

Este artículo forma parte de nuestra serie Scaling Kubernetes. Regístrese en para verlo en directo o acceder a la grabación, y consulte nuestros otros artículos de esta serie:
Reducir los costes de infraestructura se reduce a apagar los recursos cuando no se utilizan. Sin embargo, el reto es averiguar cómo encender estos recursos automáticamente cuando sea necesario. Repasemos los pasos necesarios para desplegar un clúster Kubernetes utilizando Linode Kubernetes Engine (LKE) y utilizar el Kubernetes Events-Driven Autoscaler (KEDA) para escalar a cero y volver.
Por qué escalar a cero
Imaginemos que estás ejecutando una aplicación razonablemente intensiva en recursos en Kubernetes y que solo se necesita durante las horas de trabajo.
Es posible que quieras apagarlo cuando la gente salga de la oficina y volver a encenderlo cuando empiece el día.
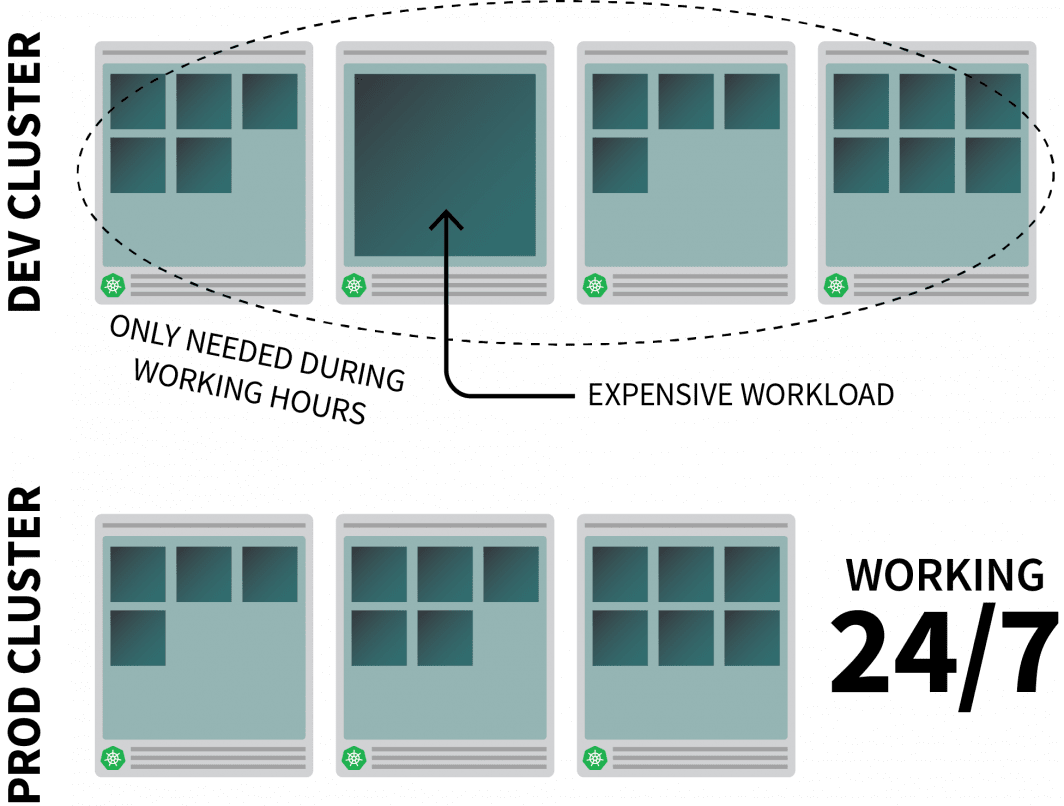
Mientras que usted podría utilizar un CronJob para escalar hacia arriba y hacia abajo la instancia, esta solución es un parche que sólo puede ejecutarse en un horario preestablecido.
¿Qué ocurre durante el fin de semana? ¿Y los días festivos? ¿O cuando el equipo está de baja por enfermedad?
