

Dieser Beitrag ist Teil unserer Serie zur Skalierung von Kubernetes. Registrieren Sie sich um ihn live zu sehen oder auf die Aufzeichnung zuzugreifen, und sehen Sie sich unsere anderen Beiträge in dieser Serie an:
Eine interessante Herausforderung bei Kubernetes ist die Bereitstellung von Workloads über mehrere Regionen hinweg. Obwohl Sie technisch gesehen einen Cluster mit mehreren Knoten in verschiedenen Regionen haben können, wird dies im Allgemeinen als etwas angesehen, das Sie aufgrund der zusätzlichen Latenzzeit vermeiden sollten.
Eine beliebte Alternative ist die Bereitstellung eines Clusters für jede Region und die Suche nach einer Möglichkeit, diese zu orchestrieren.
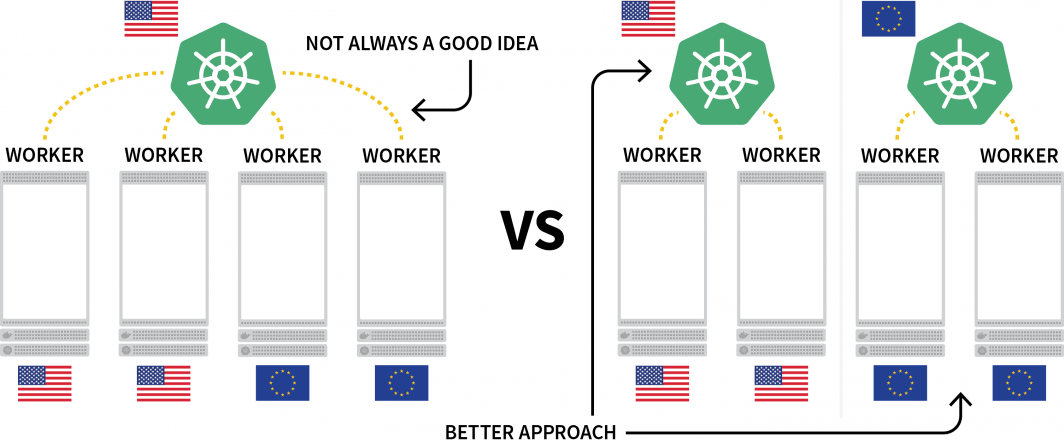
In diesem Beitrag werden Sie:
- Bilden Sie drei Cluster: einen in Nordamerika, einen in Europa und einen in Südostasien.
- Erstellen Sie einen vierten Cluster, der als Orchestrator für die anderen fungieren wird.
- Richten Sie ein einziges Netz aus den drei Clusternetzen ein, um eine nahtlose Kommunikation zu ermöglichen.
Dieser Beitrag wurde mit einem Skript versehen, das mit Terraform funktioniert und nur minimale Interaktion erfordert. Sie können den Code dafür auf LearnK8s GitHub finden.
Erstellen des Cluster-Managers
Beginnen wir mit der Erstellung des Clusters, der den Rest verwalten wird. Die folgenden Befehle können verwendet werden, um den Cluster zu erstellen und die kubeconfig-Datei zu speichern.
bash
$ linode-cli lke cluster-create \
--label cluster-manager \
--region eu-west \
--k8s_version 1.23
$ linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfig-cluster-managerMit können Sie überprüfen, ob die Installation erfolgreich war:
bash
$ kubectl get pods -A --kubeconfig=kubeconfig-cluster-managerAusgezeichnet!
Im Clustermanager installieren Sie Karmada, ein Verwaltungssystem, mit dem Sie Ihre Cloud-nativen Anwendungen über mehrere Kubernetes-Cluster und Clouds hinweg ausführen können. Karmada verfügt über eine Steuerebene, die im Cluster-Manager installiert ist, und den Agenten, der in jedem anderen Cluster installiert ist.
Die Steuerungsebene besteht aus drei Komponenten:
- Ein API-Server;
- Ein Controller Manager; und
- Ein Planer
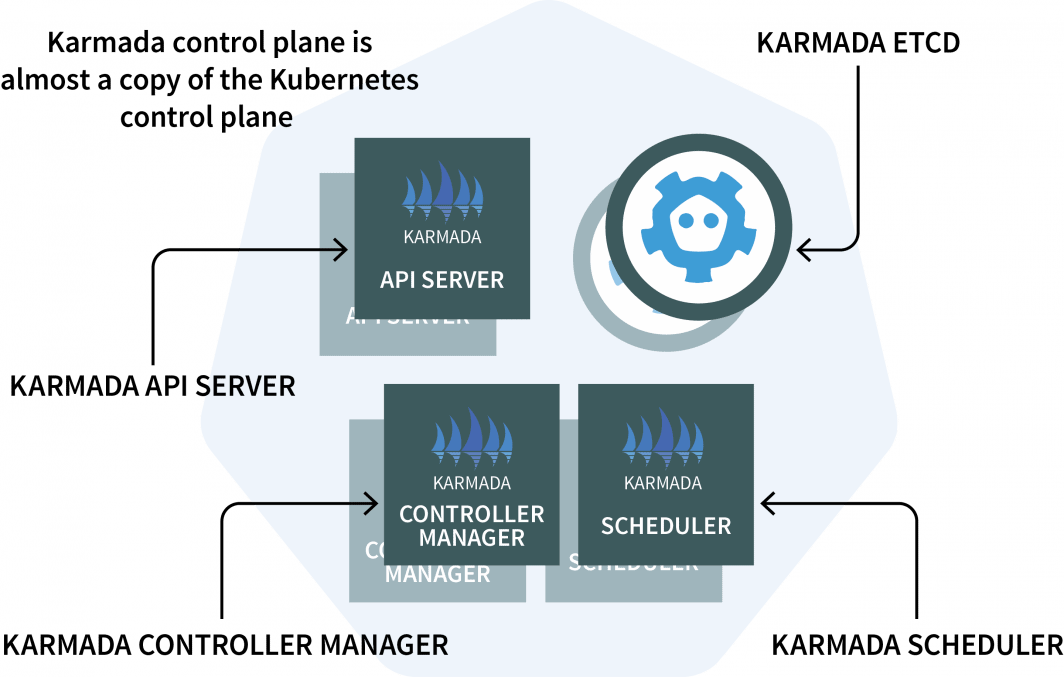
Wenn Ihnen das bekannt vorkommt, liegt das daran, dass die Kubernetes-Kontrollebene die gleichen Komponenten enthält! Karmada musste sie kopieren und erweitern, um mit mehreren Clustern arbeiten zu können.
