

Cet article fait partie de notre série sur la mise à l'échelle de Kubernetes. Inscrivez-vous sur pour regarder en direct ou accéder à l'enregistrement, et consultez les autres articles de cette série :
- Mise à l'échelle de Kubernetes à zéro (et inversement)
- Mise à l'échelle proactive pour les clusters Kubernetes
Un défi intéressant avec Kubernetes est le déploiement de charges de travail sur plusieurs régions. Bien qu'il soit techniquement possible d'avoir un cluster avec plusieurs nœuds situés dans différentes régions, cette solution est généralement considérée comme à éviter en raison de la latence supplémentaire.
Une alternative populaire consiste à déployer un cluster pour chaque région et à trouver un moyen de les orchestrer.
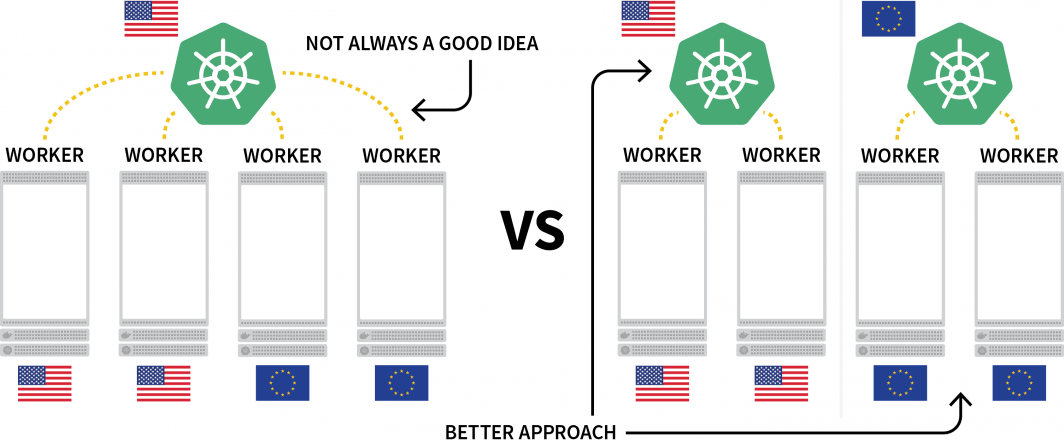
Dans ce poste, vous allez :
- Créez trois clusters : un en Amérique du Nord, un en Europe et un en Asie du Sud-Est.
- Créez un quatrième cluster qui servira d'orchestrateur pour les autres.
- Configurez un réseau unique parmi les trois réseaux de clusters pour une communication sans faille.
Ce billet a été programmé pour fonctionner avec Terraform , ce qui nécessite une interaction minimale. Vous pouvez trouver le code pour cela sur le GitHub de LearnK8s.
Création du gestionnaire de clusters
Commençons par créer le cluster qui va gérer le reste. Les commandes suivantes peuvent être utilisées pour créer le cluster et enregistrer le fichier kubeconfig.
bash
$ linode-cli lke cluster-create \
--label cluster-manager \
--region eu-west \
--k8s_version 1.23
$ linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfig-cluster-managerVous pouvez vérifier que l'installation est réussie avec :
bash
$ kubectl get pods -A --kubeconfig=kubeconfig-cluster-managerExcellent !
Dans le gestionnaire de cluster, vous installerez Karmada, un système de gestion qui vous permet d'exécuter vos applications cloud-natives sur plusieurs clusters et clouds Kubernetes. Karmada a un plan de contrôle installé dans le gestionnaire de cluster et l'agent installé dans chaque autre cluster.
Le plan de contrôle comporte trois composantes :
- Un serveur API ;
- Un contrôleur de gestion ; et
- Un planificateur
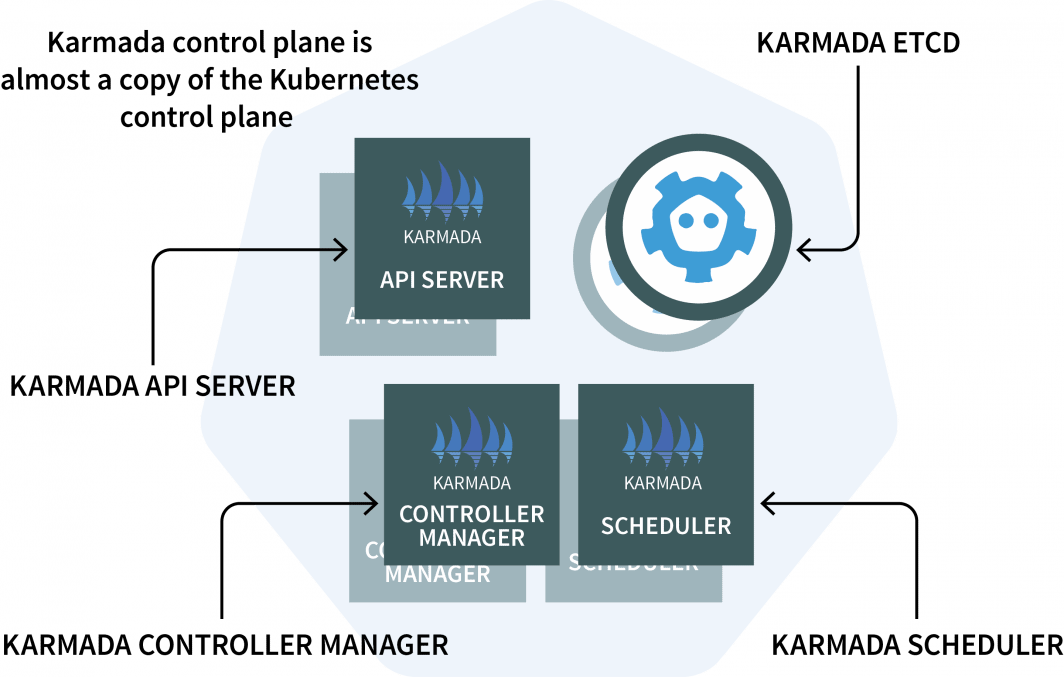
Si ces éléments vous semblent familiers, c'est parce que le plan de contrôle de Kubernetes comporte les mêmes composants ! Karmada a dû les copier et les augmenter pour qu'ils fonctionnent avec plusieurs clusters.
