

Cet article fait partie de notre série sur la mise à l'échelle de Kubernetes. Inscrivez-vous sur pour regarder en direct ou accéder à l'enregistrement, et consultez les autres articles de cette série :
- Mise à l'échelle proactive pour les clusters Kubernetes
- Mise à l'échelle de Kubernetes entre plusieurs régions
Réduire les coûts d'infrastructure se résume à éteindre les ressources lorsqu'elles ne sont pas utilisées. Cependant, le défi consiste à trouver comment activer automatiquement ces ressources lorsque cela est nécessaire. Passons en revue les étapes nécessaires au déploiement d'un cluster Kubernetes à l'aide de Linode Kubernetes Engine (LKE) et utilisons le Kubernetes Events-Driven Autoscaler (KEDA) pour passer à zéro et inversement.
Pourquoi passer à l'échelle zéro
Imaginons que vous exécutiez une application raisonnablement gourmande en ressources sur Kubernetes et que vous n'en ayez besoin que pendant les heures de travail.
Vous pourriez vouloir le désactiver lorsque les gens quittent le bureau et le réactiver lorsqu'ils commencent la journée.
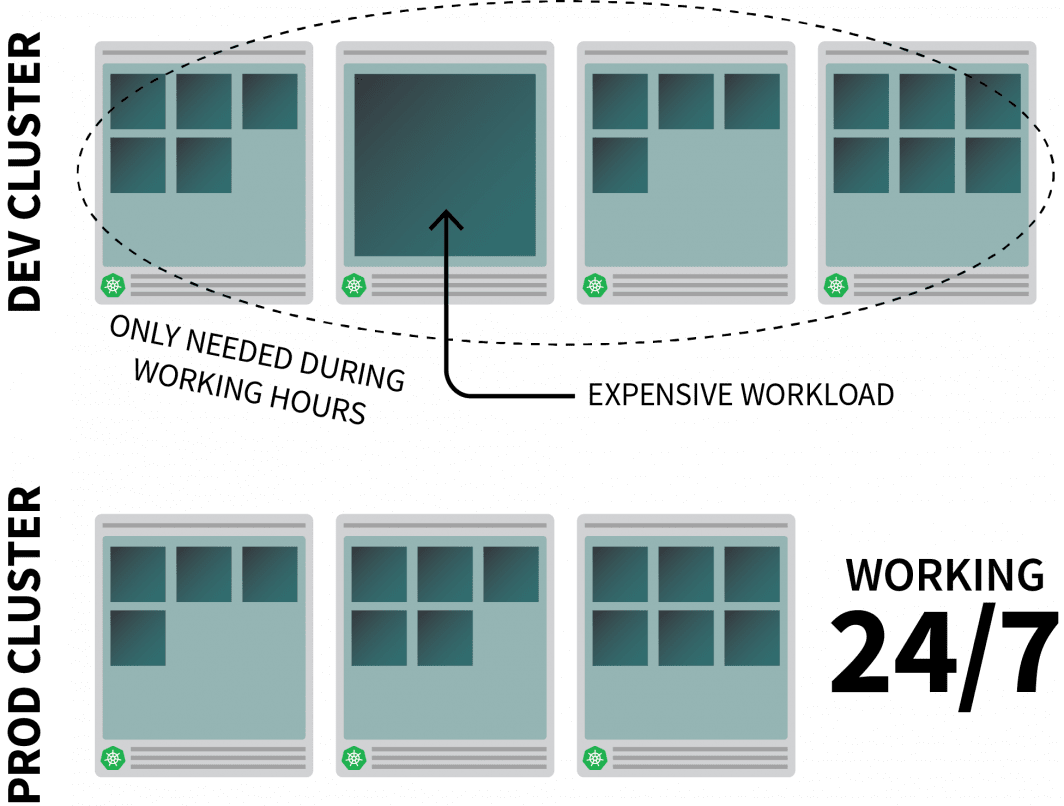
Bien que vous puissiez utiliser un CronJob pour augmenter et diminuer l'instance, cette solution est un pis-aller qui ne peut être exécuté que selon un calendrier prédéfini.
Que se passe-t-il pendant le week-end ? Et qu'en est-il des jours fériés ? Ou lorsque l'équipe est en congé maladie ?
