

Hola, soy Mike-Solutions Engineer en Linode. Si tienes curiosidad por la Alta Disponibilidad, este post debería ayudarte a aclarar las cosas. Que lo disfrutes.
En el mundo hiperconectado de hoy, los consumidores esperan tener acceso a los servicios al instante, en cualquier momento y desde cualquier lugar. Además, hay que pensar en la capacidad de atención: ¿sabe que tiene unos 30 segundos para captar la atención de un consumidor antes de que pase a otra cosa? Por esta razón, es crucial implementar la alta disponibilidad (HA) en sus aplicaciones. En esta entrada del blog, definiré la HA, explicaré los diversos componentes que forman parte de una arquitectura de HA básica y examinaré cómo construir una infraestructura de HA sencilla para una aplicación web.
¿Qué es la alta disponibilidad?
En primer lugar, definamos la disponibilidad: el porcentaje de tiempo total que un sistema informático es accesible para su uso normal. En otras palabras, la disponibilidad describe hasta qué punto un sistema está en línea y es accesible. Se podría suponer que la disponibilidad óptima es del 100%, pero eso es imposible.
Aquí es donde entra la Alta Disponibilidad. Los sistemas de alta disponibilidad son los que tienen una disponibilidad en línea que oscila entre el 99,9% y el 99,999% del tiempo (véase la Tabla 1). La HA ideal a la que hay que aspirar es del 99,999% - "cinco nueves"-, lo que supone unos cinco minutos de inactividad al año.
La alta disponibilidad en cifras
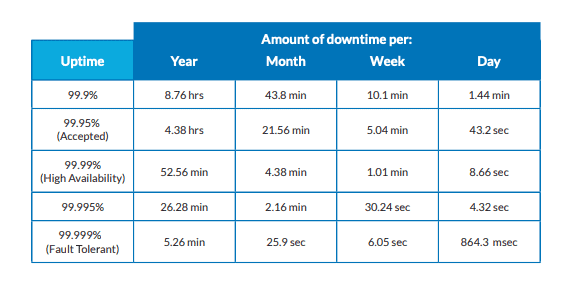
Los diseñadores de sistemas intentan conseguir la mayor HA posible. La HA puede aumentarse mediante la tolerancia a los fallos. Esto implica la creación de diferentes características del sistema que permitan un funcionamiento continuo en caso de fallo del sistema. Ejemplos de características de tolerancia a fallos son la redundancia y la replicación.
¿Cómo funciona la alta disponibilidad?
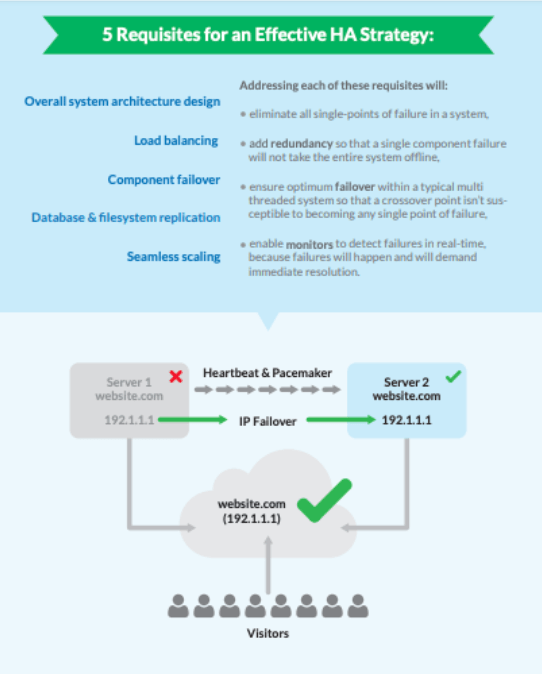
Son muchas las características que pueden formar parte de un sistema de HA ideal. Estos componentes deben estar integrados entre sí, ser supervisados continuamente y ser capaces de una rápida recuperación. Entre ellos se encuentran:
- redundancia de instancias,
- equilibrio de carga,
- la conmutación por error de hardware y software en componentes dispares,
- replicación de datos, y
- escalamiento automatizado.
