

这篇文章是我们扩展Kubernetes系列的一部分。 注册来观看直播或访问录音,并查看我们在这个系列中的其他文章:
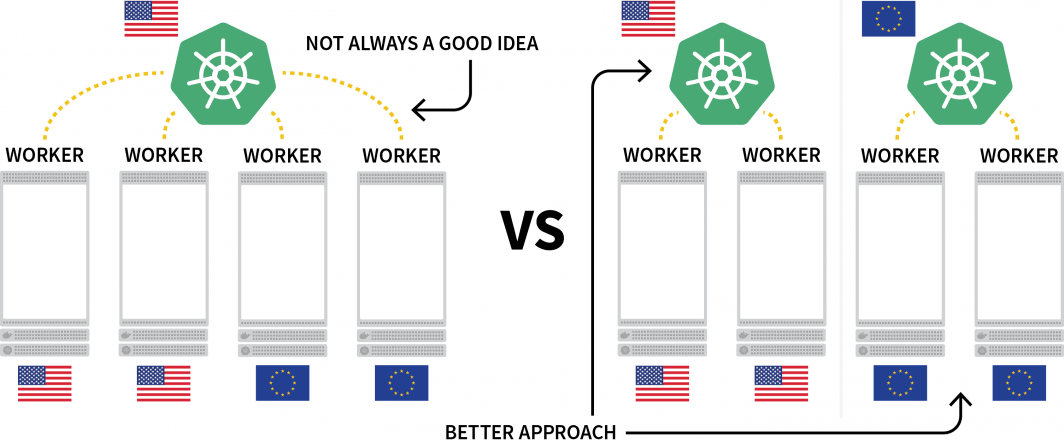
Kubernetes的一个有趣的挑战是在多个地区部署工作负载。虽然从技术上讲,你可以拥有一个由位于不同地区的几个节点组成的集群,但由于存在额外的延迟,这通常被认为是你应该避免的事情。
一个流行的替代方案是为每个区域部署一个集群,并找到一种协调它们的方法。
在这个帖子中,你将:
- 创建三个集群:一个在北美,一个在欧洲,一个在东南亚。
- 创建第四个集群,它将作为其他集群的协调者。
- 在三个集群网络中建立一个单一的网络,以实现无缝通信。
这个帖子已经被编成了脚本,可以与Terraform ,需要最小的互动。你可以在LearnK8s的GitHub上找到相关的代码。
创建群集管理器
让我们从创建将管理其余部分的集群开始。下面的命令可以用来创建集群并保存kubeconfig文件。
bash
$ linode-cli lke cluster-create \
--label cluster-manager \
--region eu-west \
--k8s_version 1.23
$ linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfig-cluster-manager你可以用以下方法验证安装是否成功。
bash
$ kubectl get pods -A --kubeconfig=kubeconfig-cluster-manager优秀的!
在集群管理器中,你将安装Karmada,一个管理系统,使你能够在多个Kubernetes集群和云中运行你的云原生应用程序。Karmada有一个安装在集群管理器中的控制平面和安装在每个其他集群中的代理。
控制平面有三个组成部分:
- 一个 API 服务器;
- 一名主计长;以及
- 一个调度员
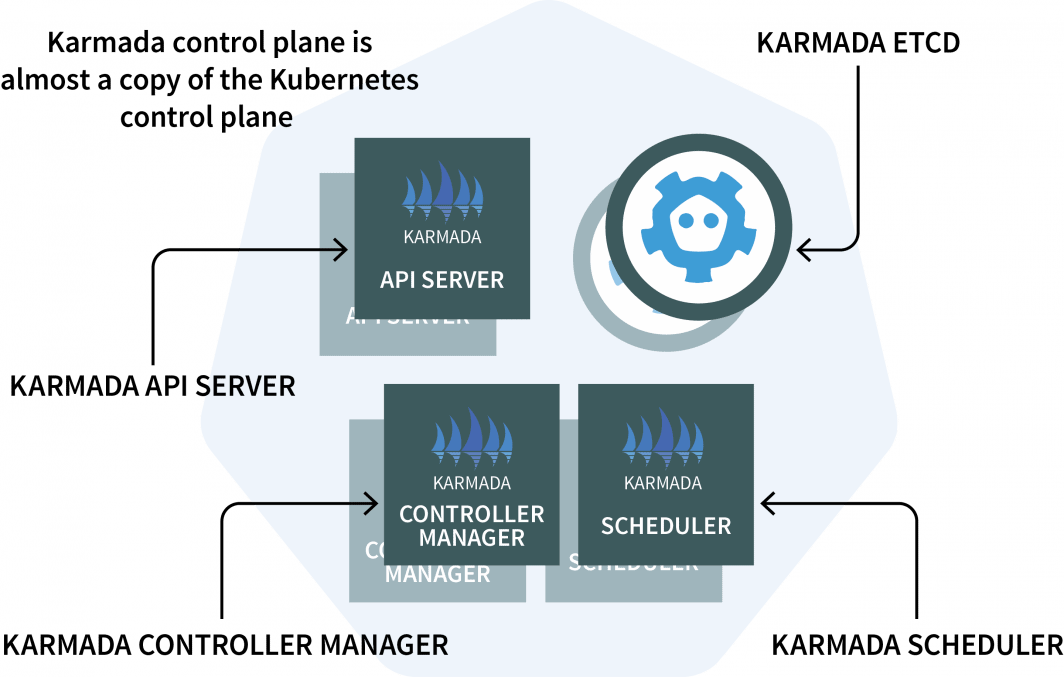
如果这些看起来很熟悉,那是因为Kubernetes控制平面具有相同的组件Karmada不得不复制和增强它们,以便与多个集群一起工作。
理论够了。
您将使用Helm安装 Karmada API 服务器。让我们添加 Helm 软件源:
bash
$ helm repo add karmada-charts https://raw.githubusercontent.com/karmada-io/karmada/master/charts
$ helm repo list
NAME URL
karmada-charts https://raw.githubusercontent.com/karmada-io/karmada/master/charts由于 Karmada API 服务器必须能够被所有其他集群访问,因此您必须
- 将其从节点中暴露出来;以及
- 确保连接是可信的。
因此,让我们用以下方式检索托管控制平面的节点的IP地址:
bash
kubectl get nodes -o jsonpath='{.items[0].status.addresses[?(@.type==\"ExternalIP\")].address}' \
--kubeconfig=kubeconfig-cluster-manager现在,你可以安装Karmada控制平面与:
bash
$ helm install karmada karmada-charts/karmada \
--kubeconfig=kubeconfig-cluster-manager \
--create-namespace --namespace karmada-system \
--version=1.2.0 \
--set apiServer.hostNetwork=false \
--set apiServer.serviceType=NodePort \
--set apiServer.nodePort=32443 \
--set certs.auto.hosts[0]="kubernetes.default.svc" \
--set certs.auto.hosts[1]="*.etcd.karmada-system.svc.cluster.local" \
--set certs.auto.hosts[2]="*.karmada-system.svc.cluster.local" \
--set certs.auto.hosts[3]="*.karmada-system.svc" \
--set certs.auto.hosts[4]="localhost" \
--set certs.auto.hosts[5]="127.0.0.1" \
--set certs.auto.hosts[6]="<insert the IP address of the node>"安装完成后,您可以检索 kubeconfig 以连接到 Karmada API 连接:
