

Este posto faz parte de nossa série de escalas Kubernetes. Cadastre-se para assistir ao vivo ou acessar a gravação, e verificar nossos outros postos nesta série:
A redução dos custos de infra-estrutura se resume a desligar os recursos quando eles não estão sendo utilizados. Entretanto, o desafio é descobrir como ligar esses recursos automaticamente quando necessário. Vamos percorrer os passos necessários para implantar um cluster Kubernetes usando o Linode Kubernetes Engine (LKE) e usar o Kubernetes Events-Driven Autoscaler (KEDA) para escalar até zero e voltar.
Por que escalar a zero
Imaginemos que você esteja executando um aplicativo com recursos razoavelmente intensivos na Kubernetes e que só é necessário durante o horário de trabalho.
Você pode querer desligá-lo quando as pessoas saírem do escritório e voltar quando começarem o dia.
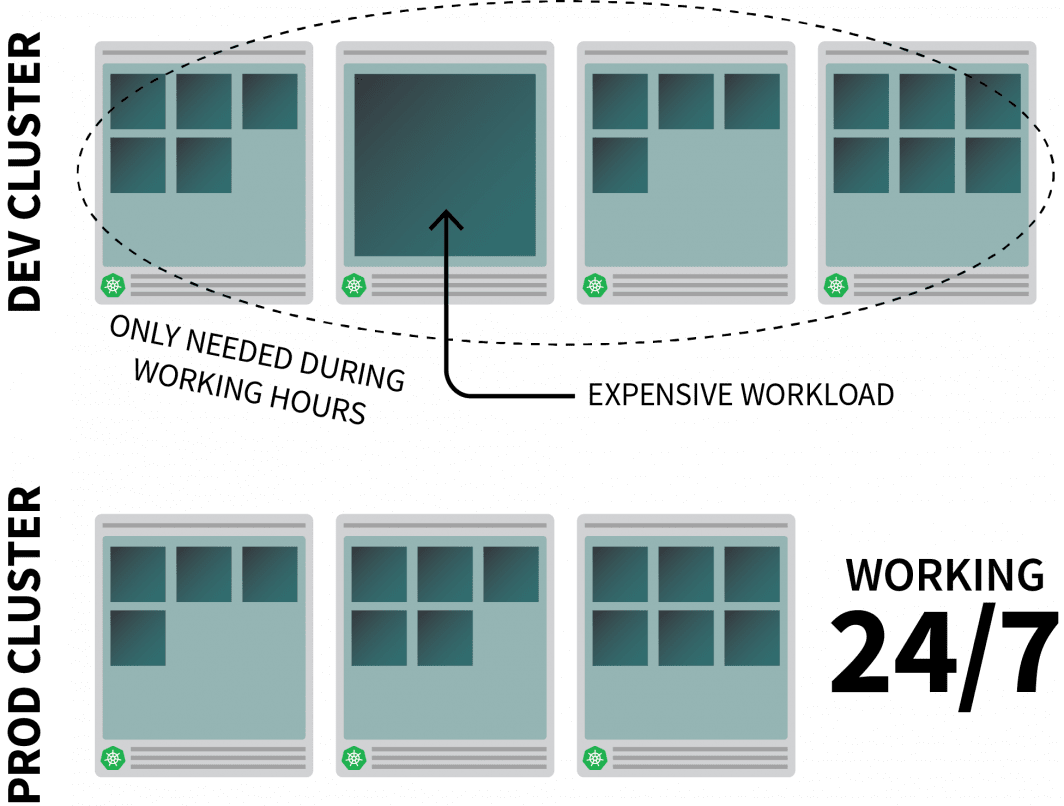
Enquanto você poderia usar um CronJob para aumentar e diminuir a escala, esta solução é uma solução que só pode funcionar em um cronograma pré-estabelecido.
O que acontece durante o fim de semana? E quanto aos feriados públicos? Ou quando a equipe está doente?
