

TL;DR: en este artículo, aprenderá a escalar proactivamente sus cargas de trabajo antes de un pico de tráfico utilizando KEDA y el escalador cron.
Al diseñar un clúster Kubernetes, es posible que deba responder a preguntas como las siguientes:
- ¿Cuánto tarda el clúster en escalar?
- ¿Cuánto tiempo tengo que esperar para que se cree un nuevo Pod?
Hay cuatro factores significativos que afectan al escalado:
- Tiempo de reacción del autoescalador horizontal Pod;
- Tiempo de reacción del Cluster Autoscaler;
- tiempo de aprovisionamiento del nodo; y
- hora de creación de la vaina.
Explorémoslos uno a uno.
Por defecto, el uso de la CPU de los pods es rastreado por kubelet cada 10 segundos, y obtenido de kubelet por el Servidor de Métricas cada 1 minuto.
El Autoscaler Horizontal Pod comprueba las métricas de CPU y memoria cada 30 segundos.
Si las métricas superan el umbral, el autoescalador aumentará el recuento de réplicas y retrocederá durante 3 minutos antes de tomar nuevas medidas. En el peor de los casos, pueden pasar hasta 3 minutos antes de que se añadan o eliminen los pods, pero de media, debería esperar 1 minuto para que el autoescalador horizontal de pods active el escalado.

El Cluster Autoscaler comprueba si hay pods pendientes y aumenta el tamaño del cluster. Detectar que el clúster necesita escalarse podría llevar:
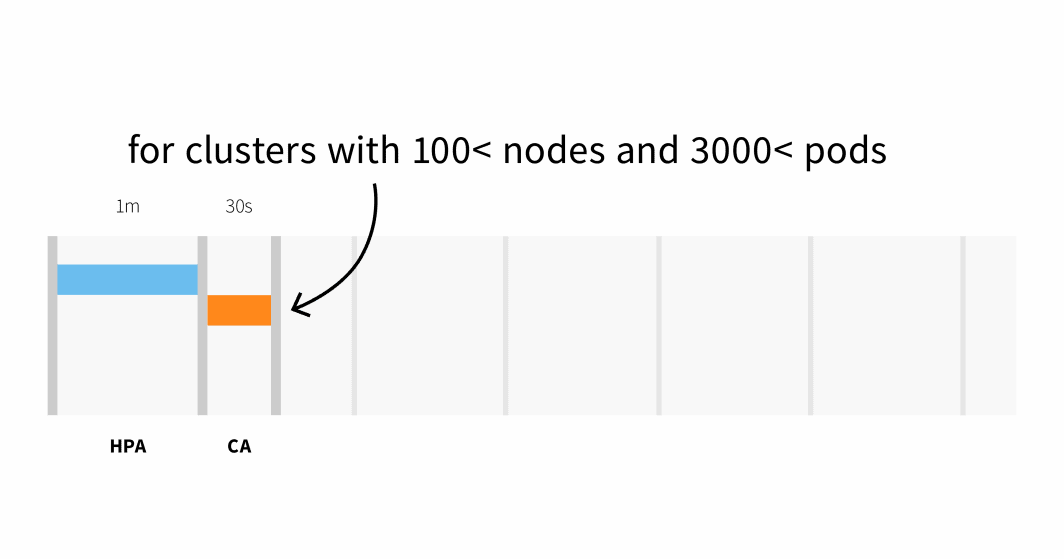
- Hasta 30 segundos en clústeres con menos de 100 nodos y 3000 pods, con una latencia media de unos cinco segundos; o bien
- Latencia de hasta 60 segundos en clústeres con más de 100 nodos, con una latencia media de unos 15 segundos.
El aprovisionamiento de nodos en Linode suele tardar de 3 a 4 minutos desde que el Cluster Autoscaler activa el API hasta que los pods pueden programarse en los nodos recién creados.