bash
kubectl get secret karmada-kubeconfig \
--kubeconfig=kubeconfig-cluster-manager \
-n karmada-system \
-o jsonpath={.data.kubeconfig} | base64 -d > karmada-config但等等,为什么又是一个kubeconfig文件?
Karmada API 旨在取代标准的 Kubernetes API 但仍保留了您习惯的所有功能。换句话说,你可以用 kubectl 创建跨越多个集群的部署。
在测试 Karmada API 和 kubectl 之前,应先修补 kubeconfig 文件。默认情况下,生成的 kubeconfig 只能在集群网络内使用。
然而,你可以替换下面这一行,使其发挥作用:
yaml
apiVersion: v1
kind: Config
clusters:
- cluster:
certificate-authority-data: LS0tLS1CRUdJTi…
insecure-skip-tls-verify: false
server: https://karmada-apiserver.karmada-system.svc.cluster.local:5443 # <- this works only in the cluster
name: karmada-apiserver
# truncated用你之前检索到的节点的IP地址替换它:
yaml
apiVersion: v1
kind: Config
clusters:
- cluster:
certificate-authority-data: LS0tLS1CRUdJTi…
insecure-skip-tls-verify: false
server: https://<node's IP address>:32443 # <- this works from the public internet
name: karmada-apiserver
# truncated很好,现在是测试卡尔马达的时候了。
安装Karmada代理
发布以下命令来检索所有的部署和所有的集群:
bash
$ kubectl get clusters,deployments --kubeconfig=karmada-config
No resources found不出所料,没有部署,也没有额外的群集。让我们再增加几个集群,并将它们连接到Karmada控制平面。
重复以下命令三次:
bash
linode-cli lke cluster-create \
--label <insert-cluster-name> \
--region <insert-region> \
--k8s_version 1.23
linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfig-<insert-cluster-name>这些值应该是以下内容:
- 集群名称
eu, 地区eu-west和kubeconfig文件kubeconfig-eu - 集群名称
ap, 地区ap-south和kubeconfig文件kubeconfig-ap - 集群名称
us, 地区us-west和kubeconfig文件kubeconfig-us
你可以通过以下方式验证集群的创建是否成功:
bash
$ kubectl get pods -A --kubeconfig=kubeconfig-eu
$ kubectl get pods -A --kubeconfig=kubeconfig-ap
$ kubectl get pods -A --kubeconfig=kubeconfig-us现在是时候让他们加入卡尔马达集群了。
Karmada在每个其他集群上使用一个代理来协调与控制平面的部署。
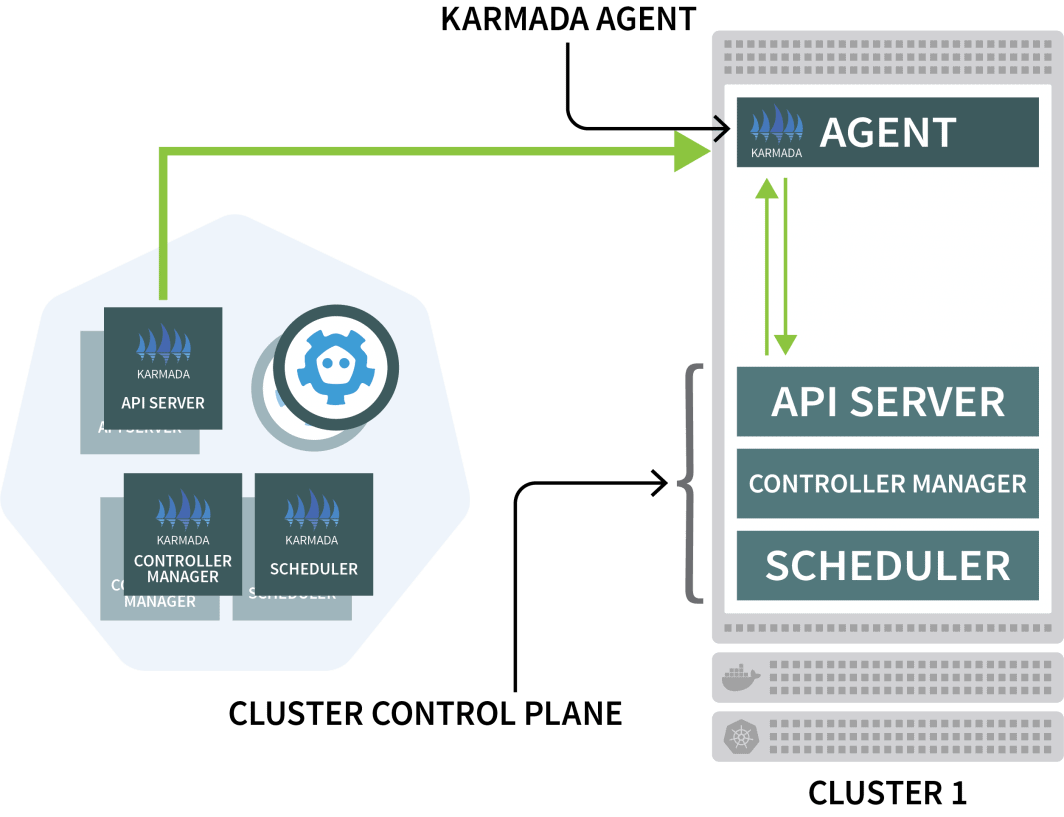
你将使用Helm来安装Karmada代理,并将其链接到集群管理器:
bash
$ helm install karmada karmada-charts/karmada \
--kubeconfig=kubeconfig-<insert-cluster-name> \
--create-namespace --namespace karmada-system \
--version=1.2.0 \
--set installMode=agent \
--set agent.clusterName=<insert-cluster-name> \
--set agent.kubeconfig.caCrt=<karmada kubeconfig certificate authority> \
--set agent.kubeconfig.crt=<karmada kubeconfig client certificate data> \
