


嘿,我是Mike,Linode的解决方案工程师。如果你对高可用性感到好奇,这篇文章应该能帮助你理清头绪。请欣赏!
在今天这个超级连接的世界里,消费者希望能在任何时间、任何地点即时获得服务。此外,你需要考虑注意力的持续时间--你知道在消费者转移注意力之前,你有大约30秒的时间来抓住他们的注意力吗?出于这个原因,在你的应用程序上实施高可用性(HA)是至关重要的。在这篇博文中,我将定义HA,解释进入基本HA架构的各种组件,并研究如何为一个Web应用建立简单的HA基础设施。
什么是高可用性?
首先,让我们定义一下可用性: 一个计算机系统可以正常使用的总时间的百分比。换句话说,可用性描述了一个系统在多大程度上是在线和可访问的。你可能认为最佳可用性是100%,但这是不可能的。
这就是高可用性的意义所在。高可用性系统是指那些在线可用性在99.9%到99.999%之间的系统(见表1)。理想的HA是99.999%--"5个9",这意味着每年大约有5分钟的停机时间。
数字上的高可用性
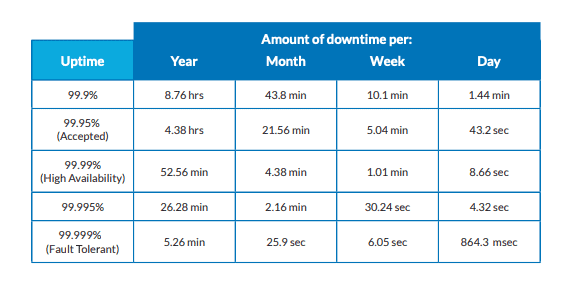
系统设计者试图实现尽可能高的HA。HA可以通过容错来提高。这涉及到建立不同的系统功能,以便在系统发生故障时能够继续运行。容错功能的例子是冗余和复制--接下来会详细介绍这些。
高可用性是如何工作的?
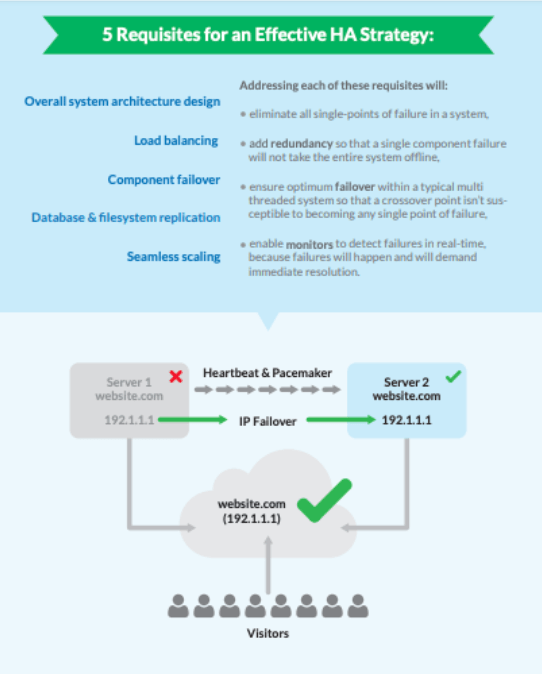
构建一个理想的HA系统可以有很多功能。这些组件必须集成在一起,持续监测,并能够迅速恢复。这些包括:
- 实例冗余、
- 负载平衡、
- 跨越不同组件的硬件和软件故障转移、
- 数据复制,以及
- 自动缩放。
这些特点在下图中得到了进一步解释:
如何评估你的系统的可用性
想确定你的云的基础设施的可用性?它是基于三个标准:
- 其规模和范围
- 包含硬件组件
- 预计将扩大规模以满足未来需求
经过评估,你可以决定修改你的基础设施。我建议你先单独修订每个标准,然后再集体修订。修订你的架构可以包括虚拟工具,如::
- 新的二级服务器和附加组件
- 支持HA的软件实用程序
- 补充硬件
负载均衡是如何影响HA的?
负载均衡可将进入的流量智能地分配给一台或多台服务器。这些工具(如Linode 的NodeBalancers)的设计宗旨是 "设置并遗忘"。它们允许无缝添加或移除后端服务器,而终端用户不会遇到任何停机时间。
一个典型的负载平衡器监测一个IP地址的传入请求,并扫描它的过载或故障。如果检测到,它遵循配置的规则(包括分配的IP故障),将流量发送到一个更容易获得的节点。这样,流量得到均匀分布,终端用户不会遇到服务中断。
几乎所有的应用程序都可以从负载均衡中受益。它是扩大用户规模的一个关键组成部分,同时也实现了冗余。

究竟什么是故障转移?
故障转移是HA系统的基石。通过故障转移,在计划或意外停机的情况下,任务会自动重新分配到第二或第三服务器。
故障转移包括硬件和软件解决方案,如在集群中添加镜像数据库服务器,或配置一个IP地址,使其将流量路由到最可用的服务器。
文件系统复制是如何工作的?
在一个HA集群中,每台服务器(如应用程序、数据库、文件系统)将被配置为镜像其他服务器,存储的数据将在架构中的所有其他服务器之间自动复制。传入的请求将能够访问数据,无论它驻留在哪台服务器上。这将为终端用户带来无缝体验。
网络文件系统(NFS)软件,如GlusterFS、LizardFS和HDFS,可以将各种类型的服务器聚集到一个并行的网络文件系统中。如果一个服务器出现故障,NFS软件会自动将针对它的请求重新分配到一个在线服务器上,该服务器的文件和数据已经被镜像和同步。

