

Hey, I’m Mike—Solutions Engineer at Linode. If you’re curious about High Availability, this post should help clear things up for you. Enjoy!
In today’s hyper-connected world, consumers expect to have access to services instantly, at any time, from any place. In addition, you need to think about attention spans—did you know you have about 30 seconds to capture a consumer’s attention before they move on? For this reason, it’s crucial to implement high availability (HA) on your applications. In this blog post, I’ll define HA, explain the various components that go into a basic HA architecture, and examine how to build simple HA infrastructure for a web application.
What is High Availability?
First, let’s define availability: the percentage of total time a computer system is accessible for normal usage. In other words, availability describes to what extent a system is online and accessible. You might assume that optimum availability is 100%, but that is impossible.
This is where High Availability comes in. HA systems are those with online availability ranging from 99.9 to 99.999 percent of the time (see Table 1). An ideal HA to strive for is 99.999%—”five nines”—which constitutes about five minutes of downtime per year.
High Availability by the Numbers
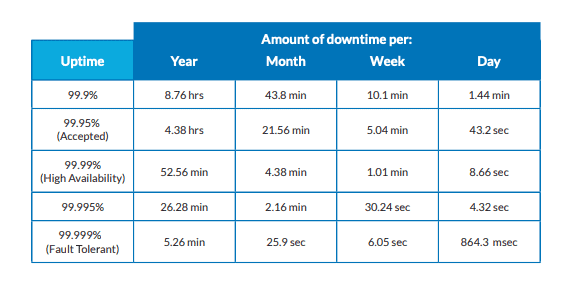
System designers try to achieve the highest HA possible. HA can be increased through fault tolerance. This involves building different system features that enable continuous operation in the event of a system failure. Examples of fault tolerance features are redundancy and replication—more on these next.
How Does High Availability Work?
There are many features that can go into building an ideal HA system. These components must be integrated together, continuously monitored, and capable of swift recovery. These include:
- instance redundancy,
- load balancing,
- hardware and software failover across disparate components,
- data replication, and
- automated scaling.
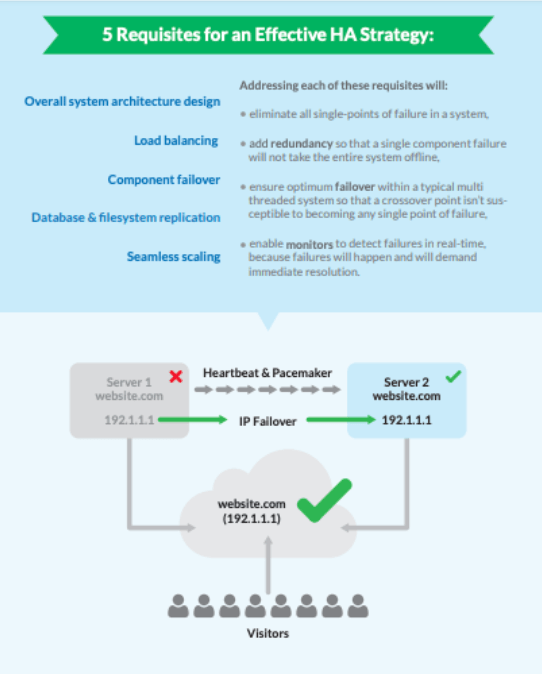
These features are further explained in the diagram below:
How to Evaluate Your System’s Availability
Want to determine the availability of your cloud’s infrastructure? It’s based on three criteria:
- its size and scope
- inclusion of hardware components
- anticipated scaling to meet future demand
After evaluating, you may decide to revise your infrastructure. I advise you to revise each criterion separately first, and then collectively. Revising your architecture can include virtual tools, such as:
- new secondary servers and add-ons
- HA-enabling software utilities
- supplemental hardware
How does load balancing affect HA?
Load balancing intelligently distributes incoming traffic over one or more servers. These tools, such as Linode’s NodeBalancers are designed to be “set and forgotten.” They allow backend servers to be seamlessly added or removed without end users encountering any downtime.
A typical load balancer monitors an IP address for incoming requests and scans it for overload or failure. If detected, it follows configured rules (including assigned IP Failover) to send traffic to a more readily available node. This way, traffic gets evenly distributed and end users do not encounter disruptions in service.
Nearly all applications can benefit from load balancing. It’s a key component to scaling in users while also achieving redundancy.

What exactly is Failover?
Failover is the cornerstone of HA systems. With failover, tasks are automatically re-routed to a secondary or tertiary server in the event of planned or accidental downtime.
Failover comprises both hardware and software solutions, such as adding mirrored database servers to a cluster, or configuring an IP address so that it will route traffic to the most available server.
How does Filesystem Replication Work?
In an HA cluster, each server (e.g., app, database, file system) will be configured to mirror other servers, with stored data being replicated automatically among all other servers in the architecture. Incoming requests will be able to access data, no matter which server it resides on. This results in a seamless experience for the end user.
Network File System (NFS) software like GlusterFS, LizardFS, and HDFS can aggregate various server types into one parallel network file system. Should one server fail, NFS software automatically re-routes requests directed at it to an online server, whose files and data have been mirrored and synchronized.

