

简要说明:在本文中,您将了解如何使用 KEDA 和 cron 扩展器在流量高峰到来之前主动扩展工作负载。
在设计Kubernetes集群时,您可能需要回答以下问题:
- 集群扩展需要多长时间?
- 在创建新舱位之前,我需要等待多长时间?
影响缩放的有四个重要因素:
- 水平 Pod Autoscaler 反应时间;
- 群集自动分压器反应时间;
- 节点配置时间;以及
- pod 创建时间。
让我们逐一探讨。
默认情况下,kubelet 每 10 秒采集一次 pod 的 CPU 使用情况,Metrics Server 每 1 分钟从kubelet 获取一次CPU 使用情况。
水平 Pod Autoscaler每 30 秒检查一次 CPU 和内存指标。
如果指标超过阈值,自动扩展器将增加副本数量,并在采取进一步行动前关闭 3 分钟。在最糟糕的情况下,添加或删除 pod 的时间可能长达 3 分钟,但平均而言,水平 Pod Autoscaler 触发扩展的时间应为 1 分钟。

群集自动分级器会检查是否有任何待处理的 pod,并增加群集的规模。检测群集是否需要扩大可能需要以下时间:
- 在拥有少于 100 个节点和 3000 个 pod 的集群上,延迟时间最长可达30 秒,平均延迟时间约为 5 秒;或
- 在超过 100 个节点的集群上,延迟时间最长可达 60 秒,平均延迟时间约为 15 秒。
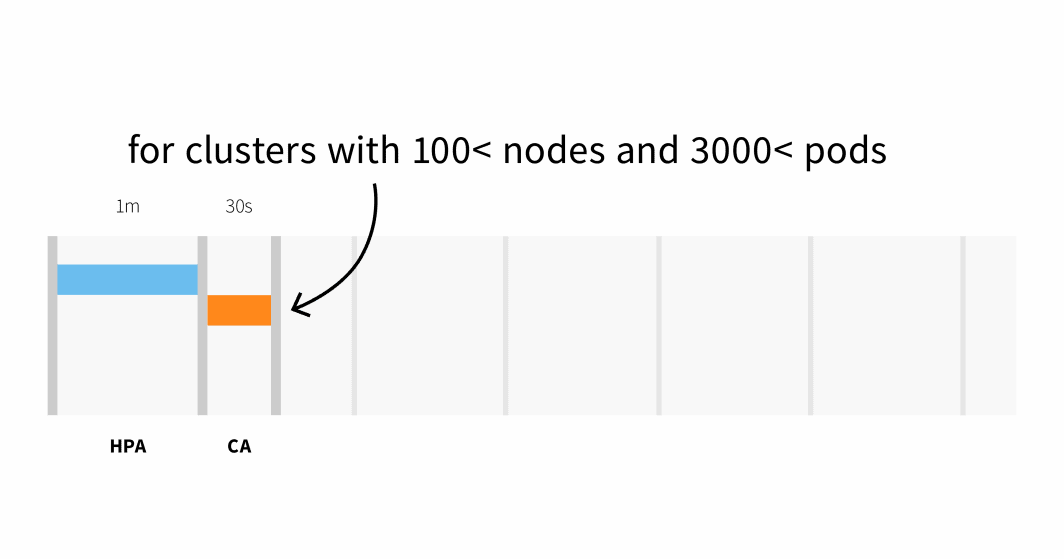
从集群自动分级器触发 API 到在新创建的节点上调度 pod,Linode 上的节点调配通常需要 3 到 4 分钟。
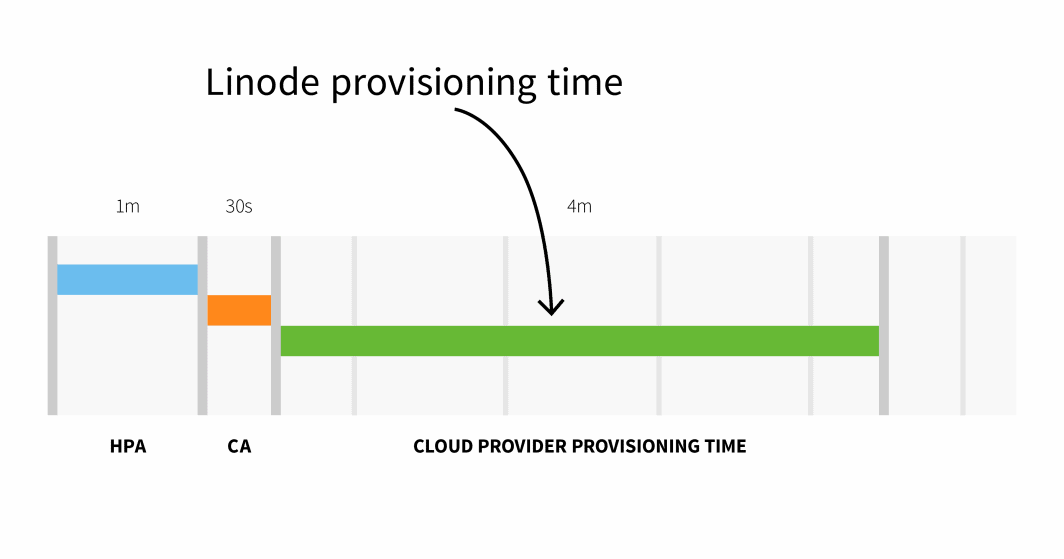
总之,通过一个小型群集,您可以
```