那么数据库呢?
这里的目标是实现同步复制--你的数据不断从一个数据库服务器复制到另一个。这导致了统一的数据分配给终端用户,而不会出现中断。你可以通过以下软件平台,以任何组合实现这一目标:
无缝扩展在哪里?
你需要你的系统成长并对终端用户作出反应。每个系统都是不同的,所以没有一个单一的、适合所有的平台来扩展系统,同时保持HA。你需要选择适合你的分布式部署平台。一些例子是:
- SaltStack:用于事件驱动的云计算自动化的可扩展和灵活的配置管理平台
- Chef:用Erlang或Ruby编写系统配置食谱的软件
- Puppet指管理类似Unix和微软Windows系统配置的软件。
让我们看一个例子
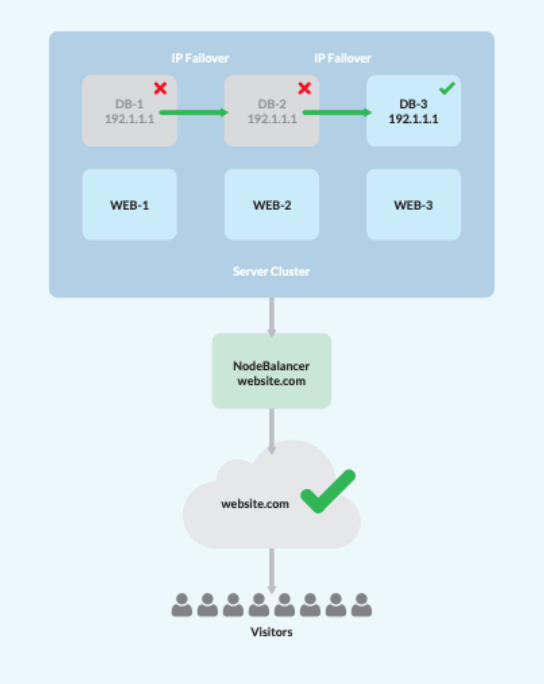
为了帮助把事情看清楚,我们把我们可以采取的步骤列表放在一起,以实现HA。这涉及到设计一个具有单个负载均衡器、三个网络/应用服务器和三个数据库服务器的系统。请注意:至少需要三个数据库服务器来建立HA架构内的数据法定人数。
- 一旦集群组装完毕,配置Web/应用服务器,使用你选择的NFS复制网站数据。
- 这将激活负载平衡器,并在三个网络/应用程序节点之间分配流量,自动删除任何失败的节点。
- 创建一个MySQL主-主配置,使用 Percona XtraDB.
- 指定一个浮动的私有IP,由Keepalived管理,以作为故障转移的功能。
- 将所有的Web/应用服务器指向浮动的私有IP,因此在任何DB服务器发生故障的情况下,它将自动转移到在线数据库节点。
Voila!这将导致对终端用户的最小干扰,因为尽管有任何故障点,服务器访问仍然可用。
总结
那么,你想建立一个HA系统?
重要的是要知道,这需要仔细规划。首先,你需要计算停机时间的实际成本。这因组织而异,并将在确定一年中多少停机时间可以接受方面发挥关键作用。这一信息对于确定硬件配置、软件工具和系统维护的正确组合至关重要。
将硬件组件添加到系统中会阻碍HA。将服务器附加到你的集群上最终会增加失败的风险,所以必须做得正确。
这是真的,一个简化的系统架构是,嗯,更简单。但是,这并不是没有妥协的结果。这种系统必须在每一个补丁或操作系统升级时脱机。这种零星的中断会削弱系统的可用性。对软件来说也是如此。一个单一的错误,如一个愚蠢的错别字或糟糕的安装,都会影响到HA。
理想的HA系统--在99.999%以上的时间内保持在线,集成了冗余、故障切换和监控,同时实时适应硬件、网络、操作系统、中间件和应用程序的补丁和升级,而不会对终端用户造成干扰。






评论 (7)
What about geographic redundancy? Node balancers no yet supports nodes in other data centers. How I can achieve this?
You’re right, Javier: our NodeBalancers offer redundancy for Linodes within the same data center. For geographic redundancy, we’d recommend using a CDN service, such as Cloudflare, Fastly, Limelight, or similar. You could set this up yourself by using a service such as HAProxy. There’s a great Community Questions post that covers this in further detail: https://www.linode.com/community/questions/17647/can-i-use-nodebalancers-across-data-centers
Otherwise, we’ve added this as a feature request for future NodeBalancer development to our internal tracker. If we make any changes, we’ll be sure to post about them here on our blog.
What about geographic redundancy?
Hi there! I just responded to a similar comment above. In short, we recommend a CDN for geographic redundancy, though you could use HAProxy if you’d like to set this up yourself.
Thanks for writing the awesome article. I really loved the stuff. You see, I have been using Linode server from past 2 years and it’s been working pretty awesome for me. Although, it’s not the conventional hosting server. Instead it’s the managed hosting instance which is being managed by Cloudways.
I hardly remember any downtime. So, am I consistently experiencing the high availability? or Cloudways is playing it’s role.
Thanks for the compliment, Marilu! There are a few things that can cause uptime, such as the dependability of the hosts or the host’s software. In your case, it could be both. In regards to Cloudways’ service, I suggest reaching out to their support as they would be in a better position to answer that question.
Yeah sure! I regularly talk to the Cloudways support team. This time I will ask them the secret behind their service.