

この投稿は「Scaling Kubernetes Series」の一部です。 登録をクリックしてライブ視聴または録画にアクセスし、このシリーズの他の投稿をご覧ください。
インフラ コスト削減のためには、使っていないときのリソースをオフにすることに尽きます。しかし、課題は、これらのリソースを必要なときに自動的にオンにする方法を見つけ出すことです。Linode Kubernetes Engine(LKE) を使って Kubernetes クラスタをデプロイし、Kubernetes Events-Driven Autoscaler (KEDA) を使ってゼロまでスケールして戻すために必要なステップを実行しましょう。
なぜScale to Zeroなのか
Kubernetes上でそれなりにリソース集約的なアプリを動かしていて、それが勤務時間中にしか必要でない場合を考えてみましょう。
退社時にオフにして、始業時にオンにするのもよいでしょう。
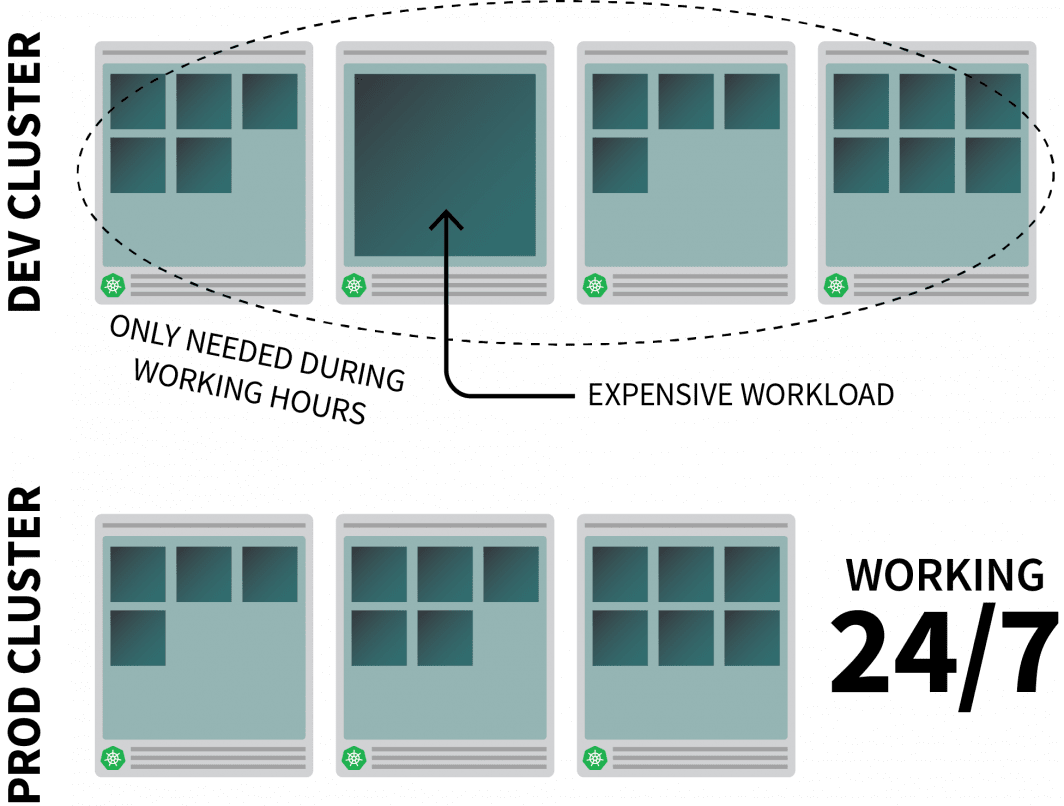
CronJobを使用してインスタンスのスケールアップとスケールダウンを行うこともできますが、このソリューションは事前に設定されたスケジュールでしか実行できない、その場しのぎのものです。
週末はどうなるのでしょうか?また、祝祭日は?あるいは、チームが病気で休んでいるときは?