--set agent.kubeconfig.key=<karmada kubeconfig client key data> \
--set agent.kubeconfig.server=https://<insert node's IP address>:32443 \你将不得不重复上述命令三次,并插入以下变量:
- 集群名称。这个名称是
eu,ap,或us - 集群管理员的证书授权。你可以在下面的表格中找到这个值
karmada-config文件under clusters[0].cluster['certificate-authority-data'].
你可以从以下方面对数值进行解码 base64. - 该用户的客户证书数据。你可以在以下文件中找到这个值
karmada-config档案在users[0].user['client-certificate-data'].
你可以从base64解码该值。 - 该用户的客户证书数据。你可以在以下文件中找到这个值
karmada-config档案在users[0].user['client-key-data'].
你可以从base64解码该值。 - 托管Karmada控制平面的节点的IP地址。
为了验证安装是否完成,你可以发出以下命令:
bash
$ kubectl get clusters --kubeconfig=karmada-config
NAME VERSION MODE READY
eu v1.23.8 Pull True
ap v1.23.8 Pull True
us v1.23.8 Pull True优秀的!
用Karmada策略协调多集群部署
在目前的配置下,你提交一个工作负载给Karmada,然后它将在其他集群中分发。
让我们通过创建一个部署来测试这一点:
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello
spec:
replicas: 3
selector:
matchLabels:
app: hello
template:
metadata:
labels:
app: hello
spec:
containers:
- image: stefanprodan/podinfo
name: hello
---
apiVersion: v1
kind: Service
metadata:
name: hello
spec:
ports:
- port: 5000
targetPort: 9898
selector:
app: hello您可以将部署提交到 Karmada API 服务器:
bash
$ kubectl apply -f deployment.yaml --kubeconfig=karmada-config这个部署有三个副本--这些副本会平均分配到三个集群上吗?
让我们检查一下:
bash
$ kubectl get deployments --kubeconfig=karmada-config
NAME READY UP-TO-DATE AVAILABLE
hello 0/3 0 0为什么卡玛达不创造花苞?
让我们描述一下部署的情况:
bash
$ kubectl describe deployment hello --kubeconfig=karmada-config
Name: hello
Namespace: default
Selector: app=hello
Replicas: 3 desired | 0 updated | 0 total | 0 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Events:
Type Reason From Message
---- ------ ---- -------
Warning ApplyPolicyFailed resource-detector No policy match for resourceKarmada不知道该如何处理这些部署,因为你没有指定一个策略。
Karmada调度器使用策略将工作负载分配给集群。
让我们定义一个简单的策略,为每个集群分配一个副本:
yaml
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: hello-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: hello
- apiVersion: v1
kind: Service
name: hello
placement:
clusterAffinity:
clusterNames:
- eu
- ap
- us
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- us
weight: 1
- targetCluster:
clusterNames:
- ap
weight: 1
- targetCluster:
clusterNames:
- eu
weight: 1你可以通过以下方式向集群提交政策:
bash
