

Questo post fa parte della nostra serie Scaling Kubernetes. Registratevi per assistere dal vivo o accedere alla registrazione, e date un'occhiata agli altri post di questa serie:
Una sfida interessante con Kubernetes è la distribuzione dei carichi di lavoro in diverse regioni. Sebbene sia tecnicamente possibile avere un cluster con diversi nodi situati in regioni diverse, questa soluzione è generalmente considerata da evitare a causa della latenza aggiuntiva.
Un'alternativa popolare è quella di distribuire un cluster per ogni regione e trovare un modo per orchestrarlo.
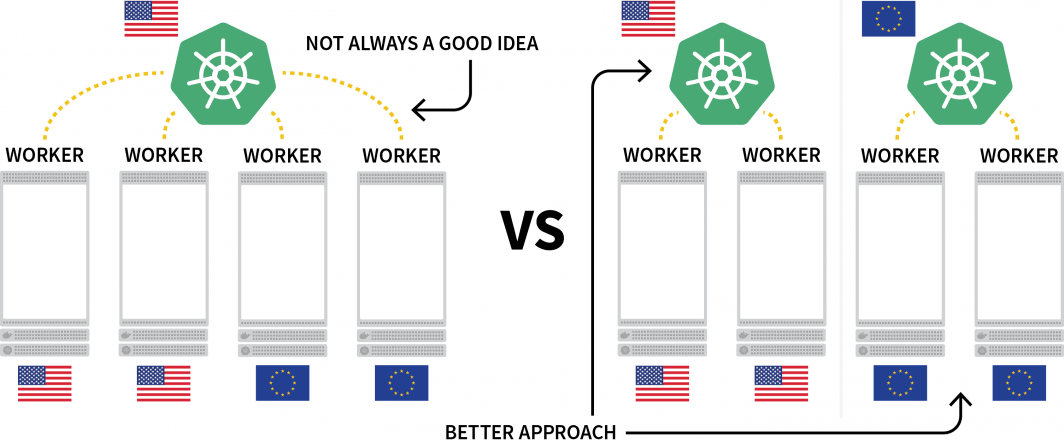
In questo post, vi sarà spiegato come:
- Creare tre cluster: uno in Nord America, uno in Europa e uno nel Sud-Est asiatico.
- Creare un quarto cluster che funga da orchestratore per gli altri.
- Impostare una singola rete tra le tre reti del cluster per una comunicazione senza interruzioni.
Questo post è stato programmato per funzionare con Terraform e richiede un'interazione minima. Il codice è disponibile su GitHub di LearnK8s.
Creazione del gestore di cluster
Iniziamo con la creazione del cluster che gestirà il resto. I seguenti comandi possono essere usati per creare il cluster e salvare il file kubeconfig.
bash
$ linode-cli lke cluster-create \
--label cluster-manager \
--region eu-west \
--k8s_version 1.23
$ linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfig-cluster-managerÈ possibile verificare che l'installazione sia avvenuta con successo con:
bash
$ kubectl get pods -A --kubeconfig=kubeconfig-cluster-managerEccellente!
Nel cluster manager si installa Karmada, un sistema di gestione che consente di eseguire le applicazioni cloud-native su più cluster Kubernetes e cloud. Karmada ha un piano di controllo installato nel cluster manager e l'agente installato in ogni altro cluster.
Il piano di controllo ha tre componenti:
- Un API Server;
- Un Controller Manager; e
- Un programmatore
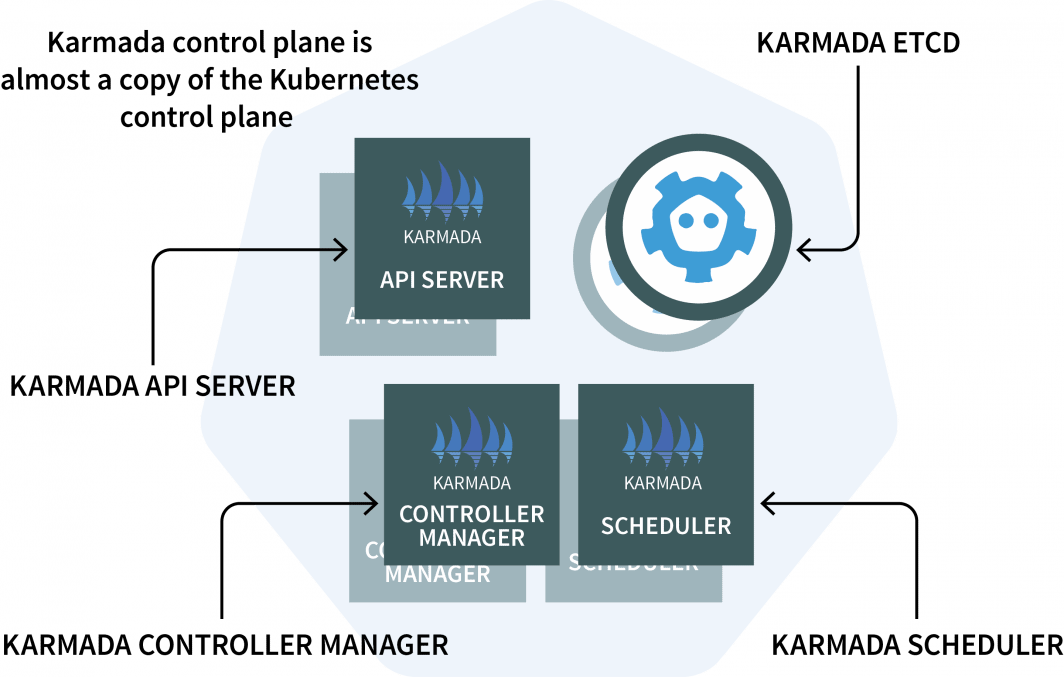
Se questi elementi vi sembrano familiari, è perché il piano di controllo di Kubernetes presenta gli stessi componenti! Karmada ha dovuto copiarli e aumentarli per poter lavorare con più cluster.