増え続けるルールのリストを生成する代わりに、トラフィックに基づいてワークロードをスケールアップすることができます。トラフィックが増えたら、レプリカをスケールアップすることができます。トラフィックがない場合は、アプリをオフにすることができます。アプリをオフにした状態で新たなリクエストが着信した場合、Kubernetesは少なくとも1つのレプリカを起動してトラフィックを処理します。

次に、方法についてです。
- アプリへのすべてのトラフィックを遮断することができます。
- トラフィックを監視する。
- は、レプリカの数を調整したり、アプリをオフにしたりするためにオートスケーラを設定します。
もし、このチュートリアルのコードを読みたい場合は、LearnK8s GitHubで読むことができます。
クラスターを作成する
まずはKubernetesクラスターを作成するところから始めましょう。
以下のコマンドで、クラスタの作成とkubeconfigファイルの保存を行うことができます。
bash
$ linode-cli lke cluster-create \
--label cluster-manager \
--region eu-west \
--k8s_version 1.23
$ linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfigでインストールが成功したことを確認できます。
bash
$ kubectl get pods -A --kubeconfig=kubeconfig環境変数でkubeconfigファイルを書き出すと、通常はより便利です。
で行うことができます。
bash
$ export KUBECONFIG=${PWD}/kubeconfig
$ kubectl get podsでは、アプリケーションをデプロイしてみましょう。
アプリケーションのデプロイ
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
spec:
containers:
- name: podinfo
image: stefanprodan/podinfo
ports:
- containerPort: 9898
---
apiVersion: v1
kind: Service
metadata:
name: podinfo
spec:
ports:
- port: 80
targetPort: 9898
selector:
app: podinfoでYAMLファイルを投稿することができます。
terminal|command=1|title=bash
$ kubectl apply -f 1-deployment.yamlとアプリを訪問することができます。
ブラウザでlocalhost:8080を開いてください。
bash
$ kubectl port-forward svc/podinfo 8080:80この時点で、アプリが表示されるはずです。
次に、オートスケーラであるKEDAをインストールしましょう。
Kubernetesイベントドリブンオートスケーラー KEDA
