

Este artículo forma parte de nuestra serie Scaling Kubernetes. Regístrese en para verlo en directo o acceder a la grabación, y consulte nuestros otros artículos de esta serie:
Cuando su clúster se queda sin recursos, el Cluster Autoscaler aprovisiona un nuevo nodo y lo añade al clúster. Si ya eres usuario de Kubernetes, habrás notado que crear y añadir un nodo al clúster lleva varios minutos.
Durante este tiempo, su aplicación puede verse fácilmente desbordada de conexiones porque no puede escalar más.

¿Cómo se puede solucionar el largo tiempo de espera?
Escalamiento proactivo, o:
- entender cómo funciona el cluster autoscaler y maximizar su utilidad;
- utilizando el programador de Kubernetes para asignar pods a un nodo; y
- aprovisionamiento de nodos trabajadores de forma proactiva para evitar un mal escalado.
Si prefieres leer el código de este tutorial, puedes encontrarlo en el GitHub de LearnK8s.
Cómo funciona el Cluster Autoscaler en Kubernetes
El Cluster Autoscaler no se fija en la disponibilidad de la memoria o la CPU cuando activa el autoescalado. En su lugar, el Cluster Autoscaler reacciona a los eventos y comprueba si hay pods no programables. Un pod es no programable cuando el programador no puede encontrar un nodo que pueda acomodarlo.
Vamos a probarlo creando un cluster.
bash
$ linode-cli lke cluster-create \
--label learnk8s \
--region eu-west \
--k8s_version 1.23 \
--node_pools.count 1 \
--node_pools.type g6-standard-2 \
--node_pools.autoscaler.enabled enabled \
--node_pools.autoscaler.max 10 \
--node_pools.autoscaler.min 1 \
$ linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfigDebes prestar atención a los siguientes detalles:
- cada nodo tiene 4GB de memoria y 2 vCPU (es decir, `g6-standard-2`);
- hay un solo nodo en el clúster; y
- el autoescalador del clúster está configurado para crecer de 1 a 10 nodos.
Puede comprobar que la instalación se ha realizado correctamente con:
bash
$ kubectl get pods -A --kubeconfig=kubeconfigExportar el archivo kubeconfig con una variable de entorno suele ser más conveniente.
Puedes hacerlo con:
bash
$ export KUBECONFIG=${PWD}/kubeconfig
$ kubectl get pods¡Excelente!
Despliegue de una aplicación
Despleguemos una aplicación que requiere 1GB de memoria y 250m* de CPU.Note: m = thousandth of a core, so 250m = 25% of the CPU
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
replicas: 1
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
spec:
containers:
- name: podinfo
image: stefanprodan/podinfo
ports:
- containerPort: 9898
resources:
requests:
memory: 1G
cpu: 250mPuede enviar el recurso al clúster con:
bash
$ kubectl apply -f podinfo.yamlEn cuanto lo haga, podrá notar algunas cosas. En primer lugar, tres vainas se ejecutan casi inmediatamente, y una está pendiente.

Y luego:
- después de unos minutos, el autoescalador crea un nodo adicional; y
- el cuarto pod se despliega en el nuevo nodo.

¿Por qué el cuarto pod no está desplegado en el primer nodo? Vamos a indagar en los recursos asignables.
Recursos asignables en los nodos de Kubernetes
Los pods desplegados en su clúster Kubernetes consumen recursos de memoria, CPU y almacenamiento.
Sin embargo, en el mismo nodo, el sistema operativo y el kubelet requieren memoria y CPU.
En un nodo trabajador de Kubernetes, la memoria y la CPU se dividen en:
- Recursos necesarios para ejecutar el sistema operativo y los demonios del sistema como SSH, systemd, etc.
- Recursos necesarios para ejecutar los agentes de Kubernetes, como el Kubelet, el tiempo de ejecución de contenedores, el detector de problemas de nodos, etc.
- Recursos disponibles para los Pods.
- Recursos reservados para el umbral de desalojo.
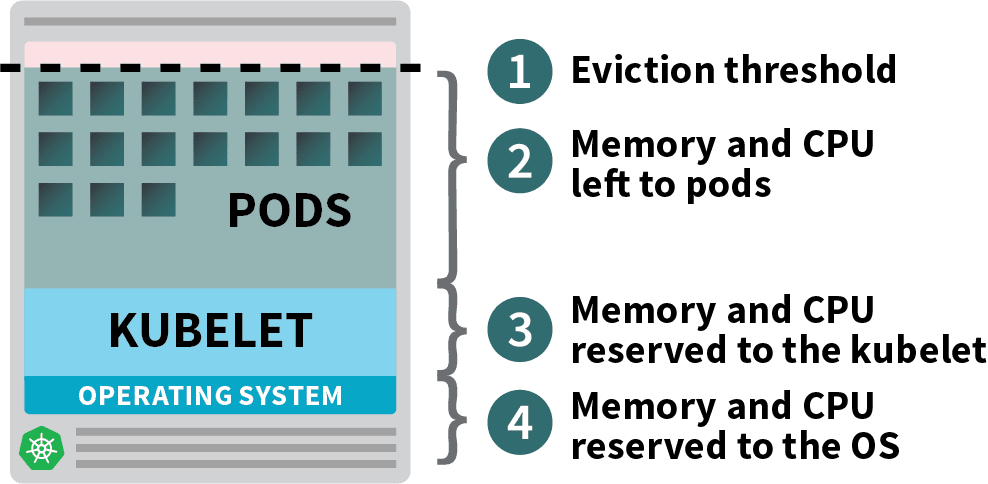
Si su clúster ejecuta un DaemonSet como kube-proxy, debe reducir aún más la memoria y la CPU disponibles.
