

TL;DR: En este post, usted aprenderá cómo elegir el mejor nodo para su clúster Kubernetes antes de escribir cualquier código.
Cuando se crea un clúster Kubernetes, una de las primeras preguntas que puede surgir es: "¿Qué tipo de nodos trabajadores debo utilizar y cuántos de ellos?".
O si utiliza un servicio gestionado de Kubernetes como Linode Kubernetes Engine (LKE), ¿debería utilizar ocho instancias de Linode 2 GB o dos de Linode 8 GB para alcanzar la capacidad informática deseada?
En primer lugar, no todos los recursos de los nodos trabajadores pueden utilizarse para ejecutar cargas de trabajo.
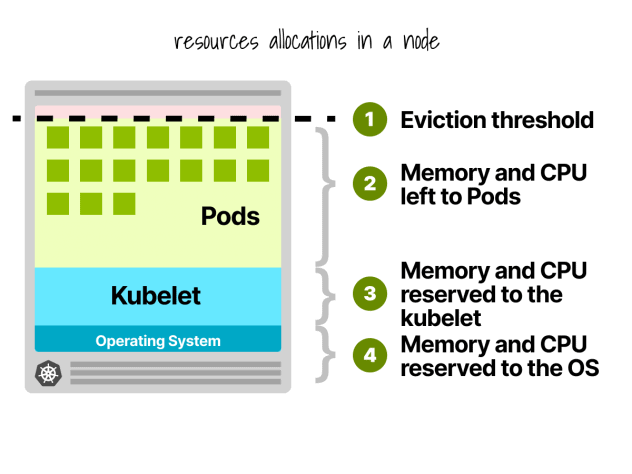
Reservas de nodos Kubernetes
En un nodo Kubernetes, la CPU y la memoria se dividen en:
- Sistema operativo
- Kubelet, CNI, CRI, CSI (y demonios del sistema)
- Vainas
- Umbral de desahucio
Pongamos un ejemplo rápido.
Imagina que tienes un cluster con una única instancia de computaciónLinode 2GB, o 1 vCPU y 2GB de RAM.
Los siguientes recursos están reservados para el kubelet y el sistema operativo:
- -500 MB de memoria.
- -60m de CPU.
Además, se reservan 100 MB para el umbral de desalojo.
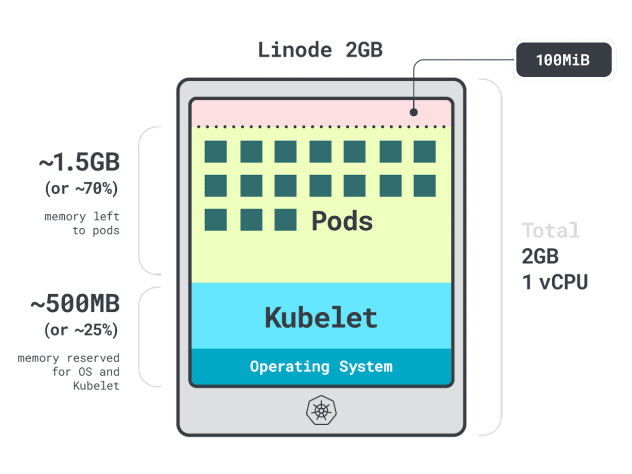
En total, un 30% de memoria y un 6% de CPU que no puedes utilizar.
Cada proveedor de nube tiene su forma de definir los límites, pero para la CPU, todos parecen estar de acuerdo en los siguientes valores:
- 6% del primer núcleo;
- 1% del núcleo siguiente (hasta 2 núcleos);
- 0,5% de los 2 núcleos siguientes (hasta 4); y
- 0,25% de cualquier núcleo por encima de cuatro núcleos.
En cuanto a los límites de memoria, varían mucho de un proveedor a otro.
Pero, en general, la reserva sigue esta tabla:
- 25% de los primeros 4 GB de memoria;
- 20% de los siguientes 4 GB de memoria (hasta 8 GB);
- 10% de los siguientes 8 GB de memoria (hasta 16 GB);
- 6% de los siguientes 112 GB de memoria (hasta 128 GB); y
- 2% de cualquier memoria superior a 128 GB.
