

Este posto faz parte de nossa série de escalas Kubernetes. Cadastre-se para assistir ao vivo ou acessar a gravação, e verificar nossos outros postos nesta série:
Um desafio interessante com a Kubernetes é a distribuição de cargas de trabalho em várias regiões. Embora você possa tecnicamente ter um cluster com vários nós localizados em diferentes regiões, isto é geralmente considerado como algo que você deve evitar devido à latência extra.
Uma alternativa popular é implantar um agrupamento para cada região e encontrar uma maneira de orquestrá-los.
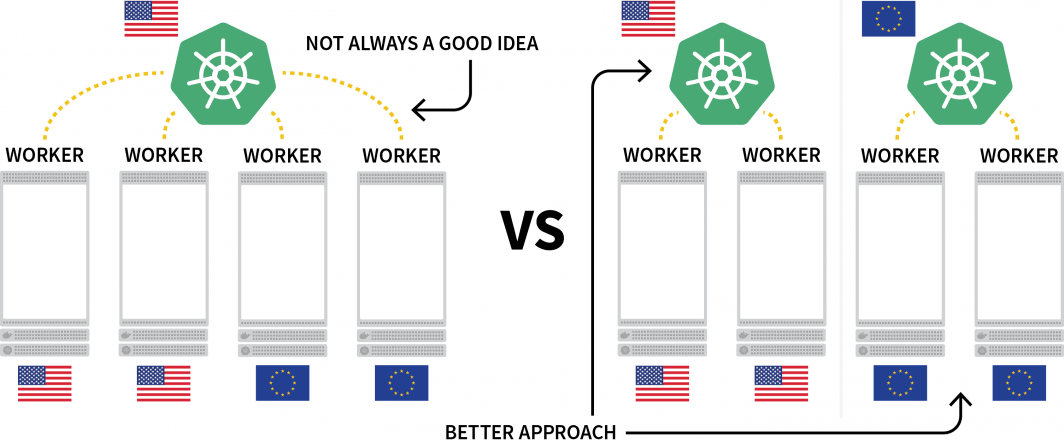
Neste posto, você o fará:
- Criar três clusters: um na América do Norte, um na Europa e um no Sudeste Asiático.
- Criar um quarto grupo que atuará como orquestrador para os outros.
- Estabelecer uma rede única a partir das três redes de cluster para uma comunicação perfeita.
Este posto foi roteirizado para trabalhar com Terraform exigindo o mínimo de interação. Você pode encontrar o código para isso no GitHub do LearnK8s.
Criando o Cluster Manager
Vamos começar com a criação do cluster que irá gerenciar o resto. Os seguintes comandos podem ser usados para criar o cluster e salvar o arquivo kubeconfig.
bash
$ linode-cli lke cluster-create \
--label cluster-manager \
--region eu-west \
--k8s_version 1.23
$ linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfig-cluster-managerVocê pode verificar se a instalação é bem sucedida:
bash
$ kubectl get pods -A --kubeconfig=kubeconfig-cluster-managerExcelente!
No gerenciador de cluster, você instalará o Karmada, um sistema de gerenciamento que permite executar suas aplicações nativas de nuvens através de múltiplos clusters e nuvens Kubernetes. A Karmada tem um plano de controle instalado no gerenciador de cluster e o agente instalado em todos os outros clusters.
O plano de controle tem três componentes:
- E API Servidor;
- Um Gerente de Controlador; e
- Um Agendador
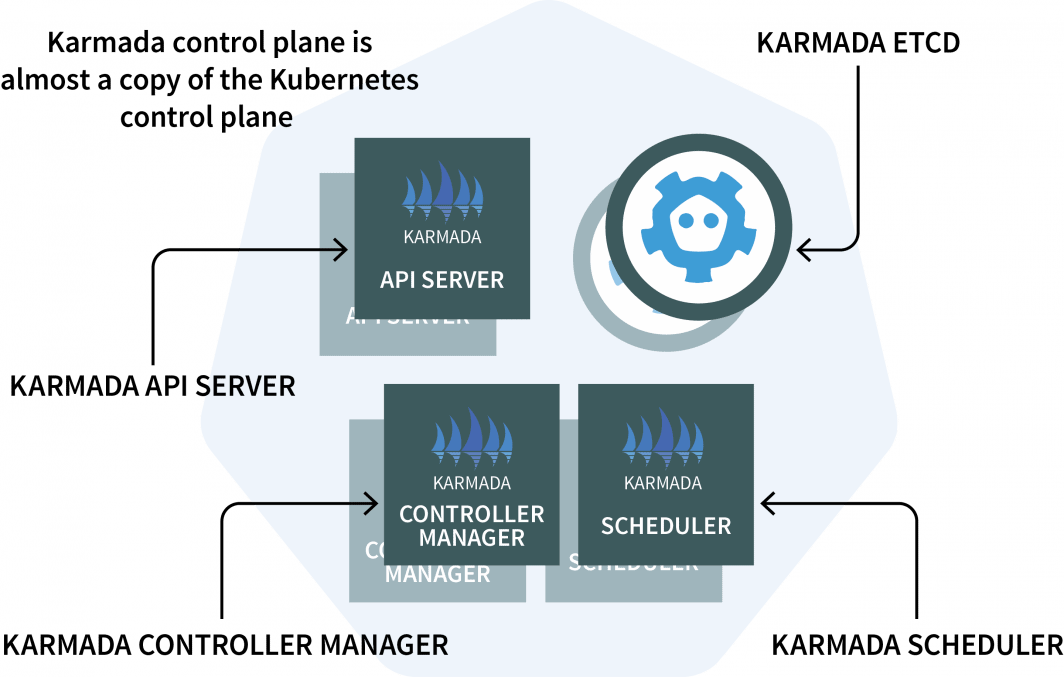
Se esses parecem familiares, é porque o plano de controle Kubernetes possui os mesmos componentes! A Karmada teve que copiá-los e ampliá-los para trabalhar com vários grupos.