Au lieu de générer une liste de règles toujours plus longue, vous pouvez faire évoluer vos charges de travail en fonction du trafic. Lorsque le trafic augmente, vous pouvez faire évoluer les répliques. S'il n'y a pas de trafic, vous pouvez désactiver l'application. Si l'application est désactivée et qu'il y a une nouvelle demande entrante, Kubernetes lancera au moins une réplique unique pour gérer le trafic.

Ensuite, parlons de comment faire :
- intercepter tout le trafic vers vos applications ;
- surveiller le trafic ; et
- configurer l'autoscaler pour ajuster le nombre de répliques ou désactiver les apps.
Si vous préférez lire le code de ce tutoriel, vous pouvez le faire sur le GitHub de LearnK8s.
Création d'un cluster
Commençons par créer un cluster Kubernetes.
Les commandes suivantes peuvent être utilisées pour créer le cluster et enregistrer le fichier kubeconfig.
bash
$ linode-cli lke cluster-create \
--label cluster-manager \
--region eu-west \
--k8s_version 1.23
$ linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfigVous pouvez vérifier que l'installation est réussie avec :
bash
$ kubectl get pods -A --kubeconfig=kubeconfigL'exportation du fichier kubeconfig avec une variable d'environnement est généralement plus pratique.
Vous pouvez le faire avec :
bash
$ export KUBECONFIG=${PWD}/kubeconfig
$ kubectl get podsMaintenant, déployons une application.
Déployer une application
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
spec:
containers:
- name: podinfo
image: stefanprodan/podinfo
ports:
- containerPort: 9898
---
apiVersion: v1
kind: Service
metadata:
name: podinfo
spec:
ports:
- port: 80
targetPort: 9898
selector:
app: podinfoVous pouvez soumettre le fichier YAML avec :
terminal|command=1|title=bash
$ kubectl apply -f 1-deployment.yamlEt vous pouvez visiter l'application avec :
Ouvrez votre navigateur à localhost:8080.
bash
$ kubectl port-forward svc/podinfo 8080:80À ce stade, vous devriez voir l'application.
Ensuite, nous allons installer KEDA - l'autoscaler.
KEDA - l'Autoscaler piloté par les événements de Kubernetes
Kubernetes propose l'Horizontal Pod Autoscaler (HPA ) comme contrôleur pour augmenter et diminuer les répliques de manière dynamique.
Malheureusement, l'APH présente quelques inconvénients :
- Il ne fonctionne pas directement - vous devez installer un serveur de métriques pour agréger et exposer les métriques.
- Il ne passe pas à zéro réplique.
- Il met à l'échelle les répliques en fonction des métriques et n'intercepte pas le trafic HTTP.
Heureusement, vous n'êtes pas obligé d'utiliser l'autoscaler officiel, mais vous pouvez utiliser KEDA à la place.
