

Hey, ich bin Mike, ein Solutions Engineer bei Linode. Wenn Sie neugierig auf Hochverfügbarkeit sind, sollte dieser Beitrag helfen, die Dinge für Sie zu klären. Viel Spaß!
In der heutigen vernetzten Welt erwarten die Verbraucher, dass sie sofort, jederzeit und von jedem Ort aus Zugang zu Services haben. Darüber hinaus müssen Sie die Aufmerksamkeitsspanne in Betracht ziehen - wussten Sie, dass Sie nur etwa 30 Sekunden Zeit haben, um die Aufmerksamkeit eines Verbrauchers zu erregen? Aus diesem Grund ist es wichtig, Hochverfügbarkeit (High Availability, HA) für Ihre Anwendungen zu implementieren. In diesem Blogbeitrag werde ich HA definieren, die verschiedenen Komponenten erklären, die in eine grundlegende HA-Architektur einfließen, und untersuchen, wie man eine einfache HA-Infrastruktur für eine Webanwendung erstellt.
Was ist Hochverfügbarkeit?
Zuerst definieren wir die Verfügbarkeit: Sie ist der Prozentsatz der Gesamtzeit, in der ein Computersystem für die normale Nutzung zugänglich ist. Mit anderen Worten, die Verfügbarkeit beschreibt, in welchem Umfang ein System online und zugänglich ist. Man könnte annehmen, dass die optimale Verfügbarkeit 100 % beträgt, aber das ist unmöglich.
Hier kommt Hochverfügbarkeit ins Spiel. HA-Systeme sind solche mit einer Online-Verfügbarkeit von 99,9 bis 99,999 Prozent der Zeit (siehe Tabelle 1). Ein idealer HA, den man anstreben sollte, ist 99,999 % - "fünf Neunen" - was etwa fünf Minuten Ausfallzeit pro Jahr entspricht.
Hochverfügbarkeit in Zahlen
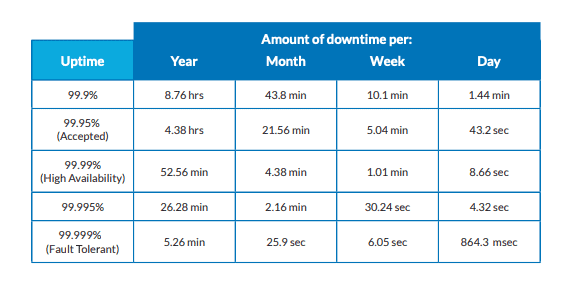
Systementwickler versuchen, den höchstmöglichen HA-Wert zu erreichen. HA kann durch Fehlertoleranz erhöht werden. Dabei werden verschiedene Systemeigenschaften aufgebaut, die ein Weiterlaufen im Falle eines Systemausfalls ermöglichen. Beispiele für Fehlertoleranzfunktionen sind Redundanz und Replikation - mehr dazu gleich.
Wie funktioniert Hochverfügbarkeit?
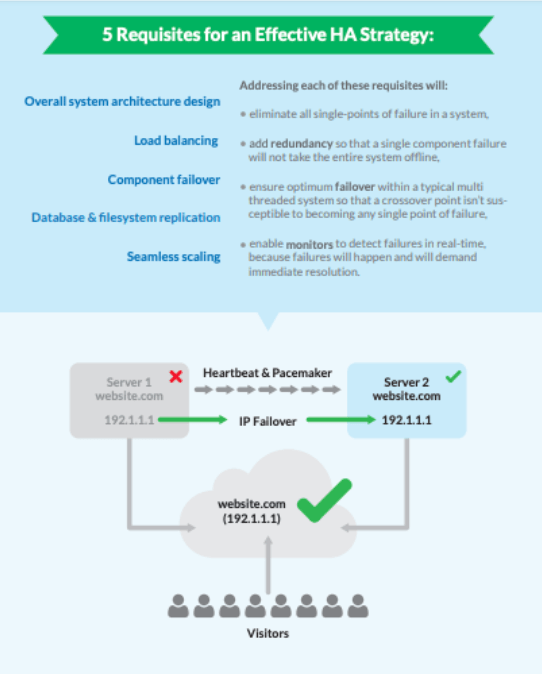
Es gibt viele Funktionen, die zum Aufbau eines idealen HA-Systems beitragen können. Diese Komponenten müssen miteinander integriert sein, kontinuierlich überwacht werden und eine schnelle Wiederherstellung ermöglichen. Dazu gehören:
- Redundanz,
- Lastausgleich,
- Hardware- und Software-Failover über verschiedene Komponenten hinweg,
- Datenreplikation, und
- automatische Skalierung.