Já chega de teoria. Vamos ao código.
Você usará o Helm para instalar o servidor Karmada API do Karmada. Vamos adicionar o repositório Helm com:
bash
$ helm repo add karmada-charts https://raw.githubusercontent.com/karmada-io/karmada/master/charts
$ helm repo list
NAME URL
karmada-charts https://raw.githubusercontent.com/karmada-io/karmada/master/chartsComo o servidor Karmada API deve ser acessível a todos os outros clusters, você terá que
- expô-lo a partir do nó; e
- garantir que a conexão seja confiável.
Portanto, vamos recuperar o endereço IP do nó que hospeda o avião de controle com:
bash
kubectl get nodes -o jsonpath='{.items[0].status.addresses[?(@.type==\"ExternalIP\")].address}' \
--kubeconfig=kubeconfig-cluster-managerAgora você pode instalar o avião de controle Karmada com:
bash
$ helm install karmada karmada-charts/karmada \
--kubeconfig=kubeconfig-cluster-manager \
--create-namespace --namespace karmada-system \
--version=1.2.0 \
--set apiServer.hostNetwork=false \
--set apiServer.serviceType=NodePort \
--set apiServer.nodePort=32443 \
--set certs.auto.hosts[0]="kubernetes.default.svc" \
--set certs.auto.hosts[1]="*.etcd.karmada-system.svc.cluster.local" \
--set certs.auto.hosts[2]="*.karmada-system.svc.cluster.local" \
--set certs.auto.hosts[3]="*.karmada-system.svc" \
--set certs.auto.hosts[4]="localhost" \
--set certs.auto.hosts[5]="127.0.0.1" \
--set certs.auto.hosts[6]="<insert the IP address of the node>"Quando a instalação estiver concluída, você poderá recuperar o kubeconfig para se conectar ao Karmada API com:
bash
kubectl get secret karmada-kubeconfig \
--kubeconfig=kubeconfig-cluster-manager \
-n karmada-system \
-o jsonpath={.data.kubeconfig} | base64 -d > karmada-configMas espere, por que outro arquivo kubeconfig?
O Karmada API foi projetado para substituir o Kubernetes padrão API mas ainda mantém todas as funcionalidades com as quais você está acostumado. Em outras palavras, você pode criar implantações que abrangem vários clusters com o kubectl.
Antes de testar o Karmada API e o kubectl, você deve corrigir o arquivo kubeconfig. Por padrão, o kubeconfig gerado só pode ser usado de dentro da rede do cluster.
No entanto, você pode substituir a seguinte linha para que ela funcione:
yaml
apiVersion: v1
kind: Config
clusters:
- cluster:
certificate-authority-data: LS0tLS1CRUdJTi…
insecure-skip-tls-verify: false
server: https://karmada-apiserver.karmada-system.svc.cluster.local:5443 # <- this works only in the cluster
name: karmada-apiserver
# truncatedSubstitua-a pelo endereço IP do nó que você recuperou anteriormente:
yaml
apiVersion: v1
kind: Config
clusters:
- cluster:
certificate-authority-data: LS0tLS1CRUdJTi…
insecure-skip-tls-verify: false
server: https://<node's IP address>:32443 # <- this works from the public internet
name: karmada-apiserver
# truncatedÓtimo, está na hora de testar o Karmada.
Instalando o Agente Karmada
Emitir o seguinte comando para recuperar todos os destacamentos e todos os aglomerados:
bash
$ kubectl get clusters,deployments --kubeconfig=karmada-config
No resources foundSem surpresas, não há implantações e não há aglomerações adicionais. Vamos adicionar mais alguns aglomerados e conectá-los ao plano de controle Karmada.
Repita os seguintes comandos três vezes:
bash
linode-cli lke cluster-create \
--label <insert-cluster-name> \
--region <insert-region> \
--k8s_version 1.23
linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfig-<insert-cluster-name>Os valores devem ser os seguintes:
- Nome do grupo
euregiãoeu-wesarquivo t e kubeconfigkubeconfig-eu - Nome do grupo
apregiãoap-southe arquivo kubeconfigkubeconfig-ap - Nome do grupo
usregiãous-weste arquivo kubeconfigkubeconfig-us
Você pode verificar se os clusters são criados com sucesso:
bash
$ kubectl get pods -A --kubeconfig=kubeconfig-eu
$ kubectl get pods -A --kubeconfig=kubeconfig-ap
$ kubectl get pods -A --kubeconfig=kubeconfig-usAgora é hora de fazê-los aderir ao aglomerado Karmada.
A Karmada usa um agente em cada outro aglomerado para coordenar o desdobramento com o plano de controle.
