

TL;DR: In questo post imparerete a scegliere il nodo migliore per il vostro cluster Kubernetes prima di scrivere qualsiasi codice.
Quando si crea un cluster Kubernetes, una delle prime domande che ci si pone è: "Che tipo di nodi worker devo usare e quanti?".
Oppure, se si utilizza un servizio Kubernetes gestito come Linode Kubernetes Engine (LKE), è opportuno utilizzare otto istanze Linode da 2 GB o due Linode da 8 GB per ottenere la capacità di calcolo desiderata?
Innanzitutto, non tutte le risorse dei nodi worker possono essere utilizzate per eseguire i carichi di lavoro.
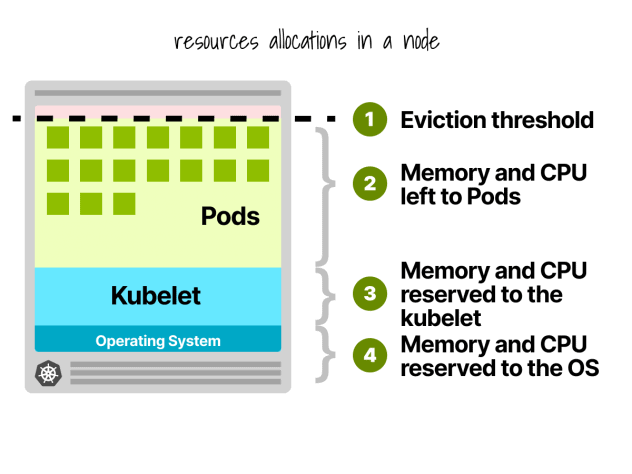
Prenotazioni dei nodi Kubernetes
In un nodo Kubernetes, la CPU e la memoria sono suddivise in:
- Sistema operativo
- Kubelet, CNI, CRI, CSI (e demoni di sistema)
- Baccelli
- Soglia di sfratto
Facciamo un rapido esempio.
Immaginate di avere un cluster con una singola istanza di calcolo Linode da 2 GB, o 1 vCPU e 2 GB di RAM.
Le seguenti risorse sono riservate a kubelet e al sistema operativo:
- -500 MB di memoria.
- -60 m di CPU.
Inoltre, 100 MB sono riservati alla soglia di sfratto.
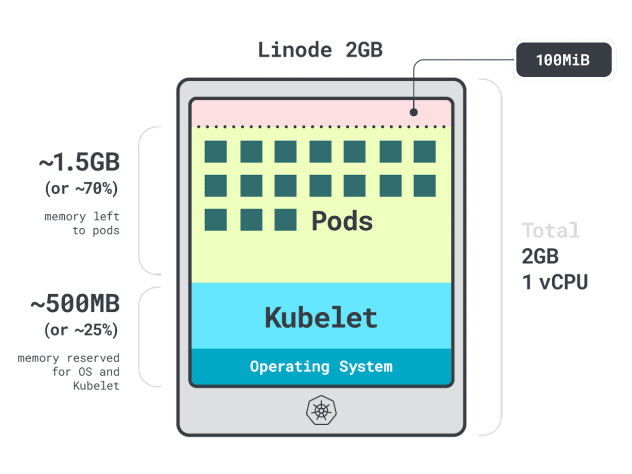
In totale, si tratta del 30% della memoria e del 6% della CPU non utilizzabili.
Ogni fornitore di cloud ha il suo modo di definire i limiti, ma per la CPU sembrano tutti concordare sui seguenti valori:
- 6% del primo nucleo;
- 1% del core successivo (fino a 2 core);
- 0,5% dei 2 core successivi (fino a 4); e
- 0,25% di tutti i core oltre i quattro core.
Per quanto riguarda i limiti di memoria, questi variano molto da un fornitore all'altro.
Ma in generale, la prenotazione segue questa tabella:
- 25% dei primi 4 GB di memoria;
- 20% dei seguenti 4 GB di memoria (fino a 8 GB);
- 10% dei seguenti 8 GB di memoria (fino a 16 GB);
- 6% dei successivi 112 GB di memoria (fino a 128 GB); e
- 2% di qualsiasi memoria superiore a 128 GB.