$ kubectl apply -f policy.yaml --kubeconfig=karmada-config让我们检查一下部署和豆荚:
bash
$ kubectl get deployments --kubeconfig=karmada-config
NAME READY UP-TO-DATE AVAILABLE
hello 3/3 3 3
$ kubectl get pods --kubeconfig=kubeconfig-eu
NAME READY STATUS RESTARTS
hello-5d857996f-hjfqq 1/1 Running 0
$ kubectl get pods --kubeconfig=kubeconfig-ap
NAME READY STATUS RESTARTS
hello-5d857996f-xr6hr 1/1 Running 0
$ kubectl get pods --kubeconfig=kubeconfig-us
NAME READY STATUS RESTARTS
hello-5d857996f-nbz48 1/1 Running 0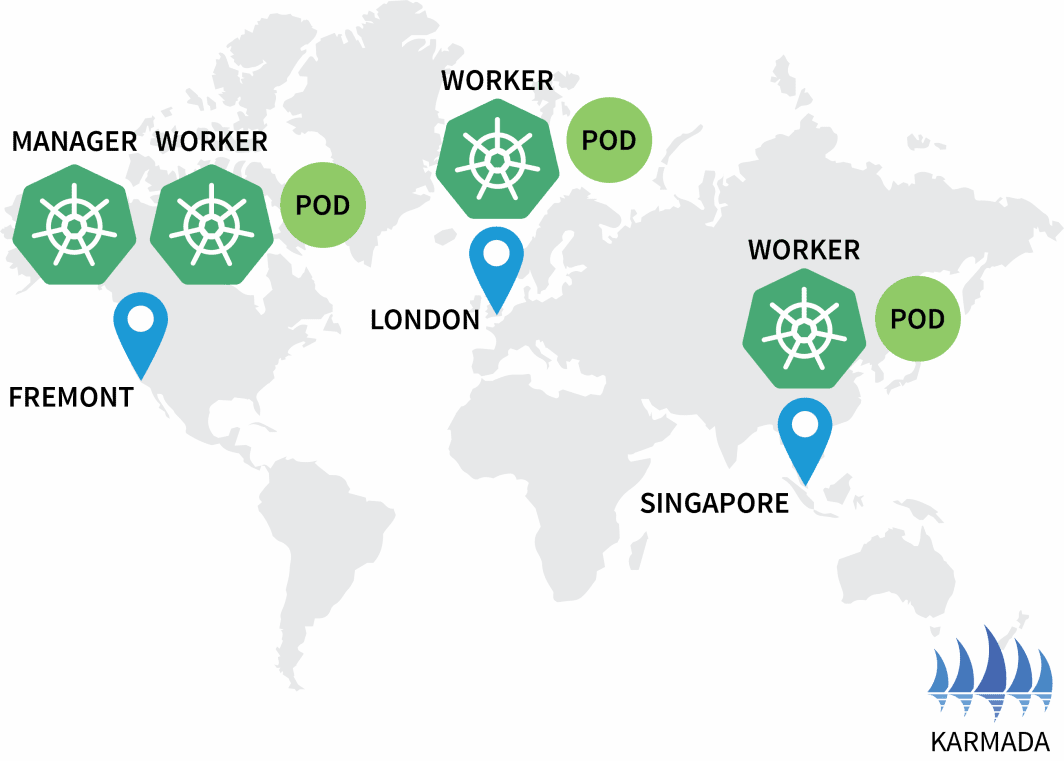
Karmada为每个集群分配了一个pod,因为你的策略为每个集群定义了相等的权重。
让我们用以下方法将部署扩大到10个副本:
bash
$ kubectl scale deployment/hello --replicas=10 --kubeconfig=karmada-config如果你检查豆荚,你可能会发现以下情况:
bash
$ kubectl get deployments --kubeconfig=karmada-config
NAME READY UP-TO-DATE AVAILABLE
hello 10/10 10 10
$ kubectl get pods --kubeconfig=kubeconfig-eu
NAME READY STATUS RESTARTS
hello-5d857996f-dzfzm 1/1 Running 0
hello-5d857996f-hjfqq 1/1 Running 0
hello-5d857996f-kw2rt 1/1 Running 0
hello-5d857996f-nz7qz 1/1 Running 0
$ kubectl get pods --kubeconfig=kubeconfig-ap
NAME READY STATUS RESTARTS
hello-5d857996f-pd9t6 1/1 Running 0
hello-5d857996f-r7bmp 1/1 Running 0
hello-5d857996f-xr6hr 1/1 Running 0
$ kubectl get pods --kubeconfig=kubeconfig-us
NAME READY STATUS RESTARTS
hello-5d857996f-nbz48 1/1 Running 0
hello-5d857996f-nzgpn 1/1 Running 0
hello-5d857996f-rsp7k 1/1 Running 0让我们修改政策,使欧盟和美国集群持有40%的豆荚,只留20%给亚太集群。
yaml
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: hello-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: hello
- apiVersion: v1
kind: Service
name: hello
placement:
clusterAffinity:
clusterNames:
- eu
- ap
- us
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- us
weight: 2
- targetCluster:
clusterNames:
- ap
weight: 1
- targetCluster:
clusterNames:
- eu
weight: 2你可以提交保单与:
bash
$ kubectl apply -f policy.yaml --kubeconfig=karmada-config你可以观察到你的豆荚分布发生了相应的变化:
bash
$ kubectl get pods --kubeconfig=kubeconfig-eu
NAME READY STATUS RESTARTS AGE
hello-5d857996f-hjfqq 1/1 Running 0 6m5s
hello-5d857996f-kw2rt 1/1 Running 0 2m27s
$ kubectl get pods --kubeconfig=kubeconfig-ap
hello-5d857996f-k9hsm 1/1 Running 0 51s
hello-5d857996f-pd9t6 1/1 Running 0 2m41s