En lugar de generar una lista de reglas cada vez mayor, puede escalar sus cargas de trabajo en función del tráfico. Cuando el tráfico aumenta, puede escalar las réplicas. Si no hay tráfico, puedes apagar la aplicación. Si la aplicación está apagada y hay una nueva solicitud entrante, Kubernetes lanzará al menos una única réplica para manejar el tráfico.

A continuación, vamos a hablar de cómo hacerlo:
- interceptar todo el tráfico hacia sus aplicaciones;
- controlar el tráfico; y
- configurar el autoescalador para ajustar el número de réplicas o desactivar las aplicaciones.
Si prefieres leer el código de este tutorial, puedes hacerlo en el GitHub de LearnK8s.
Creación de un clúster
Empecemos por crear un clúster Kubernetes.
Los siguientes comandos se pueden utilizar para crear el clúster y guardar el archivo kubeconfig.
bash
$ linode-cli lke cluster-create \
--label cluster-manager \
--region eu-west \
--k8s_version 1.23
$ linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfigPuede comprobar que la instalación se ha realizado correctamente con:
bash
$ kubectl get pods -A --kubeconfig=kubeconfigExportar el archivo kubeconfig con una variable de entorno suele ser más conveniente.
Puedes hacerlo con:
bash
$ export KUBECONFIG=${PWD}/kubeconfig
$ kubectl get podsAhora vamos a desplegar una aplicación.
Desplegar una aplicación
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
spec:
containers:
- name: podinfo
image: stefanprodan/podinfo
ports:
- containerPort: 9898
---
apiVersion: v1
kind: Service
metadata:
name: podinfo
spec:
ports:
- port: 80
targetPort: 9898
selector:
app: podinfoPuede enviar el archivo YAML con:
terminal|command=1|title=bash
$ kubectl apply -f 1-deployment.yamlY puedes visitar la aplicación con:
Abra su navegador a localhost:8080.
bash
$ kubectl port-forward svc/podinfo 8080:80En este punto, deberías ver la aplicación.
A continuación, vamos a instalar KEDA, el autoescalador.
KEDA - el autoescalador de Kubernetes impulsado por eventos
Kubernetes ofrece el Horizontal Pod Autoscaler (HPA) como controlador para aumentar y disminuir las réplicas dinámicamente.
Por desgracia, la HPA tiene algunos inconvenientes:
- No funciona de forma inmediata: es necesario instalar un servidor de métricas para agregar y exponer las métricas.
- No escala a cero réplicas.
- Escala las réplicas en función de las métricas y no intercepta el tráfico HTTP.
Afortunadamente, no tienes que usar el autoescalador oficial, sino que puedes usar KEDA en su lugar.
