

이 게시물은 쿠버네티스 스케일링 시리즈의 일부입니다. 등록하여 라이브로 시청하거나 녹화에 액세스하고 이 시리즈의 다른 게시물을 확인하십시오.
인프라 비용을 줄이면 자원이 활용되지 않을 때 리소스를 끄는 것으로 귀결됩니다. 그러나 과제는 필요할 때 이러한 리소스를 자동으로 켜는 방법을 알아내는 것입니다. LKE(Linode Kubernetes Engine)를 사용하여 쿠버네 티스 클러스터를 배포하고 쿠버네티스 이벤트 기반 오토스케일러(KEDA)를 사용하여 제로로 확장하는 데 필요한 단계를 살펴보겠습니다.
0으로 확장해야 하는 이유
Kubernetes에서 합리적으로 리소스 집약적 인 앱을 실행하고 있으며 근무 시간에만 필요하다고 가정 해 봅시다.
사람들이 사무실을 떠날 때 끄고 하루를 시작할 때 다시 켜고 싶을 수도 있습니다.
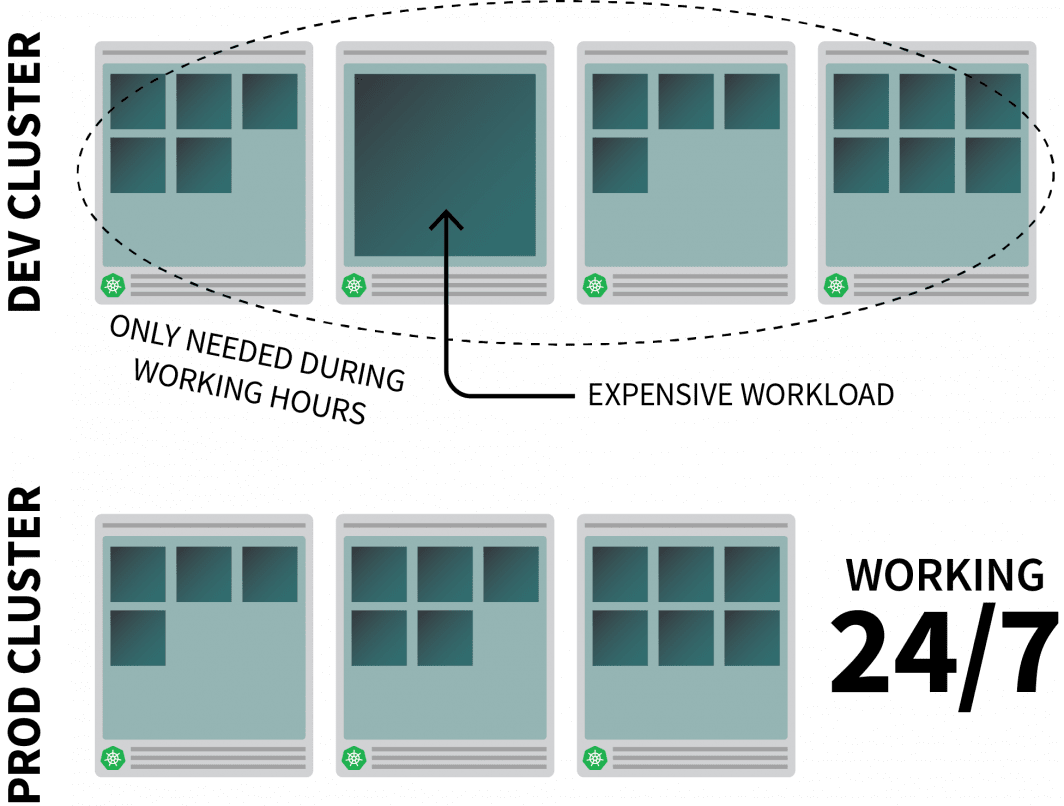
CronJob을 사용하여 인스턴스를 확장 및 축소할 수 있지만 이 솔루션은 미리 설정된 일정에 따라서만 실행할 수 있는 스톱 갭입니다.
주말에는 어떤 일이 발생합니까? 그리고 공휴일은 어떻습니까? 아니면 팀이 아플 때?
계속 증가하는 규칙 목록을 생성하는 대신 트래픽에 따라 워크로드를 확장할 수 있습니다. 트래픽이 증가하면 복제본을 확장할 수 있습니다. 트래픽이 없는 경우 앱을 끌 수 있습니다. 앱이 꺼지고 새로 들어오는 요청이 있는 경우 Kubernetes는 트래픽을 처리하기 위해 최소한 하나의 복제본을 시작합니다.

