

TL;DR: neste artigo, aprenderá a escalar proactivamente as suas cargas de trabalho antes de um pico de tráfego utilizando o KEDA e o escalonador cron.
Ao conceber um cluster Kubernetes, poderá ter de responder a perguntas como:
- Quanto tempo é necessário para que o cluster seja dimensionado?
- Quanto tempo tenho de esperar até que seja criado um novo POD?
Há quatro factores significativos que afectam o escalonamento:
- Tempo de reação do Autoscaler de cápsula horizontal;
- Tempo de reação do Cluster Autoscaler;
- tempo de aprovisionamento do nó; e
- tempo de criação do pod.
Vamos explorá-las uma a uma.
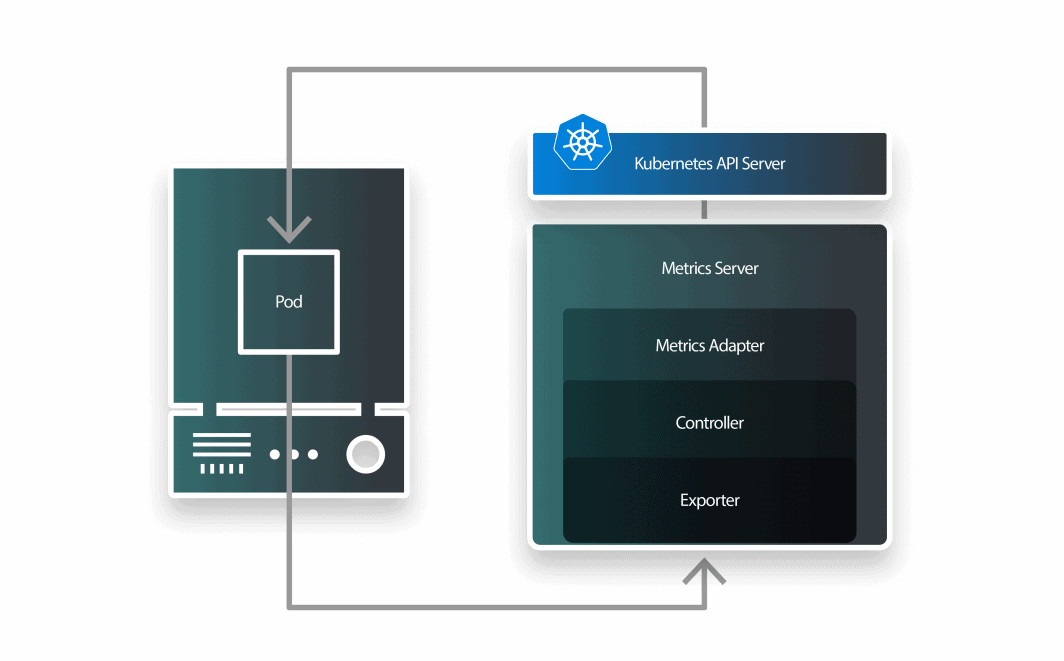
Por predefinição, a utilização da CPU dos pods é recolhida pelo kubelet a cada 10 segundos e obtida do kubelet pelo Metrics Server a cada 1 minuto.
O Horizontal Pod Autoscaler verifica as métricas de CPU e memória a cada 30 segundos.
Se as métricas excederem o limite, o autoescalonador aumentará a contagem de réplicas e recuará por 3 minutos antes de tomar outras medidas. Na pior das hipóteses, pode levar até 3 minutos para que os pods sejam adicionados ou excluídos, mas, em média, você deve esperar 1 minuto para que o Horizontal Pod Autoscaler acione o dimensionamento.

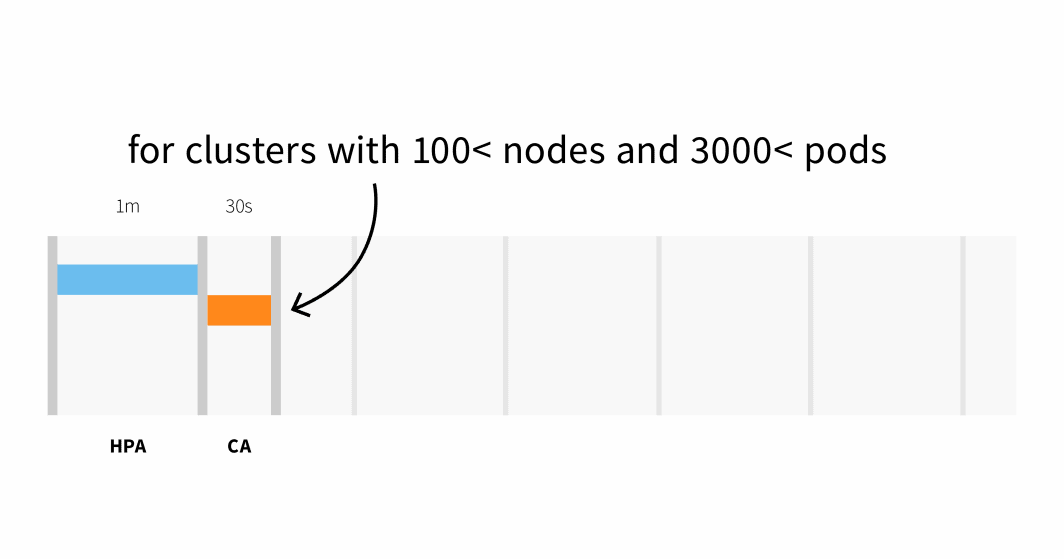
O Cluster Autoscaler verifica se existem pods pendentes e aumenta o tamanho do cluster. Detetar que o cluster precisa de ser aumentado pode demorar:
- Até 30 segundos em clusters com menos de 100 nós e 3000 pods, com uma latência média de cerca de cinco segundos; ou
- Latência de até 60 segundos em clusters com mais de 100 nós, com uma latência média de cerca de 15 segundos.
