

Questo post fa parte della nostra serie Scaling Kubernetes. Registratevi per assistere dal vivo o accedere alla registrazione, e date un'occhiata agli altri post di questa serie:
Quando il cluster esaurisce le risorse, il Cluster Autoscaler crea un nuovo nodo e lo aggiunge al cluster. Se siete già utenti di Kubernetes, avrete notato che la creazione e l'aggiunta di un nodo al cluster richiede diversi minuti.
In questo periodo, l'applicazione può essere facilmente sommersa dalle connessioni perché non può scalare ulteriormente.

Come si può risolvere il lungo tempo di attesa?
Scalare in modo proattivo, oppure:
- comprendere il funzionamento dell'autoscaler del cluster e massimizzarne l'utilità;
- utilizzando lo scheduler di Kubernetes per assegnare i pod a un nodo; e
- il provisioning dei nodi worker in modo proattivo per evitare una scarsa scalabilità.
Se si preferisce leggere il codice di questa esercitazione, lo si può trovare su GitHub di LearnK8s.
Come funziona il Cluster Autoscaler in Kubernetes
Il Cluster Autoscaler non considera la disponibilità di memoria o CPU quando attiva l'autoscaling. Invece, il Cluster Autoscaler reagisce agli eventi e verifica la presenza di pod non programmabili. Un pod è non pianificabile quando lo scheduler non riesce a trovare un nodo in grado di ospitarlo.
Verifichiamo questo aspetto creando un cluster.
bash
$ linode-cli lke cluster-create \
--label learnk8s \
--region eu-west \
--k8s_version 1.23 \
--node_pools.count 1 \
--node_pools.type g6-standard-2 \
--node_pools.autoscaler.enabled enabled \
--node_pools.autoscaler.max 10 \
--node_pools.autoscaler.min 1 \
$ linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfigÈ necessario prestare attenzione ai seguenti dettagli:
- ogni nodo ha 4 GB di memoria e 2 vCPU (cioè `g6-standard-2`);
- c'è un singolo nodo nel cluster; e
- il cluster autoscaler è configurato per crescere da 1 a 10 nodi.
È possibile verificare che l'installazione sia avvenuta con successo con:
bash
$ kubectl get pods -A --kubeconfig=kubeconfigL'esportazione del file kubeconfig con una variabile d'ambiente è solitamente più conveniente.
È possibile farlo con:
bash
$ export KUBECONFIG=${PWD}/kubeconfig
$ kubectl get podsEccellente!
Distribuzione di un'applicazione
Distribuiamo un'applicazione che richiede 1 GB di memoria e 250 m* di CPU.Note: m = thousandth of a core, so 250m = 25% of the CPU
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
replicas: 1
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
spec:
containers:
- name: podinfo
image: stefanprodan/podinfo
ports:
- containerPort: 9898
resources:
requests:
memory: 1G
cpu: 250mÈ possibile inviare la risorsa al cluster con:
bash
$ kubectl apply -f podinfo.yamlNon appena lo si fa, si notano alcune cose. Innanzitutto, tre pod sono quasi subito in esecuzione e uno è in attesa.

E poi:
- dopo alcuni minuti, l'autoscaler crea un nodo aggiuntivo; e
- il quarto pod viene distribuito nel nuovo nodo.

Perché il quarto pod non è distribuito nel primo nodo? Analizziamo le risorse allocabili.
Risorse allocabili nei nodi Kubernetes
I pod distribuiti nel cluster Kubernetes consumano risorse di memoria, CPU e storage.
Tuttavia, sullo stesso nodo, il sistema operativo e il kubelet richiedono memoria e CPU.
In un nodo worker Kubernetes, la memoria e la CPU sono suddivise in:
- Risorse necessarie per l'esecuzione del sistema operativo e dei demoni di sistema come SSH, systemd, ecc.
- Risorse necessarie per l'esecuzione degli agenti Kubernetes, come Kubelet, il runtime dei container, il rilevatore di problemi dei nodi, ecc.
- Risorse disponibili per i Pod.
- Risorse riservate alla soglia di sfratto.
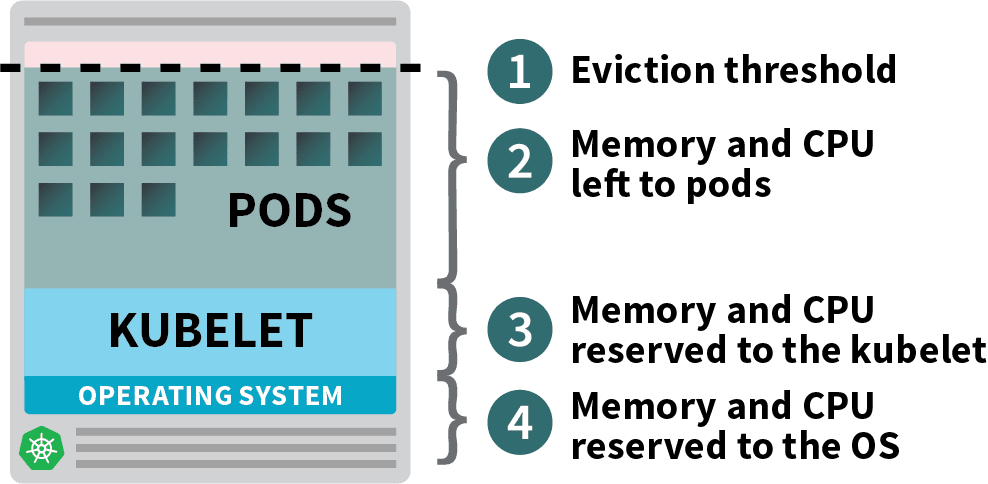
Se il cluster esegue un DaemonSet come kube-proxy, è necessario ridurre ulteriormente la memoria e la CPU disponibili.
