

Bonjour, je suis Mike, ingénieur en solutions chez Linode. Si vous êtes curieux de savoir ce qu'est la haute disponibilité, cet article devrait vous aider à y voir plus clair. Bonne lecture !
Dans le monde hyperconnecté d'aujourd'hui, les consommateurs s'attendent à avoir accès à des services instantanément, à tout moment et de n'importe où. En outre, vous devez tenir compte de la durée d'attention - saviez-vous que vous avez environ 30 secondes pour capter l'attention d'un consommateur avant qu'il ne passe à autre chose ? C'est pourquoi il est essentiel de mettre en œuvre la haute disponibilité (HA) sur vos applications. Dans cet article de blog, je définirai la haute disponibilité, j'expliquerai les différents composants d'une architecture de haute disponibilité de base et j'examinerai comment construire une infrastructure de haute disponibilité simple pour une application web.
Qu'est-ce que la haute disponibilité ?
Tout d'abord, définissons la disponibilité : le pourcentage du temps total pendant lequel un système informatique est accessible pour une utilisation normale. En d'autres termes, la disponibilité décrit dans quelle mesure un système est en ligne et accessible. On pourrait penser que la disponibilité optimale est de 100 %, mais c'est impossible.
C'est là qu'intervient la haute disponibilité. Les systèmes à haute disponibilité sont ceux dont la disponibilité en ligne est comprise entre 99,9 et 99,999 % du temps (voir tableau 1). La disponibilité idéale est de 99,999 % (cinq neuf), ce qui correspond à environ cinq minutes de temps d'arrêt par an.
La haute disponibilité en chiffres
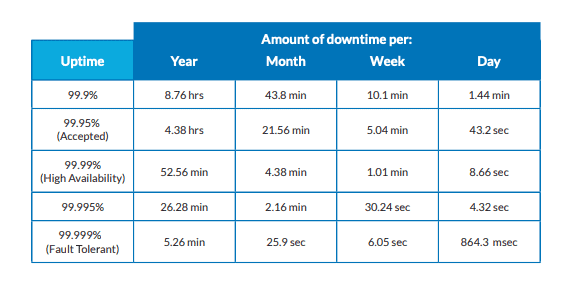
Les concepteurs de systèmes essaient d'obtenir l'HA la plus élevée possible. La tolérance aux pannes permet d'améliorer l'intégrité du système. Il s'agit de mettre en place différentes fonctionnalités du système qui permettent un fonctionnement continu en cas de défaillance du système. La redondance et la réplication sont des exemples de fonctions de tolérance aux pannes - nous y reviendrons.
Comment fonctionne la haute disponibilité ?
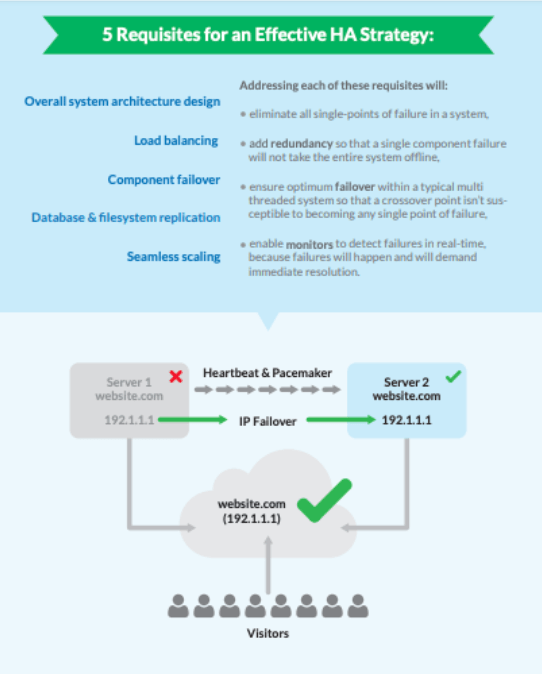
De nombreux éléments peuvent entrer dans la construction d'un système de haute disponibilité idéal. Ces composants doivent être intégrés les uns aux autres, surveillés en permanence et capables d'une récupération rapide. Il s'agit notamment des éléments suivants
- la redondance des instances,
- l'équilibrage de la charge,
- le basculement du matériel et du logiciel entre des composants disparates,
- la réplication des données, et
- la mise à l'échelle automatisée.
