: overprovisioning # <--
containers:
- name: pause
image: k8s.gcr.io/pause
resources:
requests:
cpu: 900m
memory: 3.8GEt le resoumettre au cluster avec :
bash
kubectl apply -f placeholder.yamlLa configuration est maintenant terminée.
Vous devrez peut-être attendre un peu que l'autoscaler crée le nœud, mais à ce stade, vous devriez avoir deux nœuds :
- Un nœud avec quatre pods.
- Un autre avec un pod de remplacement.
Que se passe-t-il lorsque vous faites passer le déploiement à 5 répliques ? Devrez-vous attendre que l'autoscaler crée un nouveau nœud ?
Testons avec :
bash
kubectl scale deployment/podinfo --replicas=5Vous devriez observer :
- La cinquième nacelle est créée immédiatement et se trouve en état de fonctionnement en moins de 10 secondes.
- Le pod de remplacement a été expulsé pour faire de la place pour le pod.

Et puis :
- Le cluster autoscaler a remarqué le pod en attente et a provisionné un nouveau nœud.
- Le pod placeholder est déployé dans le nœud nouvellement créé.
Pourquoi créer proactivement un seul nœud alors que vous pourriez en avoir plusieurs ?
Vous pouvez faire évoluer le pod placeholder vers plusieurs répliques. Chaque réplique préprovisionnera un nœud Kubernetes prêt à accepter des charges de travail standard. Cependant, ces nœuds sont toujours comptabilisés dans votre facture de cloud computing, mais restent inactifs et ne font rien. Vous devez donc être prudent et ne pas en créer un trop grand nombre.
Combinaison de l'Autoscaler de cluster avec l'Autoscaler de pods horizontaux
Pour comprendre l'implication de cette technique, combinons le cluster autoscaler avec le Horizontal Pod Autoscaler (HPA). Le HPA est conçu pour augmenter le nombre de répliques dans vos déploiements.
Lorsque votre application reçoit davantage de trafic, vous pouvez demander à l'autoscaler d'ajuster le nombre de répliques pour traiter davantage de demandes.
Lorsque les pods épuisent toutes les ressources disponibles, l'autoscaler du cluster déclenche la création d'un nouveau nœud afin que le HPA puisse continuer à créer davantage de répliques.
Testons cela en créant un nouveau cluster :
bash
$ linode-cli lke cluster-create \
--label learnk8s-hpa \
--region eu-west \
--k8s_version 1.23 \
--node_pools.count 1 \
--node_pools.type g6-standard-2 \
--node_pools.autoscaler.enabled enabled \
--node_pools.autoscaler.max 10 \
--node_pools.autoscaler.min 3 \
$ linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfig-hpaVous pouvez vérifier que l'installation est réussie avec :
bash
$ kubectl get pods -A --kubeconfig=kubeconfig-hpaL'exportation du fichier kubeconfig avec une variable d'environnement est plus pratique.
Vous pouvez le faire avec :
bash
$ export KUBECONFIG=${PWD}/kubeconfig-hpa
$ kubectl get podsExcellent !
Utilisons Helm pour installer Prometheus et extraire les métriques des déploiements.
Vous pouvez trouver les instructions d'installation de Helm sur leur site officiel.
bash
$ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
$ helm install prometheus prometheus-community/prometheusKubernetes offre au HPA un contrôleur permettant d'augmenter et de diminuer les répliques de manière dynamique.
Malheureusement, l'APH présente quelques inconvénients :
- Il ne fonctionne pas tout de suite. Vous devez installer un serveur de métriques pour agréger et exposer les métriques.
- Vous ne pouvez pas utiliser les requêtes PromQL dès le départ.
Heureusement, vous pouvez utiliser KEDA, qui étend le contrôleur HPA avec quelques fonctionnalités supplémentaires (y compris la lecture des métriques à partir de Prometheus).