Das ist genug Theorie. Kommen wir zum Code.
Sie werden Helm verwenden, um den Karmada-API-Server zu installieren. Fügen wir das Helm-Repository mit hinzu:
bash
$ helm repo add karmada-charts https://raw.githubusercontent.com/karmada-io/karmada/master/charts
$ helm repo list
NAME URL
karmada-charts https://raw.githubusercontent.com/karmada-io/karmada/master/chartsDa der Karmada API Server von allen anderen Clustern erreichbar sein muss, müssen Sie
- es vom Knoten aus freizulegen; und
- stellen Sie sicher, dass die Verbindung vertrauenswürdig ist.
Rufen wir also die IP-Adresse des Knotens ab, der die Steuerungsebene hostet:
bash
kubectl get nodes -o jsonpath='{.items[0].status.addresses[?(@.type==\"ExternalIP\")].address}' \
--kubeconfig=kubeconfig-cluster-managerJetzt können Sie die Karmada-Kontrollebene mit installieren:
bash
$ helm install karmada karmada-charts/karmada \
--kubeconfig=kubeconfig-cluster-manager \
--create-namespace --namespace karmada-system \
--version=1.2.0 \
--set apiServer.hostNetwork=false \
--set apiServer.serviceType=NodePort \
--set apiServer.nodePort=32443 \
--set certs.auto.hosts[0]="kubernetes.default.svc" \
--set certs.auto.hosts[1]="*.etcd.karmada-system.svc.cluster.local" \
--set certs.auto.hosts[2]="*.karmada-system.svc.cluster.local" \
--set certs.auto.hosts[3]="*.karmada-system.svc" \
--set certs.auto.hosts[4]="localhost" \
--set certs.auto.hosts[5]="127.0.0.1" \
--set certs.auto.hosts[6]="<insert the IP address of the node>"Sobald die Installation abgeschlossen ist, können Sie die kubeconfig abrufen, mit der Sie sich mit der Karmada-API verbinden:
bash
kubectl get secret karmada-kubeconfig \
--kubeconfig=kubeconfig-cluster-manager \
-n karmada-system \
-o jsonpath={.data.kubeconfig} | base64 -d > karmada-configAber Moment, warum noch eine kubeconfig-Datei?
Karmada API wurde entwickelt, um das standardmäßige Kubernetes-API zu ersetzen, behält aber dennoch alle Funktionen bei, die Sie gewohnt sind. Mit anderen Worten: Sie können mit kubectl Bereitstellungen erstellen, die mehrere Cluster umfassen.
Bevor Sie die Karmada-API und kubectl testen, sollten Sie die kubeconfig-Datei patchen. Standardmäßig kann die generierte kubeconfig nur innerhalb des Clusternetzwerks verwendet werden.
Sie können jedoch die folgende Zeile ersetzen, damit es funktioniert:
yaml
apiVersion: v1
kind: Config
clusters:
- cluster:
certificate-authority-data: LS0tLS1CRUdJTi…
insecure-skip-tls-verify: false
server: https://karmada-apiserver.karmada-system.svc.cluster.local:5443 # <- this works only in the cluster
name: karmada-apiserver
# truncatedErsetzen Sie sie durch die IP-Adresse des Knotens, die Sie zuvor abgerufen haben:
yaml
apiVersion: v1
kind: Config
clusters:
- cluster:
certificate-authority-data: LS0tLS1CRUdJTi…
insecure-skip-tls-verify: false
server: https://<node's IP address>:32443 # <- this works from the public internet
name: karmada-apiserver
# truncatedGroßartig, es ist an der Zeit, Karmada zu testen.
Installation des Karmada-Agenten
Geben Sie den folgenden Befehl ein, um alle Bereitstellungen und alle Cluster abzurufen:
bash
$ kubectl get clusters,deployments --kubeconfig=karmada-config
No resources foundEs überrascht nicht, dass es keine Bereitstellungen und keine zusätzlichen Cluster gibt. Fügen wir nun ein paar weitere Cluster hinzu und verbinden sie mit der Karmada-Kontrollebene.
Wiederholen Sie die folgenden Befehle dreimal:
bash
linode-cli lke cluster-create \
--label <insert-cluster-name> \
--region <insert-region> \
--k8s_version 1.23
linode-cli lke kubeconfig-view "insert cluster id here" --text | tail +2 | base64 -d > kubeconfig-<insert-cluster-name>Die Werte sollten die folgenden sein:
- Name des Clusters
euRegioneu-west und kubeconfig-Dateikubeconfig-eu - Name des Clusters
apRegionap-southund kubeconfig-Dateikubeconfig-ap - Name des Clusters
usRegionus-westund kubeconfig-Dateikubeconfig-us
Mit können Sie überprüfen, ob die Cluster erfolgreich erstellt wurden:
bash
$ kubectl get pods -A --kubeconfig=kubeconfig-eu
$ kubectl get pods -A --kubeconfig=kubeconfig-ap
$ kubectl get pods -A --kubeconfig=kubeconfig-usJetzt ist es an der Zeit, dass sie sich dem Karmada-Cluster anschließen.
Karmada verwendet einen Agenten auf jedem anderen Cluster, um die Bereitstellung mit der Steuerungsebene zu koordinieren.