hello-5d857996f-r7bmp 1/1 Running 0 2m41s
hello-5d857996f-xr6hr 1/1 Running 0 6m19s
$ kubectl get pods --kubeconfig=kubeconfig-us
hello-5d857996f-nbz48 1/1 Running 0 6m29s
hello-5d857996f-nzgpn 1/1 Running 0 2m51s
hello-5d857996f-rgj9t 1/1 Running 0 61s
hello-5d857996f-rsp7k 1/1 Running 0 2m51s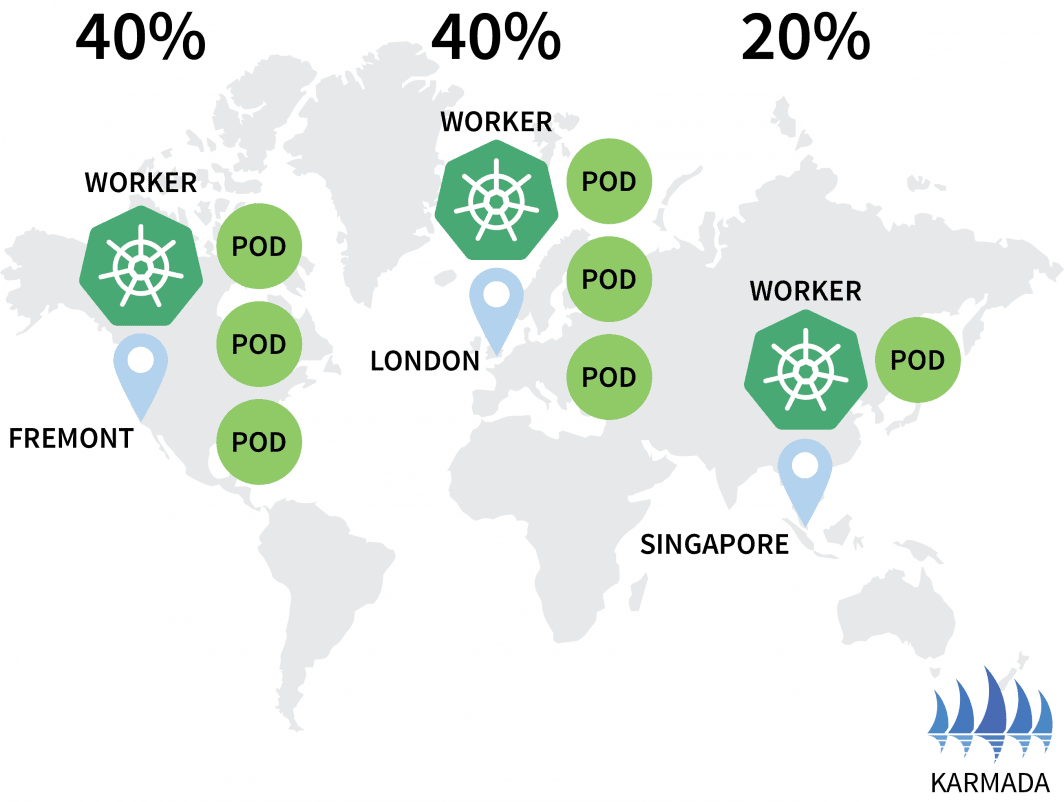
很好!
Karmada支持几种策略来分配你的工作负载。你可以查看文档,了解更多高级用例。
吊舱在三个集群中运行,但你如何访问它们?
让我们检查一下卡尔马达的服务:
bash
$ kubectl describe service hello --kubeconfig=karmada-config
Name: hello
Namespace: default
Labels: propagationpolicy.karmada.io/name=hello-propagation
propagationpolicy.karmada.io/namespace=default
Selector: app=hello
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.105.24.193
IPs: 10.105.24.193
Port: <unset> 5000/TCP
TargetPort: 9898/TCP
Events:
Type Reason Message
---- ------ -------
Normal SyncSucceed Successfully applied resource(default/hello) to cluster ap
Normal SyncSucceed Successfully applied resource(default/hello) to cluster us
Normal SyncSucceed Successfully applied resource(default/hello) to cluster eu
Normal AggregateStatusSucceed Update resourceBinding(default/hello-service) with AggregatedStatus successfully.
Normal ScheduleBindingSucceed Binding has been scheduled
Normal SyncWorkSucceed Sync work of resourceBinding(default/hello-service) successful.该服务被部署在所有三个集群中,但它们并没有连接起来。
即使Karmada可以管理几个集群,它也没有提供任何网络机制 来确保这三个集群的联系。换句话说,Karmada是一个协调跨集群部署的优秀工具,但你需要其他东西来确保这些集群可以相互通信。
用Istio连接多集群
Istio通常用于控制同一集群中的应用程序之间的网络流量。它的工作原理是拦截所有传出和传入的请求,并通过Envoy代理它们。
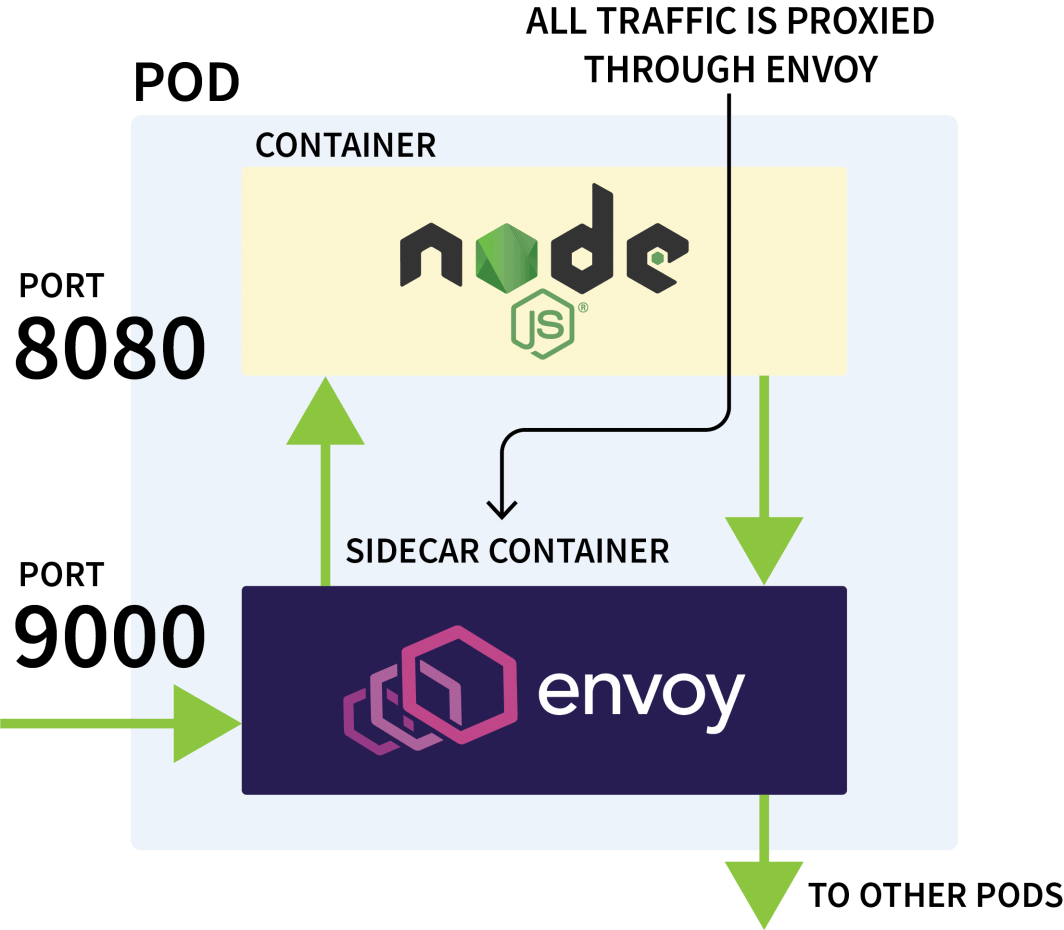
Istio控制平面负责更新和收集这些代理的指标,也可以发出指令来转移流量。
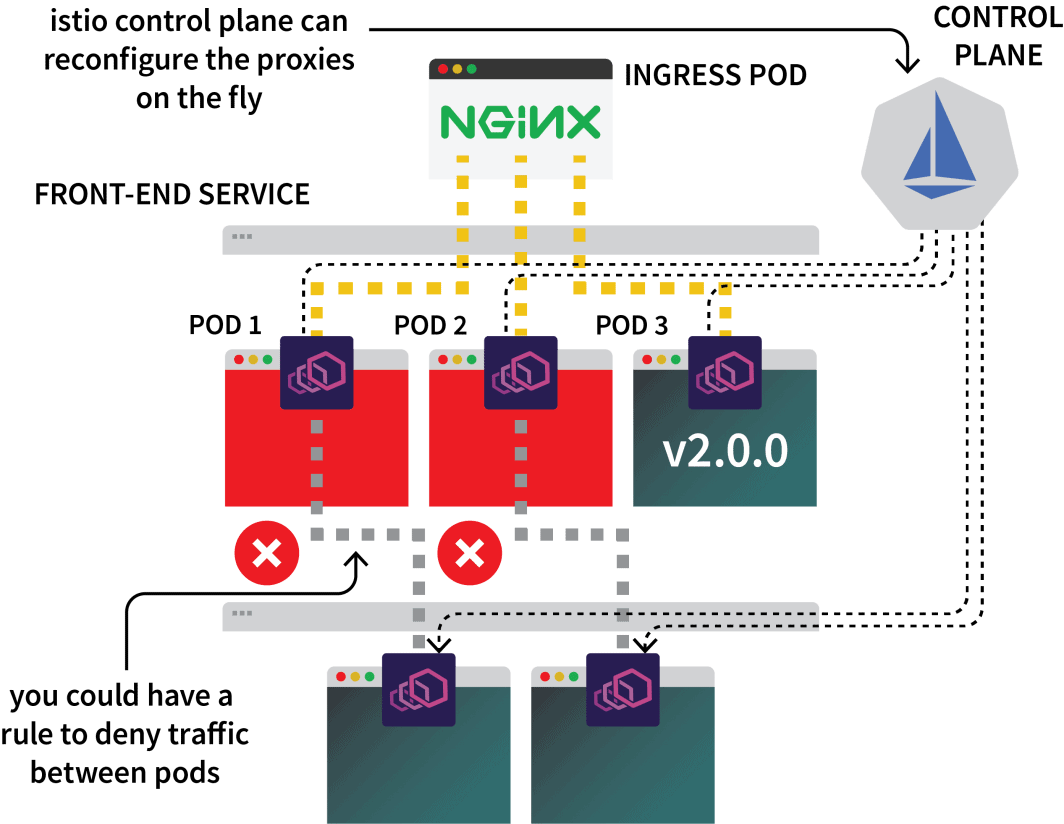
因此,你可以使用Istio拦截所有的流量到一个特定的服务,并将其引导到三个集群中的一个。这就是Istio多集群设置的想法。
理论够了,让我们动手吧。第一步是在三个集群中安装Istio。
虽然有几种方法来安装Istio,但我通常更喜欢Helm:
bash
$ helm repo add istio https://istio-release.storage.googleapis.com/charts
$ helm repo list
NAME URL
istio https://istio-release.storage.googleapis.com/charts你可以在三个集群中安装Istio,用:
bash
$ helm install istio-base istio/base \
--kubeconfig=kubeconfig-<insert-cluster-name> \
--create-namespace --namespace istio-system \
--version=1.14.1你应该更换 cluster-name 与 ap, eu 和 us 并为每个人执行命令。
基准图安装的主要是普通资源,如角色和角色绑定。
