

Questo post fa parte della nostra serie Scaling Kubernetes. Registratevi per assistere dal vivo o accedere alla registrazione, e date un'occhiata agli altri post di questa serie:
La riduzione dei costi dell'infrastruttura si riduce allo spegnimento delle risorse quando non vengono utilizzate. Tuttavia, la sfida consiste nel capire come attivare automaticamente queste risorse quando è necessario. Esaminiamo i passaggi necessari per implementare un cluster Kubernetes utilizzando Linode Kubernetes Engine (LKE) e utilizzare Kubernetes Events-Driven Autoscaler (KEDA) per scalare a zero e viceversa.
Perché scalare a zero
Immaginiamo di eseguire un'applicazione ad alta intensità di risorse su Kubernetes e che sia necessaria solo durante le ore di lavoro.
Si consiglia di spegnerlo quando le persone lasciano l'ufficio e di riaccenderlo quando iniziano la giornata.
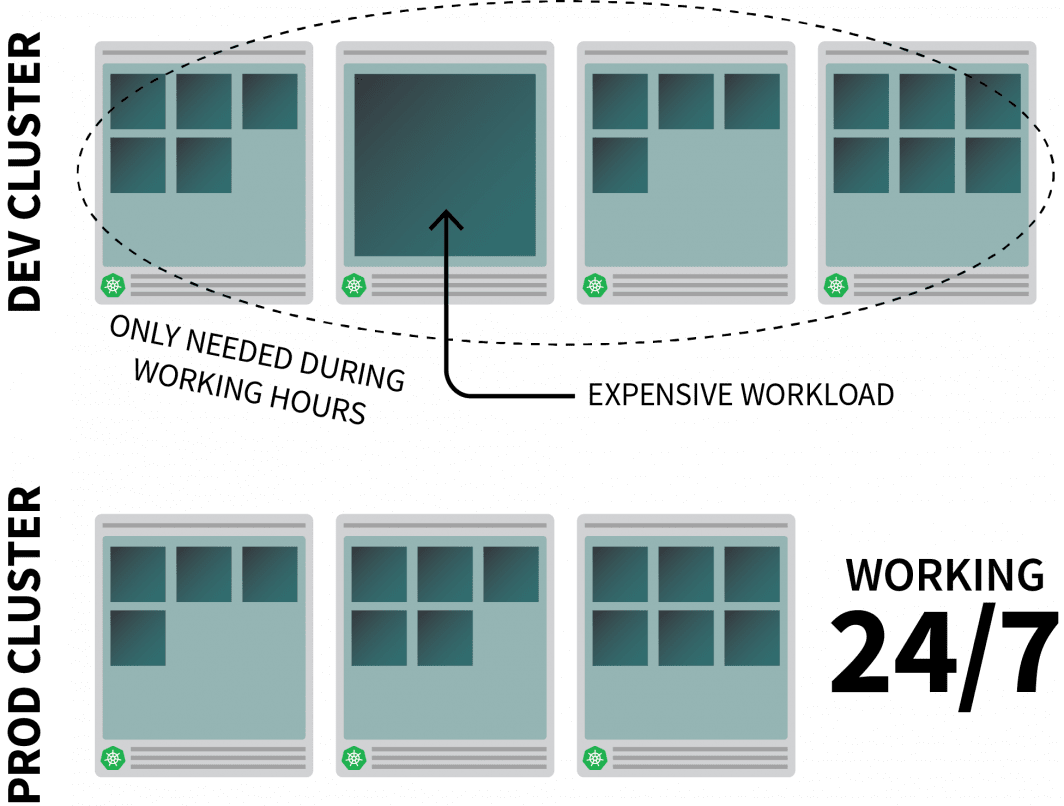
Sebbene si possa usare un CronJob per scalare l'istanza, questa soluzione è un ripiego che può essere eseguito solo in base a una pianificazione predefinita.
Cosa succede durante il fine settimana? E nei giorni festivi? O quando il team è in malattia?