KEDA est un autoscaler composé de trois éléments :
- Un détartreur
- Un adaptateur de métrique
- Un contrôleur
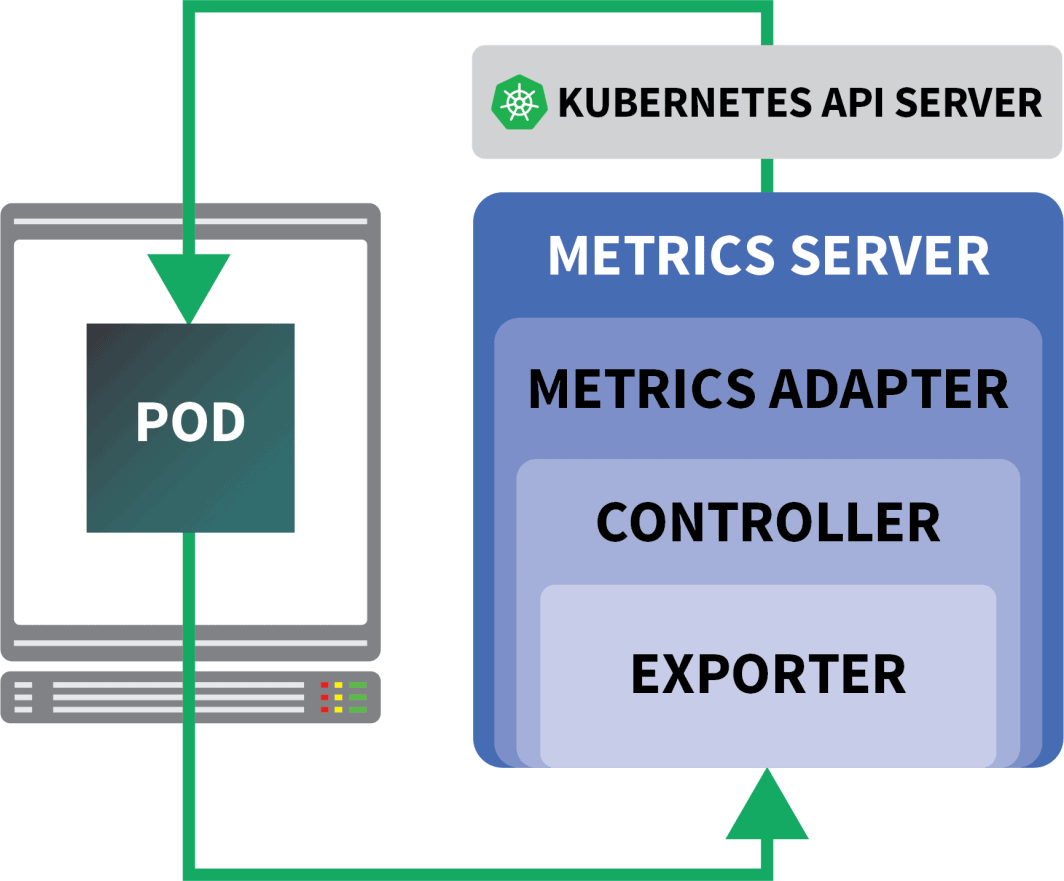
Les scalers sont comme des adaptateurs qui peuvent collecter des mesures à partir de bases de données, de courtiers en messages, de systèmes de télémétrie, etc.
Par exemple, le HTTP Scaler est un adaptateur qui peut intercepter et collecter le trafic HTTP.
Vous pouvez trouver un exemple de scaler utilisant RabbitMQ ici.
L'adaptateur de métriques est responsable de l'exposition des métriques collectées par les scalers dans un format que le pipeline de métriques de Kubernetes peut consommer.
Et enfin, le contrôleur colle tous les composants ensemble :
- Il collecte les mesures à l'aide de l'adaptateur et les expose à l'API des mesures.
- Il enregistre et gère les définitions de ressources personnalisées (CRD) spécifiques à la KEDA - c'est-à-dire ScaledObject, TriggerAuthentication, etc.
- Il crée et gère l'Autoscaler Horizontal Pod en votre nom.
C'est la théorie, mais voyons comment cela fonctionne en pratique.
Une façon plus rapide d'installer le contrôleur est d'utiliser Helm.
Vous pouvez trouver les instructions d'installation sur le site officiel de Helm.
bash
$ helm repo add kedacore https://kedacore.github.io/charts
$ helm install keda kedacore/kedaKEDA n'est pas livré avec un scaler HTTP par défaut, vous devrez donc l'installer séparément :
bash
$ helm install http-add-on kedacore/keda-add-ons-httpÀ ce stade, vous êtes prêt à mettre l'application à l'échelle.
Définition d'une stratégie d'autoscaling
Le module complémentaire KEDA HTTP expose un CRD où vous pouvez décrire comment votre application doit être mise à l'échelle.
Prenons un exemple :
yaml
kind: HTTPScaledObject
apiVersion: http.keda.sh/v1alpha1
metadata:
name: podinfo
spec:
host: example.com
targetPendingRequests: 100
scaleTargetRef:
deployment: podinfo
service: podinfo
port: 80
replicas:
min: 0
max: 10Ce fichier donne l'instruction aux intercepteurs de transmettre les requêtes pour exemple.com au service podinfo.
Il comprend également le nom du déploiement qui doit être mis à l'échelle - dans ce cas, podinfo.
Soumettons le YAML au cluster avec :
bash
$ kubectl apply -f scaled-object.yamlDès que vous soumettez la définition, le pod est supprimé !
Mais pourquoi ?
Après la création d'un HTTPScaledObject, KEDA met immédiatement à l'échelle le déploiement à zéro puisqu'il n'y a pas de trafic.
Vous devez envoyer des requêtes HTTP à l'application pour la mettre à l'échelle.