Ora che si conosce il modo in cui le risorse vengono ripartite all'interno di un nodo worker, è il momento di porre la domanda difficile: quale istanza scegliere?
Poiché le risposte corrette potrebbero essere molte, limitiamo le nostre opzioni concentrandoci sul nodo worker migliore per il vostro carico di lavoro.
Applicazioni di profilazione
In Kubernetes esistono due modi per specificare la quantità di memoria e CPU che un contenitore può utilizzare:
- Le richieste di solito corrispondono al consumo dell'app durante le normali operazioni.
- I limiti impostano il numero massimo di risorse consentite.
Lo scheduler di Kubernetes utilizza le richieste per determinare la posizione del pod nel cluster. Poiché lo scheduler non conosce il consumo (il pod non è ancora stato avviato), ha bisogno di un suggerimento. Questi "suggerimenti" sono richieste; è possibile averne una per la memoria e una per la CPU.
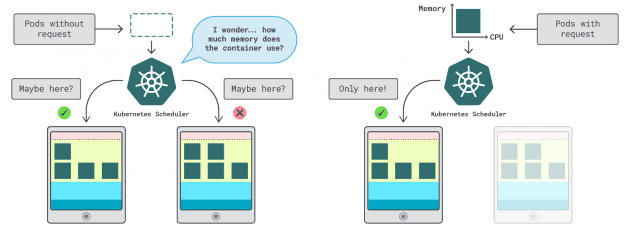
Il kubelet utilizza i limiti per arrestare il processo quando utilizza più memoria di quella consentita. Inoltre, il processo viene limitato se utilizza più tempo di CPU di quanto consentito.
Ma come si fa a scegliere i valori giusti per le richieste e i limiti?
È possibile misurare le prestazioni del carico di lavoro (media, 95° e 99° percentile, ecc.) e utilizzarle come richieste di limiti. Per facilitare il processo, due comodi strumenti possono accelerare l'analisi:
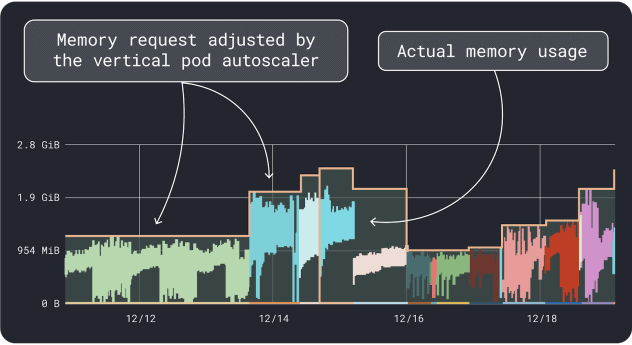
Il VPA raccoglie i dati di utilizzo della memoria e della CPU ed esegue un algoritmo di regressione che suggerisce le richieste e i limiti per la distribuzione. È un progetto ufficiale di Kubernetes e può anche essere strumentato per regolare i valori automaticamente:si può fare in modo che il controllore aggiorni le richieste e i limiti direttamente nello YAML.
KRR funziona in modo simile, ma sfrutta i dati esportati via Prometheus. Come primo passo, i carichi di lavoro devono essere strumentati per esportare le metriche in Prometheus. Una volta memorizzate tutte le metriche, è possibile utilizzare KRR per analizzare i dati e suggerire richieste e limiti.
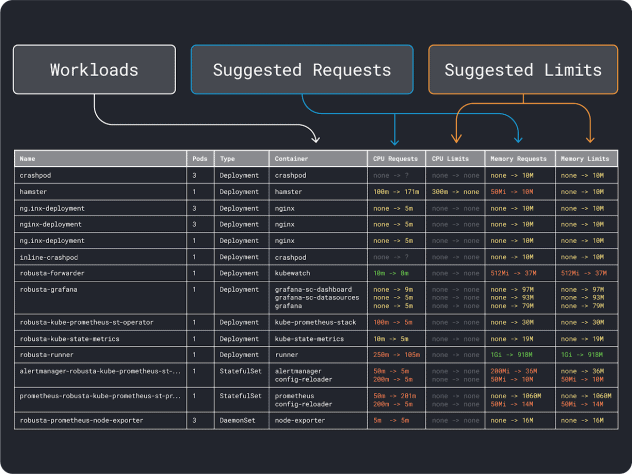
Una volta che si ha un'idea dei requisiti (approssimativi) delle risorse, si può finalmente passare alla selezione di un tipo di istanza.