Invece di generare un elenco sempre crescente di regole, è possibile scalare i carichi di lavoro in base al traffico. Quando il traffico aumenta, è possibile scalare le repliche. Se non c'è traffico, si può spegnere l'applicazione. Se l'applicazione è spenta e c'è una nuova richiesta in arrivo, Kubernetes avvierà almeno una singola replica per gestire il traffico.

Parliamo poi di come farlo:
- intercettare tutto il traffico verso le vostre applicazioni;
- monitorare il traffico; e
- impostare l'autoscaler per regolare il numero di repliche o disattivare le applicazioni.
Se preferite leggere il codice di questa esercitazione, potete farlo su GitHub di LearnK8s.
Creazione di un cluster
Iniziamo con la creazione di un cluster Kubernetes.
I seguenti comandi possono essere usati per creare il cluster e salvare il file kubeconfig.
bash
$ linode-cli lke cluster-create \
--label cluster-manager \
--region eu-west \
--k8s_version 1.23
$ linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfigÈ possibile verificare che l'installazione sia avvenuta con successo con:
bash
$ kubectl get pods -A --kubeconfig=kubeconfigL'esportazione del file kubeconfig con una variabile d'ambiente è solitamente più conveniente.
È possibile farlo con:
bash
$ export KUBECONFIG=${PWD}/kubeconfig
$ kubectl get podsOra distribuiamo un'applicazione.
Distribuzione di un'applicazione
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
spec:
containers:
- name: podinfo
image: stefanprodan/podinfo
ports:
- containerPort: 9898
---
apiVersion: v1
kind: Service
metadata:
name: podinfo
spec:
ports:
- port: 80
targetPort: 9898
selector:
app: podinfoÈ possibile inviare il file YAML con:
terminal|command=1|title=bash
$ kubectl apply -f 1-deployment.yamlE si può visitare l'app con:
Aprite il browser su localhost:8080.
bash
$ kubectl port-forward svc/podinfo 8080:80A questo punto, si dovrebbe vedere l'applicazione.
Quindi, installiamo KEDA - l'autoscaler.
KEDA - l'autoscaler Kubernetes guidato dagli eventi
Kubernetes offre l'Horizontal Pod Autoscaler (HPA) come controller per aumentare e ridurre le repliche in modo dinamico.
Purtroppo, l'HPA presenta alcuni inconvenienti:
- Non funziona in modo immediato: è necessario installare un server di metriche per aggregare ed esporre le metriche.
- Non scala a zero repliche.
- Scala le repliche in base alle metriche e non intercetta il traffico HTTP.
Fortunatamente, non è necessario utilizzare l'autoscaler ufficiale, ma è possibile utilizzare KEDA.
KEDA è un autoscaler composto da tre componenti:
- Uno scalatore
- Un adattatore di metriche
- Un controllore
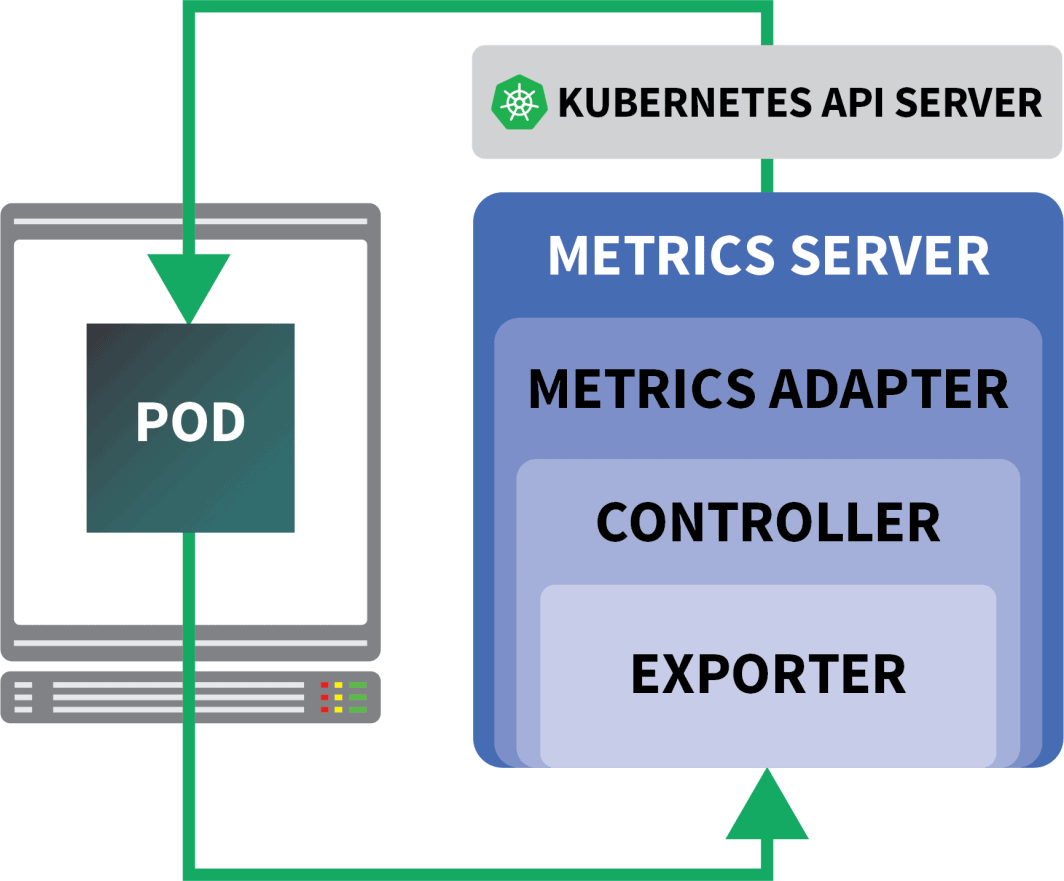
Gli scaler sono come adattatori che possono raccogliere metriche da database, message broker, sistemi di telemetria, ecc.
Ad esempio, HTTP Scaler è un adattatore in grado di intercettare e raccogliere il traffico HTTP.
Un esempio di scaler che utilizza RabbitMQ è disponibile qui.
Il Metrics Adapter è responsabile dell'esposizione delle metriche raccolte dagli scaler in un formato che la pipeline di metriche di Kubernetes può consumare.
Infine, il controllore incolla tutti i componenti tra loro:
- Raccoglie le metriche utilizzando l'adattatore e le espone all'API delle metriche.
- Registra e gestisce le Custom Resource Definitions (CRD) specifiche di KEDA, ovvero ScaledObject, TriggerAuthentication, ecc.
- Crea e gestisce l'Autoscaler Pod orizzontale per conto dell'utente.
Questa è la teoria, ma vediamo come funziona in pratica.
Un modo più rapido per installare il controller è usare Helm.
Le istruzioni per l'installazione sono disponibili sul sito ufficiale di Helm.
bash
$ helm repo add kedacore https://kedacore.github.io/charts
$ helm install keda kedacore/kedaKEDA non viene fornito con uno scaler HTTP di default, quindi è necessario installarlo separatamente:
bash
$ helm install http-add-on kedacore/keda-add-ons-httpA questo punto, siete pronti a scalare l'applicazione.
Definizione di una strategia di autoscaling
Il componente aggiuntivo KEDA HTTP espone un CRD in cui è possibile descrivere il modo in cui l'applicazione deve essere scalata.
Vediamo un esempio:
yaml
kind: HTTPScaledObject
apiVersion: http.keda.sh/v1alpha1
metadata:
name: podinfo
spec:
host: example.com
targetPendingRequests: 100
scaleTargetRef:
deployment: podinfo
service: podinfo
port: 80
replicas:
min: 0
max: 10Questo file istruisce gli intercettori a inoltrare le richieste di example.com al servizio podinfo.
