

TL;DR : Dans ce billet, vous apprendrez à choisir le meilleur nœud pour votre cluster Kubernetes avant d'écrire le moindre code.
Lorsque vous créez un cluster Kubernetes, l'une des premières questions que vous pouvez vous poser est la suivante : "Quel type de nœuds de travailleur dois-je utiliser, et combien d'entre eux ?".
Ou si vous utilisez un service Kubernetes géré comme Linode Kubernetes Engine (LKE), devez-vous utiliser huit instances Linode 2 Go ou deux instances Linode 8 Go pour atteindre la capacité de calcul souhaitée ?
Tout d'abord, toutes les ressources des nœuds de travail ne peuvent pas être utilisées pour exécuter des charges de travail.
Réservations de nœuds Kubernetes
Dans un nœud Kubernetes, le CPU et la mémoire sont divisés en :
- Système d'exploitation
- Kubelet, CNI, CRI, CSI (et démons du système)
- Cosse
- Seuil d'expulsion
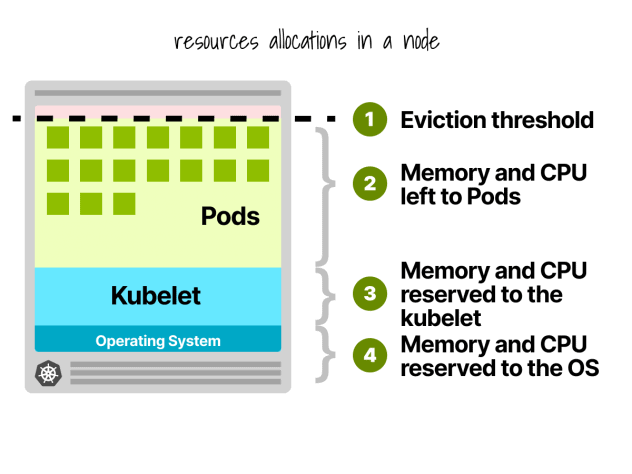
Prenons un exemple rapide.
Imaginez que vous ayez un cluster avec une seule instance de calcul Linode 2GB, ou 1 vCPU et 2GB de RAM.
Les ressources suivantes sont réservées au kubelet et au système d'exploitation :
- -500 Mo de mémoire.
- -60m de l'unité centrale.
En outre, 100 Mo sont réservés au seuil d'éviction.
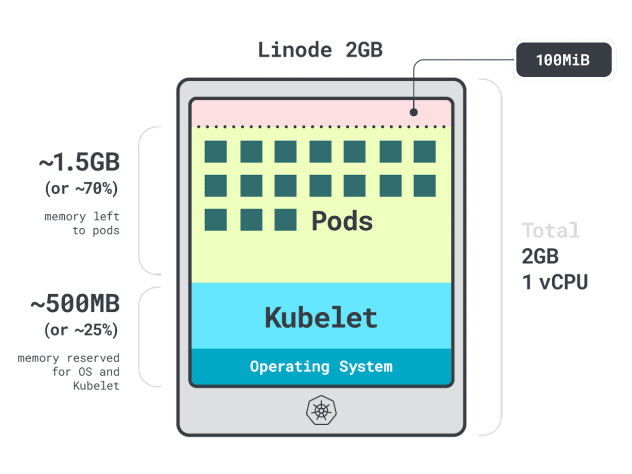
Au total, c'est 30 % de la mémoire et 6 % de l'unité centrale que vous ne pouvez pas utiliser.
Chaque fournisseur de services en nuage a sa propre façon de définir les limites, mais pour l'unité centrale, ils semblent tous s'accorder sur les valeurs suivantes :
- 6% du premier noyau ;
- 1% du cœur suivant (jusqu'à 2 cœurs) ;
- 0,5 % des 2 noyaux suivants (jusqu'à 4) ; et
- 0,25 % de tous les cœurs au-dessus de quatre cœurs.
Quant aux limites de mémoire, elles varient beaucoup d'un fournisseur à l'autre.
Mais en général, la réservation suit ce tableau :
- 25 % des 4 premiers Go de mémoire ;
- 20 % des éléments suivants 4 Go de mémoire (jusqu'à 8 Go) ;
- 10 % des éléments suivants 8 Go de mémoire (jusqu'à 16 Go) ;
- 6 % des 112 Go de mémoire suivants (jusqu'à 128 Go) ; et
- 2 % de toute mémoire supérieure à 128 Go.