Selezione di un tipo di istanza
Immaginate di aver stimato che il vostro carico di lavoro richieda 2 GB di memoria e di aver bisogno di almeno ~10 repliche.
È già possibile escludere la maggior parte delle piccole istanze con meno di `2GB * 10 = 20GB`. A questo punto, si può ipotizzare un'istanza che potrebbe funzionare bene: scegliamo Linode 32GB.
Quindi, è possibile dividere la memoria e la CPU per il numero massimo di pod che possono essere distribuiti su quell'istanza (cioè 110 in LKE) per ottenere un'unità discreta di memoria e CPU.
Ad esempio, le unità di CPU e memoria per Linode 32 GB sono:
- 257MB per l'unità di memoria (cioè (32GB - 3,66GB riservati) / 110)
- 71 m per la CPU (cioè (8000 m - 90 m riservati) / 110)
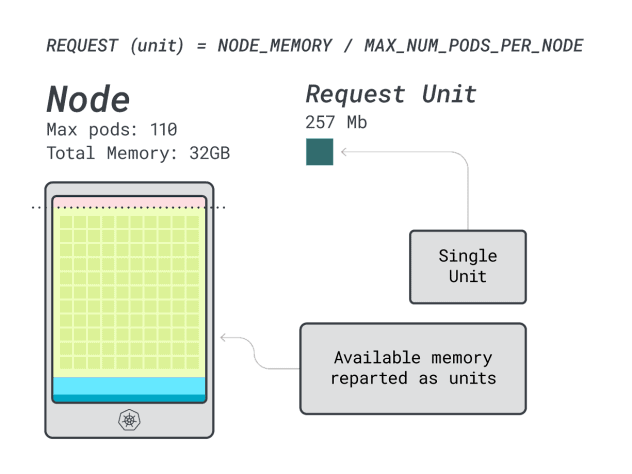
Eccellente! Nell'ultimo (e conclusivo) passo, si possono usare queste unità per stimare quanti carichi di lavoro possono adattarsi al nodo.
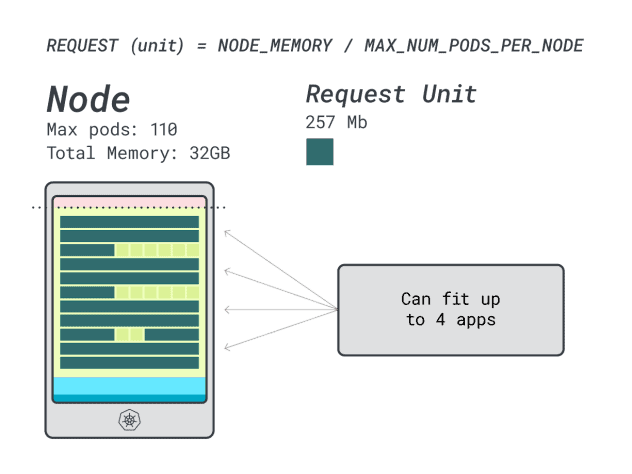
Supponendo di voler distribuire uno Spring Boot con richieste di 6 GB e 1 vCPU, questo si traduce in:
- Il numero più piccolo di unità che si adatta a 6 GB è 24 unità (24 * 257 MB = 6,1 GB).
- Il numero più piccolo di unità che si adatta a 1 vCPU è 15 unità (15 * 71m = 1065m).
I numeri suggeriscono che si esaurirà la memoria prima di esaurire la CPU e che si possono avere al massimo (110/24) 4 applicazioni distribuite nel cluster.