Kubernetesでは、レプリカを動的に増減させるためのコントローラとしてHPA(Horizontal Pod Autoscaler)が用意されています。
残念ながら、HPAにはいくつかの欠点があります。
- メトリックスサーバーをインストールし、メトリックスの集計と公開を行う必要があります。
- レプリカがゼロになるとスケールしない。
- メトリックに基づいてレプリカをスケーリングし、HTTPトラフィックを傍受しない。
幸い、公式のオートスケーラーを使わなくても、KEDAで代用することができます。
KEDAは、3つのコンポーネントからなるオートスケーラーです。
- スケーラー
- メトリックスアダプター
- Aコントローラー
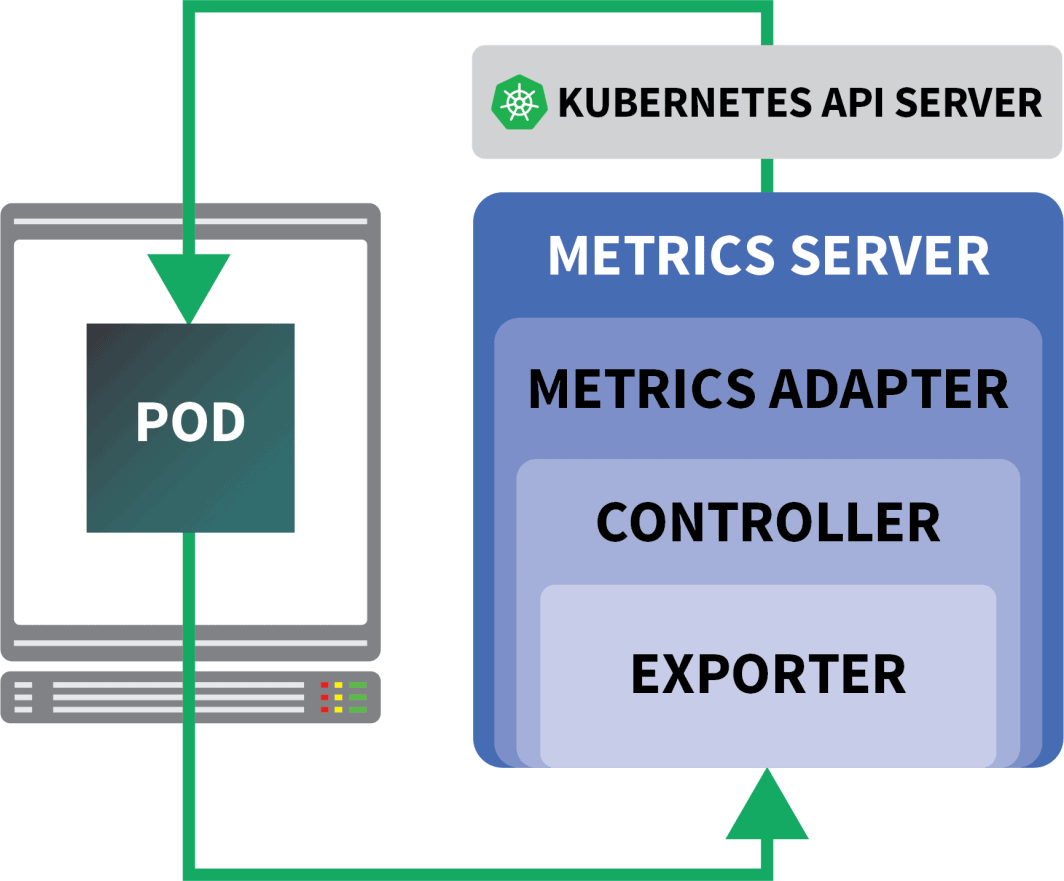
スケーラーは、データベース、メッセージブローカー、テレメトリーシステムなどからメトリクスを収集できるアダプターのようなものである。
例えば、HTTP Scalerは、HTTPトラフィックをインターセプトして収集することができるアダプタである。
RabbitMQを利用したスケーラの例はこちらで紹介しています。
Metrics Adapter は、Scaler が収集したメトリクスを、Kubernetes のメトリクス・パイプラインが消費できる形式で公開する役割を担っています。
そして最後に、すべてのコンポーネントを接着するのがコントローラーです。
- アダプタを使用してメトリクスを収集し、それをメトリクスに公開します。 API.
- KEDA固有のカスタムリソース定義(CRD)、すなわちScaledObject、TriggerAuthenticationなどの登録と管理を行います。
- Horizontal Pod Autoscalerの作成と管理を代行します。
理屈はそうですが、実際にどうなのか見てみましょう。
コントローラーのインストールには、Helmを使用するのが手っ取り早いです。
インストール方法は、Helmの公式サイトに掲載されています。
bash
$ helm repo add kedacore https://kedacore.github.io/charts
$ helm install keda kedacore/kedaKEDAにはHTTPスケーラーがデフォルトで搭載されていないので、別途インストールする必要があります。
bash
$ helm install http-add-on kedacore/keda-add-ons-httpこの時点で、アプリをスケールアップする準備が整いました。
オートスケーリング戦略の定義
KEDA HTTPアドオンでは、アプリケーションがどのようにスケールされるべきかを記述できるCRDが公開されています。
例を見てみましょう。
yaml
kind: HTTPScaledObject
apiVersion: http.keda.sh/v1alpha1
metadata:
name: podinfo
spec:
host: example.com
targetPendingRequests: 100
scaleTargetRef:
deployment: podinfo
service: podinfo
port: 80
replicas:
min: 0