Assez de théorie. Passons au code.
Vous allez utiliser Helm pour installer le serveur API Karmada. Ajoutons le dépôt Helm avec :
bash
$ helm repo add karmada-charts https://raw.githubusercontent.com/karmada-io/karmada/master/charts
$ helm repo list
NAME URL
karmada-charts https://raw.githubusercontent.com/karmada-io/karmada/master/chartsPuisque le serveur API Karmada doit être accessible à tous les autres clusters, vous devrez
- l'exposer à partir du nœud ; et
- s'assurer que la connexion est fiable.
Récupérons donc l'adresse IP du nœud hébergeant le plan de contrôle avec :
bash
kubectl get nodes -o jsonpath='{.items[0].status.addresses[?(@.type==\"ExternalIP\")].address}' \
--kubeconfig=kubeconfig-cluster-managerVous pouvez maintenant installer le plan de contrôle Karmada avec :
bash
$ helm install karmada karmada-charts/karmada \
--kubeconfig=kubeconfig-cluster-manager \
--create-namespace --namespace karmada-system \
--version=1.2.0 \
--set apiServer.hostNetwork=false \
--set apiServer.serviceType=NodePort \
--set apiServer.nodePort=32443 \
--set certs.auto.hosts[0]="kubernetes.default.svc" \
--set certs.auto.hosts[1]="*.etcd.karmada-system.svc.cluster.local" \
--set certs.auto.hosts[2]="*.karmada-system.svc.cluster.local" \
--set certs.auto.hosts[3]="*.karmada-system.svc" \
--set certs.auto.hosts[4]="localhost" \
--set certs.auto.hosts[5]="127.0.0.1" \
--set certs.auto.hosts[6]="<insert the IP address of the node>"Une fois l'installation terminée, vous pouvez récupérer le kubeconfig pour vous connecter à l'API Karmada :
bash
kubectl get secret karmada-kubeconfig \
--kubeconfig=kubeconfig-cluster-manager \
-n karmada-system \
-o jsonpath={.data.kubeconfig} | base64 -d > karmada-configMais attendez, pourquoi un autre fichier kubeconfig ?
L'API Karmada est conçue pour remplacer l'API Kubernetes standard, mais conserve toutes les fonctionnalités auxquelles vous êtes habitué. En d'autres termes, vous pouvez créer des déploiements qui couvrent plusieurs clusters avec kubectl.
Avant de tester l'API Karmada et kubectl, vous devez patcher le fichier kubeconfig. Par défaut, le fichier kubeconfig généré ne peut être utilisé qu'à l'intérieur du réseau du cluster.
Cependant, vous pouvez remplacer la ligne suivante pour que cela fonctionne :
yaml
apiVersion: v1
kind: Config
clusters:
- cluster:
certificate-authority-data: LS0tLS1CRUdJTi…
insecure-skip-tls-verify: false
server: https://karmada-apiserver.karmada-system.svc.cluster.local:5443 # <- this works only in the cluster
name: karmada-apiserver
# truncatedRemplacez-la par l'adresse IP du nœud que vous avez récupérée précédemment :
yaml
apiVersion: v1
kind: Config
clusters:
- cluster:
certificate-authority-data: LS0tLS1CRUdJTi…
insecure-skip-tls-verify: false
server: https://<node's IP address>:32443 # <- this works from the public internet
name: karmada-apiserver
# truncatedSuper, il est temps de tester Karmada.
Installation de l'agent Karmada
Exécutez la commande suivante pour récupérer tous les déploiements et tous les clusters :
bash
$ kubectl get clusters,deployments --kubeconfig=karmada-config
No resources foundSans surprise, il n'y a aucun déploiement et aucun cluster supplémentaire. Ajoutons quelques clusters supplémentaires et connectons-les au plan de contrôle de Karmada.
Répétez les commandes suivantes trois fois :
bash
linode-cli lke cluster-create \
--label <insert-cluster-name> \
--region <insert-region> \
--k8s_version 1.23
linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfig-<insert-cluster-name>Les valeurs doivent être les suivantes :
- Nom du cluster
eu, régioneu-west et le fichier kubeconfigkubeconfig-eu - Nom du cluster
ap, régionap-southet le fichier kubeconfigkubeconfig-ap - Nom du cluster
us, régionus-westet le fichier kubeconfigkubeconfig-us
Vous pouvez vérifier que les clusters sont créés avec succès avec :
bash
$ kubectl get pods -A --kubeconfig=kubeconfig-eu
$ kubectl get pods -A --kubeconfig=kubeconfig-ap
$ kubectl get pods -A --kubeconfig=kubeconfig-usIl est maintenant temps de les faire rejoindre le groupe Karmada.
Karmada utilise un agent sur chaque autre cluster pour coordonner le déploiement avec le plan de contrôle.