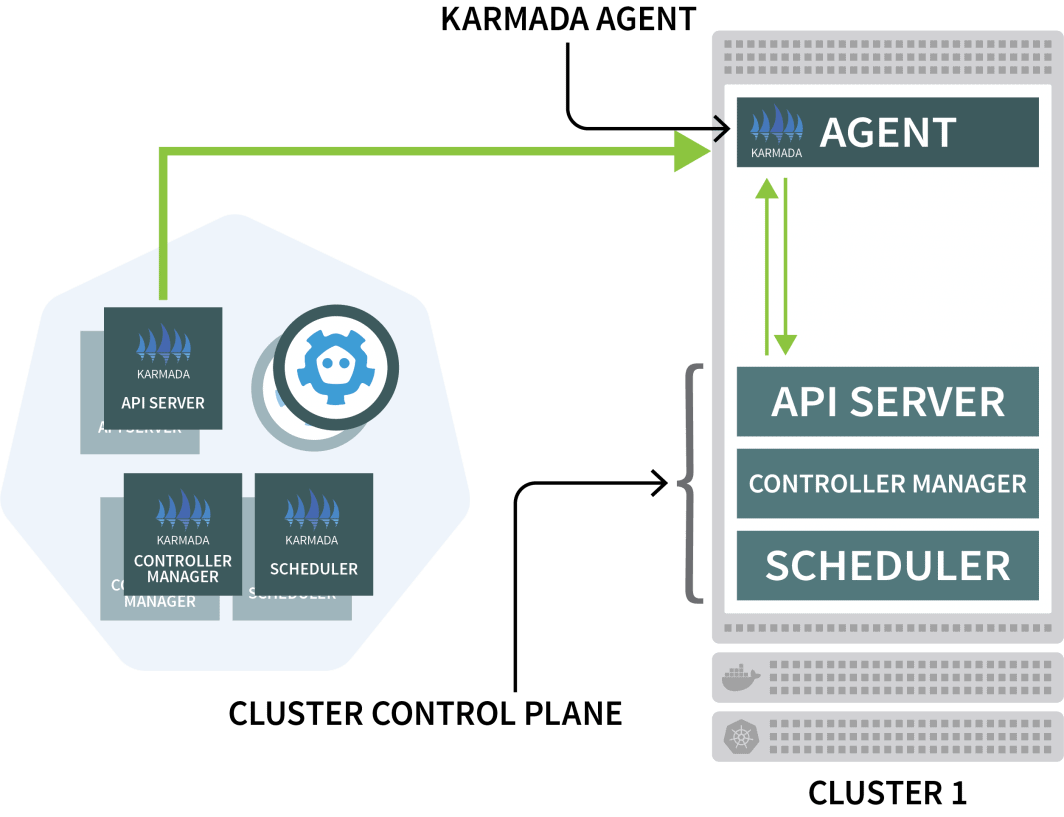
Você usará o Helm para instalar o agente Karmada e conectá-lo ao gerenciador de cluster:
bash
$ helm install karmada karmada-charts/karmada \
--kubeconfig=kubeconfig-<insert-cluster-name> \
--create-namespace --namespace karmada-system \
--version=1.2.0 \
--set installMode=agent \
--set agent.clusterName=<insert-cluster-name> \
--set agent.kubeconfig.caCrt=<karmada kubeconfig certificate authority> \
--set agent.kubeconfig.crt=<karmada kubeconfig client certificate data> \
--set agent.kubeconfig.key=<karmada kubeconfig client key data> \
--set agent.kubeconfig.server=https://<insert node's IP address>:32443 \Você terá que repetir o comando acima três vezes e inserir as seguintes variáveis:
- O nome do agrupamento. Este é ou
eu,apouus - A autoridade de certificado do gerente do cluster. Você pode encontrar este valor no
karmada-configarquivounder clusters[0].cluster['certificate-authority-data'].
Você pode decodificar o valor de base64. - Os dados do certificado de cliente do usuário. Você pode encontrar este valor no
karmada-configarquivo emusers[0].user['client-certificate-data'].
Você pode decodificar o valor a partir da base64. - Os dados do certificado de cliente do usuário. Você pode encontrar este valor no
karmada-configarquivo emusers[0].user['client-key-data'].
Você pode decodificar o valor a partir da base64. - O endereço IP do nó que hospeda o avião de controle Karmada.
Para verificar se a instalação está completa, você pode emitir o seguinte comando:
bash
$ kubectl get clusters --kubeconfig=karmada-config
NAME VERSION MODE READY
eu v1.23.8 Pull True
ap v1.23.8 Pull True
us v1.23.8 Pull TrueExcelente!
Orquestrando a implementação do Multicluster Deployment com Políticas Karmada
Com a configuração atual, você submete uma carga de trabalho à Karmada, que depois a distribuirá entre os outros grupos.
Vamos testar isso criando uma implantação:
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello
spec:
replicas: 3
selector:
matchLabels:
app: hello
template:
metadata:
labels:
app: hello
spec:
containers:
- image: stefanprodan/podinfo
name: hello
---
apiVersion: v1
kind: Service
metadata:
name: hello
spec:
ports:
- port: 5000
targetPort: 9898
selector:
app: helloVocê pode enviar a implantação para o servidor Karmada API com:
bash
$ kubectl apply -f deployment.yaml --kubeconfig=karmada-configEste desdobramento tem três réplicas - essas distribuirão igualmente entre os três grupos?
Vamos verificar:
bash
$ kubectl get deployments --kubeconfig=karmada-config
NAME READY UP-TO-DATE AVAILABLE
hello 0/3 0 0Por que a Karmada não está criando as Pods?
Vamos descrever o desdobramento:
bash
$ kubectl describe deployment hello --kubeconfig=karmada-config
Name: hello
Namespace: default
Selector: app=hello
Replicas: 3 desired | 0 updated | 0 total | 0 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Events:
Type Reason From Message
---- ------ ---- -------
Warning ApplyPolicyFailed resource-detector No policy match for resourceA Karmada não sabe o que fazer com as implantações porque você não especificou uma política.
O programador da Karmada utiliza políticas para alocar cargas de trabalho a clusters.
