

这篇文章是我们扩展Kubernetes系列的一部分。 注册来观看直播或访问录音,并查看本系列的其他文章。
当你的集群资源不足时,Cluster Autoscaler会提供一个新的节点并将其添加到集群中。如果你已经是一个Kubernetes用户,你可能已经注意到,创建和添加一个节点到集群需要几分钟时间。
在这段时间里,你的应用程序很容易被连接所淹没,因为它无法进一步扩展。

如何解决等待时间过长的问题?
主动扩大规模,或。
- 了解集群自动缩放器如何工作,并最大限度地发挥其作用。
- 使用Kubernetes调度器将pod分配给一个节点;以及
- 主动提供工作节点,以避免糟糕的扩展。
如果你喜欢阅读本教程的代码,你可以在LearnK8s GitHub上找到。
Cluster Autoscaler如何在Kubernetes中工作
Cluster Autoscaler在触发自动缩放时并不看内存或CPU的可用性。相反,Cluster Autoscaler对事件作出反应,并检查任何不可调度的pod。当调度器不能找到一个可以容纳它的节点时,一个pod就是不可调度的。
让我们通过创建一个集群来测试一下。
bash
$ linode-cli lke cluster-create \
--label learnk8s \
--region eu-west \
--k8s_version 1.23 \
--node_pools.count 1 \
--node_pools.type g6-standard-2 \
--node_pools.autoscaler.enabled enabled \
--node_pools.autoscaler.max 10 \
--node_pools.autoscaler.min 1 \
$ linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfig你应该注意以下细节。
- 每个节点有4GB内存和2个vCPU(即`g6-standard-2`)。
- 集群中只有一个节点;以及
- 集群自动缩放器被配置为从1个节点增长到10个节点。
你可以用以下方法验证安装是否成功。
bash
$ kubectl get pods -A --kubeconfig=kubeconfig用环境变量导出kubeconfig文件通常更方便。
你可以这样做。
bash
$ export KUBECONFIG=${PWD}/kubeconfig
$ kubectl get pods优秀的!
部署一个应用程序
让我们部署一个需要1GB内存和250m*CPU的应用程序。Note: m = thousandth of a core, so 250m = 25% of the CPU
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
replicas: 1
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
spec:
containers:
- name: podinfo
image: stefanprodan/podinfo
ports:
- containerPort: 9898
resources:
requests:
memory: 1G
cpu: 250m你可以通过以下方式将资源提交给集群。
bash
$ kubectl apply -f podinfo.yaml一旦你这样做,你可能会注意到一些事情。首先,有三个豆荚几乎立即运行,还有一个正在等待。

然后。
- 几分钟后,自动分配器创建一个额外的节点;以及
- 第四个pod被部署在新节点上。

为什么第四个pod没有部署在第一个节点上? 让我们来挖掘一下可分配的资源。
Kubernetes节点中可分配的资源
部署在Kubernetes集群中的Pod会消耗内存、CPU和存储资源。
然而,在同一个节点上,操作系统和Kubelet需要内存和CPU。
在Kubernetes工作节点中,内存和CPU被划分为。
- 运行操作系统和系统守护程序(如SSH、systemd等)所需的资源。
- 运行Kubernetes代理的必要资源,如Kubelet、容器运行时间、节点问题检测器等。
- 平台可用的资源。
- 为驱逐门槛保留的资源。
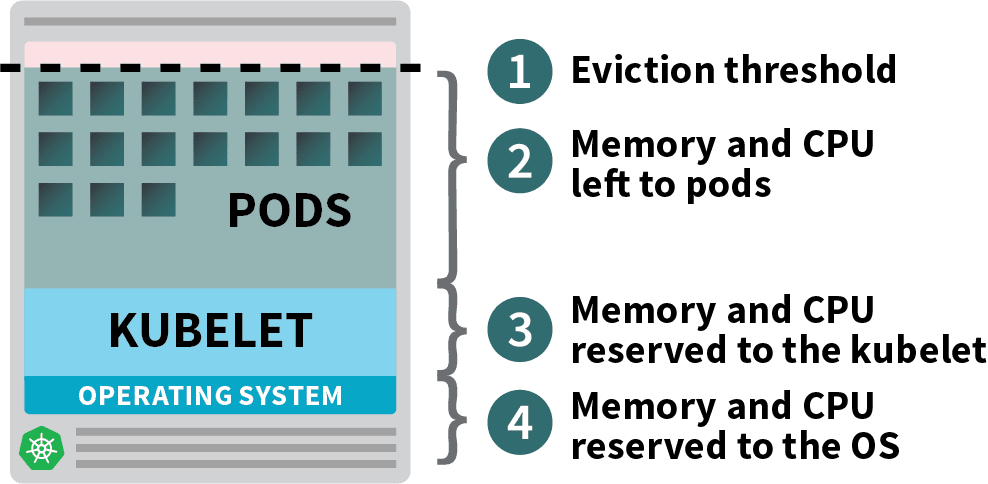
如果你的集群运行一个DaemonSet,如kube-proxy,你应该进一步减少可用内存和CPU。
因此,让我们降低要求,确保所有的pod都能装进一个节点。
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
replicas: 4
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
spec:
containers:
- name: podinfo
image: stefanprodan/podinfo
ports:
- containerPort: 9898
resources:
requests:
memory: 0.8G # <- lower memory
cpu: 200m # <- lower CPU你可以通过以下方式修改部署。
bash
$ kubectl apply -f podinfo.yaml选择正确的CPU和内存数量来优化你的实例可能是很棘手的。Learnk8s工具计算器可能会帮助你更快地完成这项工作。
你解决了一个问题,但创建一个新节点的时间呢?