Em vez de gerar uma lista sempre crescente de regras, você pode aumentar sua carga de trabalho com base no tráfego. Quando o tráfego aumenta, você pode escalar as réplicas. Se não houver tráfego, você pode desligar o aplicativo. Se o aplicativo for desligado e houver um novo pedido de entrada, Kubernetes lançará pelo menos uma réplica para lidar com o tráfego.

A seguir, vamos falar sobre como fazê-lo:
- intercepte todo o tráfego para suas aplicações;
- monitorar o tráfego; e
- configurar o autoscaler para ajustar o número de réplicas ou desativar as aplicações.
Se você preferir ler o código para este tutorial, você pode fazer isso no GitHub do LearnK8s.
Criando um Cluster
Vamos começar com a criação de um aglomerado Kubernetes.
Os seguintes comandos podem ser usados para criar o cluster e salvar o arquivo kubeconfig.
bash
$ linode-cli lke cluster-create \
--label cluster-manager \
--region eu-west \
--k8s_version 1.23
$ linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfigVocê pode verificar se a instalação é bem sucedida:
bash
$ kubectl get pods -A --kubeconfig=kubeconfigExportar o arquivo kubeconfig com uma variável de ambiente é normalmente mais conveniente.
Você pode fazer isso com:
bash
$ export KUBECONFIG=${PWD}/kubeconfig
$ kubectl get podsAgora vamos implantar uma aplicação.
Implantar uma aplicação
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
spec:
containers:
- name: podinfo
image: stefanprodan/podinfo
ports:
- containerPort: 9898
---
apiVersion: v1
kind: Service
metadata:
name: podinfo
spec:
ports:
- port: 80
targetPort: 9898
selector:
app: podinfoVocê pode enviar o arquivo YAML com:
terminal|command=1|title=bash
$ kubectl apply -f 1-deployment.yamlE você pode visitar o aplicativo com:
Abra seu navegador para o localhost:8080.
bash
$ kubectl port-forward svc/podinfo 8080:80Neste ponto, você deve ver o aplicativo.
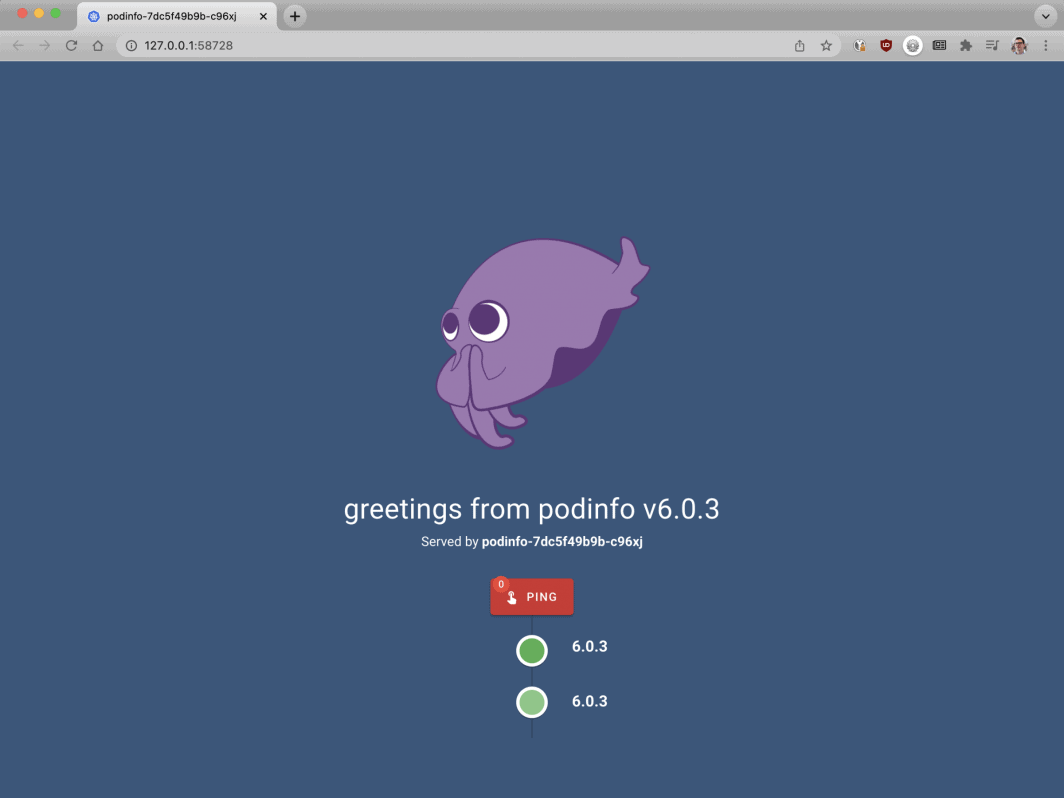
A seguir, vamos instalar o KEDA - o autoscaler.