max: 10このファイルは、example.comへのリクエストをpodinfoサービスに転送するよう、インターセプターに指示します。
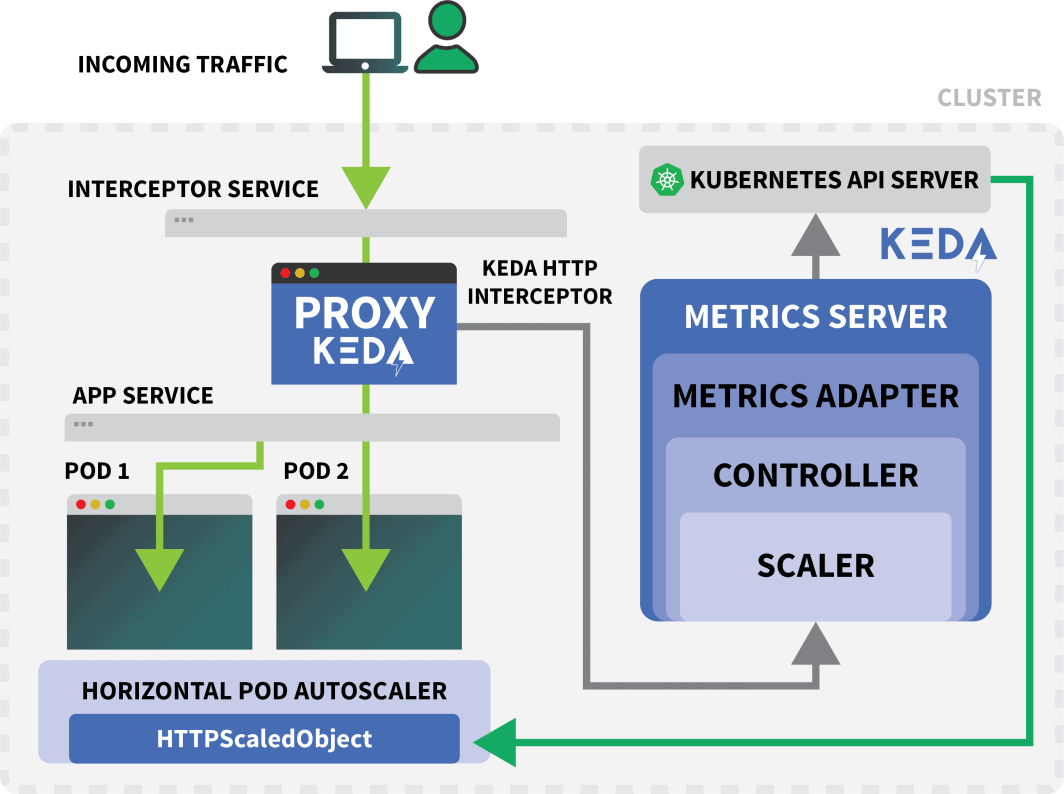
また、スケーリングされるべきデプロイメントの名前(この場合、podinfo)も含まれます。
でクラスタにYAMLを投入してみましょう。
bash
$ kubectl apply -f scaled-object.yaml定義を提出すると同時に、ポッドは削除されます
でも、なぜ?
HTTPScaledObjectが作成されると、トラフィックが発生しないため、KEDAは直ちにデプロイメントをゼロにスケールします。
アプリを拡張するためには、アプリにHTTPリクエストを送信する必要があります。
サービスに接続し、リクエストを発行してテストしてみましょう。
bash
$ kubectl port-forward svc/podinfo 8080:80コマンドがハングアップする!
リクエストに応えるポッドがないのですから、当然です。
しかし、なぜKubernetesはデプロイを1にスケーリングしないのでしょうか?
KEDAインターセプターのテスト
というKubernetesサービス。 keda-add-ons-http-interceptor-proxy は、Helm を使用してアドオンをインストールしたときに作成されます。
オートスケールが適切に機能するためには、HTTPトラフィックが最初にそのサービスを経由する必要があります。
を使用することができます。 kubectl port-forward を試してみてください。
shell
$ kubectl port-forward svc/keda-add-ons-http-interceptor-proxy 8080:8080今回は、ブラウザでそのURLにアクセスすることはできません。
1つのKEDA HTTPインターセプターで、複数のデプロイメントを処理することができます。
では、どのようにしてトラフィックの経路を決めているのでしょうか。
yaml
kind: HTTPScaledObject
apiVersion: http.keda.sh/v1alpha1
metadata:
name: podinfo
spec:
host: example.com
targetPendingRequests: 100
scaleTargetRef:
deployment: podinfo
service: podinfo
port: 80
replicas:
min: 0
max: 10HTTPScaledObjectには、まさにそのために使用されるhostフィールドがあります。
この例では、example.comからリクエストが来たことにしています。
Hostヘッダーを設定することで可能です。
bash
$ curl localhost:8080 -H 'Host: example.com'少し遅れてではありますが、回答が届きます。
Podを検査すると、デプロイがシングルレプリカにスケールされていることがわかります。
bash
$ kubectl get podsで、何が起きたの?