Así que vamos a bajar los requisitos para asegurarnos de que todos los pods pueden caber en un solo nodo:
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
replicas: 4
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
spec:
containers:
- name: podinfo
image: stefanprodan/podinfo
ports:
- containerPort: 9898
resources:
requests:
memory: 0.8G # <- lower memory
cpu: 200m # <- lower CPUPuede modificar el despliegue con:
bash
$ kubectl apply -f podinfo.yamlSeleccionar la cantidad correcta de CPU y memoria para optimizar tus instancias puede ser complicado. La calculadora de la herramienta Learnk8s podría ayudarte a hacerlo más rápidamente.
Has solucionado un problema, pero ¿qué pasa con el tiempo que se tarda en crear un nuevo nodo?
Tarde o temprano, tendrá más de cuatro réplicas. ¿Realmente hay que esperar unos minutos antes de que se creen las nuevas vainas?
La respuesta corta es sí.
Linode tiene que crear una máquina virtual desde cero, aprovisionarla y conectarla al clúster. El proceso puede durar fácilmente más de dos minutos.
Pero hay una alternativa.
Podría crear proactivamente nodos ya provisionados cuando los necesite.
Por ejemplo: puede configurar el autoescalador para que siempre tenga un nodo de reserva. Cuando los pods se despliegan en el nodo de repuesto, el autoescalador puede crear más de forma proactiva. Desafortunadamente, el autoescalador no tiene esta funcionalidad incorporada, pero puede recrearla fácilmente.
Se puede crear un pod que tenga peticiones iguales al recurso del nodo:
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning
spec:
replicas: 1
selector:
matchLabels:
run: overprovisioning
template:
metadata:
labels:
run: overprovisioning
spec:
containers:
- name: pause
image: k8s.gcr.io/pause
resources:
requests:
cpu: 900m
memory: 3.8GPuede enviar el recurso al clúster con:
bash
kubectl apply -f placeholder.yamlEsta vaina no hace absolutamente nada.
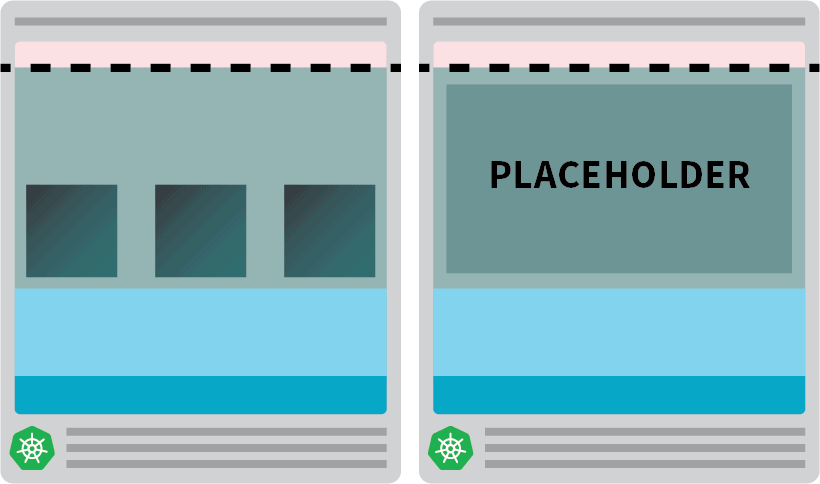
Sólo mantiene el nodo totalmente ocupado.
El siguiente paso es asegurarse de que el pod marcador de posición sea desalojado tan pronto como haya una carga de trabajo que necesite ser escalada.
Para ello, puede utilizar una clase prioritaria.
yaml
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: overprovisioning
value: -1
globalDefault: false
description: "Priority class used by overprovisioning."
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning
spec:
replicas: 1
selector:
matchLabels:
run: overprovisioning
template:
metadata:
labels:
run: overprovisioning
spec:
priorityClassName: overprovisioning # <--
containers:
- name: pause
image: k8s.gcr.io/pause
resources:
requests:
cpu: 900m
memory: 3.8GY volver a enviarlo al clúster con:
bash
kubectl apply -f placeholder.yamlAhora la configuración está completa.
Es posible que tenga que esperar un poco para que el autoescalador cree el nodo, pero en este punto, debería tener dos nodos:
- Un nodo con cuatro vainas.
- Otro con una vaina de marcador de posición.
¿Qué sucede cuando se escala el despliegue a 5 réplicas? Habrá que esperar a que el autoescalador cree un nuevo nodo?
Probemos con:
bash
kubectl scale deployment/podinfo --replicas=5Debes observar:
- El quinto pod se crea inmediatamente, y está en estado de ejecución en menos de 10 segundos.
- La vaina del marcador de posición fue desalojada para hacer espacio para la vaina.

Y luego:
- El autoescalador del clúster se dio cuenta de que el pod de marcador de posición estaba pendiente y aprovisionó un nuevo nodo.
- El pod marcador de posición se despliega en el nodo recién creado.
¿Por qué crear proactivamente un solo nodo cuando podría tener más?
Puede escalar el pod de marcador de posición a varias réplicas. Cada réplica preaprovisionará un nodo Kubernetes listo para aceptar cargas de trabajo estándar. Sin embargo, esos nodos siguen contando en su factura de la nube, pero se quedan inactivos y no hacen nada. Por lo tanto, debe tener cuidado y no crear demasiados.