KEDA - o Autoscaler Kubernetes, que funciona em eventos
A Kubernetes oferece o Pod Autoscaler Horizontal (HPA) como um controlador para aumentar e diminuir as réplicas dinamicamente.
Infelizmente, a HPA tem alguns inconvenientes:
- Não funciona fora da caixa - você precisa instalar um Metrics Server para agregar e expor as métricas.
- Não escala a zero réplicas.
- Ela escalona réplicas baseadas em métricas, e não intercepta o tráfego HTTP.
Felizmente, você não tem que usar o autoscaler oficial, mas pode usar a KEDA em seu lugar.
A KEDA é um autoscaler feito de três componentes:
- Um Escalador
- Um Adaptador de Métricas
- Um Controlador
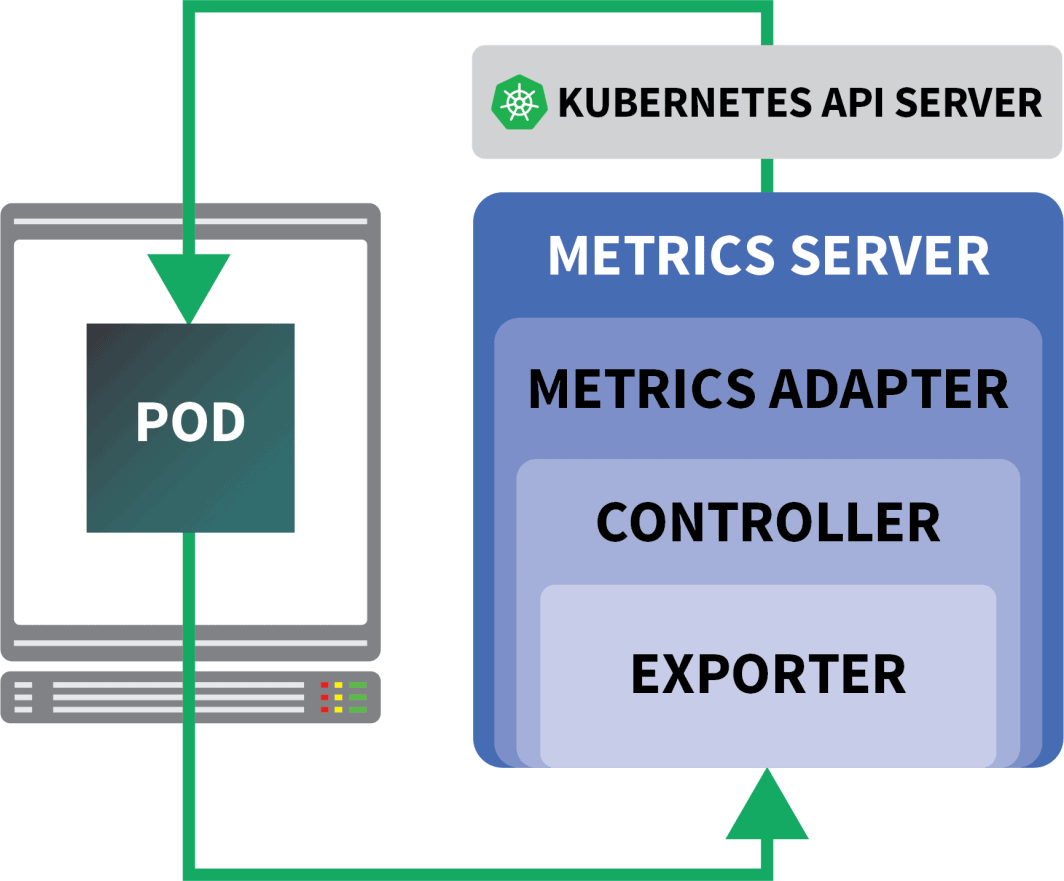
Os escaladores são como adaptadores que podem coletar métricas de bancos de dados, corretores de mensagens, sistemas de telemetria, etc.