迟早有一天,你会有四个以上的副本。你真的要在新豆荚创建之前等待几分钟吗?
简短的回答是肯定的。
Linode必须从头开始创建一个虚拟机,配置它,并将其连接到集群。这个过程可能很容易就会超过两分钟。
但是有一个替代方案。
例如:你可以将autoscaler配置为总是有一个备用节点。当pods被部署在备用节点上时,autoscaler可以主动地创建更多。不幸的是,autoscaler没有这个内置功能,但你可以很容易地重新创建它。
你可以创建一个pod,它的请求等于节点的资源。
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning
spec:
replicas: 1
selector:
matchLabels:
run: overprovisioning
template:
metadata:
labels:
run: overprovisioning
spec:
containers:
- name: pause
image: k8s.gcr.io/pause
resources:
requests:
cpu: 900m
memory: 3.8G你可以通过以下方式将资源提交给集群。
bash
kubectl apply -f placeholder.yaml这个吊舱完全没有作用。
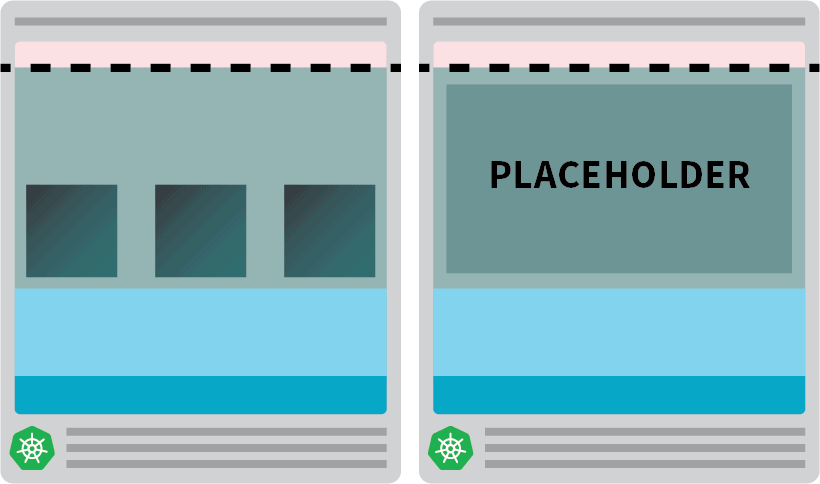
它只是让节点完全被占用。
下一步是确保一旦有需要扩展的工作负载时,占位者pod就被驱逐出去。
为此,你可以使用一个优先级类。
yaml
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: overprovisioning
value: -1
globalDefault: false
description: "Priority class used by overprovisioning."
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning
spec:
replicas: 1
selector:
matchLabels:
run: overprovisioning
template:
metadata:
labels:
run: overprovisioning
spec:
priorityClassName: overprovisioning # <--
containers:
- name: pause
image: k8s.gcr.io/pause
resources:
requests:
cpu: 900m
memory: 3.8G并将其重新提交给集群,并附上。
bash
kubectl apply -f placeholder.yaml现在设置已经完成。
你可能需要等待一下,让自动缩放器创建节点,但在这一点上,你应该有两个节点。
- 一个有四个豆荚的节点。
- 另一个有占位器的吊舱。
当你将部署规模扩大到5个副本时会发生什么?你是否需要等待自动缩放器创建一个新的节点?
让我们来测试一下。
bash
kubectl scale deployment/podinfo --replicas=5你应该观察。
- 第五个吊舱立即被创建,不到10秒就进入了运行状态。
- 占位的吊舱被驱逐,以便为该吊舱腾出空间。

然后。
- 集群的自动调节器注意到了这个待定的占位荚,并配置了一个新的节点。
- 占位者pod被部署在新创建的节点中。
当你可以拥有更多的节点时,为什么要主动地创建一个单一的节点?
你可以将占位者的pod扩展到几个副本。每个副本将预先提供一个Kubernetes节点,准备接受标准工作负载。然而,这些节点仍然计入你的云账单,但却闲置着,什么也不做。因此,你应该小心,不要创建太多的节点。
将集群自动调节器与水平吊舱自动调节器相结合
为了理解这项技术的含义,让我们把集群自动调节器和水平荚自动调节器(HPA)结合起来。HPA是为了增加你部署中的复制。
随着你的应用程序收到更多的流量,你可以让自动缩放器调整复制的数量,以处理更多的请求。
当pod用尽所有可用的资源时,集群的autoscaler将触发创建一个新的节点,以便HPA可以继续创建更多的副本。
让我们通过创建一个新的集群来测试一下。
bash
$ linode-cli lke cluster-create \
--label learnk8s-hpa \
--region eu-west \
--k8s_version 1.23 \
--node_pools.count 1 \
--node_pools.type g6-standard-2 \
--node_pools.autoscaler.enabled enabled \
--node_pools.autoscaler.max 10 \
--node_pools.autoscaler.min 3 \
$ linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfig-hpa你可以用以下方法验证安装是否成功。
bash
$ kubectl get pods -A --kubeconfig=kubeconfig-hpa用环境变量导出kubeconfig文件更方便。
你可以这样做。
bash
$ export KUBECONFIG=${PWD}/kubeconfig-hpa
$ kubectl get pods优秀的!