Combinación del Cluster Autoscaler con el Pod Autoscaler Horizontal
Para entender la implicación de esta técnica, combinemos el autoescalador de clústeres con el autoescalador horizontal de vainas (HPA). El HPA está diseñado para aumentar las réplicas en sus despliegues.
A medida que su aplicación recibe más tráfico, puede hacer que el autoescalador ajuste el número de réplicas para manejar más solicitudes.
Cuando los pods agoten todos los recursos disponibles, el autoescalador del clúster activará la creación de un nuevo nodo para que el HPA pueda seguir creando más réplicas.
Vamos a probarlo creando un nuevo cluster:
bash
$ linode-cli lke cluster-create \
--label learnk8s-hpa \
--region eu-west \
--k8s_version 1.23 \
--node_pools.count 1 \
--node_pools.type g6-standard-2 \
--node_pools.autoscaler.enabled enabled \
--node_pools.autoscaler.max 10 \
--node_pools.autoscaler.min 3 \
$ linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfig-hpaPuede comprobar que la instalación se ha realizado correctamente con:
bash
$ kubectl get pods -A --kubeconfig=kubeconfig-hpaExportar el archivo kubeconfig con una variable de entorno es más conveniente.
Puedes hacerlo con:
bash
$ export KUBECONFIG=${PWD}/kubeconfig-hpa
$ kubectl get pods¡Excelente!
Vamos a utilizar Helm para instalar Prometheus y raspar las métricas de los despliegues.
Puedes encontrar las instrucciones sobre cómo instalar Helm en su sitio web oficial.
bash
$ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
$ helm install prometheus prometheus-community/prometheusKubernetes ofrece al HPA un controlador para aumentar y disminuir las réplicas de forma dinámica.
Por desgracia, la HPA tiene algunos inconvenientes:
- No funciona de forma inmediata. Es necesario instalar un servidor de métricas para agregar y exponer las métricas.
- No se pueden utilizar consultas PromQL de forma inmediata.
Afortunadamente, puede utilizar KEDA, que amplía el controlador HPA con algunas funciones adicionales (incluida la lectura de métricas de Prometheus).
KEDA es un autoescalador formado por tres componentes:
- Un escalador
- Un adaptador de métricas
- Un controlador
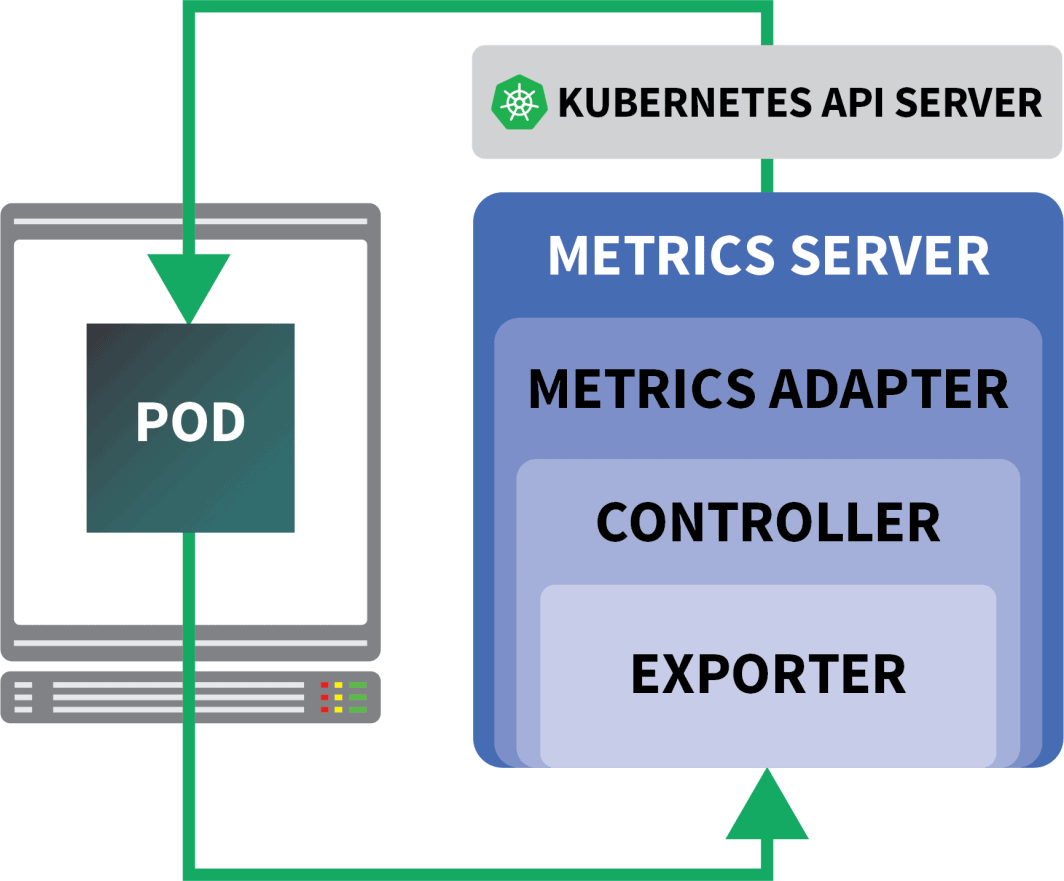
Puede instalar KEDA con Helm:
bash
$ helm repo add kedacore https://kedacore.github.io/charts
$ helm install keda kedacore/kedaAhora que Prometheus y KEDA están instalados, vamos a crear un despliegue.
Para este experimento, utilizarás una aplicación diseñada para manejar un número fijo de peticiones por segundo.