Vamos definir uma política simples que atribua uma réplica a cada agrupamento:
yaml
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: hello-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: hello
- apiVersion: v1
kind: Service
name: hello
placement:
clusterAffinity:
clusterNames:
- eu
- ap
- us
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- us
weight: 1
- targetCluster:
clusterNames:
- ap
weight: 1
- targetCluster:
clusterNames:
- eu
weight: 1Você pode submeter a política ao agrupamento com:
bash
$ kubectl apply -f policy.yaml --kubeconfig=karmada-configVamos inspecionar as implantações e as cápsulas:
bash
$ kubectl get deployments --kubeconfig=karmada-config
NAME READY UP-TO-DATE AVAILABLE
hello 3/3 3 3
$ kubectl get pods --kubeconfig=kubeconfig-eu
NAME READY STATUS RESTARTS
hello-5d857996f-hjfqq 1/1 Running 0
$ kubectl get pods --kubeconfig=kubeconfig-ap
NAME READY STATUS RESTARTS
hello-5d857996f-xr6hr 1/1 Running 0
$ kubectl get pods --kubeconfig=kubeconfig-us
NAME READY STATUS RESTARTS
hello-5d857996f-nbz48 1/1 Running 0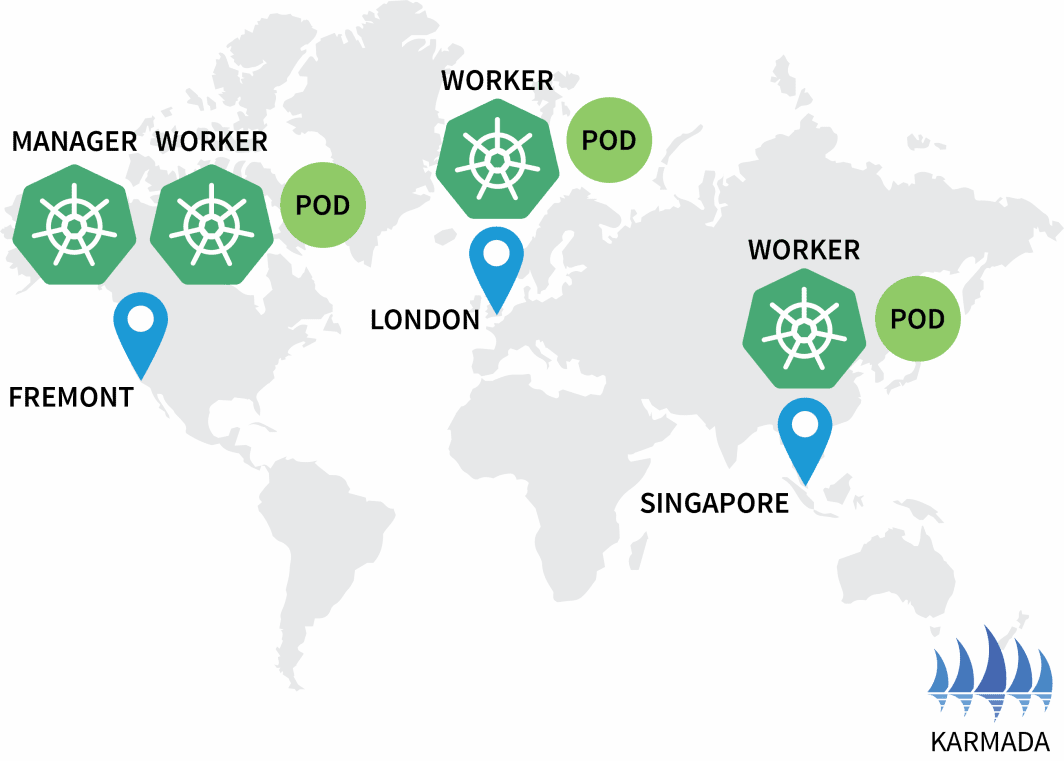
A Karmada atribuiu uma cápsula a cada agrupamento porque sua política definiu um peso igual para cada agrupamento.
Vamos escalar o desdobramento para 10 réplicas com:
bash
$ kubectl scale deployment/hello --replicas=10 --kubeconfig=karmada-configSe você inspecionar as cápsulas, você pode encontrar o seguinte:
bash
$ kubectl get deployments --kubeconfig=karmada-config
NAME READY UP-TO-DATE AVAILABLE
hello 10/10 10 10
$ kubectl get pods --kubeconfig=kubeconfig-eu
NAME READY STATUS RESTARTS
hello-5d857996f-dzfzm 1/1 Running 0
hello-5d857996f-hjfqq 1/1 Running 0
hello-5d857996f-kw2rt 1/1 Running 0
hello-5d857996f-nz7qz 1/1 Running 0
$ kubectl get pods --kubeconfig=kubeconfig-ap
NAME READY STATUS RESTARTS
hello-5d857996f-pd9t6 1/1 Running 0
hello-5d857996f-r7bmp 1/1 Running 0
hello-5d857996f-xr6hr 1/1 Running 0
$ kubectl get pods --kubeconfig=kubeconfig-us
NAME READY STATUS RESTARTS
hello-5d857996f-nbz48 1/1 Running 0
hello-5d857996f-nzgpn 1/1 Running 0
hello-5d857996f-rsp7k 1/1 Running 0Vamos emendar a política para que os clusters da UE e dos EUA detenham 40% das cápsulas e apenas 20% sejam deixados para o cluster AP.