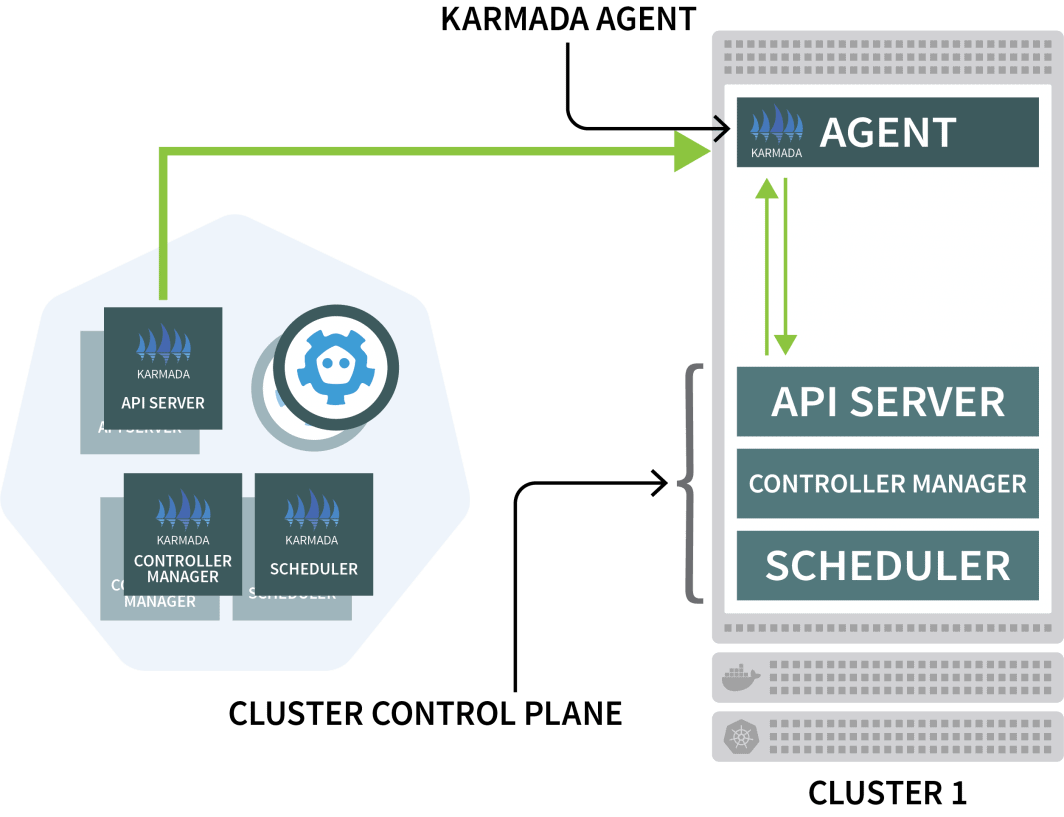
Sie werden Helm verwenden, um den Karmada-Agenten zu installieren und ihn mit dem Cluster-Manager zu verbinden:
bash
$ helm install karmada karmada-charts/karmada \
--kubeconfig=kubeconfig-<insert-cluster-name> \
--create-namespace --namespace karmada-system \
--version=1.2.0 \
--set installMode=agent \
--set agent.clusterName=<insert-cluster-name> \
--set agent.kubeconfig.caCrt=<karmada kubeconfig certificate authority> \
--set agent.kubeconfig.crt=<karmada kubeconfig client certificate data> \
--set agent.kubeconfig.key=<karmada kubeconfig client key data> \
--set agent.kubeconfig.server=https://<insert node's IP address>:32443 \Sie müssen den obigen Befehl dreimal wiederholen und die folgenden Variablen einfügen:
- Der Name des Clusters. Dieser ist entweder
eu,ap, oderus - Die Zertifizierungsstelle des Clustermanagers. Sie finden diesen Wert in der Datei
karmada-configDateiunder clusters[0].cluster['certificate-authority-data'].
Sie können den Wert entschlüsseln aus base64. - Die Daten des Client-Zertifikats des Benutzers. Sie finden diesen Wert in der Datei
karmada-configablegen unterusers[0].user['client-certificate-data'].
Sie können den Wert aus base64 dekodieren. - Die Daten des Client-Zertifikats des Benutzers. Sie finden diesen Wert in der Datei
karmada-configablegen unterusers[0].user['client-key-data'].
Sie können den Wert aus base64 dekodieren. - Die IP-Adresse des Karmada-Kontrollzentrums.
Um zu überprüfen, ob die Installation abgeschlossen ist, können Sie den folgenden Befehl eingeben:
bash
$ kubectl get clusters --kubeconfig=karmada-config
NAME VERSION MODE READY
eu v1.23.8 Pull True
ap v1.23.8 Pull True
us v1.23.8 Pull TrueAusgezeichnet!
Orchestrierung der Multicluster-Bereitstellung mit Karmada-Richtlinien
Bei der derzeitigen Konfiguration übermitteln Sie eine Arbeitslast an Karmada, das sie dann auf die anderen Cluster verteilt.
Testen wir dies, indem wir eine Bereitstellung erstellen:
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello
spec:
replicas: 3
selector:
matchLabels:
app: hello
template:
metadata:
labels:
app: hello
spec:
containers:
- image: stefanprodan/podinfo
name: hello
---
apiVersion: v1
kind: Service
metadata:
name: hello
spec:
ports:
- port: 5000
targetPort: 9898
selector:
app: helloSie können die Bereitstellung an den Karmada-API-Server mit übermitteln:
bash
$ kubectl apply -f deployment.yaml --kubeconfig=karmada-configDieser Einsatz hat drei Replikate - werden diese gleichmäßig auf die drei Cluster verteilt?
Schauen wir nach:
bash
$ kubectl get deployments --kubeconfig=karmada-config
NAME READY UP-TO-DATE AVAILABLE
hello 0/3 0 0Warum schafft Karmada die Pods nicht?
Lassen Sie uns den Einsatz beschreiben:
bash
$ kubectl describe deployment hello --kubeconfig=karmada-config
Name: hello
Namespace: default
Selector: app=hello
Replicas: 3 desired | 0 updated | 0 total | 0 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Events:
Type Reason From Message
---- ------ ---- -------
Warning ApplyPolicyFailed resource-detector No policy match for resourceKarmada weiß nicht, was es mit den Bereitstellungen machen soll, weil Sie keine Richtlinie angegeben haben.
Der Karmada-Scheduler verwendet Richtlinien für die Zuweisung von Workloads zu Clustern.