Maintenant que vous savez comment les ressources sont réparties à l'intérieur d'un nœud de travail, il est temps de poser la question délicate : quelle instance devriez-vous choisir ?
Comme il peut y avoir plusieurs réponses correctes, limitons nos options en nous concentrant sur le nœud de travail le mieux adapté à votre charge de travail.
Profilage des applications
Dans Kubernetes, vous avez deux façons de spécifier la quantité de mémoire et de CPU qu'un conteneur peut utiliser :
- Les demandes correspondent généralement à la consommation de l'application en fonctionnement normal.
- Les limites définissent le nombre maximum de ressources autorisées.
Le planificateur de Kubernetes utilise les demandes pour déterminer où le module doit être alloué dans le cluster. Comme le planificateur ne connaît pas la consommation (le pod n'a pas encore démarré), il a besoin d'un indice. Ces "hints" sont des requêtes ; vous pouvez en avoir une pour la mémoire et une pour le CPU.
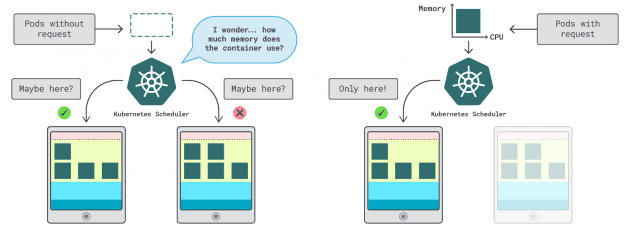
Le kubelet utilise des limites pour arrêter le processus lorsqu'il utilise plus de mémoire que ce qui est autorisé. Il limite également le processus s'il utilise plus de temps CPU que ce qui est autorisé.
Mais comment choisir les bonnes valeurs pour les demandes et les limites ?
Vous pouvez mesurer les performances de votre charge de travail (moyenne, 95e et 99e percentile, etc.) et les utiliser comme demandes de limites. Pour faciliter le processus, deux outils pratiques peuvent accélérer l'analyse :
L'APV collecte les données d'utilisation de la mémoire et du CPU et exécute un algorithme de régression qui suggère des requêtes et des limites pour votre déploiement. C'est un projet officiel de Kubernetes et il peut également être instrumenté pour ajuster les valeurs automatiquement -vous pouvez demander au contrôleur de mettre à jour les demandes et les limites directement dans votre YAML.
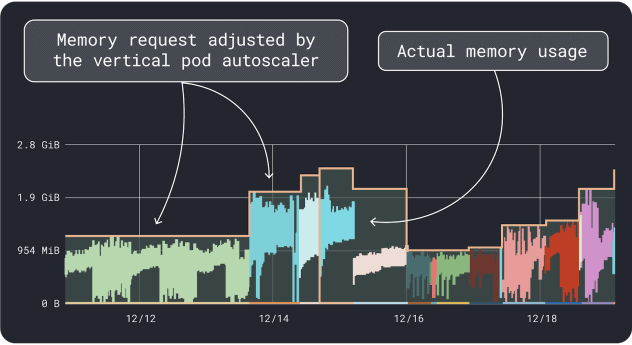
KRR fonctionne de la même manière, mais il exploite les données que vous exportez par l'intermédiaire de Prometheus. Dans un premier temps, vos charges de travail doivent être instrumentées pour exporter des mesures vers Prometheus. Une fois que vous avez stocké toutes les mesures, vous pouvez utiliser KRR pour analyser les données et suggérer des requêtes et des limites.