Quindi abbassiamo i requisiti per assicurarci che tutti i pod possano stare in un singolo nodo:
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
replicas: 4
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
spec:
containers:
- name: podinfo
image: stefanprodan/podinfo
ports:
- containerPort: 9898
resources:
requests:
memory: 0.8G # <- lower memory
cpu: 200m # <- lower CPUÈ possibile modificare la distribuzione con:
bash
$ kubectl apply -f podinfo.yamlSelezionare la giusta quantità di CPU e memoria per ottimizzare le istanze può essere complicato. Il calcolatore dello strumento Learnk8s può aiutarvi a farlo più rapidamente.
Avete risolto un problema, ma che dire del tempo necessario per creare un nuovo nodo?
Prima o poi si avranno più di quattro repliche. È davvero necessario attendere qualche minuto prima che vengano creati i nuovi pod?
La risposta breve è sì.
Linode deve creare una macchina virtuale da zero, eseguire il provisioning e collegarla al cluster. Il processo potrebbe facilmente richiedere più di due minuti.
Ma c'è un'alternativa.
È possibile creare in modo proattivo nodi già provvisti quando se ne ha bisogno.
Ad esempio, si può configurare l'autoscaler in modo che abbia sempre un nodo di riserva. Quando i pod vengono distribuiti nel nodo di riserva, l'autoscaler può crearne altri in modo proattivo. Purtroppo l'autoscaler non dispone di questa funzionalità integrata, ma è possibile ricrearla facilmente.
È possibile creare un pod che ha richieste pari alla risorsa del nodo:
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning
spec:
replicas: 1
selector:
matchLabels:
run: overprovisioning
template:
metadata:
labels:
run: overprovisioning
spec:
containers:
- name: pause
image: k8s.gcr.io/pause
resources:
requests:
cpu: 900m
memory: 3.8GÈ possibile inviare la risorsa al cluster con:
bash
kubectl apply -f placeholder.yamlQuesta capsula non fa assolutamente nulla.
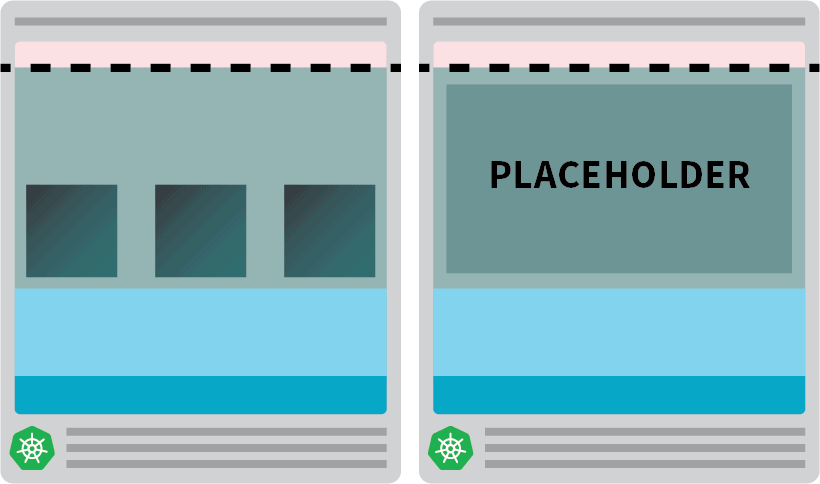
In questo modo il nodo rimane completamente occupato.
Il passo successivo consiste nell'assicurarsi che il pod placeholder venga eliminato non appena c'è un carico di lavoro da scalare.
A tal fine, è possibile utilizzare una classe di priorità.
yaml
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: overprovisioning
value: -1
globalDefault: false
description: "Priority class used by overprovisioning."
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning
spec:
replicas: 1
selector:
matchLabels:
run: overprovisioning
template:
metadata:
labels:
run: overprovisioning
spec:
priorityClassName: overprovisioning # <--
containers:
- name: pause
image: k8s.gcr.io/pause
resources:
requests:
cpu: 900m
memory: 3.8GE ripresentarlo al cluster con:
bash
kubectl apply -f placeholder.yamlOra la configurazione è completa.
Potrebbe essere necessario attendere un po' perché l'autoscaler crei il nodo, ma a questo punto si dovrebbero avere due nodi:
- Un nodo con quattro pod.
- Un altro con una capsula segnaposto.
Cosa succede quando si scala il deployment a 5 repliche? Si dovrà attendere che l'autoscaler crei un nuovo nodo?
Eseguiamo un test con:
bash
kubectl scale deployment/podinfo --replicas=5È necessario osservare:
- Il quinto pod viene creato immediatamente e si trova nello stato Running in meno di 10 secondi.
- Il baccello segnaposto è stato sfrattato per fare spazio al baccello.

E poi:
- L'autoscaler del cluster ha notato il pod placeholder in sospeso e ha effettuato il provisioning di un nuovo nodo.
- Il pod segnaposto viene distribuito nel nodo appena creato.
Perché creare in modo proattivo un solo nodo quando se ne possono avere di più?
È possibile scalare il pod placeholder a più repliche. Ogni replica pre-provvederà a un nodo Kubernetes pronto ad accettare carichi di lavoro standard. Tuttavia, questi nodi vengono comunque conteggiati nel conto del cloud, ma rimangono inattivi e non fanno nulla. Pertanto, è necessario prestare attenzione e non crearne troppi.