Ces caractéristiques sont expliquées plus en détail dans le diagramme ci-dessous :
Comment évaluer la disponibilité de votre système
Vous souhaitez déterminer la disponibilité de l'infrastructure de votre nuage ? Elle repose sur trois critères :
- sa taille et son champ d'application
- l'inclusion de composants matériels
- la mise à l'échelle prévue pour répondre à la demande future
Après l'évaluation, vous pouvez décider de réviser votre infrastructure. Je vous conseille de revoir d'abord chaque critère séparément, puis collectivement. La révision de votre architecture peut inclure des outils virtuels, tels que :
- nouveaux serveurs secondaires et modules complémentaires
- Utilitaires logiciels permettant la mise en œuvre de l'AH
- matériel supplémentaire
Comment l'équilibrage de la charge affecte-t-il l'AH ?
L'équilibrage de charge distribue intelligemment le trafic entrant sur un ou plusieurs serveurs. Ces outils, tels que Linode 's NodeBalancers, sont conçus pour être "configurés et oubliés". Ils permettent d'ajouter ou de supprimer des serveurs dorsaux de manière transparente, sans que les utilisateurs finaux ne subissent de temps d'arrêt.
Un équilibreur de charge typique surveille une adresse IP pour les demandes entrantes et l'analyse pour détecter une surcharge ou une défaillance. En cas de détection, il suit les règles configurées (y compris le basculement d'IP assigné) pour envoyer le trafic vers un nœud plus facilement disponible. De cette manière, le trafic est réparti uniformément et les utilisateurs finaux ne subissent pas d'interruption de service.
Presque toutes les applications peuvent bénéficier de l'équilibrage de charge. Il s'agit d'un élément clé pour augmenter le nombre d'utilisateurs tout en assurant la redondance.

Qu'est-ce que le basculement ?
Le basculement est la pierre angulaire des systèmes de haute disponibilité. Avec le basculement, les tâches sont automatiquement réacheminées vers un serveur secondaire ou tertiaire en cas de panne planifiée ou accidentelle.
Le basculement comprend à la fois des solutions matérielles et logicielles, telles que l'ajout de serveurs de base de données en miroir à une grappe ou la configuration d'une adresse IP de manière à acheminer le trafic vers le serveur le plus disponible.
Comment fonctionne la réplication des systèmes de fichiers ?
Dans un cluster HA, chaque serveur (par exemple, application, base de données, système de fichiers) est configuré pour refléter les autres serveurs, les données stockées étant répliquées automatiquement entre tous les autres serveurs de l'architecture. Les requêtes entrantes pourront accéder aux données, quel que soit le serveur sur lequel elles résident. L'utilisateur final bénéficie ainsi d'une expérience transparente.
Les logiciels de système de fichiers en réseau (NFS) tels que GlusterFS, LizardFS et HDFS peuvent regrouper différents types de serveurs en un système de fichiers en réseau parallèle. En cas de défaillance d'un serveur, le logiciel NFS réachemine automatiquement les demandes qui lui sont adressées vers un serveur en ligne, dont les fichiers et les données ont été mis en miroir et synchronisés.

Qu'en est-il de la base de données ?
L'objectif est de réaliser une réplication synchrone, c'est-à-dire que les données sont copiées en continu d'un serveur de base de données à l'autre. Il en résulte une distribution uniforme des données aux utilisateurs finaux, sans interruption. Les plates-formes logicielles suivantes permettent d'atteindre cet objectif, dans n'importe quelle combinaison :
Quelle est la place de la mise à l'échelle sans rupture ?
Votre système doit pouvoir évoluer et répondre aux besoins des utilisateurs finaux. Chaque système étant différent, il n'existe pas de plateforme unique pour faire évoluer un système tout en maintenant une haute disponibilité. Vous devez choisir la plateforme de déploiement distribué qui vous convient. Voici quelques exemples :
- SaltStack: une plateforme de gestion de configuration évolutive et flexible pour l'automatisation de l'informatique en nuage pilotée par les événements
- Chef: logiciel permettant d'écrire des recettes de configuration du système en Erlang ou Ruby
- Puppetlogiciel qui gère la configuration des systèmes de type Unix et Microsoft Windows
Prenons un exemple
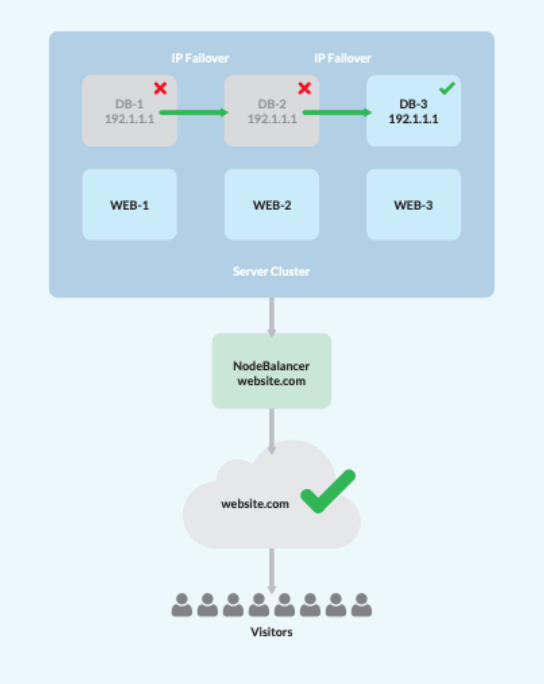
Pour mettre les choses en perspective, nous avons dressé une liste des étapes à suivre pour parvenir à l'AH. Il s'agit de concevoir un système avec un seul équilibreur de charge, trois serveurs web/application et trois serveurs de base de données. Remarque : au moins trois serveurs de base de données sont nécessaires pour établir le quorum des données dans les architectures HA.