Ahora que ya sabes cómo se reparten los recursos dentro de un nodo trabajador, es hora de plantearse la pregunta difícil: ¿qué instancia debes elegir?
Dado que podría haber muchas respuestas correctas, vamos a restringir nuestras opciones centrándonos en el mejor nodo trabajador para su carga de trabajo.
Aplicaciones de perfiles
En Kubernetes, tienes dos formas de especificar cuánta memoria y CPU puede utilizar un contenedor:
- Las peticiones suelen coincidir con el consumo de la aplicación en condiciones normales de funcionamiento.
- Los límites establecen el número máximo de recursos permitidos.
El programador de Kubernetes utiliza las solicitudes para determinar dónde debe asignarse el pod en el clúster. Dado que el planificador no conoce el consumo (el pod aún no se ha iniciado), necesita una pista. Esas "pistas" son peticiones; puede tener una para la memoria y otra para la CPU.
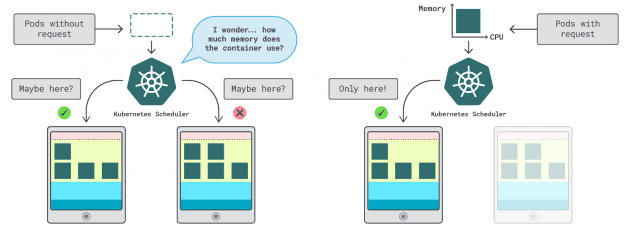
El kubelet utiliza límites para detener el proceso cuando utiliza más memoria de la permitida. También regula el proceso si utiliza más tiempo de CPU del permitido.
Pero, ¿cómo elegir los valores adecuados para las peticiones y los límites?
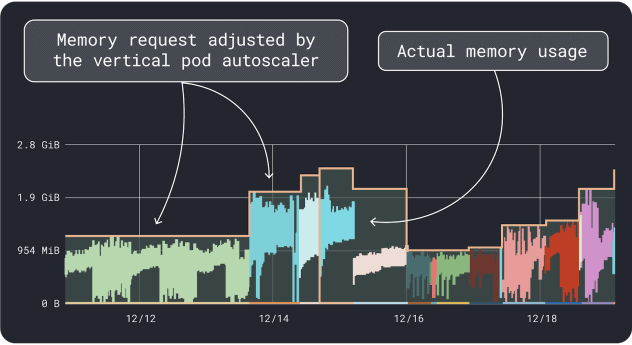
Puedes medir el rendimiento de tu carga de trabajo (es decir, la media, el percentil 95 y 99, etc.) y utilizar esas peticiones como límites. Para facilitar el proceso, dos cómodas herramientas pueden acelerar el análisis:
El VPA recopila los datos de utilización de memoria y CPU y ejecuta un algoritmo de regresión que sugiere solicitudes y límites para su despliegue. Es un proyecto oficial de Kubernetes y también se puede instrumentar para ajustar los valores automáticamente:puede hacer que el controlador actualice las solicitudes y los límites directamente en su YAML.
KRR funciona de forma similar, pero aprovecha los datos que exporta a través de Prometheus. Como primer paso, tus cargas de trabajo deben instrumentarse para exportar métricas a Prometheus. Una vez almacenadas todas las métricas, puedes utilizar KRR para analizar los datos y sugerir peticiones y límites.
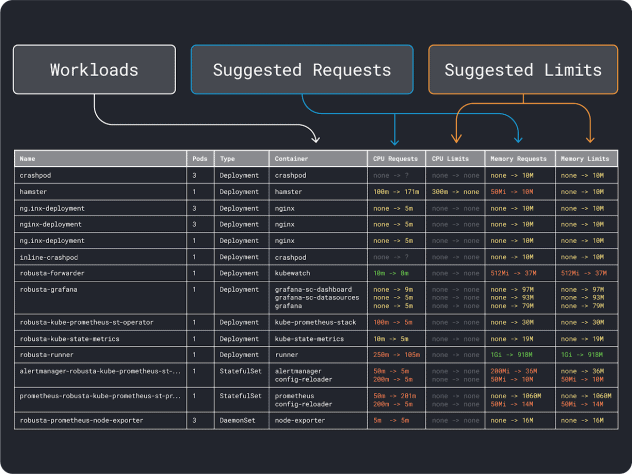
Una vez que tenga una idea (aproximada) de los recursos necesarios, puede pasar a seleccionar un tipo de instancia.