让我们用Helm来安装Prometheus ,并从部署中刮取指标。
你可以在他们的官方网站上找到关于如何安装Helm的说明。
bash
$ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
$ helm install prometheus prometheus-community/prometheusKubernetes为HPA提供了一个控制器,可以动态地增加和减少副本。
不幸的是,HPA有一些缺点。
- 它并不是开箱即用的。你需要安装一个指标服务器来汇总和公开这些指标。
- 你不能使用开箱即用的PromQL查询。
幸运的是,你可以使用KEDA,它扩展了HPA控制器的一些额外功能(包括从Prometheus 读取指标)。
- 缩放器
- 一个指标适配器
- A 控制器
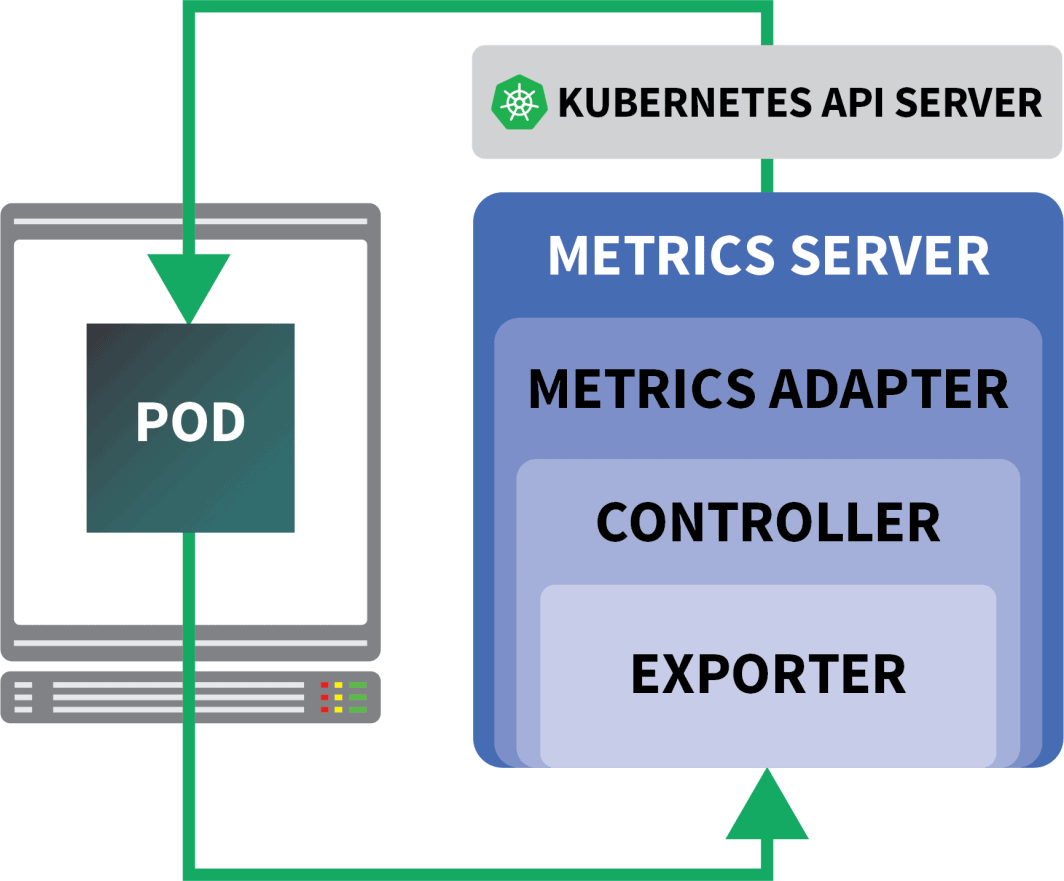
你可以用Helm安装KEDA。
bash
$ helm repo add kedacore https://kedacore.github.io/charts
$ helm install keda kedacore/keda现在,Prometheus 和KEDA已经安装完毕,让我们来创建一个部署。
在这个实验中,你将使用一个设计为每秒处理固定数量请求的应用程序。
每个pod每秒钟最多可以处理10个请求。如果pod收到第11个请求,它将把该请求留待以后再处理。
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
replicas: 4
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
annotations:
prometheus.io/scrape: "true"
spec:
containers:
- name: podinfo
image: learnk8s/rate-limiter:1.0.0
imagePullPolicy: Always
args: ["/app/index.js", "10"]
ports:
- containerPort: 8080
resources:
requests:
memory: 0.9G
---
apiVersion: v1
kind: Service
metadata:
name: podinfo
spec:
ports:
- port: 80