Basta con la teoria. Passiamo al codice.
Si utilizzerà Helm per installare il server Karmada. API per installare il server Karmada. Aggiungiamo il repository Helm con:
bash
$ helm repo add karmada-charts https://raw.githubusercontent.com/karmada-io/karmada/master/charts
$ helm repo list
NAME URL
karmada-charts https://raw.githubusercontent.com/karmada-io/karmada/master/chartsPoiché il server Karmada API deve essere raggiungibile da tutti gli altri cluster, si dovrà
- esporlo dal nodo; e
- assicurarsi che la connessione sia attendibile.
Quindi recuperiamo l'indirizzo IP del nodo che ospita il piano di controllo con:
bash
kubectl get nodes -o jsonpath='{.items[0].status.addresses[?(@.type==\"ExternalIP\")].address}' \
--kubeconfig=kubeconfig-cluster-managerOra è possibile installare il piano di controllo Karmada con:
bash
$ helm install karmada karmada-charts/karmada \
--kubeconfig=kubeconfig-cluster-manager \
--create-namespace --namespace karmada-system \
--version=1.2.0 \
--set apiServer.hostNetwork=false \
--set apiServer.serviceType=NodePort \
--set apiServer.nodePort=32443 \
--set certs.auto.hosts[0]="kubernetes.default.svc" \
--set certs.auto.hosts[1]="*.etcd.karmada-system.svc.cluster.local" \
--set certs.auto.hosts[2]="*.karmada-system.svc.cluster.local" \
--set certs.auto.hosts[3]="*.karmada-system.svc" \
--set certs.auto.hosts[4]="localhost" \
--set certs.auto.hosts[5]="127.0.0.1" \
--set certs.auto.hosts[6]="<insert the IP address of the node>"Una volta completata l'installazione, è possibile recuperare il kubeconfig per connettersi a Karmada API con:
bash
kubectl get secret karmada-kubeconfig \
--kubeconfig=kubeconfig-cluster-manager \
-n karmada-system \
-o jsonpath={.data.kubeconfig} | base64 -d > karmada-configMa aspettate, perché un altro file kubeconfig?
Karmada API è stato progettato per sostituire lo standard Kubernetes API ma mantiene tutte le funzionalità a cui siete abituati. In altre parole, è possibile creare distribuzioni che coprono più cluster con kubectl.
Prima di testare Karmada API e kubectl, è necessario modificare il file kubeconfig. Per impostazione predefinita, il kubeconfig generato può essere utilizzato solo dall'interno della rete del cluster.
Tuttavia, è possibile sostituire la riga seguente per farla funzionare:
yaml
apiVersion: v1
kind: Config
clusters:
- cluster:
certificate-authority-data: LS0tLS1CRUdJTi…
insecure-skip-tls-verify: false
server: https://karmada-apiserver.karmada-system.svc.cluster.local:5443 # <- this works only in the cluster
name: karmada-apiserver
# truncatedSostituirlo con l'indirizzo IP del nodo recuperato in precedenza:
yaml
apiVersion: v1
kind: Config
clusters:
- cluster:
certificate-authority-data: LS0tLS1CRUdJTi…
insecure-skip-tls-verify: false
server: https://<node's IP address>:32443 # <- this works from the public internet
name: karmada-apiserver
# truncatedOttimo, è il momento di testare Karmada.
Installazione dell'agente Karmada
Eseguire il seguente comando per recuperare tutte le distribuzioni e tutti i cluster:
bash
$ kubectl get clusters,deployments --kubeconfig=karmada-config
No resources foundNon sorprende che non ci siano né distribuzioni né cluster aggiuntivi. Aggiungiamo altri cluster e colleghiamoli al piano di controllo di Karmada.
Ripetere i seguenti comandi per tre volte:
bash
linode-cli lke cluster-create \
--label <insert-cluster-name> \
--region <insert-region> \
--k8s_version 1.23
linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfig-<insert-cluster-name>I valori devono essere i seguenti:
- Nome del cluster
eu, regioneeu-wese il file kubeconfigkubeconfig-eu - Nome del cluster
ap, regioneap-southe il file kubeconfigkubeconfig-ap - Nome del cluster
us, regioneus-weste il file kubeconfigkubeconfig-us
È possibile verificare che i cluster siano stati creati correttamente con:
bash
$ kubectl get pods -A --kubeconfig=kubeconfig-eu
$ kubectl get pods -A --kubeconfig=kubeconfig-ap
$ kubectl get pods -A --kubeconfig=kubeconfig-usOra è il momento di farli entrare nel gruppo Karmada.
Karmada utilizza un agente su ogni altro cluster per coordinare la distribuzione con il piano di controllo.