Combinazione dell'Autoscaler Cluster con l'Autoscaler Pod orizzontale
Per comprendere le implicazioni di questa tecnica, combiniamo l'autoscaler del cluster con l'Horizontal Pod Autoscaler (HPA). L'HPA è progettato per aumentare le repliche nelle distribuzioni.
Quando l'applicazione riceve più traffico, si può chiedere all'autoscaler di regolare il numero di repliche per gestire più richieste.
Quando i pod esauriscono tutte le risorse disponibili, l'autoscaler del cluster attiva la creazione di un nuovo nodo in modo che l'HPA possa continuare a creare altre repliche.
Verifichiamo questo creando un nuovo cluster:
bash
$ linode-cli lke cluster-create \
--label learnk8s-hpa \
--region eu-west \
--k8s_version 1.23 \
--node_pools.count 1 \
--node_pools.type g6-standard-2 \
--node_pools.autoscaler.enabled enabled \
--node_pools.autoscaler.max 10 \
--node_pools.autoscaler.min 3 \
$ linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfig-hpaÈ possibile verificare che l'installazione sia avvenuta con successo con:
bash
$ kubectl get pods -A --kubeconfig=kubeconfig-hpaL'esportazione del file kubeconfig con una variabile d'ambiente è più comoda.
È possibile farlo con:
bash
$ export KUBECONFIG=${PWD}/kubeconfig-hpa
$ kubectl get podsEccellente!
Usiamo Helm per installare Prometheus e raccogliere le metriche dalle distribuzioni.
Le istruzioni per installare Helm sono disponibili sul sito ufficiale.
bash
$ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
$ helm install prometheus prometheus-community/prometheusKubernetes offre all'HPA un controller per aumentare e ridurre le repliche in modo dinamico.
Purtroppo, l'HPA presenta alcuni inconvenienti:
- Non funziona in modo immediato. È necessario installare un server di metriche per aggregare ed esporre le metriche.
- Non è possibile utilizzare le query PromQL in modo immediato.
Fortunatamente, è possibile utilizzare KEDA, che estende il controllore HPA con alcune funzioni aggiuntive (tra cui la lettura delle metriche da Prometheus).
KEDA è un autoscaler composto da tre componenti:
- Uno scalatore
- Un adattatore di metriche
- Un controllore
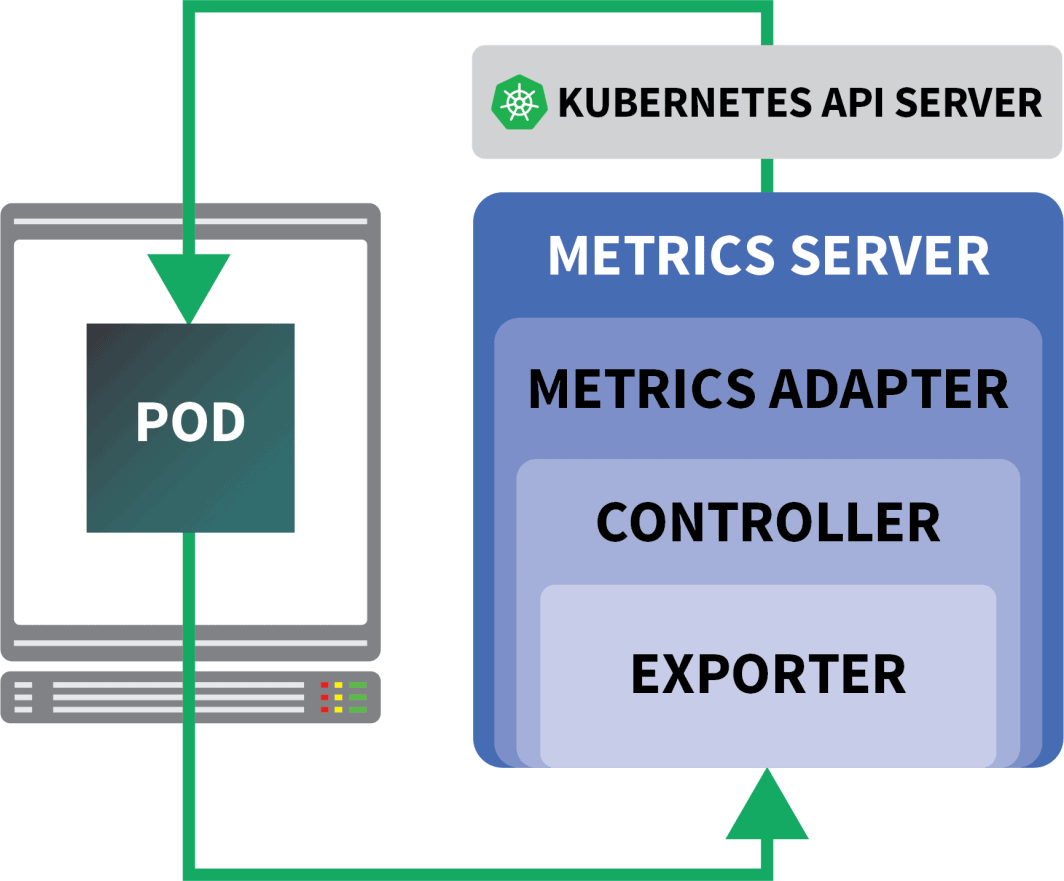
È possibile installare KEDA con Helm:
bash
$ helm repo add kedacore https://kedacore.github.io/charts
$ helm install keda kedacore/kedaOra che Prometheus e KEDA sono installati, creiamo un deployment.