What about the database?
The goal here is to achieve synchronous replication—your data is continuously copied from one database server to another. This results in uniform data distribution to end users, without disruption. You can achieve this through the following software platforms, in any combination:
Where does Seamless Scaling fit in?
You need your system to grow and be responsive to end users. Every system is different, so there is no singular, one-size-fits-all platform to scale a system while maintaining HA. You need to choose the right distributed deployment platform for you. Some examples are:
- SaltStack: a scalable and flexible configuration management platform for event-driven cloud automation
- Chef: software that writes system configuration recipes in Erlang or Ruby
- Puppet: software that manages the configuration of Unix-like and Microsoft Windows systems
Let’s Look at an Example
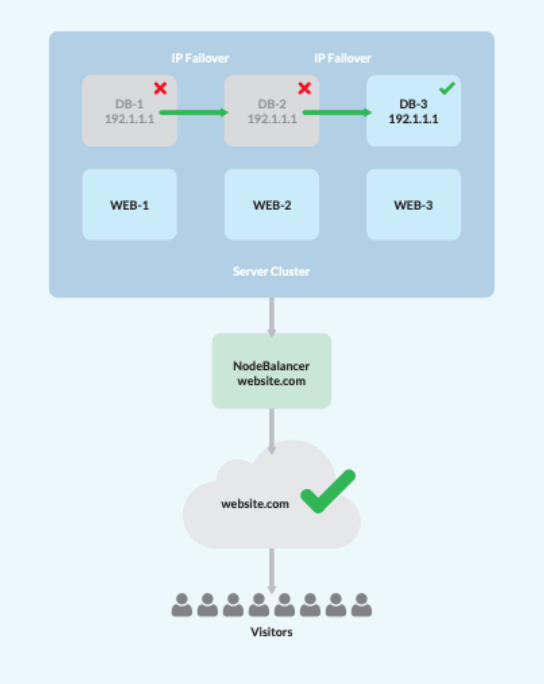
To help put things into perspective, we’ve put together a list of steps we could take to achieve HA. This involves designing a system with a single load balancer, three web/application servers, and three database servers. Please note: at least three DB servers are required to establish data quorum within HA architectures.
- Once the cluster is assembled, configure the web/app servers to replicate site data using your NFS of choice.
- This will activate the load balancer, and assign traffic among the three web/app nodes, automatically removing any nodes that have failed.
- Create a MySQL Master-Master configuration using Percona XtraDB.
- Designate a floating private IP, managed by Keepalived, to function as failover .
- Point all of the web/app servers to the floating private IP, so it will automatically move to an online database node in the case that any DB server goes down.
Voila! This will result in minimal disruption to end users because server access remains available, despite any point of failure.
Conclusion
So, you want to establish an HA system?
It’s important to know that this requires careful planning. First, you’ll need to calculate the real cost of downtime. This varies by organization and will play a key role in determining how much downtime in a given year is acceptable. This information is critical for determining the right combination of hardware configuration, software tools, and system maintenance.
Adding hardware components to a system can impede HA. Attaching a server to your cluster ultimately increases the risk of failure, so it must be done right.
It’s true—a simplified system architecture is, well, simpler. But, it doesn’t come without compromise. This kind of system must be taken offline for each and every patch or OS upgrade. This sporadic disruption will weaken the system’s availability. The same is true for software. A single error, like a silly typo or poor installation, will compromise HA.
The ideal HA system—one that remains online more than 99.999 percent of the time—integrates redundancy, failover, and monitoring, while adapting hardware, network, operating system, middleware, and application patches and upgrades online, in real-time, without end-user disruption.






Comments (7)
What about geographic redundancy? Node balancers no yet supports nodes in other data centers. How I can achieve this?
You’re right, Javier: our NodeBalancers offer redundancy for Linodes within the same data center. For geographic redundancy, we’d recommend using a CDN service, such as Cloudflare, Fastly, Limelight, or similar. You could set this up yourself by using a service such as HAProxy. There’s a great Community Questions post that covers this in further detail: https://www.linode.com/community/questions/17647/can-i-use-nodebalancers-across-data-centers
Otherwise, we’ve added this as a feature request for future NodeBalancer development to our internal tracker. If we make any changes, we’ll be sure to post about them here on our blog.
What about geographic redundancy?
Hi there! I just responded to a similar comment above. In short, we recommend a CDN for geographic redundancy, though you could use HAProxy if you’d like to set this up yourself.
Thanks for writing the awesome article. I really loved the stuff. You see, I have been using Linode server from past 2 years and it’s been working pretty awesome for me. Although, it’s not the conventional hosting server. Instead it’s the managed hosting instance which is being managed by Cloudways.
I hardly remember any downtime. So, am I consistently experiencing the high availability? or Cloudways is playing it’s role.
Thanks for the compliment, Marilu! There are a few things that can cause uptime, such as the dependability of the hosts or the host’s software. In your case, it could be both. In regards to Cloudways’ service, I suggest reaching out to their support as they would be in a better position to answer that question.
Yeah sure! I regularly talk to the Cloudways support team. This time I will ask them the secret behind their service.