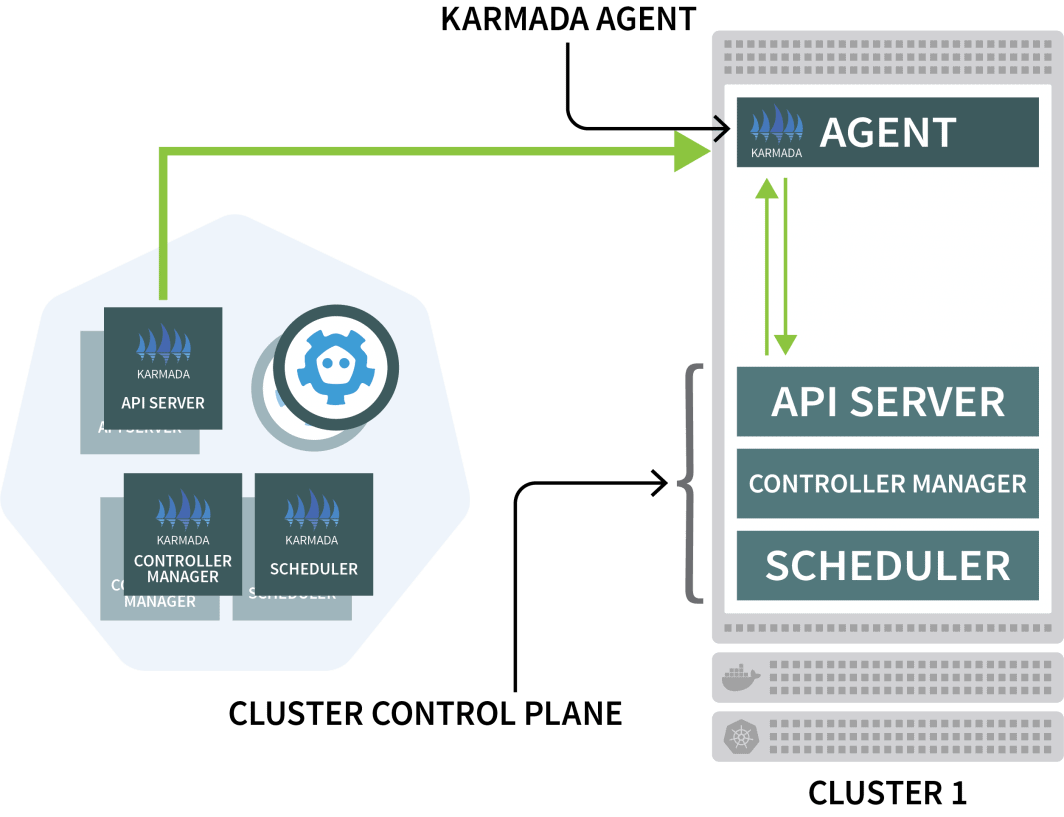
Si utilizzerà Helm per installare l'agente Karmada e collegarlo al gestore del cluster:
bash
$ helm install karmada karmada-charts/karmada \
--kubeconfig=kubeconfig-<insert-cluster-name> \
--create-namespace --namespace karmada-system \
--version=1.2.0 \
--set installMode=agent \
--set agent.clusterName=<insert-cluster-name> \
--set agent.kubeconfig.caCrt=<karmada kubeconfig certificate authority> \
--set agent.kubeconfig.crt=<karmada kubeconfig client certificate data> \
--set agent.kubeconfig.key=<karmada kubeconfig client key data> \
--set agent.kubeconfig.server=https://<insert node's IP address>:32443 \È necessario ripetere tre volte il comando precedente e inserire le seguenti variabili:
- Il nome del cluster. Questo è o
eu,ap, ous - L'autorità di certificazione del gestore del cluster. Questo valore si trova nel file
karmada-configfileunder clusters[0].cluster['certificate-authority-data'].
È possibile decodificare il valore da base64. - I dati del certificato client dell'utente. Questo valore si trova nel file
karmada-configfile sottousers[0].user['client-certificate-data'].
È possibile decodificare il valore da base64. - I dati del certificato client dell'utente. Questo valore si trova nel file
karmada-configfile sottousers[0].user['client-key-data'].
È possibile decodificare il valore da base64. - L'indirizzo IP del nodo che ospita il piano di controllo di Karmada.
Per verificare che l'installazione sia stata completata, è possibile eseguire il seguente comando:
bash
$ kubectl get clusters --kubeconfig=karmada-config
NAME VERSION MODE READY
eu v1.23.8 Pull True
ap v1.23.8 Pull True
us v1.23.8 Pull TrueEccellente!
Orchestrazione della distribuzione multicluster con le politiche di Karmada
Con la configurazione attuale, si invia un carico di lavoro a Karmada, che lo distribuirà sugli altri cluster.
Verifichiamo questo creando un deployment:
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello
spec:
replicas: 3
selector:
matchLabels:
app: hello
template:
metadata:
labels:
app: hello
spec:
containers:
- image: stefanprodan/podinfo
name: hello
---
apiVersion: v1
kind: Service
metadata:
name: hello
spec:
ports:
- port: 5000
targetPort: 9898
selector:
app: helloSi può inviare la distribuzione al server Karmada API con:
bash
$ kubectl apply -f deployment.yaml --kubeconfig=karmada-configQuesta distribuzione ha tre repliche, che verranno distribuite equamente sui tre cluster?
Controlliamo:
bash
$ kubectl get deployments --kubeconfig=karmada-config
NAME READY UP-TO-DATE AVAILABLE
hello 0/3 0 0Perché Karmada non sta creando i baccelli?
Descriviamo la distribuzione:
bash
$ kubectl describe deployment hello --kubeconfig=karmada-config
Name: hello
Namespace: default
Selector: app=hello
Replicas: 3 desired | 0 updated | 0 total | 0 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Events:
Type Reason From Message
---- ------ ---- -------
Warning ApplyPolicyFailed resource-detector No policy match for resourceKarmada non sa cosa fare con le distribuzioni perché non è stato specificato un criterio.
Lo scheduler di Karmada utilizza le politiche per allocare i carichi di lavoro ai cluster.