Per questo esperimento, si utilizzerà un'applicazione progettata per gestire un numero fisso di richieste al secondo.
Ogni pod può elaborare al massimo dieci richieste al secondo. Se il pod riceve l'undicesima richiesta, la lascerà in sospeso e la elaborerà successivamente.
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
replicas: 4
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
annotations:
prometheus.io/scrape: "true"
spec:
containers:
- name: podinfo
image: learnk8s/rate-limiter:1.0.0
imagePullPolicy: Always
args: ["/app/index.js", "10"]
ports:
- containerPort: 8080
resources:
requests:
memory: 0.9G
---
apiVersion: v1
kind: Service
metadata:
name: podinfo
spec:
ports:
- port: 80
targetPort: 8080
selector:
app: podinfoÈ possibile inviare la risorsa al cluster con:
bash
$ kubectl apply -f rate-limiter.yamlPer generare traffico, utilizzerete Locust.
La seguente definizione YAML crea un cluster di test di carico distribuito:
yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: locust-script
data:
locustfile.py: |-
from locust import HttpUser, task, between
class QuickstartUser(HttpUser):
@task
def hello_world(self):
self.client.get("/", headers={"Host": "example.com"})
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: locust
spec:
selector:
matchLabels:
app: locust-primary
template:
metadata:
labels:
app: locust-primary
spec:
containers:
- name: locust
image: locustio/locust
args: ["--master"]
ports:
- containerPort: 5557
name: comm
- containerPort: 5558
name: comm-plus-1
- containerPort: 8089
name: web-ui
volumeMounts:
- mountPath: /home/locust
name: locust-script
volumes:
- name: locust-script
configMap:
name: locust-script
---
apiVersion: v1
kind: Service
metadata:
name: locust
spec:
ports:
- port: 5557
name: communication
- port: 5558
name: communication-plus-1
- port: 80
targetPort: 8089
name: web-ui
selector:
app: locust-primary
type: LoadBalancer
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: locust
spec:
selector:
matchLabels:
app: locust-worker
template:
metadata:
labels:
app: locust-worker
spec:
containers:
- name: locust
image: locustio/locust
args: ["--worker", "--master-host=locust"]
volumeMounts:
- mountPath: /home/locust
name: locust-script
volumes:
- name: locust-script
configMap:
name: locust-scriptSi può inviare al cluster con:
bash
$ kubectl locust.yamlLocusta legge quanto segue locustfile.pyche viene memorizzato in una ConfigMap:
py
from locust import HttpUser, task, between
class QuickstartUser(HttpUser):
@task
def hello_world(self):
self.client.get("/")Il file non fa nulla di speciale, a parte fare una richiesta a un URL. Per connettersi alla dashboard di Locust, è necessario l'indirizzo IP del suo bilanciatore di carico.
È possibile recuperarlo con il seguente comando:
bash
$ kubectl get service locust -o jsonpath='{.status.loadBalancer.ingress[0].ip}'Aprite il browser e inserite l'indirizzo IP.
Eccellente!
Manca un pezzo: l'autoscaler Pod orizzontale.
L'autoscaler KEDA avvolge l'autoscaler orizzontale con un oggetto specifico chiamato ScaledObject.
yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: podinfo
spec:
scaleTargetRef:
kind: Deployment
name: podinfo
minReplicaCount: 1
maxReplicaCount: 30
cooldownPeriod: 30
pollingInterval: 1
triggers:
- type: prometheus
metadata:
serverAddress: http://prometheus-server
metricName: connections_active_keda
query: |
sum(increase(http_requests_total{app="podinfo"}[60s]))
threshold: "480" # 8rps * 60sKEDA collega le metriche raccolte da Prometheus e le alimenta a Kubernetes.
Infine, crea un Horizontal Pod Autoscaler (HPA) con queste metriche.
È possibile ispezionare manualmente l'HPA con:
bash
$ kubectl get hpa
$ kubectl describe hpa keda-hpa-podinfoÈ possibile inviare l'oggetto con:
bash
$ kubectl apply -f scaled-object.yamlÈ ora di verificare se il ridimensionamento funziona.
