

TL;DR: この記事では、KEDAとcronスケーラーを使用して、トラフィックがピークに達する前にワークロードをプロアクティブにスケーリングする方法を学びます。
Kubernetesクラスタを設計する際、次のような質問に答える必要があるかもしれない:
- クラスタのスケールにはどのくらい時間がかかりますか?
- 新しいPodが作成されるまで、どのくらい待たなければなりませんか?
スケーリングに影響する重要な要素は4つある:
- 水平ポッド・オートスケーラーの反応時間;
- クラスタ・オートスケーラーの反応時間;
- ノードのプロビジョニング時間
- ポッド作成時間。
ひとつひとつ調べてみよう。
デフォルトでは、ポッドのCPU使用率は10秒ごとにkubeletによってスクレイピングされ、1分ごとにMetrics Serverによってkubeletから取得されます。
Horizontal Pod Autoscalerは、CPUとメモリのメトリクスを30秒ごとにチェックします。
メトリクスがしきい値を超えると、オートスケーラーはレプリカの数を増やし、それ以上のアクションを起こす前に3分間バックオフします。最悪の場合、ポッドが追加または削除されるまで最大3分かかることがありますが、平均すると、Horizontal Pod Autoscalerがスケーリングをトリガするまで1分待つとお考えください。

Cluster Autoscalerは、保留中のポッドがあるかどうかをチェックし、クラスタのサイズを増やします。クラスタがスケールアップする必要があることを検出するには、次の時間がかかります:
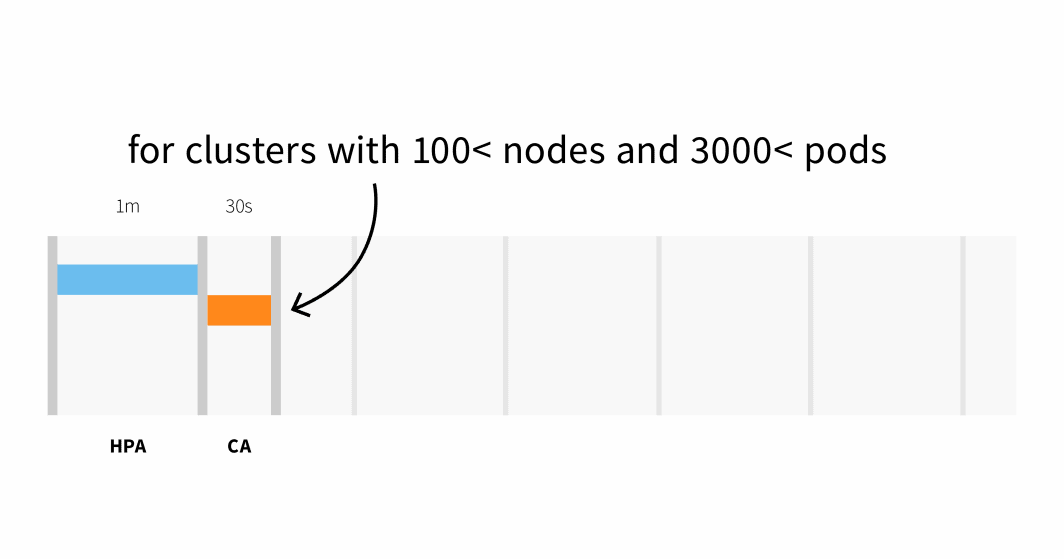
- 100ノード、3000ポッド未満のクラスタでは最大30秒、平均待ち時間は約5秒。
- 100ノード以上のクラスタでは最大60秒のレイテンシで、平均レイテンシは約15秒。
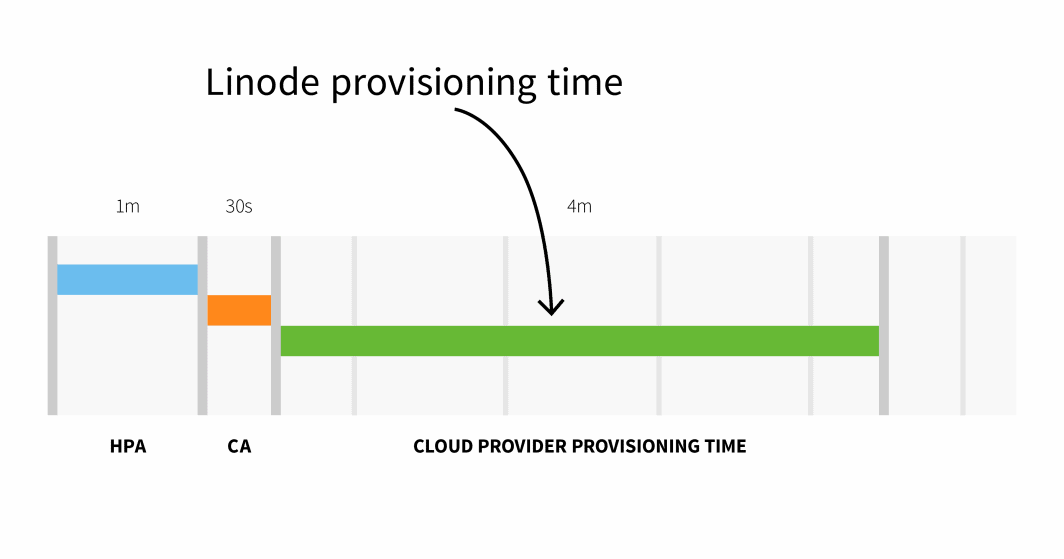