targetPort: 8080
selector:
app: podinfo你可以通过以下方式将资源提交给集群。
bash
$ kubectl apply -f rate-limiter.yaml为了产生一些流量,你将使用Locust。
下面的YAML定义创建了一个分布式负载测试集群。
yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: locust-script
data:
locustfile.py: |-
from locust import HttpUser, task, between
class QuickstartUser(HttpUser):
@task
def hello_world(self):
self.client.get("/", headers={"Host": "example.com"})
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: locust
spec:
selector:
matchLabels:
app: locust-primary
template:
metadata:
labels:
app: locust-primary
spec:
containers:
- name: locust
image: locustio/locust
args: ["--master"]
ports:
- containerPort: 5557
name: comm
- containerPort: 5558
name: comm-plus-1
- containerPort: 8089
name: web-ui
volumeMounts:
- mountPath: /home/locust
name: locust-script
volumes:
- name: locust-script
configMap:
name: locust-script
---
apiVersion: v1
kind: Service
metadata:
name: locust
spec:
ports:
- port: 5557
name: communication
- port: 5558
name: communication-plus-1
- port: 80
targetPort: 8089
name: web-ui
selector:
app: locust-primary
type: LoadBalancer
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: locust
spec:
selector:
matchLabels:
app: locust-worker
template:
metadata:
labels:
app: locust-worker
spec:
containers:
- name: locust
image: locustio/locust
args: ["--worker", "--master-host=locust"]
volumeMounts:
- mountPath: /home/locust
name: locust-script
volumes:
- name: locust-script
configMap:
name: locust-script你可以用提交给集群。
bash
$ kubectl locust.yaml蝗虫》的内容如下 locustfile.py,它被存储在一个ConfigMap中。
py
from locust import HttpUser, task, between
class QuickstartUser(HttpUser):
@task
def hello_world(self):
self.client.get("/")该文件除了向一个URL发出请求外,并没有做任何特别的事情。要连接到Locust仪表板,你需要它的负载平衡器的IP地址。
你可以用下面的命令检索它。
bash
$ kubectl get service locust -o jsonpath='{.status.loadBalancer.ingress[0].ip}'打开你的浏览器并输入该IP地址。
优秀的!
缺少了一块:Horizontal Pod Autoscaler。
KEDA的Autoscaler用一个叫ScaledObject的特定对象来包装Horizontal Autoscaler。
yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: podinfo
spec:
scaleTargetRef:
kind: Deployment
name: podinfo
minReplicaCount: 1
maxReplicaCount: 30
cooldownPeriod: 30
pollingInterval: 1