Definieren wir eine einfache Richtlinie, die jedem Cluster ein Replikat zuweist:
yaml
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: hello-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: hello
- apiVersion: v1
kind: Service
name: hello
placement:
clusterAffinity:
clusterNames:
- eu
- ap
- us
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- us
weight: 1
- targetCluster:
clusterNames:
- ap
weight: 1
- targetCluster:
clusterNames:
- eu
weight: 1Sie können die Richtlinie mit an den Cluster übermitteln:
bash
$ kubectl apply -f policy.yaml --kubeconfig=karmada-configSchauen wir uns die Bereitstellungen und Pods an:
bash
$ kubectl get deployments --kubeconfig=karmada-config
NAME READY UP-TO-DATE AVAILABLE
hello 3/3 3 3
$ kubectl get pods --kubeconfig=kubeconfig-eu
NAME READY STATUS RESTARTS
hello-5d857996f-hjfqq 1/1 Running 0
$ kubectl get pods --kubeconfig=kubeconfig-ap
NAME READY STATUS RESTARTS
hello-5d857996f-xr6hr 1/1 Running 0
$ kubectl get pods --kubeconfig=kubeconfig-us
NAME READY STATUS RESTARTS
hello-5d857996f-nbz48 1/1 Running 0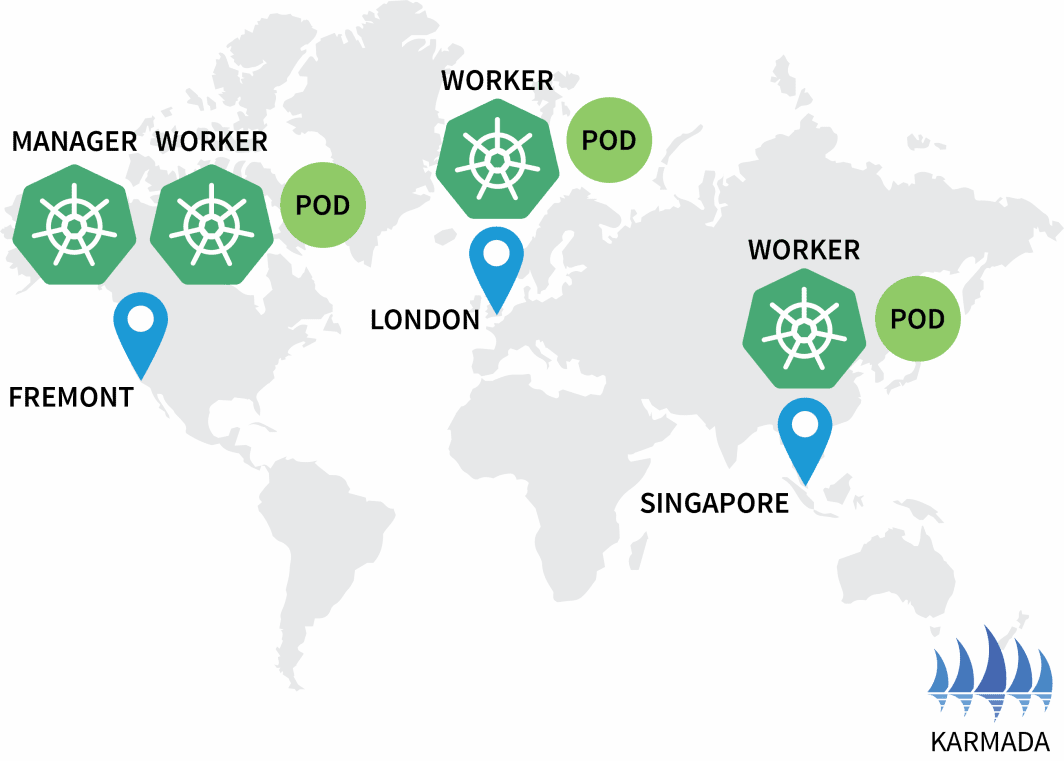
Karmada hat jedem Cluster einen Pod zugewiesen, da Ihre Richtlinie für jeden Cluster eine gleiche Gewichtung vorsieht.
Skalieren wir die Bereitstellung auf 10 Replikate mit:
bash
$ kubectl scale deployment/hello --replicas=10 --kubeconfig=karmada-configWenn Sie die Hülsen untersuchen, können Sie Folgendes feststellen:
bash
$ kubectl get deployments --kubeconfig=karmada-config
NAME READY UP-TO-DATE AVAILABLE
hello 10/10 10 10
$ kubectl get pods --kubeconfig=kubeconfig-eu
NAME READY STATUS RESTARTS
hello-5d857996f-dzfzm 1/1 Running 0
hello-5d857996f-hjfqq 1/1 Running 0
hello-5d857996f-kw2rt 1/1 Running 0
hello-5d857996f-nz7qz 1/1 Running 0
$ kubectl get pods --kubeconfig=kubeconfig-ap
NAME READY STATUS RESTARTS
hello-5d857996f-pd9t6 1/1 Running 0
hello-5d857996f-r7bmp 1/1 Running 0
hello-5d857996f-xr6hr 1/1 Running 0
$ kubectl get pods --kubeconfig=kubeconfig-us
NAME READY STATUS RESTARTS
hello-5d857996f-nbz48 1/1 Running 0
hello-5d857996f-nzgpn 1/1 Running 0
hello-5d857996f-rsp7k 1/1 Running 0Wir sollten die Politik dahingehend ändern, dass die EU- und US-Cluster 40 % der Hülsen besitzen und nur 20 % dem AP-Cluster überlassen werden.