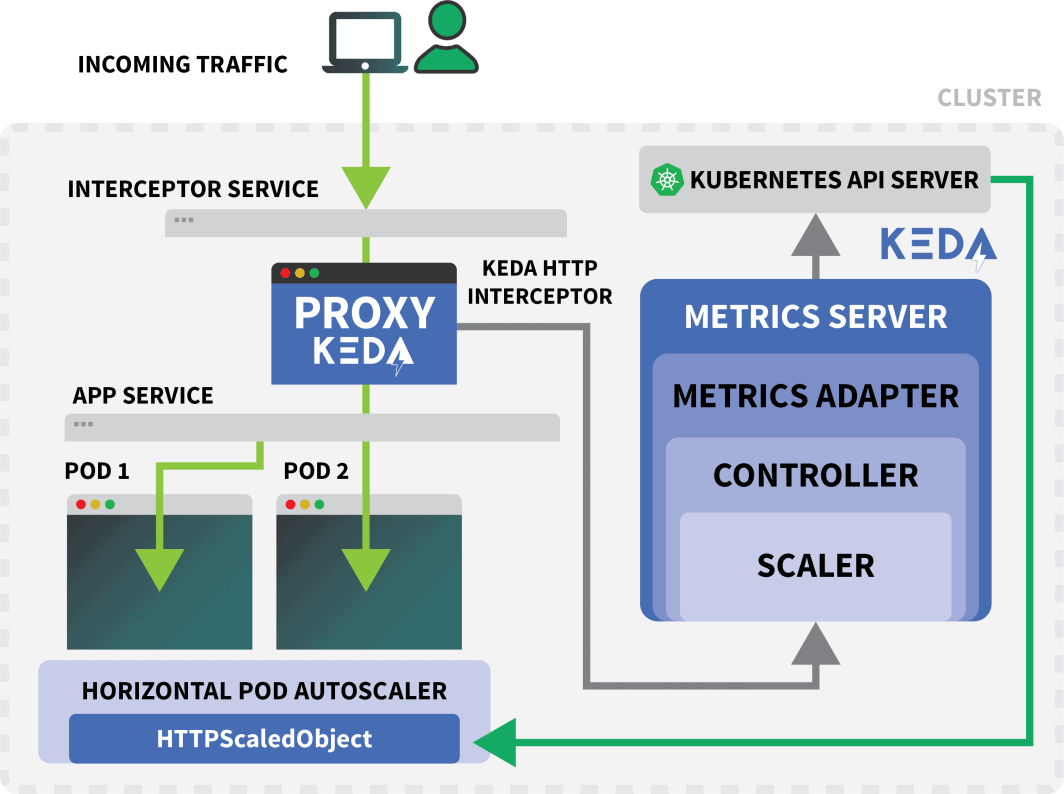
Include anche il nome del deployment che deve essere scalato, in questo caso podinfo.
Inviamo lo YAML al cluster con:
bash
$ kubectl apply -f scaled-object.yamlNon appena si invia la definizione, il pod viene cancellato!
Ma perché?
Dopo la creazione di un HTTPScaledObject, KEDA scala immediatamente la distribuzione a zero, poiché non c'è traffico.
È necessario inviare richieste HTTP all'applicazione per scalarla.
Verifichiamo questo aspetto collegandoci al servizio e inviando una richiesta.
bash
$ kubectl port-forward svc/podinfo 8080:80Il comando si blocca!
Ha senso: non ci sono pod per servire la richiesta.
Ma perché Kubernetes non scala il deployment a 1?
Test dell'intercettatore KEDA
Un servizio Kubernetes chiamato keda-add-ons-http-interceptor-proxy è stato creato quando si è usato Helm per installare il componente aggiuntivo.
Affinché l'autoscaling funzioni correttamente, il traffico HTTP deve passare prima attraverso quel servizio.
È possibile utilizzare kubectl port-forward per testarlo:
shell
$ kubectl port-forward svc/keda-add-ons-http-interceptor-proxy 8080:8080Questa volta, non è possibile visitare l'URL nel browser.
Un singolo intercettore HTTP KEDA può gestire più distribuzioni.
Come fa a sapere dove instradare il traffico?
yaml
kind: HTTPScaledObject
apiVersion: http.keda.sh/v1alpha1
metadata:
name: podinfo
spec:
host: example.com
targetPendingRequests: 100
scaleTargetRef:
deployment: podinfo
service: podinfo
port: 80
replicas:
min: 0
max: 10L'oggetto HTTPScaledObject ha un campo host che viene utilizzato proprio per questo.
In questo esempio, si finge che la richiesta provenga da example.com.