KEDA es un autoescalador formado por tres componentes:
- Un escalador
- Un adaptador de métricas
- Un controlador
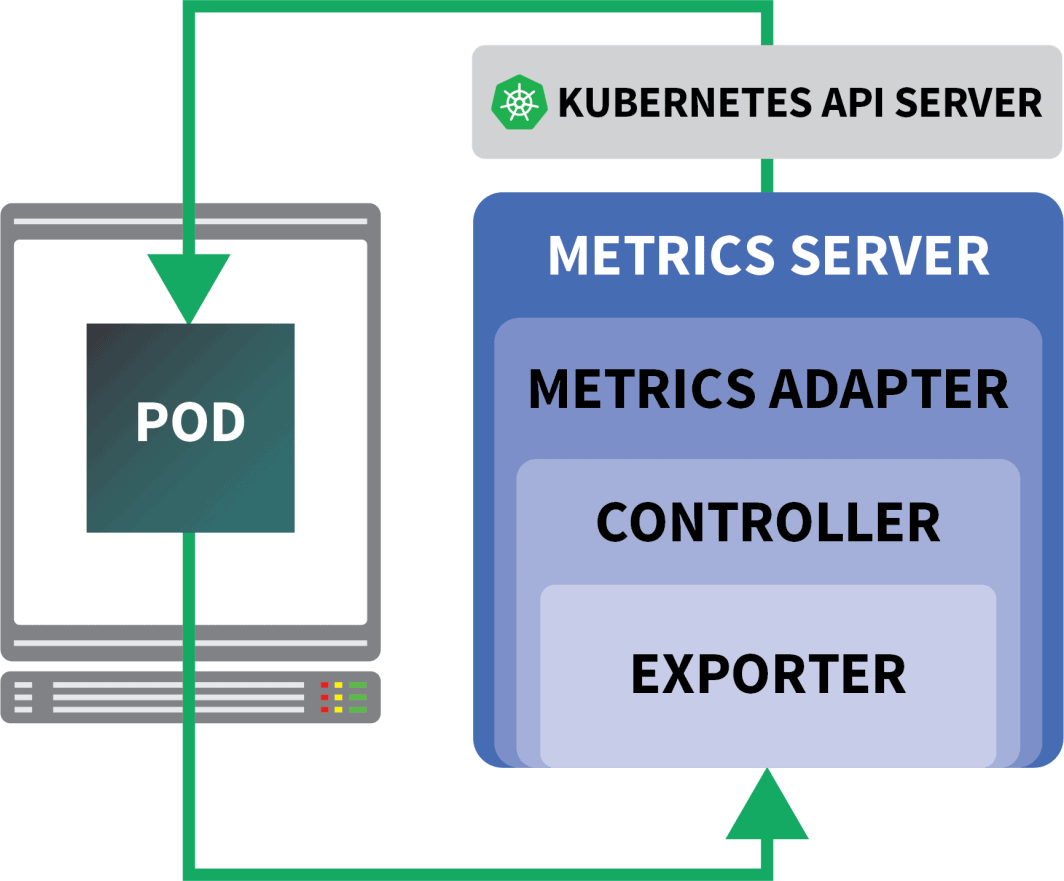
Los escaladores son como adaptadores que pueden recoger métricas de las bases de datos, corredores de mensajes, sistemas de telemetría, etc.
Por ejemplo, el HTTP Scaler es un adaptador que puede interceptar y recoger el tráfico HTTP.
Puedes encontrar un ejemplo de escalador usando RabbitMQ aquí.
El adaptador de métricas es responsable de exponer las métricas recogidas por los escaladores en un formato que el pipeline de métricas de Kubernetes pueda consumir.
Y por último, el controlador pega todos los componentes:
- Recopila las métricas utilizando el adaptador y las expone a la API de métricas.
- Registra y gestiona las definiciones de recursos personalizados (CRD) específicas de KEDA, es decir, ScaledObject, TriggerAuthentication, etc.
- Crea y gestiona el Autoscaler Horizontal Pod en su nombre.
Esa es la teoría, pero veamos cómo funciona en la práctica.
Una forma más rápida de instalar el controlador es usar Helm.
Puede encontrar las instrucciones de instalación en el sitio web oficial de Helm.
bash
$ helm repo add kedacore https://kedacore.github.io/charts
$ helm install keda kedacore/kedaKEDA no viene con un escalador HTTP por defecto, por lo que tendrás que instalarlo por separado:
bash
$ helm install http-add-on kedacore/keda-add-ons-httpLlegados a este punto, estás preparado para escalar la aplicación.
Definición de una estrategia de autoescalado
El complemento KEDA HTTP expone un CRD en el que se puede describir cómo debe escalarse la aplicación.
Veamos un ejemplo:
yaml
kind: HTTPScaledObject
apiVersion: http.keda.sh/v1alpha1
metadata:
name: podinfo
spec:
host: example.com
targetPendingRequests: 100
scaleTargetRef:
deployment: podinfo
service: podinfo
port: 80
replicas:
min: 0
max: 10Este archivo indica a los interceptores que reenvíen las solicitudes de example. com al servicio podinfo.
También incluye el nombre del despliegue que debe ser escalado - en este caso, podinfo.
Enviemos el YAML al cluster con:
bash
$ kubectl apply -f scaled-object.yamlEn cuanto envíe la definición, ¡el pod se borrará!
¿Pero por qué?
Después de crear un HTTPScaledObject, KEDA escala inmediatamente el despliegue a cero ya que no hay tráfico.
Debes enviar peticiones HTTP a la aplicación para escalarla.
Vamos a probarlo conectándonos al servicio y emitiendo una petición.
bash
$ kubectl port-forward svc/podinfo 8080:80¡El comando se cuelga!
