

こんにちは、Mike です - Linodeでソリューションエンジニアをやっています。高可用性に興味がある場合は、この記事が役に立つはずです。お楽しみください!
今日のハイパーコネクテッドの世界では、ユーザーはいつでもどこからでもサービスに即座にアクセスできることを期待しています。さらに、アテンションスパンについて考える必要があります。ユーザーはページ移動してしまう前に興味を引くには30秒しかないことを知っていますか?このため、アプリケーションに高可用性 (HA) を実装することが重要です。このブログ記事では、HA を定義し、基本的な HA アーキテクチャに入るさまざまなコンポーネントについて説明し、インフラ Web アプリケーション用に単純な HA を構築する方法を探索してみましょう。
高可用性とは?
まず、可用性定義してみましょう:コンピュータシステムが通常使用のためにアクセス可能な合計時間の割合。つまり可用性とは、システムがオンラインでアクセス可能な範囲を表します。最適な可用性は 100% と思うかもしれませんが、それは不可能です。
ここが高可用性が登場するところです。HA システムは、所定時間のうち99.9 から 99.999% のオンライン可用性を持つシステムです (表 1 を参照)。理想的なHAは99.999%(「5ナイン」)で、年間約5分間のダウンタイムに相当します。
数字で見るハイ・アベイラビリティ
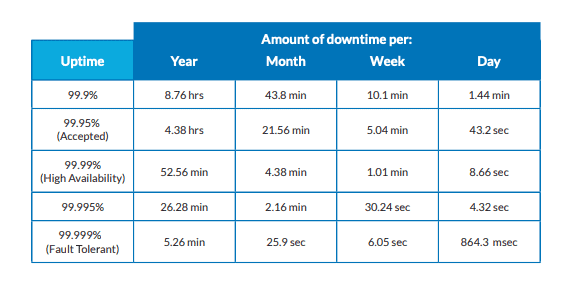
システム設計者は可能な限り最高のHAを達成しようとします。HA はフォールト トレランスを通じて増やすことができます。これにはシステム障害が発生した場合に継続的な操作を可能にするさまざまなシステム機能の構築が含まれます。フォールト トレランス機能の例としては冗長性とレプリケーションなどがあります。
高可用性のしくみは?
理想的な HA システムの構築に取り組むことができる機能は多くあります。これらのコンポーネントは一緒に統合し、継続的に監視し、迅速なリカバリを可能にする必要があります。これには、次のようなものがあります。
- インスタンスの冗長性
- ロードバランシング
- 異なるコンポーネント間でのハードウェアとソフトウェアのフェイルオーバー
- データレプリケーション
- 自動スケーリング
これらの機能については、次の図で詳しく説明します。
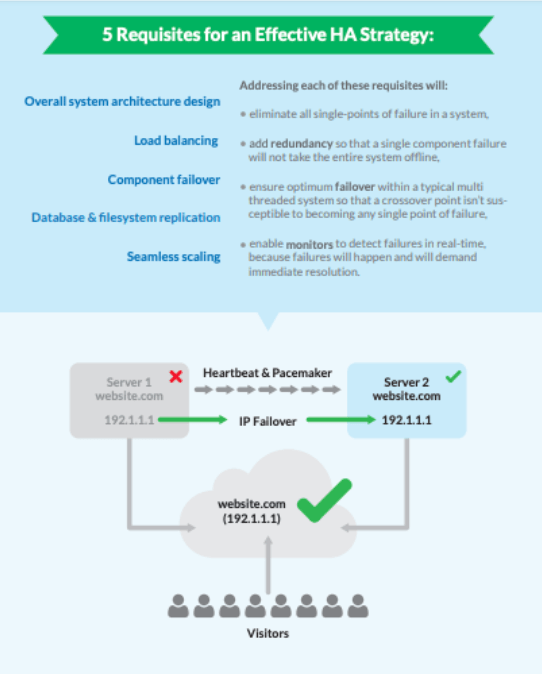
システムの可用性を評価する方法
クラウドインフラの可用性を確認するには、次の 3 つの基準に基づいて判断します。
- そのサイズと範囲
- ハードウェア コンポーネントの内包
- 将来の需要を満たす予測スケーリング
評価後、インフラの変更を行う決定もできます。最初に各基準を個別に改良し、次にまとめて改善することをお勧めします。アーキテクチャの変更には、次のような仮想ツールを含めることができます。
- 新しいセカンダリ サーバーとアドオン
- HA を有効にするソフトウェア ユーティリティ
- 補足ハードウェア
ロード バランシングは HA にどのような影響を与えますか?