O provisionamento de nós na Linode geralmente leva de 3 a 4 minutos, desde o momento em que o Cluster Autoscaler aciona o API para quando os pods podem ser agendados em nós recém-criados.
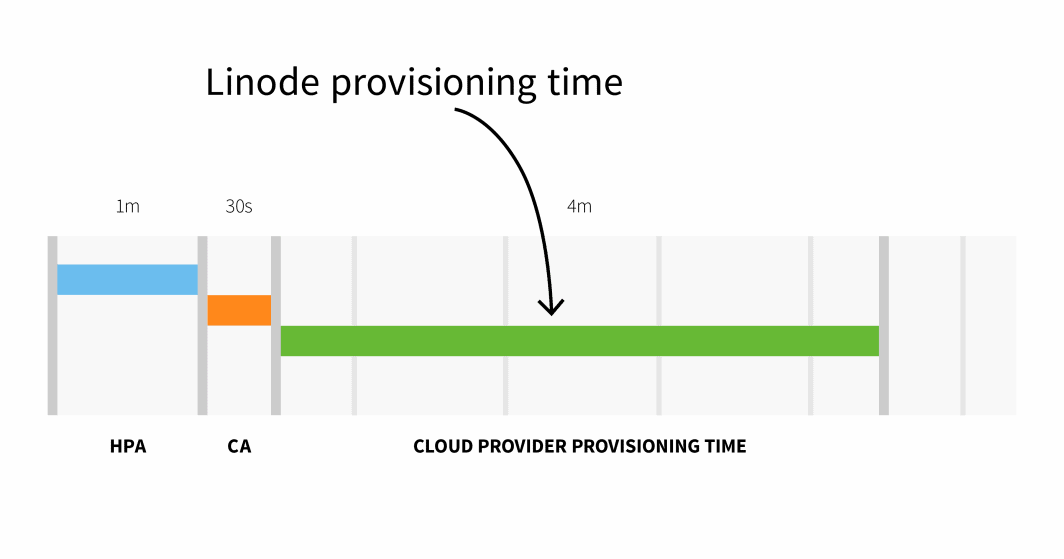
Em resumo, com um pequeno cluster, tem-se:
```
HPA delay: 1m +
CA delay: 0m30s +
Cloud provider: 4m +
Container runtime: 0m30s +
=========================
Total 6m
```
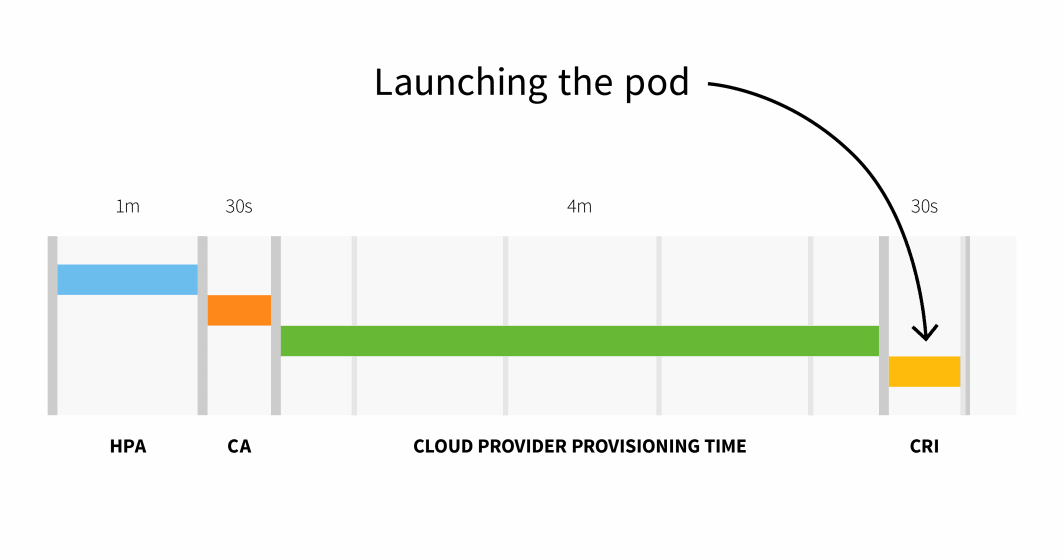
Com um cluster com mais de 100 nós, o atraso total pode ser de 6 minutos e 30 segundos... é muito tempo, por isso, como é que se pode resolver isto?
