

Olá, sou engenheiro Mike-Solutions da Linode. Se você está curioso sobre a Alta Disponibilidade, este posto deve ajudar a esclarecer as coisas para você. Aproveite!
No mundo hiper conectado de hoje, os consumidores esperam ter acesso aos serviços instantaneamente, a qualquer momento e de qualquer lugar. Além disso, você precisa pensar em intervalos de atenção - você sabe que tem cerca de 30 segundos para captar a atenção de um consumidor antes de ele seguir em frente? Por esta razão, é crucial implementar uma alta disponibilidade (HA) em suas aplicações. Neste post do blog, vou definir HA, explicar os vários componentes que vão para uma arquitetura HA básica e examinar como construir uma infra-estrutura HA simples para uma aplicação web.
O que é Alta Disponibilidade?
Primeiro, vamos definir a disponibilidade: a porcentagem do tempo total que um sistema de computador está acessível para o uso normal. Em outras palavras, a disponibilidade descreve até que ponto um sistema é on-line e acessível. Pode-se supor que a disponibilidade ótima é 100%, mas isso é impossível.
É aqui que entra a Alta Disponibilidade. Os sistemas HA são aqueles com disponibilidade on-line variando de 99,9 a 99,999 por cento do tempo (ver Tabela 1). Um HA ideal a se esforçar é 99,999%-"cinco noves" - o que constitui cerca de cinco minutos de tempo de inatividade por ano.
Alta Disponibilidade pelos Números
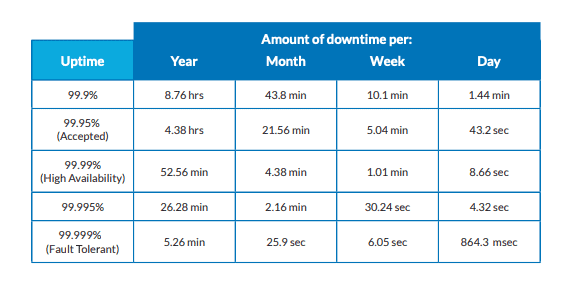
Os projetistas de sistemas tentam alcançar o maior HA possível. O HA pode ser aumentado através da tolerância a falhas. Isto envolve a construção de diferentes características do sistema que permitem uma operação contínua no caso de uma falha do sistema. Exemplos de características de tolerância a falhas são a redundância e a replicação - mais sobre estas a seguir.
Como funciona a Alta Disponibilidade?
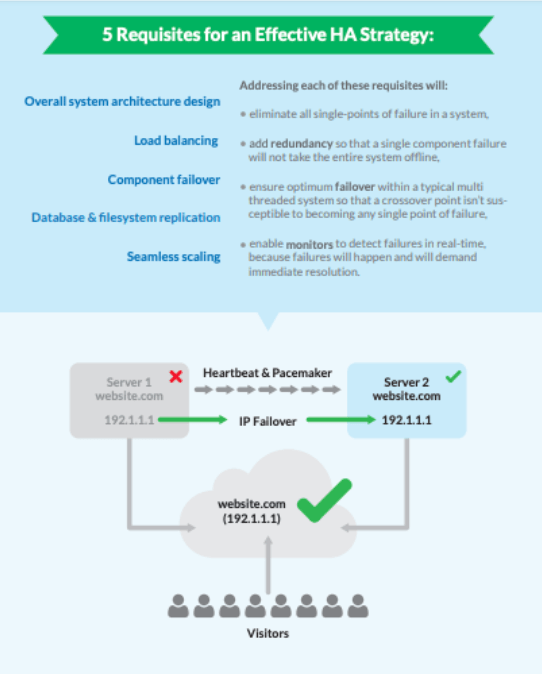
Há muitas características que podem ir para a construção de um sistema HA ideal. Estes componentes devem ser integrados entre si, monitorados continuamente e capazes de uma rápida recuperação. Estes incluem:
- exemplo de redundância,
- balanceamento de carga,
- falha de hardware e software em componentes díspares,
- replicação de dados, e
- escalonamento automático.