ロードバランシングは着信トラフィックを 複数のサーバーにインテリジェントに分散します。これらのツール、例えば Linode の NodeBalancer は”設置したら忘れる" ように設計されています。エンドユーザーがダウンタイムに遭遇することなくバックエンド サーバーをシームレスに追加または削除できます。
一般的なロード バランサーは着信要求の IP アドレスを監視し、過負荷または障害をスキャンします。それらが検出された場合は構成済みのルール (割り当てられた IP フェールオーバーを含む) に従って、より使用可能なノードにトラフィックを転送します。これによりトラフィックが均等に分散され、エンドユーザーがサービスの中断に遭遇しなくなることはありません。
ほぼすべてのアプリケーションはロードバランシングの恩恵を受けることができます。これは冗長性を実現しながらユーザーをスケーリングするための重要なコンポーネントです。

フェールオーバーとは何ですか?
フェイルオーバーは HA システムの基礎です。フェールオーバーでは、計画的または偶発的なダウンタイムが発生した場合、タスクがセカンダリ サーバーまたは第 3 のサーバーに自動的に再ルーティングされます。
フェールオーバーは、ミラー化されたデータベース サーバーをクラスタに追加したり、最も利用可能なサーバーにトラフィックをルーティングするように IP アドレスを構成したりするなど、ハードウェアソリューションとソフトウェア ソリューションの両方で構成されます。
ファイルシステムレプリケーションの仕組みは?
HA クラスターでは、各サーバー (アプリ、データベース、ファイル システムなど) は他のサーバーをミラー化するように構成され、格納されたデータはアーキテクチャ内の他のすべてのサーバー間で自動的にレプリケートされます。着信要求はどのサーバーに存在する場合でも、データにアクセスできます。これにより、エンド ユーザーはシームレスなエクスペリエンスを得ることができます。
GlusterFS、 LizardFS、及びHDFSのようなネットワーク・ファイル・システム (NFS) ソフトウェアは、さまざまなサーバー・タイプを 1 つのパラレル・ネットワーク・ファイル・システムに集約することができます。1 台のサーバーで障害が発生した場合、NFS ソフトウェアは、そのサーバーに送信された要求をファイルとデータがミラーリングされ同期されたオンライン サーバーに自動的に再ルーティングします。

データベースについてはどうでしょうか?
ここでの目標は、同期レプリケーションを実現することです。これにより、中断されることなくエンド ユーザーへの一意的なデータ配信が実現されます。これを実現するには次のソフトウェア プラットフォームを任意の組み合わせで使用します。
シームレススケーリングはどこで登場しますか?
システムを拡張させて応答性をエンド ユーザーに提供する必要があります。システムは全て異なるので、HAを維持しながらシステムを拡張するための唯一な”ワンサイズ・フィット・オール”なプラットフォームはありません。適切な分散展開プラットフォームを選択する必要があります。次に例を示します。
- SaltStack: イベントドリブンなクラウドオートメーションのためのスケーラブルで柔軟な設定管理プラットフォーム
- Chef: Erlang または Ruby でシステム設定レシピを書き込むソフトウェア
- Puppet: Unix ライクまたは Microsoft Windows システムの構成を管理するソフトウェア
例を見てみましょう
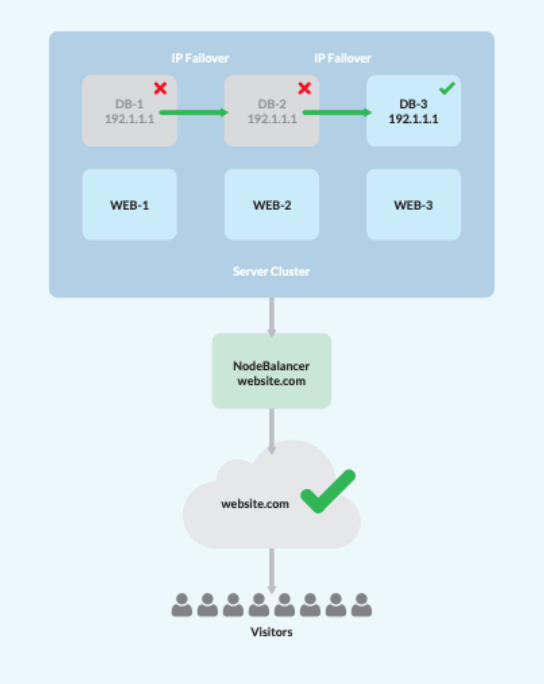
理解を深めるために、HA を実現するための手順一覧をまとめました。これには、単一のロード バランサー、3 つの Web/アプリケーション サーバー、および 3 つのデータベース サーバーを持つシステムの設計が含まれます。注意: HA アーキテクチャ内でデータ クォーラムを確立するには少なくとも 3 つの DB サーバーが必要です。
- クラスターがアセンブルされたら、選択した NFS を使用してサイト データをレプリケートするように Web/アプリ サーバーを構成します。
- これによりロード バランサーがアクティブになり、3 つの Web/アプリ ノード間でトラフィックが割り当てられ、障害が発生したノードが自動的に削除されます。
- 次のツールを使いMySQL マスターマスター設定を作成する: Percona XtraDB.