Tiene sentido; no hay vainas que sirvan la petición.
Pero, ¿por qué Kubernetes no escala el despliegue a 1?
Prueba del interceptor KEDA
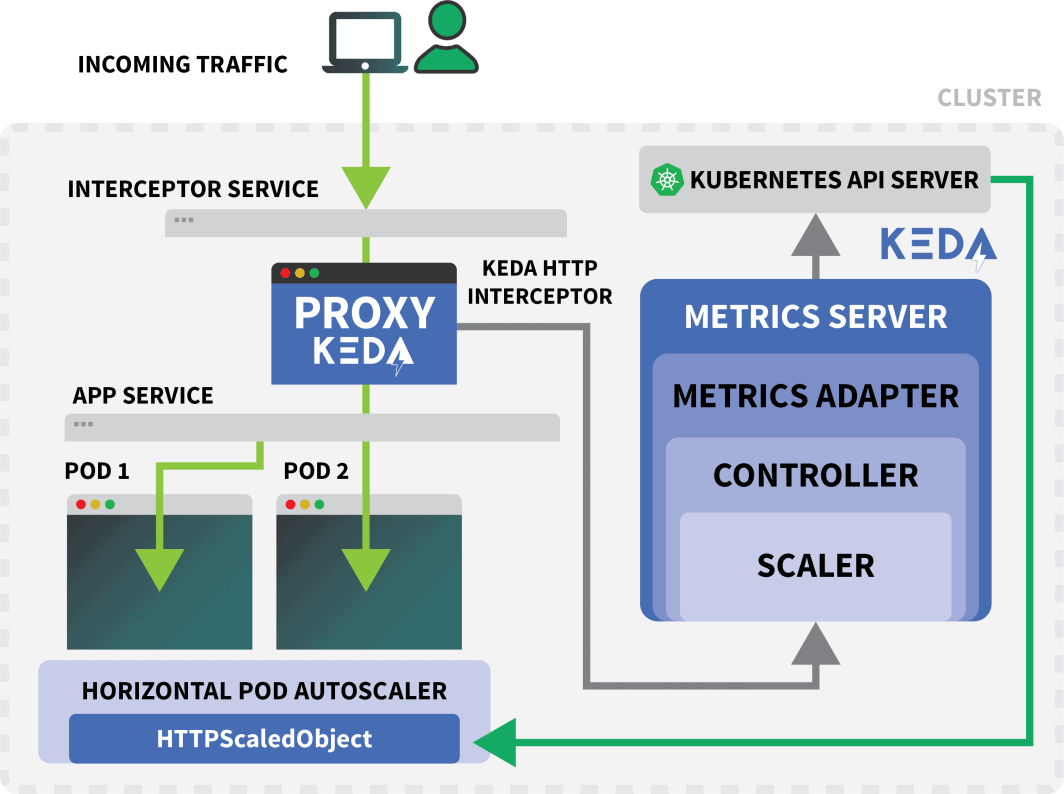
Un servicio Kubernetes llamado keda-add-ons-http-interceptor-proxy se creó cuando se utilizó Helm para instalar el complemento.
Para que el autoescalado funcione adecuadamente, el tráfico HTTP debe pasar primero por ese servicio.
Puede utilizar kubectl port-forward para probarlo:
shell
$ kubectl port-forward svc/keda-add-ons-http-interceptor-proxy 8080:8080Esta vez, no puedes visitar la URL en tu navegador.
Un solo interceptor KEDA HTTP puede gestionar varias implantaciones.
Entonces, ¿cómo sabe dónde dirigir el tráfico?
yaml
kind: HTTPScaledObject
apiVersion: http.keda.sh/v1alpha1
metadata:
name: podinfo
spec:
host: example.com
targetPendingRequests: 100
scaleTargetRef:
deployment: podinfo
service: podinfo
port: 80
replicas:
min: 0
max: 10El HTTPScaledObject tiene un campo host que se utiliza precisamente para eso.
En este ejemplo, imagine que la solicitud proviene de ejemplo.com.