- Une fois le cluster assemblé, configurez les serveurs web/app pour répliquer les données du site à l'aide du NFS de votre choix.
- Cela activera l'équilibreur de charge et répartira le trafic entre les trois nœuds web/app, en supprimant automatiquement les nœuds qui ont échoué.
- Créer une configuration MySQL Maître-Maître en utilisant Percona XtraDB.
- Désigner une IP privée flottante, gérée par Keepalived, pour servir de basculement.
- Pointer tous les serveurs web/applications vers l'IP privée flottante, afin qu'ils se déplacent automatiquement vers un nœud de base de données en ligne au cas où un serveur de base de données tomberait en panne.
Et voilà ! Les utilisateurs finaux ne subiront qu'une perturbation minimale, car l'accès au serveur reste disponible, malgré tout point de défaillance.
Conclusion
Vous souhaitez donc mettre en place un système d'AP ?
Il est important de savoir que cela nécessite une planification minutieuse. Tout d'abord, vous devrez calculer le coût réel des temps d'arrêt. Ce coût varie d'une organisation à l'autre et jouera un rôle clé dans la détermination de la durée d'indisponibilité acceptable pour une année donnée. Cette information est essentielle pour déterminer la bonne combinaison de configuration matérielle, d'outils logiciels et de maintenance du système.
L'ajout de composants matériels à un système peut entraver l'AH. L'ajout d'un serveur à votre cluster augmente le risque de défaillance, c'est pourquoi il faut le faire correctement.
Il est vrai qu'une architecture de système simplifiée est, en fait, plus simple. Mais cela ne va pas sans compromis. Ce type de système doit être mis hors ligne pour chaque correctif ou mise à niveau du système d'exploitation. Cette interruption sporadique affaiblit la disponibilité du système. Il en va de même pour les logiciels. Une simple erreur, comme une faute de frappe stupide ou une mauvaise installation, compromet l'AH.
Le système HA idéal, qui reste en ligne plus de 99,999 % du temps, intègre la redondance, le basculement et la surveillance, tout en adaptant le matériel, le réseau, le système d'exploitation, le middleware et les correctifs et mises à niveau des applications en ligne, en temps réel, sans interruption pour l'utilisateur final.





Commentaires (7)
What about geographic redundancy? Node balancers no yet supports nodes in other data centers. How I can achieve this?
You’re right, Javier: our NodeBalancers offer redundancy for Linodes within the same data center. For geographic redundancy, we’d recommend using a CDN service, such as Cloudflare, Fastly, Limelight, or similar. You could set this up yourself by using a service such as HAProxy. There’s a great Community Questions post that covers this in further detail: https://www.linode.com/community/questions/17647/can-i-use-nodebalancers-across-data-centers
Otherwise, we’ve added this as a feature request for future NodeBalancer development to our internal tracker. If we make any changes, we’ll be sure to post about them here on our blog.
What about geographic redundancy?
Hi there! I just responded to a similar comment above. In short, we recommend a CDN for geographic redundancy, though you could use HAProxy if you’d like to set this up yourself.
Thanks for writing the awesome article. I really loved the stuff. You see, I have been using Linode server from past 2 years and it’s been working pretty awesome for me. Although, it’s not the conventional hosting server. Instead it’s the managed hosting instance which is being managed by Cloudways.
I hardly remember any downtime. So, am I consistently experiencing the high availability? or Cloudways is playing it’s role.
Thanks for the compliment, Marilu! There are a few things that can cause uptime, such as the dependability of the hosts or the host’s software. In your case, it could be both. In regards to Cloudways’ service, I suggest reaching out to their support as they would be in a better position to answer that question.
Yeah sure! I regularly talk to the Cloudways support team. This time I will ask them the secret behind their service.