Definiamo un semplice criterio che assegna una replica a ogni cluster:
yaml
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: hello-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: hello
- apiVersion: v1
kind: Service
name: hello
placement:
clusterAffinity:
clusterNames:
- eu
- ap
- us
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- us
weight: 1
- targetCluster:
clusterNames:
- ap
weight: 1
- targetCluster:
clusterNames:
- eu
weight: 1È possibile inviare il criterio al cluster con:
bash
$ kubectl apply -f policy.yaml --kubeconfig=karmada-configEsaminiamo le distribuzioni e i pod:
bash
$ kubectl get deployments --kubeconfig=karmada-config
NAME READY UP-TO-DATE AVAILABLE
hello 3/3 3 3
$ kubectl get pods --kubeconfig=kubeconfig-eu
NAME READY STATUS RESTARTS
hello-5d857996f-hjfqq 1/1 Running 0
$ kubectl get pods --kubeconfig=kubeconfig-ap
NAME READY STATUS RESTARTS
hello-5d857996f-xr6hr 1/1 Running 0
$ kubectl get pods --kubeconfig=kubeconfig-us
NAME READY STATUS RESTARTS
hello-5d857996f-nbz48 1/1 Running 0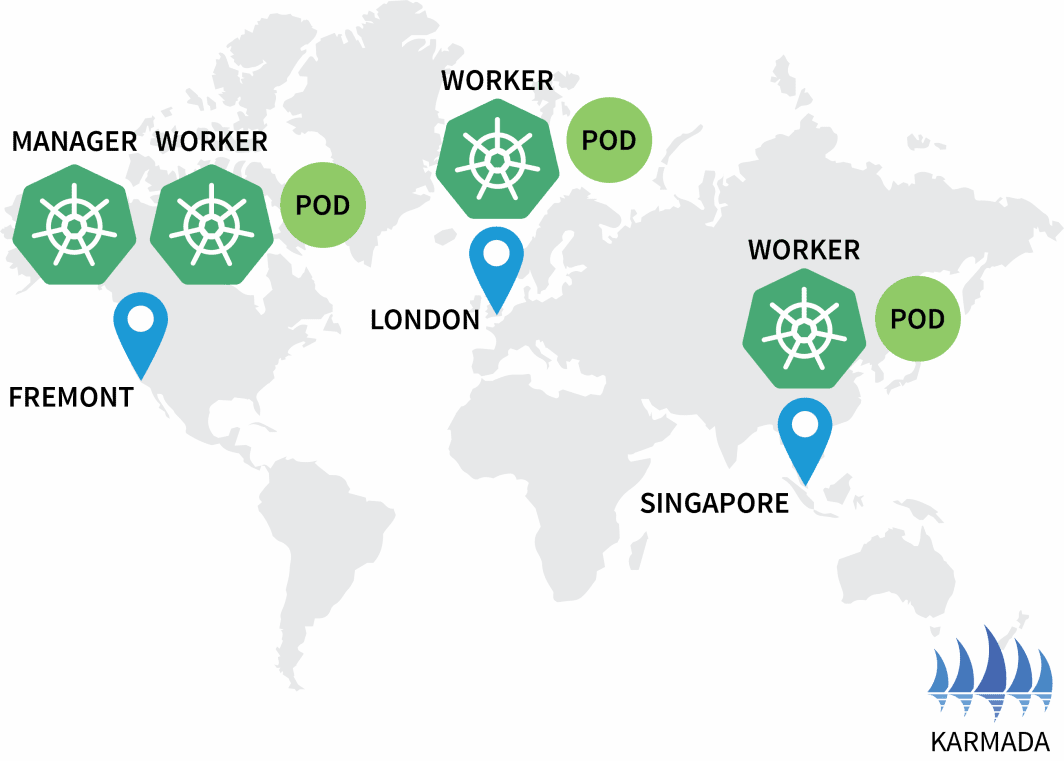
Karmada ha assegnato un pod a ogni cluster perché la politica ha definito un peso uguale per ogni cluster.
Scaliamo il deployment a 10 repliche con:
bash
$ kubectl scale deployment/hello --replicas=10 --kubeconfig=karmada-configSe si ispezionano i baccelli, si può trovare quanto segue:
bash
$ kubectl get deployments --kubeconfig=karmada-config
NAME READY UP-TO-DATE AVAILABLE
hello 10/10 10 10
$ kubectl get pods --kubeconfig=kubeconfig-eu
NAME READY STATUS RESTARTS
hello-5d857996f-dzfzm 1/1 Running 0
hello-5d857996f-hjfqq 1/1 Running 0
hello-5d857996f-kw2rt 1/1 Running 0
hello-5d857996f-nz7qz 1/1 Running 0
$ kubectl get pods --kubeconfig=kubeconfig-ap
NAME READY STATUS RESTARTS
hello-5d857996f-pd9t6 1/1 Running 0
hello-5d857996f-r7bmp 1/1 Running 0
hello-5d857996f-xr6hr 1/1 Running 0
$ kubectl get pods --kubeconfig=kubeconfig-us
NAME READY STATUS RESTARTS
hello-5d857996f-nbz48 1/1 Running 0
hello-5d857996f-nzgpn 1/1 Running 0
hello-5d857996f-rsp7k 1/1 Running 0Modifichiamo la politica in modo che i cluster UE e USA detengano il 40% dei baccelli e solo il 20% sia lasciato al cluster AP.