Selección de un tipo de instancia
Imagina que has estimado que tu carga de trabajo requiere 2GB de peticiones de memoria, y que estimas necesitar al menos ~10 réplicas.
Ya puedes descartar la mayoría de instancias pequeñas con menos de `2GB * 10 = 20GB`. Llegados a este punto, puedes adivinar una instancia que podría funcionar bien: elijamos Linode 32GB.
A continuación, puede dividir la memoria y la CPU por el número máximo de pods que pueden desplegarse en esa instancia (es decir, 110 en LKE) para obtener una unidad discreta de memoria y CPU.
Por ejemplo, las unidades de CPU y memoria para el Linode 32 GB son:
- 257 MB para la unidad de memoria (es decir, (32 GB - 3,66 GB reservados) / 110)
- 71 m para la CPU (es decir, (8000 m - 90 m reservados) / 110)
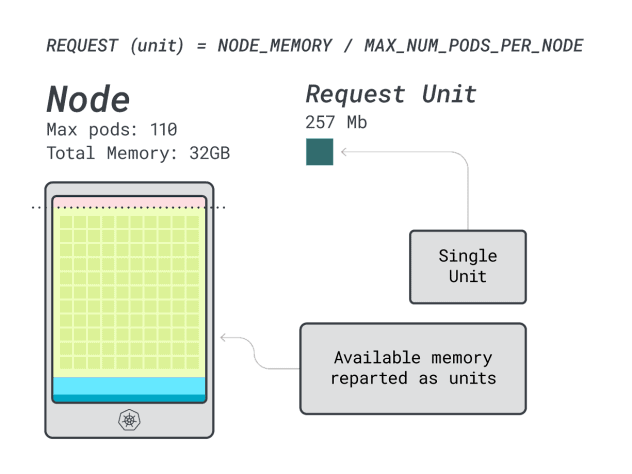
Excelente. En el último (y definitivo) paso, puedes utilizar esas unidades para estimar cuántas cargas de trabajo caben en el nodo.
Asumiendo que quieres desplegar un Spring Boot con peticiones de 6GB y 1 vCPU, esto se traduce en:
- El menor número de unidades que cabe en 6 GB es 24 unidades (24 * 257 MB = 6,1 GB)
- El menor número de unidades que cabe en 1 vCPU es 15 unidades (15 * 71m = 1065m)
Los números sugieren que te quedarás sin memoria antes que sin CPU, y que puedes tener como máximo (110/24) 4 aplicaciones desplegadas en el clúster.
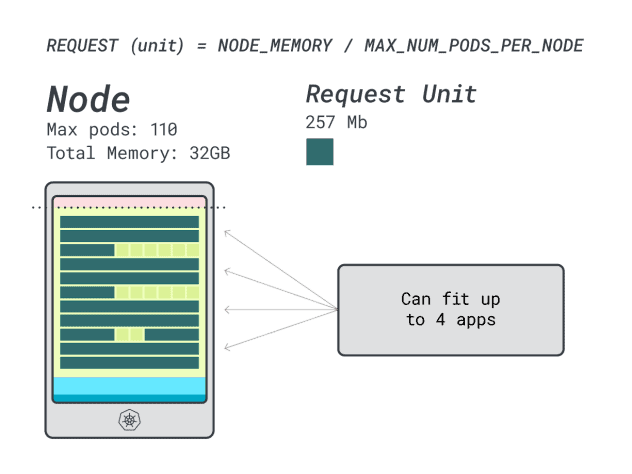
Cuando se ejecutan cuatro cargas de trabajo en esta instancia, se utiliza:
- 24 unidades de memoria \* 4 = 96 unidades y quedan 14 sin utilizar (~12%)
- 15 unidades vCPU \* 4 = 60 unidades y 50 quedan sin usar (~45%)
No está mal, pero ¿podemos hacerlo mejor?