Por exemplo, o HTTP Scaler é um adaptador que pode interceptar e coletar tráfego HTTP.
Você pode encontrar um exemplo de um escalador usando o RabbitMQ aqui.
O Adaptador de Métricas é responsável por expor as métricas coletadas pelos escaladores em um formato que a Kubernetes Metrics pipeline pode consumir.
E finalmente, o controlador cola todos os componentes juntos:
- Ele coleta as métricas usando o adaptador e as expõe às métricas API.
- Ele registra e gerencia as Definições de Recursos Personalizados (CRD) específicas da KEDA - ou seja, ScaledObject, TriggerAuthentication, etc.
- Ele cria e gerencia o Pod Autoscaler Horizontal em seu nome.
Essa é a teoria, mas vamos ver como ela funciona na prática.
Uma maneira mais rápida de instalar o controlador é usar o Helm.
Você pode encontrar as instruções de instalação no site oficial do Helm.
bash
$ helm repo add kedacore https://kedacore.github.io/charts
$ helm install keda kedacore/kedaA KEDA não vem com um escaler HTTP por padrão, então você terá que instalá-lo separadamente:
bash
$ helm install http-add-on kedacore/keda-add-ons-httpNeste ponto, você está pronto para dimensionar o aplicativo.
Definindo uma estratégia de autoescalonamento
O suplemento HTTP KEDA expõe um CRD onde você pode descrever como sua aplicação deve ser escalonada.
Vamos dar uma olhada em um exemplo:
yaml
kind: HTTPScaledObject
apiVersion: http.keda.sh/v1alpha1
metadata:
name: podinfo
spec:
host: example.com
targetPendingRequests: 100
scaleTargetRef:
deployment: podinfo
service: podinfo
port: 80
replicas:
min: 0
max: 10Este arquivo instrui os interceptores a encaminhar pedidos por exemplo.com para o serviço de podinfo.
Também inclui o nome da implantação que deve ser escalonada - neste caso, podinfo.
Vamos enviar o YAML para o grupo com:
bash
$ kubectl apply -f scaled-object.yamlAssim que você submeter a definição, a cápsula é apagada!
Mas por quê?
Depois que um HTTPScaledObject é criado, a KEDA imediatamente escalona o desdobramento para zero, já que não há tráfego.
Você deve enviar solicitações HTTP para o aplicativo para escalá-lo.
Vamos testar isto conectando-nos ao serviço e emitindo um pedido.
bash
$ kubectl port-forward svc/podinfo 8080:80O comando fica pendurado!
Faz sentido; não há cápsulas para atender o pedido.
Mas por que a Kubernetes não está escalando o desdobramento para 1?