KEDAのサービスにトラフィックをルーティングすると、インターセプターは、まだ応答がない保留中のHTTPリクエストの数を記録する。
KEDAスケーラは、定期的にインターセプターのキューのサイズをチェックし、メトリクスを保存します。
KEDAコントローラはメトリックを監視し、必要に応じてレプリカの数を増減させます。この場合、1つのリクエストが保留されています。これは、KEDAコントローラーがデプロイメントを1つのレプリカにスケールさせるのに十分な数です。
で個々のインターセプターの保留中のHTTPリクエストキューの状態を取得することができます。
bash
$ kubectl proxy &
$ curl -L localhost:8001/api/v1/namespaces/default/services/keda-add-ons-http-interceptor-admin:9090/proxy/queue
{"example.com":0,"localhost:8080":0}この設計のため、アプリへのトラフィックをどのようにルーティングするかに注意する必要があります。
KEDAがトラフィックを拡張できるのは、インターセプトが可能な場合のみです。
既存のイングレスコントローラーがあり、それを使用してアプリにトラフィックを転送したい場合、HTTPアドオンサービスにトラフィックを転送するようにイングレスマニフェストを修正する必要があります。
例を見てみましょう。
KEDA HTTPアドオンとIngressの組み合わせ
nginx-ingressコントローラをHelmでインストールすることができます。
bash
$ helm upgrade --install ingress-nginx ingress-nginx \
--repo https://kubernetes.github.io/ingress-nginx \
--namespace ingress-nginx --create-namespacePodinfoにトラフィックをルーティングするためのingressマニフェストを書きましょう。
yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: podinfo
spec:
ingressClassName: nginx
rules:
- host: example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: keda-add-ons-http-interceptor-proxy # <- this
port:
number: 8080でロードバランサーのIPを取得することができます。
bash
LB_IP=$(kubectl get services -l "app.kubernetes.io/component=controller" -o jsonpath="{.items[0].status.loadBalancer.ingress
[0].ip}" -n ingress-nginx)でようやくアプリにリクエストできる。
bash
curl $LB_IP -H "Host: example.com"うまくいった!
長く待っていれば、やがて展開がゼロになることに気づくでしょう。
Kubernetes上のServerlessと比較するとどうでしょうか?
このセットアップと、OpenFaaSのようなKubernetes上のサーバーレスフレームワークとの間には、いくつかの大きな違いがあります。
- KEDAでは、アプリをデプロイするために再アーキテクチャやSDKを使用する必要はありません。
- サーバーレスフレームワークは、リクエストのルーティングとサービングを担当します。あなたはロジックを書くだけです。
- KEDAでは、デプロイは普通のコンテナです。サーバーレスフレームワークの場合、必ずしもそうとは限りません。
このスケーリングを実際に見てみたいですか?Scaling Kubernetes Webinarシリーズにご登録ください。



コメント (5)
Very nice tutorial. In the case without the nginx ingress, can you explain how to access from the outside, instead of the localhost? I tried to use a NodePort service, but the port gets closed when the Interceptor is installed. The Interceptor proxy is a ClusterIP service. How can we access it from the outside? Is there any sort of kubectl port forwarding instruction?
Hi Rui! I forwarded your question to Daniele and here is his response:
It should work with NodePort, but you have to set the right header (i.e.
Host: example.com) when you make the request. There is no way for the interceptor to decide where the traffic should go without that.Muito bom o conteudo!!!
Where does NodeBalancer show up in this configuration? Does LKE take over that job?
Hi Lee – The NodeBalancer is created during the installation of the nginx-ingress controller. For a more detailed explanation of this process you can check out our guide titled Deploying NGINX Ingress on Linode Kubernetes Engine.
Once the NodeBalancer is provisioned it is controlled via LKE. We don’t recommend configuring the settings of your LKE NodeBalancers through the Cloud Manager.