yaml
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: hello-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: hello
- apiVersion: v1
kind: Service
name: hello
placement:
clusterAffinity:
clusterNames:
- eu
- ap
- us
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- us
weight: 2
- targetCluster:
clusterNames:
- ap
weight: 1
- targetCluster:
clusterNames:
- eu
weight: 2Você pode apresentar a política com:
bash
$ kubectl apply -f policy.yaml --kubeconfig=karmada-configVocê pode observar a distribuição de sua cápsula mudando de acordo:
bash
$ kubectl get pods --kubeconfig=kubeconfig-eu
NAME READY STATUS RESTARTS AGE
hello-5d857996f-hjfqq 1/1 Running 0 6m5s
hello-5d857996f-kw2rt 1/1 Running 0 2m27s
$ kubectl get pods --kubeconfig=kubeconfig-ap
hello-5d857996f-k9hsm 1/1 Running 0 51s
hello-5d857996f-pd9t6 1/1 Running 0 2m41s
hello-5d857996f-r7bmp 1/1 Running 0 2m41s
hello-5d857996f-xr6hr 1/1 Running 0 6m19s
$ kubectl get pods --kubeconfig=kubeconfig-us
hello-5d857996f-nbz48 1/1 Running 0 6m29s
hello-5d857996f-nzgpn 1/1 Running 0 2m51s
hello-5d857996f-rgj9t 1/1 Running 0 61s
hello-5d857996f-rsp7k 1/1 Running 0 2m51s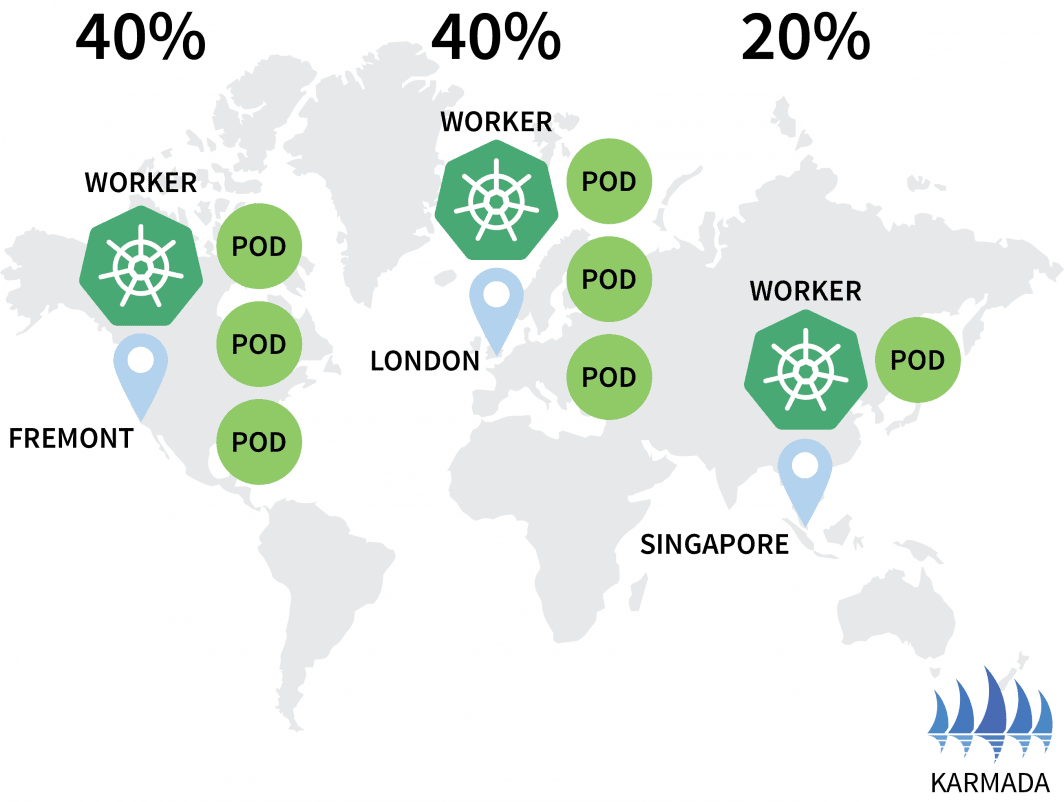
Ótimo!
A Karmada apóia várias políticas para distribuir suas cargas de trabalho. Você pode verificar a documentação para casos de uso mais avançado.
As cápsulas estão funcionando nos três grupos, mas como você pode acessá-las?
Vamos inspecionar o serviço em Karmada:
bash
$ kubectl describe service hello --kubeconfig=karmada-config
Name: hello
Namespace: default
Labels: propagationpolicy.karmada.io/name=hello-propagation
propagationpolicy.karmada.io/namespace=default
Selector: app=hello
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.105.24.193
IPs: 10.105.24.193
Port: <unset> 5000/TCP
TargetPort: 9898/TCP
Events:
Type Reason Message
---- ------ -------
Normal SyncSucceed Successfully applied resource(default/hello) to cluster ap
Normal SyncSucceed Successfully applied resource(default/hello) to cluster us
Normal SyncSucceed Successfully applied resource(default/hello) to cluster eu
Normal AggregateStatusSucceed Update resourceBinding(default/hello-service) with AggregatedStatus successfully.
Normal ScheduleBindingSucceed Binding has been scheduled
Normal SyncWorkSucceed Sync work of resourceBinding(default/hello-service) successful.O serviço é implantado nos três clusters, mas eles não estão conectados.
Mesmo que a Karmada possa gerenciar vários clusters, ela não fornece nenhum mecanismo de rede para garantir que os três clusters estejam ligados. Em outras palavras, a Karmada é uma excelente ferramenta para orquestrar implantações entre os agrupamentos, mas é necessário algo mais para garantir que esses agrupamentos possam se comunicar uns com os outros.
Conectando Multi Clusters com Istio
Istio é normalmente usado para controlar o tráfego da rede entre aplicações no mesmo cluster. Ele funciona interceptando todas as solicitações de saída e de entrada e as aproxima através do Envoy.