实际的安装被打包在 istiod 图。但在你进行这项工作之前,你必须 配置Istio证书授权(CA)。 以确保这三个集群能够相互连接和信任。
在一个新的目录中,用以下方式克隆Istio资源库:
bash
$ git clone https://github.com/istio/istio创建一个 certs 文件夹,并改变到该目录:
bash
$ mkdir certs
$ cd certs用以下方式创建根证书:
bash
$ make -f ../istio/tools/certs/Makefile.selfsigned.mk root-ca该命令生成了以下文件:
root-cert.pem: 生成的根证书root-key.pem: 生成的根密钥root-ca.conf:为OpenSSL生成根证书而进行的配置root-cert.csr:为根证书生成的CSR
对于每个集群,为Istio证书授权生成一个中间证书和密钥:
bash
$ make -f ../istio/tools/certs/Makefile.selfsigned.mk cluster1-cacerts
$ make -f ../istio/tools/certs/Makefile.selfsigned.mk cluster2-cacerts
$ make -f ../istio/tools/certs/Makefile.selfsigned.mk cluster3-cacerts这些命令将生成以下文件,放在一个名为 cluster1, cluster2,以及 cluster3:
bash
$ kubectl create secret generic cacerts -n istio-system \
--kubeconfig=kubeconfig-<cluster-name>
--from-file=<cluster-folder>/ca-cert.pem \
--from-file=<cluster-folder>/ca-key.pem \
--from-file=<cluster-folder>/root-cert.pem \
--from-file=<cluster-folder>/cert-chain.pem你应该用以下变量执行命令:
| cluster name | folder name |
| :----------: | :---------: |
| ap | cluster1 |
| us | cluster2 |
| eu | cluster3 |完成这些后,你终于准备好安装istiod了:
bash
$ helm install istiod istio/istiod \
--kubeconfig=kubeconfig-<insert-cluster-name> \
--namespace istio-system \
--version=1.14.1 \
--set global.meshID=mesh1 \
--set global.multiCluster.clusterName=<insert-cluster-name> \
--set global.network=<insert-network-name>你应该用以下变量重复该命令三次:
| cluster name | network name |
| :----------: | :----------: |
| ap | network1 |
| us | network2 |
| eu | network3 |你还应该用拓扑注释来标记Istio命名空间:
bash
$ kubectl label namespace istio-system topology.istio.io/network=network1 --kubeconfig=kubeconfig-ap
$ kubectl label namespace istio-system topology.istio.io/network=network2 --kubeconfig=kubeconfig-us
$ kubectl label namespace istio-system topology.istio.io/network=network3 --kubeconfig=kubeconfig-eu就这些吗?
几乎。
使用东西方网关进行隧道流量
你仍然需要:
- 一个网关,将流量从一个集群输送到另一个集群;以及
- 一个发现其他集群的IP地址的机制。
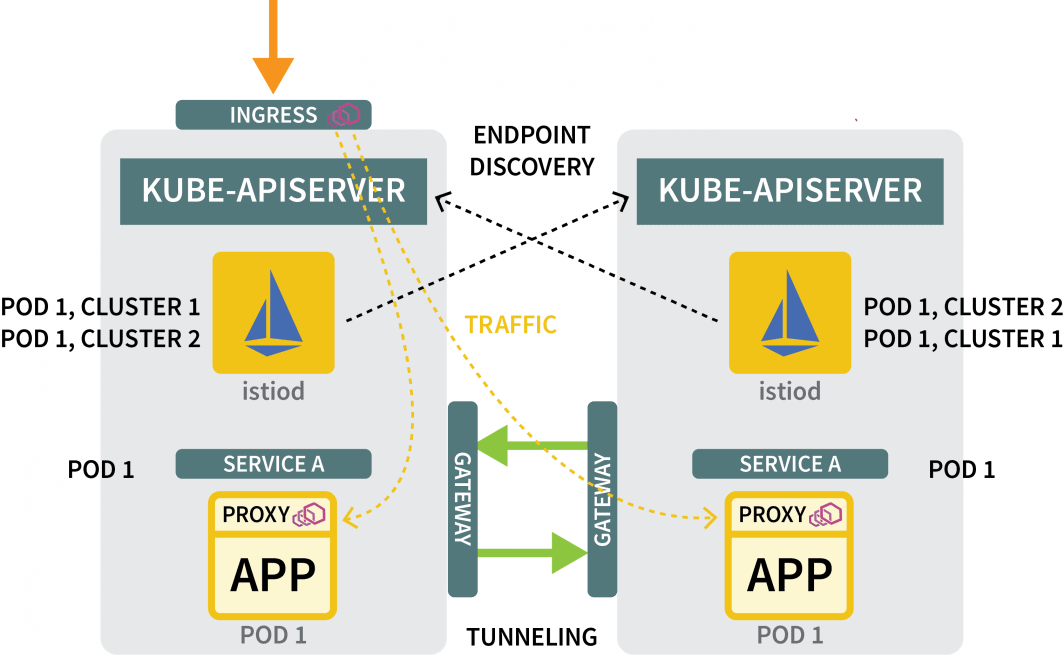
对于网关,你可以用Helm来安装它:
bash
$ helm install eastwest-gateway istio/gateway \
--kubeconfig=kubeconfig-<insert-cluster-name> \
--namespace istio-system \
--version=1.14.1 \
--set labels.istio=eastwestgateway \
--set labels.app=istio-eastwestgateway \