Cada pod puede procesar como máximo diez peticiones por segundo. Si el pod recibe la undécima petición, dejará la petición pendiente y la procesará más tarde.
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
replicas: 4
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
annotations:
prometheus.io/scrape: "true"
spec:
containers:
- name: podinfo
image: learnk8s/rate-limiter:1.0.0
imagePullPolicy: Always
args: ["/app/index.js", "10"]
ports:
- containerPort: 8080
resources:
requests:
memory: 0.9G
---
apiVersion: v1
kind: Service
metadata:
name: podinfo
spec:
ports:
- port: 80
targetPort: 8080
selector:
app: podinfoPuede enviar el recurso al clúster con:
bash
$ kubectl apply -f rate-limiter.yamlPara generar un poco de tráfico, utilizará Locust.
La siguiente definición YAML crea un cluster de pruebas de carga distribuido:
yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: locust-script
data:
locustfile.py: |-
from locust import HttpUser, task, between
class QuickstartUser(HttpUser):
@task
def hello_world(self):
self.client.get("/", headers={"Host": "example.com"})
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: locust
spec:
selector:
matchLabels:
app: locust-primary
template:
metadata:
labels:
app: locust-primary
spec:
containers:
- name: locust
image: locustio/locust
args: ["--master"]
ports:
- containerPort: 5557
name: comm
- containerPort: 5558
name: comm-plus-1
- containerPort: 8089
name: web-ui
volumeMounts:
- mountPath: /home/locust
name: locust-script
volumes:
- name: locust-script
configMap:
name: locust-script
---
apiVersion: v1
kind: Service
metadata:
name: locust
spec:
ports:
- port: 5557
name: communication
- port: 5558
name: communication-plus-1
- port: 80
targetPort: 8089
name: web-ui
selector:
app: locust-primary
type: LoadBalancer
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: locust
spec:
selector:
matchLabels:
app: locust-worker
template:
metadata:
labels:
app: locust-worker
spec:
containers:
- name: locust
image: locustio/locust
args: ["--worker", "--master-host=locust"]
volumeMounts:
- mountPath: /home/locust
name: locust-script
volumes:
- name: locust-script
configMap:
name: locust-scriptPuedes presentarla al clúster con:
bash
$ kubectl locust.yamlLocust dice lo siguiente locustfile.pyque se almacena en un ConfigMap:
py
from locust import HttpUser, task, between
class QuickstartUser(HttpUser):
@task
def hello_world(self):
self.client.get("/")El archivo no hace nada especial, aparte de hacer una petición a una URL. Para conectarse al panel de control de Locust, se necesita la dirección IP de su equilibrador de carga.
Puede recuperarlo con el siguiente comando:
bash
$ kubectl get service locust -o jsonpath='{.status.loadBalancer.ingress[0].ip}'Abre tu navegador e introduce esa dirección IP.
¡Excelente!
Falta una pieza: el Autoscaler Horizontal del Pod.
El autoescalador KEDA envuelve el autoescalador horizontal con un objeto específico llamado ScaledObject.
yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: podinfo
spec:
scaleTargetRef:
kind: Deployment
name: podinfo
minReplicaCount: 1
maxReplicaCount: 30
cooldownPeriod: 30
pollingInterval: 1
triggers:
- type: prometheus
metadata:
serverAddress: http://prometheus-server
metricName: connections_active_keda
query: |
sum(increase(http_requests_total{app="podinfo"}[60s]))
threshold: "480" # 8rps * 60sKEDA enlaza las métricas recogidas por Prometheus y las alimenta a Kubernetes.
Por último, crea un Horizontal Pod Autoscaler (HPA) con esas métricas.
Puede inspeccionar manualmente el HPA con:
bash
$ kubectl get hpa
$ kubectl describe hpa keda-hpa-podinfoPuedes presentar el objeto con:
bash
$ kubectl apply -f scaled-object.yamlEs el momento de probar si el escalado funciona.