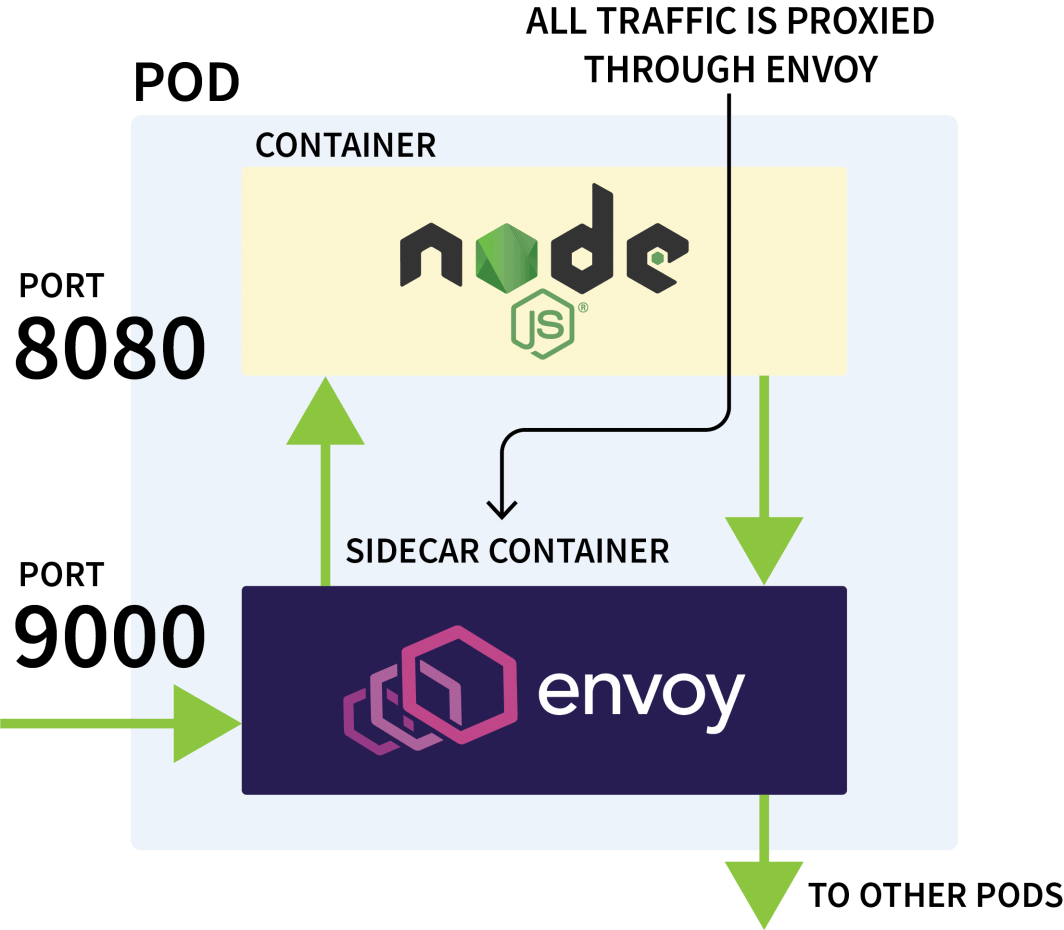
O avião de controle Istio é responsável pela atualização e coleta de métricas desses procuradores e também pode emitir instruções para desviar o tráfego.
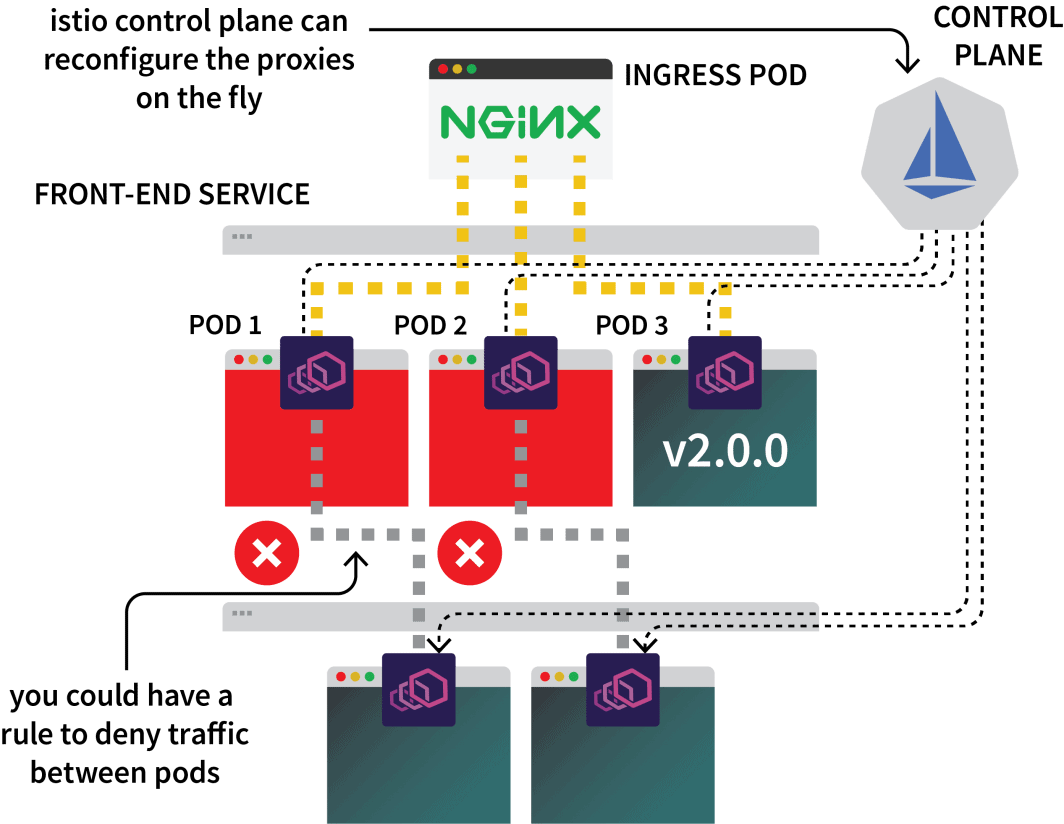
Assim, você poderia usar o Istio para interceptar todo o tráfego para um determinado serviço e direcioná-lo para um dos três clusters. Essa é a idéia com a configuração do Istio multicluster.
Já chega de teorias - vamos sujar nossas mãos. O primeiro passo é instalar o Istio nos três clusters.
Embora existam várias maneiras de instalar o Istio, eu geralmente prefiro o Helm:
bash
$ helm repo add istio https://istio-release.storage.googleapis.com/charts
$ helm repo list
NAME URL
istio https://istio-release.storage.googleapis.com/chartsVocê pode instalar o Istio nos três clusters com:
bash
$ helm install istio-base istio/base \
--kubeconfig=kubeconfig-<insert-cluster-name> \
--create-namespace --namespace istio-system \
--version=1.14.1Você deve substituir o cluster-name com ap, eu e us e executar o comando para cada um deles.
O gráfico de base instala principalmente recursos comuns, tais como Roles e RoleBindings.
A instalação real é embalada no istiod gráfico. Mas antes de prosseguir com isso, você tem que configurar a Autoridade Certificadora Istio (CA) para garantir que os três clusters possam se conectar e confiar uns nos outros.