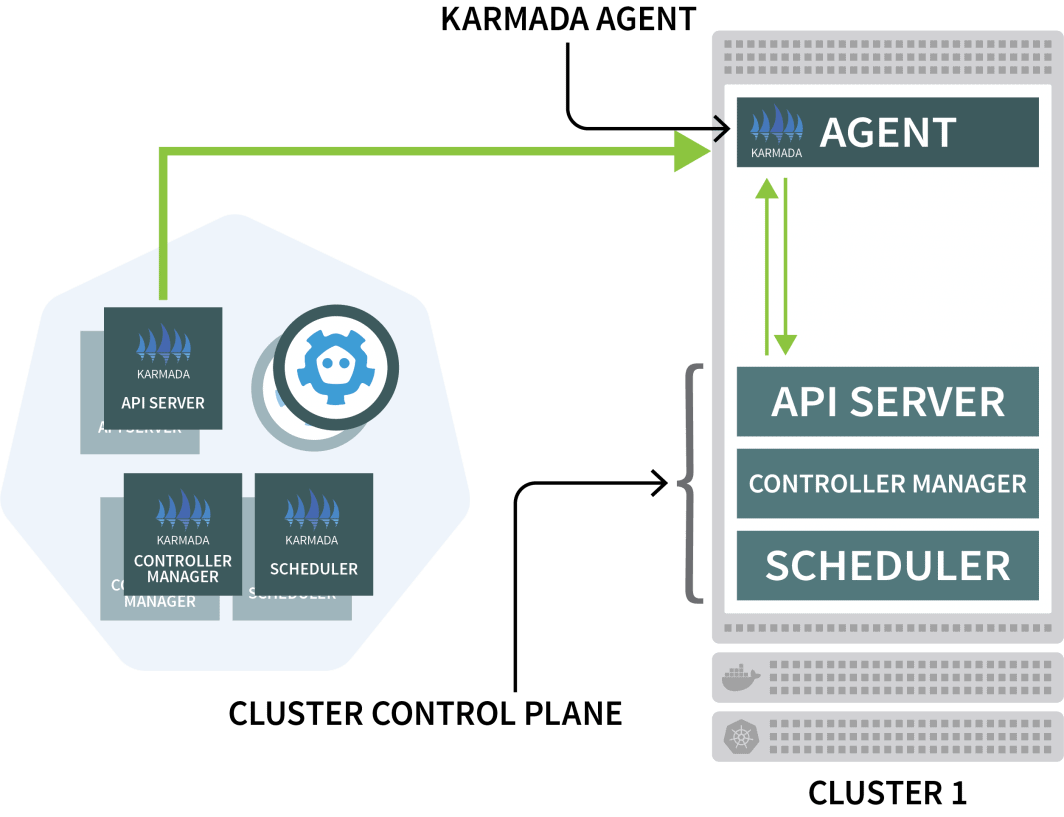
Vous utiliserez Helm pour installer l'agent Karmada et le lier au gestionnaire de cluster :
bash
$ helm install karmada karmada-charts/karmada \
--kubeconfig=kubeconfig-<insert-cluster-name> \
--create-namespace --namespace karmada-system \
--version=1.2.0 \
--set installMode=agent \
--set agent.clusterName=<insert-cluster-name> \
--set agent.kubeconfig.caCrt=<karmada kubeconfig certificate authority> \
--set agent.kubeconfig.crt=<karmada kubeconfig client certificate data> \
--set agent.kubeconfig.key=<karmada kubeconfig client key data> \
--set agent.kubeconfig.server=https://<insert node's IP address>:32443 \Vous devrez répéter la commande ci-dessus trois fois et insérer les variables suivantes :
- Le nom du cluster. Il s'agit soit
eu,apouus - L'autorité de certification du gestionnaire de cluster. Vous pouvez trouver cette valeur dans le
karmada-configfichierunder clusters[0].cluster['certificate-authority-data'].
Vous pouvez décoder la valeur de base64. - Les données du certificat client de l'utilisateur. Vous pouvez trouver cette valeur dans le
karmada-configfichier soususers[0].user['client-certificate-data'].
Vous pouvez décoder la valeur de base64. - Les données du certificat client de l'utilisateur. Vous pouvez trouver cette valeur dans le
karmada-configfichier soususers[0].user['client-key-data'].
Vous pouvez décoder la valeur de base64. - L'adresse IP du nœud hébergeant le plan de contrôle Karmada.
Pour vérifier que l'installation est terminée, vous pouvez lancer la commande suivante :
bash
$ kubectl get clusters --kubeconfig=karmada-config
NAME VERSION MODE READY
eu v1.23.8 Pull True
ap v1.23.8 Pull True
us v1.23.8 Pull TrueExcellent !
Orchestrer le déploiement multi-clusters avec les politiques de Karmada
Dans la configuration actuelle, vous soumettez une charge de travail à Karmada, qui la distribue ensuite aux autres clusters.
Testons cela en créant un déploiement :
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello
spec:
replicas: 3
selector:
matchLabels:
app: hello
template:
metadata:
labels:
app: hello
spec:
containers:
- image: stefanprodan/podinfo
name: hello
---
apiVersion: v1
kind: Service
metadata:
name: hello
spec:
ports:
- port: 5000
targetPort: 9898
selector:
app: helloVous pouvez soumettre le déploiement au serveur API de Karmada avec :
bash
$ kubectl apply -f deployment.yaml --kubeconfig=karmada-configCe déploiement comporte trois répliques - seront-elles réparties de manière égale sur les trois clusters ?
Vérifions :
bash
$ kubectl get deployments --kubeconfig=karmada-config
NAME READY UP-TO-DATE AVAILABLE
hello 0/3 0 0Pourquoi Karmada ne crée-t-il pas les pods ?
Décrivons le déploiement :
bash
$ kubectl describe deployment hello --kubeconfig=karmada-config
Name: hello
Namespace: default
Selector: app=hello
Replicas: 3 desired | 0 updated | 0 total | 0 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Events:
Type Reason From Message
---- ------ ---- -------
Warning ApplyPolicyFailed resource-detector No policy match for resourceKarmada ne sait pas quoi faire avec les déploiements parce que vous n'avez pas spécifié de politique.
Le planificateur Karmada utilise des politiques pour allouer les charges de travail aux clusters.