yaml
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: hello-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: hello
- apiVersion: v1
kind: Service
name: hello
placement:
clusterAffinity:
clusterNames:
- eu
- ap
- us
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- us
weight: 2
- targetCluster:
clusterNames:
- ap
weight: 1
- targetCluster:
clusterNames:
- eu
weight: 2Sie können die Police mit einreichen:
bash
$ kubectl apply -f policy.yaml --kubeconfig=karmada-configSie können beobachten, wie sich die Verteilung Ihres Pods entsprechend verändert:
bash
$ kubectl get pods --kubeconfig=kubeconfig-eu
NAME READY STATUS RESTARTS AGE
hello-5d857996f-hjfqq 1/1 Running 0 6m5s
hello-5d857996f-kw2rt 1/1 Running 0 2m27s
$ kubectl get pods --kubeconfig=kubeconfig-ap
hello-5d857996f-k9hsm 1/1 Running 0 51s
hello-5d857996f-pd9t6 1/1 Running 0 2m41s
hello-5d857996f-r7bmp 1/1 Running 0 2m41s
hello-5d857996f-xr6hr 1/1 Running 0 6m19s
$ kubectl get pods --kubeconfig=kubeconfig-us
hello-5d857996f-nbz48 1/1 Running 0 6m29s
hello-5d857996f-nzgpn 1/1 Running 0 2m51s
hello-5d857996f-rgj9t 1/1 Running 0 61s
hello-5d857996f-rsp7k 1/1 Running 0 2m51s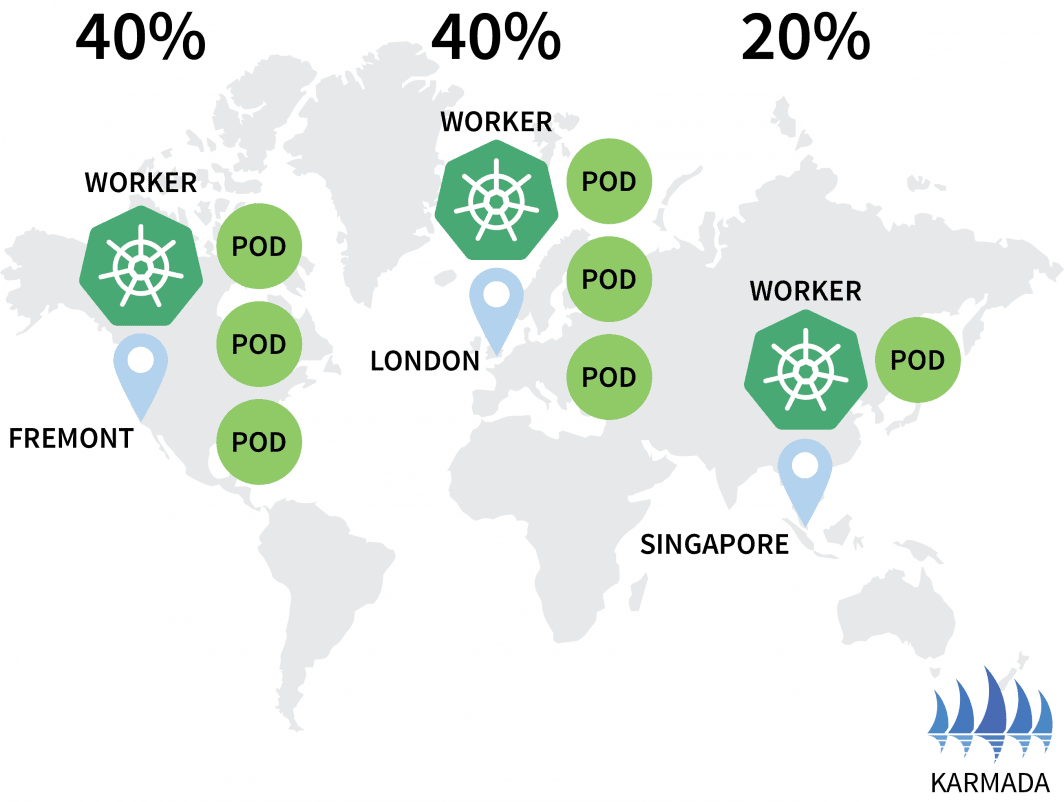
Großartig!
Karmada unterstützt verschiedene Richtlinien zur Verteilung Ihrer Arbeitslasten. Sie können die Dokumentation für fortgeschrittene Anwendungsfälle einsehen.
Die Pods laufen in den drei Clustern, aber wie kann man auf sie zugreifen?
Schauen wir uns den Service in Karmada an:
bash
$ kubectl describe service hello --kubeconfig=karmada-config
Name: hello
Namespace: default
Labels: propagationpolicy.karmada.io/name=hello-propagation
propagationpolicy.karmada.io/namespace=default
Selector: app=hello
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.105.24.193
IPs: 10.105.24.193
Port: <unset> 5000/TCP
TargetPort: 9898/TCP
Events:
Type Reason Message
---- ------ -------
Normal SyncSucceed Successfully applied resource(default/hello) to cluster ap
Normal SyncSucceed Successfully applied resource(default/hello) to cluster us
Normal SyncSucceed Successfully applied resource(default/hello) to cluster eu
Normal AggregateStatusSucceed Update resourceBinding(default/hello-service) with AggregatedStatus successfully.
Normal ScheduleBindingSucceed Binding has been scheduled
Normal SyncWorkSucceed Sync work of resourceBinding(default/hello-service) successful.Der Dienst ist in allen drei Clustern implementiert, aber sie sind nicht miteinander verbunden.
Auch wenn Karmada mehrere Cluster verwalten kann, bietet es keinen Netzwerkmechanismus , der sicherstellt, dass die drei Cluster miteinander verbunden sind. Mit anderen Worten: Karmada ist ein hervorragendes Werkzeug zur Orchestrierung von Bereitstellungen über Cluster hinweg, aber Sie brauchen etwas anderes, um sicherzustellen, dass diese Cluster miteinander kommunizieren können.
Verbinden von mehreren Clustern mit Istio
Istio wird in der Regel verwendet, um den Netzwerkverkehr zwischen Anwendungen im selben Cluster zu kontrollieren. Es funktioniert, indem es alle ausgehenden und eingehenden Anfragen abfängt und sie durch Envoy weiterleitet.
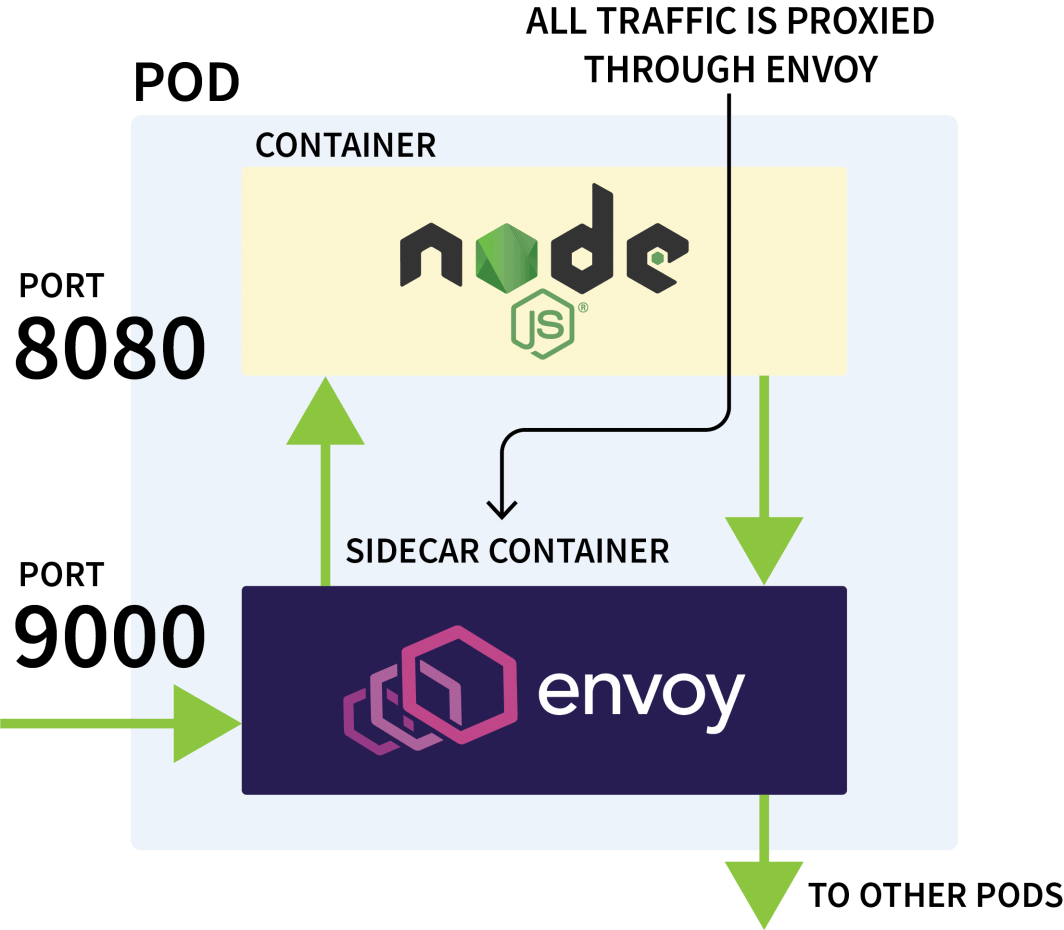
Die Istio-Kontrollebene ist für die Aktualisierung und das Sammeln von Metriken von diesen Proxys zuständig und kann auch Anweisungen zur Umleitung des Datenverkehrs geben.