Puede hacerlo configurando la cabecera Host:
bash
$ curl localhost:8080 -H 'Host: example.com'Recibirá una respuesta, aunque con un ligero retraso.
Si inspecciona los pods, observará que el despliegue fue escalado a una sola réplica:
bash
$ kubectl get pods¿Qué acaba de pasar?
Cuando se dirige el tráfico al servicio de KEDA, el interceptor lleva la cuenta del número de peticiones HTTP pendientes que aún no han tenido respuesta.
El escalador KEDA comprueba periódicamente el tamaño de la cola del interceptor y almacena las métricas.
El controlador KEDA supervisa las métricas y aumenta o disminuye el número de réplicas según sea necesario. En este caso, hay una sola solicitud pendiente, suficiente para que el controlador KEDA escale el despliegue a una sola réplica.
Puedes obtener el estado de la cola de peticiones HTTP pendientes de un interceptor individual con:
bash
$ kubectl proxy &
$ curl -L localhost:8001/api/v1/namespaces/default/services/keda-add-ons-http-interceptor-admin:9090/proxy/queue
{"example.com":0,"localhost:8080":0}Debido a este diseño, debes tener cuidado con la forma de dirigir el tráfico a tus aplicaciones.
KEDA sólo puede escalar el tráfico si puede ser interceptado.
Si tiene un controlador de entrada existente y desea utilizarlo para reenviar el tráfico a su aplicación, tendrá que modificar el manifiesto de entrada para reenviar el tráfico al servicio complementario HTTP.
Veamos un ejemplo.
Combinación del complemento HTTP de KEDA con el Ingress
Puede instalar el controlador nginx-ingress con Helm:
bash
$ helm upgrade --install ingress-nginx ingress-nginx \
--repo https://kubernetes.github.io/ingress-nginx \
--namespace ingress-nginx --create-namespaceEscribamos un manifiesto de entrada para enrutar el tráfico a podinfo:
yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: podinfo
spec:
ingressClassName: nginx
rules:
- host: example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: keda-add-ons-http-interceptor-proxy # <- this
port:
number: 8080Puede recuperar la IP del equilibrador de carga con:
bash
LB_IP=$(kubectl get services -l "app.kubernetes.io/component=controller" -o jsonpath="{.items[0].status.loadBalancer.ingress
[0].ip}" -n ingress-nginx)Finalmente puedes hacer una petición a la aplicación con:
bash
curl $LB_IP -H "Host: example.com"¡Funcionó!
Si esperas lo suficiente, notarás que el despliegue acabará por reducirse a cero.
¿Cómo se compara esto con Serverless en Kubernetes?
Hay varias diferencias significativas entre esta configuración y un marco sin servidor en Kubernetes como OpenFaaS:
- Con KEDA, no es necesario volver a crear una arquitectura o utilizar un SDK para desplegar la aplicación.
- Los frameworks sin servidor se encargan de enrutar y servir las peticiones. Tú solo escribes la lógica.
- Con KEDA, los despliegues son contenedores regulares. Con un framework sin servidor, eso no siempre es cierto.
¿Quiere ver este escalado en acción? Regístrese en nuestra serie de seminarios web sobre el escalado de Kubernetes.



Comentarios (5)
Very nice tutorial. In the case without the nginx ingress, can you explain how to access from the outside, instead of the localhost? I tried to use a NodePort service, but the port gets closed when the Interceptor is installed. The Interceptor proxy is a ClusterIP service. How can we access it from the outside? Is there any sort of kubectl port forwarding instruction?
Hi Rui! I forwarded your question to Daniele and here is his response:
It should work with NodePort, but you have to set the right header (i.e.
Host: example.com) when you make the request. There is no way for the interceptor to decide where the traffic should go without that.Muito bom o conteudo!!!
Where does NodeBalancer show up in this configuration? Does LKE take over that job?
Hi Lee – The NodeBalancer is created during the installation of the nginx-ingress controller. For a more detailed explanation of this process you can check out our guide titled Deploying NGINX Ingress on Linode Kubernetes Engine.
Once the NodeBalancer is provisioned it is controlled via LKE. We don’t recommend configuring the settings of your LKE NodeBalancers through the Cloud Manager.