yaml
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: hello-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: hello
- apiVersion: v1
kind: Service
name: hello
placement:
clusterAffinity:
clusterNames:
- eu
- ap
- us
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- us
weight: 2
- targetCluster:
clusterNames:
- ap
weight: 1
- targetCluster:
clusterNames:
- eu
weight: 2È possibile presentare la polizza con:
bash
$ kubectl apply -f policy.yaml --kubeconfig=karmada-configÈ possibile osservare la distribuzione del baccello che cambia di conseguenza:
bash
$ kubectl get pods --kubeconfig=kubeconfig-eu
NAME READY STATUS RESTARTS AGE
hello-5d857996f-hjfqq 1/1 Running 0 6m5s
hello-5d857996f-kw2rt 1/1 Running 0 2m27s
$ kubectl get pods --kubeconfig=kubeconfig-ap
hello-5d857996f-k9hsm 1/1 Running 0 51s
hello-5d857996f-pd9t6 1/1 Running 0 2m41s
hello-5d857996f-r7bmp 1/1 Running 0 2m41s
hello-5d857996f-xr6hr 1/1 Running 0 6m19s
$ kubectl get pods --kubeconfig=kubeconfig-us
hello-5d857996f-nbz48 1/1 Running 0 6m29s
hello-5d857996f-nzgpn 1/1 Running 0 2m51s
hello-5d857996f-rgj9t 1/1 Running 0 61s
hello-5d857996f-rsp7k 1/1 Running 0 2m51s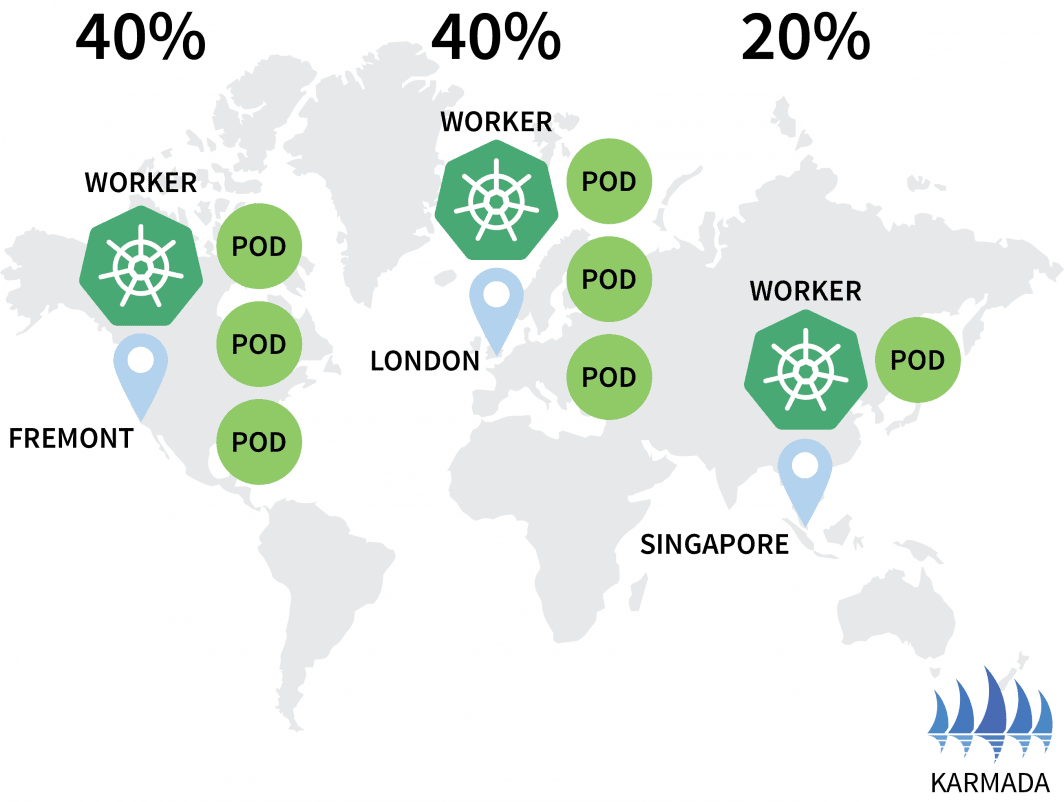
Grande!
Karmada supporta diverse politiche per distribuire i carichi di lavoro. È possibile consultare la documentazione per casi d'uso più avanzati.
I pod sono in esecuzione nei tre cluster, ma come è possibile accedervi?
Esaminiamo il servizio di Karmada:
bash
$ kubectl describe service hello --kubeconfig=karmada-config
Name: hello
Namespace: default
Labels: propagationpolicy.karmada.io/name=hello-propagation
propagationpolicy.karmada.io/namespace=default
Selector: app=hello
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.105.24.193
IPs: 10.105.24.193
Port: <unset> 5000/TCP
TargetPort: 9898/TCP
Events:
Type Reason Message
---- ------ -------
Normal SyncSucceed Successfully applied resource(default/hello) to cluster ap
Normal SyncSucceed Successfully applied resource(default/hello) to cluster us
Normal SyncSucceed Successfully applied resource(default/hello) to cluster eu
Normal AggregateStatusSucceed Update resourceBinding(default/hello-service) with AggregatedStatus successfully.
Normal ScheduleBindingSucceed Binding has been scheduled
Normal SyncWorkSucceed Sync work of resourceBinding(default/hello-service) successful.Il servizio è distribuito in tutti e tre i cluster, ma non sono collegati.
Anche se Karmada può gestire diversi cluster, non fornisce alcun meccanismo di rete per assicurarsi che i tre cluster siano collegati. In altre parole, Karmada è uno strumento eccellente per orchestrare le distribuzioni tra i cluster, ma è necessario qualcos'altro per assicurarsi che questi cluster possano comunicare tra loro.
Connessione di più cluster con Istio
Istio viene solitamente utilizzato per controllare il traffico di rete tra le applicazioni dello stesso cluster. Funziona intercettando tutte le richieste in uscita e in entrata e proxiandole attraverso Envoy.