Pode escalar proactivamente os seus volumes de trabalho ou, se conhecer bem os seus padrões de tráfego, pode escalar antecipadamente.
Escalonamento preventivo com KEDA
Se servir tráfego com padrões previsíveis, faz sentido aumentar as suas cargas de trabalho (e nós) antes de qualquer pico e diminuir quando o tráfego diminuir.
O Kubernetes não fornece nenhum mecanismo para escalar cargas de trabalho com base em datas ou horários, portanto, nesta parte, você usará o KEDA -o Kubernetes Event Driven Autoscaler.
O KEDA é um autoscaler composto por três componentes:
- um escalpador;
- um adaptador de métricas; e
- um controlador.
Pode instalar a KEDA com Helm:
```bash
$ helm repo add kedacore https://kedacore.github.io/charts
$ helm install keda kedacore/keda
```Agora que Prometheus e KEDA estão instalados, vamos criar uma implantação.
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
replicas: 1
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
spec:
containers:
- name: podinfo
image: stefanprodan/podinfoPode submeter o recurso ao agrupamento com:
```bash
$ kubectl apply -f deployment.yaml
```O KEDA trabalha em cima do Horizontal Pod Autoscaler existente e envolve-o com uma Definição de Recurso Personalizada chamada ScaleObject.
O seguinte ScaledObject utiliza o Cron Scaler para definir uma janela de tempo em que o número de réplicas deve ser alterado:
```yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 1
scaleTargetRef:
name: podinfo
triggers:
- type: cron
metadata:
timezone: Europe/London
start: 23 * * * *
end: 28 * * * *
desiredReplicas: "5"
```Pode submeter o objecto com:
```bash
$ kubectl apply -f scaled-object.yaml
```O que é que vai acontecer a seguir? Nada. A escala automática só será activada entre 23 * * * * e 28 * * * *. Com a ajuda de Cron Guru, pode traduzir as duas expressões cron para:
- Comece no minuto 23 (por exemplo, 2:23, 3:23, etc.).
- Parar no minuto 28 (por exemplo, 2:28, 3:28, etc.).
Se esperar até à data de início, verificará que o número de réplicas aumenta para 5.
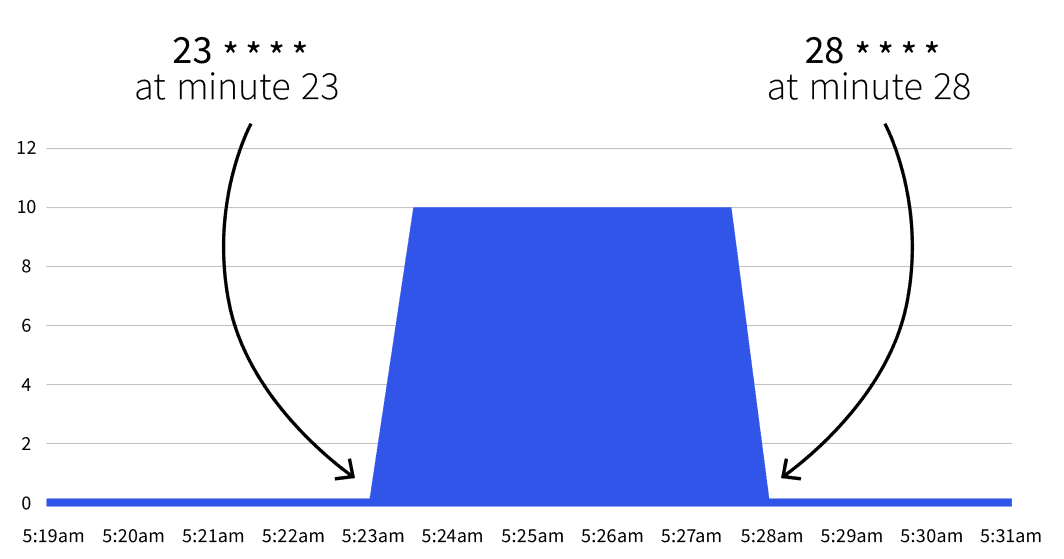
O número volta a ser 1 após o 28º minuto? Sim, o autoscaler retorna à contagem de réplicas especificada em minReplicaCount.