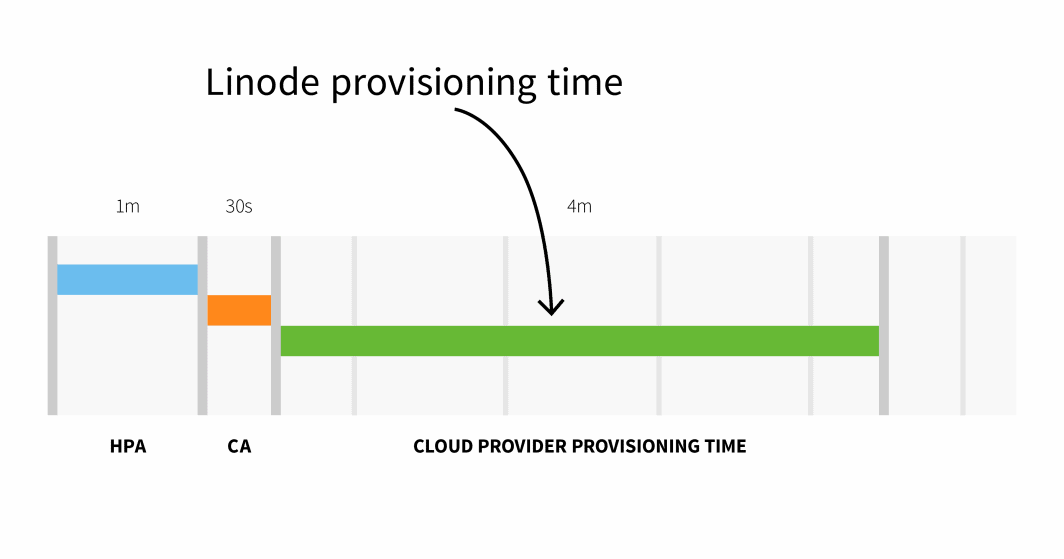
En resumen, con un clúster pequeño, tienes:
```
HPA delay: 1m +
CA delay: 0m30s +
Cloud provider: 4m +
Container runtime: 0m30s +
=========================
Total 6m
```
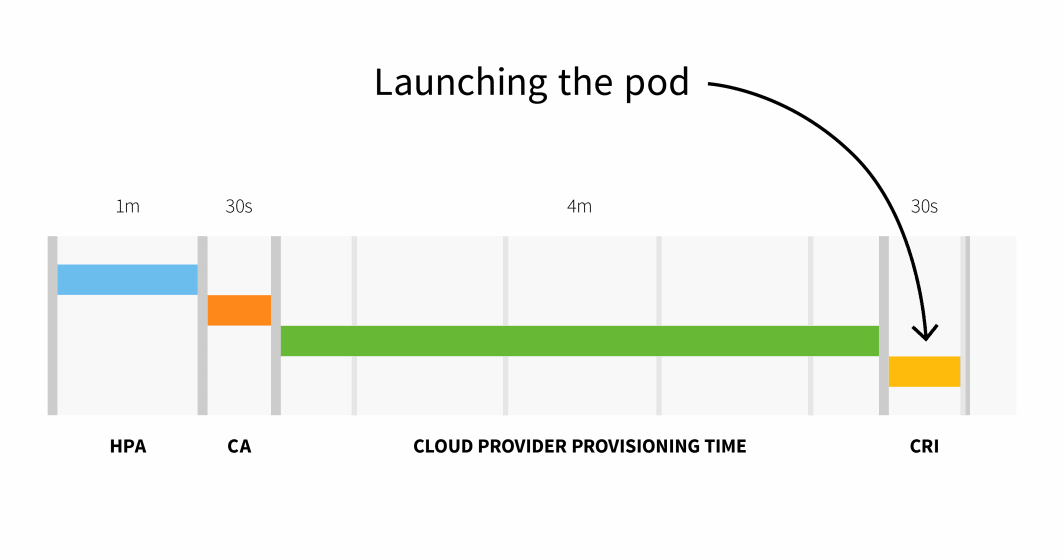
Con un clúster de más de 100 nodos, el retraso total podría ser de 6 minutos y 30 segundos... eso es mucho tiempo, así que ¿cómo solucionarlo?
Puede escalar proactivamente sus cargas de trabajo o, si conoce bien sus patrones de tráfico, puede escalar por adelantado.
Escalado preventivo con KEDA
Si sirve tráfico con patrones predecibles, tiene sentido escalar sus cargas de trabajo (y nodos) antes de cualquier pico y escalar hacia abajo una vez que el tráfico disminuye.
Kubernetes no proporciona ningún mecanismo para escalar las cargas de trabajo basado en fechas u horas, por lo que en esta parte, se utilizará KEDA-el Kubernetes Event Driven Autoscaler.