Em um novo diretório, clone o repositório Istio com:
bash
$ git clone https://github.com/istio/istioCriar um certs pasta e mudar para esse diretório:
bash
$ mkdir certs
$ cd certsCriar o certificado de raiz com:
bash
$ make -f ../istio/tools/certs/Makefile.selfsigned.mk root-caO comando gerou os seguintes arquivos:
root-cert.pem: o certificado de raiz geradoroot-key.pem: a chave raiz geradaroot-ca.confa configuração para OpenSSL para gerar o certificado de raizroot-cert.csra RSC gerada para o certificado de raiz
Para cada agrupamento, gerar um certificado intermediário e uma chave para a Autoridade Certificadora Istio:
bash
$ make -f ../istio/tools/certs/Makefile.selfsigned.mk cluster1-cacerts
$ make -f ../istio/tools/certs/Makefile.selfsigned.mk cluster2-cacerts
$ make -f ../istio/tools/certs/Makefile.selfsigned.mk cluster3-cacertsOs comandos irão gerar os seguintes arquivos em um diretório chamado cluster1, cluster2e cluster3:
bash
$ kubectl create secret generic cacerts -n istio-system \
--kubeconfig=kubeconfig-<cluster-name>
--from-file=<cluster-folder>/ca-cert.pem \
--from-file=<cluster-folder>/ca-key.pem \
--from-file=<cluster-folder>/root-cert.pem \
--from-file=<cluster-folder>/cert-chain.pemVocê deve executar os comandos com as seguintes variáveis:
| cluster name | folder name |
| :----------: | :---------: |
| ap | cluster1 |
| us | cluster2 |
| eu | cluster3 |Com estes prontos, você está finalmente pronto para instalar o istiod:
bash
$ helm install istiod istio/istiod \
--kubeconfig=kubeconfig-<insert-cluster-name> \
--namespace istio-system \
--version=1.14.1 \
--set global.meshID=mesh1 \
--set global.multiCluster.clusterName=<insert-cluster-name> \
--set global.network=<insert-network-name>Você deve repetir o comando três vezes com as seguintes variáveis:
| cluster name | network name |
| :----------: | :----------: |
| ap | network1 |
| us | network2 |
| eu | network3 |Você também deve etiquetar o espaço de nomes Istio com uma anotação topológica:
bash
$ kubectl label namespace istio-system topology.istio.io/network=network1 --kubeconfig=kubeconfig-ap
$ kubectl label namespace istio-system topology.istio.io/network=network2 --kubeconfig=kubeconfig-us
$ kubectl label namespace istio-system topology.istio.io/network=network3 --kubeconfig=kubeconfig-euIsso é tudo?
Quase.
Túnel de Trânsito com um Portal Leste-Oeste
Você ainda precisa:
- uma porta de entrada para canalizar o tráfego de um aglomerado para outro; e
- um mecanismo para descobrir endereços IP em outros clusters.
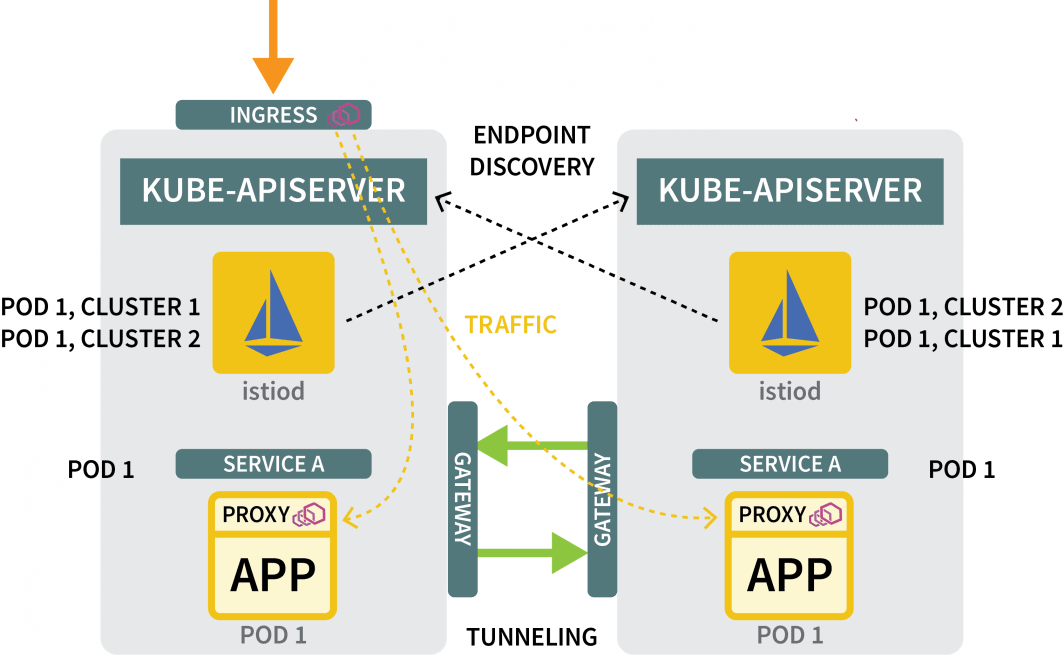
Para o portal, você pode usar o Helm para instalá-lo:
bash
$ helm install eastwest-gateway istio/gateway \
--kubeconfig=kubeconfig-<insert-cluster-name> \
--namespace istio-system \
--version=1.14.1 \
--set labels.istio=eastwestgateway \
--set labels.app=istio-eastwestgateway \
--set labels.topology.istio.io/network=istio-eastwestgateway \
--set labels.topology.istio.io/network=istio-eastwestgateway \
--set networkGateway=<insert-network-name> \
--set service.ports[0].name=status-port \
--set service.ports[0].port=15021 \
--set service.ports[0].targetPort=15021 \
--set service.ports[1].name=tls \
--set service.ports[1].port=15443 \
--set service.ports[1].targetPort=15443 \
--set service.ports[2].name=tls-istiod \
--set service.ports[2].port=15012 \
--set service.ports[2].targetPort=15012 \
--set service.ports[3].name=tls-webhook \
--set service.ports[3].port=15017 \
--set service.ports[3].targetPort=15017 \Você deve repetir o comando três vezes com as seguintes variáveis:
| cluster name | network name |
| :----------: | :----------: |
| ap | network1 |
| us | network2 |
| eu | network3 |Depois, para cada agrupamento, exponha um Gateway com o seguinte recurso:
yaml
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: cross-network-gateway
spec:
selector:
istio: eastwestgateway
servers:
- port:
number: 15443
name: tls
protocol: TLS
tls:
mode: AUTO_PASSTHROUGH
hosts:
- "*.local"Você pode enviar o arquivo para os agrupamentos com:
bash
$ kubectl apply -f expose.yaml --kubeconfig=kubeconfig-eu
$ kubectl apply -f expose.yaml --kubeconfig=kubeconfig-ap
$ kubectl apply -f expose.yaml --kubeconfig=kubeconfig-usPara os mecanismos de descoberta, você precisa compartilhar as credenciais de cada agrupamento. Isto é necessário porque os agrupamentos não se conhecem uns aos outros.