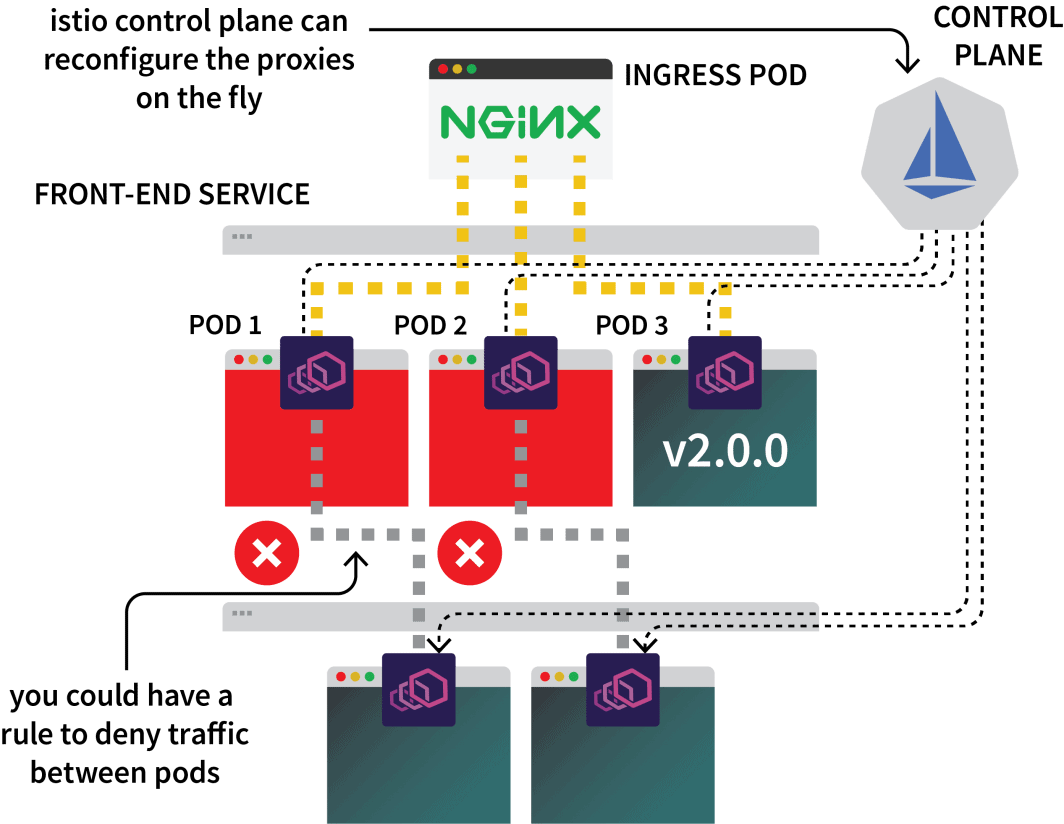
Sie könnten also Istio verwenden, um den gesamten Datenverkehr zu einem bestimmten Dienst abzufangen und ihn an einen der drei Cluster zu leiten. Das ist die Idee hinter dem Multicluster-Setup von Istio.
Genug der Theorie - machen wir uns die Hände schmutzig. Der erste Schritt besteht darin, Istio in den drei Clustern zu installieren.
Es gibt zwar mehrere Möglichkeiten, Istio zu installieren, aber ich bevorzuge normalerweise Helm:
bash
$ helm repo add istio https://istio-release.storage.googleapis.com/charts
$ helm repo list
NAME URL
istio https://istio-release.storage.googleapis.com/chartsSie können Istio in den drei Clustern mit installieren:
bash
$ helm install istio-base istio/base \
--kubeconfig=kubeconfig-<insert-cluster-name> \
--create-namespace --namespace istio-system \
--version=1.14.1Sie sollten die cluster-name mit ap, eu und us und führen Sie den Befehl für jeden aus.
Das Basisdiagramm installiert vor allem allgemeine Ressourcen wie Rollen und RoleBindings.
Die eigentliche Installation ist im Paket mit dem istiod Karte. Doch bevor Sie damit fortfahren, müssen Sie Konfiguration der Istio-Zertifizierungsstelle (CA) um sicherzustellen, dass die drei Cluster miteinander in Verbindung treten und sich gegenseitig vertrauen können.