--set labels.topology.istio.io/network=istio-eastwestgateway \
--set labels.topology.istio.io/network=istio-eastwestgateway \
--set networkGateway=<insert-network-name> \
--set service.ports[0].name=status-port \
--set service.ports[0].port=15021 \
--set service.ports[0].targetPort=15021 \
--set service.ports[1].name=tls \
--set service.ports[1].port=15443 \
--set service.ports[1].targetPort=15443 \
--set service.ports[2].name=tls-istiod \
--set service.ports[2].port=15012 \
--set service.ports[2].targetPort=15012 \
--set service.ports[3].name=tls-webhook \
--set service.ports[3].port=15017 \
--set service.ports[3].targetPort=15017 \你应该用以下变量重复该命令三次:
| cluster name | network name |
| :----------: | :----------: |
| ap | network1 |
| us | network2 |
| eu | network3 |然后为每个集群暴露一个具有以下资源的网关:
yaml
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: cross-network-gateway
spec:
selector:
istio: eastwestgateway
servers:
- port:
number: 15443
name: tls
protocol: TLS
tls:
mode: AUTO_PASSTHROUGH
hosts:
- "*.local"你可以通过以下方式将文件提交给群组:
bash
$ kubectl apply -f expose.yaml --kubeconfig=kubeconfig-eu
$ kubectl apply -f expose.yaml --kubeconfig=kubeconfig-ap
$ kubectl apply -f expose.yaml --kubeconfig=kubeconfig-us对于发现机制,你需要分享每个集群的凭证。这是必要的,因为各集群之间并不了解对方。
为了发现其他IP地址,它们需要访问其他集群,并将这些集群注册为可能的流量目的地。要做到这一点,你必须用其他集群的kubeconfig文件创建一个Kubernetes秘密。
Istio将使用这些连接到其他集群,发现端点并指示Envoy代理转发流量。
你将需要三个秘密:
yaml
apiVersion: v1
kind: Secret
metadata:
labels:
istio/multiCluster: true
annotations:
networking.istio.io/cluster: <insert cluster name>
name: "istio-remote-secret-<insert cluster name>"
type: Opaque
data:
<insert cluster name>: <insert cluster kubeconfig as base64>你应该用以下变量创建这三个秘密:
| cluster name | secret filename | kubeconfig |
| :----------: | :-------------: | :-----------: |
| ap | secret1.yaml | kubeconfig-ap |
| us | secret2.yaml | kubeconfig-us |
| eu | secret3.yaml | kubeconfig-eu |现在你应该向集群提交秘密,注意不要向AP集群提交AP秘密。
这些命令应该是以下内容:
bash
$ kubectl apply -f secret2.yaml -n istio-system --kubeconfig=kubeconfig-ap
$ kubectl apply -f secret3.yaml -n istio-system --kubeconfig=kubeconfig-ap
$ kubectl apply -f secret1.yaml -n istio-system --kubeconfig=kubeconfig-us