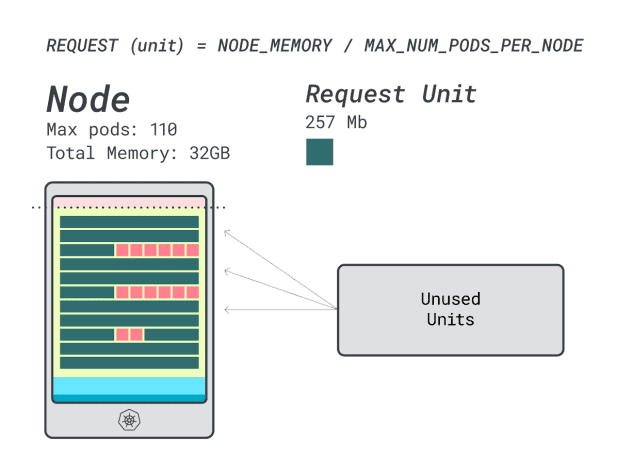
Quando si eseguono quattro carichi di lavoro su questa istanza, si usa:
- 24 unità di memoria \* 4 = 96 unità e 14 rimangono inutilizzate (~12%)
- 15 unità vCPU \* 4 = 60 unità e 50 rimangono inutilizzate (~45%)
Non male, ma possiamo fare meglio?
Proviamo con un'istanza Linode da 64 GB (64 GB / 16 vCPU).
Supponendo di voler distribuire la stessa applicazione, i numeri cambiano in:
- Un'unità di memoria è di ~527MB (cioè (64GB - 6,06GB riservati) / 110).
- Una CPU è di ~145m (cioè (16000m - 110m riservati) / 110).
- Il numero più piccolo di unità che si adatta a 6 GB è 12 unità (12 * 527 MB = 6,3 GB).
- Il numero minimo di unità che si adatta a 1 vCPU è di 7 unità (7 * 145m = 1015m).
Quanti carichi di lavoro si possono inserire in questa istanza?
Poiché la memoria è al massimo e ogni carico di lavoro richiede 12 unità, il numero massimo di applicazioni è 9 (cioè 110/12).
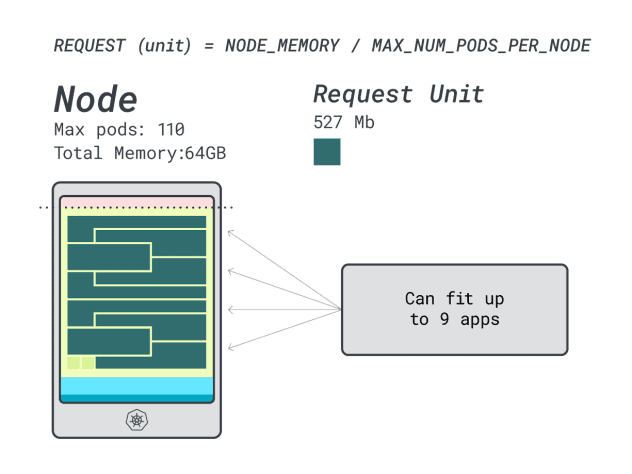
Se si calcola l'efficienza/lo spreco, si scopre che:
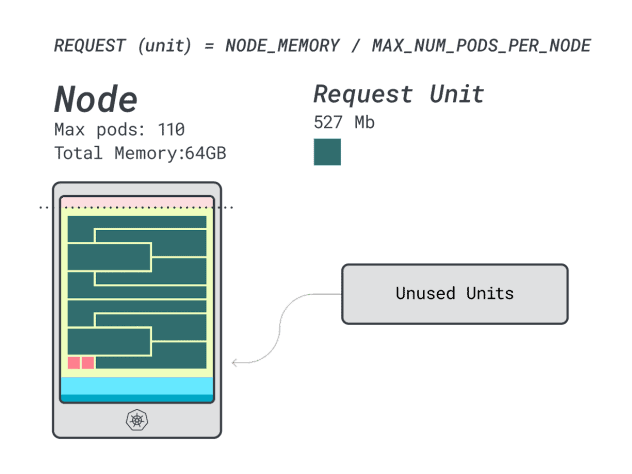
- 12 unità di memoria \* 9 = 108 unità e 2 rimangono inutilizzate (~2%)
- 7 unità vCPU \* 9 = 63 unità e 47 rimangono inutilizzate (~42%)
Mentre i numeri relativi allo spreco di CPU sono quasi identici all'istanza precedente, l'utilizzo della memoria è drasticamente migliorato.