Klonen Sie das Istio-Repository mit in ein neues Verzeichnis:
bash
$ git clone https://github.com/istio/istioErstellen einer certs und wechseln Sie in dieses Verzeichnis:
bash
$ mkdir certs
$ cd certsErstellen Sie das Stammzertifikat mit:
bash
$ make -f ../istio/tools/certs/Makefile.selfsigned.mk root-caDer Befehl erzeugte die folgenden Dateien:
root-cert.pem: das erzeugte Stammzertifikatroot-key.pem: der generierte Root-Schlüsselroot-ca.confdie Konfiguration für OpenSSL, um das Stammzertifikat zu erzeugenroot-cert.csr: die generierte CSR für das Stammzertifikat
Generieren Sie für jeden Cluster ein Zwischenzertifikat und einen Schlüssel für die Istio-Zertifizierungsstelle:
bash
$ make -f ../istio/tools/certs/Makefile.selfsigned.mk cluster1-cacerts
$ make -f ../istio/tools/certs/Makefile.selfsigned.mk cluster2-cacerts
$ make -f ../istio/tools/certs/Makefile.selfsigned.mk cluster3-cacertsDie Befehle erzeugen die folgenden Dateien in einem Verzeichnis namens cluster1, cluster2, und cluster3:
bash
$ kubectl create secret generic cacerts -n istio-system \
--kubeconfig=kubeconfig-<cluster-name>
--from-file=<cluster-folder>/ca-cert.pem \
--from-file=<cluster-folder>/ca-key.pem \
--from-file=<cluster-folder>/root-cert.pem \
--from-file=<cluster-folder>/cert-chain.pemSie sollten die Befehle mit den folgenden Variablen ausführen:
| cluster name | folder name |
| :----------: | :---------: |
| ap | cluster1 |
| us | cluster2 |
| eu | cluster3 |Damit sind Sie endlich bereit, istiod zu installieren:
bash
$ helm install istiod istio/istiod \
--kubeconfig=kubeconfig-<insert-cluster-name> \
--namespace istio-system \
--version=1.14.1 \
--set global.meshID=mesh1 \
--set global.multiCluster.clusterName=<insert-cluster-name> \
--set global.network=<insert-network-name>Wiederholen Sie den Befehl dreimal mit den folgenden Variablen:
| cluster name | network name |
| :----------: | :----------: |
| ap | network1 |
| us | network2 |
| eu | network3 |Sie sollten auch den Istio-Namensraum mit einer Topologie-Annotation versehen:
bash
$ kubectl label namespace istio-system topology.istio.io/network=network1 --kubeconfig=kubeconfig-ap
$ kubectl label namespace istio-system topology.istio.io/network=network2 --kubeconfig=kubeconfig-us
$ kubectl label namespace istio-system topology.istio.io/network=network3 --kubeconfig=kubeconfig-euIst das alles?
Fast.
Tunneln des Datenverkehrs mit einem Ost-West-Gateway
Sie brauchen noch:
- ein Gateway, um den Verkehr von einem Cluster zum anderen zu leiten; und
- einen Mechanismus zur Ermittlung von IP-Adressen in anderen Clustern.
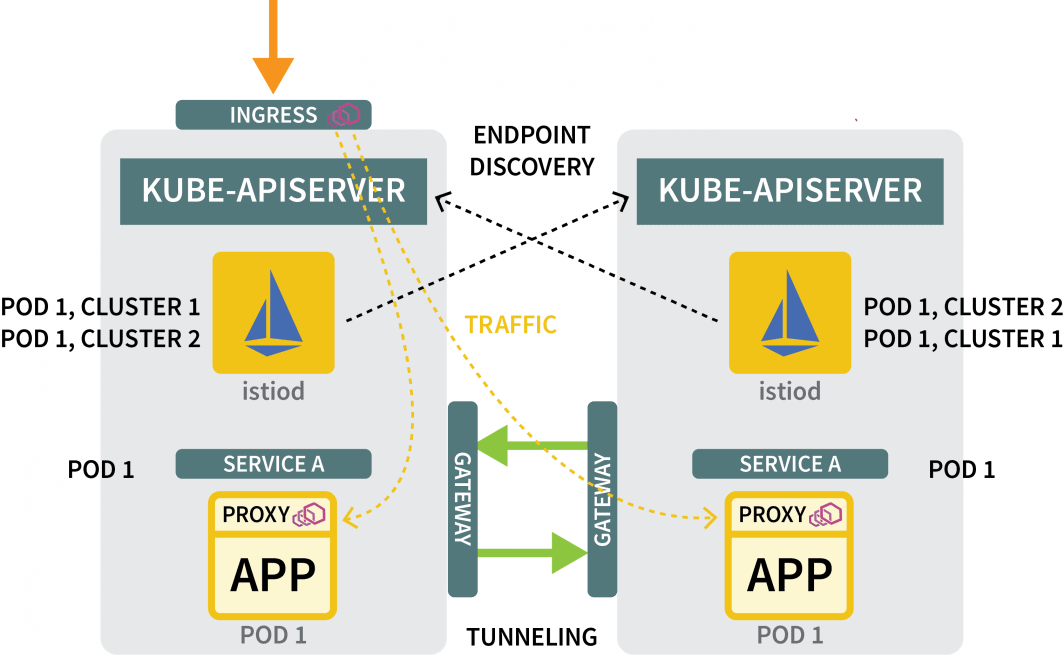
Für das Gateway können Sie Helm verwenden, um es zu installieren:
bash
$ helm install eastwest-gateway istio/gateway \
--kubeconfig=kubeconfig-<insert-cluster-name> \
--namespace istio-system \
--version=1.14.1 \
--set labels.istio=eastwestgateway \
--set labels.app=istio-eastwestgateway \
--set labels.topology.istio.io/network=istio-eastwestgateway \
--set labels.topology.istio.io/network=istio-eastwestgateway \
--set networkGateway=<insert-network-name> \
--set service.ports[0].name=status-port \
--set service.ports[0].port=15021 \
--set service.ports[0].targetPort=15021 \
--set service.ports[1].name=tls \
--set service.ports[1].port=15443 \
--set service.ports[1].targetPort=15443 \
--set service.ports[2].name=tls-istiod \
--set service.ports[2].port=15012 \
--set service.ports[2].targetPort=15012 \
--set service.ports[3].name=tls-webhook \
--set service.ports[3].port=15017 \
--set service.ports[3].targetPort=15017 \Wiederholen Sie den Befehl dreimal mit den folgenden Variablen:
| cluster name | network name |
| :----------: | :----------: |
| ap | network1 |
| us | network2 |
| eu | network3 |Stellen Sie dann für jeden Cluster ein Gateway mit der folgenden Ressource bereit:
yaml
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: cross-network-gateway
spec:
selector:
istio: eastwestgateway
servers:
- port:
number: 15443
name: tls
protocol: TLS
tls:
mode: AUTO_PASSTHROUGH
hosts:
- "*.local"Sie können die Datei den Clustern mit übergeben:
bash
$ kubectl apply -f expose.yaml --kubeconfig=kubeconfig-eu
$ kubectl apply -f expose.yaml --kubeconfig=kubeconfig-ap
$ kubectl apply -f expose.yaml --kubeconfig=kubeconfig-usFür die Erkennungsmechanismen müssen Sie die Anmeldedaten jedes Clusters gemeinsam nutzen. Dies ist notwendig, da die Cluster einander nicht kennen.