HPA delay: 1m +
CA delay: 0m30s +
Cloud provider: 4m +
Container runtime: 0m30s +
=========================
Total 6m
```
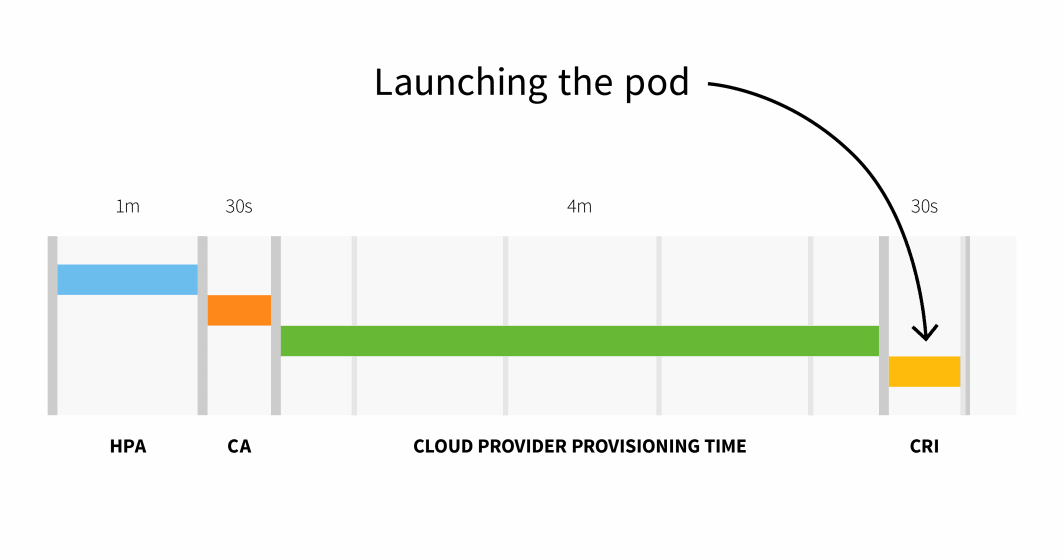
如果集群有 100 多个节点,总延迟时间可能会达到 6 分 30 秒......这是一段很长的时间,那么如何解决这个问题呢?
您可以主动扩展工作负载,或者,如果您对流量模式非常了解,也可以提前扩展。
利用 KEDA 进行抢先扩展
如果您提供的流量具有可预测的模式,那么在流量达到峰值之前扩大工作负载(和节点),并在流量减少时缩小工作负载(和节点)的规模是合理的。
Kubernetes 没有提供任何根据日期或时间扩展工作负载的机制,因此在这一部分,你将使用KEDA--Kubernetes 事件驱动自动分级器。
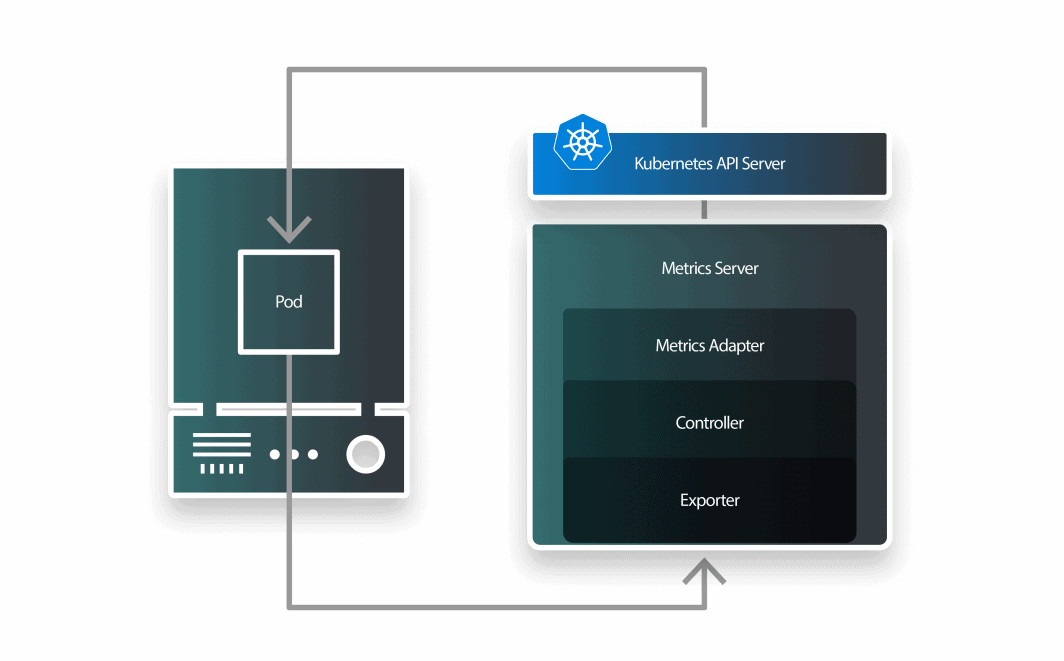
KEDA 是由三个部分组成的自动定标器:
- 缩放器;
- 度量适配器;以及
- a 控制器。
你可以用Helm安装KEDA。
```bash
$ helm repo add kedacore https://kedacore.github.io/charts
$ helm install keda kedacore/keda
```现在,Prometheus 和KEDA已经安装完毕,让我们来创建一个部署。
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
replicas: 1
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