Testons cela en nous connectant au service et en émettant une requête.
bash
$ kubectl port-forward svc/podinfo 8080:80La commande se bloque !
C'est logique, il n'y a pas de pods pour répondre à la demande.
Mais pourquoi Kubernetes ne met-il pas le déploiement à l'échelle 1 ?
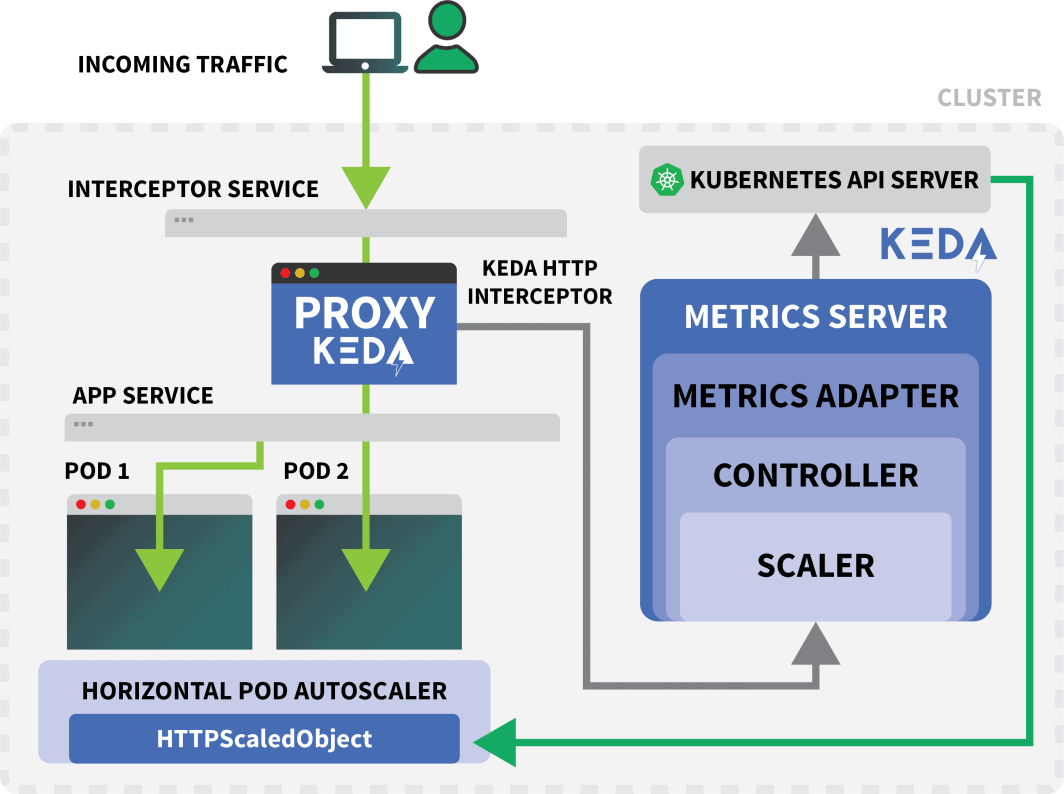
Test de l'intercepteur KEDA
Un service Kubernetes appelé keda-add-ons-http-interceptor-proxy a été créé lorsque vous avez utilisé Helm pour installer le module complémentaire.
Pour que l'autoscaling fonctionne correctement, le trafic HTTP doit d'abord passer par ce service.
Vous pouvez utiliser kubectl port-forward pour le tester :
shell
$ kubectl port-forward svc/keda-add-ons-http-interceptor-proxy 8080:8080Cette fois, vous ne pouvez pas visiter l'URL dans votre navigateur.
Un seul intercepteur HTTP KEDA peut gérer plusieurs déploiements.
Alors comment sait-il où acheminer le trafic ?
yaml
kind: HTTPScaledObject
apiVersion: http.keda.sh/v1alpha1
metadata:
name: podinfo
spec:
host: example.com
targetPendingRequests: 100
scaleTargetRef:
deployment: podinfo
service: podinfo
port: 80
replicas:
min: 0
max: 10Le HTTPScaledObject possède un champ "host" qui sert précisément à cela.
Dans cet exemple, on suppose que la demande provient de exemple.com.
Vous pouvez le faire en définissant l'en-tête Host :
bash
$ curl localhost:8080 -H 'Host: example.com'Vous recevrez une réponse, mais avec un léger retard.