Définissons une politique simple qui attribue une réplique à chaque cluster :
yaml
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: hello-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: hello
- apiVersion: v1
kind: Service
name: hello
placement:
clusterAffinity:
clusterNames:
- eu
- ap
- us
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- us
weight: 1
- targetCluster:
clusterNames:
- ap
weight: 1
- targetCluster:
clusterNames:
- eu
weight: 1Vous pouvez soumettre la politique au cluster avec :
bash
$ kubectl apply -f policy.yaml --kubeconfig=karmada-configInspectons les déploiements et les pods :
bash
$ kubectl get deployments --kubeconfig=karmada-config
NAME READY UP-TO-DATE AVAILABLE
hello 3/3 3 3
$ kubectl get pods --kubeconfig=kubeconfig-eu
NAME READY STATUS RESTARTS
hello-5d857996f-hjfqq 1/1 Running 0
$ kubectl get pods --kubeconfig=kubeconfig-ap
NAME READY STATUS RESTARTS
hello-5d857996f-xr6hr 1/1 Running 0
$ kubectl get pods --kubeconfig=kubeconfig-us
NAME READY STATUS RESTARTS
hello-5d857996f-nbz48 1/1 Running 0
Karmada a attribué un pod à chaque cluster car votre politique a défini un poids égal pour chaque cluster.
Mettons à l'échelle le déploiement à 10 répliques avec :
bash
$ kubectl scale deployment/hello --replicas=10 --kubeconfig=karmada-configSi vous inspectez les gousses, vous pouvez trouver les éléments suivants :
bash
$ kubectl get deployments --kubeconfig=karmada-config
NAME READY UP-TO-DATE AVAILABLE
hello 10/10 10 10
$ kubectl get pods --kubeconfig=kubeconfig-eu
NAME READY STATUS RESTARTS
hello-5d857996f-dzfzm 1/1 Running 0
hello-5d857996f-hjfqq 1/1 Running 0
hello-5d857996f-kw2rt 1/1 Running 0
hello-5d857996f-nz7qz 1/1 Running 0
$ kubectl get pods --kubeconfig=kubeconfig-ap
NAME READY STATUS RESTARTS
hello-5d857996f-pd9t6 1/1 Running 0
hello-5d857996f-r7bmp 1/1 Running 0
hello-5d857996f-xr6hr 1/1 Running 0
$ kubectl get pods --kubeconfig=kubeconfig-us
NAME READY STATUS RESTARTS
hello-5d857996f-nbz48 1/1 Running 0
hello-5d857996f-nzgpn 1/1 Running 0
hello-5d857996f-rsp7k 1/1 Running 0Modifions la politique de manière à ce que les clusters européens et américains détiennent 40% des pods et que seuls 20% soient laissés au cluster AP.
yaml
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: hello-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: hello
- apiVersion: v1
kind: Service
name: hello
placement:
clusterAffinity:
clusterNames:
- eu
- ap
- us
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- us
weight: 2
- targetCluster:
clusterNames:
- ap
weight: 1
- targetCluster:
clusterNames:
- eu
weight: 2Vous pouvez soumettre la police avec :
bash
$ kubectl apply -f policy.yaml --kubeconfig=karmada-configVous pouvez observer que la distribution de votre pod change en conséquence :
bash
$ kubectl get pods --kubeconfig=kubeconfig-eu
NAME READY STATUS RESTARTS AGE
hello-5d857996f-hjfqq 1/1 Running 0 6m5s
hello-5d857996f-kw2rt 1/1 Running 0 2m27s
$ kubectl get pods --kubeconfig=kubeconfig-ap
hello-5d857996f-k9hsm 1/1 Running 0 51s
hello-5d857996f-pd9t6 1/1 Running 0 2m41s
hello-5d857996f-r7bmp 1/1 Running 0 2m41s
hello-5d857996f-xr6hr 1/1 Running 0 6m19s
$ kubectl get pods --kubeconfig=kubeconfig-us
hello-5d857996f-nbz48 1/1 Running 0 6m29s
hello-5d857996f-nzgpn 1/1 Running 0 2m51s
hello-5d857996f-rgj9t 1/1 Running 0 61s
hello-5d857996f-rsp7k 1/1 Running 0 2m51s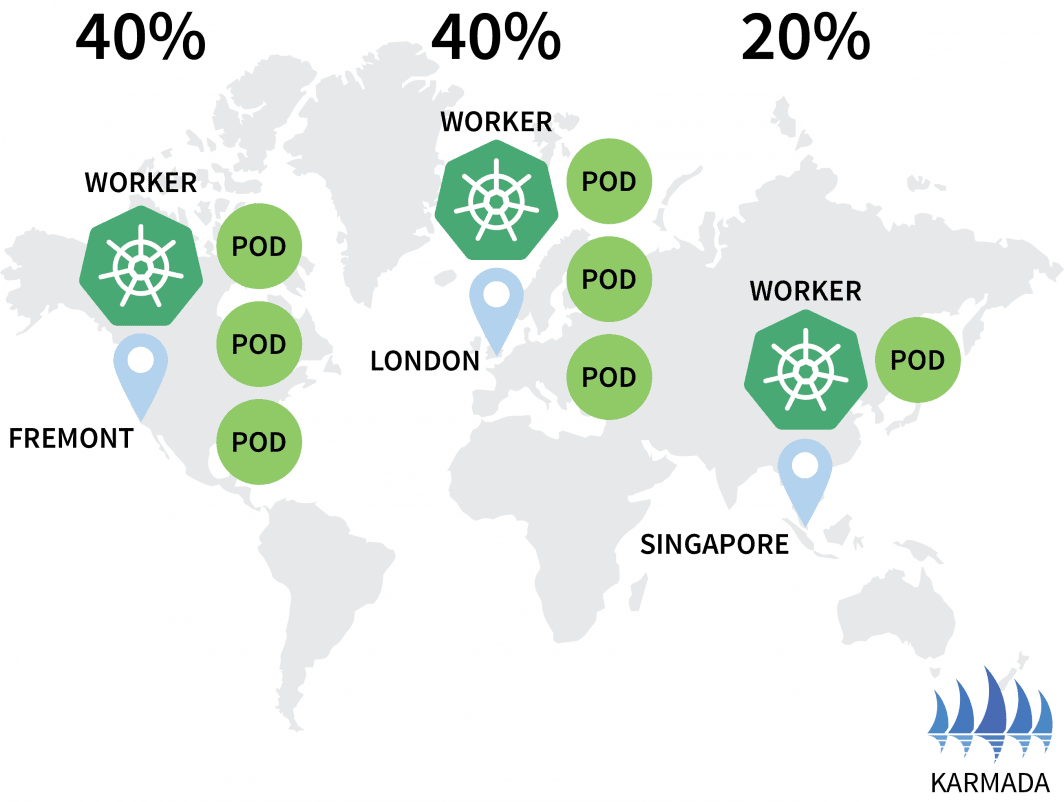
Super !