Estas características são explicadas com mais detalhes no diagrama abaixo:
Como Avaliar a Disponibilidade de seu Sistema
Deseja determinar a disponibilidade da infra-estrutura de sua nuvem? Baseia-se em três critérios:
- seu tamanho e escopo
- inclusão de componentes de hardware
- Escala antecipada para atender a demanda futura
Após a avaliação, você pode decidir revisar sua infra-estrutura. Aconselho-o a revisar cada critério separadamente primeiro, e depois coletivamente. A revisão de sua arquitetura pode incluir ferramentas virtuais, como, por exemplo
- novos servidores secundários e add-ons
- Utilitários de software habilitador de HA
- hardware suplementar
Como o balanceamento de carga afeta o HA?
O balanceamento de carga distribui de forma inteligente o tráfego de entrada em um ou mais servidores. Essas ferramentas, como o NodeBalancers da Linode, foram projetadas para serem "configuradas e esquecidas". Elas permitem que os servidores de back-end sejam adicionados ou removidos sem problemas, sem que os usuários finais enfrentem qualquer tempo de inatividade.
Um equilibrador de carga típico monitora um endereço IP para pedidos recebidos e o escaneia em busca de sobrecarga ou falha. Se detectado, ele segue regras configuradas (incluindo falha de IP atribuído) para enviar tráfego para um nó mais prontamente disponível. Desta forma, o tráfego é distribuído uniformemente e os usuários finais não encontram interrupções no serviço.
Quase todas as aplicações podem se beneficiar do balanceamento de carga. É um componente chave para escalonar nos usuários e, ao mesmo tempo, alcançar redundância.

O que é exatamente o Failover?
O failover é a pedra angular dos sistemas HA. Com o failover, as tarefas são automaticamente redirecionadas para um servidor secundário ou terciário em caso de parada planejada ou acidental.
O Failover compreende soluções de hardware e software, tais como adicionar servidores de banco de dados espelhados a um cluster, ou configurar um endereço IP para que ele encaminhe o tráfego para o servidor mais disponível.
Como funciona a replicação de sistemas de arquivos?
Em um cluster HA, cada servidor (por exemplo, aplicativo, banco de dados, sistema de arquivos) será configurado para espelhar outros servidores, com os dados armazenados sendo replicados automaticamente entre todos os outros servidores da arquitetura. As solicitações recebidas poderão acessar os dados, não importando em qual servidor eles residam. Isto resulta em uma experiência perfeita para o usuário final.
Os softwares Network File System (NFS) como GlusterFS, LizardFS e HDFS podem agregar vários tipos de servidores em um sistema de arquivos de rede paralelo. Caso um servidor falhe, o software NFS redireciona automaticamente as solicitações dirigidas a ele para um servidor online, cujos arquivos e dados foram espelhados e sincronizados.

E quanto ao banco de dados?
O objetivo aqui é conseguir uma replicação síncrona - seus dados são copiados continuamente de um servidor de banco de dados para outro. Isto resulta na distribuição uniforme dos dados aos usuários finais, sem interrupção. Você pode conseguir isto através das seguintes plataformas de software, em qualquer combinação:
Onde se encaixa o Seamless Scaling?
Você precisa de seu sistema para crescer e ser responsivo aos usuários finais. Cada sistema é diferente, portanto não há uma plataforma única, de tamanho único, para escalar um sistema enquanto mantém o HA. Você precisa escolher a plataforma de implantação distribuída certa para você. Alguns exemplos são:
- SaltStack: uma plataforma de gerenciamento de configuração escalável e flexível para automação de nuvens acionadas por eventos
- Chef: software que escreve receitas de configuração do sistema em Erlang ou Ruby
- Puppet: software que gerencia a configuração de sistemas Unix e Microsoft Windows
Vejamos um exemplo
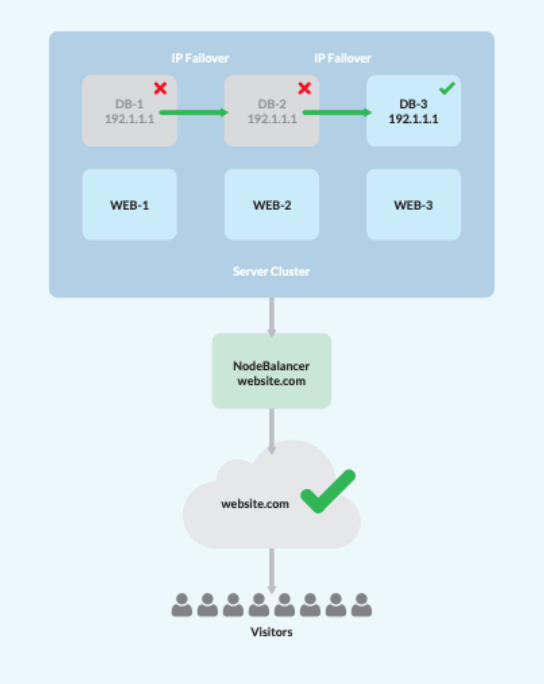
Para ajudar a colocar as coisas em perspectiva, elaboramos uma lista de medidas que poderíamos tomar para alcançar HA. Isto envolve projetar um sistema com um único balanceador de carga, três servidores web/aplicativos e três servidores de banco de dados. Atenção: pelo menos três servidores DB são necessários para estabelecer o quorum de dados dentro das arquiteturas HA.