Estas características se explican con más detalle en el siguiente diagrama:
Cómo evaluar la disponibilidad de su sistema
¿Quiere determinar la disponibilidad de la infraestructura de su nube? Se basa en tres criterios:
- su tamaño y alcance
- inclusión de componentes de hardware
- la ampliación prevista para satisfacer la demanda futura
Tras la evaluación, puede decidir revisar su infraestructura. Le aconsejo que revise primero cada criterio por separado y luego en conjunto. La revisión de su arquitectura puede incluir herramientas virtuales, como:
- nuevos servidores secundarios y complementos
- Utilidades de software que permiten la HA
- hardware adicional
¿Cómo afecta el equilibrio de carga a la HA?
El balanceo de carga distribuye de forma inteligente el tráfico entrante entre uno o varios servidores. Estas herramientas, como NodeBalancers deLinode, están diseñadas para "fijarse y olvidarse". Permiten añadir o eliminar sin problemas servidores backend sin que los usuarios finales sufran ningún tiempo de inactividad.
Un equilibrador de carga típico supervisa una dirección IP en busca de solicitudes entrantes y la analiza en busca de sobrecargas o fallos. Si se detecta, sigue las reglas configuradas (incluida la conmutación por error de la IP asignada) para enviar el tráfico a un nodo más disponible. De este modo, el tráfico se distribuye uniformemente y los usuarios finales no encuentran interrupciones en el servicio.
Casi todas las aplicaciones pueden beneficiarse del equilibrio de carga. Es un componente clave para escalar en usuarios al mismo tiempo que se logra la redundancia.

¿Qué es exactamente la conmutación por error?
La conmutación por error es la piedra angular de los sistemas de HA. Con la conmutación por error, las tareas se redirigen automáticamente a un servidor secundario o terciario en caso de que se produzca una interrupción planificada o accidental.
La conmutación por error comprende soluciones de hardware y software, como añadir servidores de bases de datos en espejo a un clúster, o configurar una dirección IP para que dirija el tráfico al servidor más disponible.
¿Cómo funciona la replicación del sistema de archivos?
En un clúster de HA, cada servidor (por ejemplo, aplicación, base de datos, sistema de archivos) se configurará para reflejar otros servidores, y los datos almacenados se replicarán automáticamente entre todos los demás servidores de la arquitectura. Las solicitudes entrantes podrán acceder a los datos, independientemente del servidor en el que residan. El resultado es una experiencia sin fisuras para el usuario final.
Los programas de sistemas de archivos en red (NFS), como GlusterFS, LizardFS y HDFS, pueden agrupar varios tipos de servidores en un sistema de archivos en red paralelo. Si un servidor falla, el software NFS redirige automáticamente las peticiones dirigidas a él a un servidor en línea, cuyos archivos y datos han sido duplicados y sincronizados.

¿Y la base de datos?
El objetivo es conseguir una replicación sincrónica: los datos se copian continuamente de un servidor de base de datos a otro. El resultado es una distribución uniforme de los datos a los usuarios finales, sin interrupciones. Puede conseguirlo mediante las siguientes plataformas de software, en cualquier combinación:
¿Dónde encaja el Seamless Scaling?
Necesita que su sistema crezca y responda a los usuarios finales. Cada sistema es diferente, por lo que no existe una plataforma única para escalar un sistema manteniendo la HA. Tiene que elegir la plataforma de despliegue distribuido adecuada para usted. Algunos ejemplos son:
- SaltStack: una plataforma de gestión de la configuración escalable y flexible para la automatización de la nube basada en eventos
- Chef: software que escribe recetas de configuración del sistema en Erlang o Ruby
- Puppet: software que gestiona la configuración de los sistemas tipo Unix y Microsoft Windows
Veamos un ejemplo
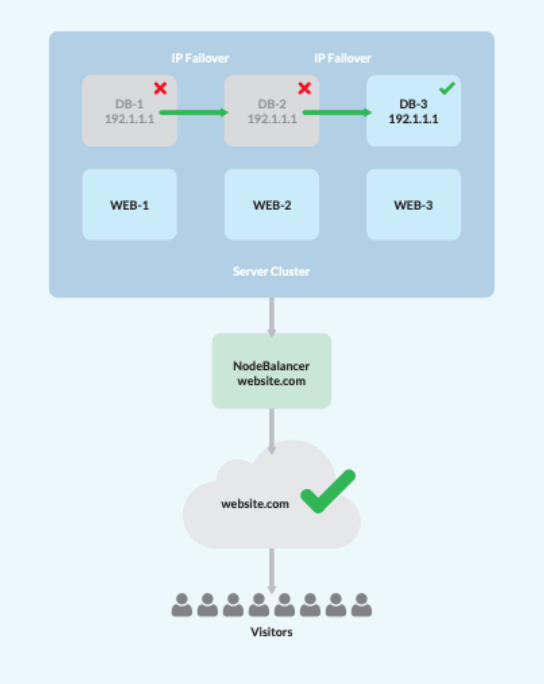
Para ayudar a poner las cosas en perspectiva, hemos elaborado una lista de pasos que podríamos dar para conseguir HA. Se trata de diseñar un sistema con un único equilibrador de carga, tres servidores web/aplicación y tres servidores de base de datos. Nota: se necesitan al menos tres servidores de base de datos para establecer el quórum de datos en las arquitecturas de HA.