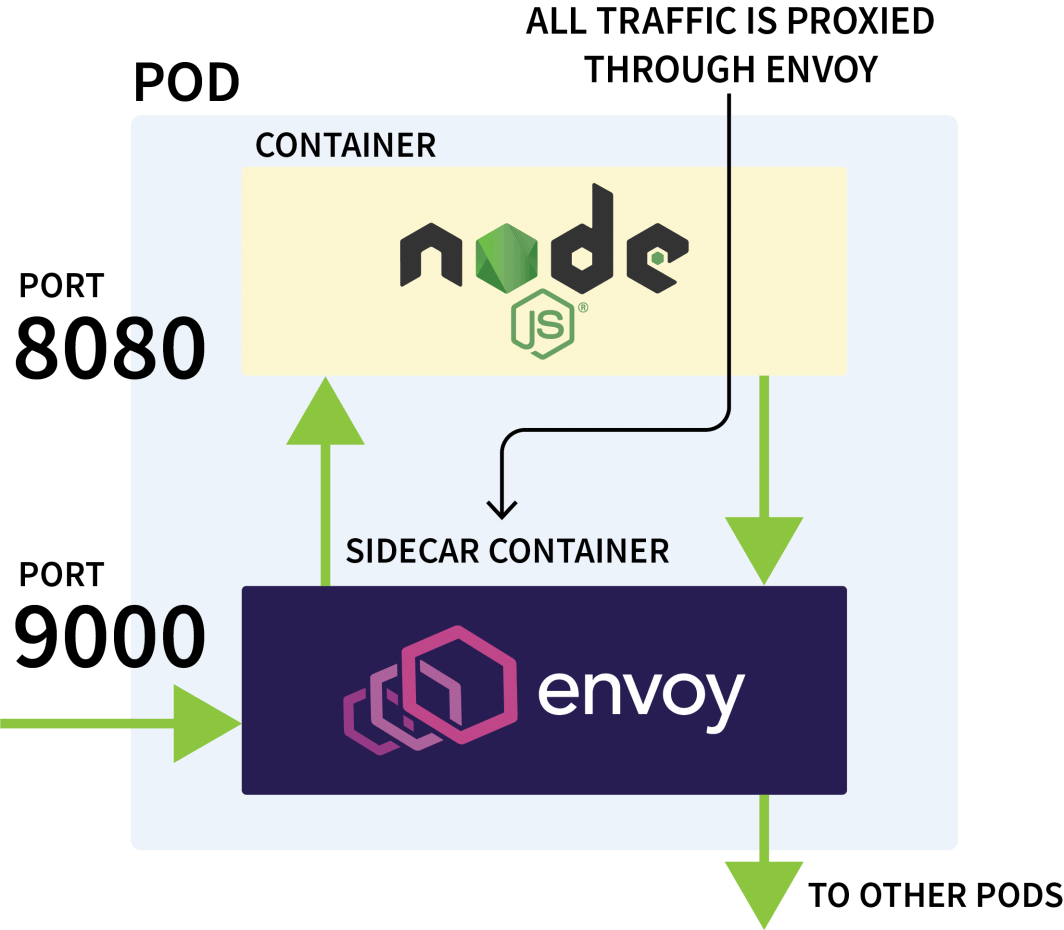
Il piano di controllo di Istio è incaricato di aggiornare e raccogliere le metriche da questi proxy e può anche impartire istruzioni per deviare il traffico.
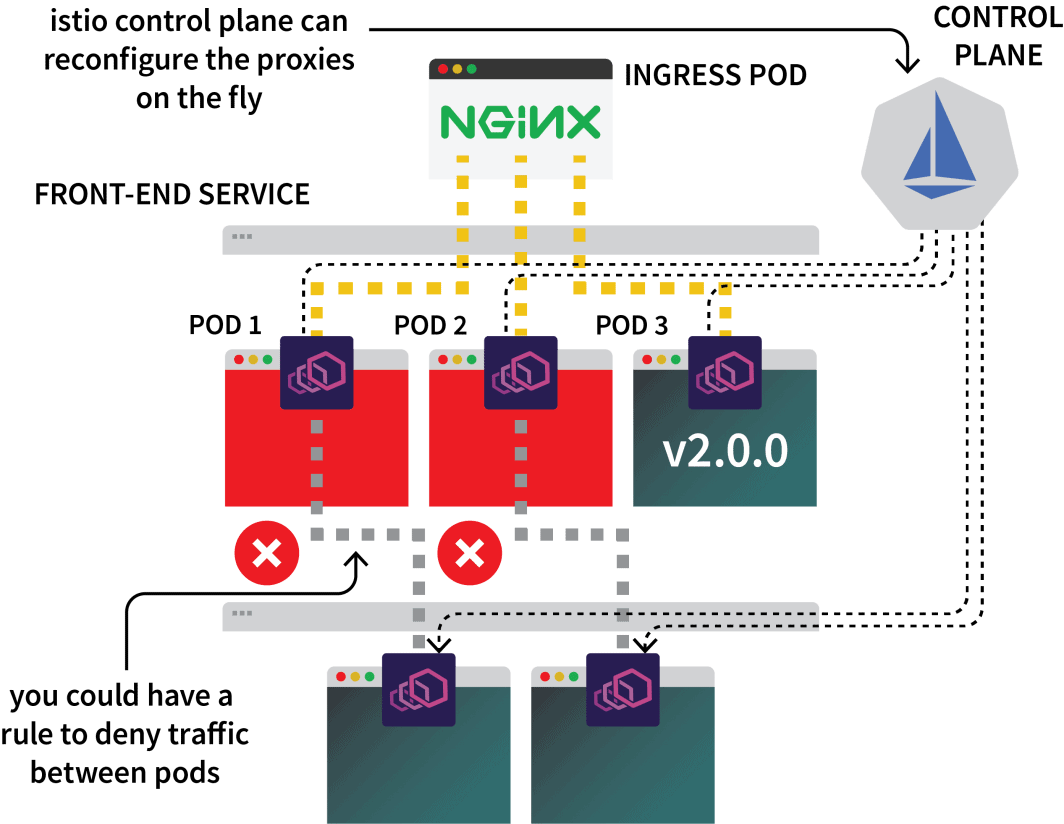
Quindi si può usare Istio per intercettare tutto il traffico verso un particolare servizio e indirizzarlo a uno dei tre cluster. Questa è l'idea della configurazione multicluster di Istio.
Basta con la teoria: sporchiamoci le mani. Il primo passo è installare Istio nei tre cluster.
Sebbene esistano diversi modi per installare Istio, di solito preferisco Helm:
bash
$ helm repo add istio https://istio-release.storage.googleapis.com/charts
$ helm repo list
NAME URL
istio https://istio-release.storage.googleapis.com/chartsÈ possibile installare Istio nei tre cluster con:
bash
$ helm install istio-base istio/base \
--kubeconfig=kubeconfig-<insert-cluster-name> \
--create-namespace --namespace istio-system \
--version=1.14.1Si consiglia di sostituire il cluster-name con ap, eu e us ed eseguire il comando per ciascuno di essi.
Il diagramma di base installa per lo più risorse comuni, come Ruoli e RoleBindings.
L'installazione vera e propria è contenuta nel file istiod grafico. Ma prima di procedere, occorre configurare l'Autorità di certificazione (CA) di Istio per assicurarsi che i tre cluster possano connettersi e fidarsi l'uno dell'altro.