KEDA est un autoscaler composé de trois éléments :
- Un détartreur
- Un adaptateur de métrique
- Un contrôleur
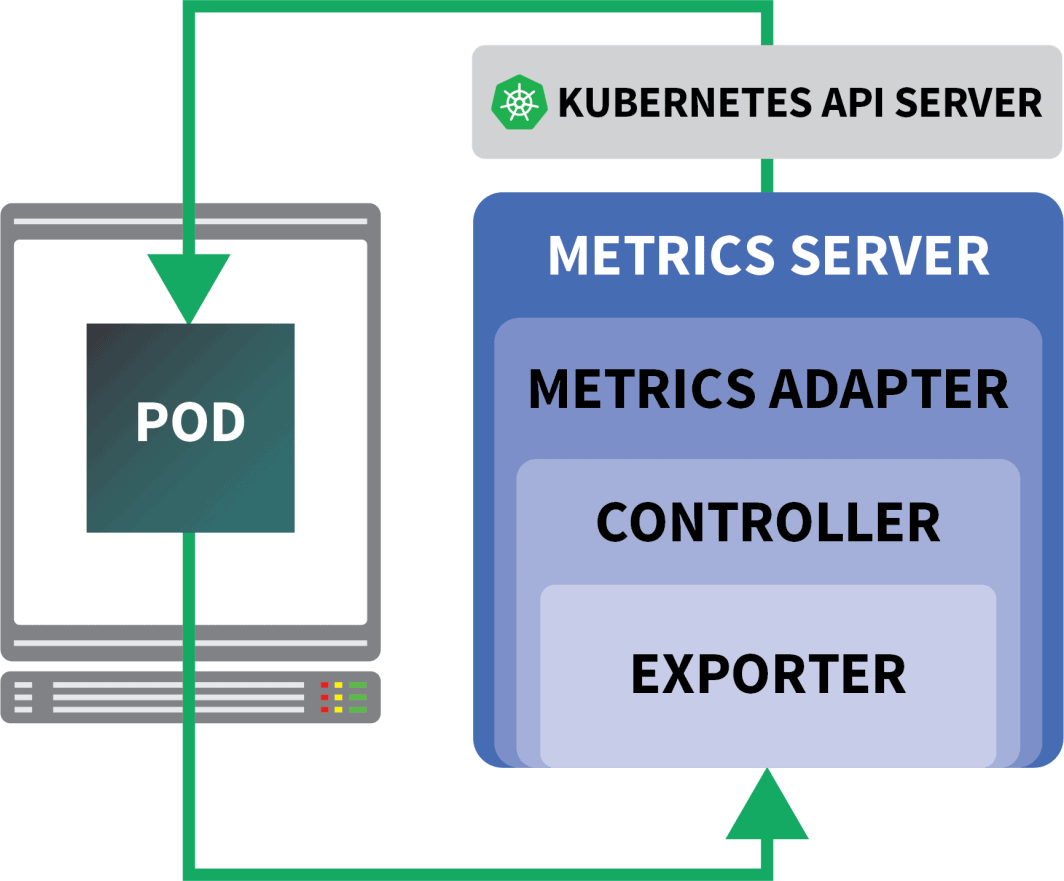
Vous pouvez installer KEDA avec Helm :
bash
$ helm repo add kedacore https://kedacore.github.io/charts
$ helm install keda kedacore/kedaMaintenant que Prometheus et KEDA sont installés, créons un déploiement.
Pour cette expérience, vous utiliserez une application conçue pour gérer un nombre fixe de demandes par seconde.
Chaque pod peut traiter au maximum dix demandes par seconde. Si le pod reçoit la 11e demande, il la laissera en attente et la traitera plus tard.
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
replicas: 4
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
annotations:
prometheus.io/scrape: "true"
spec:
containers:
- name: podinfo
image: learnk8s/rate-limiter:1.0.0
imagePullPolicy: Always
args: ["/app/index.js", "10"]
ports:
- containerPort: 8080
resources:
requests:
memory: 0.9G
---
apiVersion: v1
kind: Service
metadata:
name: podinfo
spec:
ports:
- port: 80
targetPort: 8080
selector:
app: podinfoVous pouvez soumettre la ressource au cluster avec :
bash
$ kubectl apply -f rate-limiter.yamlPour générer du trafic, vous utiliserez Locust.