- Una vez montado el clúster, configure los servidores web/de aplicaciones para replicar los datos del sitio utilizando el NFS de su elección.
- Esto activará el equilibrador de carga, y asignará el tráfico entre los tres nodos web/app, eliminando automáticamente los nodos que hayan fallado.
- Cree una configuración Master-Master de MySQL utilizando Percona XtraDB.
- Designar una IP privada flotante, gestionada por Keepalived, para que funcione como failover .
- Apunta todos los servidores web/de aplicaciones a la IP privada flotante, para que se mueva automáticamente a un nodo de base de datos en línea en el caso de que algún servidor de base de datos se caiga.
Voilà! De este modo, las interrupciones para los usuarios finales serán mínimas, ya que el acceso al servidor sigue estando disponible, a pesar de cualquier punto de fallo.
Conclusión
Entonces, ¿quieres establecer un sistema de HA?
Es importante saber que esto requiere una cuidadosa planificación. En primer lugar, tendrá que calcular el coste real del tiempo de inactividad. Esto varía según la organización y desempeñará un papel clave a la hora de determinar cuánto tiempo de inactividad es aceptable en un año determinado. Esta información es fundamental para determinar la combinación adecuada de configuración de hardware, herramientas de software y mantenimiento del sistema.
Añadir componentes de hardware a un sistema puede impedir la HA. Adjuntar un servidor a su clúster aumenta, en última instancia, el riesgo de fallo, por lo que debe hacerse bien.
Es cierto que una arquitectura de sistema simplificada es, bueno, más sencilla. Pero, no viene sin compromiso. Este tipo de sistema debe desconectarse para cada parche o actualización del sistema operativo. Esta interrupción esporádica debilitará la disponibilidad del sistema. Lo mismo ocurre con el software. Un solo error, como una errata tonta o una mala instalación, comprometerá la HA.
El sistema de HA ideal -que permanece en línea más del 99,999% del tiempo- integra la redundancia, la conmutación por error y la supervisión, a la vez que adapta los parches y las actualizaciones de hardware, red, sistema operativo, middleware y aplicaciones en línea, en tiempo real, sin interrumpir al usuario final.







Comentarios (7)
What about geographic redundancy? Node balancers no yet supports nodes in other data centers. How I can achieve this?
You’re right, Javier: our NodeBalancers offer redundancy for Linodes within the same data center. For geographic redundancy, we’d recommend using a CDN service, such as Cloudflare, Fastly, Limelight, or similar. You could set this up yourself by using a service such as HAProxy. There’s a great Community Questions post that covers this in further detail: https://www.linode.com/community/questions/17647/can-i-use-nodebalancers-across-data-centers
Otherwise, we’ve added this as a feature request for future NodeBalancer development to our internal tracker. If we make any changes, we’ll be sure to post about them here on our blog.
What about geographic redundancy?
Hi there! I just responded to a similar comment above. In short, we recommend a CDN for geographic redundancy, though you could use HAProxy if you’d like to set this up yourself.
Thanks for writing the awesome article. I really loved the stuff. You see, I have been using Linode server from past 2 years and it’s been working pretty awesome for me. Although, it’s not the conventional hosting server. Instead it’s the managed hosting instance which is being managed by Cloudways.
I hardly remember any downtime. So, am I consistently experiencing the high availability? or Cloudways is playing it’s role.
Thanks for the compliment, Marilu! There are a few things that can cause uptime, such as the dependability of the hosts or the host’s software. In your case, it could be both. In regards to Cloudways’ service, I suggest reaching out to their support as they would be in a better position to answer that question.
Yeah sure! I regularly talk to the Cloudways support team. This time I will ask them the secret behind their service.