Karmada prend en charge plusieurs politiques pour distribuer vos charges de travail. Vous pouvez consulter la documentation pour des cas d'utilisation plus avancés.
Les pods fonctionnent dans les trois clusters, mais comment y accéder ?
Allons inspecter le service à Karmada :
bash
$ kubectl describe service hello --kubeconfig=karmada-config
Name: hello
Namespace: default
Labels: propagationpolicy.karmada.io/name=hello-propagation
propagationpolicy.karmada.io/namespace=default
Selector: app=hello
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.105.24.193
IPs: 10.105.24.193
Port: <unset> 5000/TCP
TargetPort: 9898/TCP
Events:
Type Reason Message
---- ------ -------
Normal SyncSucceed Successfully applied resource(default/hello) to cluster ap
Normal SyncSucceed Successfully applied resource(default/hello) to cluster us
Normal SyncSucceed Successfully applied resource(default/hello) to cluster eu
Normal AggregateStatusSucceed Update resourceBinding(default/hello-service) with AggregatedStatus successfully.
Normal ScheduleBindingSucceed Binding has been scheduled
Normal SyncWorkSucceed Sync work of resourceBinding(default/hello-service) successful.Le service est déployé dans les trois clusters, mais ils ne sont pas connectés.
Même si Karmada peut gérer plusieurs clusters, il ne fournit aucun mécanisme de mise en réseau pour s'assurer que les trois clusters sont reliés entre eux. En d'autres termes, Karmada est un excellent outil pour orchestrer des déploiements sur plusieurs clusters, mais vous avez besoin d'autre chose pour vous assurer que ces clusters peuvent communiquer entre eux.
Connecter plusieurs clusters avec Istio
Istio est généralement utilisé pour contrôler le trafic réseau entre les applications d'un même cluster. Il fonctionne en interceptant toutes les requêtes sortantes et entrantes et en les faisant passer par Envoy.
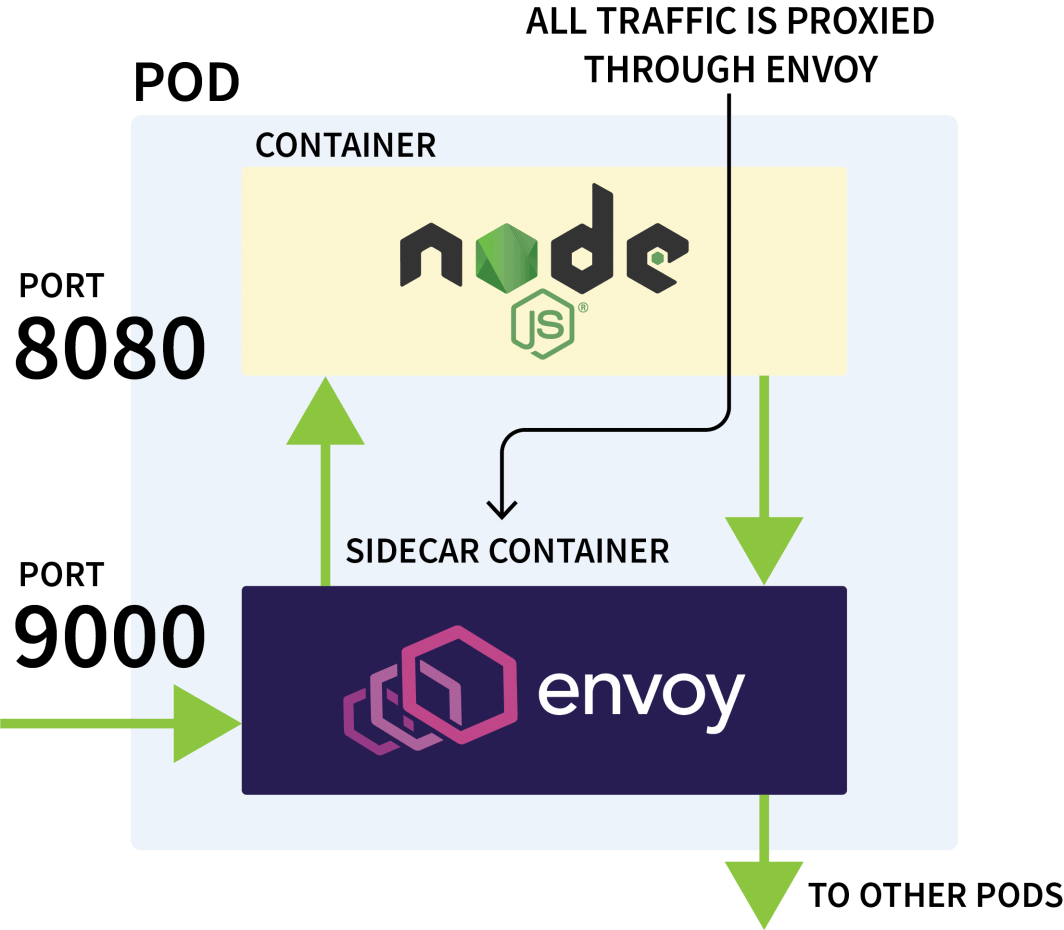
Le plan de contrôle d'Istio est chargé de mettre à jour et de collecter les métriques de ces proxies et peut également émettre des instructions pour dévier le trafic.