En el panel de control de Locust, lance un experimento con la siguiente configuración:
- Número de usuarios:
300 - Tasa de desove:
0.4 - Anfitrión:
http://podinfo
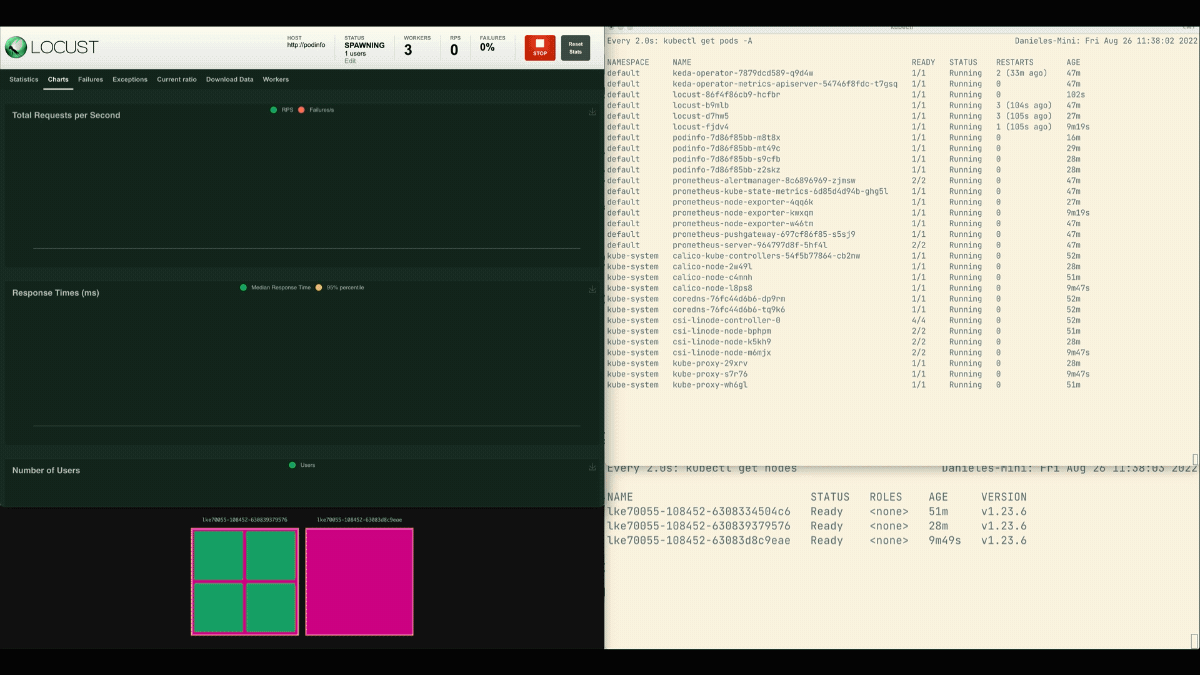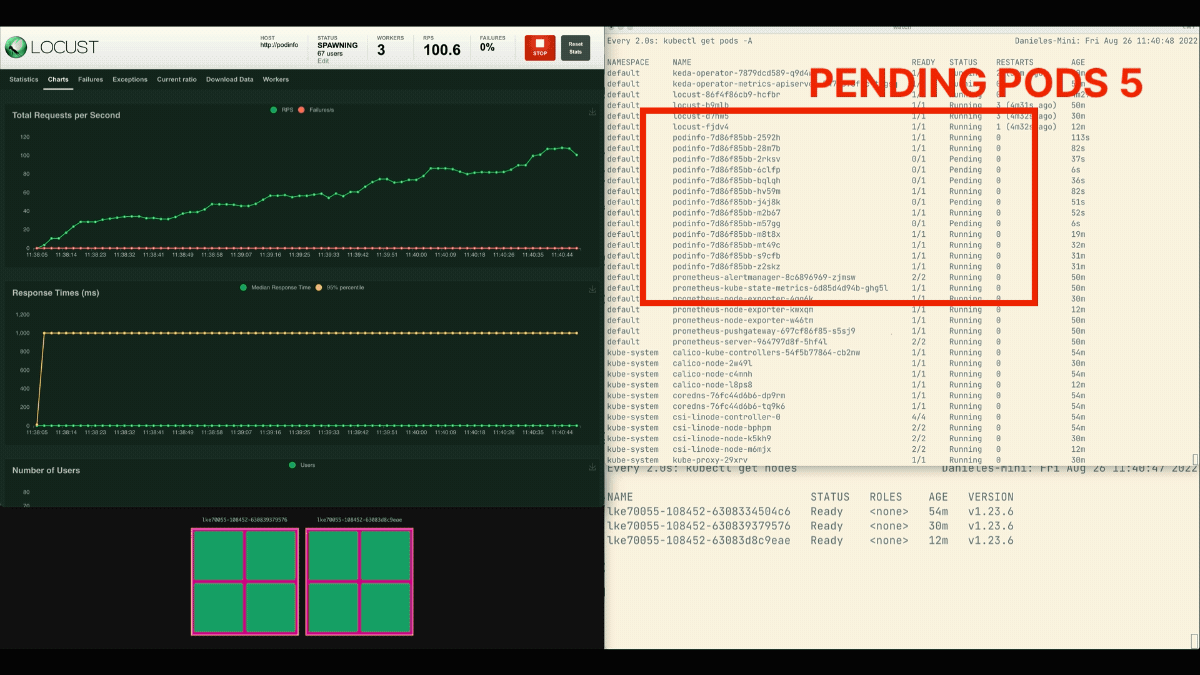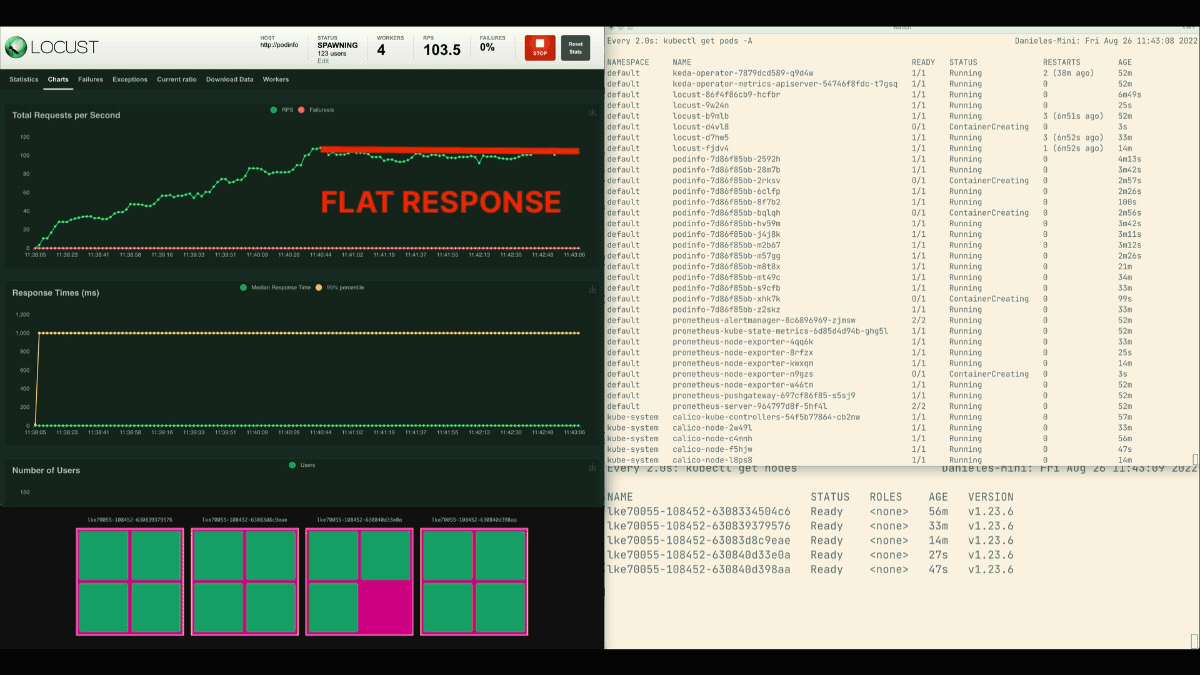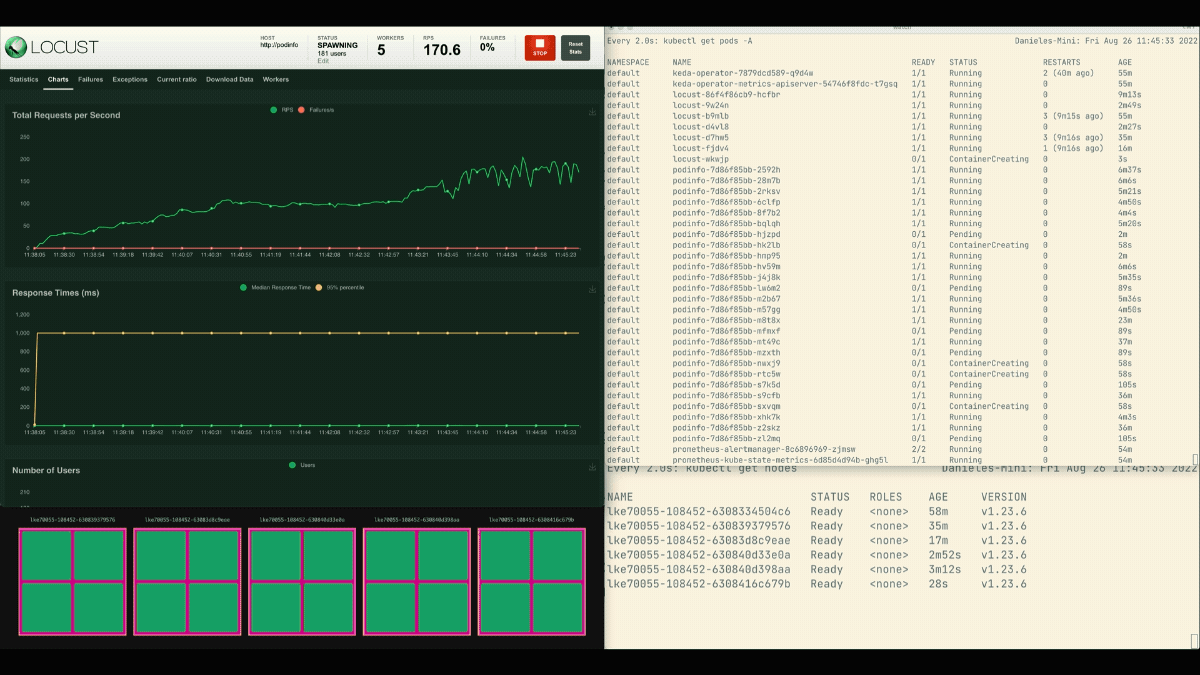
El número de réplicas va en aumento.
¡Excelente! ¿Pero te has dado cuenta?
Después de que el despliegue escale a 8 pods, tiene que esperar unos minutos antes de que se creen más pods en el nuevo nodo.
En este periodo, las peticiones por segundo se estancan porque las ocho réplicas actuales sólo pueden atender diez peticiones cada una.
Reduzcamos la escala y repitamos el experimento:
bash
kubectl scale deployment/podinfo --replicas=4 # or wait for the autoscaler to remove podsEsta vez, vamos a sobreaprovisionar el nodo con el pod marcador de posición:
yaml
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: overprovisioning
value: -1
globalDefault: false
description: "Priority class used by overprovisioning."