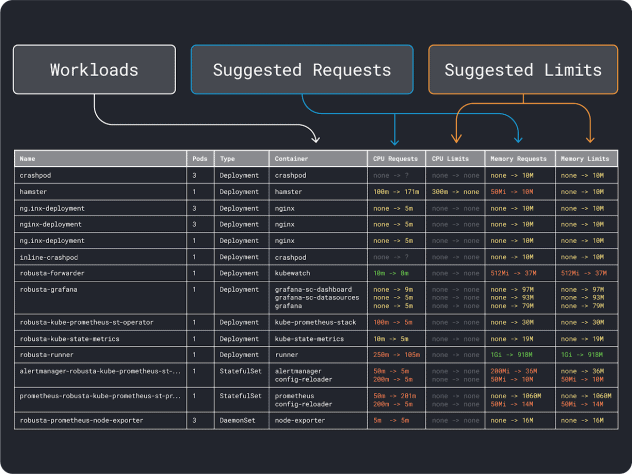
Une fois que vous avez une idée des besoins (approximatifs) en ressources, vous pouvez enfin sélectionner un type d'instance.
Sélection d'un type d'instance
Imaginez que vous estimiez que votre charge de travail nécessite 2 Go de requêtes mémoire et que vous estimiez avoir besoin d'au moins 10 répliques.
Vous pouvez déjà exclure la plupart des petites instances avec moins de `2GB * 10 = 20GB`. A ce stade, vous pouvez deviner une instance qui pourrait bien fonctionner : choisissons Linode 32GB.
Ensuite, vous pouvez diviser la mémoire et le CPU par le nombre maximum de pods qui peuvent être déployés sur cette instance (c'est-à-dire 110 dans LKE) pour obtenir une unité discrète de mémoire et de CPU.
Par exemple, les unités de CPU et de mémoire pour le Linode 32 GB sont les suivantes :
- 257MB pour l'unité de mémoire (c'est-à-dire (32GB - 3.66GB réservés) / 110)
- 71m pour l'unité centrale (c'est-à-dire (8000m - 90m réservés) / 110)
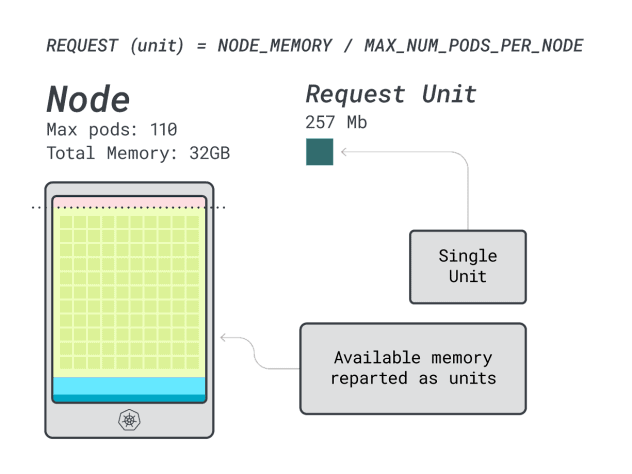
Excellent ! Dans la dernière (et ultime) étape, vous pouvez utiliser ces unités pour estimer le nombre de charges de travail que peut contenir le nœud.
En supposant que vous souhaitiez déployer un Spring Boot avec des requêtes de 6GB et 1 vCPU, cela se traduit par :
- Le plus petit nombre d'unités correspondant à 6GB est 24 unités (24 * 257MB = 6.1GB).
- Le plus petit nombre d'unités correspondant à 1 vCPU est de 15 unités (15 * 71m = 1065m).
Les chiffres suggèrent que vous serez à court de mémoire avant d'être à court de CPU, et que vous pouvez avoir au maximum (110/24) 4 applications déployées dans le cluster.
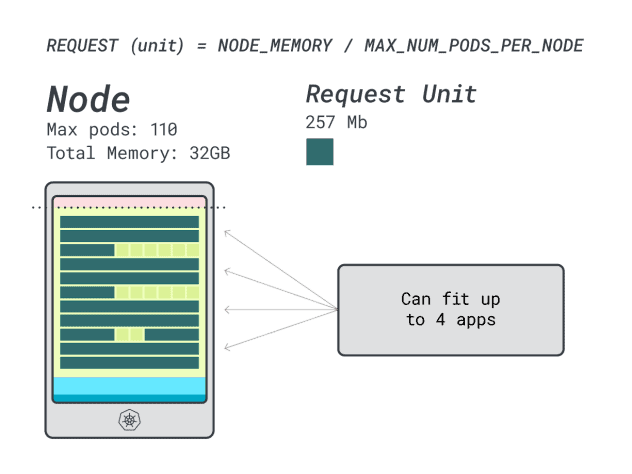
Lorsque vous exécutez quatre charges de travail sur cette instance, vous utilisez :
- 24 unités de mémoire \* 4 = 96 unités et 14 sont inutilisées (~12%)
- 15 unités vCPU \* 4 = 60 unités et 50 sont inutilisées (~45%)
Ce n'est pas mal, mais pouvons-nous faire mieux ?