In una nuova directory, clonare il repository Istio con:
bash
$ git clone https://github.com/istio/istioCreare un certs e passare a quella cartella:
bash
$ mkdir certs
$ cd certsCreare il certificato radice con:
bash
$ make -f ../istio/tools/certs/Makefile.selfsigned.mk root-caIl comando ha generato i seguenti file:
root-cert.pem: il certificato radice generatoroot-key.pem: la chiave radice generataroot-ca.conf: la configurazione per OpenSSL per generare il certificato di rootroot-cert.csr: il CSR generato per il certificato radice
Per ogni cluster, generare un certificato intermedio e una chiave per l'autorità di certificazione Istio:
bash
$ make -f ../istio/tools/certs/Makefile.selfsigned.mk cluster1-cacerts
$ make -f ../istio/tools/certs/Makefile.selfsigned.mk cluster2-cacerts
$ make -f ../istio/tools/certs/Makefile.selfsigned.mk cluster3-cacertsI comandi genereranno i seguenti file in una directory denominata cluster1, cluster2, e cluster3:
bash
$ kubectl create secret generic cacerts -n istio-system \
--kubeconfig=kubeconfig-<cluster-name>
--from-file=<cluster-folder>/ca-cert.pem \
--from-file=<cluster-folder>/ca-key.pem \
--from-file=<cluster-folder>/root-cert.pem \
--from-file=<cluster-folder>/cert-chain.pemI comandi devono essere eseguiti con le seguenti variabili:
| cluster name | folder name |
| :----------: | :---------: |
| ap | cluster1 |
| us | cluster2 |
| eu | cluster3 |Fatto questo, si è finalmente pronti a installare istiod:
bash
$ helm install istiod istio/istiod \
--kubeconfig=kubeconfig-<insert-cluster-name> \
--namespace istio-system \
--version=1.14.1 \
--set global.meshID=mesh1 \
--set global.multiCluster.clusterName=<insert-cluster-name> \
--set global.network=<insert-network-name>Ripetete il comando tre volte con le seguenti variabili:
| cluster name | network name |
| :----------: | :----------: |
| ap | network1 |
| us | network2 |
| eu | network3 |Si dovrebbe anche etichettare lo spazio dei nomi di Istio con un'annotazione di topologia:
bash
$ kubectl label namespace istio-system topology.istio.io/network=network1 --kubeconfig=kubeconfig-ap
$ kubectl label namespace istio-system topology.istio.io/network=network2 --kubeconfig=kubeconfig-us
$ kubectl label namespace istio-system topology.istio.io/network=network3 --kubeconfig=kubeconfig-euTutto qui?
Quasi.
Tunneling del traffico con un gateway est-ovest
È ancora necessario:
- un gateway per incanalare il traffico da un cluster all'altro; e
- un meccanismo per scoprire gli indirizzi IP in altri cluster.
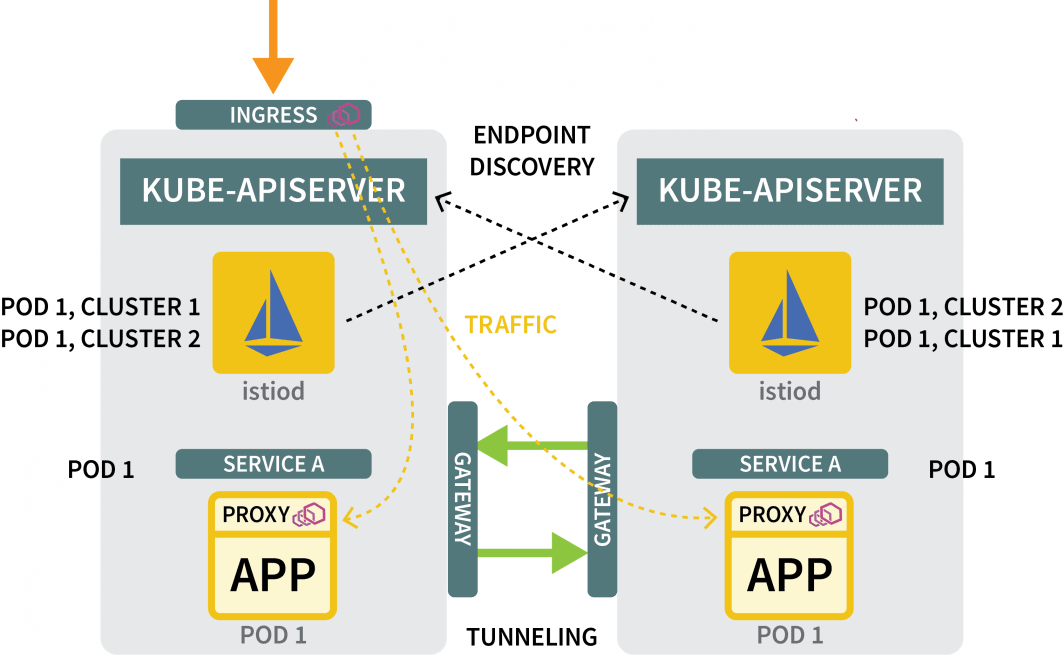
Per il gateway, si può usare Helm per installarlo:
bash
$ helm install eastwest-gateway istio/gateway \
--kubeconfig=kubeconfig-<insert-cluster-name> \
--namespace istio-system \
--version=1.14.1 \
--set labels.istio=eastwestgateway \
--set labels.app=istio-eastwestgateway \
--set labels.topology.istio.io/network=istio-eastwestgateway \
--set labels.topology.istio.io/network=istio-eastwestgateway \
--set networkGateway=<insert-network-name> \
--set service.ports[0].name=status-port \
--set service.ports[0].port=15021 \
--set service.ports[0].targetPort=15021 \
--set service.ports[1].name=tls \
--set service.ports[1].port=15443 \
--set service.ports[1].targetPort=15443 \
--set service.ports[2].name=tls-istiod \
--set service.ports[2].port=15012 \
--set service.ports[2].targetPort=15012 \
--set service.ports[3].name=tls-webhook \
--set service.ports[3].port=15017 \
--set service.ports[3].targetPort=15017 \Ripetete il comando tre volte con le seguenti variabili:
| cluster name | network name |
| :----------: | :----------: |
| ap | network1 |
| us | network2 |
| eu | network3 |Quindi, per ogni cluster, esporre un gateway con la seguente risorsa:
yaml
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: cross-network-gateway
spec:
selector:
istio: eastwestgateway
servers:
- port:
number: 15443
name: tls
protocol: TLS
tls:
mode: AUTO_PASSTHROUGH
hosts:
- "*.local"È possibile inviare il file ai cluster con:
bash
$ kubectl apply -f expose.yaml --kubeconfig=kubeconfig-eu
$ kubectl apply -f expose.yaml --kubeconfig=kubeconfig-ap
$ kubectl apply -f expose.yaml --kubeconfig=kubeconfig-usPer i meccanismi di scoperta, è necessario condividere le credenziali di ciascun cluster. Questo è necessario perché i cluster non sono a conoscenza l'uno dell'altro.