다음으로 다음 방법에 대해 이야기 해 보겠습니다.
- 앱에 대한 모든 트래픽을 가로챌 수 있습니다.
- 트래픽 모니터링; 그리고
- 자동 크기 조정기를 설정하여 복제본 수를 조정하거나 앱을 끕니다.
이 자습서의 코드를 읽으려는 경우 LearnK8s GitHub에서 이 작업을 수행할 수 있습니다.
클러스터 만들기
쿠버네티스 클러스터를 만드는 것부터 시작해보자.
다음 명령을 사용하여 클러스터를 만들고 kubeconfig 파일을 저장할 수 있습니다.
bash
$ linode-cli lke cluster-create \
--label cluster-manager \
--region eu-west \
--k8s_version 1.23
$ linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfig다음을 사용하여 설치가 성공했는지 확인할 수 있습니다.
bash
$ kubectl get pods -A --kubeconfig=kubeconfigkubeconfig 파일을 환경 변수로 내보내는 것이 일반적으로 더 편리합니다.
다음을 사용하여 그렇게 할 수 있습니다.
bash
$ export KUBECONFIG=${PWD}/kubeconfig
$ kubectl get pods이제 응용 프로그램을 배포해 보겠습니다.
응용 프로그램 배포
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
spec:
containers:
- name: podinfo
image: stefanprodan/podinfo
ports:
- containerPort: 9898
---
apiVersion: v1
kind: Service
metadata:
name: podinfo
spec:
ports:
- port: 80
targetPort: 9898
selector:
app: podinfo다음과 같이 YAML 파일을 제출할 수 있습니다.
terminal|command=1|title=bash
$ kubectl apply -f 1-deployment.yaml그리고 당신은 다음과 함께 응용 프로그램을 방문 할 수 있습니다 :
브라우저를 localhost:8080으로 엽니다.
bash
$ kubectl port-forward svc/podinfo 8080:80이 시점에서 앱이 표시됩니다.
다음으로, 자동 스케일러 인 KEDA를 설치합시다.
KEDA — 쿠버네티스 이벤트 기반 오토스케일러
쿠버네티스는 HPA(Horizontal Pod Autoscaler) 를 컨트롤러로 제공하여 복제본을 동적으로 늘리거나 줄일 수 있습니다.
불행히도 HPA에는 몇 가지 단점이 있습니다.
- 기본적으로 작동하지 않으므로 메트릭을 집계하고 노출하려면 메트릭 서버를 설치해야 합니다.