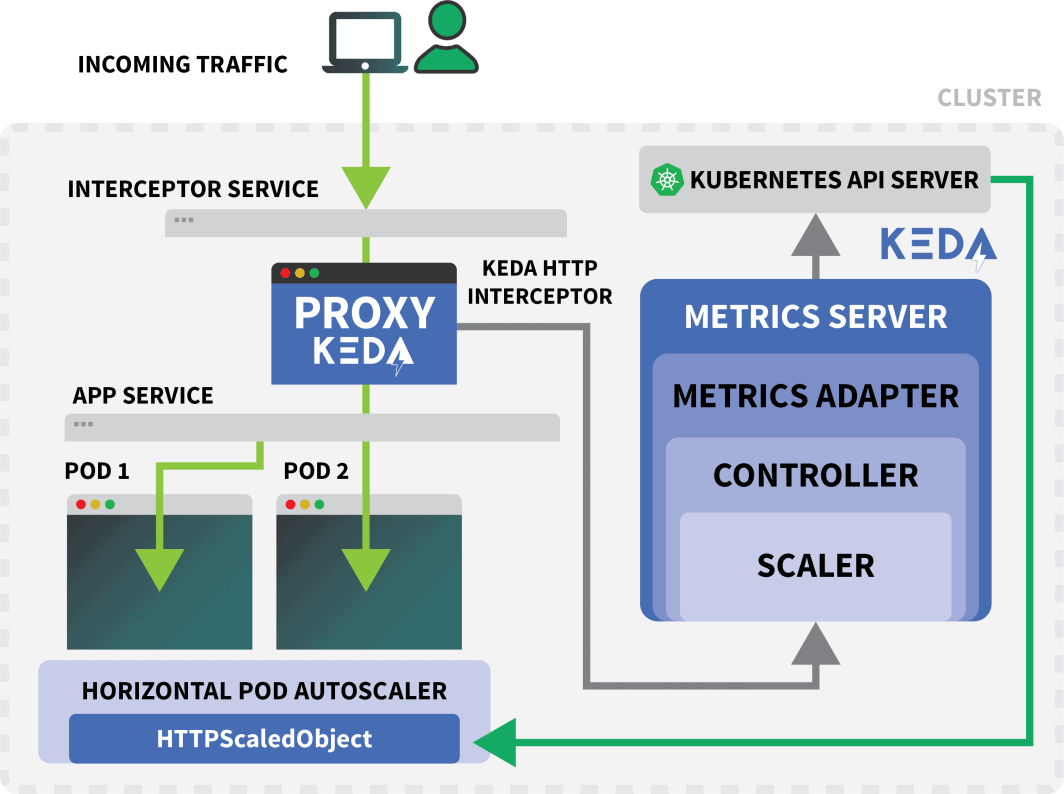
Teste do interceptor KEDA
Um serviço Kubernetes chamado keda-add-ons-http-interceptor-proxy foi criado quando você usou o Helm para instalar o add-on.
Para que o autoscaling funcione apropriadamente, o tráfego HTTP deve passar primeiro por esse serviço.
Você pode usar kubectl port-forward para testá-lo:
shell
$ kubectl port-forward svc/keda-add-ons-http-interceptor-proxy 8080:8080Desta vez, você não pode visitar a URL em seu navegador.
Um único interceptor HTTP KEDA pode lidar com várias implantações.
Então, como ele sabe para onde encaminhar o tráfego?
yaml
kind: HTTPScaledObject
apiVersion: http.keda.sh/v1alpha1
metadata:
name: podinfo
spec:
host: example.com
targetPendingRequests: 100
scaleTargetRef:
deployment: podinfo
service: podinfo
port: 80
replicas:
min: 0
max: 10O HTTPScaledObject tem um campo hospedeiro que é usado precisamente para isso.
Neste exemplo, finja que o pedido vem do site example.com.
Você pode fazer isso definindo o cabeçalho do Host:
bash
$ curl localhost:8080 -H 'Host: example.com'Você receberá uma resposta, embora com um ligeiro atraso.
Se você inspecionar as cápsulas, você notará que o desdobramento foi escalado para uma única réplica:
bash
$ kubectl get podsEntão, o que acabou de acontecer?