Um andere IP-Adressen zu ermitteln, müssen sie auf andere Cluster zugreifen und diese als mögliche Ziele für den Datenverkehr registrieren. Zu diesem Zweck müssen Sie ein Kubernetes-Geheimnis mit der kubeconfig-Datei für die anderen Cluster erstellen.
Istio verwendet diese, um sich mit den anderen Clustern zu verbinden, die Endpunkte zu erkennen und die Envoy-Proxys anzuweisen, den Datenverkehr weiterzuleiten.
Sie benötigen drei Geheimnisse:
yaml
apiVersion: v1
kind: Secret
metadata:
labels:
istio/multiCluster: true
annotations:
networking.istio.io/cluster: <insert cluster name>
name: "istio-remote-secret-<insert cluster name>"
type: Opaque
data:
<insert cluster name>: <insert cluster kubeconfig as base64>Sie sollten die drei Geheimnisse mit den folgenden Variablen erstellen:
| cluster name | secret filename | kubeconfig |
| :----------: | :-------------: | :-----------: |
| ap | secret1.yaml | kubeconfig-ap |
| us | secret2.yaml | kubeconfig-us |
| eu | secret3.yaml | kubeconfig-eu |Nun sollten Sie die Geheimnisse an den Cluster übermitteln und dabei darauf achten, dass das AP-Geheimnis nicht an den AP-Cluster übermittelt wird.
Die Befehle sollten die folgenden sein:
bash
$ kubectl apply -f secret2.yaml -n istio-system --kubeconfig=kubeconfig-ap
$ kubectl apply -f secret3.yaml -n istio-system --kubeconfig=kubeconfig-ap
$ kubectl apply -f secret1.yaml -n istio-system --kubeconfig=kubeconfig-us
$ kubectl apply -f secret3.yaml -n istio-system --kubeconfig=kubeconfig-us
$ kubectl apply -f secret1.yaml -n istio-system --kubeconfig=kubeconfig-eu
$ kubectl apply -f secret2.yaml -n istio-system --kubeconfig=kubeconfig-euUnd das ist alles!
Sie können die Einrichtung nun testen.
Testen der Multicluster-Vernetzung
Lassen Sie uns einen Einsatz für einen Schlaf-Pod erstellen.
Sie verwenden diesen Pod, um eine Anfrage an die zuvor erstellte Hello-Bereitstellung zu stellen:
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: sleep
spec:
selector:
matchLabels:
app: sleep
template:
metadata:
labels:
app: sleep
spec:
terminationGracePeriodSeconds: 0
containers:
- name: sleep
image: curlimages/curl
command: ["/bin/sleep", "3650d"]
imagePullPolicy: IfNotPresent
volumeMounts:
- mountPath: /etc/sleep/tls
name: secret-volume
volumes:
- name: secret-volume
secret:
secretName: sleep-secret
optional: trueSie können die Bereitstellung mit erstellen:
bash
$ kubectl apply -f sleep.yaml --kubeconfig=karmada-configDa es für diese Bereitstellung keine Richtlinie gibt, wird Karmada sie nicht bearbeiten und in der Schwebe lassen. Sie können die Richtlinie ändern, um die Bereitstellung mit aufzunehmen:
yaml
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: hello-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: hello
- apiVersion: v1
kind: Service
name: hello
- apiVersion: apps/v1
kind: Deployment
name: sleep
placement:
clusterAffinity:
clusterNames:
- eu
- ap
- us
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- us
weight: 2
- targetCluster:
clusterNames:
- ap
weight: 2
- targetCluster:
clusterNames:
- eu
weight: 1Sie können die Richtlinie mit anwenden:
bash
$ kubectl apply -f policy.yaml --kubeconfig=karmada-configMit können Sie herausfinden, wo der Pod eingesetzt wurde:
bash
$ kubectl get pods --kubeconfig=kubeconfig-eu
$ kubectl get pods --kubeconfig=kubeconfig-ap
$ kubectl get pods --kubeconfig=kubeconfig-usAngenommen, der Pod ist auf dem US-Cluster gelandet, führen Sie nun folgenden Befehl aus
Now, assuming the pod landed on the US cluster, execute the following command:
bash
for i in {1..10}
do
kubectl exec --kubeconfig=kubeconfig-us -c sleep \
"$(kubectl get pod --kubeconfig=kubeconfig-us -l \
app=sleep -o jsonpath='{.items[0].metadata.name}')" \
-- curl -sS hello:5000 | grep REGION
doneSie werden feststellen, dass die Antwort von verschiedenen Schoten aus verschiedenen Regionen kommt!
Auftrag erledigt!
Wie geht es jetzt weiter?
Diese Konfiguration ist recht einfach und lässt einige weitere Funktionen vermissen, die Sie wahrscheinlich einbauen möchten:
- können Sie von jedem Cluster aus einen Istio-Ingress bereitstellen, um den Datenverkehr aufzunehmen;
- Sie könnten Istio verwenden , um den Datenverkehr so zu gestalten, dass lokaler Datenverkehr bevorzugt wird; und
- können Sie Regeln zur Durchsetzung von Istio-Richtlinien verwenden, um festzulegen, wie der Datenverkehr zwischen den Clustern fließen kann.
Wir fassen zusammen, was wir in diesem Beitrag behandelt haben:
- die Verwendung von Karmada zur Kontrolle mehrerer Cluster;
- Festlegung von Richtlinien zur Planung von Workloads über mehrere Cluster hinweg;
- Nutzung von Istio zur Überbrückung der Vernetzung von mehreren Clustern und
- wie Istio den Datenverkehr abfängt und ihn an andere Cluster weiterleitet.
Sie können einen vollständigen Überblick über die Skalierung von Kubernetes über verschiedene Regionen hinweg sowie über andere Skalierungsmethoden erhalten, indem Sie sich für unsere Webinar-Reihe anmelden und diese auf Abruf ansehen.




Kommentare