È possibile farlo impostando l'intestazione Host:
bash
$ curl localhost:8080 -H 'Host: example.com'Riceverete una risposta, anche se con un leggero ritardo.
Se si ispezionano i pod, si noterà che l'installazione è stata scalata a una singola replica:
bash
$ kubectl get podsChe cosa è successo?
Quando si instrada il traffico verso il servizio KEDA, l'intercettore tiene traccia del numero di richieste HTTP in sospeso che non hanno ancora ricevuto risposta.
Lo scaler KEDA controlla periodicamente la dimensione della coda dell'intercettore e memorizza le metriche.
Il controller KEDA monitora le metriche e aumenta o diminuisce il numero di repliche in base alle necessità. In questo caso, è in corso una singola richiesta, sufficiente al controller KEDA per scalare il deployment a una singola replica.
È possibile recuperare lo stato della coda di richieste HTTP in sospeso di un singolo intercettore con:
bash
$ kubectl proxy &
$ curl -L localhost:8001/api/v1/namespaces/default/services/keda-add-ons-http-interceptor-admin:9090/proxy/queue
{"example.com":0,"localhost:8080":0}A causa di questo design, è necessario prestare attenzione al modo in cui si instrada il traffico verso le app.
KEDA può scalare il traffico solo se può essere intercettato.
Se si dispone di un controller di ingress esistente e si desidera utilizzarlo per inoltrare il traffico alla propria applicazione, è necessario modificare il manifest di ingress per inoltrare il traffico al servizio aggiuntivo HTTP.
Vediamo un esempio.
Combinazione dell'add-on HTTP KEDA con Ingress
È possibile installare il controller nginx-ingress con Helm:
bash
$ helm upgrade --install ingress-nginx ingress-nginx \
--repo https://kubernetes.github.io/ingress-nginx \
--namespace ingress-nginx --create-namespaceScriviamo un manifest di ingress per instradare il traffico verso podinfo:
yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: podinfo
spec:
ingressClassName: nginx
rules:
- host: example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: keda-add-ons-http-interceptor-proxy # <- this
port:
number: 8080È possibile recuperare l'IP del bilanciatore di carico con:
bash
LB_IP=$(kubectl get services -l "app.kubernetes.io/component=controller" -o jsonpath="{.items[0].status.loadBalancer.ingress
[0].ip}" -n ingress-nginx)È infine possibile effettuare una richiesta all'app con:
bash
curl $LB_IP -H "Host: example.com"Ha funzionato!
Se si attende abbastanza a lungo, si noterà che il dispiegamento finirà per azzerarsi.
Come si confronta con Serverless su Kubernetes?
Ci sono diverse differenze significative tra questa configurazione e un framework serverless su Kubernetes come OpenFaaS:
- Con KEDA, non è necessario riarchitettare o utilizzare un SDK per distribuire l'applicazione.
- I framework serverless si occupano di instradare e servire le richieste. Voi scrivete solo la logica.
- Con KEDA, le distribuzioni sono normali contenitori. Con un framework serverless, questo non è sempre vero.
Volete vedere questo scaling in azione? Registratevi alla serie di webinar Scaling Kubernetes.



Commenti (5)
Very nice tutorial. In the case without the nginx ingress, can you explain how to access from the outside, instead of the localhost? I tried to use a NodePort service, but the port gets closed when the Interceptor is installed. The Interceptor proxy is a ClusterIP service. How can we access it from the outside? Is there any sort of kubectl port forwarding instruction?
Hi Rui! I forwarded your question to Daniele and here is his response:
It should work with NodePort, but you have to set the right header (i.e.
Host: example.com) when you make the request. There is no way for the interceptor to decide where the traffic should go without that.Muito bom o conteudo!!!
Where does NodeBalancer show up in this configuration? Does LKE take over that job?
Hi Lee – The NodeBalancer is created during the installation of the nginx-ingress controller. For a more detailed explanation of this process you can check out our guide titled Deploying NGINX Ingress on Linode Kubernetes Engine.
Once the NodeBalancer is provisioned it is controlled via LKE. We don’t recommend configuring the settings of your LKE NodeBalancers through the Cloud Manager.