Per scoprire altri indirizzi IP, devono accedere ad altri cluster e registrarli come possibili destinazioni del traffico. A tal fine, è necessario creare un segreto Kubernetes con il file kubeconfig per gli altri cluster.
Istio li userà per connettersi agli altri cluster, scoprire gli endpoint e istruire i proxy Envoy a inoltrare il traffico.
Sono necessari tre segreti:
yaml
apiVersion: v1
kind: Secret
metadata:
labels:
istio/multiCluster: true
annotations:
networking.istio.io/cluster: <insert cluster name>
name: "istio-remote-secret-<insert cluster name>"
type: Opaque
data:
<insert cluster name>: <insert cluster kubeconfig as base64>È necessario creare i tre segreti con le seguenti variabili:
| cluster name | secret filename | kubeconfig |
| :----------: | :-------------: | :-----------: |
| ap | secret1.yaml | kubeconfig-ap |
| us | secret2.yaml | kubeconfig-us |
| eu | secret3.yaml | kubeconfig-eu |Ora è necessario inviare i segreti al cluster, facendo attenzione a non inviare il segreto AP al cluster AP.
I comandi devono essere i seguenti:
bash
$ kubectl apply -f secret2.yaml -n istio-system --kubeconfig=kubeconfig-ap
$ kubectl apply -f secret3.yaml -n istio-system --kubeconfig=kubeconfig-ap
$ kubectl apply -f secret1.yaml -n istio-system --kubeconfig=kubeconfig-us
$ kubectl apply -f secret3.yaml -n istio-system --kubeconfig=kubeconfig-us
$ kubectl apply -f secret1.yaml -n istio-system --kubeconfig=kubeconfig-eu
$ kubectl apply -f secret2.yaml -n istio-system --kubeconfig=kubeconfig-euE questo è tutto!
Siete pronti a testare la configurazione.
Test della rete multicluster
Creiamo un deployment per un pod di sonno.
Si userà questo pod per fare una richiesta al deployment Hello creato in precedenza:
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: sleep
spec:
selector:
matchLabels:
app: sleep
template:
metadata:
labels:
app: sleep
spec:
terminationGracePeriodSeconds: 0
containers:
- name: sleep
image: curlimages/curl
command: ["/bin/sleep", "3650d"]
imagePullPolicy: IfNotPresent
volumeMounts:
- mountPath: /etc/sleep/tls
name: secret-volume
volumes:
- name: secret-volume
secret:
secretName: sleep-secret
optional: trueÈ possibile creare l'installazione client con:
bash
$ kubectl apply -f sleep.yaml --kubeconfig=karmada-configPoiché non esiste un criterio per questa distribuzione, Karmada non la elaborerà e la lascerà in sospeso. È possibile modificare il criterio per includere l'installazione client con:
yaml
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: hello-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: hello
- apiVersion: v1
kind: Service
name: hello
- apiVersion: apps/v1
kind: Deployment
name: sleep
placement:
clusterAffinity:
clusterNames:
- eu
- ap
- us
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- us
weight: 2
- targetCluster:
clusterNames:
- ap
weight: 2
- targetCluster:
clusterNames:
- eu
weight: 1È possibile applicare la politica con:
bash
$ kubectl apply -f policy.yaml --kubeconfig=karmada-configÈ possibile capire dove è stato distribuito il pod con:
bash
$ kubectl get pods --kubeconfig=kubeconfig-eu
$ kubectl get pods --kubeconfig=kubeconfig-ap
$ kubectl get pods --kubeconfig=kubeconfig-usOra, supponendo che il pod sia atterrato sul cluster USA, eseguite il seguente comando:
Now, assuming the pod landed on the US cluster, execute the following command:
bash
for i in {1..10}
do
kubectl exec --kubeconfig=kubeconfig-us -c sleep \
"$(kubectl get pod --kubeconfig=kubeconfig-us -l \
app=sleep -o jsonpath='{.items[0].metadata.name}')" \
-- curl -sS hello:5000 | grep REGION
donePotreste notare che la risposta proviene da baccelli diversi di regioni diverse!
Lavoro fatto!
Dove andare a finire?
Questa configurazione è piuttosto elementare e manca di molte altre funzioni che probabilmente vorrete incorporare:
- si potrebbe esporre un ingress Istio da ogni cluster per ingerire il traffico;
- si può utilizzare Istio per modellare il traffico in modo da privilegiare il traffico locale; e
- si potrebbero usare le regole di applicazione dei criteri di Istio per definire come il traffico può fluire tra i cluster.
Per ricapitolare quanto abbiamo trattato in questo post:
- utilizzando Karmada per controllare diversi cluster;
- definire i criteri per pianificare i carichi di lavoro su più cluster;
- utilizzare Istio per collegare in rete più cluster; e
- come Istio intercetta il traffico e lo inoltra ad altri cluster.
È possibile vedere una panoramica completa dello scaling di Kubernetes tra le regioni, oltre ad altre metodologie di scaling, registrandosi alla nostra serie di webinar e guardandoli on-demand.



Commenti