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning
spec:
replicas: 1
selector:
matchLabels:
run: overprovisioning
template:
metadata:
labels:
run: overprovisioning
spec:
priorityClassName: overprovisioning
containers:
- name: pause
image: k8s.gcr.io/pause
resources:
requests:
cpu: 900m
memory: 3.9GPuedes presentarla al clúster con:
bash
kubectl apply -f placeholder.yamlAbra el panel de control de Locust y repita el experimento con la siguiente configuración:
- Número de usuarios:
300 - Tasa de desove:
0.4 - Anfitrión:
http://podinfo
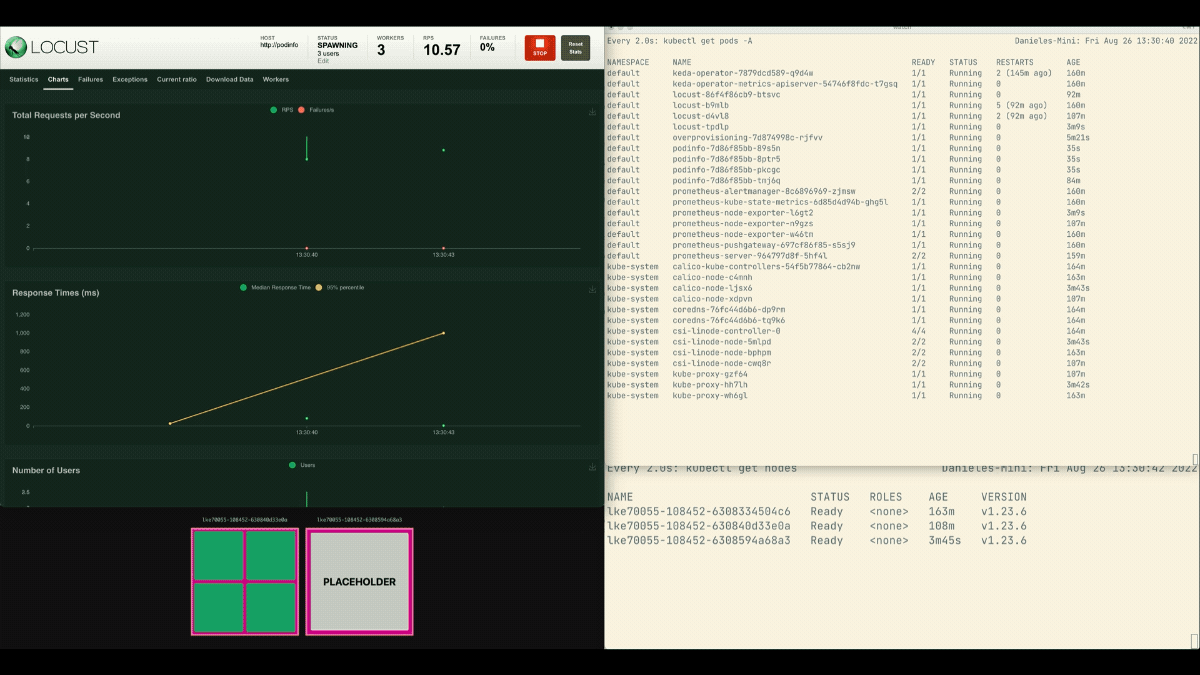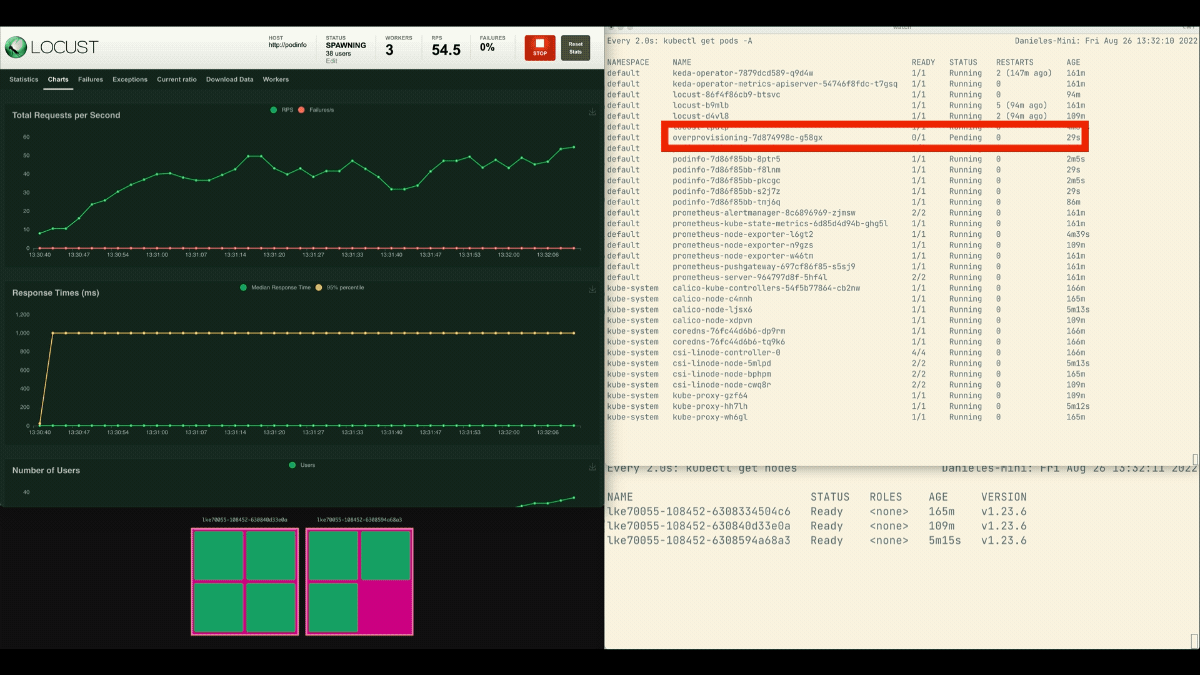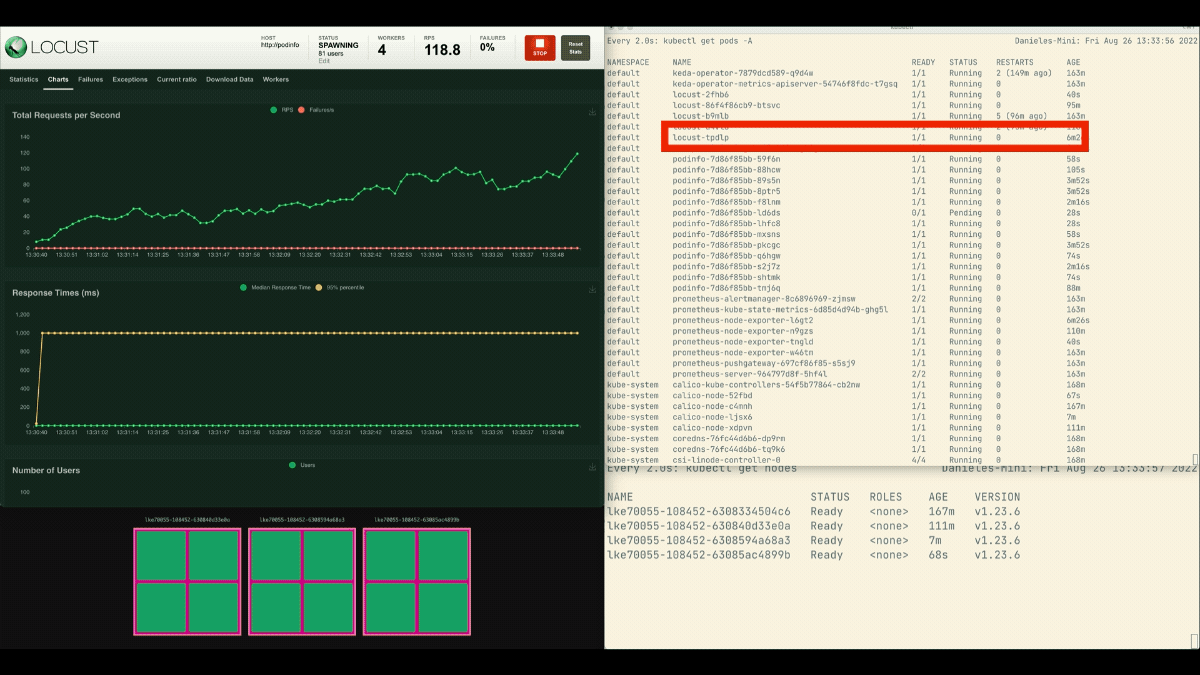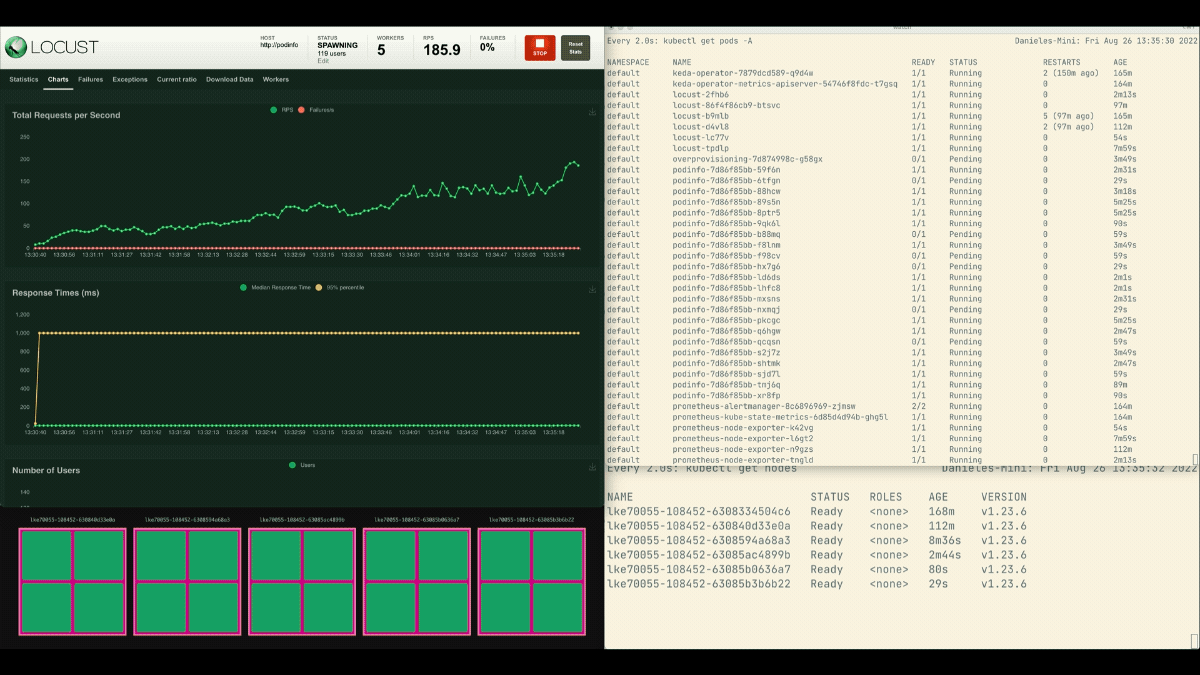
Esta vez, se crean nuevos nodos en segundo plano y las peticiones por segundo aumentan sin aplanarse. Un gran trabajo.
Recapitulemos lo aprendido en este post:
- el autoescalador de clústeres no hace un seguimiento del consumo de CPU o memoria. En su lugar, monitoriza los pods pendientes;
- puede crear un pod que utilice la memoria y la CPU totales disponibles para aprovisionar un nodo Kubernetes de forma proactiva;
- Los nodos Kubernetes tienen recursos reservados para el kubelet, el sistema operativo y el umbral de desalojo; y
- puede combinar Prometheus con KEDA para escalar su pod con una consulta PromQL.
¿Quiere seguir nuestra serie de seminarios web sobre el escalado de Kubernetes? Regístrese para empezar y aprenda más sobre el uso de KEDA para escalar clústeres Kubernetes a cero.




Comentarios