Possiamo finalmente confrontare i costi:
- L'istanza Linode da 32 GB può ospitare al massimo 4 carichi di lavoro. A capacità totale, ogni pod costa 48 dollari al mese (cioè 192 dollari di costo dell'istanza diviso per quattro carichi di lavoro).
- *L'istanza Linode da 64 GB può ospitare fino a 9 carichi di lavoro. A capacità totale, ogni pod costa 42,6 dollari/mese (cioè 384 dollari di costo dell'istanza diviso per nove carichi di lavoro).
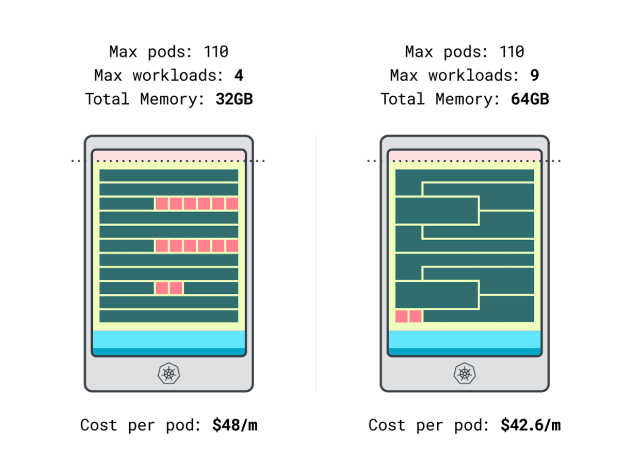
In altre parole, la scelta di un'istanza di dimensioni maggiori può farvi risparmiare fino a 6 dollari al mese per carico di lavoro. Ottimo!
Confronto dei nodi con la calcolatrice
Ma cosa succede se si vogliono testare più istanze? Fare questi calcoli richiede molto lavoro.
Accelerate il processo utilizzando la calcolatrice learnk8s.
Il primo passo per utilizzare il calcolatore è inserire le richieste di memoria e CPU. Il sistema calcola automaticamente le risorse riservate e suggerisce l'utilizzo e i costi. Sono disponibili altre funzioni utili: assegnare le richieste di CPU e memoria in base all'utilizzo dell'applicazione. Se l'applicazione occasionalmente esplode in un utilizzo maggiore della CPU o della memoria, non c'è problema.
Ma cosa succede quando tutti i Pod utilizzano tutte le risorse al loro limite?
Questo potrebbe portare a un sovraccarico di lavoro. Il widget al centro fornisce una percentuale di sovraccarico della CPU o della memoria.
Cosa succede quando ci si impegna troppo?
- Se si esagera con la memoria, il kubelet sfratta i pod e li sposta altrove nel cluster.
- Se si esegue un overcommit sulla CPU, i carichi di lavoro utilizzeranno la CPU disponibile in modo proporzionale.
Infine, è possibile utilizzare il widget DaemonSets e Agent, un comodo meccanismo per modellare pod che vengono eseguiti su tutti i nodi. Ad esempio, LKE ha il plugin Cilium e CSI distribuiti come DaemonSet. Questi pod utilizzano risorse che non sono disponibili per i carichi di lavoro e devono essere sottratti dai calcoli. Il widget consente di farlo!
Sintesi
In questo articolo ci siamo addentrati in un processo sistematico di determinazione del prezzo e di identificazione dei nodi worker per il vostro cluster LKE.
Avete imparato come Kubernetes riserva le risorse per i nodi e come potete ottimizzare il vostro cluster per trarne vantaggio. Volete saperne di più? Registratevi per vedere tutto questo in azione con il nostro webinar in collaborazione con i servizi di cloud computing di Akamai.




Commenti