Quando você encaminha o tráfego para o serviço da KEDA, o interceptor mantém um registro do número de solicitações HTTP pendentes que ainda não tiveram resposta.
O escalador da KEDA verifica periodicamente o tamanho da fila do interceptor e armazena as métricas.
O controlador KEDA monitora as métricas e aumenta ou diminui o número de réplicas conforme necessário. Neste caso, um único pedido está pendente - o suficiente para o controlador KEDA escalar o desdobramento para uma única réplica.
Você pode buscar o estado de uma fila de pedidos HTTP pendentes de um interceptor individual:
bash
$ kubectl proxy &
$ curl -L localhost:8001/api/v1/namespaces/default/services/keda-add-ons-http-interceptor-admin:9090/proxy/queue
{"example.com":0,"localhost:8080":0}Devido a este projeto, você deve ser cuidadoso na forma como encaminha o tráfego para suas aplicações.
A KEDA só pode escalar o tráfego se ele puder ser interceptado.
Se você tiver um controlador de entrada existente e desejar usá-lo para encaminhar o tráfego para seu aplicativo, você precisará alterar o manifesto de entrada para encaminhar o tráfego para o serviço HTTP add-on.
Vamos dar uma olhada em um exemplo.
Combinando o HTTP Add-On da KEDA com o Ingress
Você pode instalar o controlador de entrada nginx-ingress controller com Helm:
bash
$ helm upgrade --install ingress-nginx ingress-nginx \
--repo https://kubernetes.github.io/ingress-nginx \
--namespace ingress-nginx --create-namespaceVamos escrever um manifesto de entrada para encaminhar o tráfego para o podinfo:
yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: podinfo
spec:
ingressClassName: nginx
rules:
- host: example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: keda-add-ons-http-interceptor-proxy # <- this
port:
number: 8080Você pode recuperar o IP do equilibrador de carga com:
bash
LB_IP=$(kubectl get services -l "app.kubernetes.io/component=controller" -o jsonpath="{.items[0].status.loadBalancer.ingress
[0].ip}" -n ingress-nginx)Você pode finalmente fazer um pedido para o aplicativo com:
bash
curl $LB_IP -H "Host: example.com"Funcionou!
Se você esperar o tempo suficiente, notará que o desdobramento acabará sendo reduzido a zero.
Como isso se compara ao Serverless na Kubernetes?
Há várias diferenças significativas entre esta configuração e uma estrutura sem servidor em Kubernetes como o OpenFaaS:
- Com a KEDA, não há necessidade de rearquitetura ou de usar um SDK para implantar o aplicativo.
- As estruturas sem servidor cuidam do encaminhamento e atendimento de pedidos. Você só escreve a lógica.
- Com a KEDA, as implantações são contêineres regulares. Com uma estrutura sem servidor, isso nem sempre é verdade.
Quer ver esta escalada em ação? Inscreva-se em nossa série de webinar Kubernetes de escalonamento.




Comentários (5)
Very nice tutorial. In the case without the nginx ingress, can you explain how to access from the outside, instead of the localhost? I tried to use a NodePort service, but the port gets closed when the Interceptor is installed. The Interceptor proxy is a ClusterIP service. How can we access it from the outside? Is there any sort of kubectl port forwarding instruction?
Hi Rui! I forwarded your question to Daniele and here is his response:
It should work with NodePort, but you have to set the right header (i.e.
Host: example.com) when you make the request. There is no way for the interceptor to decide where the traffic should go without that.Muito bom o conteudo!!!
Where does NodeBalancer show up in this configuration? Does LKE take over that job?
Hi Lee – The NodeBalancer is created during the installation of the nginx-ingress controller. For a more detailed explanation of this process you can check out our guide titled Deploying NGINX Ingress on Linode Kubernetes Engine.
Once the NodeBalancer is provisioned it is controlled via LKE. We don’t recommend configuring the settings of your LKE NodeBalancers through the Cloud Manager.