Essayons avec une instance Linode 64 GB (64GB / 16 vCPU).
En supposant que vous souhaitiez déployer la même application, les chiffres changent :
- Une unité de mémoire représente ~527MB (c'est-à-dire (64GB - 6.06GB réservé) / 110).
- Une unité centrale représente ~145m (c'est-à-dire (16000m - 110m réservés) / 110).
- Le plus petit nombre d'unités correspondant à 6GB est 12 unités (12 * 527MB = 6.3GB).
- Le plus petit nombre d'unités correspondant à 1 vCPU est de 7 unités (7 * 145m = 1015m).
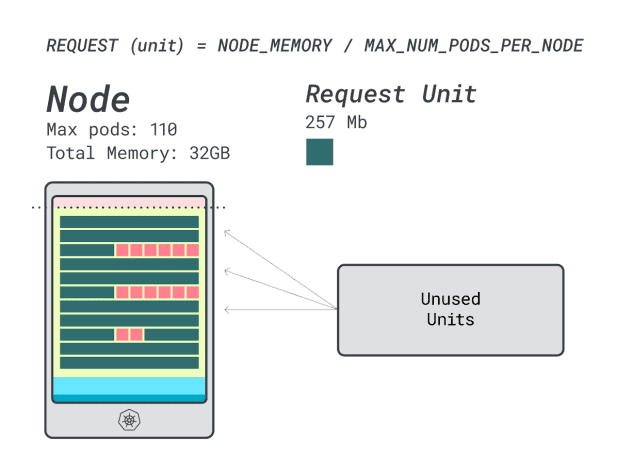
Combien de charges de travail pouvez-vous intégrer dans cette instance ?
Étant donné que la mémoire est au maximum et que chaque charge de travail nécessite 12 unités, le nombre maximal d'applications est de 9 (c'est-à-dire 110/12).
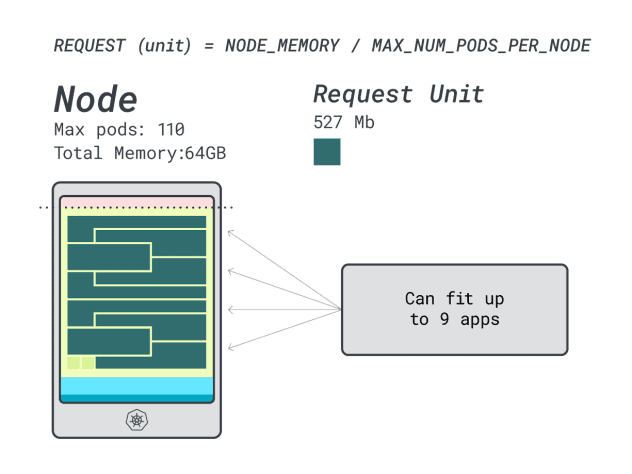
Si vous calculez l'efficacité/le gaspillage, vous trouverez :
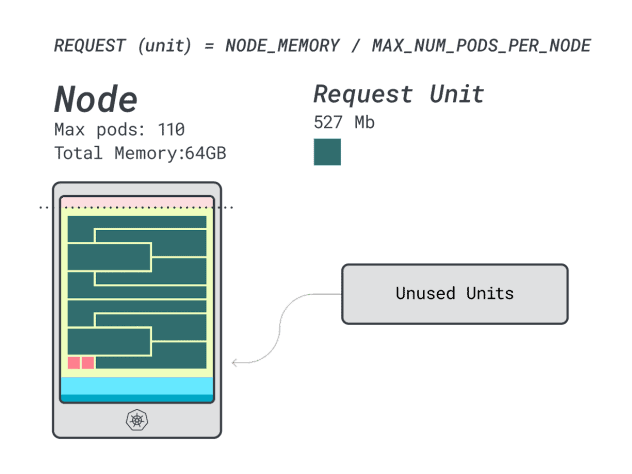
- 12 unités de mémoire \* 9 = 108 unités et 2 sont inutilisées (~2%)
- 7 unités vCPU \* 9 = 63 unités et 47 sont inutilisées (~42%)
Alors que les chiffres relatifs à l'unité centrale gaspillée sont presque identiques à ceux de l'instance précédente, l'utilisation de la mémoire s'est considérablement améliorée.