- 복제본이 0으로 확장되지 않습니다.
- 메트릭을 기반으로 복제본의 크기를 조정하고 HTTP 트래픽을 가로채지 않습니다.
다행히도 공식 자동 스케일러를 사용할 필요는 없지만 대신 KEDA를 사용할 수 있습니다.
KEDA 는 세 가지 구성 요소로 구성된 자동 스케일러입니다.
- 스케일러
- 메트릭 어댑터
- 컨트롤러
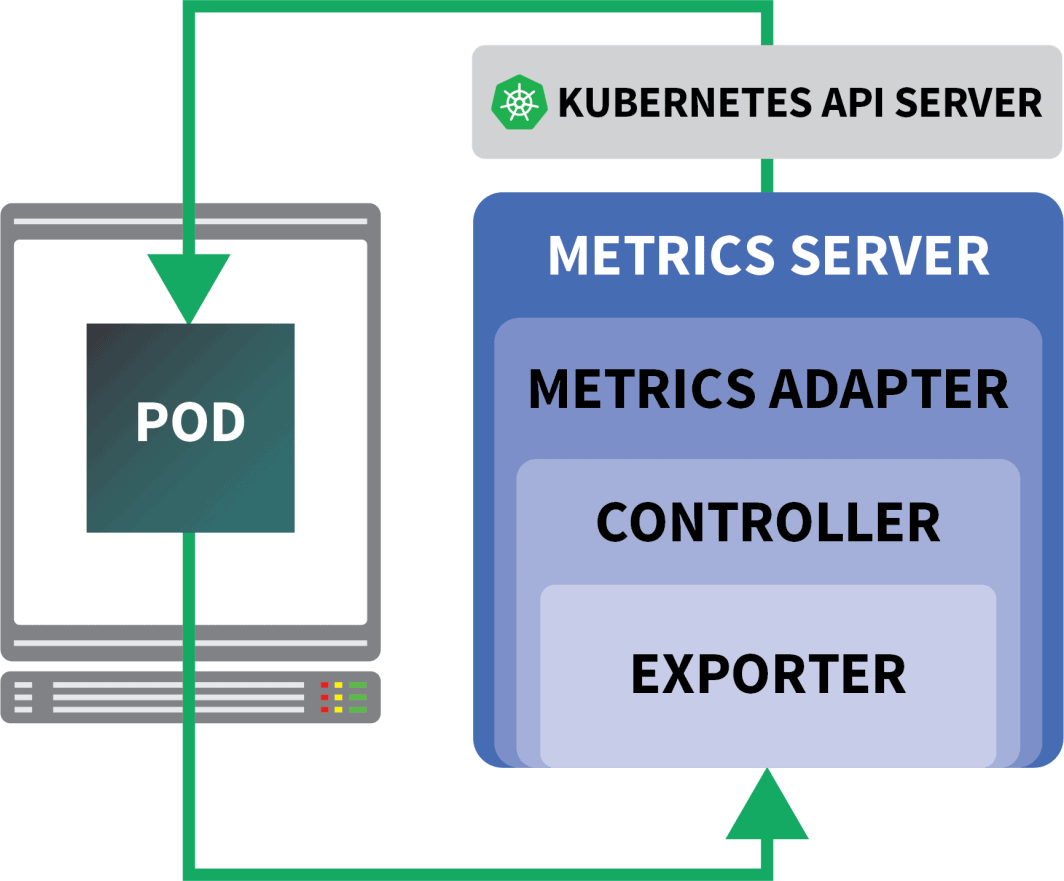
스케일러는 데이터베이스, 메시지 브로커, 원격 분석 시스템 등에서 메트릭을 수집할 수 있는 어댑터와 같습니다.
예를 들어 HTTP 스케일러는 HTTP 트래픽을 가로채고 수집할 수 있는 어댑터입니다.
여기에서 RabbitMQ를 사용하는 스케일러의 예를 찾을 수 있습니다.
메트릭 어댑터는 스케일러에 의해 수집된 메트릭을 쿠버네티스 메트릭 파이프라인이 사용할 수 있는 형식으로 노출하는 역할을 합니다.
마지막으로 컨트롤러는 모든 구성 요소를 함께 붙입니다.
- 어댑터를 사용하여 메트릭을 수집하고 메트릭에 노출합니다. API.
- KEDA 특정 CRD(사용자 지정 리소스 정의)(예: ScaledObject, TriggerAuthentication) 등을 등록하고 관리합니다.
- 그것은 당신을 대신하여 수평 포드 자동 스케일러를 생성하고 관리합니다.
그것이 이론이지만, 실제로 어떻게 작동하는지 봅시다.
컨트롤러를 설치하는 더 빠른 방법은 Helm을 사용하는 것입니다.
설치 지침은 공식 Helm 웹 사이트에서 찾을 수 있습니다.
bash
$ helm repo add kedacore https://kedacore.github.io/charts
$ helm install keda kedacore/kedaKEDA는 기본적으로 HTTP 스케일러와 함께 제공되지 않으므로 별도로 설치해야합니다.
bash
$ helm install http-add-on kedacore/keda-add-ons-http이제 앱을 확장할 준비가 되었습니다.
자동 크기 조정 전략 정의
KEDA HTTP 추가 기능은 응용 프로그램의 크기를 조정하는 방법을 설명할 수 있는 CRD를 노출합니다.
예를 들어 보겠습니다.
yaml
kind: HTTPScaledObject
apiVersion: http.keda.sh/v1alpha1
metadata:
name: podinfo
spec:
host: example.com
targetPendingRequests: 100
scaleTargetRef:
deployment: podinfo
service: podinfo
port: 80
replicas:
min: 0
max: 10이 파일은 인터셉터에게 example.com 요청을 podinfo 서비스로 전달하도록 지시합니다.