triggers:
- type: prometheus
metadata:
serverAddress: http://prometheus-server
metricName: connections_active_keda
query: |
sum(increase(http_requests_total{app="podinfo"}[60s]))
threshold: "480" # 8rps * 60sKEDA连接了由Prometheus 收集的指标,并将其反馈给Kubernetes。
最后,它用这些指标创建一个Horizontal Pod Autoscaler(HPA)。
你可以通过以下方式手动检查HPA。
bash
$ kubectl get hpa
$ kubectl describe hpa keda-hpa-podinfo你可以用提交对象。
bash
$ kubectl apply -f scaled-object.yaml现在是测试缩放是否有效的时候了。
在Locust仪表板上,用以下设置启动一个实验。
- 用户的数量。
300 - 产卵率。
0.4 - 主持人。
http://podinfo
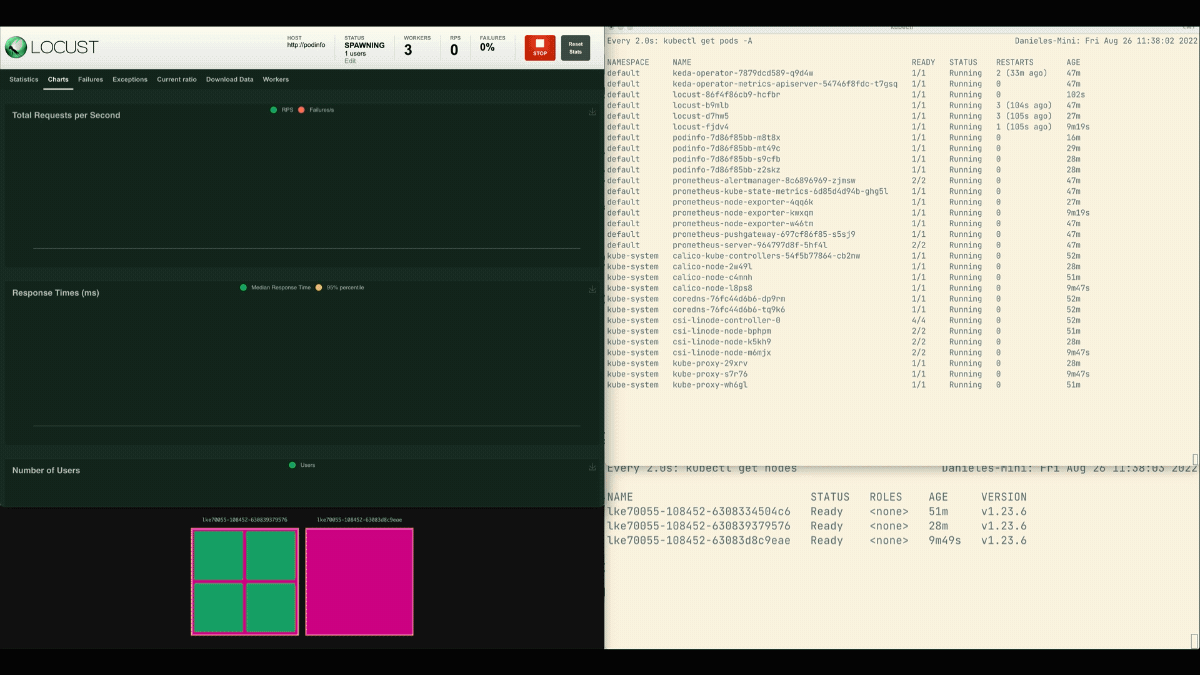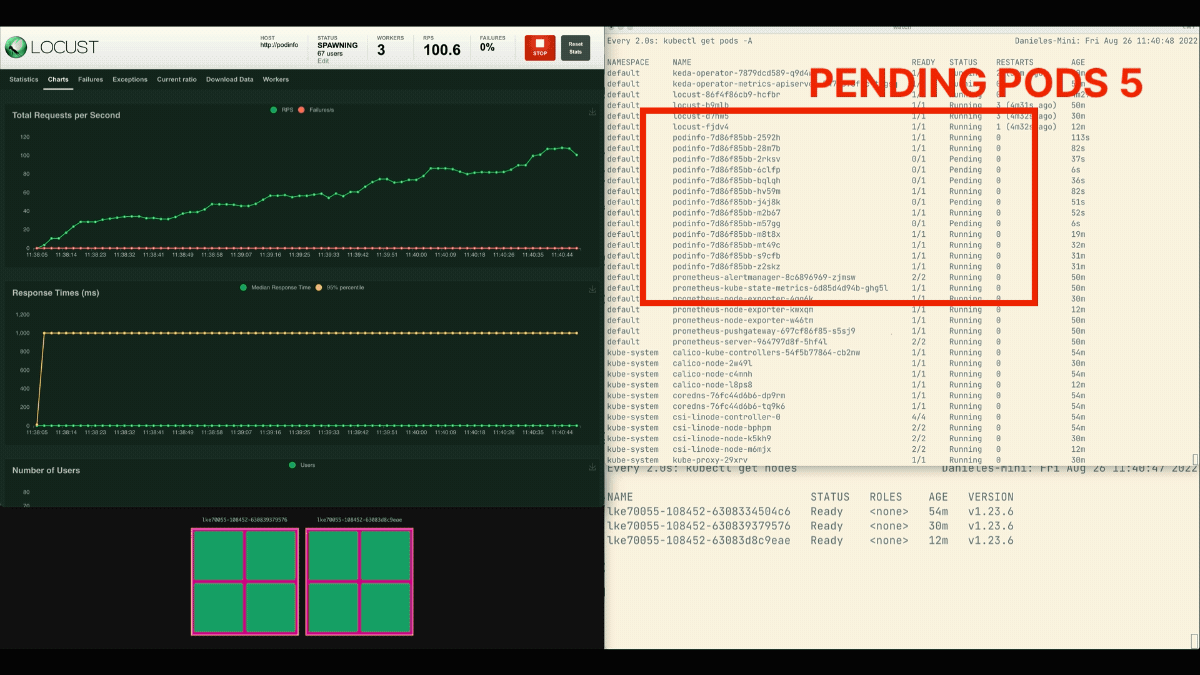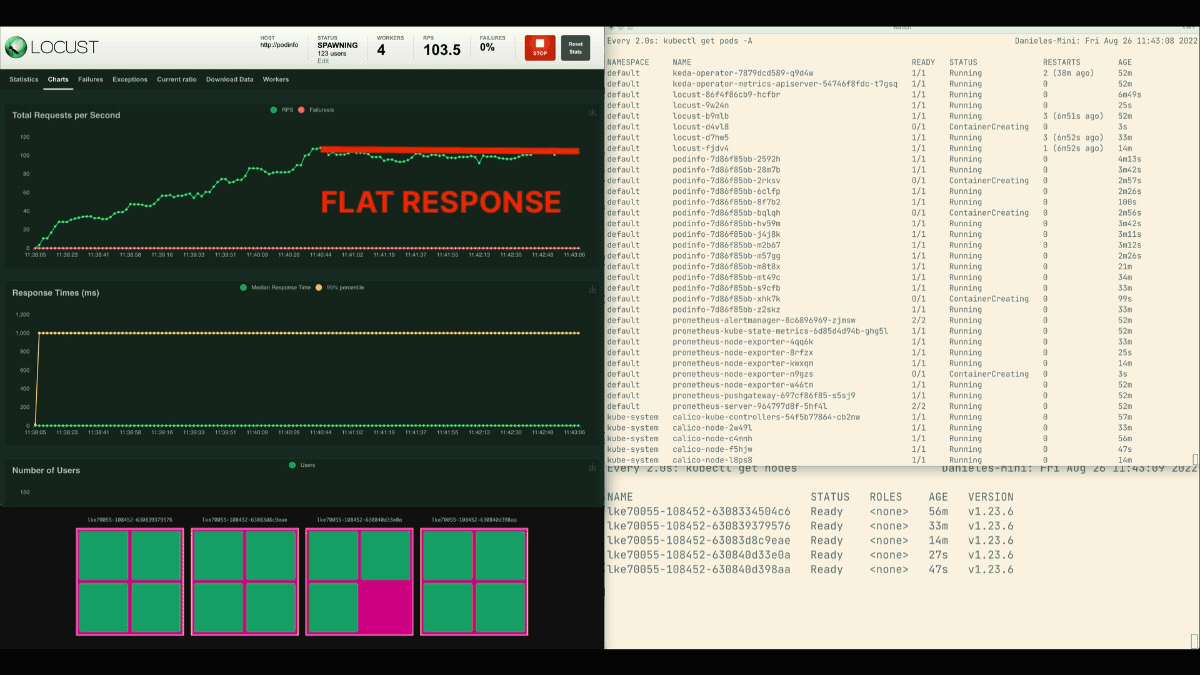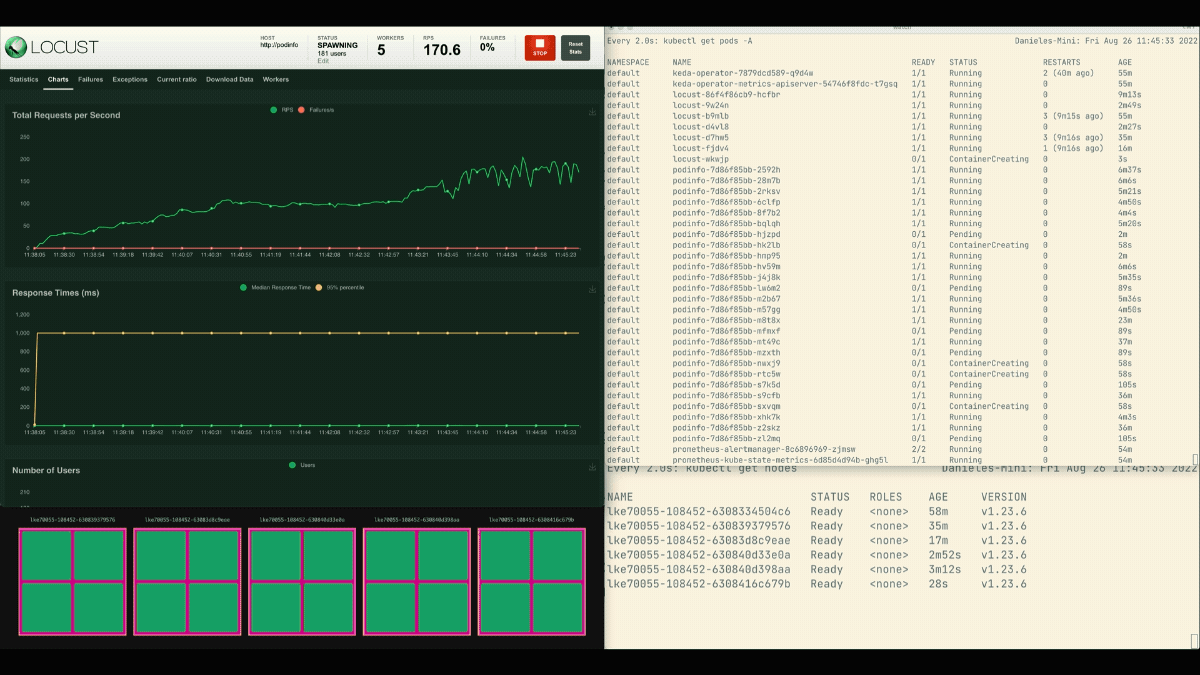
复制品的数量正在增加!
优秀的!但你注意到了吗?
在部署扩展到8个pod后,必须等待几分钟才能在新节点上创建更多pod。
在这个时期,每秒的请求量停滞不前,因为目前的8个副本只能处理每个10个请求。
让我们缩小规模,重复这个实验。
bash
kubectl scale deployment/podinfo --replicas=4 # or wait for the autoscaler to remove pods这一次,让我们用占位者的pod来过度配置节点。
yaml
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: overprovisioning
value: -1
globalDefault: false
description: "Priority class used by overprovisioning."