Probemos con una instancia Linode 64 GB (64GB / 16 vCPU).
Suponiendo que quieras desplegar la misma aplicación, los números cambian a:
- Una unidad de memoria equivale a ~527 MB (es decir, (64 GB - 6,06 GB reservados) / 110).
- Una CPU mide ~145m (es decir, (16000m - 110m reservados) / 110).
- El menor número de unidades que cabe en 6 GB es 12 unidades (12 * 527 MB = 6,3 GB).
- El menor número de unidades que cabe en 1 vCPU es 7 unidades (7 * 145m = 1015m).
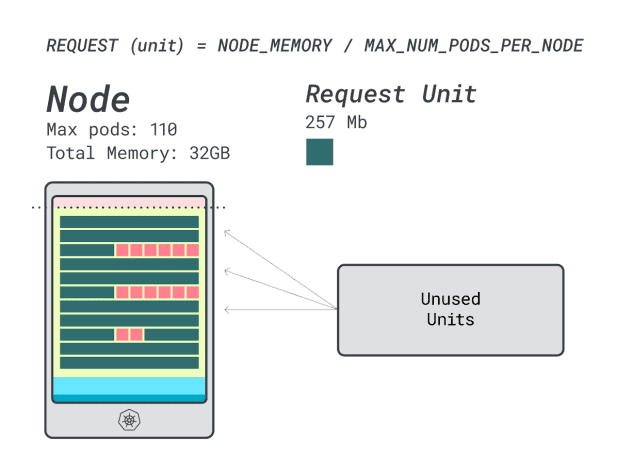
¿Cuántas cargas de trabajo caben en esta instancia?
Como la memoria está al máximo y cada carga de trabajo requiere 12 unidades, el número máximo de aplicaciones es 9 (es decir, 110/12).
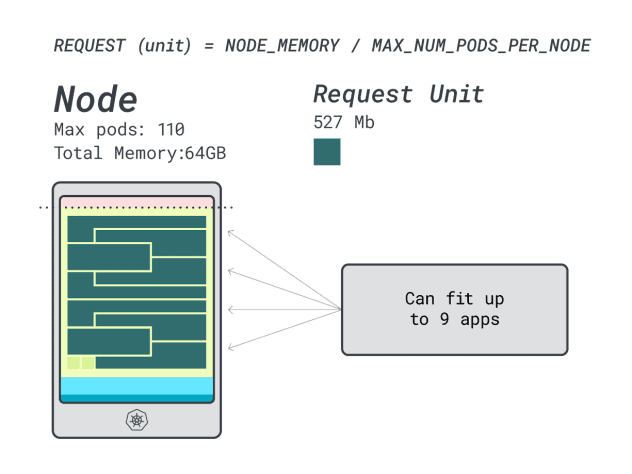
Si calculas la eficiencia/desperdicio, encontrarás:
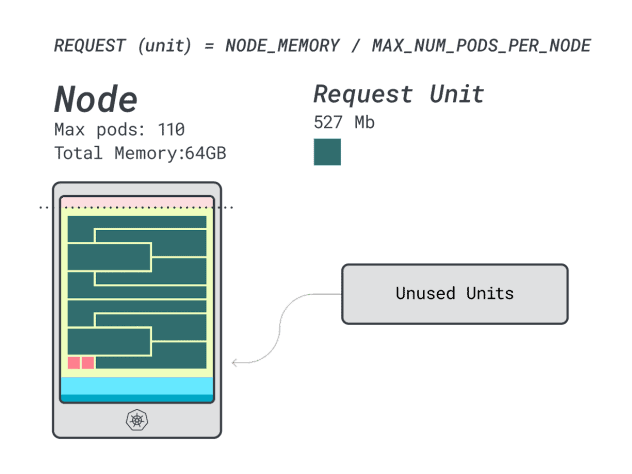
- 12 unidades de memoria \* 9 = 108 unidades y quedan 2 sin utilizar (~2%)
- 7 unidades vCPU \* 9 = 63 unidades y quedan 47 sin utilizar (~42%)
Mientras que los números para la CPU desperdiciada son casi idénticos a los de la instancia anterior, la utilización de la memoria ha mejorado drásticamente.