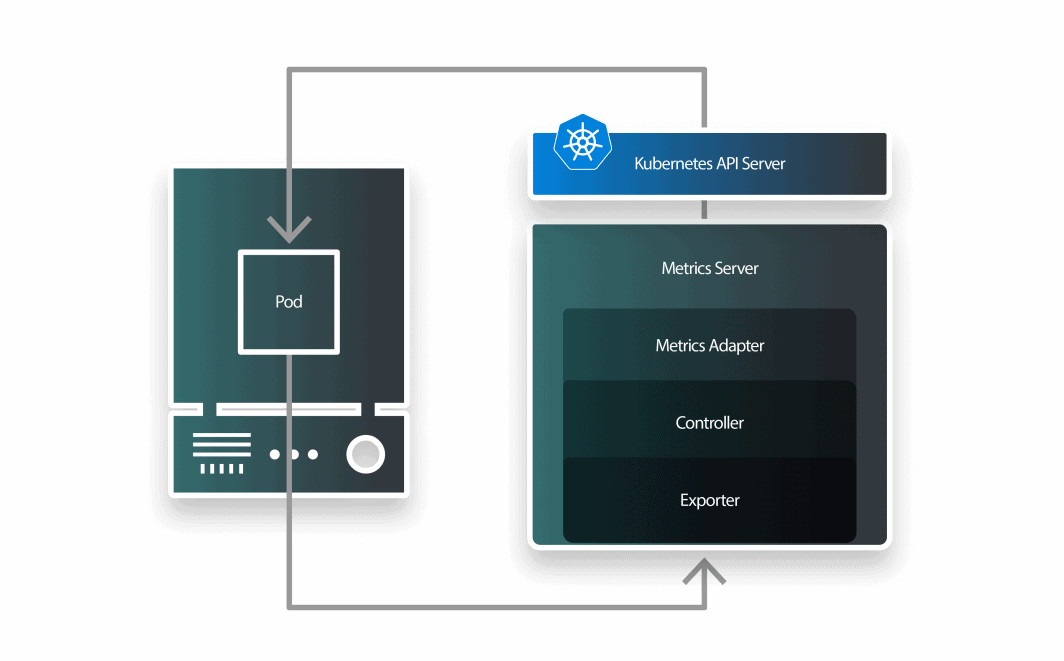
KEDA es un autoescalador formado por tres componentes:
- un escalador;
- un adaptador de métricas; y
- un controlador.
Puede instalar KEDA con Helm:
```bash
$ helm repo add kedacore https://kedacore.github.io/charts
$ helm install keda kedacore/keda
```Ahora que Prometheus y KEDA están instalados, vamos a crear un despliegue.
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
replicas: 1
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
spec:
containers:
- name: podinfo
image: stefanprodan/podinfoPuede enviar el recurso al clúster con:
```bash
$ kubectl apply -f deployment.yaml
```KEDA funciona sobre el Autoescalador Horizontal Pod existente y lo envuelve con una Definición de Recurso Personalizada llamada ScaleObject.
El siguiente ScaledObject utiliza el Cron Scaler para definir una ventana de tiempo en la que se debe cambiar el número de réplicas:
```yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 1
scaleTargetRef:
name: podinfo
triggers:
- type: cron
metadata:
timezone: Europe/London
start: 23 * * * *
end: 28 * * * *
desiredReplicas: "5"
```Puedes presentar el objeto con:
```bash
$ kubectl apply -f scaled-object.yaml
```¿Qué pasará después? Nada. La autoescala sólo se activará entre 23 * * * * y 28 * * * *. Con la ayuda de Gurú de Cronpuede traducir las dos expresiones cron a:
- Comience en el minuto 23 (por ejemplo, 2:23, 3:23, etc.).
- Deténgase en el minuto 28 (por ejemplo, 2:28, 3:28, etc.).
Si espera hasta la fecha de inicio, observará que el número de réplicas aumenta a 5.
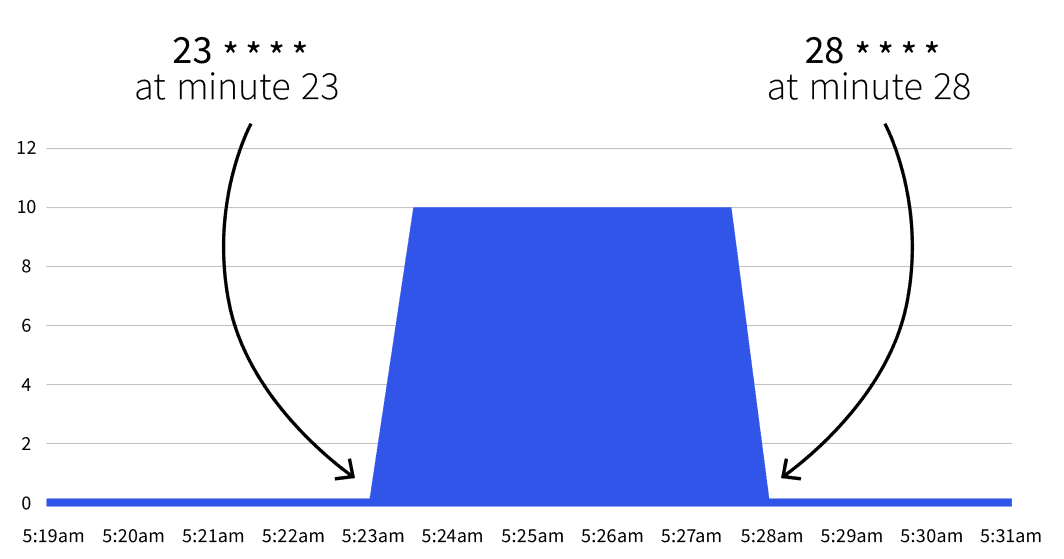
¿Vuelve el número a 1 después del minuto 28? Sí, el autoescalador vuelve al recuento de réplicas especificado en minReplicaCount.