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: overprovisioning
spec:
replicas: 1
selector:
matchLabels:
run: overprovisioning
template:
metadata:
labels:
run: overprovisioning
spec:
priorityClassName: overprovisioning
containers:
- name: pause
image: k8s.gcr.io/pause
resources:
requests:
cpu: 900m
memory: 3.9G你可以用提交给集群。
bash
kubectl apply -f placeholder.yaml打开Locust仪表板,用以下设置重复实验。
- 用户的数量。
300 - 产卵率。
0.4 - 主持人。
http://podinfo
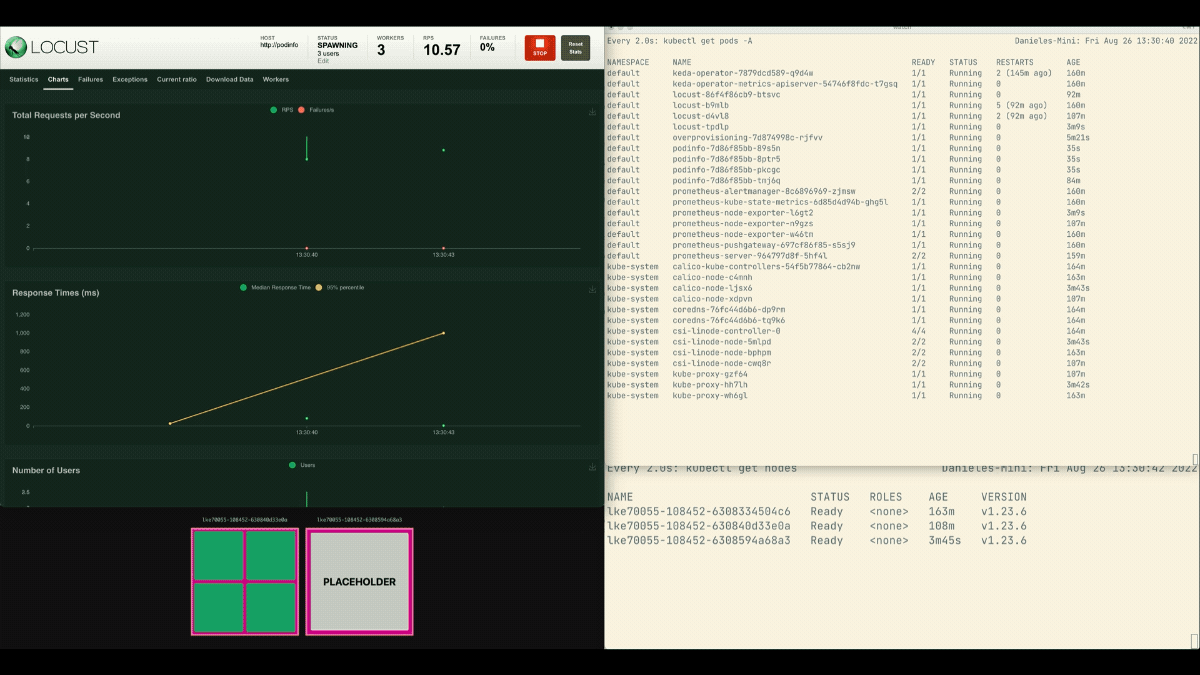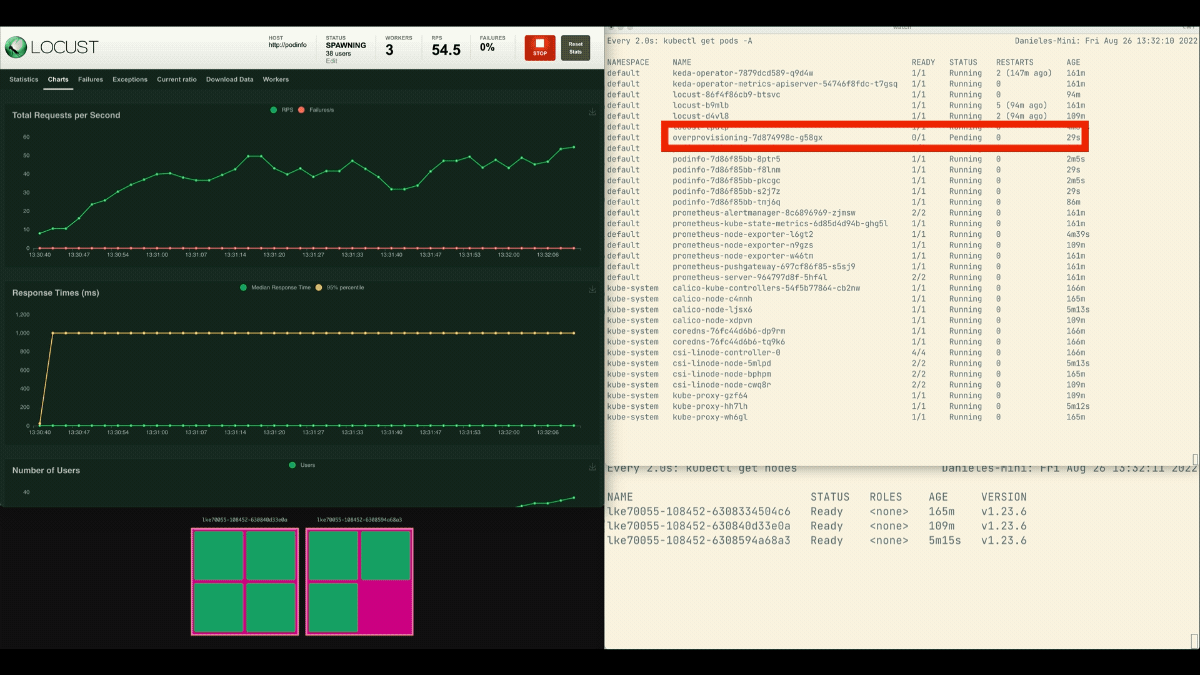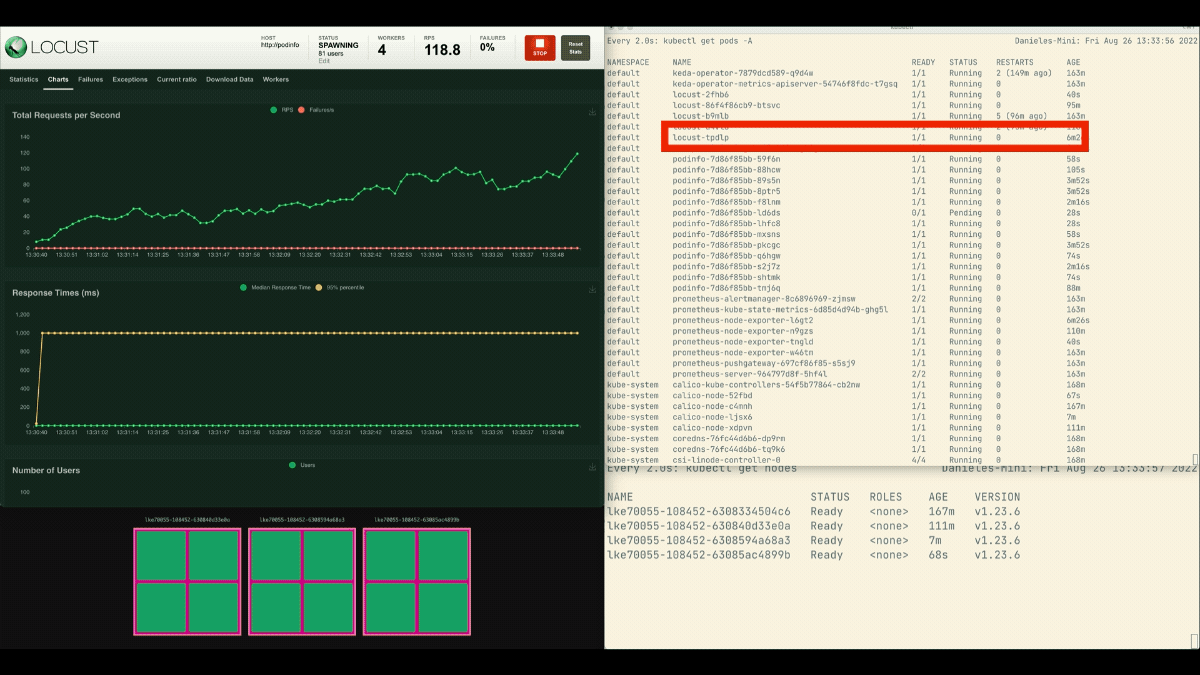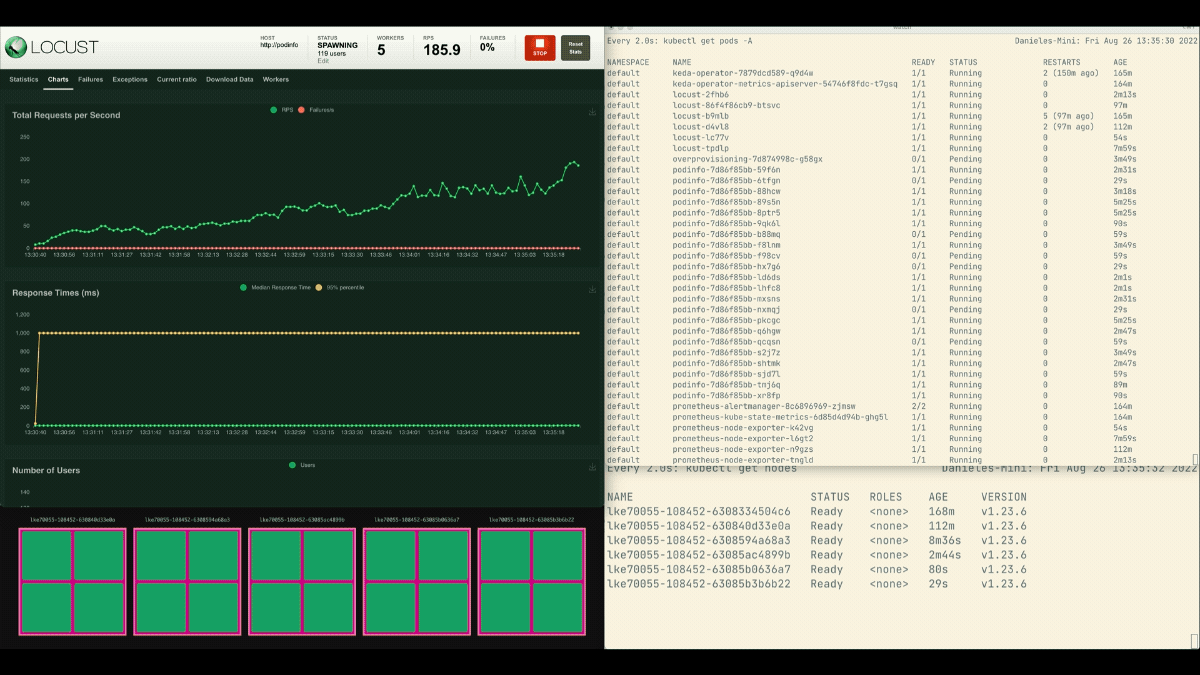
这一次,新的节点是在后台创建的,每秒的请求数增加了,但没有变平。干得好!
让我们回顾一下你在这篇文章中学到的东西。
- 集群自动调节器不跟踪CPU或内存消耗。相反,它监测待处理的pod。
- 你可以创建一个pod,使用可用的总内存和CPU来主动配置一个Kubernetes节点。
- Kubernetes节点为kubelet、操作系统和驱逐门槛保留了资源;以及
- 你可以把Prometheus 和KEDA结合起来,用PromQL查询来扩展你的pod。
想跟随我们的Scaling Kubernetes系列网络研讨会吗?注册开始,并了解更多关于使用KEDA将Kubernetes集群扩展到零的信息。




注释