Por fin podemos comparar costes:
- La instancia Linode de 32 GB tiene capacidad para un máximo de 4 cargas de trabajo. Con la capacidad total, cada pod cuesta 48 $/mes (es decir, 192 $ de coste de la instancia divididos por cuatro cargas de trabajo).
- *La instancia Linode de 64 GB puede albergar hasta 9 cargas de trabajo. Con la capacidad total, cada pod cuesta 42,6 $/mes (es decir, 384 $ de coste de la instancia divididos por nueve cargas de trabajo).
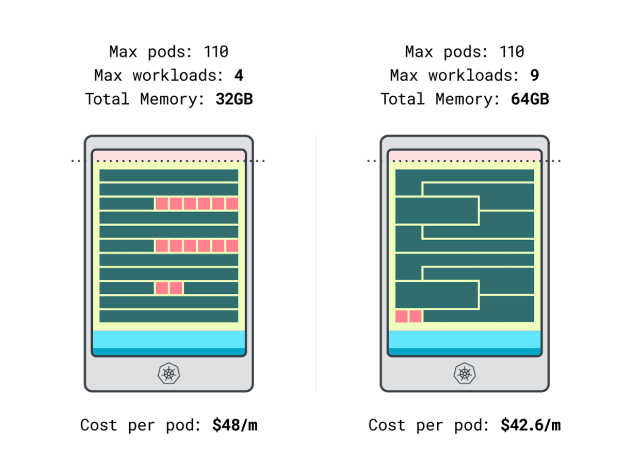
En otras palabras, elegir el tamaño de instancia más grande puede ahorrarle hasta 6 dólares al mes por carga de trabajo. Espléndido.
Comparación de nodos con la calculadora
Pero, ¿y si quieres probar más instancias? Hacer esos cálculos es mucho trabajo.
Acelera el proceso con la calculadora learnk8s.
El primer paso para utilizar la calculadora es introducir tus peticiones de memoria y CPU. El sistema calcula automáticamente los recursos reservados y sugiere la utilización y los costes. Hay algunas funciones útiles adicionales: asigna las solicitudes de CPU y memoria cercanas al uso de la aplicación. Si de vez en cuando la aplicación hace un uso excesivo de la CPU o la memoria, no pasa nada.
Pero, ¿qué ocurre cuando todos los Pods utilizan todos los recursos hasta el límite?
Esto podría llevar a un sobrecompromiso. El widget en el centro le da un porcentaje de sobrecompromiso de CPU o memoria.
¿Qué ocurre cuando te comprometes en exceso?
- Si se sobrecompromete memoria, el kubelet desalojará los pods y los moverá a otro lugar del cluster.
- Si sobrecompromete la CPU, las cargas de trabajo utilizarán la CPU disponible proporcionalmente.
Por último, puede utilizar el widget DaemonSets y Agent, un práctico mecanismo para modelar pods que se ejecutan en todos sus nodos. Por ejemplo, LKE tiene los plugins Cilium y CSI desplegados como DaemonSets. Estos pods utilizan recursos que no están disponibles para sus cargas de trabajo y deben restarse de los cálculos. El widget le permite hacer precisamente eso.
Resumen
En este artículo, se sumergió en un proceso sistemático para determinar el precio e identificar los nodos trabajadores para su clúster LKE.
Has aprendido cómo Kubernetes reserva recursos para los nodos y cómo puedes optimizar tu clúster para aprovecharlo. ¿Quiere saber más? Regístrese para ver esto en acción con nuestro seminario web en colaboración con los servicios de computación en la nube de Akamai.



Comentarios