La définition YAML suivante crée un cluster de test de charge distribué :
yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: locust-script
data:
locustfile.py: |-
from locust import HttpUser, task, between
class QuickstartUser(HttpUser):
@task
def hello_world(self):
self.client.get("/", headers={"Host": "example.com"})
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: locust
spec:
selector:
matchLabels:
app: locust-primary
template:
metadata:
labels:
app: locust-primary
spec:
containers:
- name: locust
image: locustio/locust
args: ["--master"]
ports:
- containerPort: 5557
name: comm
- containerPort: 5558
name: comm-plus-1
- containerPort: 8089
name: web-ui
volumeMounts:
- mountPath: /home/locust
name: locust-script
volumes:
- name: locust-script
configMap:
name: locust-script
---
apiVersion: v1
kind: Service
metadata:
name: locust
spec:
ports:
- port: 5557
name: communication
- port: 5558
name: communication-plus-1
- port: 80
targetPort: 8089
name: web-ui
selector:
app: locust-primary
type: LoadBalancer
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: locust
spec:
selector:
matchLabels:
app: locust-worker
template:
metadata:
labels:
app: locust-worker
spec:
containers:
- name: locust
image: locustio/locust
args: ["--worker", "--master-host=locust"]
volumeMounts:
- mountPath: /home/locust
name: locust-script
volumes:
- name: locust-script
configMap:
name: locust-scriptVous pouvez le soumettre au cluster avec :
bash
$ kubectl locust.yamlLocust lit ce qui suit locustfile.pyqui est stocké dans une ConfigMap :
py
from locust import HttpUser, task, between
class QuickstartUser(HttpUser):
@task
def hello_world(self):
self.client.get("/")Le fichier ne fait rien de spécial, si ce n'est d'effectuer une requête vers une URL. Pour vous connecter au tableau de bord de Locust, vous avez besoin de l'adresse IP de son équilibreur de charge.
Vous pouvez le récupérer avec la commande suivante :
bash
$ kubectl get service locust -o jsonpath='{.status.loadBalancer.ingress[0].ip}'Ouvrez votre navigateur et entrez cette adresse IP.
Excellent !
Il manque une pièce : l'Autoscaler horizontal du pod.
L'autoscaler KEDA enveloppe l'Autoscaler horizontal avec un objet spécifique appelé ScaledObject.
yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: podinfo