Linodeでのノードのプロビジョニングは、Cluster Autoscalerがノードのプロビジョニングをトリガーしてから、新しく作成されたノードにポッドをスケジュールできるようになるまで、通常3~4分かかります。 API をトリガーしてから、新しく作成されたノードにポッドをスケジューリングできるようになるまで、通常3~4分かかります。
まとめると、小さなクラスターでは、次のようなことができる:
```
HPA delay: 1m +
CA delay: 0m30s +
Cloud provider: 4m +
Container runtime: 0m30s +
=========================
Total 6m
```
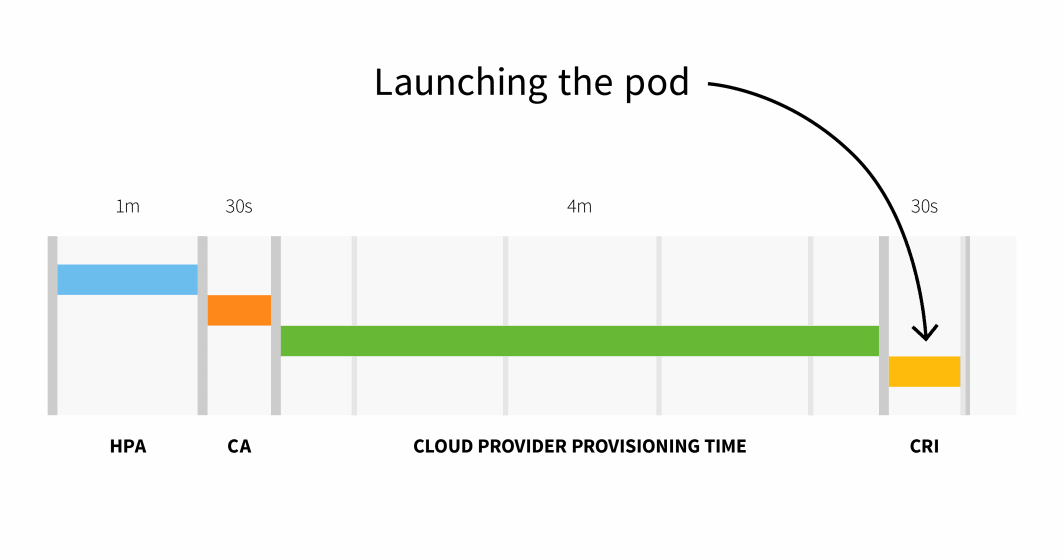
100ノード以上のクラスタでは、合計遅延は6分30秒にもなる。
ワークロードをプロアクティブにスケーリングすることもできるし、トラフィックパターンを熟知していれば、事前にスケーリングすることもできる。
KEDAによるプリエンプティブ・スケーリング
予測可能なパターンのトラフィックを提供する場合、ピーク前にワークロード(およびノード)をスケールアップし、トラフィックが減少したらスケールダウンすることは理にかなっています。
Kubernetesは日付や時間に基づいてワークロードをスケールするメカニズムを提供していないので、このパートではKEDA(Kubernetes Event Driven Autoscaler)を使用する。
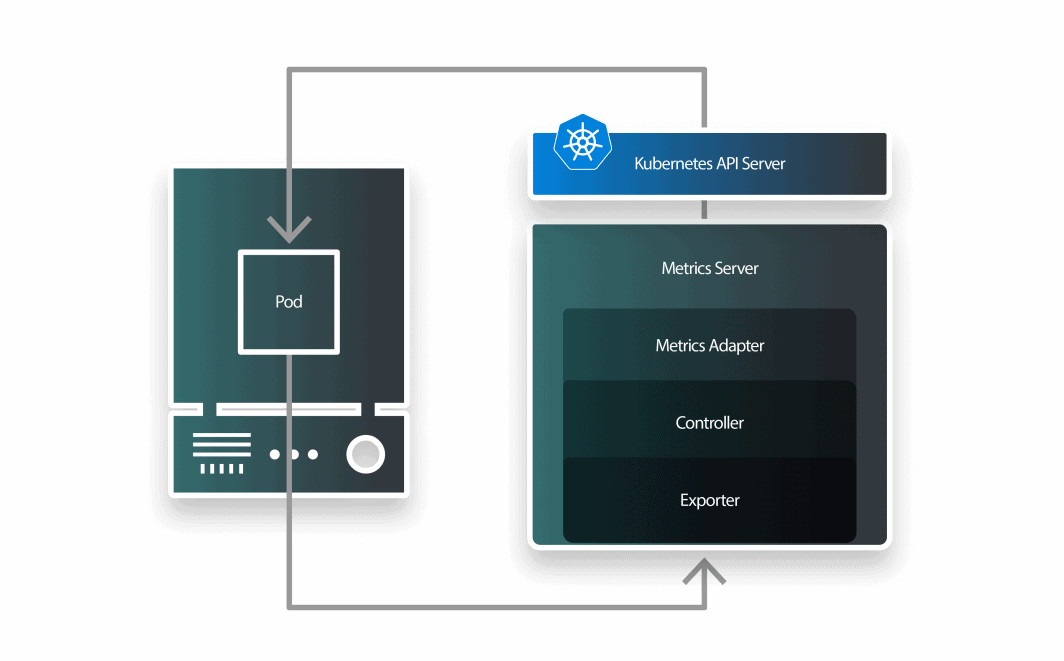
KEDAは3つのコンポーネントからなるオートスケーラーである:
- スケーラー;
- メトリクス・アダプタ
- コントローラー。
HelmでKEDAをインストールすることができます。
```bash
$ helm repo add kedacore https://kedacore.github.io/charts
$ helm install keda kedacore/keda
```Prometheus と KEDA がインストールされたので、デプロイメントを作成しましょう。