$ kubectl apply -f secret3.yaml -n istio-system --kubeconfig=kubeconfig-us
$ kubectl apply -f secret1.yaml -n istio-system --kubeconfig=kubeconfig-eu
$ kubectl apply -f secret2.yaml -n istio-system --kubeconfig=kubeconfig-eu就这样吧!
你已经准备好测试设置了。
测试多集群网络
让我们为一个睡眠舱创建一个部署。
你将使用这个pod向你先前创建的Hello部署发出请求:
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: sleep
spec:
selector:
matchLabels:
app: sleep
template:
metadata:
labels:
app: sleep
spec:
terminationGracePeriodSeconds: 0
containers:
- name: sleep
image: curlimages/curl
command: ["/bin/sleep", "3650d"]
imagePullPolicy: IfNotPresent
volumeMounts:
- mountPath: /etc/sleep/tls
name: secret-volume
volumes:
- name: secret-volume
secret:
secretName: sleep-secret
optional: true你可以用以下方式创建部署:
bash
$ kubectl apply -f sleep.yaml --kubeconfig=karmada-config由于没有这个部署的政策,Karmada将不处理它,让它待定。你可以修改政策以包括部署:
yaml
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: hello-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: hello
- apiVersion: v1
kind: Service
name: hello
- apiVersion: apps/v1
kind: Deployment
name: sleep
placement:
clusterAffinity:
clusterNames:
- eu
- ap
- us
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- us
weight: 2
- targetCluster:
clusterNames:
- ap
weight: 2
- targetCluster:
clusterNames:
- eu
weight: 1你可以通过以下方式应用该政策:
bash
$ kubectl apply -f policy.yaml --kubeconfig=karmada-config你可以弄清楚吊舱的部署地点:
bash
$ kubectl get pods --kubeconfig=kubeconfig-eu
$ kubectl get pods --kubeconfig=kubeconfig-ap
$ kubectl get pods --kubeconfig=kubeconfig-us现在,假设pod降落在美国集群上,执行以下命令:
Now, assuming the pod landed on the US cluster, execute the following command:
bash
for i in {1..10}
do
kubectl exec --kubeconfig=kubeconfig-us -c sleep \
"$(kubectl get pod --kubeconfig=kubeconfig-us -l \
app=sleep -o jsonpath='{.items[0].metadata.name}')" \
-- curl -sS hello:5000 | grep REGION
done你可能会注意到,这种反应来自于不同地区的不同豆荚!
工作完成!
今后该何去何从?
这种设置是相当基本的,而且缺乏你可能想要加入的几个更多的功能:
- 你可以从每个集群暴露出一个Istio ingress来摄取流量;
- 你可以使用Istio来塑造流量,使本地流量成为首选;以及
- 你可能想使用Istio策略执行规则来定义流量如何在集群之间流动。
回顾一下我们在这篇文章中所涉及的内容:
- 使用Karmada来控制几个群组;
- 定义策略,在几个集群之间安排工作负载;
- 使用Istio来连接多个集群的网络;以及
- Istio如何拦截流量并将其转发到其他群集。
你可以通过注册我们的网络研讨会系列和观看点播,看到跨区域扩展Kubernetes的完整演练,以及其他扩展方法。



注释