spec:
scaleTargetRef:
kind: Deployment
name: podinfo
minReplicaCount: 1
maxReplicaCount: 30
cooldownPeriod: 30
pollingInterval: 1
triggers:
- type: prometheus
metadata:
serverAddress: http://prometheus-server
metricName: connections_active_keda
query: |
sum(increase(http_requests_total{app="podinfo"}[60s]))
threshold: "480" # 8rps * 60sKEDA établit un pont entre les métriques collectées par Prometheus et les transmet à Kubernetes.
Enfin, il crée un pod autoscaler horizontal (HPA) avec ces paramètres.
Vous pouvez inspecter manuellement le HPA avec :
bash
$ kubectl get hpa
$ kubectl describe hpa keda-hpa-podinfoVous pouvez soumettre l'objet avec :
bash
$ kubectl apply -f scaled-object.yamlIl est temps de tester si la mise à l'échelle fonctionne.
Dans le tableau de bord de Locust, lancez une expérience avec les paramètres suivants :
- Nombre d'utilisateurs :
300 - Taux de reproduction :
0.4 - Hôte :
http://podinfo
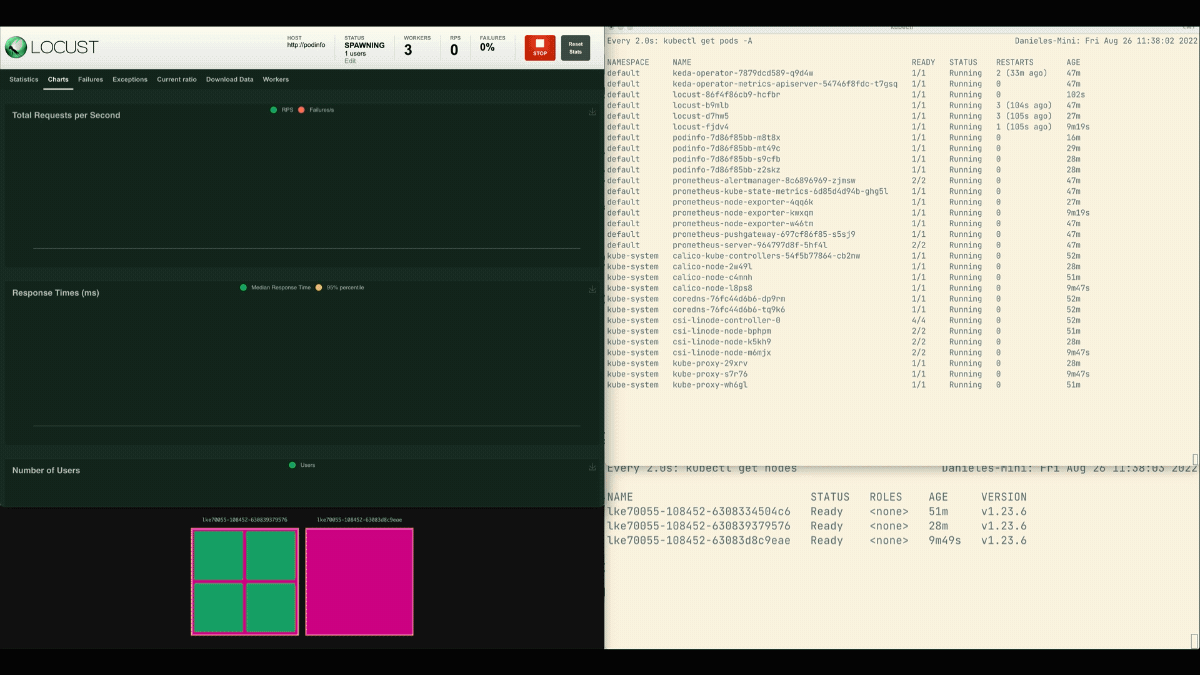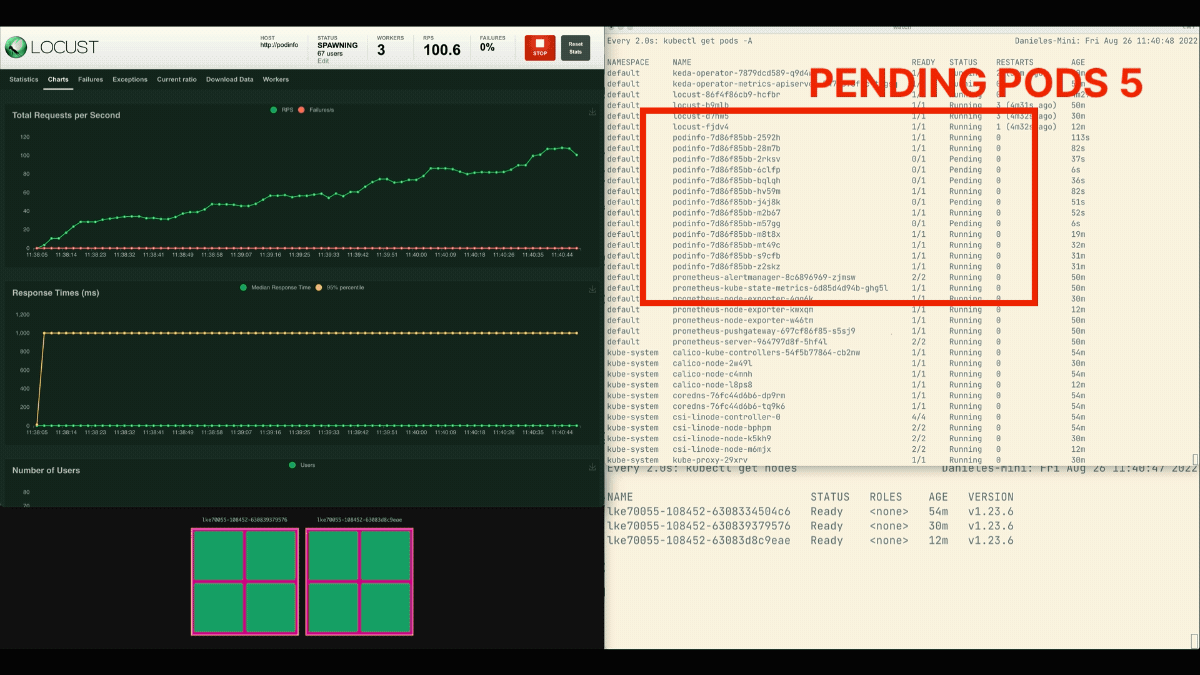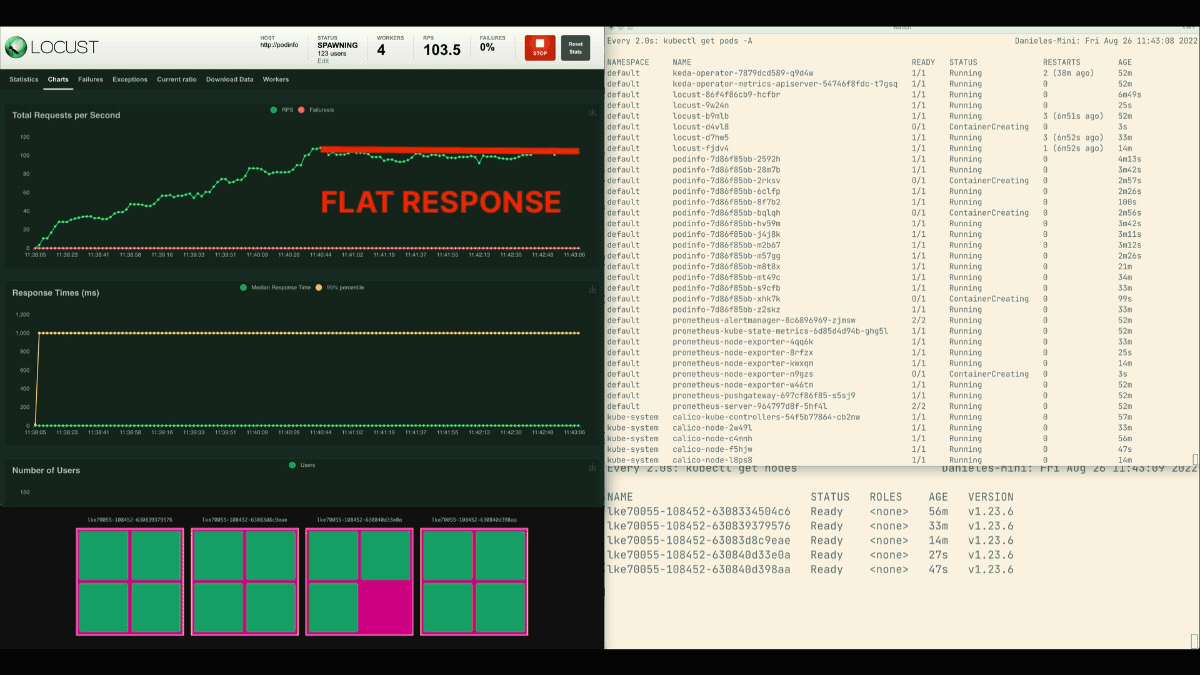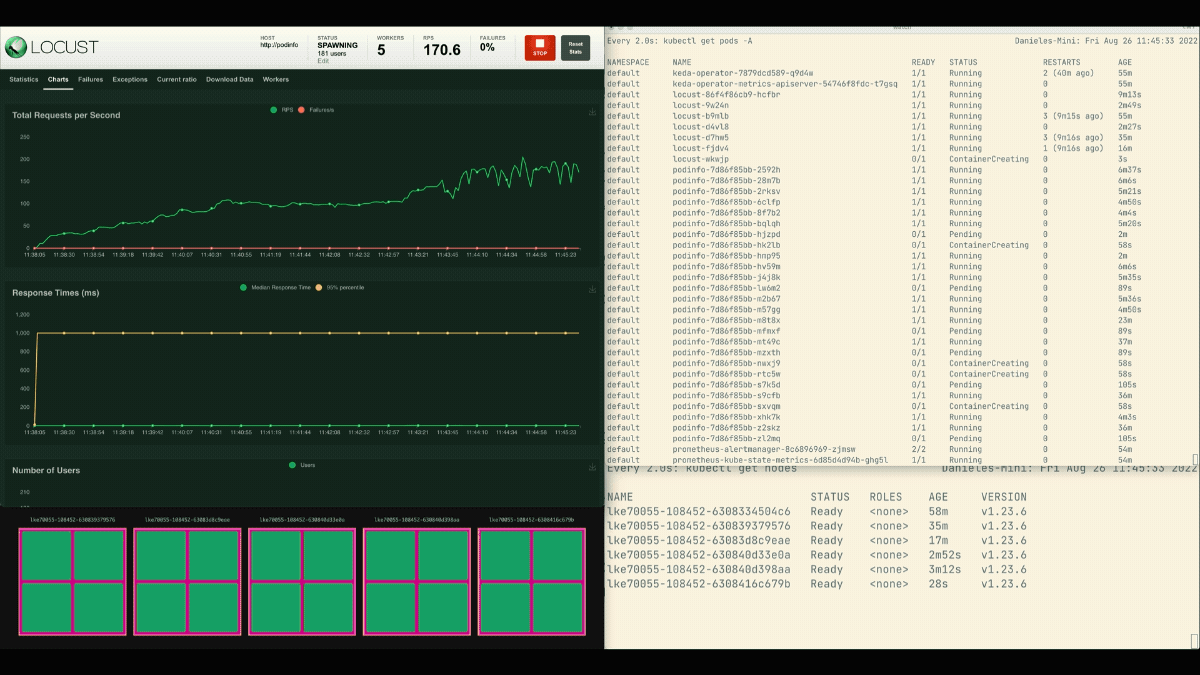
Le nombre de répliques augmente !