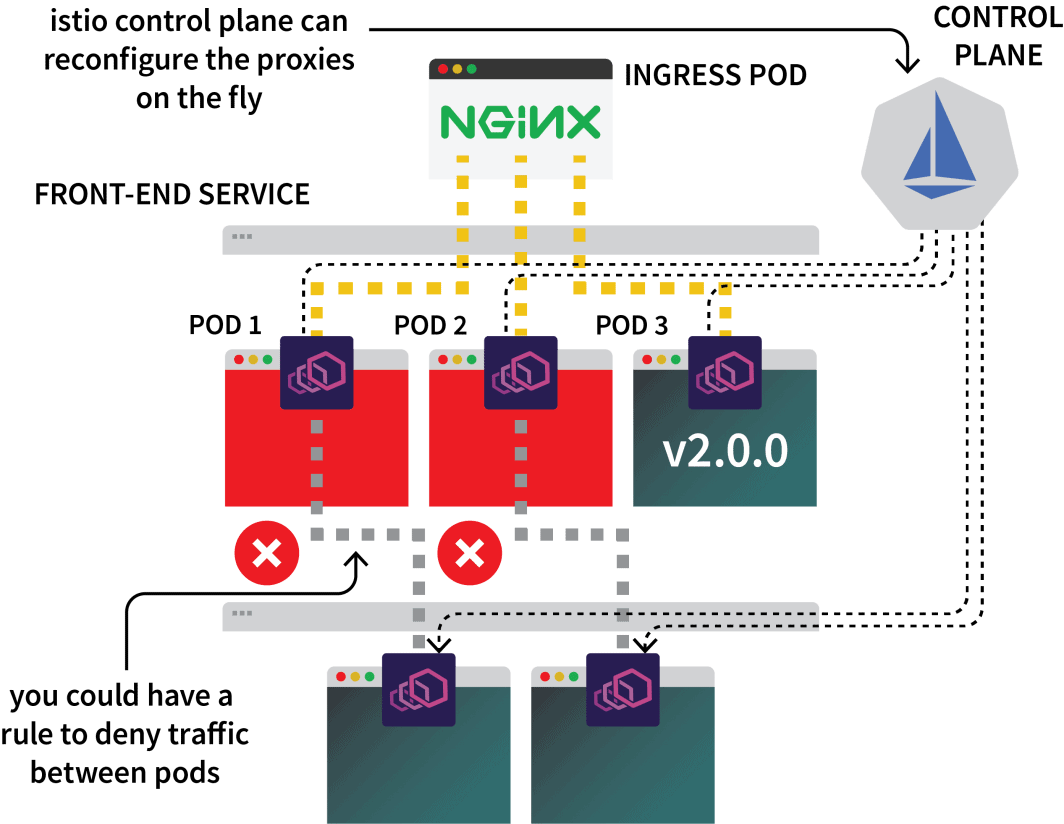
Vous pourriez donc utiliser Istio pour intercepter tout le trafic vers un service particulier et le diriger vers l'un des trois clusters. C'est l'idée de la configuration multicluster d'Istio.
Assez de théorie, passons aux choses sérieuses. La première étape consiste à installer Istio dans les trois clusters.
Bien qu'il existe plusieurs façons d'installer Istio, je préfère généralement Helm :
bash
$ helm repo add istio https://istio-release.storage.googleapis.com/charts
$ helm repo list
NAME URL
istio https://istio-release.storage.googleapis.com/chartsVous pouvez installer Istio dans les trois clusters avec :
bash
$ helm install istio-base istio/base \
--kubeconfig=kubeconfig-<insert-cluster-name> \
--create-namespace --namespace istio-system \
--version=1.14.1Vous devez remplacer le cluster-name avec ap, eu et us et exécutez la commande pour chacun d'eux.
Le tableau de base installe principalement des ressources communes, telles que les rôles et les RoleBindings.
L'installation proprement dite est emballée dans le istiod graphique. Mais avant de procéder à cela, vous devez configurer l'autorité de certification Istio (CA) pour s'assurer que les trois clusters peuvent se connecter et se faire confiance.