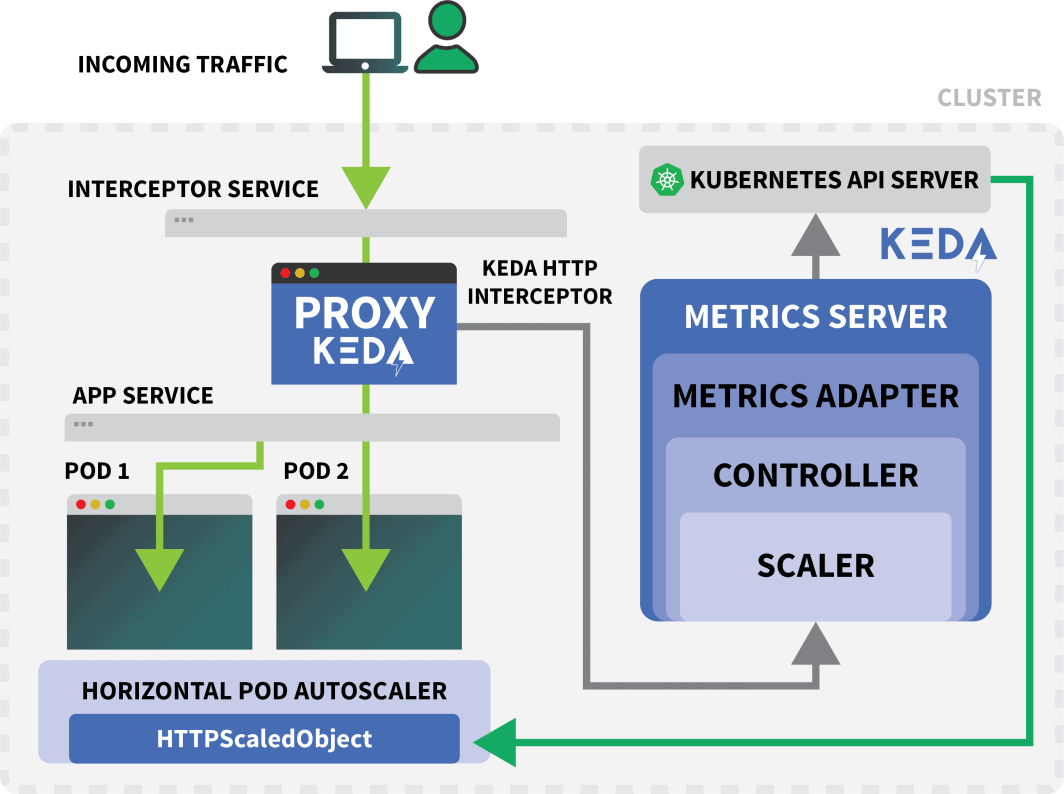
또한 크기를 조정해야 하는 배포 이름(이 경우 podinfo)도 포함됩니다.
YAML을 클러스터에 제출해 보겠습니다.
bash
$ kubectl apply -f scaled-object.yaml정의를 제출하자마자 포드가 삭제됩니다!
하지만 왜?
HTTPScaledObject를 만든 후 KEDA는 트래픽이 없으므로 즉시 배포를 0으로 확장합니다.
앱을 확장하려면 앱에 HTTP 요청을 보내야 합니다.
서비스에 연결하고 요청을 발행하여 테스트해 보겠습니다.
bash
$ kubectl port-forward svc/podinfo 8080:80명령이 중단되었습니다!
그것은 의미가 있습니다. 요청을 처리할 포드가 없습니다.
그러나 쿠버네티스가 배포를 1로 확장하지 않는 이유는 무엇입니까?
KEDA 인터셉터 테스트
쿠버네티스 서비스라는 keda-add-ons-http-interceptor-proxy Helm을 사용하여 추가 기능을 설치할 때 만들어졌습니다.
자동 크기 조정이 적절하게 작동하려면 HTTP 트래픽이 먼저 해당 서비스를 통해 라우팅되어야 합니다.
당신은 사용할 수 있습니다 kubectl port-forward 그것을 테스트하려면 :
shell
$ kubectl port-forward svc/keda-add-ons-http-interceptor-proxy 8080:8080이번에는 브라우저에서 URL을 방문 할 수 없습니다.
단일 KEDA HTTP 인터셉터는 여러 배포를 처리할 수 있습니다.
그렇다면 트래픽을 라우팅할 위치를 어떻게 알 수 있을까요?
yaml
kind: HTTPScaledObject
apiVersion: http.keda.sh/v1alpha1
metadata:
name: podinfo
spec:
host: example.com
targetPendingRequests: 100
scaleTargetRef:
deployment: podinfo
service: podinfo
port: 80
replicas:
min: 0
max: 10HTTPScaledObject에는 이를 위해 정확하게 사용되는 호스트 필드가 있습니다.
이 예제에서는 요청이 example.com 에서 온 것처럼 가장합니다.
Host 헤더를 설정하여 그렇게 할 수 있습니다.
bash
$ curl localhost:8080 -H 'Host: example.com'약간의 지연에도 불구하고 응답을 받게됩니다.