Excellent ! Mais avez-vous remarqué ?
Lorsque le déploiement passe à 8 pods, il faut attendre quelques minutes avant que d'autres pods soient créés sur le nouveau nœud.
Pendant cette période, les demandes par seconde stagnent car les huit répliques actuelles ne peuvent traiter que dix demandes chacune.
Réduisons l'échelle et répétons l'expérience :
bash
kubectl scale deployment/podinfo --replicas=4 # or wait for the autoscaler to remove podsCette fois, nous allons surprovisionner le nœud avec le pod de remplacement :
yaml
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: overprovisioning
value: -1
globalDefault: false
description: "Priority class used by overprovisioning."
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning
spec:
replicas: 1
selector:
matchLabels:
run: overprovisioning
template:
metadata:
labels:
run: overprovisioning
spec:
priorityClassName: overprovisioning
containers:
- name: pause
image: k8s.gcr.io/pause
resources:
requests:
cpu: 900m
memory: 3.9GVous pouvez le soumettre au cluster avec :
bash
kubectl apply -f placeholder.yamlOuvrez le tableau de bord de Locust et répétez l'expérience avec les paramètres suivants :
- Nombre d'utilisateurs :
300 - Taux de reproduction :
0.4 - Hôte :
http://podinfo
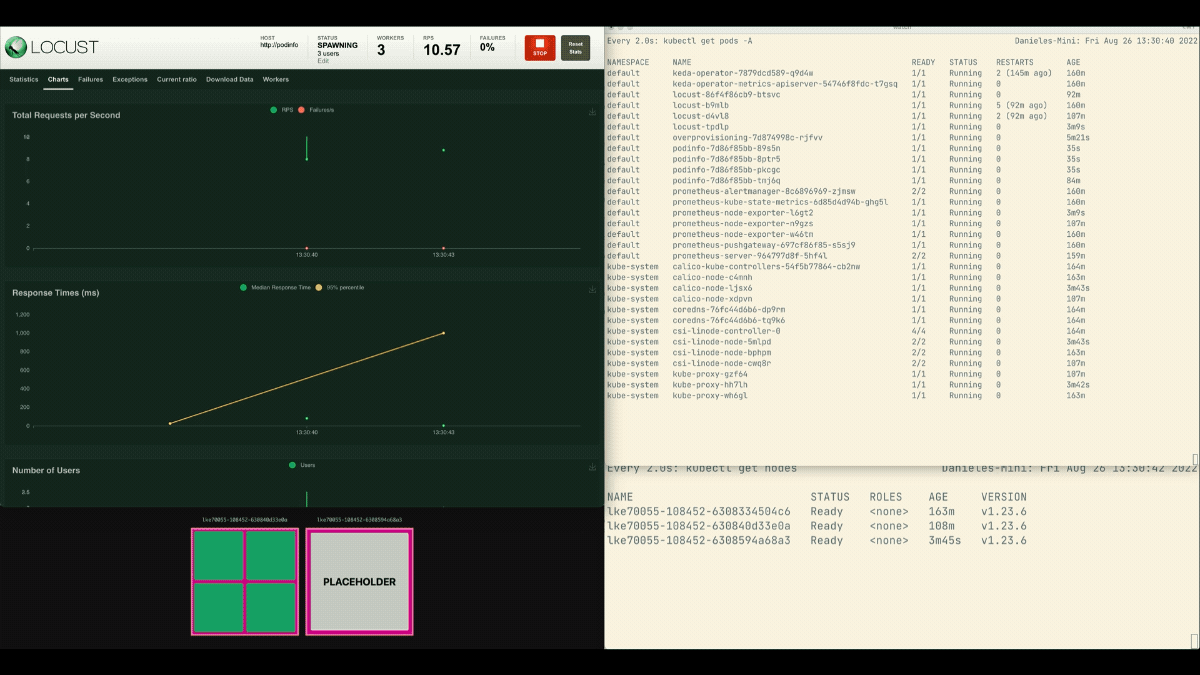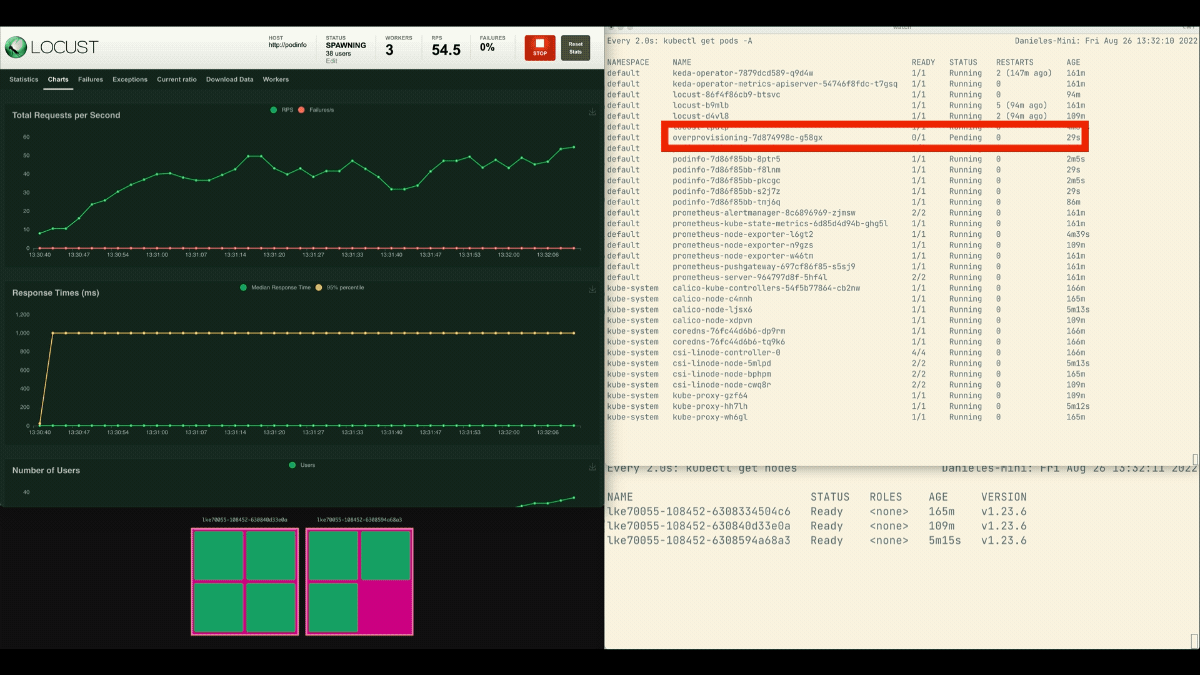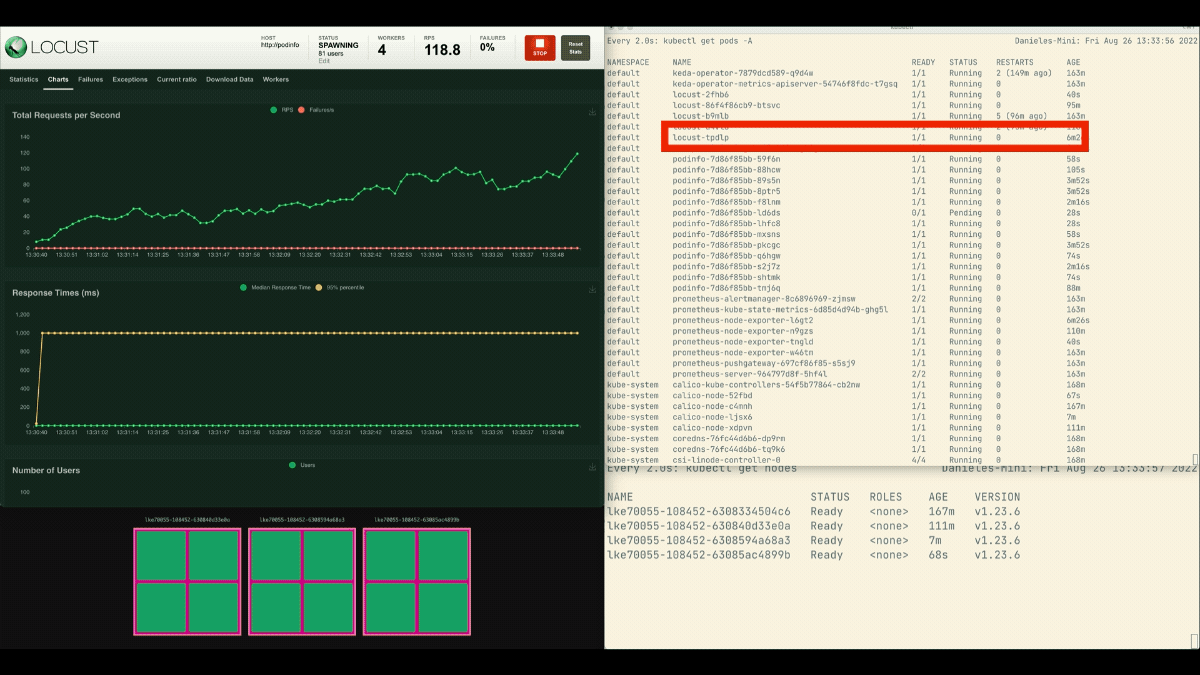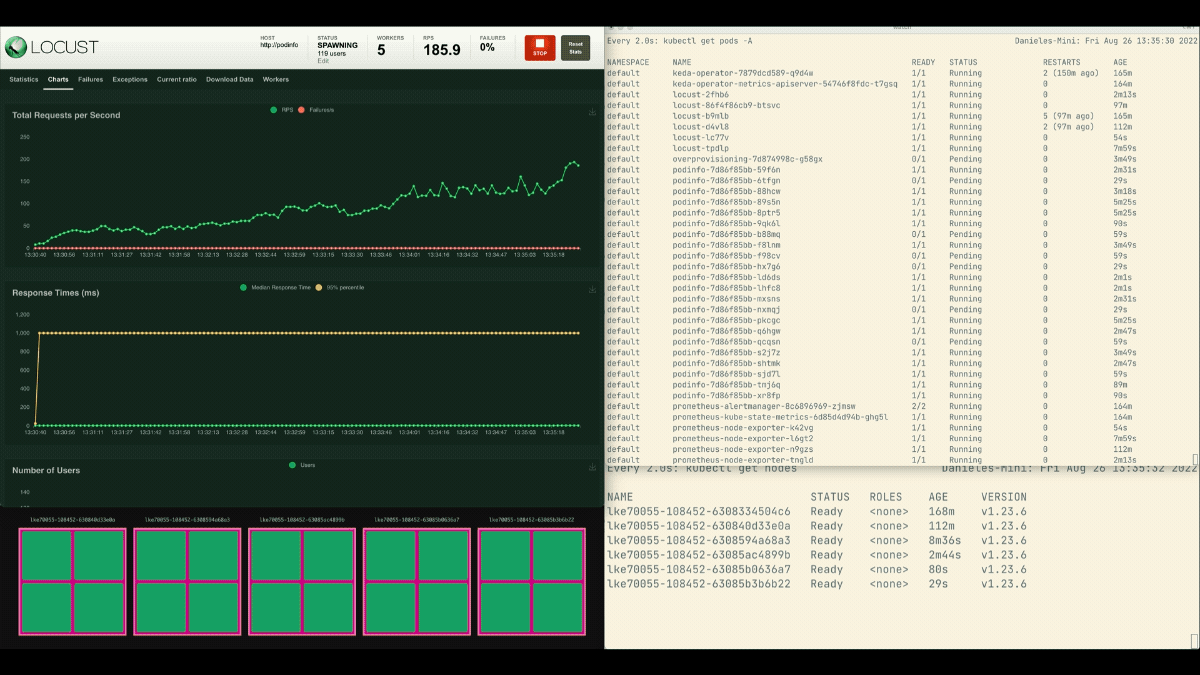
Cette fois, de nouveaux nœuds sont créés en arrière-plan et les demandes par seconde augmentent sans stagner. Excellent travail !
Récapitulons ce que vous avez appris dans ce post :
- le cluster autoscaler ne suit pas la consommation de CPU ou de mémoire. Il surveille plutôt les pods en attente ;
- vous pouvez créer un pod qui utilise la totalité de la mémoire et du CPU disponibles pour provisionner un nœud Kubernetes de manière proactive ;
- Les nœuds Kubernetes disposent de ressources réservées pour les kubelets, le système d'exploitation et le seuil d'éviction ; et
- vous pouvez combiner Prometheus avec KEDA pour faire évoluer votre pod avec une requête PromQL.
Vous souhaitez suivre notre série de webinaires sur la mise à l'échelle de Kubernetes ? Inscrivez-vous pour commencer et découvrez comment utiliser KEDA pour mettre à l'échelle les clusters Kubernetes.




Commentaires