Si vous inspectez les pods, vous remarquerez que le déploiement a été réduit à une seule réplique :
bash
$ kubectl get podsAlors, qu'est-ce qui vient de se passer ?
Lorsque vous acheminez du trafic vers le service de la KEDA, l'intercepteur garde la trace du nombre de demandes HTTP en attente qui n'ont pas encore reçu de réponse.
Le scaler KEDA vérifie périodiquement la taille de la file d'attente de l'intercepteur et stocke les métriques.
Le contrôleur KEDA surveille les mesures et augmente ou diminue le nombre de répliques selon les besoins. Dans ce cas, une seule demande est en attente, ce qui suffit au contrôleur KEDA pour faire passer le déploiement à une seule réplique.
Vous pouvez récupérer l'état de la file d'attente des requêtes HTTP d'un intercepteur individuel avec :
bash
$ kubectl proxy &
$ curl -L localhost:8001/api/v1/namespaces/default/services/keda-add-ons-http-interceptor-admin:9090/proxy/queue
{"example.com":0,"localhost:8080":0}En raison de cette conception, vous devez faire attention à la manière dont vous acheminez le trafic vers vos applications.
KEDA ne peut dimensionner le trafic que s'il peut être intercepté.
Si vous disposez d'un contrôleur ingress existant et que vous souhaitez l'utiliser pour transférer le trafic vers votre application, vous devrez modifier le manifeste ingress pour transférer le trafic vers le service complémentaire HTTP.
Prenons un exemple.
Combinaison de l'extension HTTP de KEDA avec Ingress
Vous pouvez installer le contrôleur nginx-ingress avec Helm :
bash
$ helm upgrade --install ingress-nginx ingress-nginx \
--repo https://kubernetes.github.io/ingress-nginx \
--namespace ingress-nginx --create-namespaceÉcrivons un manifeste d'entrée pour router le trafic vers le podinfo :
yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: podinfo
spec:
ingressClassName: nginx
rules:
- host: example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: keda-add-ons-http-interceptor-proxy # <- this
port:
number: 8080Vous pouvez récupérer l'IP de l'équilibreur de charge avec :
bash
LB_IP=$(kubectl get services -l "app.kubernetes.io/component=controller" -o jsonpath="{.items[0].status.loadBalancer.ingress
[0].ip}" -n ingress-nginx)Vous pouvez enfin faire une demande à l'application avec :
bash
curl $LB_IP -H "Host: example.com"Ça a marché !
Si vous attendez suffisamment longtemps, vous remarquerez que le déploiement finira par être réduit à zéro.
Comment cela se compare-t-il à Serverless sur Kubernetes ?
Il existe plusieurs différences significatives entre cette configuration et un framework serverless sur Kubernetes tel que OpenFaaS :
- Avec KEDA, il n'est pas nécessaire de réarchitecturer ou d'utiliser un SDK pour déployer l'application.
- Les frameworks sans serveur se chargent de l'acheminement et du traitement des demandes. Vous n'écrivez que la logique.
- Avec KEDA, les déploiements sont des conteneurs ordinaires. Avec un framework serverless, ce n'est pas toujours vrai.
Vous voulez voir cette mise à l'échelle en action ? Inscrivez-vous à notre série de webinaires sur la mise à l'échelle de Kubernetes.



Commentaires (5)
Very nice tutorial. In the case without the nginx ingress, can you explain how to access from the outside, instead of the localhost? I tried to use a NodePort service, but the port gets closed when the Interceptor is installed. The Interceptor proxy is a ClusterIP service. How can we access it from the outside? Is there any sort of kubectl port forwarding instruction?
Hi Rui! I forwarded your question to Daniele and here is his response:
It should work with NodePort, but you have to set the right header (i.e.
Host: example.com) when you make the request. There is no way for the interceptor to decide where the traffic should go without that.Muito bom o conteudo!!!
Where does NodeBalancer show up in this configuration? Does LKE take over that job?
Hi Lee – The NodeBalancer is created during the installation of the nginx-ingress controller. For a more detailed explanation of this process you can check out our guide titled Deploying NGINX Ingress on Linode Kubernetes Engine.
Once the NodeBalancer is provisioned it is controlled via LKE. We don’t recommend configuring the settings of your LKE NodeBalancers through the Cloud Manager.