Para descobrir outros endereços IP, eles precisam acessar outros clusters e registrá-los como possíveis destinos para o tráfego. Para isso, é necessário criar um segredo Kubernetes com o arquivo kubeconfig para os outros clusters.
Istio usará esses para se conectar com os outros grupos, descobrir os pontos finais e instruir os procuradores do Enviado a encaminhar o tráfego.
Você vai precisar de três segredos:
yaml
apiVersion: v1
kind: Secret
metadata:
labels:
istio/multiCluster: true
annotations:
networking.istio.io/cluster: <insert cluster name>
name: "istio-remote-secret-<insert cluster name>"
type: Opaque
data:
<insert cluster name>: <insert cluster kubeconfig as base64>Você deve criar os três segredos com as seguintes variáveis:
| cluster name | secret filename | kubeconfig |
| :----------: | :-------------: | :-----------: |
| ap | secret1.yaml | kubeconfig-ap |
| us | secret2.yaml | kubeconfig-us |
| eu | secret3.yaml | kubeconfig-eu |Agora você deve submeter os segredos ao grupo, prestando atenção para não submeter o segredo AP ao grupo AP.
Os comandos devem ser os seguintes:
bash
$ kubectl apply -f secret2.yaml -n istio-system --kubeconfig=kubeconfig-ap
$ kubectl apply -f secret3.yaml -n istio-system --kubeconfig=kubeconfig-ap
$ kubectl apply -f secret1.yaml -n istio-system --kubeconfig=kubeconfig-us
$ kubectl apply -f secret3.yaml -n istio-system --kubeconfig=kubeconfig-us
$ kubectl apply -f secret1.yaml -n istio-system --kubeconfig=kubeconfig-eu
$ kubectl apply -f secret2.yaml -n istio-system --kubeconfig=kubeconfig-euE isso é tudo!
Você está pronto para testar a configuração.
Teste da Rede Multicluster
Vamos criar um desdobramento para um sleep pod.
Você usará esta cápsula para fazer um pedido para a implantação do Olá que você criou anteriormente:
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: sleep
spec:
selector:
matchLabels:
app: sleep
template:
metadata:
labels:
app: sleep
spec:
terminationGracePeriodSeconds: 0
containers:
- name: sleep
image: curlimages/curl
command: ["/bin/sleep", "3650d"]
imagePullPolicy: IfNotPresent
volumeMounts:
- mountPath: /etc/sleep/tls
name: secret-volume
volumes:
- name: secret-volume
secret:
secretName: sleep-secret
optional: trueVocê pode criar a implantação com:
bash
$ kubectl apply -f sleep.yaml --kubeconfig=karmada-configComo não há uma política para esta implantação, a Karmada não irá processá-la e deixá-la pendente. Você pode alterar a política para incluir o desdobramento com:
yaml
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: hello-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: hello
- apiVersion: v1
kind: Service
name: hello
- apiVersion: apps/v1
kind: Deployment
name: sleep
placement:
clusterAffinity:
clusterNames:
- eu
- ap
- us
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- us
weight: 2
- targetCluster:
clusterNames:
- ap
weight: 2
- targetCluster:
clusterNames:
- eu
weight: 1Você pode aplicar a política com:
bash
$ kubectl apply -f policy.yaml --kubeconfig=karmada-configVocê pode descobrir onde a cápsula foi colocada:
bash
$ kubectl get pods --kubeconfig=kubeconfig-eu
$ kubectl get pods --kubeconfig=kubeconfig-ap
$ kubectl get pods --kubeconfig=kubeconfig-usAgora, assumindo que a cápsula pousou no cluster americano, execute o seguinte comando:
Now, assuming the pod landed on the US cluster, execute the following command:
bash
for i in {1..10}
do
kubectl exec --kubeconfig=kubeconfig-us -c sleep \
"$(kubectl get pod --kubeconfig=kubeconfig-us -l \
app=sleep -o jsonpath='{.items[0].metadata.name}')" \
-- curl -sS hello:5000 | grep REGION
doneVocê pode notar que a resposta vem de diferentes cápsulas de diferentes regiões!
Trabalho feito!
Para onde ir a partir daqui?
Esta configuração é bastante básica e carece de várias outras características que você provavelmente deseja incorporar:
- você poderia expor uma entrada Istio de cada aglomerado para ingerir o tráfego;
- você poderia usar o Istio para moldar o tráfego para que o tráfego local seja preferido; e
- você pode querer usar as regras de aplicação da política do Istio para definir como o tráfego pode fluir entre os agrupamentos.
Para recapitular o que cobrimos neste post:
- usando a Karmada para controlar vários clusters;
- definindo políticas para programar cargas de trabalho em vários clusters;
- usando Istio para fazer a ligação em rede de múltiplos clusters; e
- como Istio intercepta o tráfego e o encaminha para outros aglomerados.
Você pode ver uma caminhada completa da escalada Kubernetes através das regiões, além de outras metodologias de escalada, registrando-se para nossa série de webinars e assistindo on-demand.




Comentários