spec:
containers:
- name: podinfo
image: stefanprodan/podinfo你可以通过以下方式将资源提交给集群。
```bash
$ kubectl apply -f deployment.yaml
```KEDA 可在现有水平 Pod Autoscaler 的基础上使用名为ScaleObject 的自定义资源定义。
下面的 ScaledObject 使用Cron Scaler来定义一个时间窗口,在该窗口中,副本的数量应该发生变化:
```yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 1
scaleTargetRef:
name: podinfo
triggers:
- type: cron
metadata:
timezone: Europe/London
start: 23 * * * *
end: 28 * * * *
desiredReplicas: "5"
```你可以用提交对象。
```bash
$ kubectl apply -f scaled-object.yaml
```接下来会发生什么?什么都不会发生。自动缩放只会在 23 * * * * 和 28 * * * *.借助 Cron Guru,可以将这两个 cron 表达式翻译为
- 从第 23 分钟开始(如 2:23、3:23 等)。
- 停在第 28 分钟处(如 2:28、3:28 等)。
如果等到开始日期,你会发现副本数量增加到 5 个。
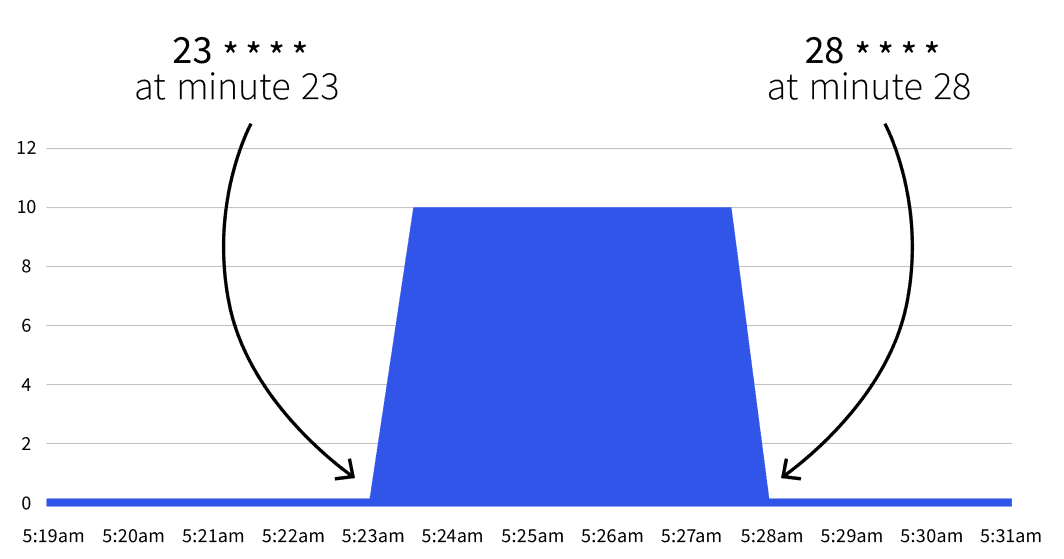
第 28 分钟后,数量会回到 1 吗?是的,自动平衡器会返回到在 minReplicaCount.