Nella dashboard di Locust, avviare un esperimento con le seguenti impostazioni:
- Numero di utenti:
300 - Tasso di riproduzione:
0.4 - Ospite:
http://podinfo
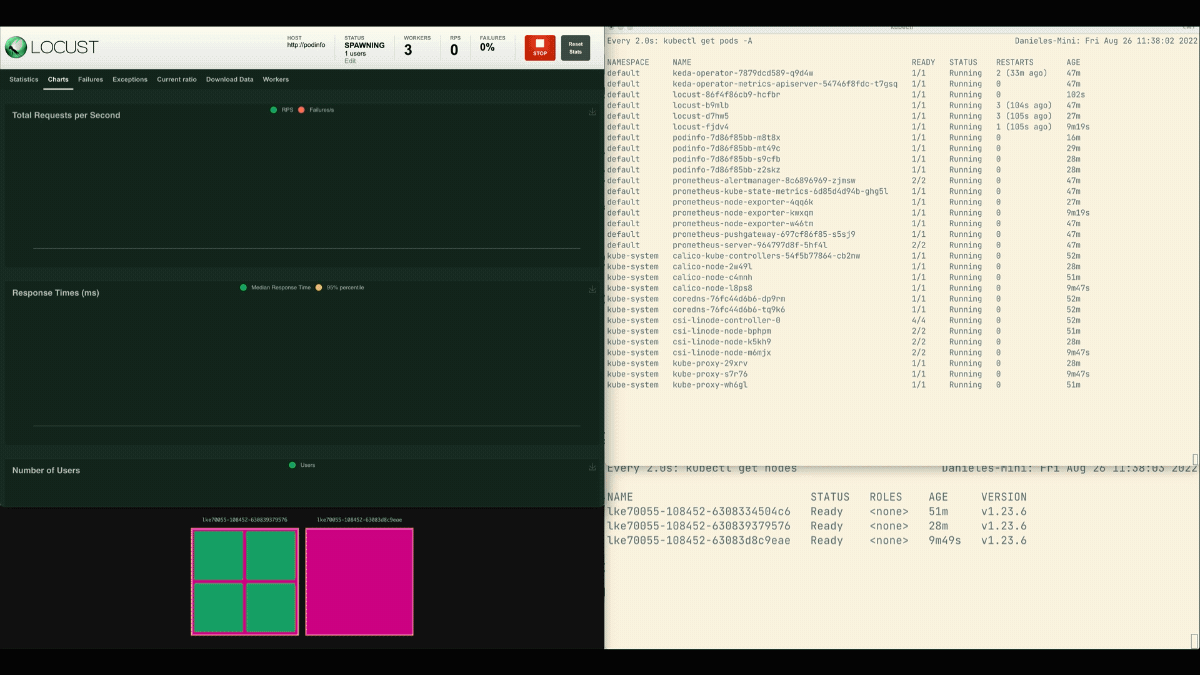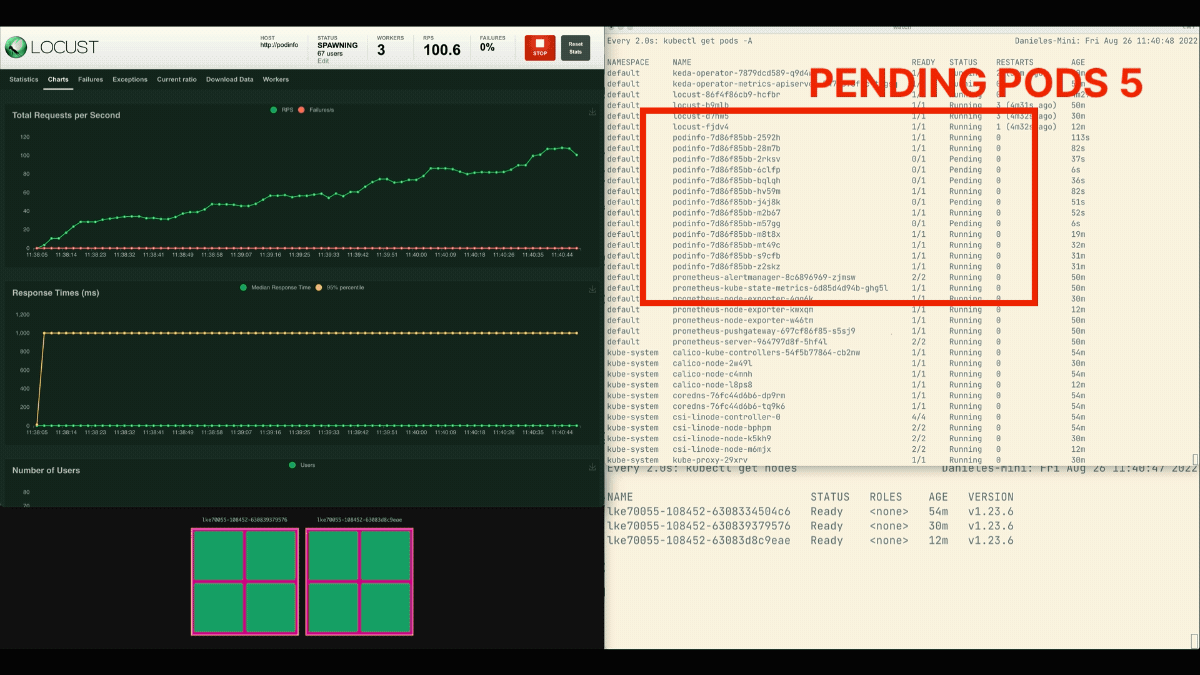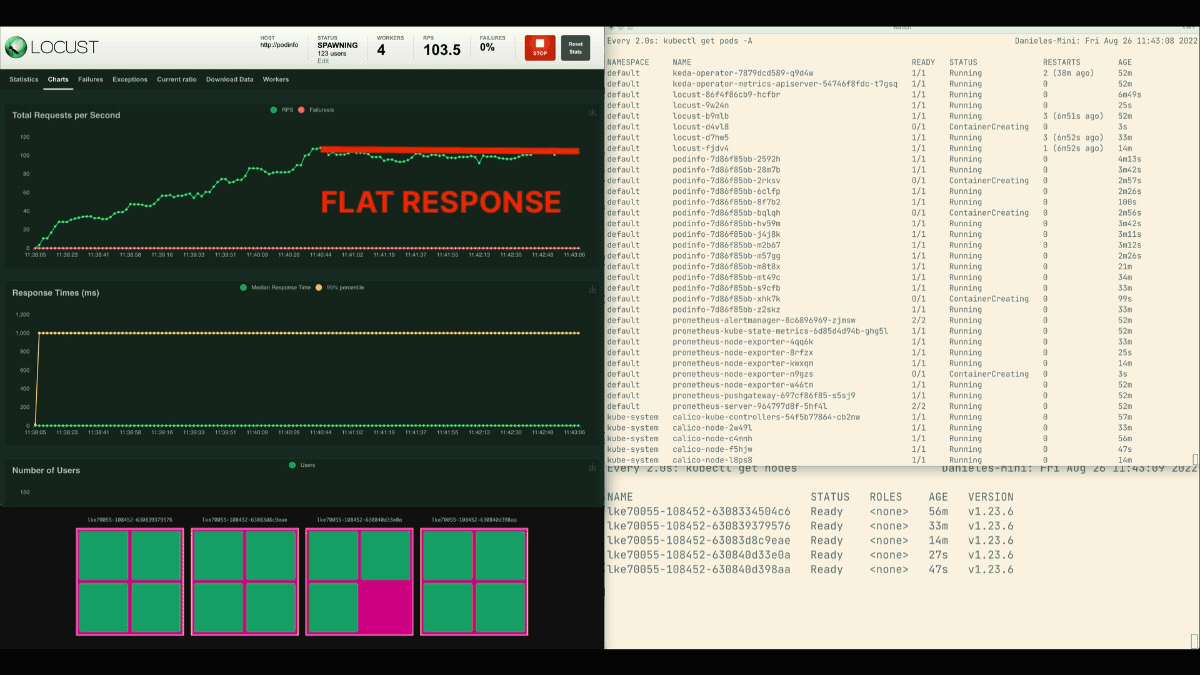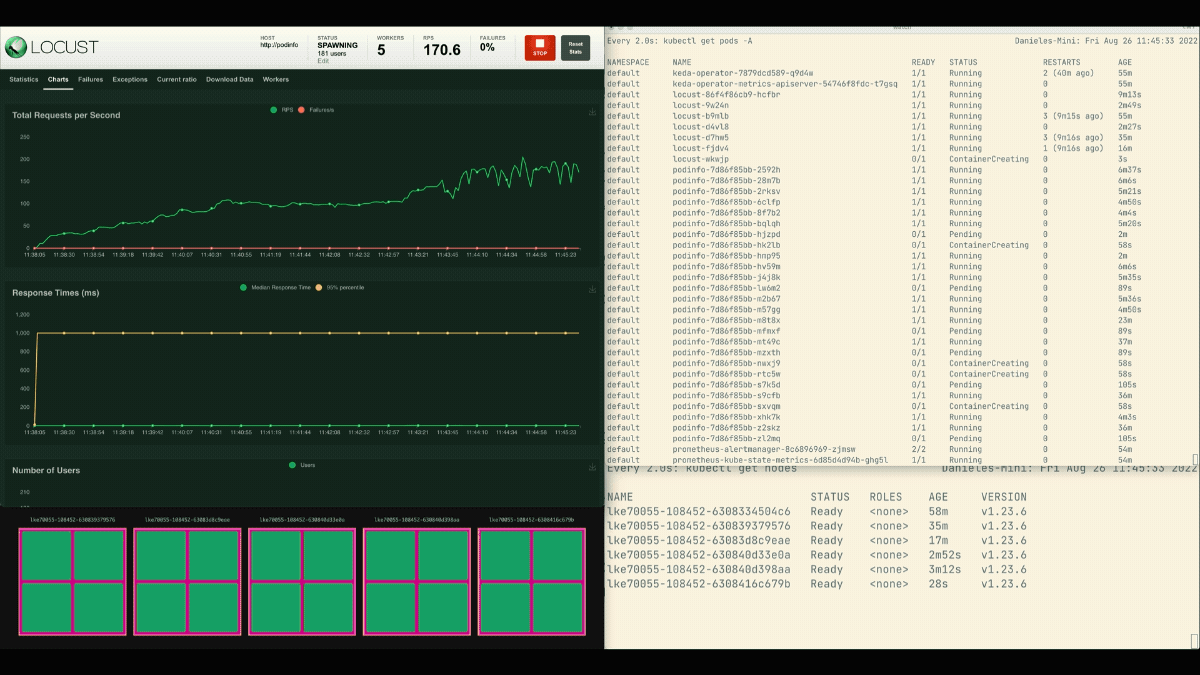
Il numero di repliche è in aumento!
Eccellente! Ma l'avete notato?
Dopo che il deployment scala a 8 pod, deve attendere alcuni minuti prima che vengano creati altri pod nel nuovo nodo.
In questo periodo, le richieste al secondo ristagnano perché le otto repliche attuali possono gestire solo dieci richieste ciascuna.
Riduciamo la scala e ripetiamo l'esperimento:
bash
kubectl scale deployment/podinfo --replicas=4 # or wait for the autoscaler to remove podsQuesta volta, si esegue l'overprovisioning del nodo con il pod segnaposto:
yaml
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: overprovisioning
value: -1
globalDefault: false
description: "Priority class used by overprovisioning."