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
replicas: 1
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
spec:
containers:
- name: podinfo
image: stefanprodan/podinfoでリソースをクラスタに投入することができます。
```bash
$ kubectl apply -f deployment.yaml
```KEDAは既存のHorizontal Pod Autoscalerの上で動作し、ScaleObjectというカスタムリソース定義でラップします。
以下のScaledObjectは、Cron Scalerを使用して、レプリカの数を変更する時間ウィンドウを定義します:
```yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 1
scaleTargetRef:
name: podinfo
triggers:
- type: cron
metadata:
timezone: Europe/London
start: 23 * * * *
end: 28 * * * *
desiredReplicas: "5"
```でオブジェクトを提出することができます。
```bash
$ kubectl apply -f scaled-object.yaml
```次に何が起こるのか?何も起こりません。オートスケールは 23 * * * * と 28 * * * *.の助けを借りて クロン グルこの2つのクーロン式を訳すとこうなる:
- 分23秒からスタート(例:2分23秒、3分23秒など)。
- 分28秒で止める(例:2分28秒、3分28秒など)。
開始日まで待つと、レプリカの数が5に増えていることに気づくだろう。
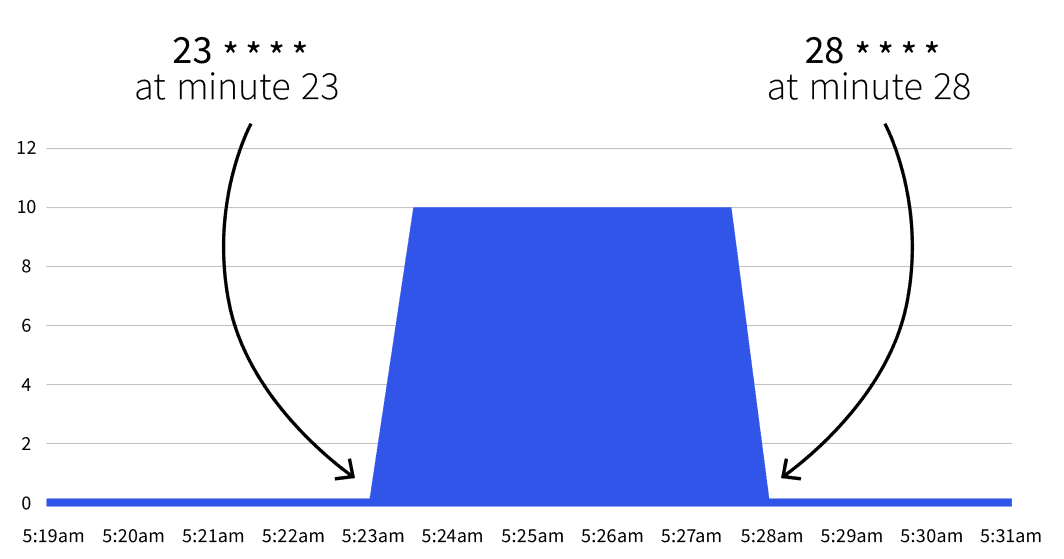
28分後に数は1に戻りますか?はい。 minReplicaCount.