- Keepalivedによって管理されるフローティング プライベート IP を、フェールオーバーとして機能するように指定します。
- すべての Web/アプリ サーバーをフローティング プライベート IP にポイントし、DB サーバーがダウンした場合に自動的にオンライン データベース ノードに移動します。
これで出来上がり!これにより障害が発生してもサーバーアクセスが使用可能なままになるため、エンド ユーザーへの影響は最小限に抑えられます。
結論
さあ、HA システムを構築したいですか?
これには慎重な計画立案が必要だと知ることが重要です。まず、ダウンタイムの実際のコストを計算する必要があります。これは組織によって異なり、ある年のダウンタイムが許容できる程度を判断するうえで重要な役割を果たします。この情報は、ハードウェア構成、ソフトウェア ツール、およびシステム保守の適切な組み合わせを決定するうえで重要です。
ハードウェア コンポーネントをシステムに追加すると、HA を妨げる可能性があります。サーバーをクラスタに接続する事で究極的には障害発生リスクが高まるため、正しく実行する必要があります。
簡素化されたシステム アーキテクチャは言葉通り、よりシンプルです。しかし、それは妥協なしには来ません。そのようなシステムはパッチまたは OS のアップグレードごとにオフラインにする必要があります。この散発的な中断はシステムの可用性を弱めます。ソフトウェアについても同様です。愚かなタイプミスやインストール不良などのエラーが一つでもあると、HAを危険にさらします。
99.999%以上の時間をオンラインに保つ理想的なHAシステムは、冗長性、フェイルオーバー、監視を統合し、ハードウェア、ネットワーク、オペレーティング・システム、ミドルウェア、アプリケーションのパッチとアップグレードをエンドユーザーの中断なしにオンラインでリアルタイムで適応させるものです。





コメント (7)
What about geographic redundancy? Node balancers no yet supports nodes in other data centers. How I can achieve this?
You’re right, Javier: our NodeBalancers offer redundancy for Linodes within the same data center. For geographic redundancy, we’d recommend using a CDN service, such as Cloudflare, Fastly, Limelight, or similar. You could set this up yourself by using a service such as HAProxy. There’s a great Community Questions post that covers this in further detail: https://www.linode.com/community/questions/17647/can-i-use-nodebalancers-across-data-centers
Otherwise, we’ve added this as a feature request for future NodeBalancer development to our internal tracker. If we make any changes, we’ll be sure to post about them here on our blog.
What about geographic redundancy?
Hi there! I just responded to a similar comment above. In short, we recommend a CDN for geographic redundancy, though you could use HAProxy if you’d like to set this up yourself.
Thanks for writing the awesome article. I really loved the stuff. You see, I have been using Linode server from past 2 years and it’s been working pretty awesome for me. Although, it’s not the conventional hosting server. Instead it’s the managed hosting instance which is being managed by Cloudways.
I hardly remember any downtime. So, am I consistently experiencing the high availability? or Cloudways is playing it’s role.
Thanks for the compliment, Marilu! There are a few things that can cause uptime, such as the dependability of the hosts or the host’s software. In your case, it could be both. In regards to Cloudways’ service, I suggest reaching out to their support as they would be in a better position to answer that question.
Yeah sure! I regularly talk to the Cloudways support team. This time I will ask them the secret behind their service.