Nous pouvons enfin comparer les coûts :
- L'instance Linode 32 Go peut accueillir au maximum 4 charges de travail. À la capacité totale, chaque pod coûte 48 $ / mois (soit 192 $ de coût de l'instance divisé par quatre charges de travail).
- *L'instance Linode 64 Go peut accueillir jusqu'à 9 charges de travail. À la capacité totale, chaque pod coûte 42,6 $ / mois (c'est-à-dire 384 $ de coût de l'instance divisé par neuf charges de travail).
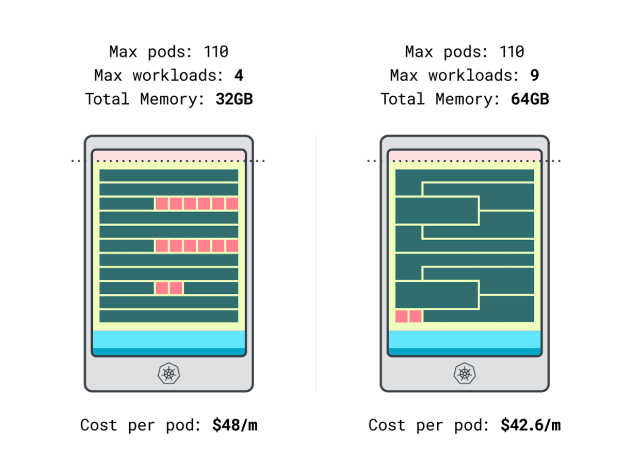
En d'autres termes, le choix d'une instance plus grande peut vous faire économiser jusqu'à 6 dollars par mois et par charge de travail. C'est formidable !
Comparaison des nœuds à l'aide de la calculatrice
Mais qu'en est-il si vous souhaitez tester davantage d'instances ? Effectuer ces calculs représente un travail considérable.
Accélérez le processus en utilisant la calculatrice learnk8s.
La première étape de l'utilisation de la calculatrice consiste à entrer vos demandes de mémoire et de CPU. Le système calcule automatiquement les ressources réservées et suggère l'utilisation et les coûts. Il existe d'autres fonctions utiles : assigner les demandes d'unité centrale et de mémoire en fonction de l'utilisation de l'application. Si l'application utilise occasionnellement beaucoup de mémoire ou d'unité centrale, c'est très bien.
Mais que se passe-t-il lorsque tous les pods utilisent toutes les ressources jusqu'à leurs limites ?
Cela peut entraîner un surengagement. Le widget au centre vous donne un pourcentage de surcharge du processeur ou de la mémoire.
Que se passe-t-il lorsque l'on s'engage trop ?
- Si vous vous engagez trop sur la mémoire, le kubelet expulsera les pods et les déplacera ailleurs dans le cluster.
- Si vous vous engagez trop sur l'unité centrale, les charges de travail utiliseront l'unité centrale disponible de manière proportionnelle.
Enfin, vous pouvez utiliser le widget DaemonSets et Agent, un mécanisme pratique pour modéliser des pods qui s'exécutent sur tous vos nœuds. Par exemple, le plugin Cilium et CSI de LKE est déployé en tant que DaemonSets. Ces pods utilisent des ressources qui ne sont pas disponibles pour vos charges de travail et doivent être soustraites des calculs. Le widget vous permet justement de le faire !
Résumé
Dans cet article, vous vous êtes plongé dans un processus systématique de tarification et d'identification des nœuds de travail pour votre cluster LKE.
Vous avez appris comment Kubernetes réserve des ressources pour les nœuds et comment vous pouvez optimiser votre cluster pour en tirer parti. Vous voulez en savoir plus ? Inscrivez-vous pour voir cela en action grâce à notre webinaire en partenariat avec les services de cloud computing d'Akamai.



Commentaires