ある間隔の間にレプリカの数を増やすとどうなりますか?23分から28分の間に、デプロイメントを10レプリカにスケールした場合、KEDAは変更を上書きし、カウントを設定します。28分後に同じ実験を繰り返すと、レプリカ数は10に設定されます。理論がわかったところで、実際の使用例を見てみましょう。
勤務時間中の規模縮小
開発環境にデプロイがあり、勤務時間中はアクティブにし、夜間はオフにする必要があります。
次のようなScaledObjectが使える:
```yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 0
scaleTargetRef:
name: podinfo
triggers:
- type: cron
metadata:
timezone: Europe/London
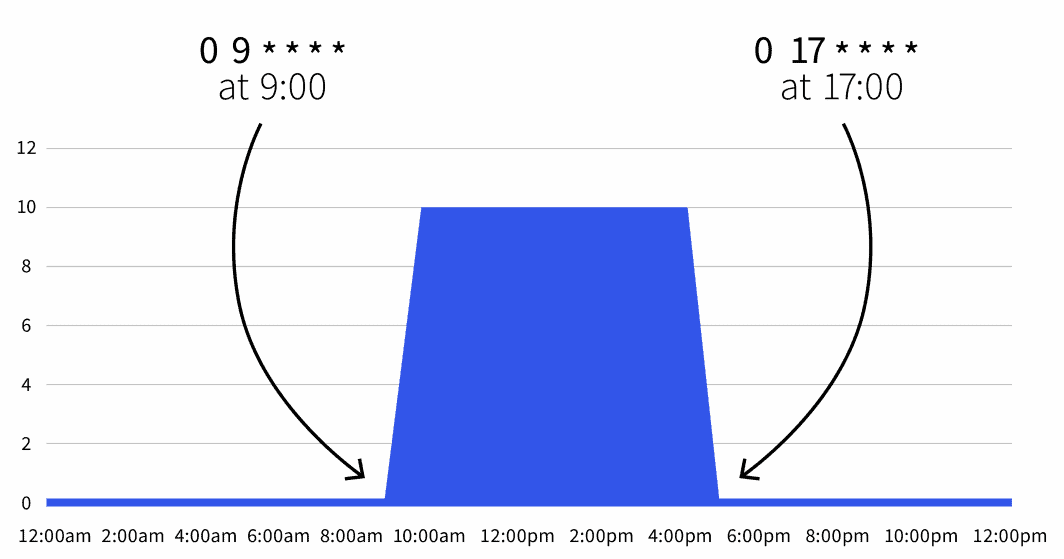
start: 0 9 * * *
end: 0 17 * * *
desiredReplicas: "10"
```デフォルトのレプリカ数はゼロだが、就業時間中(午前9時から午後5時まで)はレプリカ数が10にスケールされる。
また、Scaled Objectを展開して週末を除外することもできます:
```yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 0
scaleTargetRef:
name: podinfo
triggers:
- type: cron
metadata:
timezone: Europe/London
start: 0 9 * * 1-5
end: 0 17 * * 1-5
desiredReplicas: "10"
```今、あなたの仕事量は月曜から金曜の9時から5時までしかない。いくつかのトリガーを組み合わせることができるので、例外を含めることもできます。
週末の規模縮小
例えば、水曜日にワークロードを長くアクティブにしておくつもりなら、次のような定義が使える:
```yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 0
scaleTargetRef:
name: podinfo
triggers:
- type: cron
metadata:
timezone: Europe/London
start: 0 9 * * 1-5
end: 0 17 * * 1-5
desiredReplicas: "10"
- type: cron
metadata:
timezone: Europe/London
start: 0 17 * * 3
end: 0 21 * * 3
desiredReplicas: "10"
```この定義では、水曜日の午前9時から午後9時を除き、月曜日から金曜日の9時から5時までが仕事時間となる。
まとめ
KEDA cron autoscalerでは、ワークロードをスケールアウト/スケールインする時間範囲を定義できます。
これにより、トラフィックがピークに達する前にPodをスケールすることができ、事前にCluster Autoscalerをトリガーすることができます。
この記事であなたは学んだ:
- クラスタ・オートスケーラの仕組み。
- 水平スケールとクラスタへのノード追加にかかる時間。
- KEDAでcron式に基づいてアプリを拡張する方法。
もっと詳しく知りたいですか?アカマイのクラウド・コンピューティング・サービスとの提携によるウェビナーで、このソリューションの実例をご覧ください。




コメント