Diese Merkmale werden im folgenden Diagramm näher erläutert:
So bewerten Sie die Verfügbarkeit Ihres Systems
Sie möchten die Verfügbarkeit der Infrastruktur Ihrer Cloud bestimmen? Sie basiert auf drei Kriterien:
- seine Größe und seinen Umfang
- Einbindung von Hardwarekomponenten
- voraussichtliche Skalierung zur Deckung des zukünftigen Bedarfs
Nach der Bewertung können Sie sich gegebenenfalls für eine Überarbeitung Ihrer Infrastruktur entscheiden. Ich empfehle Ihnen, jedes Kriterium zuerst einzeln und dann zusammen zu überprüfen. Die Überarbeitung Ihrer Architektur kann virtuelle Tools beinhalten, wie z.B.:
- neue Sekundärserver und Add-ons
- HA-fähige Software-Dienstprogramme
- ergänzende Hardware
Wie wirkt sich der Lastausgleich auf HA aus?
Der Lastausgleich verteilt den eingehenden Datenverkehr intelligent auf einen oder mehrere Server. Entsprechende Tools wie z.B. der Linode NodeBalancer sind so konzipiert, dass sie "gesetzt und vergessen" werden können. Sie ermöglichen es, Backend-Server nahtlos hinzuzufügen oder zu entfernen, ohne dass Endbenutzer Ausfallzeiten hinnehmen müssen.
Ein typischer Load Balancer überwacht eine IP-Adresse auf eingehende Anfragen und scannt sie auf Überlastung oder Fehler. Findet er etwas, folgt er vorkonfigurierten Regeln (einschließlich des zugewiesenen IP-Failovers), um den Datenverkehr an einen leichter zugänglichen Knoten zu senden. Auf diese Weise wird der Datenverkehr gleichmäßig verteilt, es kommt zu keinen Störungen für den Endbenutzern.
Fast alle Anwendungen können vom Lastausgleich profitieren. Es ist eine Schlüsselkomponente für die Skalierung von Benutzern mit gleichzeitiger Redundanz.

Was genau ist ein Failover?
Der Failover ist der Eckpfeiler der HA-Systeme. Mit einem Failover werden Tasks bei geplanten oder versehentlichen Ausfallzeiten automatisch auf einen sekundären oder tertiären Server umgeleitet.
Ein Failover umfasst sowohl Hard- als auch Softwarelösungen, wie z.B. beim Hinzufügen von gespiegelten Datenbankservern zu einem Cluster oder beim Konfigurieren einer IP-Adresse, so dass der Datenverkehr auf den gerade verfügbaren Server geleitet wird.
Wie funktioniert die Dateisystemreplikation?
In einem HA-Cluster wird jeder Server (z.B. für Apps, Datenbanken oder Dateisysteme) so konfiguriert, dass er andere Server spiegelt, wobei gespeicherte Daten automatisch auf alle anderen Server in der Architektur repliziert werden. Eingehende Anfragen können auf Daten zugreifen, unabhängig davon, auf welchem Server sie sich befinden. Dies führt zu einem nahtlosen Erlebnis für den Endanwender.
Network File System (NFS)-Software wie GlusterFS, LizardFS oder HDFS kann verschiedene Servertypen zu einem parallelen Netzwerk-Dateisystem zusammenfassen. Sollte ein Server ausfallen, leitet die NFS-Software an ihn gerichtete Anfragen automatisch an einen Online-Server um, dessen Dateien und Daten gespiegelt und synchronisiert wurden.

Was ist mit der Datenbank?
Unser Ziel ist es hier, eine synchrone Replikation zu erreichen - Ihre Daten werden kontinuierlich von einem Datenbankserver auf einen anderen kopiert. Dies führt zu einer einheitlichen Datenverteilung an die Endanwender, ohne Unterbrechungen. Dies können Sie mit den folgenden Softwareplattformen in beliebiger Kombination erreichen:
Wie passt Seamless Scaling hier hinein?
Sie benötigen Ihr System, um zu wachsen und auf Endbenutzer zu reagieren. Jedes System ist anders, so dass es keine einzigartige, einheitliche Plattform gibt, um ein System unter Beibehaltung der HA zu skalieren. Sie müssen die richtige Distributed Deployment Platform für sich auswählen. Hier einige Beispiele:
- SaltStack: eine skalierbare und flexible Konfigurationsmanagement-Plattform für die ereignisgesteuerte Cloud-Automatisierung.
- Chef: Software, die Anleitungen für die Systemkonfiguration in Erlang oder Ruby schreibt.
- Puppet: Software, die die Konfiguration von Unix-ähnlichen und Microsoft Windows-Systemen verwaltet.