Dans un nouveau répertoire, clonez le dépôt d'Istio avec :
bash
$ git clone https://github.com/istio/istioCréer un certs et changez dans ce répertoire :
bash
$ mkdir certs
$ cd certsCréez le certificat racine avec :
bash
$ make -f ../istio/tools/certs/Makefile.selfsigned.mk root-caLa commande a généré les fichiers suivants :
root-cert.pemle certificat racine généréroot-key.pem: la clé racine généréeroot-ca.conf: la configuration pour OpenSSL pour générer le certificat racineroot-cert.csr: le CSR généré pour le certificat racine
Pour chaque cluster, générez un certificat et une clé intermédiaires pour l'autorité de certification Istio :
bash
$ make -f ../istio/tools/certs/Makefile.selfsigned.mk cluster1-cacerts
$ make -f ../istio/tools/certs/Makefile.selfsigned.mk cluster2-cacerts
$ make -f ../istio/tools/certs/Makefile.selfsigned.mk cluster3-cacertsLes commandes vont générer les fichiers suivants dans un répertoire nommé cluster1, cluster2et cluster3:
bash
$ kubectl create secret generic cacerts -n istio-system \
--kubeconfig=kubeconfig-<cluster-name>
--from-file=<cluster-folder>/ca-cert.pem \
--from-file=<cluster-folder>/ca-key.pem \
--from-file=<cluster-folder>/root-cert.pem \
--from-file=<cluster-folder>/cert-chain.pemVous devez exécuter les commandes avec les variables suivantes :
| cluster name | folder name |
| :----------: | :---------: |
| ap | cluster1 |
| us | cluster2 |
| eu | cluster3 |Une fois ces opérations effectuées, vous êtes enfin prêt à installer istiod :
bash
$ helm install istiod istio/istiod \
--kubeconfig=kubeconfig-<insert-cluster-name> \
--namespace istio-system \
--version=1.14.1 \
--set global.meshID=mesh1 \
--set global.multiCluster.clusterName=<insert-cluster-name> \
--set global.network=<insert-network-name>Vous devez répéter la commande trois fois avec les variables suivantes :
| cluster name | network name |
| :----------: | :----------: |
| ap | network1 |
| us | network2 |
| eu | network3 |Vous devez également étiqueter l'espace de noms Istio avec une annotation de topologie :
bash
$ kubectl label namespace istio-system topology.istio.io/network=network1 --kubeconfig=kubeconfig-ap
$ kubectl label namespace istio-system topology.istio.io/network=network2 --kubeconfig=kubeconfig-us
$ kubectl label namespace istio-system topology.istio.io/network=network3 --kubeconfig=kubeconfig-euC'est tout ?
Presque.
Tunnelisation du trafic avec une passerelle est-ouest
Vous en avez toujours besoin :
- une passerelle pour canaliser le trafic d'un cluster à l'autre ; et
- un mécanisme pour découvrir les adresses IP dans d'autres clusters.
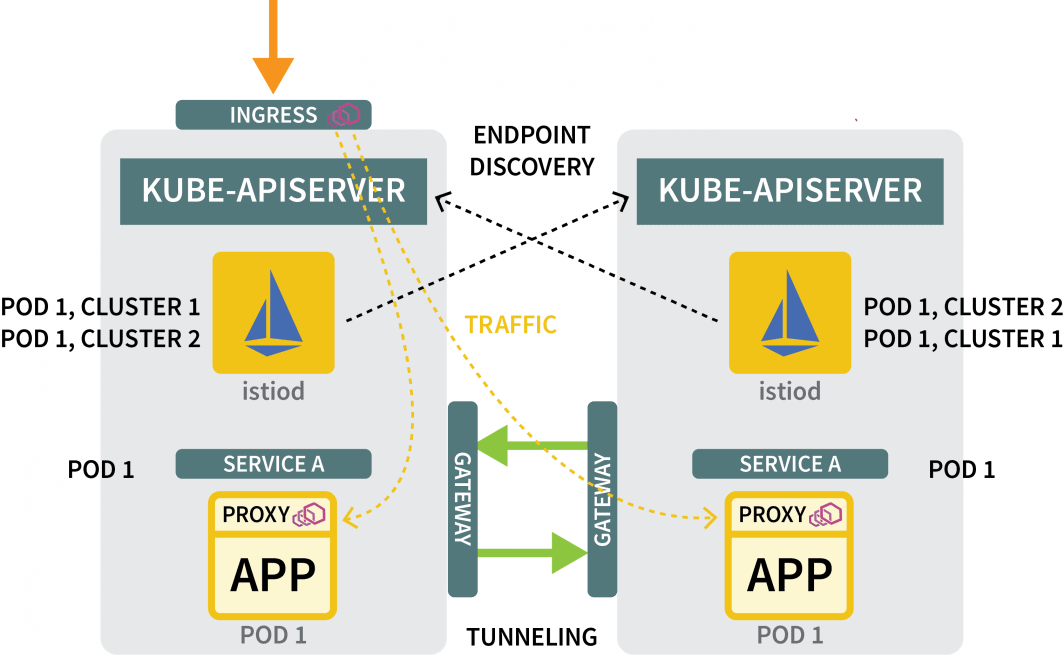
Pour la passerelle, vous pouvez utiliser Helm pour l'installer :
bash
$ helm install eastwest-gateway istio/gateway \
--kubeconfig=kubeconfig-<insert-cluster-name> \
--namespace istio-system \
--version=1.14.1 \
--set labels.istio=eastwestgateway \
--set labels.app=istio-eastwestgateway \
--set labels.topology.istio.io/network=istio-eastwestgateway \
--set labels.topology.istio.io/network=istio-eastwestgateway \
--set networkGateway=<insert-network-name> \
--set service.ports[0].name=status-port \
--set service.ports[0].port=15021 \
--set service.ports[0].targetPort=15021 \
--set service.ports[1].name=tls \
--set service.ports[1].port=15443 \
--set service.ports[1].targetPort=15443 \
--set service.ports[2].name=tls-istiod \
--set service.ports[2].port=15012 \
--set service.ports[2].targetPort=15012 \
--set service.ports[3].name=tls-webhook \
--set service.ports[3].port=15017 \
--set service.ports[3].targetPort=15017 \Vous devez répéter la commande trois fois avec les variables suivantes :
| cluster name | network name |
| :----------: | :----------: |
| ap | network1 |
| us | network2 |
| eu | network3 |Ensuite, pour chaque cluster, exposez une passerelle avec la ressource suivante :
yaml
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: cross-network-gateway
spec:
selector:
istio: eastwestgateway
servers:
- port:
number: 15443
name: tls
protocol: TLS
tls:
mode: AUTO_PASSTHROUGH
hosts:
- "*.local"Vous pouvez soumettre le fichier aux clusters avec :
bash
$ kubectl apply -f expose.yaml --kubeconfig=kubeconfig-eu
$ kubectl apply -f expose.yaml --kubeconfig=kubeconfig-ap
$ kubectl apply -f expose.yaml --kubeconfig=kubeconfig-usPour les mécanismes de découverte, vous devez partager les informations d'identification de chaque cluster. Ceci est nécessaire car les clusters ne sont pas conscients les uns des autres.