如果在其中一个时间间隔之间增加副本数量,会发生什么情况?如果在第 23 和 28 分钟之间,你将部署规模扩大到 10 个副本,KEDA 将覆盖你的更改并设置副本数。如果你在第 28 分钟后重复同样的实验,副本数量将被设置为 10。既然理论知识已经了解,我们就来看看一些实际用例。
工作时间缩减
您在开发环境中部署了一个系统,该系统应在工作时间处于活动状态,并在夜间关闭。
您可以使用下面的缩放对象:
```yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 0
scaleTargetRef:
name: podinfo
triggers:
- type: cron
metadata:
timezone: Europe/London
start: 0 9 * * *
end: 0 17 * * *
desiredReplicas: "10"
```默认副本数量为零,但在工作时间(上午 9 点至下午 5 点),副本数量会增加到 10 个。
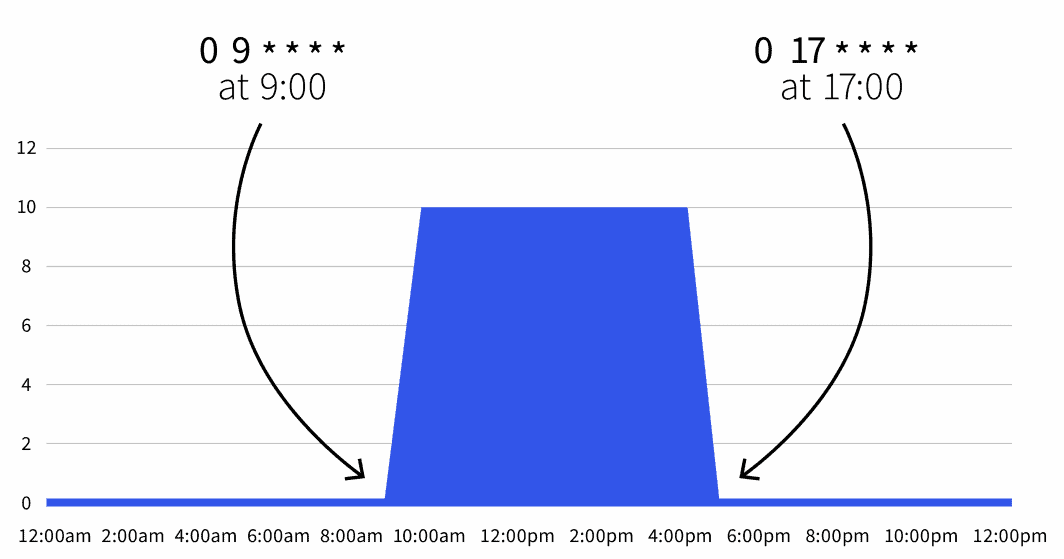
您也可以展开缩放对象,将周末排除在外:
```yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 0
scaleTargetRef:
name: podinfo
triggers:
- type: cron
metadata:
timezone: Europe/London
start: 0 9 * * 1-5
end: 0 17 * * 1-5
desiredReplicas: "10"
```现在,您的工作量只在周一至周五的 9 点到 5 点之间活动。由于您可以将多个触发器结合起来,因此也可以将例外情况包括在内。
周末缩减规模
例如,如果您计划在周三让工作负载保持更长时间的活动状态,您可以使用以下定义:
```yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 0
scaleTargetRef:
name: podinfo
triggers:
- type: cron
metadata:
timezone: Europe/London
start: 0 9 * * 1-5
end: 0 17 * * 1-5
desiredReplicas: "10"
- type: cron
metadata:
timezone: Europe/London
start: 0 17 * * 3
end: 0 21 * * 3
desiredReplicas: "10"
```根据这一定义,除周三从上午 9 点到晚上 9 点外,其余时间的工作时间为周一至周五的 9 点至 5 点。
摘要
KEDA cron 自动分级器可让你定义一个时间范围,在此范围内你想将工作负载分级为分出/分入。
这有助于您在流量高峰前扩展 pod,从而提前触发群集自动调节器。
在本文中,您将学到
- 群集自动分压器的工作原理
- 向集群横向扩展和添加节点需要多长时间。
- 如何使用 KEDA 根据 cron 表达式扩展应用程序。




注释