Schauen wir uns ein Beispiel an
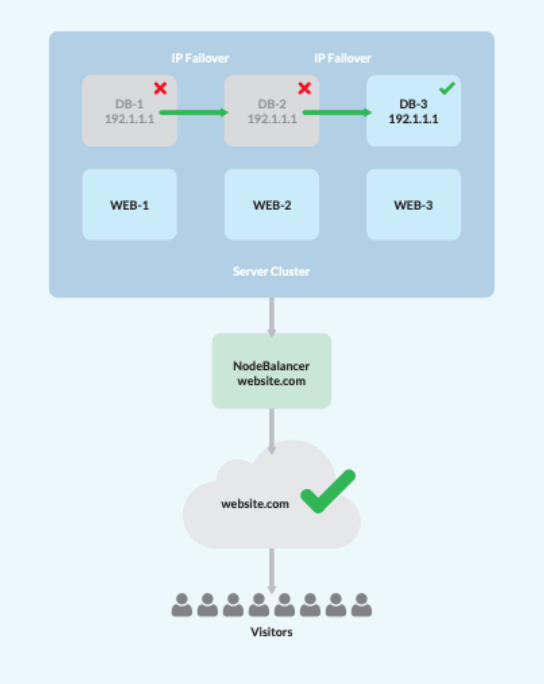
Um die Dinge richtig werten zu können, haben wir eine Liste von Schritten zusammengestellt, mit denen wir HA erreichen können. Dabei wird ein System mit einem Load Balancer, drei Web-/Anwendungs-Servern und drei Datenbankservern entworfen. Bitte beachten Sie: Es sind mindestens drei DB-Server erforderlich, um das Datenquorum innerhalb von HA-Architekturen zu erreichen.
- Sobald der Cluster zusammengestellt ist, konfigurieren Sie die Web/App-Server so, dass sie die Standort-Daten mit Ihrem bevorzugten NFS replizieren.
- Dadurch wird der Load Balancer aktiviert und der Datenverkehr auf die drei Web/App-Knoten verteilt, wobei ausgefallene Knoten automatisch entfernt werden.
- Erstellen Sie eine MySQL Master-Master-Konfiguration mit Percona XtraDB.
- Bestimmen Sie eine schwebende private IP, die von Keepalived verwaltet wird, um als Failover zu fungieren.
- Richten Sie alle Web-/App-Server auf die schwebende private IP aus, damit sie automatisch auf einen Online-Datenbankknoten umziehen, falls ein DB-Server ausfällt.
Voila! Dies führt zu einer minimalen Unterbrechung für die Endbenutzer, da der Serverzugriff trotz eines eventuellen Fehlerpunkts verfügbar bleibt.
Fazit
Sie wollen also ein HA-System einrichten?
Es ist wichtig zu wissen, dass dies eine sorgfältige Planung erfordert. Zuerst müssen Sie die tatsächlichen Kosten von Ausfallzeiten berechnen. Dies variiert je nach Unternehmen und spielt eine Schlüsselrolle bei der Bestimmung, wie viel Ausfallzeit in einem bestimmten Jahr akzeptabel ist. Diese Informationen sind entscheidend für die Hardwarekonfiguration, die Softwaretools und die Systemwartung.
Das Hinzufügen von Hardwarekomponenten zu einem System kann HA erschweren. Das Hinzufügen eines Servers zu Ihrem Cluster erhöht letztlich das Risiko eines Ausfalls, daher muss es richtig gemacht werden.
Es ist wahr - eine vereinfachte Systemarchitektur ist, naja, einfacher. Aber man kommt nicht ohne Kompromisse aus. Diese Art von System muss für jeden einzelnen Patch oder jedes Betriebssystem-Upgrade offline genommen werden. Diese sporadischen Unterbrechungen beeinträchtigen die Verfügbarkeit des Systems. Das Gleiche gilt für Software. Ein einzelner Fehler, wie z.B. ein dummer Tippfehler oder eine schlechte Installation, gefährdet die HA.
Das ideale HA-System - ein System, das mehr als 99,999 Prozent der Zeit online bleibt - bietet Redundanz, Ausfallsicherung und Monitoring und passt Hardware-, Netzwerk-, Betriebssystem-, Middleware- und Anwendungs-Patches und Upgrades in Echtzeit und ohne Unterbrechungen für den Endbenutzers an.







Kommentare (7)
What about geographic redundancy? Node balancers no yet supports nodes in other data centers. How I can achieve this?
You’re right, Javier: our NodeBalancers offer redundancy for Linodes within the same data center. For geographic redundancy, we’d recommend using a CDN service, such as Cloudflare, Fastly, Limelight, or similar. You could set this up yourself by using a service such as HAProxy. There’s a great Community Questions post that covers this in further detail: https://www.linode.com/community/questions/17647/can-i-use-nodebalancers-across-data-centers
Otherwise, we’ve added this as a feature request for future NodeBalancer development to our internal tracker. If we make any changes, we’ll be sure to post about them here on our blog.
What about geographic redundancy?
Hi there! I just responded to a similar comment above. In short, we recommend a CDN for geographic redundancy, though you could use HAProxy if you’d like to set this up yourself.
Thanks for writing the awesome article. I really loved the stuff. You see, I have been using Linode server from past 2 years and it’s been working pretty awesome for me. Although, it’s not the conventional hosting server. Instead it’s the managed hosting instance which is being managed by Cloudways.
I hardly remember any downtime. So, am I consistently experiencing the high availability? or Cloudways is playing it’s role.
Thanks for the compliment, Marilu! There are a few things that can cause uptime, such as the dependability of the hosts or the host’s software. In your case, it could be both. In regards to Cloudways’ service, I suggest reaching out to their support as they would be in a better position to answer that question.
Yeah sure! I regularly talk to the Cloudways support team. This time I will ask them the secret behind their service.