포드를 검사하면 배포가 단일 복제본으로 확장되었음을 알 수 있습니다.
bash
$ kubectl get pods그래서 방금 무슨 일이 일어 났습니까?
트래픽을 KEDA의 서비스로 라우팅할 때 인터셉터는 아직 응답이 없는 보류 중인 HTTP 요청 수를 추적합니다.
KEDA 스케일러는 인터셉터의 큐 크기를 주기적으로 확인하고 메트릭을 저장합니다.
KEDA 컨트롤러는 메트릭을 모니터링하고 필요에 따라 복제본 수를 늘리거나 줄입니다. 이 경우 KEDA 컨트롤러가 배포를 단일 복제본으로 확장하기에 충분한 단일 요청이 보류 중입니다.
다음을 사용하여 개별 인터셉터의 보류 중인 HTTP 요청 큐의 상태를 가져올 수 있습니다.
bash
$ kubectl proxy &
$ curl -L localhost:8001/api/v1/namespaces/default/services/keda-add-ons-http-interceptor-admin:9090/proxy/queue
{"example.com":0,"localhost:8080":0}이 디자인으로 인해 트래픽을 앱으로 라우팅하는 방법에주의해야합니다.
KEDA는 트래픽을 가로챌 수 있는 경우에만 트래픽을 확장할 수 있습니다.
기존 수신 컨트롤러가 있고 이를 사용하여 트래픽을 앱으로 전달하려면 트래픽을 HTTP 추가 기능 서비스로 전달하도록 수신 매니페스트를 수정해야 합니다.
예를 들어 보겠습니다.
KEDA HTTP 애드온과 수신 결합
설치할 수 있습니다. nginx헬름을 가진 침투 관제사:
bash
$ helm upgrade --install ingress-nginx ingress-nginx \
--repo https://kubernetes.github.io/ingress-nginx \
--namespace ingress-nginx --create-namespace트래픽을 podinfo로 라우팅하는 수신 매니페스트를 작성해 보겠습니다.
yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: podinfo
spec:
ingressClassName: nginx
rules:
- host: example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: keda-add-ons-http-interceptor-proxy # <- this
port:
number: 8080다음을 사용하여 부하 분산 장치의 IP를 검색할 수 있습니다.
bash
LB_IP=$(kubectl get services -l "app.kubernetes.io/component=controller" -o jsonpath="{.items[0].status.loadBalancer.ingress
[0].ip}" -n ingress-nginx)마지막으로 다음을 사용하여 앱에 요청할 수 있습니다.
bash
curl $LB_IP -H "Host: example.com"잘됐어요!
충분히 오래 기다리면 배포가 결국 0으로 확장된다는 것을 알 수 있습니다.
이것은 쿠버네티스의 서버리스와 어떻게 비교됩니까?
이 설정과 OpenFaaS와 같은 쿠버네티스의 서버리스 프레임워크 사이에는 몇 가지 중요한 차이점이 있습니다.
- KEDA를 사용하면 앱을 배포하기 위해 SDK를 다시 아키텍처하거나 사용할 필요가 없습니다.
- 서버리스 프레임워크는 라우팅 및 요청 제공을 처리합니다. 논리만 작성하면 됩니다.
- KEDA를 사용하면 배포가 일반 컨테이너입니다. 서버리스 프레임 워크를 사용하면 항상 그런 것은 아닙니다.
이 크기 조정이 실제로 작동하는지 확인하고 싶으신가요? Scaling Kubernetes 웨비나 시리즈에 등록하세요.




댓글 (5)
Very nice tutorial. In the case without the nginx ingress, can you explain how to access from the outside, instead of the localhost? I tried to use a NodePort service, but the port gets closed when the Interceptor is installed. The Interceptor proxy is a ClusterIP service. How can we access it from the outside? Is there any sort of kubectl port forwarding instruction?
Hi Rui! I forwarded your question to Daniele and here is his response:
It should work with NodePort, but you have to set the right header (i.e.
Host: example.com) when you make the request. There is no way for the interceptor to decide where the traffic should go without that.Muito bom o conteudo!!!
Where does NodeBalancer show up in this configuration? Does LKE take over that job?
Hi Lee – The NodeBalancer is created during the installation of the nginx-ingress controller. For a more detailed explanation of this process you can check out our guide titled Deploying NGINX Ingress on Linode Kubernetes Engine.
Once the NodeBalancer is provisioned it is controlled via LKE. We don’t recommend configuring the settings of your LKE NodeBalancers through the Cloud Manager.