- Uma vez montado o cluster, configure os servidores web/app para replicar os dados do site usando o NFS de sua escolha.
- Isto ativará o equilibrador de carga e atribuirá tráfego entre os três nós da web/app, removendo automaticamente quaisquer nós que tenham falhado.
- Criar uma configuração MySQL Master-Master usando Percona XtraDB.
- Designar um IP privado flutuante, gerenciado por Keepalived, para funcionar como failover .
- Aponte todos os servidores web/app para o IP privado flutuante, de modo que ele se moverá automaticamente para um nó de banco de dados on-line no caso de qualquer servidor DB cair.
Voilá! Isto resultará em uma interrupção mínima para os usuários finais porque o acesso ao servidor permanece disponível, apesar de qualquer ponto de falha.
Conclusão
Então, você quer estabelecer um sistema HA?
É importante saber que isto requer um planejamento cuidadoso. Primeiro, você precisará calcular o custo real do tempo de inatividade. Isto varia de acordo com a organização e desempenhará um papel fundamental para determinar quanto tempo de inatividade em um determinado ano é aceitável. Esta informação é fundamental para determinar a combinação certa de configuração de hardware, ferramentas de software e manutenção do sistema.
A adição de componentes de hardware a um sistema pode impedir o HA. Anexar um servidor a seu cluster acaba aumentando o risco de falha, portanto, deve ser feito corretamente.
É verdade - uma arquitetura de sistema simplificada é, bem, mais simples. Mas, ela não vem sem compromisso. Este tipo de sistema deve ser retirado do ar para cada atualização do sistema operacional ou de cada patch. Esta interrupção esporádica irá enfraquecer a disponibilidade do sistema. O mesmo se aplica ao software. Um único erro, como um erro de digitação bobo ou uma instalação ruim, comprometerá o HA.
O sistema HA ideal - um sistema que permanece online mais de 99,999% do tempo - integra redundância, failover e monitoramento, enquanto adapta hardware, rede, sistema operacional, middleware e patches e atualizações de aplicativos online, em tempo real, sem interrupção do usuário final.







Comentários (7)
What about geographic redundancy? Node balancers no yet supports nodes in other data centers. How I can achieve this?
You’re right, Javier: our NodeBalancers offer redundancy for Linodes within the same data center. For geographic redundancy, we’d recommend using a CDN service, such as Cloudflare, Fastly, Limelight, or similar. You could set this up yourself by using a service such as HAProxy. There’s a great Community Questions post that covers this in further detail: https://www.linode.com/community/questions/17647/can-i-use-nodebalancers-across-data-centers
Otherwise, we’ve added this as a feature request for future NodeBalancer development to our internal tracker. If we make any changes, we’ll be sure to post about them here on our blog.
What about geographic redundancy?
Hi there! I just responded to a similar comment above. In short, we recommend a CDN for geographic redundancy, though you could use HAProxy if you’d like to set this up yourself.
Thanks for writing the awesome article. I really loved the stuff. You see, I have been using Linode server from past 2 years and it’s been working pretty awesome for me. Although, it’s not the conventional hosting server. Instead it’s the managed hosting instance which is being managed by Cloudways.
I hardly remember any downtime. So, am I consistently experiencing the high availability? or Cloudways is playing it’s role.
Thanks for the compliment, Marilu! There are a few things that can cause uptime, such as the dependability of the hosts or the host’s software. In your case, it could be both. In regards to Cloudways’ service, I suggest reaching out to their support as they would be in a better position to answer that question.
Yeah sure! I regularly talk to the Cloudways support team. This time I will ask them the secret behind their service.