Pour découvrir d'autres adresses IP, ils doivent accéder à d'autres clusters et les enregistrer comme destinations possibles du trafic. Pour ce faire, vous devez créer un secret Kubernetes avec le fichier kubeconfig pour les autres clusters.
Istio les utilisera pour se connecter aux autres clusters, découvrir les points de terminaison et demander aux proxies Envoy de transférer le trafic.
Vous aurez besoin de trois secrets :
yaml
apiVersion: v1
kind: Secret
metadata:
labels:
istio/multiCluster: true
annotations:
networking.istio.io/cluster: <insert cluster name>
name: "istio-remote-secret-<insert cluster name>"
type: Opaque
data:
<insert cluster name>: <insert cluster kubeconfig as base64>Vous devez créer les trois secrets avec les variables suivantes :
| cluster name | secret filename | kubeconfig |
| :----------: | :-------------: | :-----------: |
| ap | secret1.yaml | kubeconfig-ap |
| us | secret2.yaml | kubeconfig-us |
| eu | secret3.yaml | kubeconfig-eu |Maintenant vous devez soumettre les secrets au cluster en faisant attention à ne pas soumettre le secret AP au cluster AP.
Les commandes doivent être les suivantes :
bash
$ kubectl apply -f secret2.yaml -n istio-system --kubeconfig=kubeconfig-ap
$ kubectl apply -f secret3.yaml -n istio-system --kubeconfig=kubeconfig-ap
$ kubectl apply -f secret1.yaml -n istio-system --kubeconfig=kubeconfig-us
$ kubectl apply -f secret3.yaml -n istio-system --kubeconfig=kubeconfig-us
$ kubectl apply -f secret1.yaml -n istio-system --kubeconfig=kubeconfig-eu
$ kubectl apply -f secret2.yaml -n istio-system --kubeconfig=kubeconfig-euEt c'est tout !
Vous êtes prêt à tester la configuration.
Test de la mise en réseau multicluster
Créons un déploiement pour un pod de sommeil.
Vous utiliserez ce pod pour faire une demande au déploiement Hello que vous avez créé précédemment :
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: sleep
spec:
selector:
matchLabels:
app: sleep
template:
metadata:
labels:
app: sleep
spec:
terminationGracePeriodSeconds: 0
containers:
- name: sleep
image: curlimages/curl
command: ["/bin/sleep", "3650d"]
imagePullPolicy: IfNotPresent
volumeMounts:
- mountPath: /etc/sleep/tls
name: secret-volume
volumes:
- name: secret-volume
secret:
secretName: sleep-secret
optional: trueVous pouvez créer le déploiement avec :
bash
$ kubectl apply -f sleep.yaml --kubeconfig=karmada-configComme il n'y a pas de politique pour ce déploiement, Karmada ne le traitera pas et le laissera en attente. Vous pouvez modifier la politique pour inclure le déploiement avec :
yaml
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: hello-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: hello
- apiVersion: v1
kind: Service
name: hello
- apiVersion: apps/v1
kind: Deployment
name: sleep
placement:
clusterAffinity:
clusterNames:
- eu
- ap
- us
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- us
weight: 2
- targetCluster:
clusterNames:
- ap
weight: 2
- targetCluster:
clusterNames:
- eu
weight: 1Vous pouvez appliquer la politique avec :
bash
$ kubectl apply -f policy.yaml --kubeconfig=karmada-configVous pouvez déterminer l'endroit où le pod a été déployé avec :
bash
$ kubectl get pods --kubeconfig=kubeconfig-eu
$ kubectl get pods --kubeconfig=kubeconfig-ap
$ kubectl get pods --kubeconfig=kubeconfig-usMaintenant, en supposant que le pod a atterri sur le cluster US, exécutez la commande suivante :
Now, assuming the pod landed on the US cluster, execute the following command:
bash
for i in {1..10}
do
kubectl exec --kubeconfig=kubeconfig-us -c sleep \
"$(kubectl get pod --kubeconfig=kubeconfig-us -l \
app=sleep -o jsonpath='{.items[0].metadata.name}')" \
-- curl -sS hello:5000 | grep REGION
doneVous remarquerez peut-être que la réponse provient de différentes gousses provenant de différentes régions !
C'est fait !
Où aller à partir de maintenant ?
Cette configuration est assez basique et manque de plusieurs fonctionnalités supplémentaires que vous souhaitez probablement intégrer :
- vous pourriez exposer une entrée Istio à partir de chaque cluster pour ingérer le trafic ;
- vous pourriez utiliser Istio pour façonner le trafic de manière à privilégier le trafic local ; et
- vous pouvez utiliser les règles d'application de la politique d'Istio pour définir comment le trafic peut circuler entre les clusters.
Pour récapituler ce que nous avons couvert dans ce post :
- en utilisant Karmada pour contrôler plusieurs clusters ;
- définir une politique pour planifier les charges de travail sur plusieurs clusters ;
- l'utilisation d'Istio pour établir un pont entre les réseaux de plusieurs grappes ; et
- comment Istio intercepte le trafic et le transmet à d'autres clusters.
Vous pouvez assister à une présentation complète de la mise à l'échelle de Kubernetes dans plusieurs régions, ainsi que d'autres méthodologies de mise à l'échelle, en vous inscrivant à notre série de webinaires et en les regardant à la demande.




Commentaires