¿Qué ocurre si se incrementa el número de réplicas entre uno de los intervalos? Si, entre los minutos 23 y 28, escalas tu despliegue a 10 réplicas, KEDA sobrescribirá tu cambio y establecerá el recuento. Si repites el mismo experimento después del minuto 28, el recuento de réplicas se fijará en 10. Ahora que ya conoces la teoría, veamos algunos casos de uso práctico.
Reducción de la jornada laboral
Usted tiene un despliegue en un entorno de desarrollo que debe estar activo durante las horas de trabajo y debe apagarse durante la noche.
Podrías utilizar el siguiente ScaledObject:
```yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 0
scaleTargetRef:
name: podinfo
triggers:
- type: cron
metadata:
timezone: Europe/London
start: 0 9 * * *
end: 0 17 * * *
desiredReplicas: "10"
```El recuento de réplicas por defecto es cero, pero durante el horario laboral (de 9 a 17 horas), las réplicas se escalan a 10.
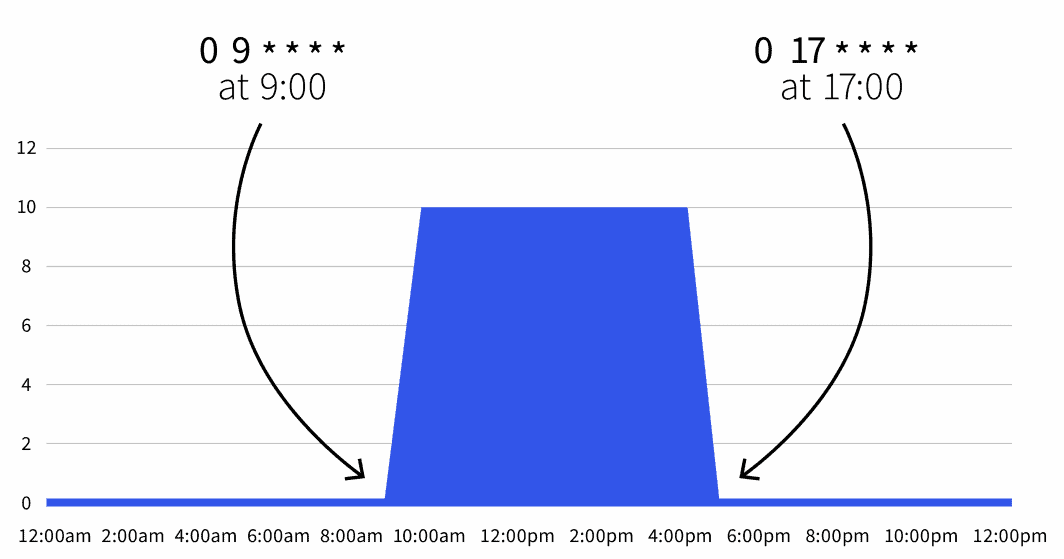
También puede ampliar el Objeto escalado para excluir el fin de semana:
```yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 0
scaleTargetRef:
name: podinfo
triggers:
- type: cron
metadata:
timezone: Europe/London
start: 0 9 * * 1-5
end: 0 17 * * 1-5
desiredReplicas: "10"
```Ahora su carga de trabajo sólo está activa de 9 a 5 de lunes a viernes. Como puede combinar varios desencadenantes, también podría incluir excepciones.
Reducción durante los fines de semana
Por ejemplo, si tiene previsto mantener activas las cargas de trabajo durante más tiempo el miércoles, podría utilizar la siguiente definición:
```yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 0
scaleTargetRef:
name: podinfo
triggers:
- type: cron
metadata:
timezone: Europe/London
start: 0 9 * * 1-5
end: 0 17 * * 1-5
desiredReplicas: "10"
- type: cron
metadata:
timezone: Europe/London
start: 0 17 * * 3
end: 0 21 * * 3
desiredReplicas: "10"
```En esta definición, la carga de trabajo está activa entre las 9.00 y las 17.00 horas de lunes a viernes, excepto el miércoles, que es de 9.00 a 21.00 horas.
Resumen
El autoescalador cron de KEDA le permite definir un intervalo de tiempo en el que desea escalar sus cargas de trabajo.
Esto le ayuda a escalar los pods antes de los picos de tráfico, lo que activará el Cluster Autoscaler con antelación.
En este artículo has aprendido:
- Cómo funciona el Cluster Autoscaler.
- Cuánto se tarda en escalar horizontalmente y añadir nodos a su clúster.
- Cómo escalar aplicaciones basadas en expresiones cron con KEDA.
¿Desea obtener más información? Regístrese para verlo en acción durante nuestro seminario web en colaboración con los servicios de computación en nube de Akamai.



Comentarios