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning
spec:
replicas: 1
selector:
matchLabels:
run: overprovisioning
template:
metadata:
labels:
run: overprovisioning
spec:
priorityClassName: overprovisioning
containers:
- name: pause
image: k8s.gcr.io/pause
resources:
requests:
cpu: 900m
memory: 3.9GSi può inviare al cluster con:
bash
kubectl apply -f placeholder.yamlAprite la dashboard di Locust e ripetete l'esperimento con le seguenti impostazioni:
- Numero di utenti:
300 - Tasso di riproduzione:
0.4 - Ospite:
http://podinfo
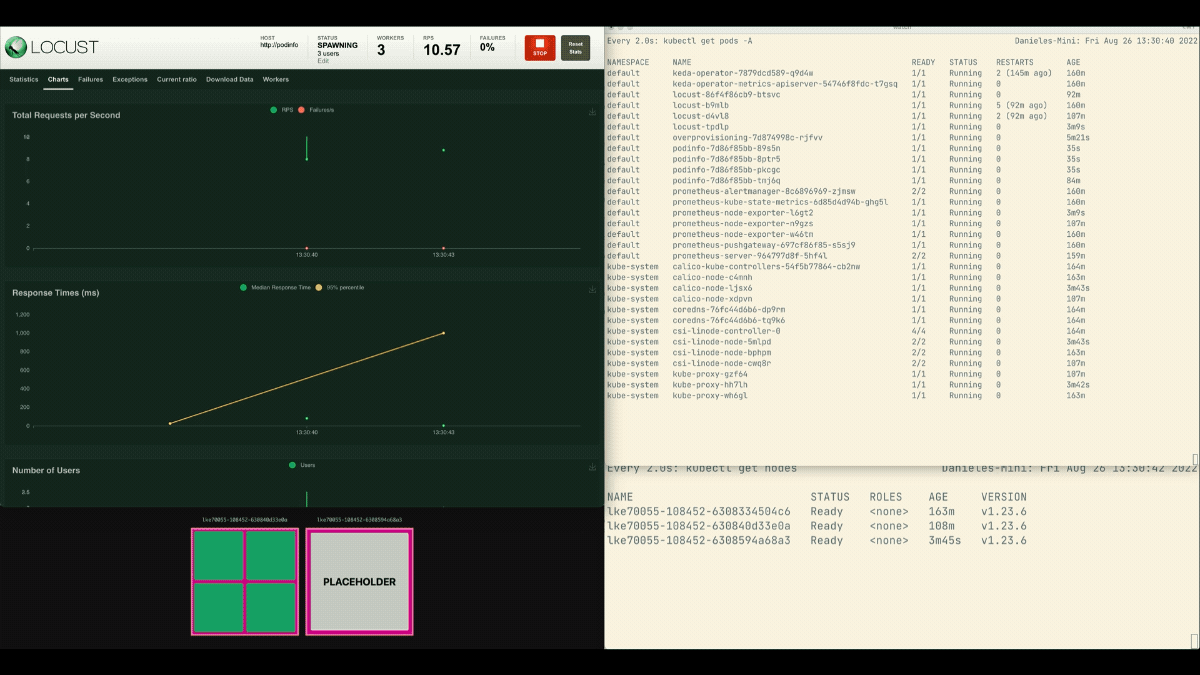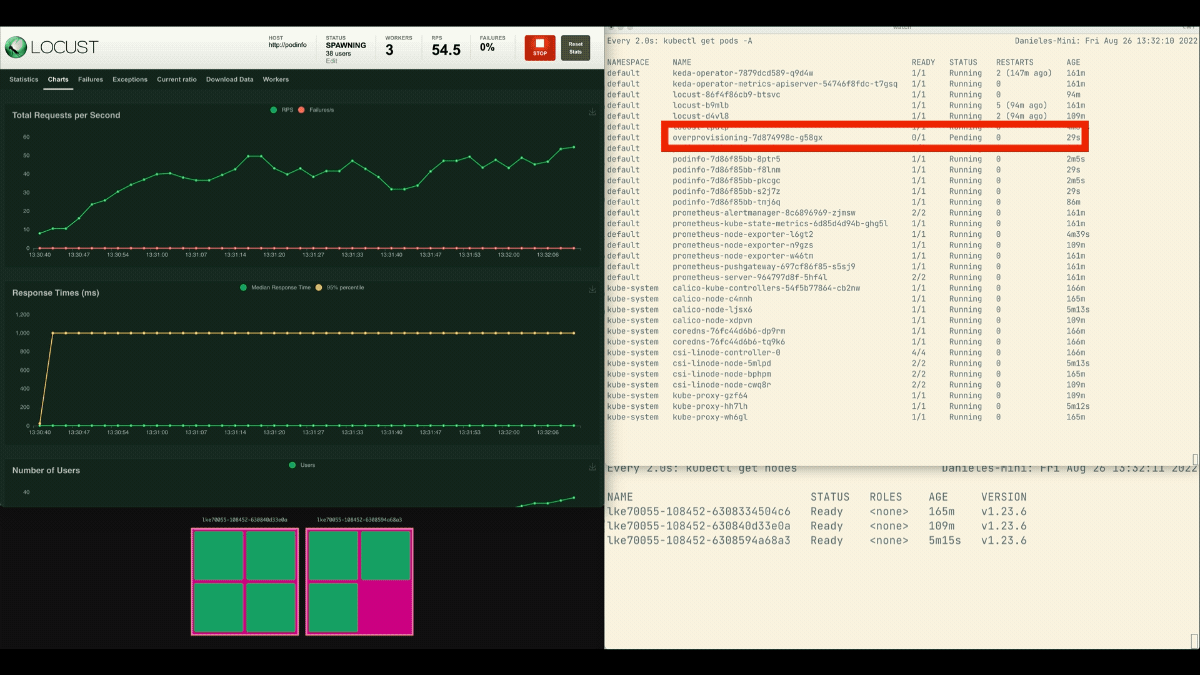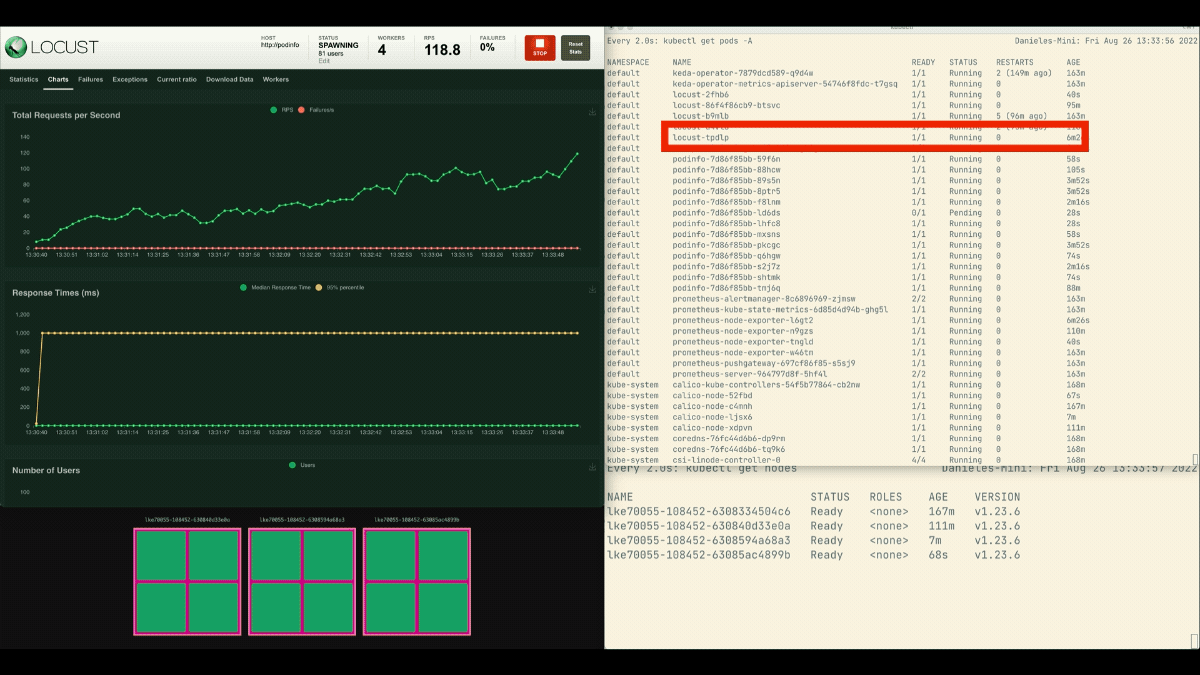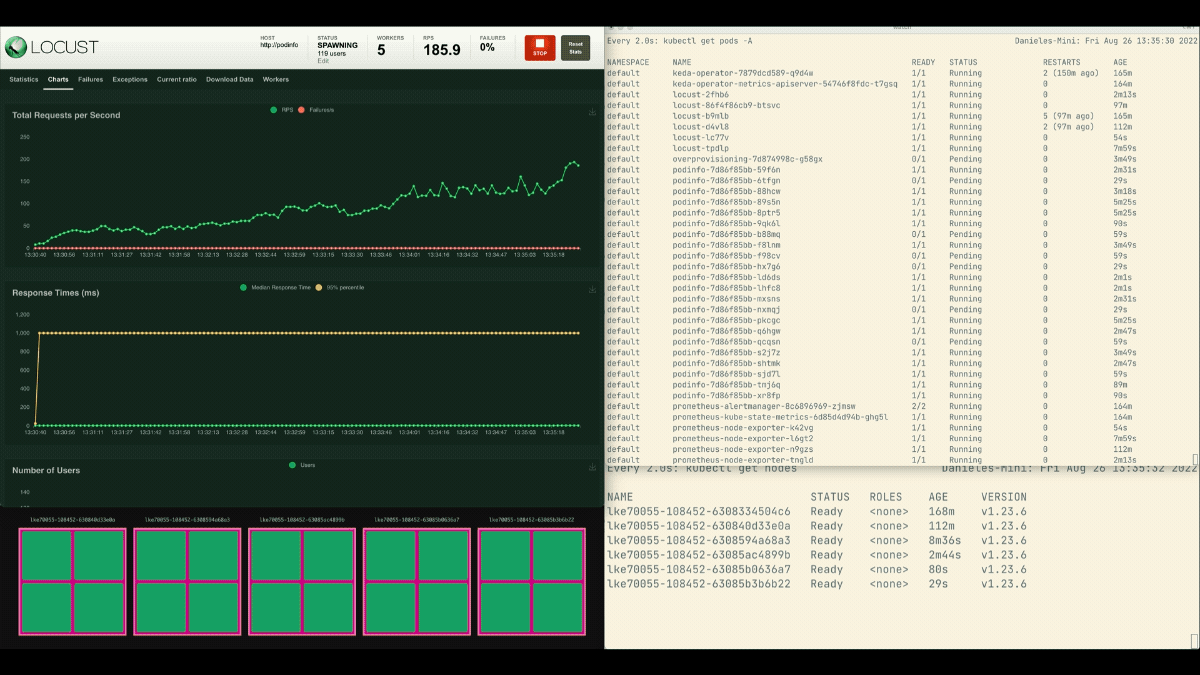
Questa volta, i nuovi nodi vengono creati in background e le richieste al secondo aumentano senza appiattirsi. Ottimo lavoro!
Riassumiamo quanto appreso in questo post:
- l'autoscaler del cluster non tiene traccia del consumo di CPU o di memoria. Invece, monitora i pod in attesa;
- è possibile creare un pod che utilizza la memoria e la CPU totali disponibili per il provisioning proattivo di un nodo Kubernetes;
- I nodi Kubernetes hanno risorse riservate per kubelet, sistema operativo e soglia di eviction; e
- è possibile combinare Prometheus con KEDA per scalare il pod con una query PromQL.
Volete seguire la nostra serie di webinar su Scaling Kubernetes? Registratevi per iniziare e saperne di più sull'uso di KEDA per scalare i cluster Kubernetes a zero.




Commenti