O que acontece se você incrementar o número de réplicas entre um dos intervalos? Se, entre os minutos 23 e 28, você escalar sua implantação para 10 réplicas, o KEDA sobrescreverá sua alteração e definirá a contagem. Se você repetir a mesma experiência após o 28º minuto, a contagem de réplicas será definida como 10. Agora que você conhece a teoria, vamos ver alguns casos de uso práticos.
Reduzir o horário de trabalho
Tem uma implementação num ambiente de desenvolvimento que deve estar ativa durante o horário de trabalho e deve ser desligada durante a noite.
Pode utilizar o seguinte ScaledObject:
```yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 0
scaleTargetRef:
name: podinfo
triggers:
- type: cron
metadata:
timezone: Europe/London
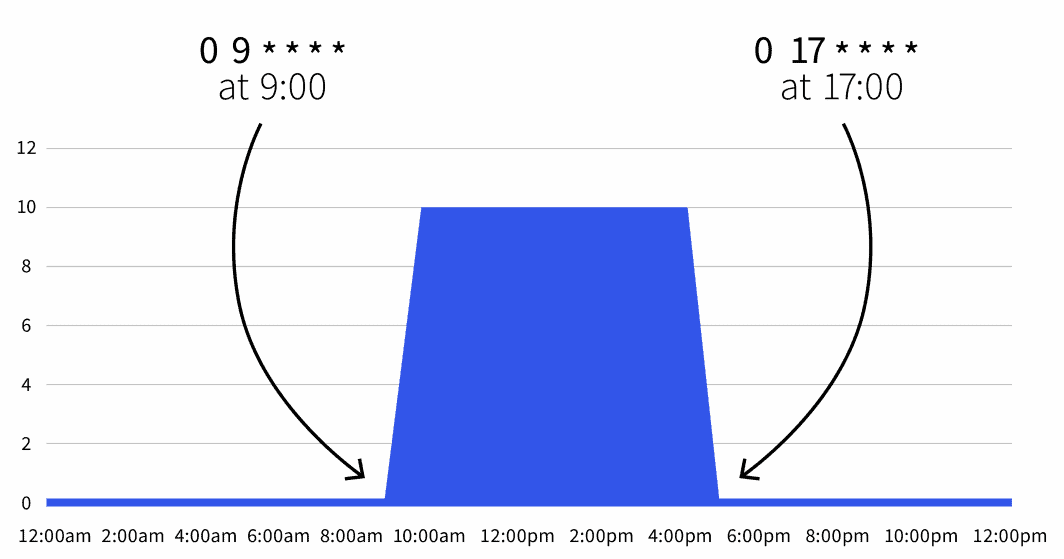
start: 0 9 * * *
end: 0 17 * * *
desiredReplicas: "10"
```A contagem de réplicas predefinida é zero, mas durante o horário de trabalho (das 9h00 às 17h00), as réplicas são escaladas para 10.
Também é possível expandir o Objeto escalado para excluir o fim de semana:
```yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 0
scaleTargetRef:
name: podinfo
triggers:
- type: cron
metadata:
timezone: Europe/London
start: 0 9 * * 1-5
end: 0 17 * * 1-5
desiredReplicas: "10"
```Agora, o seu volume de trabalho só está ativo das 9 às 17 horas, de segunda a sexta-feira. Uma vez que é possível combinar vários accionadores, também é possível incluir excepções.
Reduzir a escala durante os fins-de-semana
Por exemplo, se planear manter as cargas de trabalho activas durante mais tempo na quarta-feira, pode utilizar a seguinte definição:
```yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 0
scaleTargetRef:
name: podinfo
triggers:
- type: cron
metadata:
timezone: Europe/London
start: 0 9 * * 1-5
end: 0 17 * * 1-5
desiredReplicas: "10"
- type: cron
metadata:
timezone: Europe/London
start: 0 17 * * 3
end: 0 21 * * 3
desiredReplicas: "10"
```Nesta definição, o volume de trabalho está ativo entre as 9 e as 17 horas, de segunda a sexta-feira, exceto à quarta-feira, que funciona das 9 às 21 horas.
Resumo
O escalonador automático KEDA cron permite-lhe definir um intervalo de tempo no qual pretende escalonar as suas cargas de trabalho.
Isso ajuda a dimensionar pods antes do pico de tráfego, o que acionará o Cluster Autoscaler com antecedência.
Neste artigo, aprendeu:
- Como funciona o Cluster Autoscaler.
- Quanto tempo demora a escalar horizontalmente e a adicionar nós ao seu cluster.
- Como escalar aplicações com base em expressões cron com o KEDA.
Quer saber mais? Registe-se para ver isto em ação durante o nosso webinar em parceria com os serviços de computação em nuvem da Akamai.



Comentários